Unity DOTS中的baking(四)blob assets
blob assets表示不可变的二进制数据,在运行时也不会发生更改。由于blob assets是只读的,这意味着可以安全地并行访问它们。此外,blob assets仅限于使用非托管类型,这意味着它们与Burst编译器兼容。而且由于它们是非托管类型,序列化和反序列化的速度要比其他数据格式快得多。blob assets只能包含值类型,除了标准的值类型之外,还支持三种特殊的数据类型:BlobArray, BlobPtr, BlobString。
在baking中创建一个blob asset的过程,可以分为以下若干步骤:
- 创建一个
BlobBuilder,它在Unity内部分配一些内存; - 调用
BlobBuilder.ConstructRoot构造blob asset的根节点; - 把需要的数据填充到上一步骤返回的根节点中;
- 调用
BlobBuilder.CreateBlobAssetReference创建一个BlobAssetReference。这个API会把blob asset复制到最终位置; - 释放第一步创建的
BlobBuilder; - 调用
AddBlobAsset将blob asset注册到baker中,如果不执行这一步,blob asset的引用计数将不会更新,也就是说blob asset可能会被意外释放; - 调用
AddComponent将BlobAssetReference添加到entity上。
在官网了解完这些理论知识之后,我们来动手实践一下。首先定义一个BlobAssetReference引用的struct MyBlobData,它包含一个BlobArray和一个int:
public struct MyBlobData
{public BlobArray<int> blobArray;public int blobInt;
}
然后再定义一个component,它包含一个BlobAssetReference:
public struct MyBlobComponent : IComponentData
{public BlobAssetReference<MyBlobData> blobReference;
}
接下来就是根据上面所说的步骤,创建出BlobAssetReference:
public BlobAssetReference<MyBlobData> CreateBlobData()
{using (var blobBuilder = new BlobBuilder(Allocator.TempJob)){ref var root = ref blobBuilder.ConstructRoot<MyBlobData>();var array = blobBuilder.Allocate(ref root.blobArray, 10);for (int i = 0; i < 10; i++){array[i] = i;}root.blobInt = 42;return blobBuilder.CreateBlobAssetReference<MyBlobData>(Allocator.Persistent);}
}
最后就是把BlobAssetReference注册到baker里去:
public override void Bake(MyBlobAssetAuthoring authoring)
{var entity = GetEntity(TransformUsageFlags.None);var blobReference = CreateBlobData();AddBlobAsset(ref blobReference, out _);AddComponent(entity, new MyBlobComponent { blobReference = blobReference });
}
此时在Unity里,可以看到MyBlobComponent,但是无法看到component里数据的详细信息:
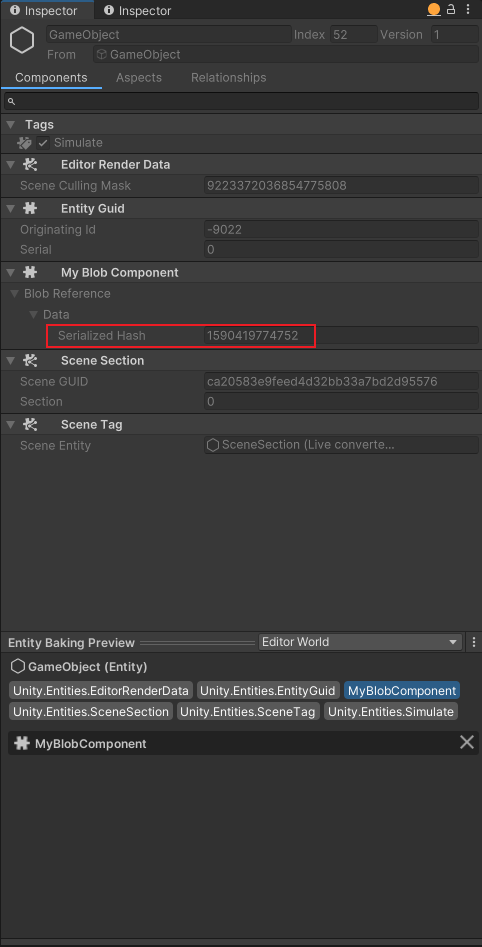
我们可以借助System,在运行时打印这个component的信息:
foreach (var blob in SystemAPI.Query<RefRW<MyBlobComponent>>())
{int x = blob.ValueRO.blobReference.Value.blobArray[4];int y = blob.ValueRO.blobReference.Value.blobInt;Debug.Log(string.Format ("{0}, {1}", x, y));
}
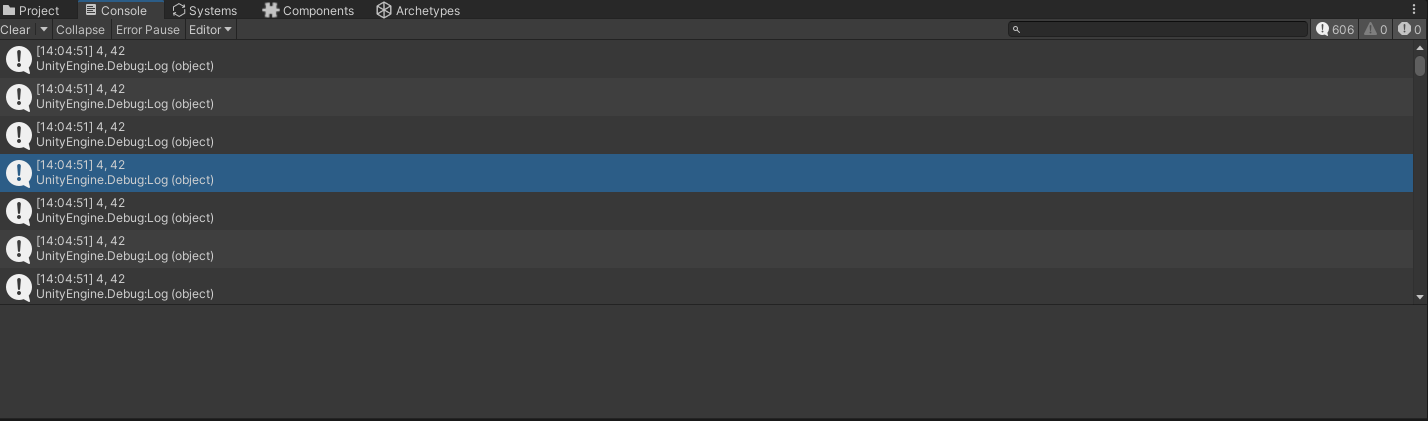
可以看到一切正常。那么,我们现在回过头来,看看Unity官方文档中创建一个blob asset的过程,每一步骤背后究竟做了哪些事情。
第一步,创建BlobBuilder,BlobBuilder的构造函数会初始化内部使用的若干成员变量:
/// <summary>
/// Constructs a BlobBuilder object.
/// </summary>
/// <param name="allocator">The type of allocator to use for the BlobBuilder's internal, temporary data. Use
/// <see cref="Unity.Collections.Allocator.Temp"/> unless the BlobBuilder exists across more than four Unity frames.</param>
/// <param name="chunkSize">(Optional) The minimum amount of memory to allocate while building an asset.
/// The default value should suit most use cases. A smaller chunkSize results in more allocations; a larger
/// chunkSize could increase the BlobBuilder's total memory allocation (which is freed when you dispose of
/// the BlobBuilder.</param>
public BlobBuilder(AllocatorManager.AllocatorHandle allocator, int chunkSize = 65536)
{m_allocator = allocator;m_allocations = new NativeList<BlobAllocation>(16, m_allocator);m_patches = new NativeList<OffsetPtrPatch>(16, m_allocator);m_chunkSize = CollectionHelper.Align(chunkSize, 16);m_currentChunkIndex = -1;
}
注释中提到了两个参数的作用,allocator用于BlobBuilder内部数据的分配,除非BlobBuilder的生命周期很长,否则就应该使用Allocator.Temp,用完就回收;chunkSize用来控制BlobBuilder存放数据的内存块大小,太小的话会导致多次内存分配,太大则会导致内存占用负担,一般用默认值就可以了。
函数体内部初始化了5个成员变量,m_allocations是一个BlobAllocation类型的list,它记录了每个内存块chunk当前的状态,即内存块的起始指针p,和当前已经分配掉的内存大小size。
struct BlobAllocation
{public int size;public byte* p;
}
m_patches则是一个OffsetPtrPatch类型的list,它记录了需要patch的数据结构内存分配的信息。什么是需要patch的数据结构?我们前面提到blob assets除了支持标准值类型之外,还支持BlobArray, BlobPtr, BlobString这三种类型。这三种类型的变量,在初始化时往往还没有真正地分配所需要的内存,后续分配内存时,需要通过一种方式把变量和内存关联起来。OffsetPtrPatch类型记录了变量的起始地址指针offsetPtr,以及与变量关联的内存分配信息target,还有一个length字段记录数组的长度。
struct OffsetPtrPatch
{public int* offsetPtr;public BlobDataRef target;public int length; // if length != 0 this is an array patch and the length should be patched
}
BlobDataRef类型包含此次内存分配所在的chunk index,以及在chunk中的内存偏移量offset:
struct BlobDataRef
{public int allocIndex;public int offset;
}
m_chunkSize就是存放数据的内存块大小,这里会对传入的参数值进行处理,返回一个16字节对齐的大小。对齐函数的实现也蛮有趣的:
/// <summary>
/// Returns an allocation size in bytes that factors in alignment.
/// </summary>
/// <example><code>
/// // 55 aligned to 16 is 64.
/// int size = CollectionHelper.Align(55, 16);
/// </code></example>
/// <param name="size">The size to align.</param>
/// <param name="alignmentPowerOfTwo">A non-zero, positive power of two.</param>
/// <returns>The smallest integer that is greater than or equal to `size` and is a multiple of `alignmentPowerOfTwo`.</returns>
/// <exception cref="ArgumentException">Thrown if `alignmentPowerOfTwo` is not a non-zero, positive power of two.</exception>
public static int Align(int size, int alignmentPowerOfTwo)
{if (alignmentPowerOfTwo == 0)return size;CheckIntPositivePowerOfTwo(alignmentPowerOfTwo);return (size + alignmentPowerOfTwo - 1) & ~(alignmentPowerOfTwo - 1);
}
首先要检查传入的对齐字节数是不是2的幂:
[Conditional("ENABLE_UNITY_COLLECTIONS_CHECKS"), Conditional("UNITY_DOTS_DEBUG")]
internal static void CheckIntPositivePowerOfTwo(int value)
{var valid = (value > 0) && ((value & (value - 1)) == 0);if (!valid){throw new ArgumentException($"Alignment requested: {value} is not a non-zero, positive power of two.");}
}
2的幂的二进制表示为1000…000,减一则为01111…111,按位与之后必为0。
所谓的字节对齐,就是要找到离传入参数值最接近的字节对齐的倍数。那么,我们只需要对原来的size加上alignmentPowerOfTwo - 1,就能保证得到的值一定超过了这个最接近的对齐值。接下来只要把超出的部分去掉就可以了,对alignmentPowerOfTwo - 1取反得到的就是1111…1000…000,后面的这些0就是个mask,按位与这个mask就可以去掉超出的部分了。
最后一个成员变量,m_currentChunkIndex,表示当前已经分配到的chunk index,初始化时还没开始内存分配,默认为-1。
第二步,调用ConstructRoot创建根节点,它会分配出足够容纳传入类型T的空间。
/// <summary>
/// Creates the top-level fields of a single blob asset.
/// </summary>
/// <remarks>
/// This function allocates memory for the top-level fields of a blob asset and returns a reference to it. Use
/// this root reference to initialize field values and to allocate memory for arrays and structs.
/// </remarks>
/// <typeparam name="T">A struct that defines the structure of the blob asset.</typeparam>
/// <returns>A reference to the blob data under construction.</returns>
public ref T ConstructRoot<T>() where T : struct
{var allocation = Allocate(UnsafeUtility.SizeOf<T>(), UnsafeUtility.AlignOf<T>());return ref UnsafeUtility.AsRef<T>(AllocationToPointer(allocation));
}
UnsafeUtility.SizeOf<T>()会返回struct的大小,这里的大小是带有padding的,比如我们这里的struct MyBlobData,返回的大小为12。UnsafeUtility.AlignOf<T>()返回的是struct的对齐字节,对于struct MyBlobData,对齐字节为4,如果MyBlobData中包含一个long成员,对齐字节就是8了。
下层的Allocate函数会根据传入的参数size和alignment进行内存分配。函数返回一个BlobDataRef类型的变量,表示此次分配的结果,即分配到了哪个chunk,以及在chunk中的地址。内存分配的策略其实不算复杂,我们这里不去分析代码,而是使用图示的方式来表达。
首先,初始情况下,m_currentChunkIndex为-1,那么需要直接分配一个chunk,然后将m_currentChunkIndex设置为0,并保存分配的chunk信息。由于是一个空白的chunk,那么就可以从chunk的首地址开始分配。
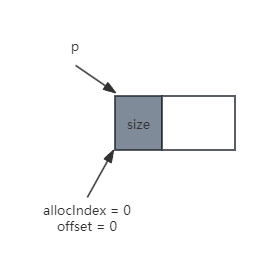
如图所示,p和size表示本次分配之后的chunk信息,p为chunk的首地址,size为已经分配掉的内存大小;allocIndex和offset表示本次分配的结果,allocIndex表示分配的内存在第0号chunk上,offset表示分配的内存首地址相对于chunk的首地址偏移量,这里为0。
有了chunk之后,后续的内存分配都在这个chunk上进行。为了保证存取数据的效率,后续分配的首地址都在对应struct的对齐字节整数倍上进行。
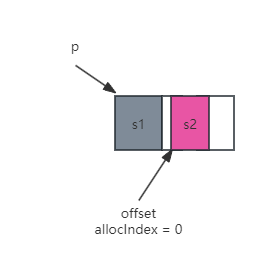
如图所示,第二次分配后,chunk的size信息需要更新为两次分配的内存大小,以及第二次分配用于字节对齐的大小总和。此次分配的结果,offset不再为0,而是chunk空闲的首地址再加上用于字节对齐的偏移量。
举个通俗的例子,假如第一次分配了12字节的struct内存,而第二次要分配的struct,总共64字节,但它是8字节对齐的,那么这里就不会紧挨着从12字节的位置继续分配,而是计算8字节对齐的整数倍,也就是16字节处,开始分配这个struct。这样两个struct之间其实是有4个字节的间隙,用于第二个struct字节对齐的。
当chunk剩余的内存空间不足时,就会再去申请一个新的chunk,同时会把上一个chunk中已经分配的空间调整到16字节对齐,这是因为chunk都是按照16字节对齐的地址进行分配的。
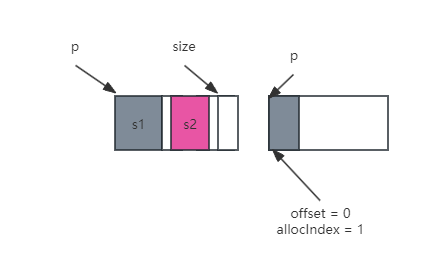
那如果需要分配的内存,超过一个chunk的大小,要怎么办呢?Unity会先计算一个16字节对齐后的大小,然后直接分配一个这样大的chunk。也就是说,Unity内部维护的chunk list,每个chunk的大小其实未必相同。
根据Allocate函数返回的分配结果,要如何转换成对应T类型的对象呢?我们前面提到,分配的结果,包含了分配的chunk索引,以及在chunk中的地址偏移量。那么只需要拿到chunk的首地址,加上偏移量就能得到实际分配T类型对象的指针了:
void* AllocationToPointer(BlobDataRef blobDataRef)
{return m_allocations[blobDataRef.allocIndex].p + blobDataRef.offset;
}
再把指针强转成对象即可。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public unsafe static ref T AsRef<T>(void* ptr) where T : struct
{return ref *(T*)ptr;
}
第三步,我们的Component中还包含了BlobArray,那么也需要为它分配内存,这里调用的是BlobBuilder.Allocate函数,它接受一个BlobArray对象的引用,以及要创建的数组大小这两个参数,返回一个BlobBuilderArray类对象,这个对象封装了数组访问的行为。
/// <summary>
/// Allocates enough memory to store <paramref name="length"/> elements of struct <typeparamref name="T"/>.
/// </summary>
/// <param name="ptr">A reference to a BlobArray field in a blob asset.</param>
/// <param name="length">The number of elements to allocate.</param>
/// <typeparam name="T">The struct data type.</typeparam>
/// <returns>A reference to the newly allocated array as a mutable BlobBuilderArray instance.</returns>
public BlobBuilderArray<T> Allocate<T>(ref BlobArray<T> ptr, int length) where T : struct
{return Allocate(ref ptr, length, UnsafeUtility.AlignOf<T>());
}
数组对象的内存分配逻辑与我们之前说的根节点内存分配逻辑大体相似,只不过这里需要额外考虑一点,如何把新分配的数组内存,与对象本身关联起来。分配数组内存的时机,往往是在对象初始化之后。Unity这里会把对象的地址,此次内存分配的结果,以及分配数组的长度,记录在OffsetPtrPatch类型的变量中。
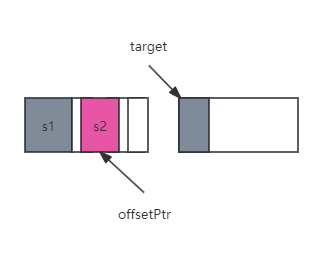
返回的BlobBuilderArray类型是一个相当简单的数据结构,仅仅包含一个数据指针以及数组长度:
/// <summary>
/// Used by the <see cref="BlobBuilder"/> methods to reference the arrays within a blob asset.
/// </summary>
/// <remarks>Use this reference to initialize the data of a newly created <see cref="BlobArray{T}"/>.</remarks>
/// <typeparam name="T">The data type of the elements in the array.</typeparam>
public unsafe ref struct BlobBuilderArray<T> where T : struct
{private void* m_data;private int m_length;
}
这个struct重载了下标操作符,方便读写数据:
/// <summary>
/// Array index accessor for the elements in the array.
/// </summary>
/// <param name="index">The sequential index of an array item.</param>
/// <exception cref="IndexOutOfRangeException">Thrown when index is less than zero or greater than the length of the array (minus one).</exception>
public ref T this[int index]
{get{CheckIndexOutOfRange(index);return ref UnsafeUtility.ArrayElementAsRef<T>(m_data, index);}
}
ArrayElementAsRef就是个指针的计算操作:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public unsafe static ref T ArrayElementAsRef<T>(void* ptr, int index) where T : struct
{return ref *(T*)((byte*)ptr + (long)index * (long)sizeof(T));
}
到目前为止,数组的内存和对象还没有正确关联起来。这个实际上是在第4步,创建BlobAssetReference对象时完成的。CreateBlobAssetReference会把上面几步分配的内存拷贝到最终的位置上。
在拷贝之前,Unity做了若干准备工作,首先是定义了一个offsets数组,每个offset等于前一个offset加上当前chunk已经分配的内存大小,最后一个offset的值就是所有chunk分配的内存大小之和;然后还定义了sortedAllocs和sortedPatches两个数组,它们分别保存的是每个chunk的首地址和每个待关联对象的首地址,并且根据地址的高低进行了排序。

然后,Unity会分配一个长度为要拷贝的数据大小再加上BlobAssetHeader这一数据结构大小的buffer。offsets其实就是每个要拷贝的数据位于buffer的地址偏移。之后,Unity将每个chunk挨个拷贝到buffer中去,由于chunk之前已经做过16字节对齐了,这里就不需要再做其他工作了。
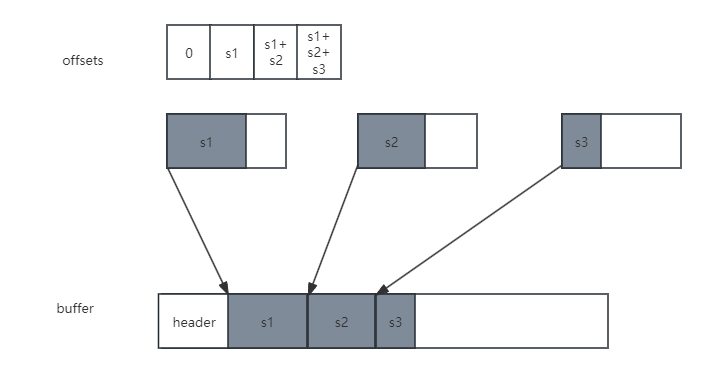
下一步,Unity开始把BlobArray,BlobPtr, BlobString这几种类型的变量和内存进行关联。首先要找到变量和内存分别在buffer中所对应的地址,两个地址相减得到真正的offset。
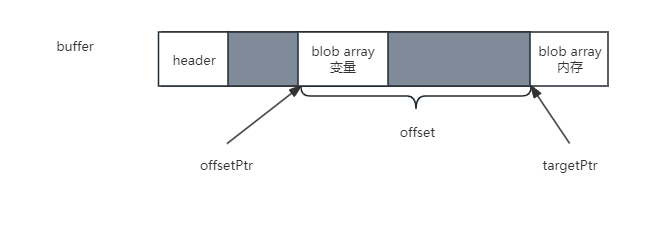
最关键的一步来了,回填,我们先看下BlobArray,BlobPtr, BlobString这几种类型的数据结构:
public unsafe struct BlobString
{internal BlobArray<byte> Data;
}public unsafe struct BlobPtr<T> where T : struct
{internal int m_OffsetPtr;
}public unsafe struct BlobArray<T> where T : struct
{internal int m_OffsetPtr;internal int m_Length;
}
它们有个共同特点,就是前4个字节,都是存放了一个int类型的offset ptr。这个值表示变量指向的内存地址距离变量自身的地址偏移量。直到此时此刻才会被填充。如果被指向的内存还包含长度信息,说明变量是BlobArray类型的,那么还需要回填一下数组的长度。
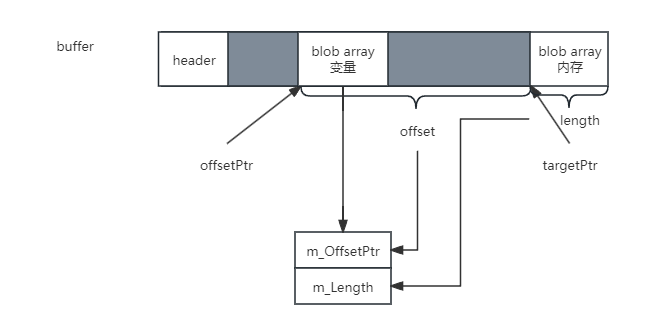
最后一步,Unity会填充header的信息,BlobAssetHeader是一个占用32字节的struct,它强制定义了内存的布局:
unsafe struct BlobAssetHeader
{[FieldOffset(0)] public void* ValidationPtr;[FieldOffset(8)] public int Length;[FieldOffset(12)] public AllocatorManager.AllocatorHandle Allocator;[FieldOffset(16)] public ulong Hash;[FieldOffset(24)] private ulong Padding;
}
其中,ValidationPtr表示存放数据的首地址。函数最后返回的是BlobAssetReference类型的对象,该对象也包含一个指针,指向存放数据的首地址。
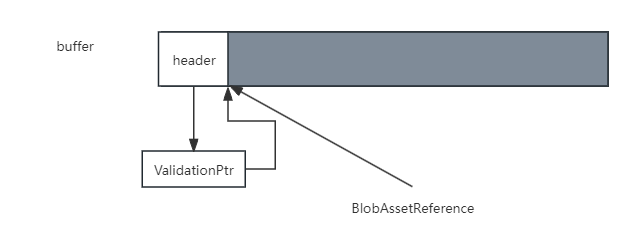
最后,我们来提一下AddBlobAsset这个函数。本文开头提到,这个函数是用来将blob asset注册到baker中的,如果不注册blob asset可能会被错误释放。这里Unity实现的技巧比较trick,和所谓的引用计数毫无关系:
internal void ProtectAgainstDisposal()
{ValidateNotNull();if (IsProtected){throw new InvalidOperationException("Cannot protect this BlobAssetReference, it is already protected.");}
#if UNITY_64Header->ValidationPtr = (void*)~(long)m_Ptr;
#elseHeader->ValidationPtr = (void*)~(int)m_Ptr;
#endif
}
Unity会把blob asset header的ValidationPtr进行修改,让它不再指向原来存放数据的位置。然后Unity就可以通过比较ValidationPtr和数据的首地址,判断当前blob asset是否被引用住:
bool IsProtected
{get{
#if UNITY_64return Header->ValidationPtr == (void*)~(long)m_Ptr;
#elsereturn Header->ValidationPtr == (void*)~(int)m_Ptr;
#endif}
}
如果被引用住了,Dispose时则不会释放该blob asset。
public void Dispose()
{ValidateNotNull();ValidateNotProtected();ValidateNotDeserialized();Memory.Unmanaged.Free(Header, Header->Allocator);m_Ptr = null;
}
Reference
[1] Blob assets
[2] Create a blob asset


![每日一题 --- 删除链表的倒数第 N 个结点[力扣][Go]](https://img-blog.csdnimg.cn/img_convert/f8f8838f486669d6071ffdfec2e76c4e.jpeg)