文献来源: 王向前,张宝隆,李慧宗.本体研究综述[J].情报杂志,2016,35(06):163-170.
一、本体的定义
本体概念被引入人工智能、知识工程等领域后被赋予了新的含义。然而不同的专家学者对本体的理解不同,所给出的定义也有所差异。
人工智能领域的学者Neches(1991)等人对ontology进行定义,即:本体是构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延的规则的定义。Neches是最早对本体定义进行研究的学者,从内容的角度给出了本体定义,概括出了本体的基本要素,包括领域术语、关系和规则。这为其后各领域学者对本体的定义研究提供了参考借鉴。 美国斯坦福大学Gruber(1993)给出了本体的定义:本体是概念化的规范说明。Gruber给出的本体定义最为经典,但是未能全面概括出本体的本质。 随后,Borst等人(1997)对Gruber给出的定义进行了补充,即“本体是共享概念模型的形式化规范说明”。Borst提出了本体共享的概念,阐明了本体的共享本质,但没有说明概念与概念之间的关系。德国学者Studer等人(1998)又对Borst的定义进行了扩展,提出了概念关系之间的“明确”定义,认为:“本体是共享概念模型的明确的形式化规范说明”。Studer给出的本体定义被各领域专家学者高度认可,其涵盖了本体的基本特征:共享、明确、概念化、形式化,被学术界广泛引用,对于后来的本体研究具有重要意义。
中国学者对本体定义也做了很多研究。张晓林教授(2002)认为“ontology”是概念集,是特定领域公认的关于该领域的对象及其关系的概念化表述。张秀兰教授通过对国内外各领域本体定义的深入研究,总结出了本体定义:本体是通过描述、捕获领域知识,确定领域内共同认可的概念和概念间的关系,以用于领域内的不同主体之间交流与知识共享的形式化规范说明。
对比中外学者关于本体的定义不难发现,国外对本体的研究较为深入,所给出的本体定义比较经典,被学术界广泛引用。而国内关于本体的研究起步较晚,多数学者对本体的研究是在国外学者的基础上进行的,对于本体的定义强调领域概念,是对本体定义的进一步扩展。关于本体定义,学术界一直没有统一的定论,但存在基本的共识,即本体包括:概念化、形式化、可共享、明确、描述领域知识这五大特征。这五大特征基本概括出了本体的实质内容,但随着本体理论和技术的不断拓新和发展以及本体应用的日渐成熟,对于本体的认识会更加清晰,本体定义也将会更加全面准确。
二、本体描述语言
本体作为一种共享的、对概念的形式化描述,需要用事先规定的语言对其进行描述或表示。在本体理论和技术研究过程中,涌现出了多种本体描述语言。其中,具有代表性的本体描述语言可以划分为两类:基于谓词逻辑的本体描述语言和基于Web的本体描述语言。
(一) 基于谓词逻辑的本体描述语言
基于谓词逻辑的本体描述语言主要包括Ontolingua、OCML、LOOM、Cycl和Flogic。其中,Ontolingua、OCM L和Flogic是基于一阶谓词逻辑和框架模型的本体描述语言,LOOM是基于描述逻辑的,Cycl是在一阶谓词逻辑基础上进行扩展的二阶逻辑语言。这些本体描述语言可以通过形式化的表示来实现计算机的自动处理,但不足之处在于有些概念及概念关系难以用谓词逻辑准确表示,形式化表示具有局限性。
(二) 基于Web的本体描述语言
基于Web的本体描述语言主要包括XOL、RDFS、SHOE、OIL、DAML+OIL和OWL。XOL是基于XML的本体交换语言,SHOE是简单HTM L本体的扩展,这两种语言的形式化基础是框架。RDFS、OIL、DAML+OIL和OWL都是基于RDF的进一步扩充,继承了RDF的语法和表达能力。
(三)本体描述语言比较
随着计算机技术和互联网技术的发展,基于Web的本体描述语言逐渐成为主要本体描述语言。以下就基于Web的本体语言进行主要元素和推理机制方面的比较,采用西班牙马德里大学理工分校的评价标准和框架。表1、表2中,“有”表示描述语言具有此特性,“无”表示描述语言不具有此特性,“可实现”表示无强制要求但是可以实现此特性。
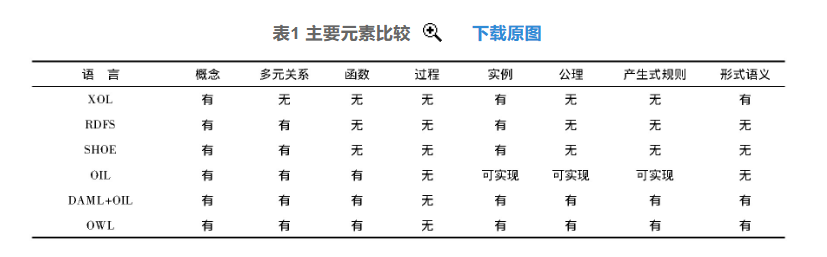
从表1可以看出,这6种语言基本都支持概念、多元关系和实例的定义,XOL、RDFS和SHOE缺乏函数、公理和产生式规则,对领域知识的定义不够完整。OWL和DAM L+OIL对各主要元素基本上都支持,对领域知识的定义较为完备,说明这两种语言具有较强的知识表达能力,而OIL在此方面则表现不足。

从表2可以看出,基于Web的本体描述语言多数不具备“出错处理”“过程的执行”和“限制性检验”,但都具备“单调性”“简单继承”和“多重继承”。DAM L+OIL语言具有大部分特征,其推理能力相对较好,而目前最常用的OWL语言,其推理能力表现一般。从推理机制比较可以看出,目前还没有最佳的本体描述语言,所以在构建本体时要根据应用领域选择最合适的语言。总的来说,上述几种语言各具特点,都能很好的描述本体,但这些在知识推理和表达方面都有所欠缺,没有一种语言能够同时兼备推理性和表达性。因此,在应对不同领域对知识表达和推理的不同需求时,应注意选择合适的本体描述语言。目前,由于OWL是W3C的推荐标准,符合RDF/XM L标准语法格式,并且能够与多种本体描述语言进行兼容和交互,所以应用范围很广,深受用户的青睐。2012年W3C又推出的OWL2是对OWL进一步完善,在OWL的语法方面进行了改进,并且提供更强大的表达能力和逻辑推理能力,在本体构建方面和语义网中将会有更广阔的应用前景。
三、本体构建抽象方法
本体构建方法可分为抽象方法和具体方法[12]。抽象方法用来说明本体构建需要哪些步骤,具有宏观指导作用。而具体方法是用于说明本体构建过程中需要哪些具体方法。本文只讨论抽象方法。
目前具有代表性的本体构建方法有骨架法[13]、IDEF5法[14]、七步法[15]、五步循环法[16]、METH-ONTOLOGY法[17]、TOVE法[18]、KACTUS法[18]、SENSUS法[19]和循环获取法[20]。
骨架法、TOVE法和IDEF5法多用于企业领域本体的构建,它们的主要区别在于:骨架法是基于流程导向的构建方法,它提供了构建方法学框架;TOVE法本质上是构建本体所描述的知识逻辑模型;而IDEF5法可通过提供图表语言和细化说明来构建企业领域的本体。
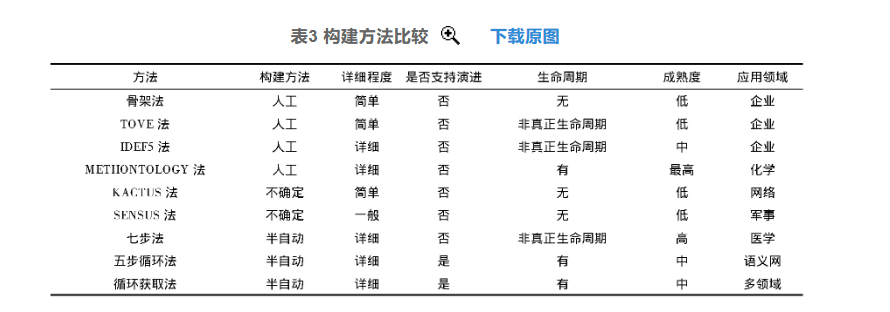
M ETHONTOLOCY法、KACTUS法、SENSUS法和七步法,主要用于构建领域知识本体,它们的不同之处在于:METHONTOLOCY法是以化学领域的本体构建方法为基础,经过改进发展而来的,构建方法更为通用;KACTUS法主要是对已有本体的提炼、扩展,难以用于构建新的本体;SENSUS法遵循自上而下的层级结构,可操作性较强;七步法是基于本体构建工具Protégé的本体构建方法,较为实用,应用广泛。
五步循环法和循环获取法比较相似,都强调本体迭代循环,支持本体演进,但五步法是用于语义网环境下本体学习的本体构建方法,而循环获取法是基于文本的领域本体构建方法,缺乏具体的技术。
从构建方法、应用领域等多方面对本体构建方法进行比较(见表3),并总结各方法的优缺点[22](见表4)。

从表中的比较可以看出,这些方法都有各自的适用领域,方法通用性比较差。除五步循环法和循环获取法,其它方法都不支持演进,方法的可扩展性不强。而七步法和METHONTOLOGY法成熟度较高,方法较为具体详细,被各领域学者专家广泛引用。
四、本体构建工具
本体开发是一项庞大的工程,需要借助开发工具来完成本体的构建任务。本体构建工具主要用于本体的开发,多数工具都具有编辑、图示、自动将系统内容转换为数据库、自动转换置标语言等功能。目前常用的本体构建工具主要分为两类:可视化手工构建工具和半自动化构建工具。
(一) 可视化手工构建工具
可视化手工构建工具主要有Protégé、Apollo、Web Onto、Web ODE和Onto Edit等,这类工具通常为用户提供可视化界面,用户可以通过简单的操作完成本体的构建。
a.Protégé。Protégé具有图形化的用户界面,操作简单便捷,提供详细的帮助文档,支持模块化设计。并且支持DAML+OIL和OWL语言,可利用RDF、RDFS和OWL等本体描述语言在系统外对本体进行编辑和修改。Protégé由于其开放源码、支持中文编辑而深受国内学者青睐。但Protégé最大的缺陷在于不能批量导入数据,构建大规模本体费时费力,手工输入错误率比较高,效率较低。
b.Apollo。Apollo采用Java语言,支持知识模型中的所有原语:本体、实例、类、功能和关系,可在编辑过程中完成一致性检测。但其在本体语言的支持能力、逻辑推理能力和可扩展性等方面还存在问题。
c.Web Onto。Web Onto是基于OCM L推理引擎的知识模型,提供多重继承、锁机制,支持用户浏览、构建和编辑本体,提供定制数据表示类型的选项和客户端API,便于检索信息。但是Web Onto不提供源代码,扩展性较差。
d.Web ODE。Web ODE是本体设计环境(ODE)的升级版,可以通过Java、RMI、COBRA、XML等技术实现,支持METHONTOLOGY本体构建方法,可通过定义实例集来提高概念模型的重用性,具有很大的灵活性和扩展性。
e.Onto Edit。Onto Edit是一个支持用图形化的方法实现本体开发和管理的工程环境,提供对本体的并发操作,支持RDFS、DAML+OIL语言,并且支持多种插件,具有良好的扩展功能。然而这几种构建工具都没有自动或者半自动获取知识和维护能力,所构建的本体兼容性差,在异构系统中难以复用。
(二)半自动化构建工具
目前,尚未出现本体自动化构建工具,基于Java语言的Jena也仅属于半自动本体构建工具。Jena提供实现本体形式化的方法,可通过程序调用方法来实现本体的自动构建。Jena可运用多种协议发布数据,能够高效存储大规模RDF三元组到硬盘,提供处理OWL和RDFS本体的API,同时客户可以利用Java API访问Jena,并将数据共享至互联网,从而可以实现本体共享。Jena大大提高了构建本体的效率,但还没有实现完全意义上的自动化本体构建,仍需进一步研究。
总之,目前常用的本体构建工具仍存在诸多问题,还未实现高效快捷的本体自动化构建。虽然多数工具提供了有好的图形界面和错误检查机制,避免了多数人为错误的发生,但这些工具仍需要手工输入和编辑大量的数据信息,费时费力,并且出错率较高,难以实现大规模的本体构建。
五、基于叙词表构建本体
本体作为网络环境下重要知识组织系统(KOS),在精准高效的知识组织和知识检索方面显示出极大的优越性。而传统知识组织系统如叙词表在网络环境中的局限性却越来越明显,但由于其概念精练规范、层次结构清晰、语义关系明确等特点,符合本体结构特征,使得其可以转换为本体。目前,国内外在利用叙词表进行本体构建方面已有大量的研究和实践,基于叙词表的本体构建也是本体研究中的一个热点问题。
叙词表转换方式主要有手工转换和自动或半自动转换。手工转换主要通过手工操作构建本体模型,将叙词表中的专业词汇转换为本体概念,再将词汇关系及注释转换为本体语义关系,最后添加领域知识等完善本体。这类手工方式主要出现在叙词表转换本体研究的初期,如金晶等[29]以手工方式对电子政务子领域“软件”叙词表进行本体构建;孙倩等利用农业科学叙词表实现了果树学领域本体的构建;刘春艳等基于SKOS进行了UKAT叙词表到本体的转换。手工转换方式费时费力、效率低、过程繁琐,所以在叙词表转换研究中应用较少,与之相关的研究也没有太多进展。
自动或半自动转换主要通过制定完备的转换规则,然后设计转换算法来实现叙词表向本体的半自动或自动转换。这类方法是叙词表转换本体的热点研究方向,现在多数基于叙词表构建本体的研究采用这种转换方式,叙词表转换本体的具体方法有很多,其中比较具有代表性的有以下四种。
a.联合国粮农组织在农业本体研究项目中,提出一个由叙词表向本体转化的方法模型:首先需要细化转换规则,丰富语义关系;其次增加推理规则;最后采用程序辅助填词,进行概念抽取,按照转换规则构建本体。该方法实用性较强,可实现叙词表半自动化转换本体,衣治安等[34]所构建的石油领域本体就是采用此种方法。
b.米佳提出了一种基于概念的转换方法。首先需要对叙词表中术语的明确性进行分析,确定之后在进行语法转换,主要是原始语法格式转化为RDF(S),最后进行语义转换。该方式是叙词表转化本体最基本的方法,可将任意形式的叙词表转换为本体,不需要提前构建本体模型,具有较强的实用性和通用性。在运用到不同领域进行叙词表转换时,可进行适应性的改进。
c.陈立华通过研究总结出了基于OWL的网络叙词表转换方法步骤。首先在准备阶段需要对叙词表进行分析;其次确定类和属性,建立类间关系层次结构;接着建立语法和语义关系参照表;最后使用OWL进行标准化表示和描述。使用此方法构建的本体具有更好的推理能力,更易更新和维护。该方法是在米佳所提方法基础上的进一步优化改进,适用于网络环境下的叙词表转换,具有较强的实用性。
d.纪姗姗等针对不同类型的叙词表,总结出了一个叙词表转换为本体的通用方法。该方法主要包括四个过程:叙词表分析、叙词表转换、语义丰富及本体校验。在叙词表转换过程中有TBox、ABox、扩展(Population)三种转换方式可供选择,以适应不同类型的叙词表。该方法的特色之处在于提供了本体校验,可通过编写检测算法对转换的本体进行一致性和准确性检验,以降低人为出错率。
目前,我国叙词表有130多种,其中大多数尚未转化为本体,在叙词表转换研究方面仍有大量工作要做。以叙词表为基础构建领域本体,不仅能充分利用资源,使叙词表在语义网络中得到新发展,同时可以降低本体构建成本,节省大量的时间精力。因此,叙词表的本体化构建将是本体研究的重要方向。在叙词表转换本体研究中,应深入研究语义丰富技术及语义关系的细分规则,以促进叙词表转化技术的发展,丰富本体构建理论。
六、本体评价方法
随着本体研究的深入,各领域本体数量不断增多,这些本体在可靠性、准确性、科学性等方面存在较大差异。因此,本体评价作为改善本体质量的手段日益受各领域专家学者的重视。通过研究相关文献发现,主要有以下几种本体评价方法:
(一)用户评价法
用户评价法让用户通过投票来评价本体的优劣,但这种方法很大程度上取决于用户的主观意识,不能全面客观的对本体进行评价,因此没有得到推广使用。
(二)应用评价法
应用评价法是将本体使用到某个特定的应用或任务中,通过应用结果的优劣来评价本体,这种方法能够较为直观的评价所构建本体的质量。然而这种评价方法具有一定的局限性,在某些情况下,本体应用结果的优劣难以客观评判,应用此方法对本体的评价也不尽准确。
(三)语料库评价法
语料库评价法是通过测试本体与相关领域语料库的匹配程度来对本体进行评价。但这种方法是从领域覆盖度的角度评价本体,不能对本体进行综合全面的评价。
(四)专家评价法
专家评价法利用相关领域专家的专业知识对本体的质量进行评价。该方法主要用于本体学习评价,难以重复使用,无法进行大规模的本体评价,并且评价结果受限于专家的知识水平,评价结果不具有可比性。
(五)复合指标评价法
复合指标评价法是依据一定的原则标准来建立本体评价指标体系,然后对各个指标进行评价打分,并结合每个指标的权重计算最终的评价结果。该方法开放性、全面性较强,可通过指标体系进行全面评价,是最为常用的本体评价方法。但该方法的评价结果过于依赖指标体系,各个指标的科学性和指标体系的完善程度将会直接影响到评价的结果。因此,在使用该方法时筛选的指标要具有代表性,指标体系要合理完善,指标权重要适当。
(六)黄金标准评价法
黄金标准评价法将所构建的本体与领域内公认较为成熟的“黄金标准”本体进行比较,利用比较结果对所构建的本体进行评价。这种方法缺陷在于难以评估作为“黄金标准”本体的质量,并且在对比评价过程中需要高水准的领域专家参与。
总的来说,这6种本体评价方法都有其可行性和适用性,但方法本身的局限性较大,跨领域的通用性较差,难以广泛使用。目前,基于指标体系的评价方法是最为常用的。所以,在本体评价中,可以通过建立科学完善的指标体系对本体质量进行量化评价,再利用专家评价法等方法进行辅助评价,这使得对本体的质量评估会更加客观、全面。
七、本体的应用
随着本体理论和技术研究的深入,本体被应用于很多领域,在这些领域发挥着重要作用。由于本体的应用十分广泛,受篇幅限制,实难一一列举,本文从以下几个方面进行阐述。
(一)在信息检索中的应用
由于本体具有较好的概念层次结构和逻辑推理能力,所以在信息检索领域应用比较广泛。本体在信息检索中的应用主要集中在两个环节:一是利用本体进行文档预处理;二是提高信息检索的准确率。
(二)在语义Web中的应用
本体作为具有共同标准的概念体系,支持逻辑推理,促进计算机相互理解和互操作,可有效提升语义Web的性能,提供更加智能化的语义Web服务。本体在语义Web中的应用研究主要集中在提高对模糊信息的语言描述能力,促进半自动化和自动化本体生成和本体演进。
(三)在异构数据集成与融合中的应用
分布式的网络环境下,海量数据信息存储于不同的系统、数据库中,造成了数据的冗余和异构问题。而本体作为共享概念模型的明确的形式化规范说明,可以有效解决异构数据的集成和融合问题。
(四) 在其他学科领域的应用
除了上述领域,本体也广泛应用于医药、教育、电子商务、农业、军事、旅游、地理信息、法律、生物等领域。在这些专业领域中,多数是通过构建领域本体,实现领域知识的融合和知识信息共享。
八、问题与展望
总体来讲,目前本体研究和应用还处于低水平发展阶段。虽然关于本体的研究日益增多,但还存在诸多问题,仍需要集各专家学者之智慧,进一步深入研究。
a.本体定义。关于本体的定义,学术界众说纷纭,尚未形成统一标准的定义。其中Gruber给出的本体定义最为经典,Studer等人的本体定义被引用最多,但该定义仍不能概括本体的全貌。因此,关于本体定义的研究应进一步深入,对本体进行全面概括,统一学术界关于本体的定义,以丰富本体理论,为后续研究提供参考。
b.本体构建。与本体构建的相关研究很多,但还没有形成成熟的构建方法体系。构建本体需要手工操作,本体构建方法和构建工具难以匹配,本体构建不能大规模进行,难以满足语义网环境下的需求。但随着机器自动化构建技术的逐渐成熟,自动化或半自动化的规模构建本体方法必将取代手工操作。因此,适用于语义网环境的本体自动化构建方法和工具的研究应该是后续研究和应用的主要方向之一。
现在常用的本体构建工具中,只有Protege支持中文输入,可以构建中文本体,但在中文推理机制方面却表现不佳。而其他构建工具基本上都不支持中文,这给中文本体构建带来了很大的困难,严重阻碍了国内本体研究的发展。因此,研发支持中文且具有强大中文推理能力的构建工具将是今后本体研究中的一个重要任务。
c.本体评价。本体评价对本体质量评估非常重要,但目前针对本体评价问题缺乏全面、系统、深入的研究,没有成熟统一的评价标准和评价工具,缺乏本体评价方法理论体系,本体评价的实证研究也相对较少。因此,对于本体评价方法和评价标准仍需进一步研究。并且随着语义网的发展,基于描述逻辑构建的本体评价方法也值得深入研究。
d.本体集成。目前,本体集成方法和本体集成工具都不是很成熟。本体的集成多是半自动化的,映射和合并的准确率不能保证,难以实现大规模的本体集成。此外,目前的本体映射方法和合并方法多是针对一对一的情况,无法进行一对多或多对多的本体映射,这使得大量本体的集成和融合变得困难。因此,在本体集成研究中,要找出高效的本体集成方法,开发相应的本体集成工具,从而提高本体的集成效率,以支持大规模的本体开发。
e.本体自动学习。本体学习是基于统计和机器学习等技术自动地或半自动从已有资源中获取目标本体的技术。随着本体技术的不断发展,领域本体构建的需求将会越来越大,本体自动学习技术会大大提高知识获取的质量和效率。然而,目前国内外在此方面的研究仍处于起步阶段,本体学习仍是处于半自动状态。因此,本体自动学习将是下一步本体研究中的一个重要方向。