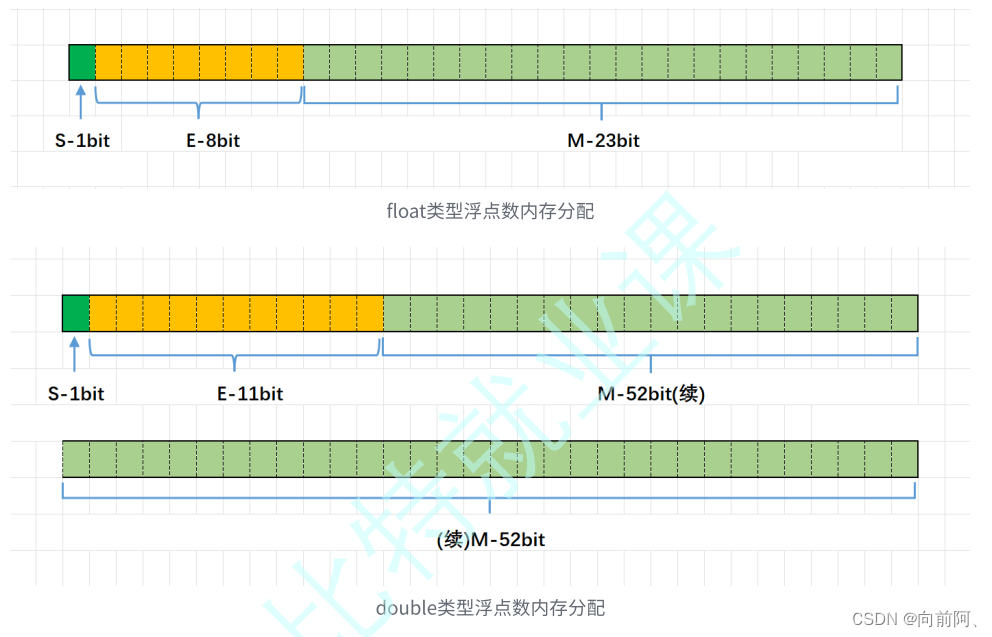
论文(2023年)链接:https://arxiv.org/pdf/2302.00923.pdf
GitHub项目链接:GitHub - amazon-science/mm-cot: Official implementation for "Multimodal Chain-of-Thought Reasoning in Language Models" (stay tuned and more will be updated)
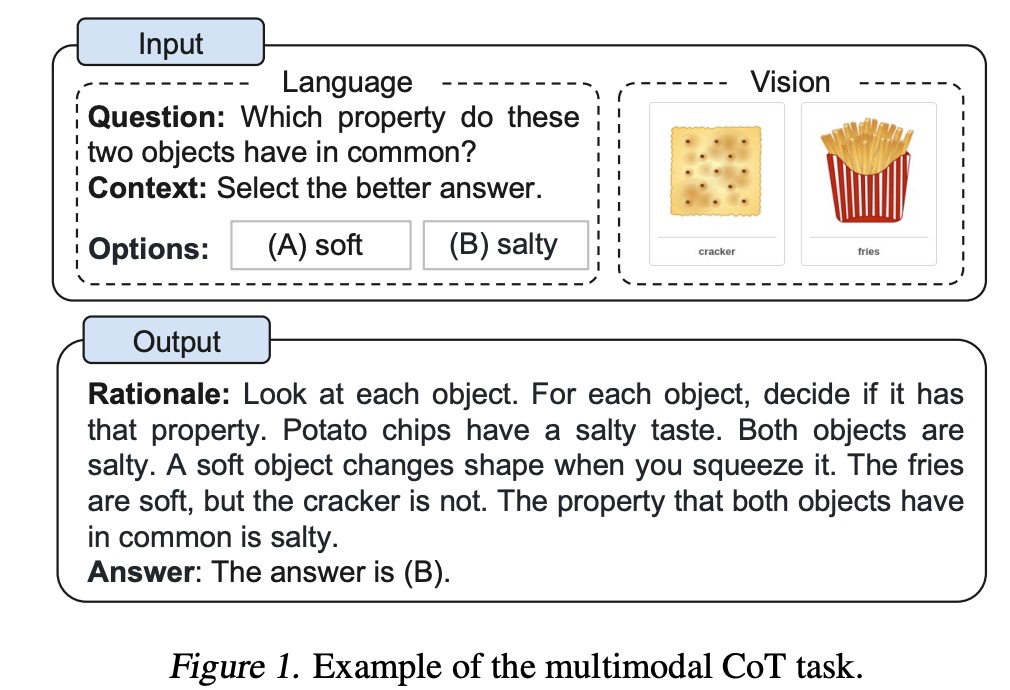
CoT(chain of thought)想必大家都略有耳闻,就是在问大语言模型问题的时候,加入一步一步的思考步骤,以便让大模型有更好的效果,之前大多是文本类型的描述。这篇2023年的文章直接提出了一种Multimodal-CoT:直接结合了文本和图片这两类数据类型来做CoT,实验效果那当然是显著提升。文章在开头给出了multimodal CoT的示例:
在介绍的时候作者提到,为了验证multimodal CoT的效果,目前有两类常用的方法来做multimodal CoT的实验,一种是将不同modality的数据转化成一种modality作为输入,比如把图片中的文字部分抽取出来,一起喂给大语言模型。另一种,是将不同modality的数据进行特征融合然后自己微调语言模型。这篇文章做了模型微调这个任务。实验数据是Science QA。接下来看下这篇文章的框架图:
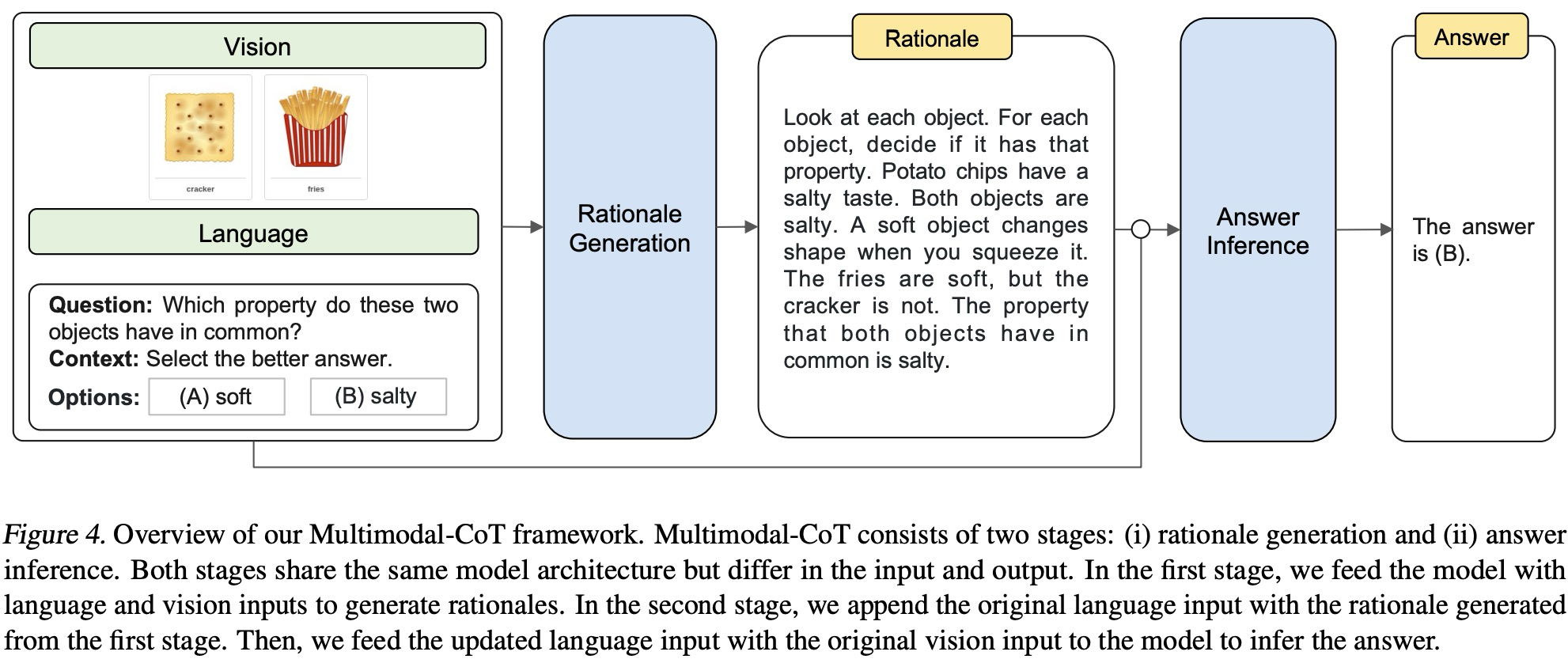
首先,作者将文本和图片输入一起用于生成CoT的内容,这里说是rationale generation(原理生成),目测就是一边将图片生成讲解,一边结合原始的文本输入,一起得到我们的思维链内容(新的文本输入)。然后将我们的思维链内容结合原本的language input一起喂给大模型来得到最终的答案。因此本文将原理生成和答案生成分成了两步,作者写了一个算法流程:

再给一个具体例子的截图:

至于baseline,作者说他们:
To begin with, we fine-tune a text-only baseline for CoT reasoning on the ScienceQA benchmark...Our task is modeled as a text generation problem, where the model takes the textual information as the input and generates the output sequence that consists of the rationale and the answer.
看起来就是根据原始文本输出CoT。
实验过程中,作者发现图片标题其实并不起作用:
As using image captions does not yield significant performance gains in Section 3.3, we did not use the captions.
在抽取图片feature的时候,作者用了三个不同的模型进行了比较,分别是CLIP,DETR和ResNet,发现DETR效果最好哈。另外,还有一个有意思的发现是,作者抽样了一些回答正确的不正确的QA及其对应的CoT,在answer是正确的例子里,有10%的CoT其实是错的。。。咱们的模型有时候还是可以通过忽略不正确的逻辑推理还能预测正确的答案。
好的,读完了这篇文章,知道图片信息可能可以通过一些模型读出来,rationale信息可以自动生成,再用于CoT-based的结果判断。
哦,读了这篇文章还有一个非常有意思的项目是:https://github.com/salesforce/LAVIS/tree/f982acc73288408bceda2d35471a8fcf55aa04ca/projects/instructblip
这个项目大家可以看看,可以生成图片的说明哦!
from lavis.models import load_model_and_preprocess
# loads InstructBLIP model
model, vis_processors, _ = load_model_and_preprocess(name="blip2_vicuna_instruct", model_type="vicuna7b", is_eval=True, device=device)
# prepare the image
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)model.generate({"image": image, "prompt": "Write a short description for the image."})




![[蓝桥杯 2022 省 A] 求和](https://img-blog.csdnimg.cn/direct/6802f778d4d041bc8870c6a901fccbbf.png)