主要整理了采用冗余双写方案后的问题解决方案。
1、问题:冗余双写场景下,如何解决数据一致性问题?
方案一:
直接RPC调用+Seata分布式事务框架,采用该方式实现了事务的强一致性,代码逻辑简单的同时业务侵入性比较小。Seata支持AT、TCC、Soga三种模式:AT:隔离性好和低改造成本,但性能低;TCC:性能和隔离性好,但改造成本大;Soga:性能和低改造成本,但隔离性不好。先调用写入普通用户的短链表Rpc方法,后调用写入商家短链表的Rpc方法,通过@GlobalTransaction方式注解主方法。
缺点:采用事务一致性后,高并发场景下性能下降严重,且本身Seata自身也存在一定的性能损耗。Seata更适用于后台管理系统等并发量不高的应用,并不适用C端应用。

方案二:
使用消息队列(MQ)作为通信中介是一种高效的方式,其中生产者仅需确认消息发送成功即可,而订阅的消费者(B端/C端)则负责消费消息。对于商户(生产者)而言,一旦消息成功发送,便可立即返回成功标识,使得响应效率最大化。具体的业务逻辑,如创建短链码等任务,则由相应的消费者负责处理。这种方式不再依赖于强一致性(全局锁),从而提升了系统的请求并发量。然而,为确保最终一致性,必须加强消息处理的幂等性和异常处理能力。
缺点:弱一致性,不适用于需要强一致的场景,当消费者消费失败时,需要额外写接口回滚生产者业务逻辑。

2、问题:市面上有很多MQ产品,例如Kafka或RabbitMq,两者各有千秋,Mq产品如何选择?
方案一:
Kafka采用发布/订阅模式,消息被分区并分发给订阅者,每个消费者可以独立地消费特定分区的消息。通过消费者组使得消息能够分组消费,一个topic可以有多个partition,一个partition leader可以由一个消费者组中的一个消费者进行消费。

缺点:Kafka的消息存储是基于日志的,主要用于实时数据处理场景,如日志收集、事件流处理、指标监控等。对于消息传递的可靠性和灵活性,如延迟消费能则缺乏对应支撑,需要业务处理。
方案二:
RabbitMq则是将消息投递到交换机,通过匹配规则投递消息到队列,再由队列对应的消费者进行消费,它更强调消息传递的可靠性,更符合业务场景的功能开发,自带了延迟队列和异常消息处理。其次在rabbitmq的社区更加活跃,配套文档和案例十分完善,降低了使用者的学习成本,并在团队中较多人会使用。

1)Rabbitmq可配置异常超时配置,当队列消费异常时且超出重试次数时,自动将消息投递到异常交换机中,由匹配机制传递到队列,最后再交由异常消费者订阅,短信还是邮件通知告警也是在此处解决。RepublishMessageRecoverer。
#消息确认方式,manual(手动ack) 和auto(自动ack);消息消费重试到达指定次数进到异常交换机和异常队列,需要改为自动ack确认消息
spring.rabbitmq.listener.simple.acknowledge-mode=auto
#开启重试,消费者代码不能添加try catch捕获不往外抛异常
spring.rabbitmq.listener.simple.retry.enabled=true
#最大重试次数
spring.rabbitmq.listener.simple.retry.max-attempts=4
# 重试消息的时间间隔,5秒
spring.rabbitmq.listener.simple.retry.initial-interval=5000
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.retry.MessageRecoverer;
import org.springframework.amqp.rabbit.retry.RepublishMessageRecoverer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
@Slf4j
public class RabbitMQErrorConfig {/*** 异常交换机*/private String shortLinkErrorExchange = "short_link.error.exchange";/*** 异常队列*/private String shortLinkErrorQueue = "short_link.error.queue";/*** 异常routing key*/private String shortLinkErrorRoutingKey = "short_link.error.routing.key";@Autowiredprivate RabbitTemplate rabbitTemplate;/*** 建立异常交换机** @return*/@Beanpublic TopicExchange errorTopicExchange() {return new TopicExchange(shortLinkErrorExchange, true, false);}/*** 建立队列** @return*/@Beanpublic Queue errorQueue() {return new Queue(shortLinkErrorQueue, true);}/*** 建立绑定关系** @return*/@Beanpublic Binding bingdingErrorQueueAndExchange() {return BindingBuilder.bind(errorQueue()).to(errorTopicExchange()).with(shortLinkErrorRoutingKey);}/*** 配置RepublishMessageRecoverer* 消息重试一定次数后,用特定的routingKey转发到指定的交换机中,方便后续排查和告警*/@Beanpublic MessageRecoverer messageRecoverer() {return new RepublishMessageRecoverer(rabbitTemplate, shortLinkErrorExchange, shortLinkErrorRoutingKey);}
}注意:消息消费确认使用自动确认方式(acknowledge-mode=auto)
2)Rabbitmq的延迟队列采用死信队列方式解决,即被投递的队列无消费者订阅,所进入该队列的消息超时未消费时,会重新投递到另外的队列,超时时间则就是延迟时间。
@Configuration
@Data
public class RabbitMQConfig {/*** 交换机*/private String orderEventExchange="order.event.exchange";/*** 延迟队列, 不能被监听消费*/private String orderCloseDelayQueue="order.close.delay.queue";/*** 关单队列, 延迟队列的消息过期后转发的队列,被消费者监听*/private String orderCloseQueue="order.close.queue";/*** 进入延迟队列的路由key*/private String orderCloseDelayRoutingKey="order.close.delay.routing.key";/*** 进入死信队列的路由key,消息过期进入死信队列的key*/private String orderCloseRoutingKey="order.close.routing.key";/*** 过期时间 毫秒,临时改为1分钟定时关单*/private Integer ttl=1000*60;/*** 消息转换器* @return*/@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}/*** 创建交换机 Topic类型,也可以用dirct路由* 一般一个微服务一个交换机* @return*/@Beanpublic Exchange orderEventExchange(){return new TopicExchange(orderEventExchange,true,false);}/*** 延迟队列*/@Beanpublic Queue orderCloseDelayQueue(){Map<String,Object> args = new HashMap<>(3);args.put("x-dead-letter-exchange",orderEventExchange);args.put("x-dead-letter-routing-key",orderCloseRoutingKey);args.put("x-message-ttl",ttl);return new Queue(orderCloseDelayQueue,true,false,false,args);}/*** 死信队列,普通队列,用于被监听*/@Beanpublic Queue orderCloseQueue(){return new Queue(orderCloseQueue,true,false,false);}/*** 第一个队列,即延迟队列的绑定关系建立* @return*/@Beanpublic Binding orderCloseDelayBinding(){return new Binding(orderCloseDelayQueue,Binding.DestinationType.QUEUE,orderEventExchange,orderCloseDelayRoutingKey,null);}/*** 死信队列绑定关系建立* @return*/@Beanpublic Binding orderCloseBinding(){return new Binding(orderCloseQueue,Binding.DestinationType.QUEUE,orderEventExchange,orderCloseRoutingKey,null);}}@Component
@Slf4j
@RabbitListener(queuesToDeclare = {@Queue("order.close.queue"),@Queue("order.update.queue")})
public class ProductOrderMQListener {@Autowiredprivate ProductOrderService productOrderService;@RabbitHandlerpublic void productOrderHandler(EventMessage eventMessage, Message message, Channel channel){log.info("监听到消息ProductrOrderMQListener message:{}", eventMessage);try {productOrderService.handleProductOrderMessage(eventMessage);} catch (Exception e) {log.error("消费失败:{}", eventMessage);throw new BizException(BizCodeEnum.MQ_CONSUME_EXCEPTION);}log.info("消费成功");}}
3、问题:海量数据场景下冗余双写唯一码生成方式探讨,以短链码(订单号)讲解。
方案1:
生产者端生成短链码。先在数据库查询短链码是否存在,不存在的话通过redis设计一个分布式锁key=code并配置过期时间(加锁失败则重新生成),存在则重新生成,重复以上操作。随后再C端消费者和B端消费者均写入成功后再进行解锁。

缺点:性能比较低,用户需要等待所生成的短链上锁,最终入库解锁才能返回给用户,等待时间较长。
方案2:
消费者(C端/B端)生成短链码。用户请求后立即返回消息给客户,随后消费者(C端/B端)各自进行加锁写入数据库,确保两者冲突时能遵照统一ver版本自增机制,重新生成短链码。

/*** 如果短链码重复,则调用这个方法* url前缀的编号递增1* 如果还是用雪花算法,则容易C端和B端不一致,所以才用编号递增+1的方式* 123456789&http://baidu.com/download.html** @param url* @return*/public static String addUrlPrefixVersion(String url) {String urlPrefix = url.substring(0, url.indexOf("&"));String originalUrl = url.substring(url.indexOf("&") + 1);Long newUrlPrefix = Long.parseLong(urlPrefix) + 1;String newUrl = newUrlPrefix + "&" + originalUrl;return newUrl;}/*** 判断短链域名是否合法* 判断组名是否合法* 生成长链摘要* 生成短链码* 加锁* 查询短链码是否存在* 构建短链对象* 保存数据库** @param eventMessage* @return*/@Overridepublic boolean handlerAddShortLink(EventMessage eventMessage) {Long accountNo = eventMessage.getAccountNo();String messageType = eventMessage.getEventMessageType();String content = eventMessage.getContent();ShortLinkAddRequest addRequest = JsonUtil.json2Obj(content, ShortLinkAddRequest.class);//短链域名校验DomainDO domainDO = checkDomain(addRequest.getDomainType(), addRequest.getDomainId(), accountNo);LinkGroupDO linkGroupDO = checkLinkGroup(addRequest.getGroupId(), accountNo);//长链摘要生成String originalUrlDigest = CommonUtil.MD5(addRequest.getOriginalUrl());//短链码重复标记boolean duplicateCodeFlag = false;//生成短链码String shortLinkCode = shortLinkComponent.createShortLinkCode(addRequest.getOriginalUrl());String script ="if redis.call('EXISTS',KEYS[1])==0 then " +"redis.call('set',KEYS[1],ARGV[1]); " +"redis.call('expire',KEYS[1],ARGV[2]); " +"return 1;" +" elseif redis.call('get',KEYS[1]) == ARGV[1] then " +"return 2;" +" else return 0; " +"end;";Long result = redisTemplate.execute(newDefaultRedisScript<>(script, Long.class), Arrays.asList(shortLinkCode), accountNo, 100);//加锁成功if (result > 0) {//C端处理if (EventMessageTypeEnum.SHORT_LINK_ADD_LINK.name().equalsIgnoreCase(messageType)) {//先判断短链码是否被占用ShortLinkDO shortLinkDOInDB = shortLinkManager.findByShortLinkCode(shortLinkCode);if (shortLinkDOInDB == null) {//扣减流量包boolean reduceFlag = reduceTraffic(eventMessage,shortLinkCode);//扣减成功才创建流量包if(reduceFlag){//链式调用ShortLinkDO shortLinkDO = ShortLinkDO.builder().accountNo(accountNo).code(shortLinkCode).title(addRequest.getTitle()).originalUrl(addRequest.getOriginalUrl()).domain(domainDO.getValue()).groupId(linkGroupDO.getId()).expired(addRequest.getExpired()).sign(originalUrlDigest).state(ShortLinkStateEnum.ACTIVE.name()).del(0).build();shortLinkManager.addShortLink(shortLinkDO);//校验组是否合法return true;}} else {log.error("C端短链码重复:{}", eventMessage);duplicateCodeFlag = true;}} else if (EventMessageTypeEnum.SHORT_LINK_ADD_MAPPING.name().equalsIgnoreCase(messageType)) {//先判断短链码是否被占用GroupCodeMappingDO groupCodeMappingDOInDB = groupCodeMappingManager.findByCodeAndGroupId(shortLinkCode, linkGroupDO.getId(), accountNo);if (groupCodeMappingDOInDB == null) {//B端处理GroupCodeMappingDO groupCodeMappingDO = GroupCodeMappingDO.builder().accountNo(accountNo).code(shortLinkCode).title(addRequest.getTitle()).originalUrl(addRequest.getOriginalUrl()).domain(domainDO.getValue()).groupId(linkGroupDO.getId()).expired(addRequest.getExpired()).sign(originalUrlDigest).state(ShortLinkStateEnum.ACTIVE.name()).del(0).build();groupCodeMappingManager.add(groupCodeMappingDO);return true;} else {log.error("B端短链码重复:{}", eventMessage);duplicateCodeFlag = true;}}} else {//加锁失败,自旋100毫秒,再调用;失败的可能是短链码已经被占用了,需要重新生成log.error("加锁失败:{}", eventMessage);try {TimeUnit.MILLISECONDS.sleep(100);} catch (InterruptedException e) {}duplicateCodeFlag = true;}if (duplicateCodeFlag) {String newOriginalUrl = CommonUtil.addUrlPrefixVersion(addRequest.getOriginalUrl());addRequest.setOriginalUrl(newOriginalUrl);eventMessage.setContent(JsonUtil.obj2Json(addRequest));log.warn("短链码保存失败,重新生成:{}", eventMessage);handlerAddShortLink(eventMessage);}return false;}4、问题:海量数据高并发场景下冗余双写消费端生成唯一码错乱问题处理,以短链码(订单号)讲解。冲突详细如下:
1)用户A生成短链码AABBCC ,C端先插入,B端还没插入
2)用户B也生成短链码AABBCC ,B端先插入,C端还没插入
3)用户A生成短链码AABBCC ,B端插入 (死锁,相互等待)
4)用户B生成短链码AABBCC ,C端插入(死锁,相互等待)
那么如何让1、3可以成功, 2、4可以成功呢?
方案1:
添加本地锁,synchronize、lock等,再锁内处理事务。JDK指的是以线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的,synchronized 和 ReentrantLock 都是可重入锁
缺点:锁在当前进程内,集群部署下依旧存在问题。
方案2:
添加分布式锁,redis、zookeeper等实现,虽然还是锁,但是多个进程共用的锁标记,可以用Redis、Zookeeper、Mysql。当一个线程获取对象锁之后,其他节点的同个业务线程可以再次获取本对象上的锁。
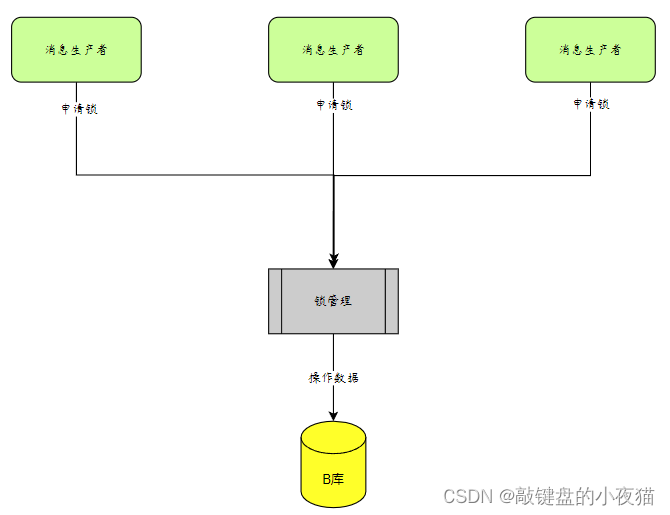
设计分布式锁应该考虑:
1)排他性。在分布式应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行;
2)容错性。分布式锁一定能得到释放,比如客户端奔溃或者网络中断;
3)满足可重入、高性能、高可用;
4)注意分布式锁的开销、锁粒度;
分布式锁设计(redis):
key 是锁的唯一标识,一般按业务来决定命名,比如想要给一种商品的秒杀活动加锁,key 命名为 “seckill_商品ID” 。value就可以使用固定值,比如设置成1。短链码可以:short_link:code:xxxx,基于redis实现分布式锁,文档http://www.redis.cn/commands.html#string
methodA(){String key = "short_link:code:abcdef"if(setnx(key,1) == 1){expire(key,30,TimeUnit.MILLISECONDS)try {//做对应的业务逻辑} finally {del(key)}}else{//睡眠100毫秒,然后自旋调用本方法methodA()}
} 问题:多个命令之间不是原子性操作,如setnx和expire之间,如果setnx成功,但是expire失败,且宕机了,则这个资源就是死锁
核心是保证多个指令原子性,加锁使用setnx setex 可以保证原子性,那解锁使用判断和设置等怎么保证原子性。
多个命令的原子性:采用 lua脚本+redis, 由于【判断和删除】是lua脚本执行,所以要么全成功,要么全失败
使用原子命令:设置和配置过期时间 setnx / setex
如: set key 1 ex 30 nx
java代码里面 String key = "short_link:code:abcdef"
redisTemplate.opsForValue().setIfAbsent(key,1,30,TimeUnit.MILLISECONDS)//key1是短链码,ARGV[1]是accountNo,ARGV[2]是过期时间
String script = "if redis.call('EXISTS',KEYS[1])==0 then redis.call('set',KEYS[1],ARGV[1]); redis.call('expire',KEYS[1],ARGV[2]); return 1;" +" elseif redis.call('get',KEYS[1]) == ARGV[1] then return 2;" +" else return 0; end;";Long result = redisTemplate.execute(newDefaultRedisScript<>(script, Long.class), Arrays.asList(code), value,100);

![每日一题 --- 删除链表的倒数第 N 个结点[力扣][Go]](https://img-blog.csdnimg.cn/img_convert/f8f8838f486669d6071ffdfec2e76c4e.jpeg)