作者:悬衡
一、前言
在 Java 中有一个非常经典的死锁问题, 就是明明自己已经占用了线程池, 却还继续去申请它, 自己等自己, 就死锁了, 如下图和代码:

// 这段代码将死锁到天荒地老final ExecutorService executorService = Executors.newSingleThreadExecutor();executorService.submit(() -> {Future<?> subTask = executorService.submit(() -> System.out.println("Hello dead lock"));try {subTask.get();} catch (ExecutionException | InterruptedException ignore) { }});
相比别的死锁问题, 这一类问题的坑点在于, 因为线程池的实现问题, jstack 等 jvm 工具无法对其自动诊断, 只能肉眼看出。
在 Kotlin 协程中, 因为底层的线程池申请更加黑盒, 如果不是足够了解, 很容易踩到这类坑。
本文不会再去重复 Kotlin 协程的基本语法, 而是专注于死锁的话题。
下面两段代码你觉得是否有死锁风险?:
-
第一段代码看起来很恶心, 但是它反而是没有死锁风险的
runBlocking(Dispatchers.IO) {runBlocking {launch (Dispatchers.IO) {println("hello coroutine")}}}
-
第二段代码看着 "挺简洁的", 其实是有死锁风险的
runBlocking(Dispatchers.IO) {runBlocking {launch (Dispatchers.IO) {println("hello coroutine")}}}
只要同一时间有 64 个请求同时进入这个代码块, 就永远不要想出来了, 而且因为协程的线程池都是复用的, 其他协程也别想执行了, 比如下面这段代码就能锁死整个应用:
// 用传统 Java 线程池来模拟 64 个请求val threadPool = Executors.newFixedThreadPool(64)repeat(64) {threadPool.submit {runBlocking(Dispatchers.IO) {println("hello runBlocking $it")// 在协程环境中本不应该调用 sleep, 这里为了模拟耗时计算和调用,不得已使用// 正常协程休眠应该用 delayThread.sleep(5000)runBlocking {launch (Dispatchers.IO) {// 因为死锁, 下面这行永远都打印不出来println("hello launch $it")}}}}}Thread.sleep(5000)runBlocking(Dispatchers.IO) {// 别的协程也执行不了, 下面这行也永远打印不出来println("hello runBlocking2")}
随便翻翻代码仓库, 就能看到大量存在类似风险的代码, 之前还差点因此发生事故。
本文将会剖析 Kotlin 协程死锁的根本原因, 以及如何彻底地从坑中爬出来。
笔者主要是做服务端的, 文中内容可能更贴近服务端开发场景, 如果移动端场景有所不同, 也欢迎在评论区讨论。
二、runBlocking 线程调度常识
2.1 主线程的独角戏
runBlocking 从表面上理解就是开启一个协程, 并且等待它结束。
Java 的线程思维总让人觉得 runBlocking 会用一个新线程异步执行其中的代码块, 实际上不是这样。runBlocking 在不加参数时, 默认使用当前线程执行:
fun main() {println("External Thread name: ${Thread.currentThread().name}")runBlocking {println("Inner Thread name: ${Thread.currentThread().name}")}}
输出如下:
External Thread name: mainInner Thread name: main
如果我在里面不带参数使用 launch/async 等等, 也都是在当前的主线程中执行:
runBlocking {val result = async {println("async Thread name: ${Thread.currentThread().name}")1 + 1}// 在另一个协程中完成 1+1 的计算val intRes = result.await()println("result:$intRes, thread: ${Thread.currentThread().name}")}
打印结果:
async Thread name: mainresult:2, thread: main
从线程的思维看, 容易误认为以上代码会死锁。其实不会, 因为 await 并不会阻塞线程, 而是直接用主线程继续运行了 async 中的代码块。整个调度过程如下:
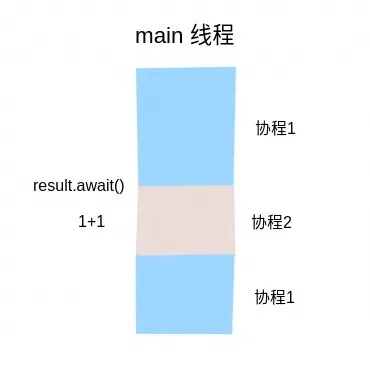
所以对于不带参的 runBlocking/launch/async 来说, 无论你怎么折腾都是不会死锁的。比如一开头的例子看起来很复杂, 却不会死锁:
// 一直都在当前线程中, 根本就没有线程切换,当然不会死锁runBlocking {runBlocking {runBlocking {runBlocking {runBlocking {println("Hello Coroutine")}}}}}
打印输出:
Hello Coroutine虽然不会死锁, 但是这个时候其实就是个单线程, 对于 IO 密集型任务无法起到并行加速的效果。
2.2 IO 与 Default 的暧昧关系
如果想要真正地异步执行, 可以给 runBlocking 加个参数, 常用的有 Dispatchers.Default 和 Dispatchers.IO:
println("current thread:${Thread.currentThread().name}")runBlocking(Dispatchers.Default) {println("Default thread:${Thread.currentThread().name}")}runBlocking(Dispatchers.IO) {println("IO thread:${Thread.currentThread().name}")}
打印输出:
current thread:mainDefault thread:DefaultDispatcher-worker-1IO thread:DefaultDispatcher-worker-1
runBlocking 终于不是运行在 main 线程里了, 而是到了 kotlin 内置的一个 DefaultDispatcher 线程池。比较奇怪的是, 明明用了 Default 和 IO 两个不同的 Dispatcher, 最终却执行在同一个线程? 这就涉及它们的 "暧昧" 关系了。
Default 和 IO 底层其实都是从一个线程池分配线程的, 他们分别从中切出一部分供自己使用: 其中 64 个线程是给 IO 使用的, 另外和 CPU 核数相同数量的线程是给 Default 使用的。所以 DefaultDispatcher 线程池最多会有 64+CPU 核数 个线程, 我的个人电脑是 12 核, 所以在我电脑上最多会有 64+12=76 个线程。

其设计思想在于, Default 是用于 CPU 密集型任务的, 这种任务的并发度和 CPU 核数相同是最合适的, 太多就会导致上下文切换开销了。而 IO 顾名思义是用于 IO 密集型任务的, 对于这种任务并发可以给高一点, 默认就给了 64。
既然 DefaultDispatcher 线程池是被分成两部分单独使用的, 那为什么非要放在一个线程池里呢? 是因为 Kotlin 允许在当前线程中切换 IO 和 Default 类型, 这样可以降低 IO 和 Default 切换时的开销。使用 withContext 方法就可以实现在不切换线程的情况下, 对任务进行 Default 到 IO 的切换:
runBlocking(Dispatchers.Default) {println("default thread name ${Thread.currentThread().name}")withContext(Dispatchers.IO) {println("io thread name ${Thread.currentThread().name}")}}
输出如下:
default thread name DefaultDispatcher-worker-1io thread name DefaultDispatcher-worker-1
所以之前的图是不够严谨的, 并不是说 DefaultDispatcher 有一部分专门为 Default 服务, 另一部分专门为 IO 服务。线程还是像超市里的收银员一样, 无论贫贱富贵, 都逐一为人们服务。只是做了一个 "计数" 上的限制, 比如同时运行的 IO 协程不能超过 64 个, 同时运行的 Default 协程不能超过 CPU 核数。对于同一个线程来说, 它则是有可能刚刚还在运行 Default 协程, 下一秒就变成了 IO 协程了:

复用同一个线程池会不会导致 Default 和 IO 任务之间的隔离性变差呢? 这点不用担心, Kotlin 的隔离做得还是挺好, 从上层等价理解成有两个专门的线程池分别服务 Default 和 IO。
比如当 IO 的 64 个线程耗尽时, Default 线程即使用 withContext 也切换不过去:
val threadPool = Executors.newFixedThreadPool(64)// 阻塞 64 个 IO 线程repeat(64) {threadPool.submit {runBlocking(Dispatchers.IO) {// 协程中应该用 delay, 而不是 sleep, 这里出于演示目的采取错误做法Thread.sleep(Long.MAX_VALUE)}}}runBlocking(Dispatchers.Default) {println("in default thread ${Thread.currentThread().name}")withContext(Dispatchers.IO) {// 永远也打印不不出来, 因为申请不到 IO 的资源println("in io thread ${Thread.currentThread().name}")}}
打印输出:
in default thread DefaultDispatcher-worker-1复制代码
2.3 线程阻塞与协程阻塞的区别
在 Kotlin 中,还有一个和 runBlocking 类似的 api, 叫做 coroutineScope, 也是启动一个协程运行代码块, 并且等待它结束, 区别在于:
-
coroutineScope 是 suspend 函数, 只能用在协程的上下文中(比如 runBlocking 的代码块, 或者其他 suspend 函数中);
-
runBlocking 是线程维度的阻塞, 而 coroutineScope 是协程维度的阻塞;
比如开头的有死锁风险的代码:
runBlocking(Dispatchers.IO) {runBlocking {launch (Dispatchers.IO) {println("hello coroutine")}}}
换成 coroutineScope 就解决了:
runBlocking(Dispatchers.IO) {coroutineScope {launch (Dispatchers.IO) {println("hello coroutine")}}}
可以做个实验发现确实不会死锁:
// 用传统 Java 线程池来模拟 64 个请求val threadPool = Executors.newFixedThreadPool(64)repeat(64) {threadPool.submit {runBlocking(Dispatchers.IO) {println("hello runBlocking $it")Thread.sleep(5000)coroutineScope {launch (Dispatchers.IO) {// 5s 后顺利打印出来println("hello launch $it")}}}}}runBlocking(Dispatchers.IO) {// 顺利打印出来println("hello runBlocking2")}
为什么能够解决这个问题呢? 因为 runBlocking 会将线程阻塞住, 换句话说就是 "即便我什么事情都不干也要占个线程";而 coroutineScope 只会阻塞协程, 也就是说 "线程可以忙活其他协程的任务"。
上文中提到的 withContext, 功能和 coroutineScope 也是类似的, 只是可以进一步支持切换协程上下文。
Thread.sleep 和 delay 的区别也是类似
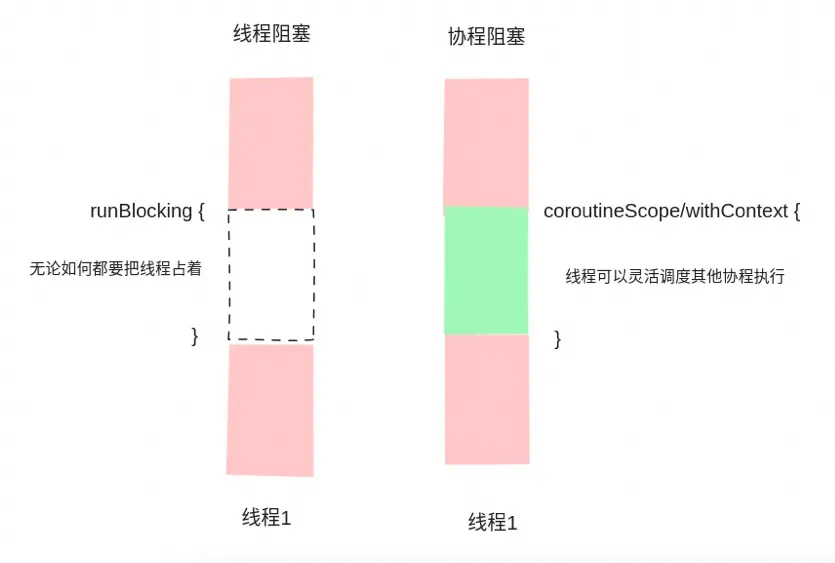
所以 runBlocking 是个很奇怪的东西, 如果彻底拥抱协程, 理论上不需要感知任何线程维度的东西。比如在 Go 语言这种内置协程的语言中,就没听说过什么线程维度的概念。但是 JVM 生态毕竟历史包袱太重, 大量的老代码都是基于线程写的, 所以 Kotlin 就提供了这个方法, 在文档中也说 "设计上仅仅用于桥接传统线程代码与协程上下文"(参考[1])。
三、规避死锁的方案
方案一: 规避在协程上下文中使用 runBlocking(很难)
我觉得 Kotlin 官方也是这么想的, 靠程序员自觉规避。如果想要阻塞等待一个代码块的执行, 在不同的场景中选择合适的方法:

理论上说说很容易, 实际上很难。
现实中的函数都是一层层嵌套复用的, 谁知道隔了多少层, 里面有一个 runBlocking 的调用, 一不小心就踩雷。
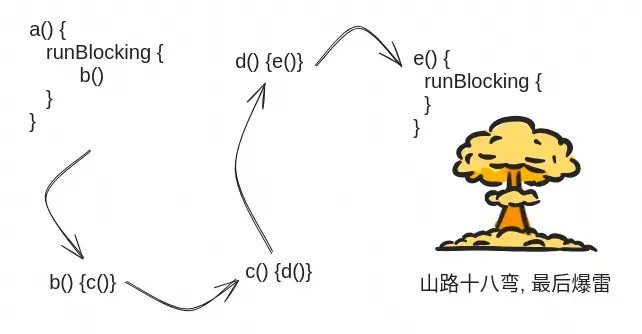
我和 另一篇文章 的作者都有过亲身经历。
方案二:禁止使用 runBlocking, 彻底拥抱协程(过于理想)
在 How I Fell in Kotlin’s RunBlocking Deadlock Trap, and How You Can Avoid It [2]这篇文章中, 作者就建议在项目中彻底禁止使用 runBlocking, 这也意味着项目要彻底拥抱协程, 从入口处就是 suspend 方法。这就需要框架的良好支持。
在 Spring WebFlux 中就支持直接将 Controller 中的方法定义为 suspend(参考文档[3]):
@RestControllerclass UserController(private val userRepository: UserRepository) {@GetMapping("/{id}")suspend fun findOne(@PathVariable id: String): User? {//....}}
但是阿里的大多数应用提供的都是 HSF 接口, 而不是 http。HSF 目前还不支持定义 suspend 的 Provider 方法, 但是支持异步调用, 可以自己在基础上做封装。
不过我还是觉得这种方式过于理想了, 首先自己动手去封装还是有一定风险, 如果在框架升级过程中出现什么问题还得自己背锅;其次框架这么多, 每遇到一个都改造一下, 还是有点恶心的。
方案三:当成一个线程池的语法糖用(大多数场景推荐)
虽然协程最大的优势是非阻塞 IO, 但是大多数应用并没有这么高的性能需求, 大家也就是图个语法简洁, 写得爽一点。
那么我们就只需要按照和平时线程写法等价的方式写就可以了。假设我们有一个方法, 要异步调用某个接口十次, 并且等待它们结束再返回, 我们用传统的线程要怎么写呢?如下:
public class ThreadExample {private final static Executor EXECUTOR = Executors.newFixedThreadPool(64);public void example(String[] args) throws InterruptedException {CountDownLatch cd = new CountDownLatch(10);for (int i = 0; i < 10; i++) {EXECUTOR.execute(() -> {invokeRpc();cd.countDown();});}// 等待 10 个并行任务结束再返回cd.await();}}
传统的线程使用方式的特点是:
-
每个任务独立线程池, 不复用, 所以底层方法也不可能再去申请这个线程池, 不会死锁;
-
当前线程阻塞, 等待另外十个线程结束;
用协程也能做到上面两点
-
使用 asCoroutineDispatcher 可以将线程池转换成一个当前任务专用 Dispatcher 供 launch 使用;
-
runBlocking 不带参数默认就是在当前线程中执行, 起到类似 CountDownLatch 的效果。
class CoroutineExample {companion object {val THREAD_POOL = Executors.newFixedThreadPool(64).asCoroutineDispatcher()}fun example() {runBlocking {repeat(10) {launch(THREAD_POOL) {invokeRpc()}}}}}
这样无论是在上游,还会下游有嵌套的 runBlocking, 都不会死锁了。因为我们只是把它当成了一个线程的语法糖来用。
最后来实战修复一个死锁问题:
fun main() {// 用传统 Java 线程池来模拟 64 个请求val threadPool = Executors.newFixedThreadPool(64)repeat(64) {threadPool.submit {runBlocking {// 这里还在主线程中println("hello runBlocking $it")launch(Dispatchers.IO) {// 因为 Dispatchers.IO, 这里已经进入了 DefaultDispatcher 线程池// 如果下游嵌套 runBlocking, 则会有死锁风险Thread.sleep(5000)// 将嵌套的 runBlocking 藏在子方法中, 更加隐秘subTask(it)}}}}Thread.sleep(5000)runBlocking(Dispatchers.IO) {// 别的协程也执行不了, 下面这行也永远打印不出来println("hello runBlocking2")}}fun subTask(i: Int) {runBlocking {launch (Dispatchers.IO) {// 因为死锁, 下面这行永远都打印不出来println("hello launch $i")}}}
按照我们的原则修改下就能解决问题:
val TASK_THREAD_POOL = Executors.newFixedThreadPool(20).asCoroutineDispatcher()fun main() {// 用传统 Java 线程池来模拟 64 个请求val threadPool = Executors.newFixedThreadPool(64)repeat(64) {threadPool.submit {runBlocking {println("hello runBlocking $it")launch(TASK_THREAD_POOL) {Thread.sleep(5000)subTask2(it)}}}}Thread.sleep(5000)runBlocking(TASK_THREAD_POOL) {// 顺利打印println("hello runBlocking2")}}val SUB_TASK_THREAD_POOL = Executors.newFixedThreadPool(20).asCoroutineDispatcher()fun subTask2(i: Int) {runBlocking {launch (SUB_TASK_THREAD_POOL) {// 顺利打印println("hello launch $i")}}}
虽然我们用的线程还没有 DefaultDispatcher 留给 IO 的 64 个这么多, 但是上面的代码却不会死锁。
参考链接
[01] 秒杀方案
https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html
[02] 优化方案
https://betterprogramming.pub/how-i-fell-in-kotlins-runblocking-deadlock-trap-and-how-you-can-avoid-it-db9e7c4909f1
[03] 跨机房单元化部署
https://spring.io/blog/2019/04/12/going-reactive-with-spring-coroutines-and-kotlin-flow