文章目录
- 文件操作
- 回顾(C/C++)
- 系统调用接口
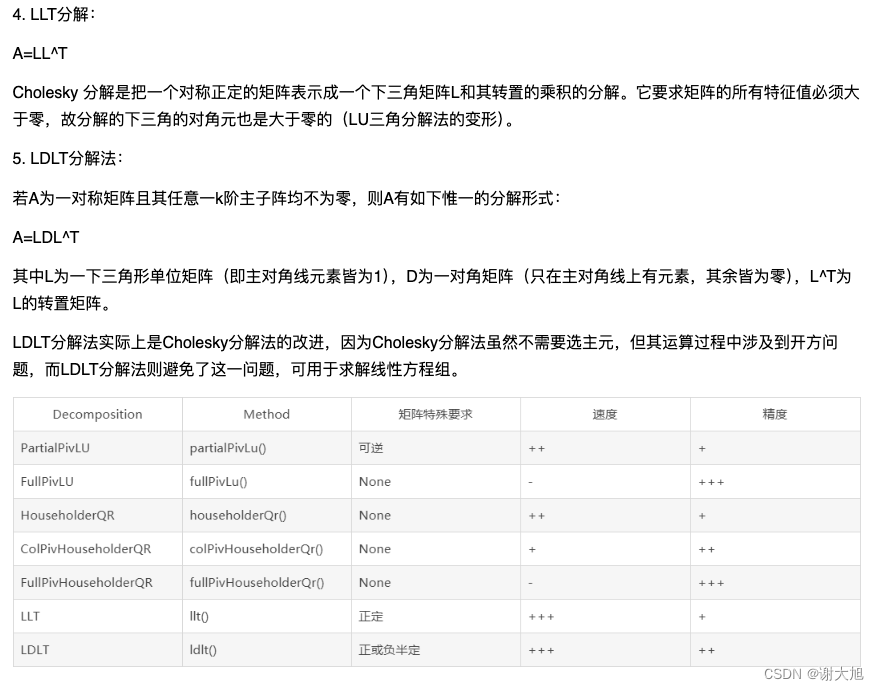
- 管理文件
- 认识一切皆文件
- C/C++的文件操作函数与系统调用接口的关系
- ……
- 重定向与缓冲区 -- 认识
- 重定向与缓冲区 -- 理解使用
- 重定向
- 缓冲区
- 实现一个简单的Shell(加上重定向)
- 标准输出和标准错误(在重定向下的意义)
- 磁盘文件
- 磁盘存储文件
- 操作系统对磁盘存储进行逻辑抽象
- inode 编号
- 软硬链接(不是软件和硬件链接的意思(大雾))
- 软硬链接是什么样子
- 软硬链接的特征
- 用处
- 动静态库
- 静态库
- 动态库
- 使用外部库
- 动态库加载 -- 可执行程序和地址空间
文件操作
回顾(C/C++)
C语言
#include<stdio.h>
int main() {FILE*pf = fopen("test.txt", "w");if (pf == NULL) {perror("fopen");return 1;}char* str = "abcdefghijklmn";int d = 1234567890;fprintf(pf, "%s\n%d", str, d);//int fprintf( FILE *stream, const char *format, ... );fclose(pf);return 0;
}
C++
虽然没学,但接触了这么久的C++,想必以下的对象和语句各位都能看懂
using namespace std;
#include<string.h>
#include<fstream>
int main() {ofstream out("test.txt");if (!out.is_open()) return 1;string str = "abcdefghijklmn\n";out.write(str.c_str(), str.size());out.close();return 0;
}
但这些不是我们此次学习的重点,我们要学的是从系统层面认识文件:
系统调用接口
打开关闭文件
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
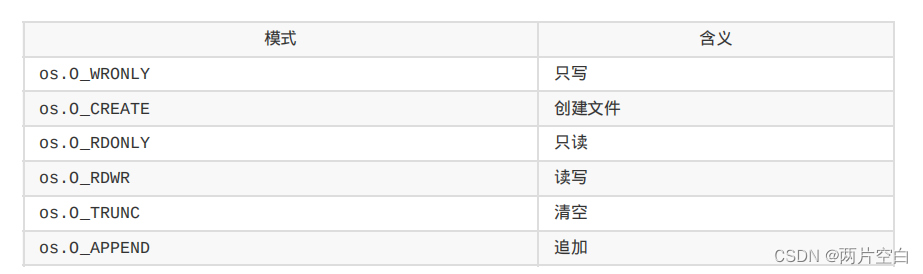
int main(){ int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);//打开名为 log.txt 的文件,只写,若不存在则创建,权限设为666 if(fd < 0){ perror("open"); return 1; } close(fd); return 0; return 0;
}
问题一:O_WRONLY | O_CREAT 为什么可以表示 “只写,若不存在则创建” 的含义?
显然这两个符号全大写,在我们的认知中这是宏的特征,这些符号的某一个bit位为1标定相应的信息,以此通过二进制去传递信号
问题二:创建出的文件的权限不是我们想要的:

原因很简单:权限掩码修正了初始的权限
我们可以通过使用系统调用 umask 动态地设置进程的权限掩码
//创建文件前加一行
umask(0);
写入
我们使用 write 进行写入:
const char* str = "123456789\n111111111111\naaaaaaaaaaaaaaa";
write(fd,str,strlen(str));
结果:
但我们发现此处的写入和C语言写入不同的是,若修改写入内容再次执行代码,会发现并非是清空文件后再写入,而是覆盖写入
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); //通过增添O_TRUNC表示存在文件则清空文件内容 -- TRUNC:截断

O_APPEND:追加写入
open函数的返回值
返回文件描述符
int main(){ int fd1 = open("log1.txt", O_WRONLY | O_CREAT, 0666); printf("fd1:%d\n",fd1); int fd2 = open("log2.txt", O_WRONLY | O_CREAT, 0666); printf("fd2:%d\n",fd2); int fd3 = open("log3.txt", O_WRONLY | O_CREAT, 0666); printf("fd3:%d\n",fd3); int fd4 = open("log4.txt", O_WRONLY | O_CREAT, 0666); printf("fd4:%d\n",fd4);return 0;
}
输出结果:
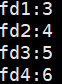
0:标准输入–键盘 1:标准输出–显示器 2:标准错误–显示器
这是C语言运行时默认打开的三个输出流:stdin、stdout、stderror
管理文件
先描述再组织
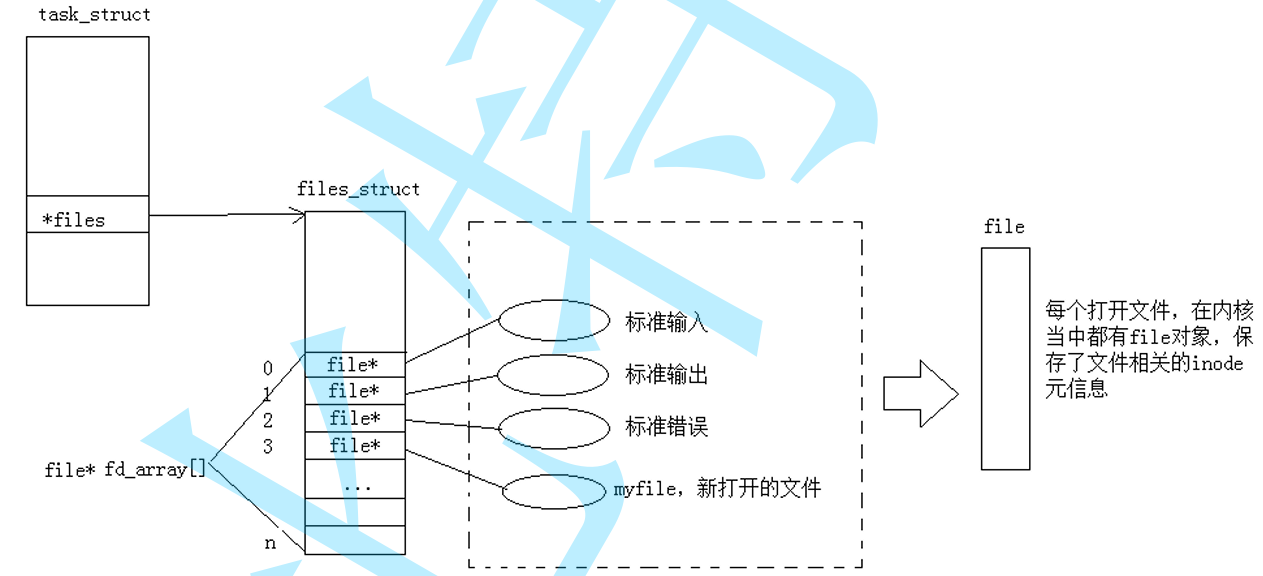
类比管理进程,磁盘内有许多的文件,对于那些被打开的文件,操作系统会用 一种内核数据结构(struct file) 去描述这些文件的属性……并将它们用双链表的方式链接起来
内核数据结构中有一个指针,指向文件内核级的缓存
文件 = 属性+内容
文件的属性存入内核数据结构,文件的内容存入文件内核级的缓存中
不同的进程如何标定自己打开的文件?
进程PCB中有一个属性:struct files_struct* files
而struct files_struct 结构体内部有一个名为 struct file* fd_ array[N] 的指针数组,里面存储着 struct file 的指针,以此建立进程和文件的联系
而struct file* fd_ array[N] 这个指针数组的下标即为 open 函数的返回值–文件描述符的本质即为文件映射关系的数组的下标

认识一切皆文件

C/C++的文件操作函数与系统调用接口的关系
文件操作系统调用接口示例:
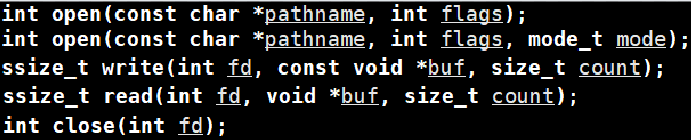
可见,系统对文件的操作只认文件描述符fd
那么以C语言的 FILE * fopen ( const char * filename, const char * mode ); 函数为例,怎么理解通过FILE访问文件?(C语言的标准输入、输出、错误:FILE *stdin; FILE *stdout; FILE *stderr; 可见它们也是FILE)
FILE是C语言提供的结构体类型,其内部封装了文件描述符fd
//输出其中的文件描述符
FILE* fp = fopen("log.txt","w");
printf("fp:%d\n",fp->_fileno);
fclose(fp);
在C语言在用fopen函数访问文件时,必然会使用FILE封装的文件操作符
C语言为什么要这么做?
我们对文件进行操作,既可以使用系统调用,也可以使用语言提供的文件操作方法
Linux下的系统调用在其他平台上是不起作用的,但C语言提供的操作方法对系统调用进行了封装,代码具有跨平台性
扩展:C语言的源代码在不同的平台下会被编译成不同的库,以此实现了跨平台性
……
写了一个这样的代码并执行:
int main(){while(1){printf("pid:%d\n",getpid());sleep(1);}return 0;
}
复制SSH渠道在另一个窗口执行以下指令(此次进程pid是25860):
ls /proc/25860/ -l

cwd:当前工作路径
exe:当前对应的可执行程序的二进制文件
fd:文件描述符
ls /proc/25860/fd -l

表示的是 0 1 2 对应的文件(标准输入、标准输出、标准错误)在/dev/pts/1中打开(如果是我们自己的电脑,应该分别对应键盘、显示器、显示器 —— 但这是云服务器,输入输出都在终端上,呈现出来就是这个样子)
/dev/pts/1是我们打开的终端
于是我们可以在一个终端向另一个终端中进行打印

//当然也可以在写一个代码指定终端打印:
int fd = open("/dev/pts/1",O_WRONLY|O_APPEND);
//……………………………………………………………………………………………………………………
到底还是文件
重定向与缓冲区 – 认识
获取文件属性
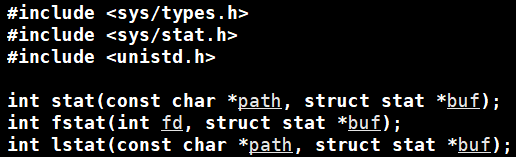
struct stat:输出型参数,传入stat对象指针,给你填好其中的内容(文件属性)
stat结构体:

#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
const char* filename = "log.txt";
int main(){ //读取文件属性 struct stat st; int n = stat(filename,&st); if(n<0) return 1;//<0获取失败 printf("file size:%lu\n",st.st_size);//文件大小(lu:无符号长整形整数) //读取文件内容 int fd = open(filename,O_RDONLY);//打开文件,只读 if(fd<0){ perror("open"); return 2; } printf("fd:%d\n",fd); char* file_buffer = (char*)malloc(st.st_size+1);//开缓冲区(老师偏要掐着大小开) n = read(fd,file_buffer,st.st_size);//n=0表示到达文件末尾 n>0表示读到多少字节 if(n>0){ file_buffer[n] = '\0'; printf("%s\n",file_buffer); } free(file_buffer); return 0;
}
文件描述符的分配规则
查自己的文件描述表,分配最小的没有被使用的fd
即上面的代码中,如果你一开始就执行了 close(0) 或 close(2),那么fd的值就会变成 0 或 2
重定向
在下面的代码中,我们关闭了标准输出流:
int main(){close(1);int fd = open(filename,O_CREAT | O_WRONLY | O_TRUNC, 0666);//打开文件,只读if(fd<0){perror("open");return 1;}printf("printf fd:%d\n",fd);fprintf(stdout,"fprintf fd:%d\n",fd);fflush(stdout);close(fd);return 0;
}

为什么输出到了文件中?
我们知道,标准输出流 stdout 的数据类型是FILE*,其内部存储着的文件描述符为 1,被打开的文件的文件描述符为 1,printf 函数默认输出到标准输出流中(现在看来不如说是文件描述符为1的文件中)
这就是重定向
缓冲区
上面的代码中,如果最后不加 fflush(stdout); 这条语句,则文件内没有内容:
C语言的FILE结构体中,封装的不只有文件描述符 file_no,还有语言级别的缓冲区
我们常用的 fflush(stdout); 语句是将语言级别的文件缓冲区中的内容刷新到文件内核级别的文件缓冲区
平常我们在 return 0;之后会刷新缓冲区,而这里因为在 return 0 之前文件就被关闭,又没有 fflush 函数,故不会刷新缓冲区
重定向与缓冲区 – 理解使用
重定向
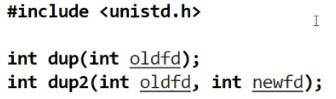
dup2:是一个系统调用函数,用于复制文件描述符,并将其指定为新的文件描述符
用起来也是非常简单:
const char* filename = "log.txt";
int main(){int fd = open(filename,O_CREAT | O_WRONLY | O_TRUNC, 0666);//打开文件,只读if(fd<0){perror("open");return 1;}dup2(fd, 1);//让1文件描述符表示原来的fd文件printf("printf fd:%d\n",fd);fprintf(stdout,"fprintf fd:%d\n",fd);while(1){printf("pid:%d\n",getpid());fflush(stdout);sleep(1);}fflush(stdout);return 0;
}


缓冲区
● C语言提供了语言级别的缓冲区的好处:
1.解耦合 —— 用户将数据交给C语言的缓冲区后就不用管之后的事情了,降低了用户和操作系统之间的耦合
2.提高(使用者和刷新IO的)效率 —— 使用系统调用是需要代价的(操作系统要做很多事情,你可能需要等待),但把数据直接交给C语言不需要;如果我使用了10次printf,C语言并不会每次都立刻刷新缓冲区,而是一起刷新
● 缓冲区是什么
就是一段内存空间
● 为什么要提供缓冲区
给上层提供高效的IO体验,间接提高整体的效率
● 怎么做
a. 刷新策略
- 立即刷新:(语言级)fflush (系统级) #include <unistd.h> void sync(void);
- 行刷新(显示器 – 照顾用户的查看习惯)
- 全缓冲:缓冲区写满才刷新(普通文件)
b.特殊情况
进程退出,系统会自动刷新
刷新策略对于用户和内核级别是通用的,但现在我们只关心用户层面

● 查看C语言中的缓冲区:
vim /usr/include/stdio.h
底行模式下查找:
可以看到 FILE 也称 _IO_FILE


vim /usr/include/libio.h
底行模式下查找:

每打开一个文件,它就自带一个这样的缓冲区—— printf 和 scanf 都是这样
实现一个简单的Shell(加上重定向)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>#define SIZE 512
#define ZERO '\0'
#define SEP " "//分隔符
#define NUM 32
#define SkipPath(p) do{ p += (strlen(p)-1); while(*p != '/') p--; }while(0)
//————————————————————————————
//————————————————————————————下面这部分是为重定向定义的
//跳过空格(比如echo hello world > log.txt,> 后有一个空格,而我们需要的是空格后面的文件名)
#define SkipSpace(cmd, pos) do{\while(1){\if(isspace(cmd[pos]))\pos++;\else break;\}\
}while(0)//重定向类型
#define None_Redir 0//没有重定向
#define In_Redir 1//输入重定向
#define Out_Redir 2//输出重定向
#define App_Redir 3//追加重定向int redir_type = None_Redir;
char* filename = NULL;
//————————————————————————————
//————————————————————————————
char cwd[SIZE * 2];//当前进程所处路径
char* gArgv[NUM];//用于存储命令行参数
int lastcode = 0;//错误码//简单功能实现1:结束进程
void Die()
{exit(1);
}
//简单功能实现2:获取环境变量
const char* GetHome()
{const char* home = getenv("HOME");if (home == NULL) return "/";return home;
}
//简单功能实现3:获取用户名
const char* GetUserName()
{const char* name = getenv("USER");if (name == NULL) return "None";return name;
}
//简单功能实现4:获取设备名
const char* GetHostName()
{const char* hostname = getenv("HOSTNAME");if (hostname == NULL) return "None";return hostname;
}
//简单功能实现5:获取当前工作目录所处路径
const char* GetCwd()
{const char* cwd = getenv("PWD");if (cwd == NULL) return "None";return cwd;
}//简单功能实现6:打印命令行(输入命令时前面默认打印的那个东西)
void MakeCommandLineAndPrint()
{char line[SIZE];const char* username = GetUserName();const char* hostname = GetHostName();const char* cwd = GetCwd();SkipPath(cwd);snprintf(line, sizeof(line), "[%s@%s %s]> ", username, hostname, strlen(cwd) == 1 ? "/" : cwd + 1);//int snprintf(char* str, size_t size, const char* format, ...)//(1) 如果格式化后的字符串长度 < size,则将此字符串全部复制到str中,并给其后添加一个字符串结束符('\0');//(2) 如果格式化后的字符串长度 >= size,则只将其中的(size - 1)个字符复制到str中,并给其后添加一个字符串结束符('\0'),返回值为欲写入的字符串长度//最后这个strlen(cwd) == 1 ? "/" : cwd + 1的含义为若当前绝对路径为/home/hazb(经过SkipPath函数后cwd指向的字符串为/hazb),则打印hazb,若当前绝对路径为/就打印/printf("%s", line);fflush(stdout);
}
//简单功能实现7:获取用户输入的命令行参数(并填入输出型参数command中)
int GetUserCommand(char command[], size_t n)
{char* s = fgets(command, n, stdin);if (s == NULL) return -1;command[strlen(command) - 1] = ZERO;return strlen(command);
}
//简单功能实现8:分割命令行参数
void SplitCommand(char command[], size_t n)
{(void)n;// "ls -a -l -n" -> "ls" "-a" "-l" "-n" gArgv[0] = strtok(command, SEP);int index = 1;while ((gArgv[index++] = strtok(NULL, SEP))); // done, 故意写成=,表示先赋值,在判断. 分割之后,strtok会返回NULL,刚好让gArgv最后一个元素是NULL, 并且while判断结束
}
//简单功能实现9:特殊处理cd命令
void Cd()
{const char* path = gArgv[1];if (path == NULL) path = GetHome();// path 一定存在chdir(path);// 刷新环境变量char temp[SIZE * 2];getcwd(temp, sizeof(temp));snprintf(cwd, sizeof(cwd), "PWD=%s", temp);putenv(cwd); // OK
}
int CheckBuildin()//检查是否是内建命令(比如cd)
{int yes = 0;const char* enter_cmd = gArgv[0];if (strcmp(enter_cmd, "cd") == 0){yes = 1;Cd();}else if (strcmp(enter_cmd, "echo") == 0 && strcmp(gArgv[1], "$?") == 0){yes = 1;printf("%d\n", lastcode);lastcode = 0;}return yes;
}//执行命令
void ExecuteCommand()
{pid_t id = fork();if (id < 0) Die();else if (id == 0){//重定向设置(通过看filename有没有被处理过判断是否有重定向)if (filename != NULL) {if (redir_type == In_Redir){int fd = open(filename, O_RDONLY);dup2(fd, 0);}else if (redir_type == Out_Redir){int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);dup2(fd, 1);}else if (redir_type == App_Redir){int fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);dup2(fd, 1);}else{}}// childexecvp(gArgv[0], gArgv);exit(errno);}else{// fahter(等待子进程返回并看是否要打印错误信息)int status = 0;pid_t rid = waitpid(id, &status, 0);if (rid > 0){lastcode = WEXITSTATUS(status);if (lastcode != 0) printf("%s:%s:%d\n", gArgv[0], strerror(lastcode), lastcode);}}
}
//判断是否存在重定向:
void CheckRedir(char cmd[])
{// > >> <// "ls -a -l -n > myfile.txt"int pos = 0;int end = strlen(cmd);while (pos < end){if (cmd[pos] == '>'){if (cmd[pos + 1] == '>'){cmd[pos++] = 0;//分割重定向前后的命令行参数pos++;redir_type = App_Redir;SkipSpace(cmd, pos);filename = cmd + pos;}else{cmd[pos++] = 0;redir_type = Out_Redir;SkipSpace(cmd, pos);filename = cmd + pos;}}else if (cmd[pos] == '<'){cmd[pos++] = 0;redir_type = In_Redir;SkipSpace(cmd, pos);filename = cmd + pos;}else{pos++;}}
}int main()
{int quit = 0;while (!quit){// 0. 重置redir_type = None_Redir;filename = NULL;// 1. 我们需要自己输出一个命令行MakeCommandLineAndPrint();// 2. 获取用户命令字符串char usercommand[SIZE];int n = GetUserCommand(usercommand, sizeof(usercommand));if (n <= 0) return 1;// 2.1 checkredirCheckRedir(usercommand);// 2.2 debug(测试用)
// printf("cmd: %s\n", usercommand);
// printf("redir: %d\n", redir_type);
// printf("filename: %s\n", filename);
//// 3. 命令行字符串分割. SplitCommand(usercommand, sizeof(usercommand));// 4. 检测命令是否是内建命令(不需要子进程去执行的命令--比如cd)n = CheckBuildin();if (n) continue;// 5. 执行命令ExecuteCommand();}return 0;
}
标准输出和标准错误(在重定向下的意义)
对于以下的代码:
int main(){ fprintf(stdout,"stdout\n"); fprintf(stderr,"stderr\n"); return 0;
}
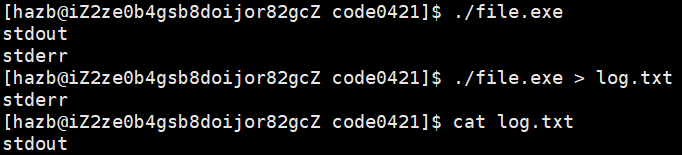
● 解释:尽管 stdout 和 stderr 指向同一个文件(显示器),但 > 重定向仅为 “标准输出重定向”
原因:虽然我们平时写代码会将正确、错误的信息都通过stdout打印,但像是在debug等情况时,正确的信息会通过 stdout 打印,错误的信息通过 stderr 打印,只需要一次重定向我们就可以把正确和错误的信息在文件的层面上区分(可以方便我们debug)
● 如何重定向 stderr 呢:

● 将 stdout 和 stderr 重定向到同一个文件:

解释:1>log.txt:1文件描述符指向的文件重定向为 log.txt,2>&1:1文件描述符下标内的指针(struct file*)拷贝给2文件描述符下标中的指针
● perror
perror 向 2 打印(printf 向 1 打印)
这么做可以方便将错误信息过滤出来,便于查看
磁盘文件
以上我们仅对被打开的文件进行了讨论,那么剩下的占大部分的未被打开的文件被存放在哪里,又要如何被找到然后打开呢?
存放在磁盘,通过路径+文件名寻找
研究磁盘文件,本质是在研究数据(文件)如何存取的问题
磁盘存储文件

操作系统对磁盘存储进行逻辑抽象
为什么要这么做 —— OS直接使用CHS,耦合度太高,于是为了方便实现内核进行磁盘管理

对于大块的空间,磁盘也会进行分区管理:

分区也只需要记录起始块号和结束块号就能分区
磁盘分区后还会对区进行分组管理:
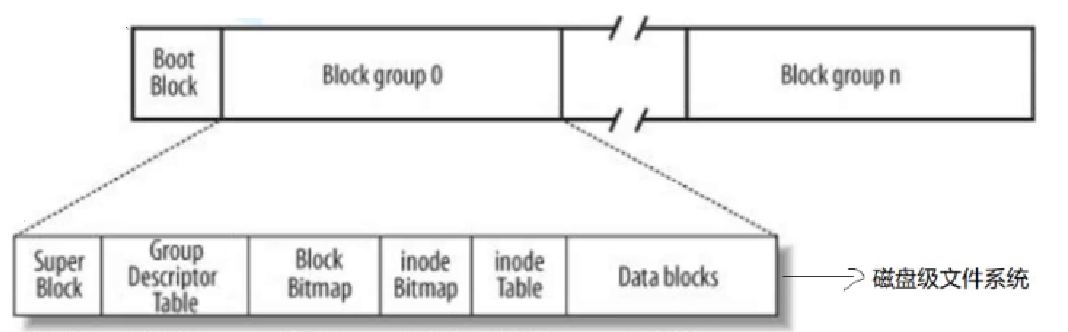
文件 = 内容 + 数据
Linux文件系统特点:文件内容和文件属性分开存储
Data blocks(数据区):存放文件内容(前面我们说过操作系统中以4KB–8个扇区为单位,故存放内容的基本单位也是4KB)
Block Bitmap(块位图):记录了Data Block中数据块被占用的情况(是否被占用);只需一个块(可以是多个块) – 4KB位图就可以表示410248 == 32,768个块被占用的情况
inode Table(i节点表):存放文件属性,如文件大小、所有者、最近修改时间等(对于一个文件属性的集合来说,大小固定,128字节 – 一个块可以表示32个inode)
inode Bitmap(inode位图):每一个 bit 表示一个 indoe 是否空闲可用
struct inode{//文件的属性int size;mode_t mode;int creater;int time;//...int inode_number;int datablocks[N];//该文件占用的块号(inode记录了与数据块的映射关系)——可见只要找到了indoe,就可以得到文件的内容+属性//这个N是多大呢?不同文件系统里N不同,我们此处讲的是ext2(常用的是ext3和ext4,不过它们的区别主要在日志和安全上),ext2中N是15//下标0~11的datablocks直接映射到块(直接寻址),最多存48KB;下标12、13会进行间接寻址,即用映射的块再进行映射,最多存2* 4*1024/4 *4*1024(2个间接寻址 块的大小为4KB--换算为4*1024字节 认为数字的类型为int占4个字节->至此能映射2*4*1024/4个块,可以映射的大小:2*4*1024/4*4*1024字节 = 8G);下标14会进行两次间接寻址……//如果文件太大,分给当前组的数据块不够用,寻址时是可以跨组访问的——但这样无疑会降低整体的效率(位置跨越过大,对于作为硬件的磁头和盘片就要重新寻址)
};
//其中没有文件名
Group Descriptor Table(CDT 块组描述符):描述一个块组的具体使用情况
Super Block(超级块):描述整个分区整体的信息,(eg.bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息)
超级块不是每个分组都有的,但也不是在整个分区里只有一个,根据不同的文件系统,它一般会在2~3个组中存在且内容是保持一致的
原因:如果只有一个,Super Block的信息被破坏,可以说整个文件系统结构就被破坏了,但多个Super Block则可以使文件系统更健壮(eg.当前组的Super Block被破坏,分区直接挂了–电脑蓝屏,重启时提醒是否恢复数据–用其他组的Super Block对当前默认使用的Super Block做校验)
在每一个区间内部分组,然后写入文件系统的管理数据(指的就是以上的东西,填入需要填入的属性信息,清空位图……),这个过程叫做 “格式化” —— 格式化的本质就是在磁盘中写入文件系统
inode 编号
我们寻找文件时,都是要先得到文件的 inode 编号
inode 编号是以分区为单位整体分配的(inode不能跨分区访问)
Super Block会记录下分组的情况(某一组的块号是多少到多少),Super Block 和 GDT 中有 inode 在每个分组中可取到的范围(某组申请的inode是有一定范围的)

数据块(Data Block)的分配同理
● 我们平常都在用文件名去找文件,但这里怎么全是 inode ?
先谈谈目录:
我们知道,目录也是文件,= 内容 + 属性
stat 显示文件的状态信息(属性),可见目录和普通文件基本没有区别
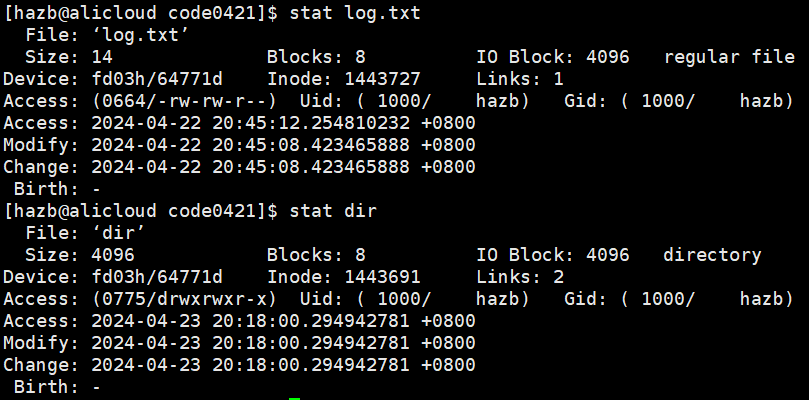
目录的 “内容” 放什么?—— 文件名和 inode 编号的映射关系
以以下命令为例:我们输入cat log.txt(文件名),在执行时会根据文件名和inode的映射关系得到 inode 编号,然后会使用 inode 去系统中找到相应的文件

这就可以解释:
1.一个目录下不能存在同名文件
2.去掉目录的读权限后,ls 指令就没法执行了:我们无法获取文件名和 inode 编号的映射关系了
3.如何理解一个文件的增删查改:
增:新建文件,在当前组申请inode(Super Block会记录该分配什么inode–下标从0开始),因为对于不同的组,inode规定了范围[a,b],inode 再加上 a 即可(之后就是修改inode的位图,分配数据区后再修改块位图……)
删:只需修改两个位图即可 —— 这可以说明为什么我们平时一个大文件下载半天,但删除却是几秒的事情
● 寻找文件的真实情况
上面说我们要找文件,是先提供文件名(事实上我们不止提供了文件名,还提供了路径),根据目录存储的文件名和 inode 的映射关系找到它的 inode,进而用 inode 去找对应的文件
但目录也是文件,想要使用目录里的东西,你也得先把目录找到,就这样不断向前,直至遇到根目录(根目录的文件名和inode在开机时就确定下来了)
—— 逆向的路径解析
这就是为什么在linux中定位一个文件在任何时候都要有路径的原因
不过这个工作(逆向路径解析)每次都要进行吗?不用,linux会缓存我们常用的路径结构
软硬链接(不是软件和硬件链接的意思(大雾))
软硬链接是什么样子
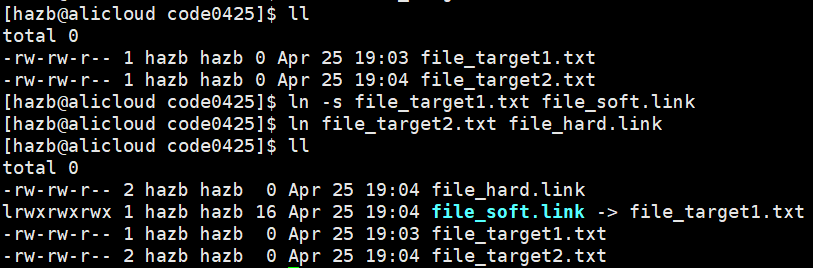
如图,建立 file_target1.txt 的软连接和 file_target2.txt 的硬链接
软硬链接的特征
软连接:有独立的 inode 编号,是一个独立的文件(类似windows中的快捷方式)
软连接的内容:目标文件对应的路径字符串
硬链接:没有独立的 inode 编号,不是一个独立的文件
可见将硬链接的目标文件删除后硬链接仍能使用 ——
硬链接本质就是文件名和inode的映射关系;建立硬链接,就是在指定目录下添加一个新的文件名和inode编号的映射关系
上面的操作可以看做是 对文件的重命名
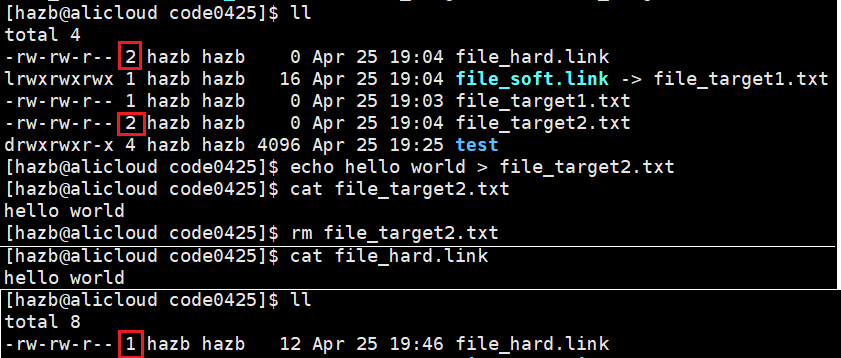
● 上面用红框标出的是“硬链接数”(也称引用计数)
文件的磁盘级引用计数:有多少个文件名字字符串通过inode编号指向本文件
小结:
定位一个文件我们有两种方式:1.路径 2.使用目标文件的inode(它们终归都是要借助inode编号)
1 对应软链接,2 对应硬链接
用处
1.软连接的用处:
如果我们有这样一个 “项目”:
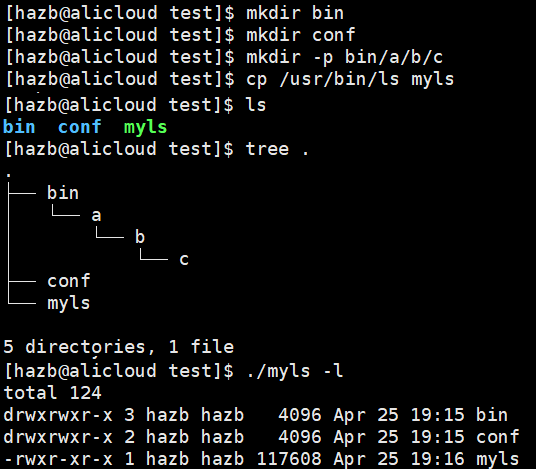
倘若我们需要将 myls放入 ./bin/a/b/c 目录中,那么我们在当前这个 test 目录下想要使用 myls 就需要:
./bin/a/b/c/myls -l
我们可以用软连接的方式进行优化:
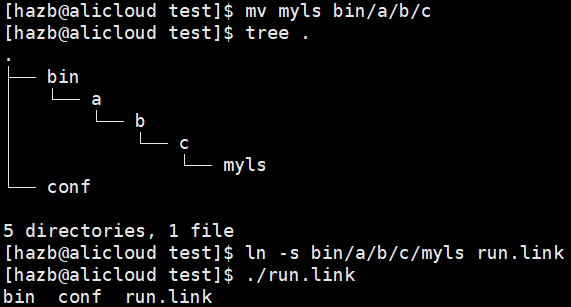
2.硬链接的用处
新建一个目录和一个文件,发现它们的引用计数分别是 2 和 1

为什么目录是2:
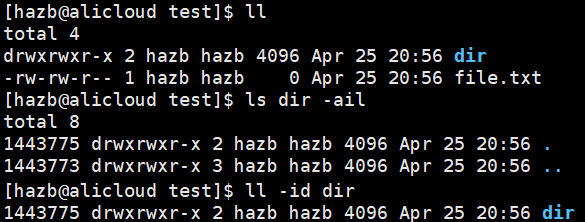
可见,目录中的隐藏文件 . 是目录的重命名
在目录 dir 内部再创建一个目录 dir_,发现 dir 的引用计数变成了3 —— dir_ 中的隐藏文件 … 是目录 dir 的重命名
硬链接可以构建Linux的相对路径结构,让我们可以使用 . 和 … 来进行路径定位
注意:
● Linux 系统中,不允许给目录建立硬链接 —— 避免形成路径环绕(路径环绕eg./home/hazb目录下有一个根目录的硬链接,在搜索时若搜索到硬链接处,岂不就回到了根目录下)
但显然,Linux中的 . 和 … 形成了很多的路径环绕,这莫不是只许官郎防火不许百姓点灯?—— . 和 … 的文件名是固定的,所有的文件指令在设定的时候几乎都能知道它们是干什么的
一般用硬链接来做文件备份
动静态库
Linux 中,.so 是动态库,.a 是静态库
Windows 中,.dll是动态库,.lib 是静态库
看看库是什么样子:

ldd:查看可执行程序所依赖的库
其中 /lib64/libc.so.6 就是C标准库

C++标准库

静态库
假如我在和同学合作一个项目,我来写函数,同学去调用
我写的:
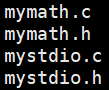
同学只需根据头文件的指导去调用我们写的函数去写他的main.c文件即可
//极其简陋的示例代码如下:
//mystdio.h
#include<stdio.h>
//mystdio.c
#include"mystdio.h"
//mymath.h
int Add(int x, int y);
//mymath.c
#include"mymath.h"
#include<stdio.h>
int Add(int x, int y){return x+y;
}
//main.c
#include<mymath.h>
#include<mystdio.h>
int main(){printf("结果是:%d\n",Add(1,2));return 0;
}
之后 gcc main.c mymath.c mystdio.c -o main.exe,即可得到可执行文件
(虽然暂且不知道怎么解释老师先把以上三个文件先编译成 .o 文件再处理的含义……——老师写的是gcc main.o mymath.o mystdio.o -o main.exe)
但如果我们写的文件很多,怎么处理方便?
ar -rc libmyc.a *.o 命令将函数的实现文件 “打包”(这个打包不需要我们解包,可以直接用)(ar:归档工具,相当于打包工具,rc:replace and create)
gcc main.c libmyc.a -o main.exe 即可得到可执行文件
所谓库文件,本质就是把 .o 文件打包
如果有许多人要用我们写的函数,我们就可以把打包好的文件发到网上让他们去下载,下载下来以后可以进行安装:
我们打包整理好的文件:
安装(即把头文件和库文件拷贝到系统的头文件搜索路径和库文件搜索路径里)

系统库的搜索路径下能看到我们拷贝的文件(安装完了)
在以上的安装完成之后,在引用我们写的函数调用的头文件时,就不需要用 “” 而可以用 <> 了

但直接使用 gcc main.c 指令仍无法通过,原因:
我们一直以来用的都是C、C++的库,gcc 和 g++是默认认识C/C++的库的,而我们这个 libmyc.a 是第三方提供的,gcc 和 g++ 不认识
解决方式:gcc main.c -llibmyc.a(表示不仅要链接main.c,还要链接我们写的这个库 —— 仍过不了,因为gcc、g++默认libmyc.a这个文件因去掉前后缀 – 应该写成 gcc main.c -lmyc)
不过十分不推荐将非官方的人写的东西放在系统里
这样我们就完成了卸载的工作

● 既然不推荐以上做法,那应该如何在当前目录下调用我们的函数呢
我们的目录:
gcc 提供了允许程序员动态指定头文件和库的搜索路径的指令:
gcc main.c -I ./mylib/include/ -L ./mylib/lib -lmyc //-I指定用户自定义的头文件的搜索路径,-L指定用户自定义的库文件的搜索路径 -l执行确定的第三方库的名称(去掉前后缀)
//为什么头文件后面我们不写-l选项呢 —— 在main.c里面我们引用指定了头文件名称
这么写时,main.c 内引用时使用 <> 仍可通过编译
如果不加 -I 选项:
main.c里面引用指定了头文件时:#include “mylib/include/mystdio.h” 采用这样的写法(不能使用<>,会去系统默认的路径下去寻找其中的内容)
动态库
//使用以下的指令形成.o文件
gcc -fPIC -c mystdio.c
gcc -fPIC -c mymath.c
//fPIC:产生位置无关码
因为动态库实在是太常用,gcc 就支持形成动态库:
gcc -shared *.o -o libmyc.so//shared:表示生成共享库格式(别生成可执行程序了)
把形成的动态库放入我们的mylib目录中:
gcc main.c -I ./mylib/include/ -L ./mylib/lib -lmyc 即可得到可执行程序(经过了动态链接)
在后面加上 -static 选项表示静态链接,不加则表示 优先 动态链接
(但其实你如果加上-static可能是没法通过的,因为其意为强制静态链接,要求链接的任何库都必须提供对应的静态库版本——而系统中大多数时候提供的只有动态库,不提供静态库(比如C/C++的静态库就需要我们自己去安装))
但理论上说这个可执行程序运行是会有问题的(之所以说是理论上,因为我的没问题,可能和系统有关?):

问题描述:找不到 libmyc.so 文件
原因:尽管你在上面的指令里表明了头文件、库的位置,头文件在预编译时展开(拷贝到源文件中),而动态库则需要在程序运行的时候找到动态库加载并运行 —— 上面的指令是对 gcc 这个编译器说的,操作系统不知道,自然也就无法根据你给出的路径去找库文件
解决方法:
- 将库文件安装到系统(将 libmyc.so 拷贝到 /lib64 这个动态库里)—— 不好
- 建立软连接(在 /lib64 中建立与 libmyc.so 文件的软链接)
sudo ln -s libmyc.so文件所在路径 /lib64/libmyc.so
sudo unlink /lib64/libmyc.so
- 命令行导入环境变量(加载库路径环境变量:LD_LIBRARY_PATH)
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:libmyc.so文件所在路径//但环境变量是内存级的,重登一次就会失效
-
修改 .bashrc 配置文件,让环境变量永久生效
登录脚本文件 .bash_profile 和 .bashrc
打开 .bashrc 文件并在以下语句后加上 :libmyc.so文件所在路径 来配置环境变量

-
新增动态库搜索的配置文件
cd 进入 /ect/ld.so.conf.d 目录下 --> 创建 .conf 文件 --> 在该文件中写入libmyc.so文件所在路径,保存退出 --> ldconfig 命令让配置文件生效(需要超级用户的权限)
ld – load,so – 动态库,conf – 配置文件,d – 目录,这个目录中都是系统级的配置文件
使用外部库
系统中其实有很多库,它们通常由一组互相关联的用来完成某项常见工作的函数构成。比如用来处理屏幕显示情况
的函数(ncurses库)
使用示例:
- 安装 Linux下安装ncurses库
- 可见 ncurses 为我们提供了头文件和动态库

- 找一位大佬的程序做演示,白嫖大佬的代码到 game.c 文件中 linux环境下Ncurses实现贪吃蛇游戏
- 编译成可执行程序
gcc game.c -lpthread -lcurses //加上 -lcurses (-l选项)是因为这是一个第三方库,虽然头文件和动态库已经被安装到了系统里,但我们需要给编译器指定要链接的动态库;至于-lpthread嘛……这不是我现在学的东西 - 运行
动态库加载 – 可执行程序和地址空间
//总之就是一个从1加到top的简单程序
#include<stdio.h>
int Sum(int top){int i = 1;int ret = 0;for(; i<=top; i++){ret += i;}return ret;
}
int main(){int top = 100;int result = Sum(top);printf("result:%d\n",result);return 0;
}
objdump -S code > code.s //反汇编
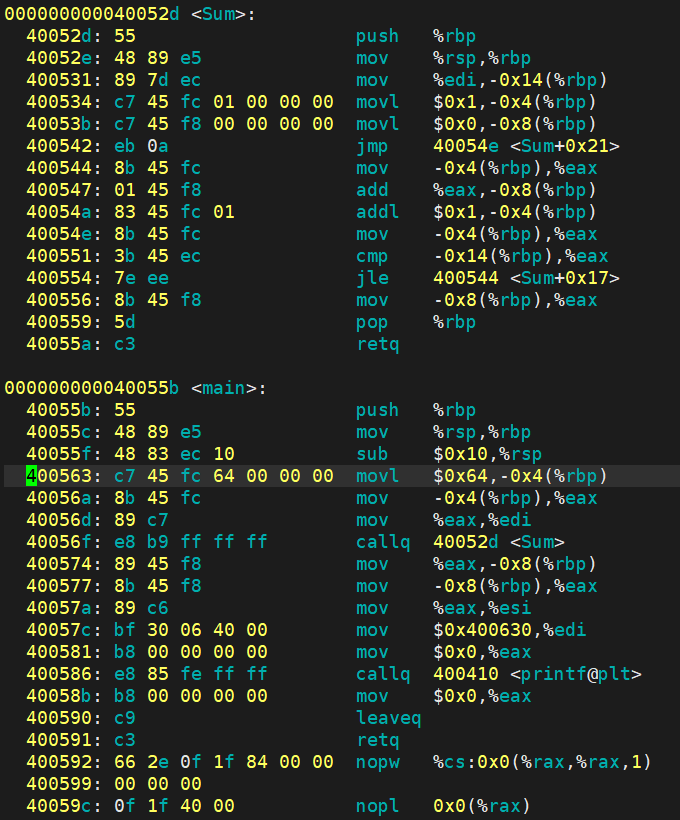
根据反汇编代码可以看出,形成的可执行程序内部有地址(还未被加载时就有)(每一行汇编语句都有其对应的地址)
定义的函数名、变量名在翻译成二进制后变成了地址
在 Linux 中形成的可执行程序的格式:ELF的可执行程序;我们不能只知道可执行程序是个二进制文件就完了,二进制是有自己的固定格式的:elf可执行程序的头部(其中就包含了可执行程序的属性)
● 如何编址?
编制范围:0000…0000 到 FFFF…FFFF – 全0到全F
地址分类:
绝对编址:从全0到全F连续编址(依次往后排)
相对编址:每一个区域的起始地址+偏移量(从0开始)
程序和库的加载:

判断库是否已经被加载到了物理内存中:
和进程一样,库也需要被操作系统管理,因此需要被描述组织 —— 对于加载到内存的库,会用库描述的结构体记录其属性(名字、和什么进程映射了……),内存中往往会有很多的库,所以许多的这样的结构体用链表连接了起来
进程运行到需要用到某个库的地方时,发现库不在,于是缺页中断,让操作系统去遍历以上链表看其是否已经被加载
回顾动态库选项 -fPIC :让动态库能够被独立加载,不能拷贝到可执行程序里,和可执行程序一般进行完全编址,方便其在物理内存中任意加载、在进程地址空间任意映射