尚硅谷的ShardingShphere分库分表课程总结
课程来源:尚硅谷ShardingSphere5实战教程(快速入门掌握核心)_哔哩哔哩_bilibili
高性能架构模式
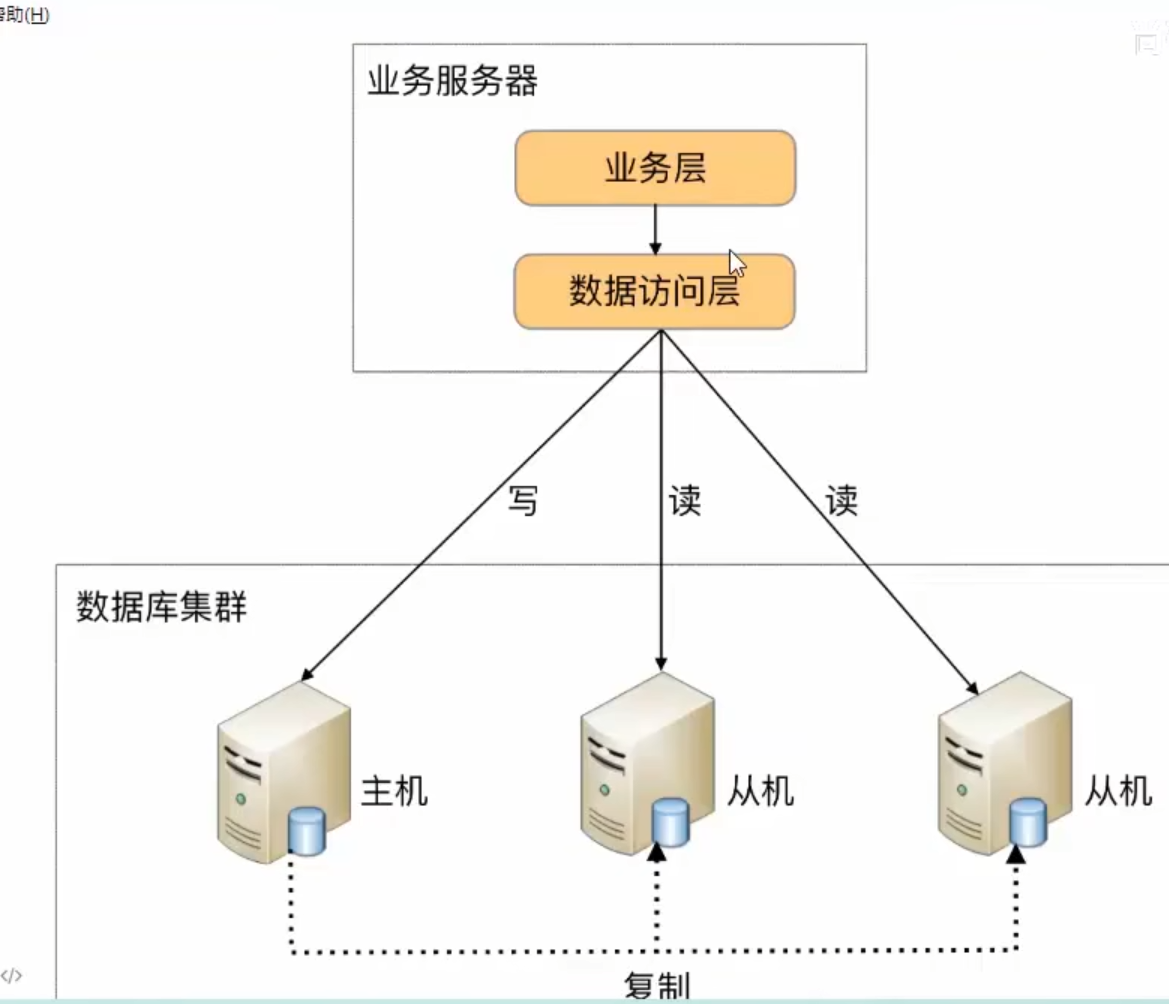
读写分离
主库写从库读
CAP定理

一致性
可用性
分区容错性
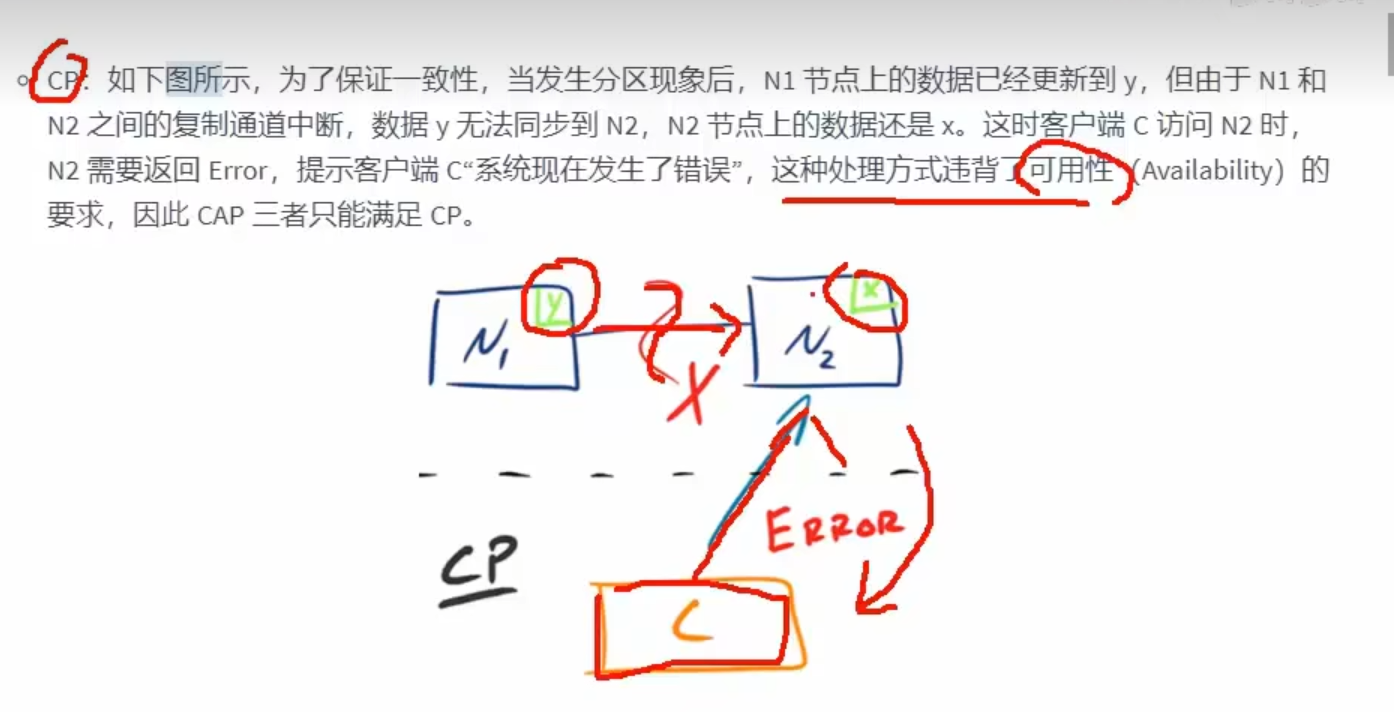
CP
数据一致我们才返回
保证一致性,牺牲可用性
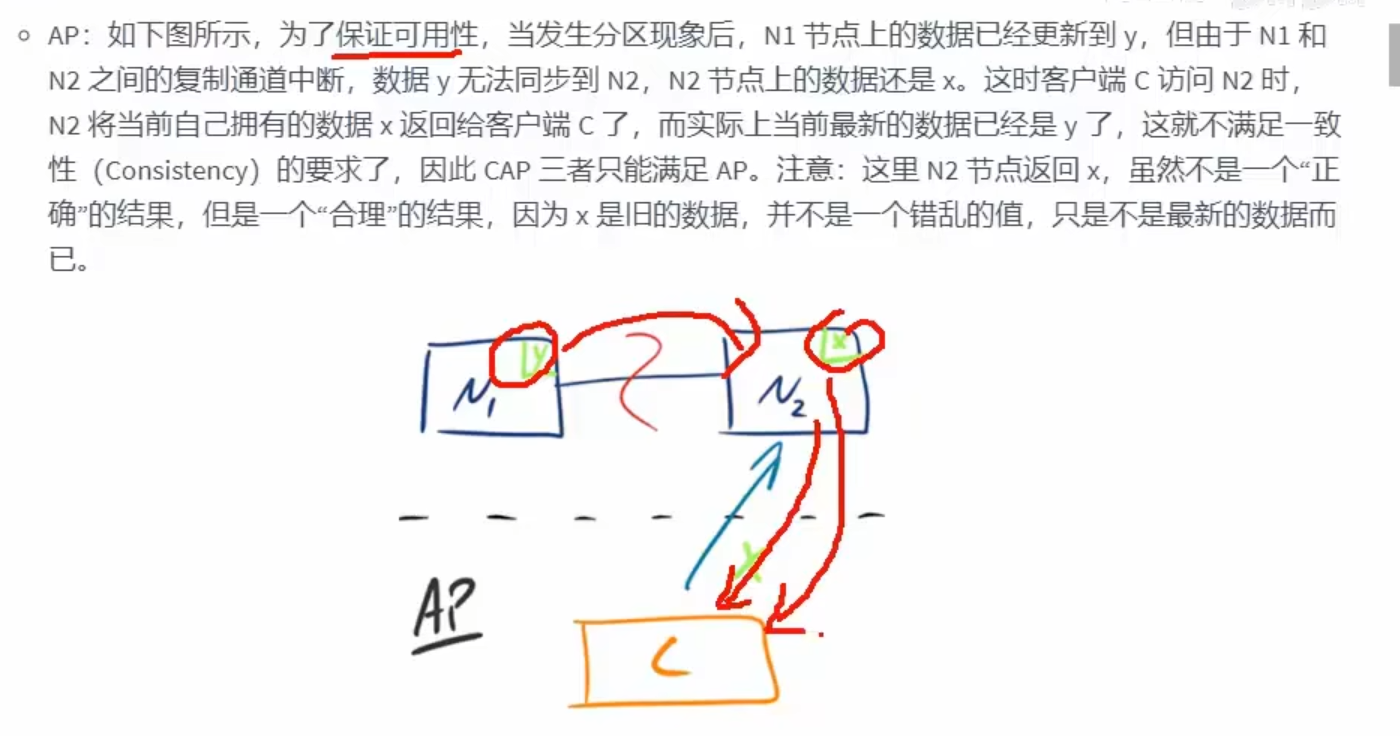
AP
保证可用性,牺牲一致性
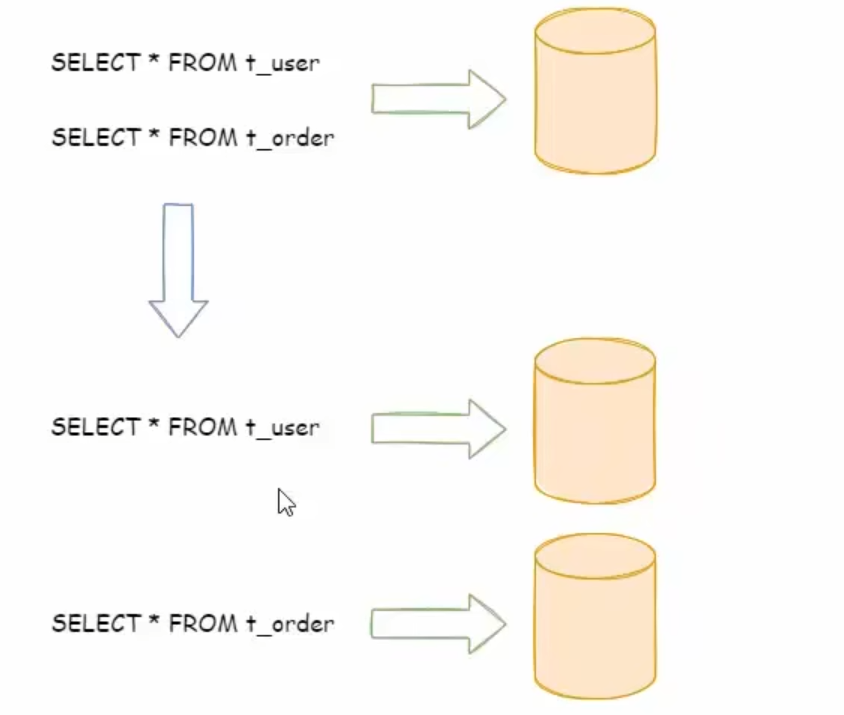
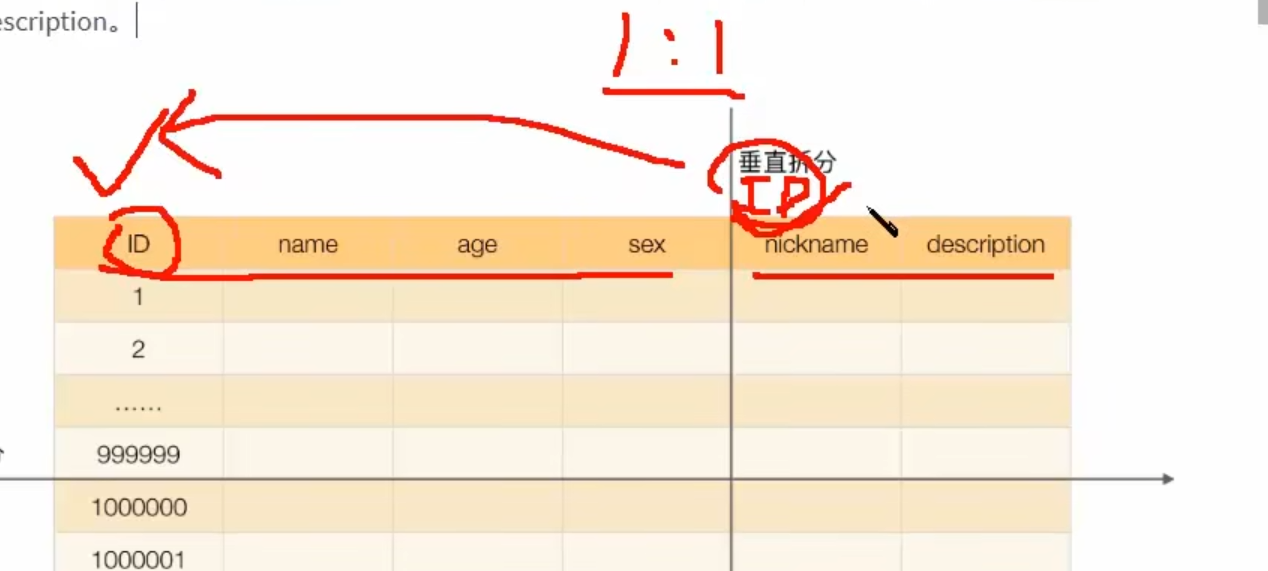
垂直分片之垂直分库
读写分离存在缺陷,没法分散数据库的存储压力
为了减轻存储压力,所以我们还要把数据库分布到多台服务器上
所以我们来做分片
分片的手段是 分库和分表
分片分为 垂直分片和水平分片

垂直分片之垂直分表
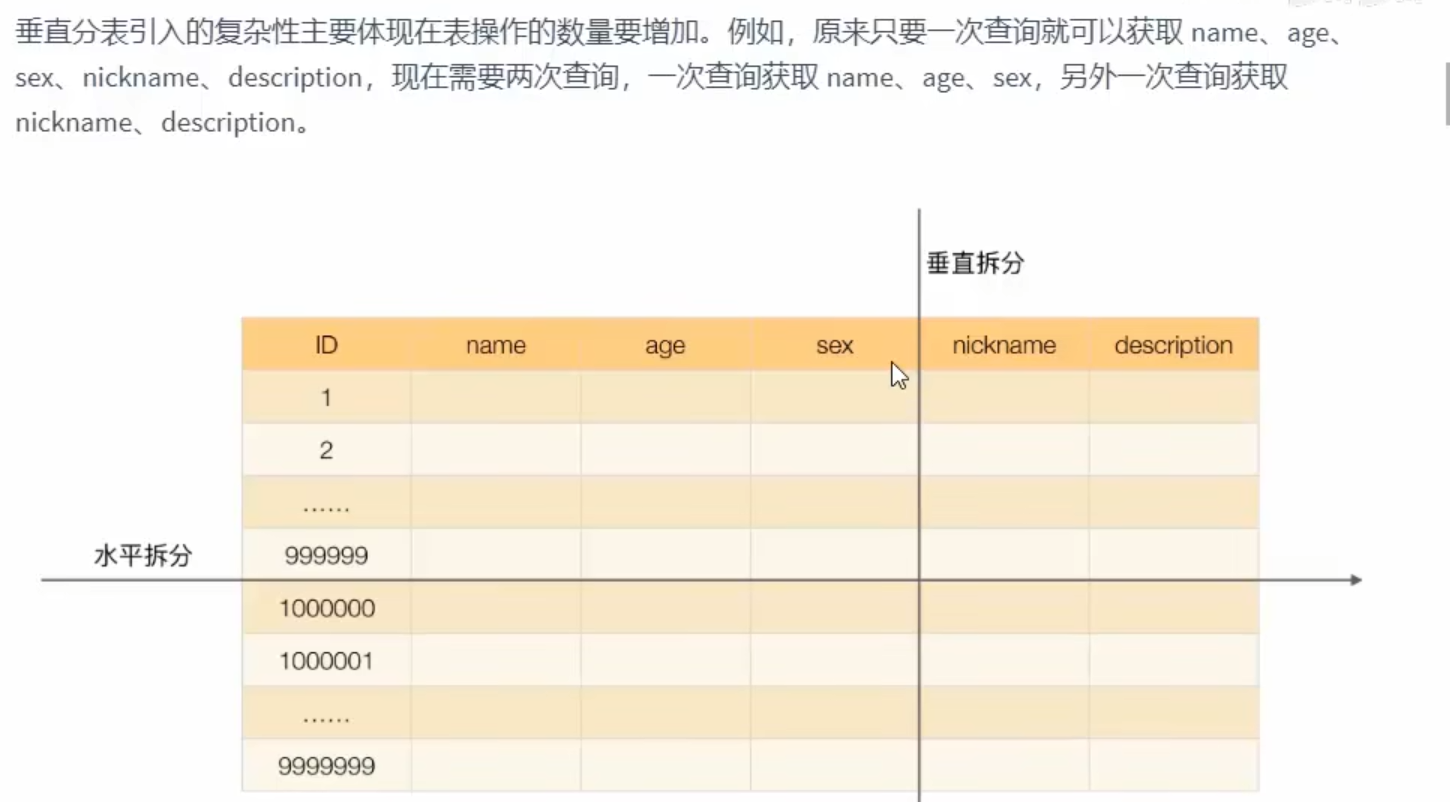
如果有主键策略,那么这两个表分开之后,主键策略是一致的
水平分片
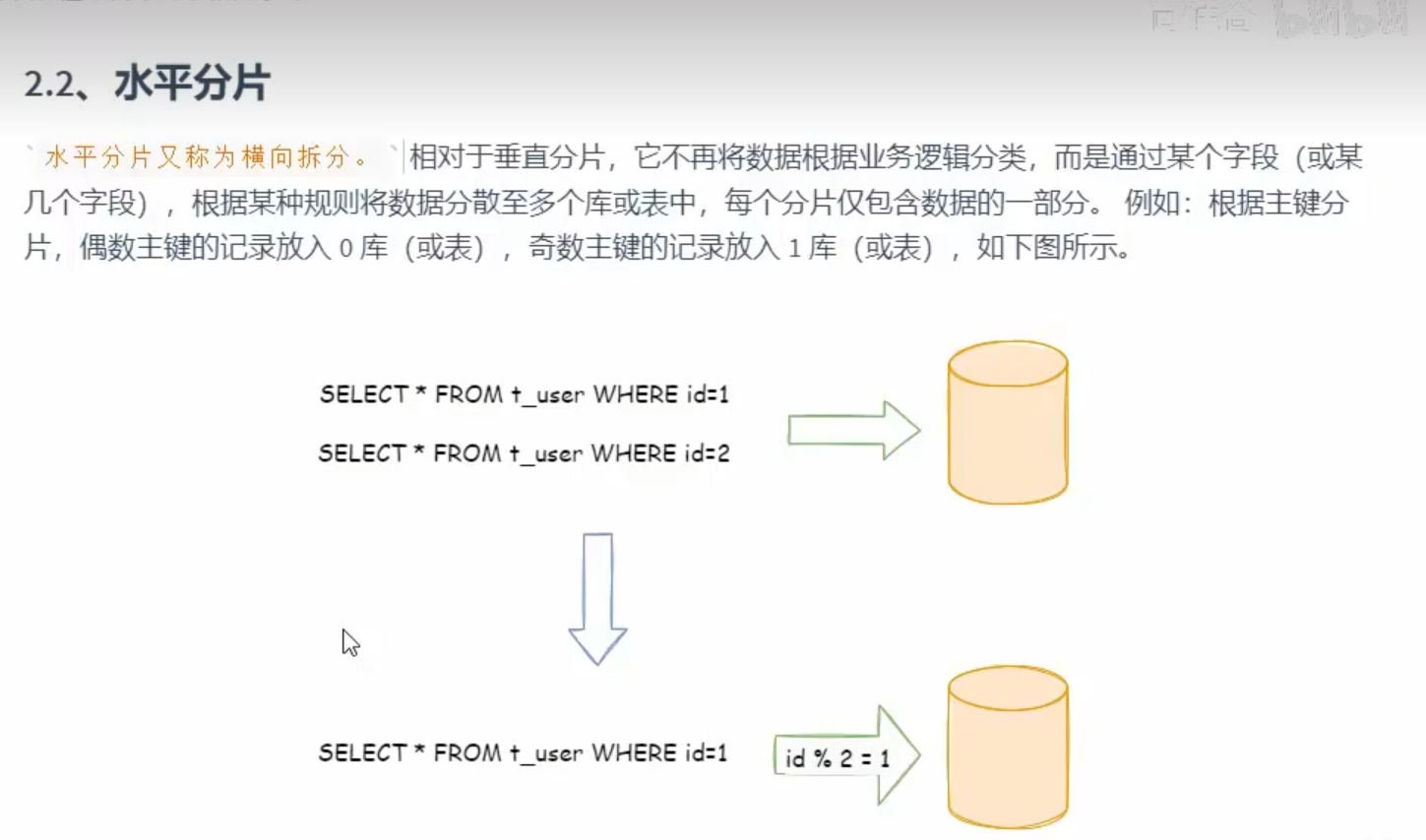
我们会进行取模的操作
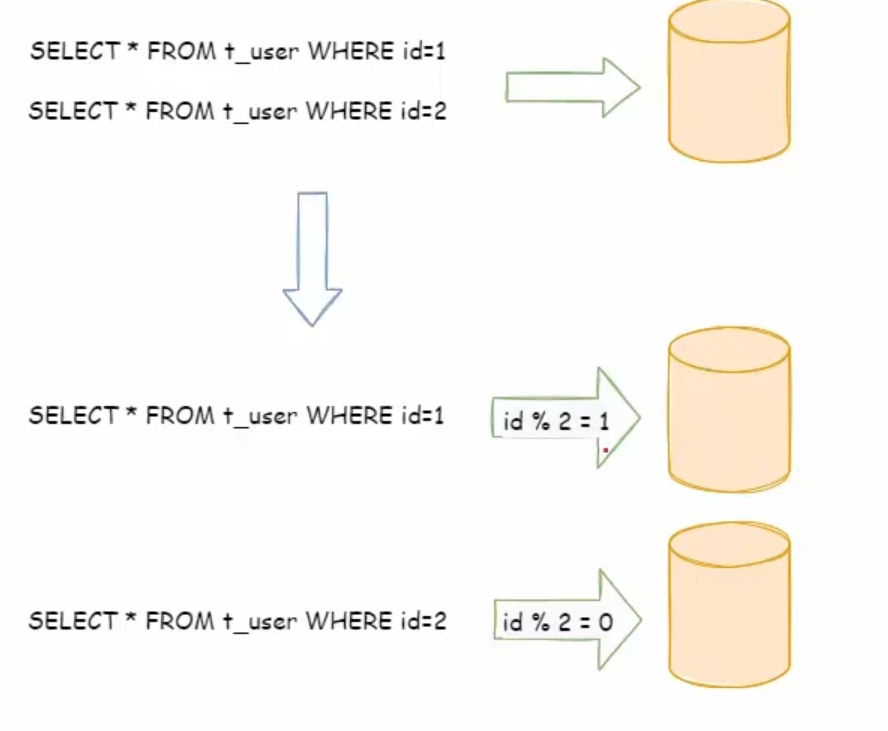
水平分表和水平分库

读写分离和数据分片
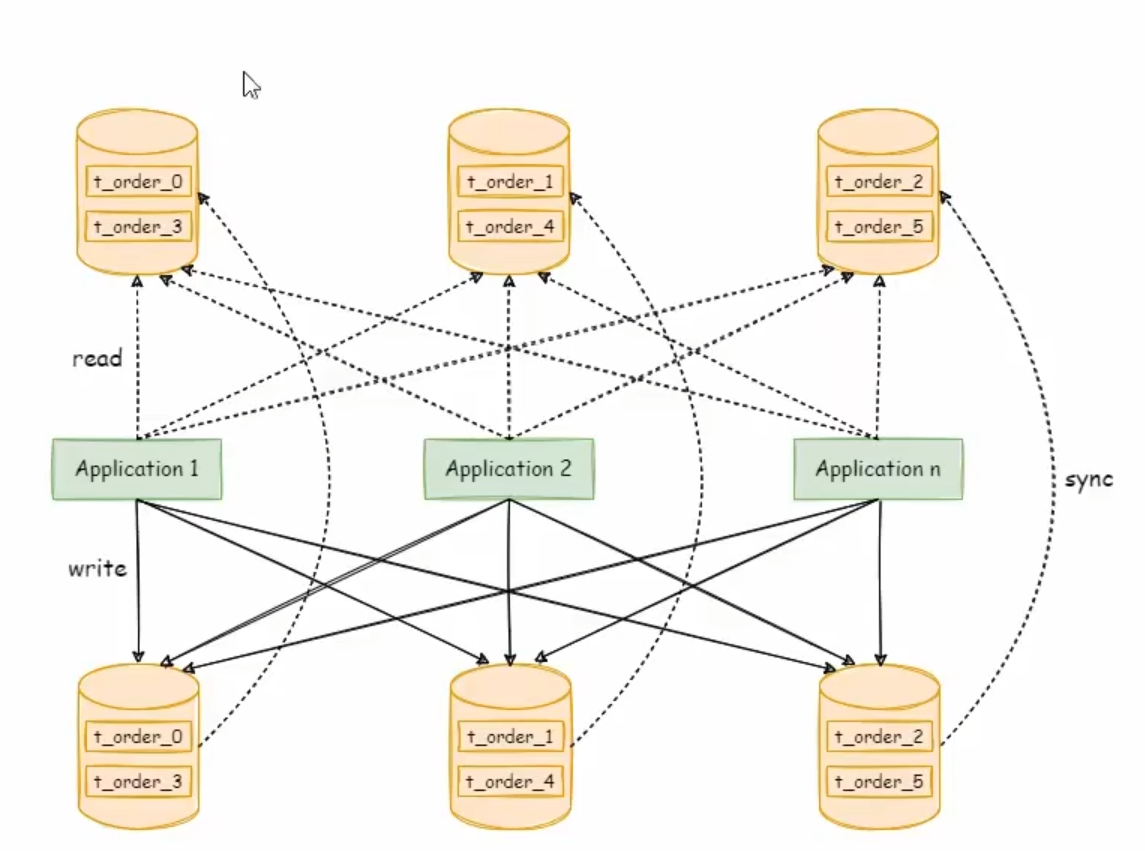
实现方式
程序代码封装
‘
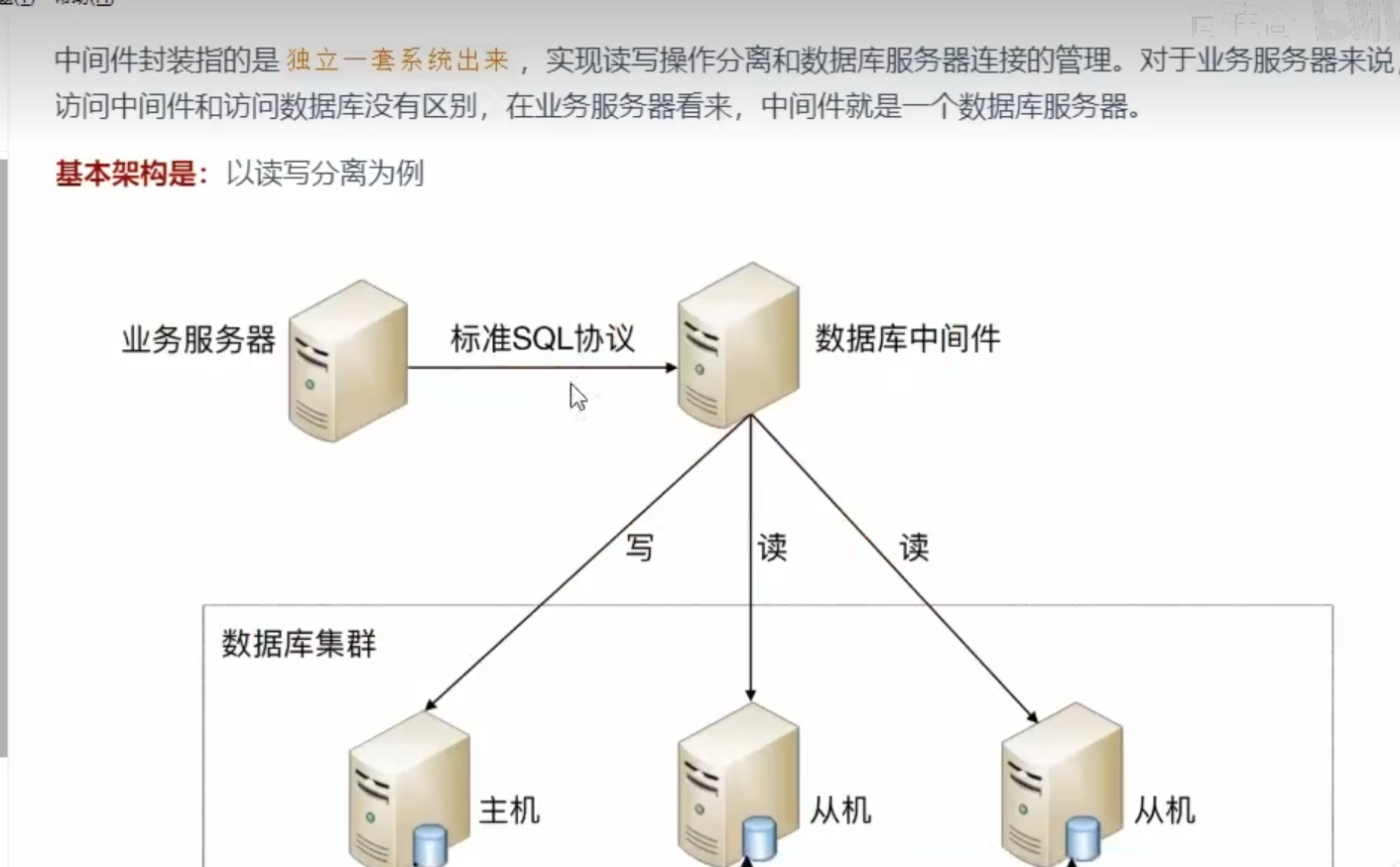
中间件封装
常用解决方案
ShardingSphere和Mycat

简单介绍ShardingSphere
Apache ShardingSphere
这个是官网
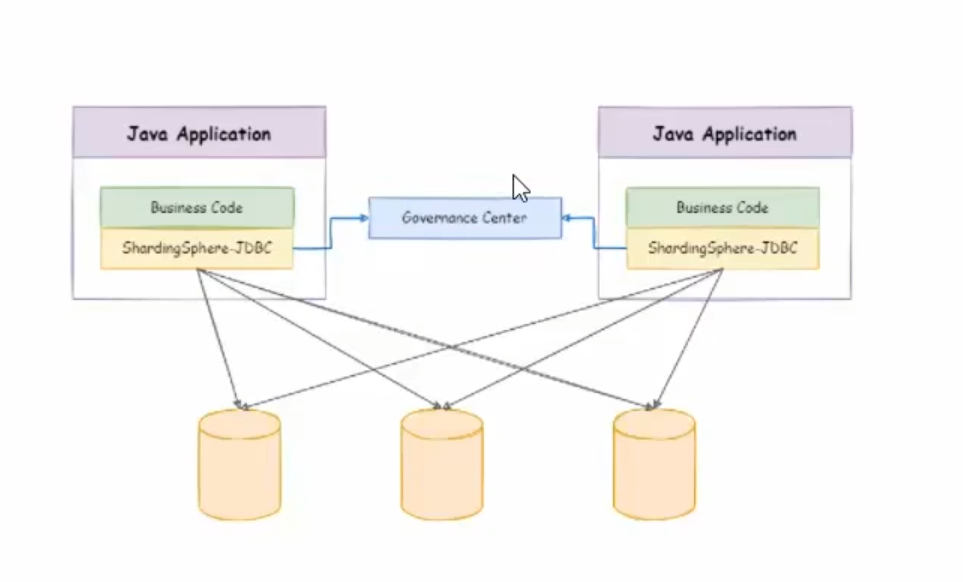
shardingsphere-jdbc
中间的那个组件,我们可以使用zookeeper
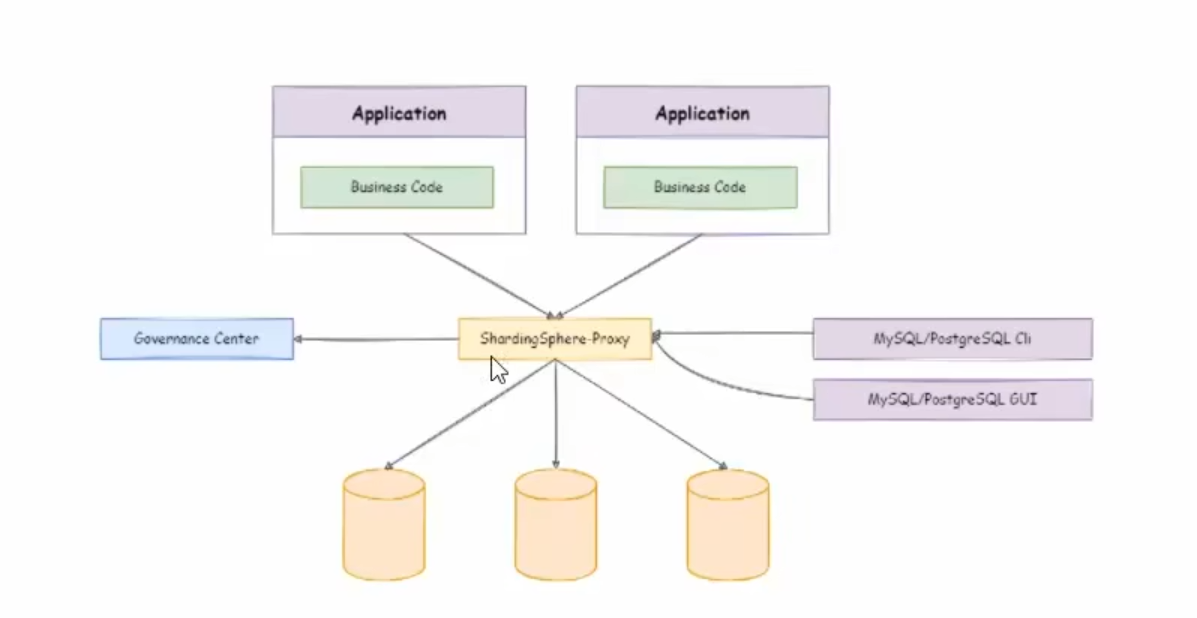
shardingsphere-proxy
MYSQL主从同步
启动主服务器
我们跟着文档来就行了
准备主服务器和创建Mysql配置文件
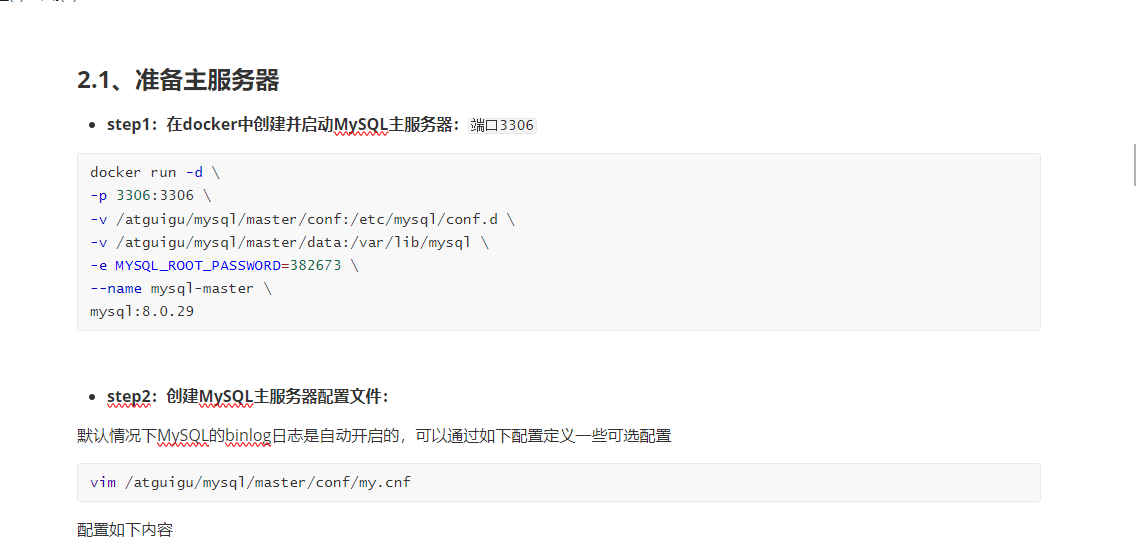
配置完之后然后重启
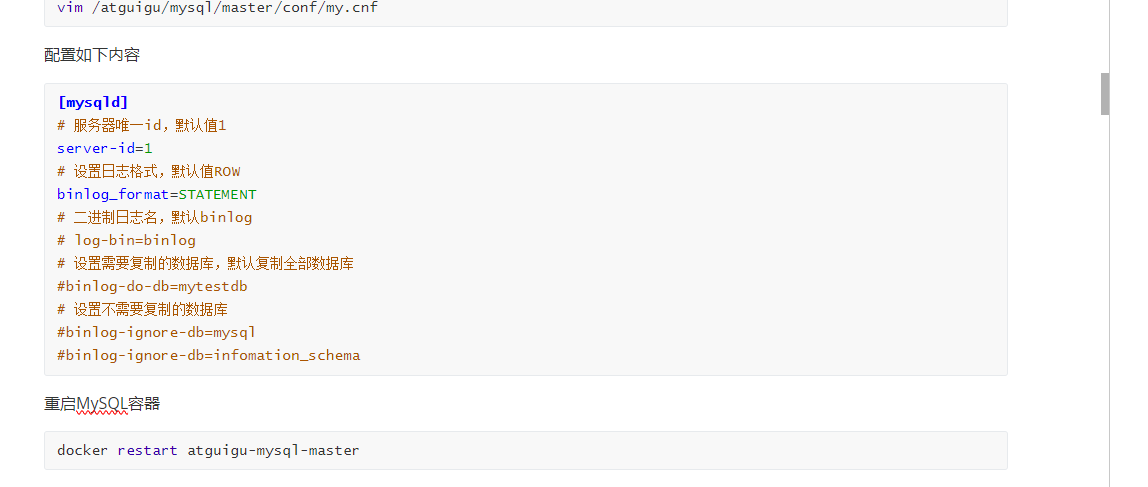
进入容器内部,修改默认密码校验方式
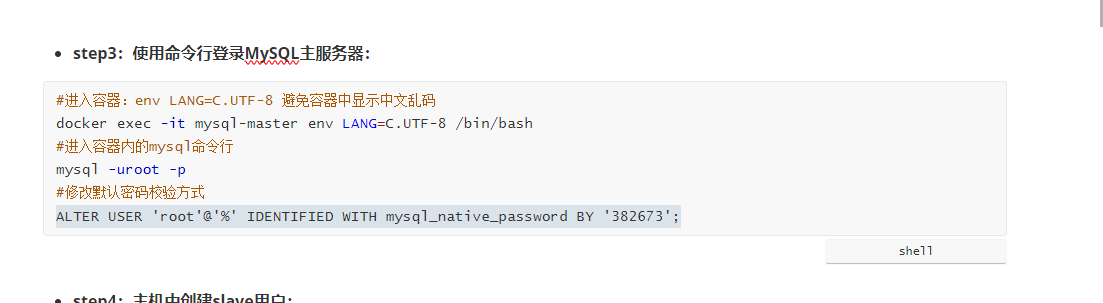
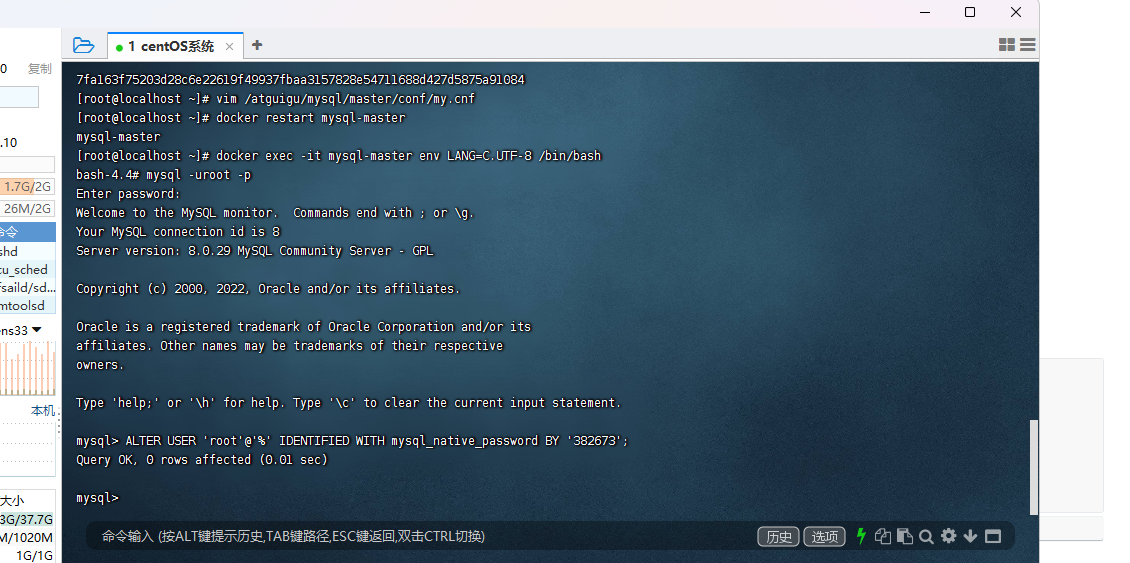
设置主服务器
创建slave用户
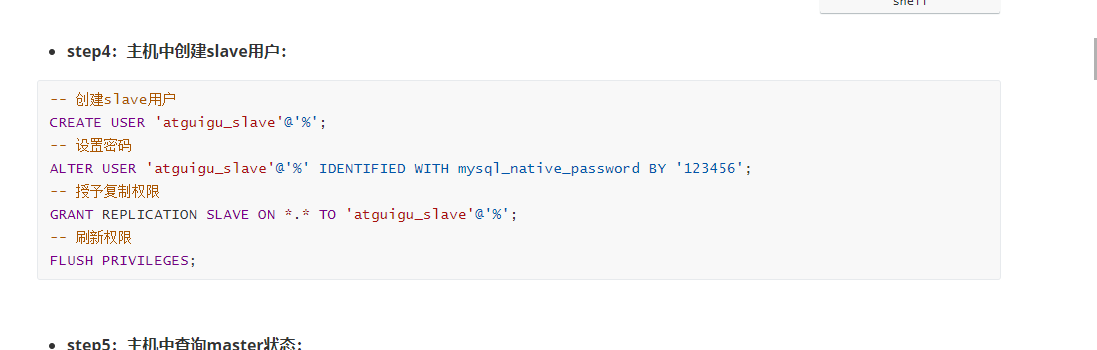
设置密码
授予复制权限
刷新权限
牛魔的,这两个root的权限是不同的

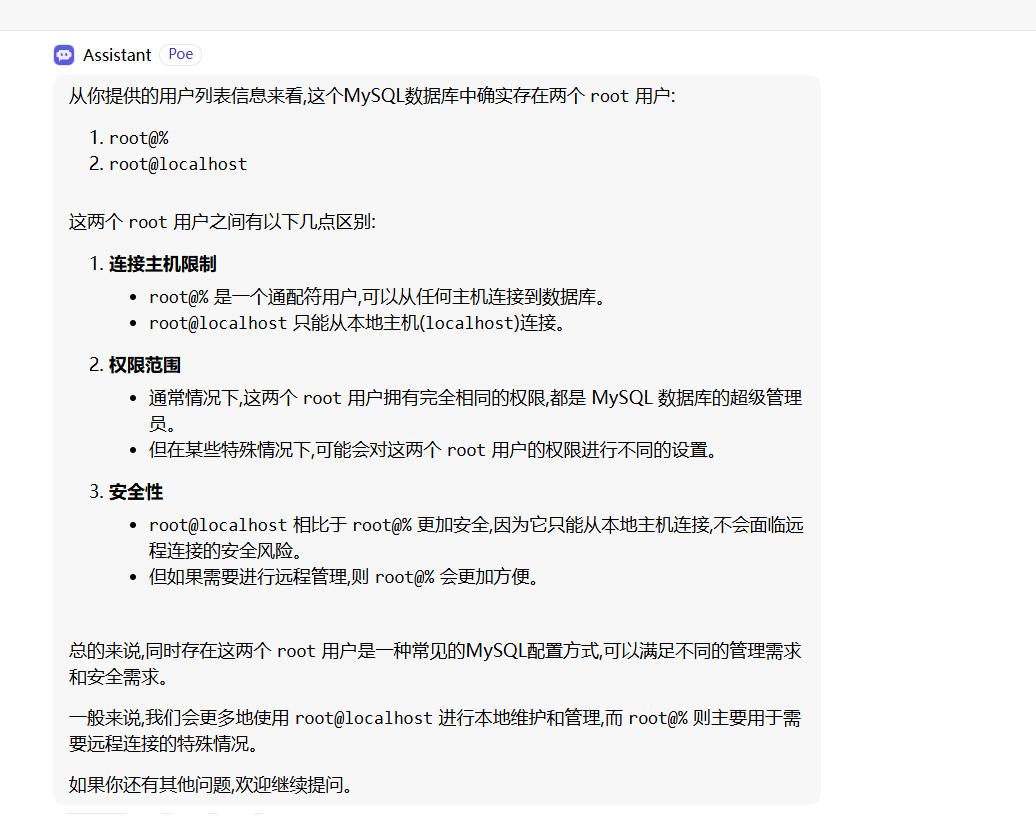
我换到root%,就有了授权的权限,但是如果我是那个localhost的root,我就没有权限
我不知道这是什么问题,只是储备太少了
但现在授权成功了
我们也可以远程连的时候,直接在表里面创建我们的用户
查看我们的mysql主机的状态
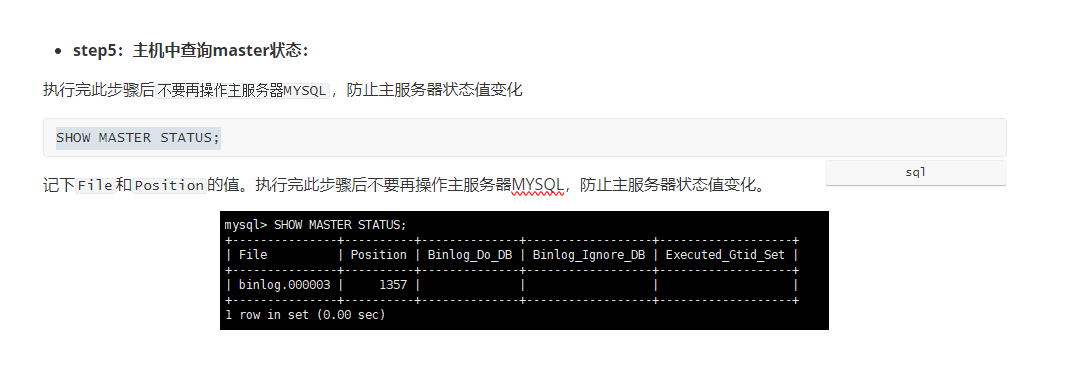
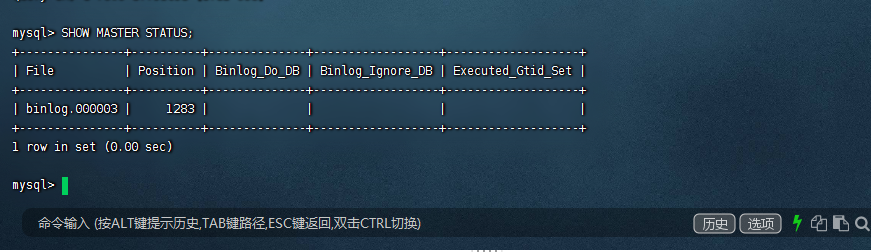
我们的从服务器要向主服务器,去读取我们的binlog日志
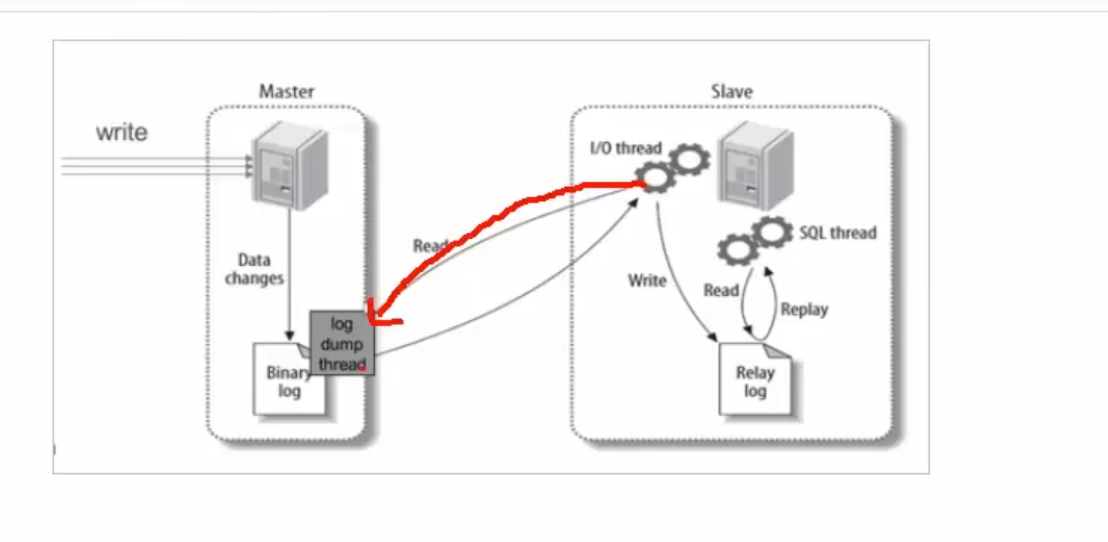
所以我们的这个要配置到我们的从服务器当中

安装启动从服务器
和之前一样,对着文档操作
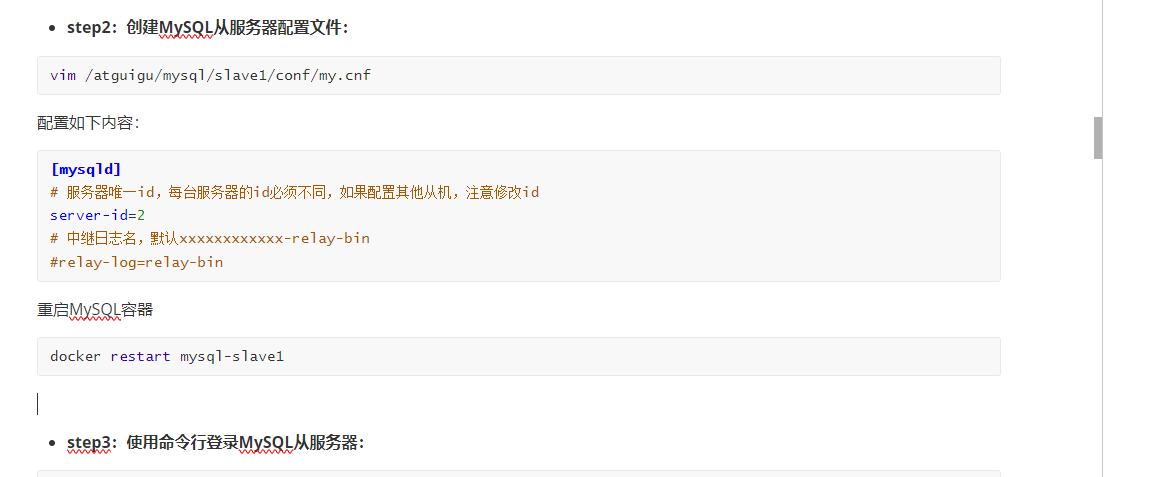
server-id
每台服务器的ID必须不同
配置服务器的主从关系
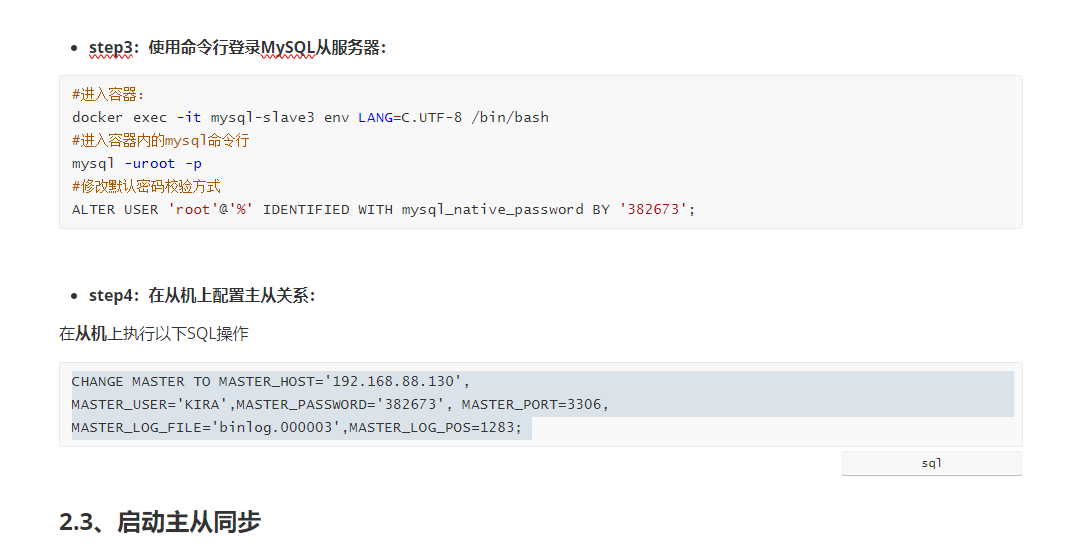
妈的这种配置给我搞烦了
而且我好像直接创建了一个新的多级目录里面的文件
然后我就无法成功创建这个文件
可能是一次性创建太多了
启动主从同步
我们现在进入了3个容器的mysql里面
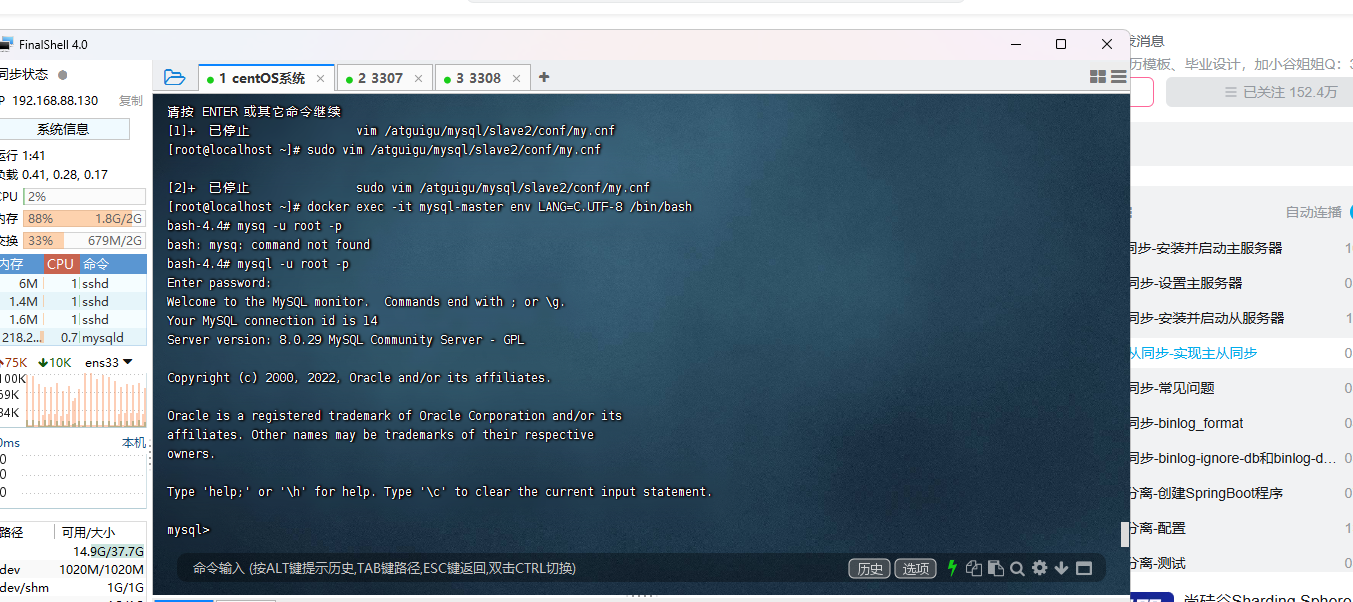
我们这两个是YES,就说明我们的主从启动成功了
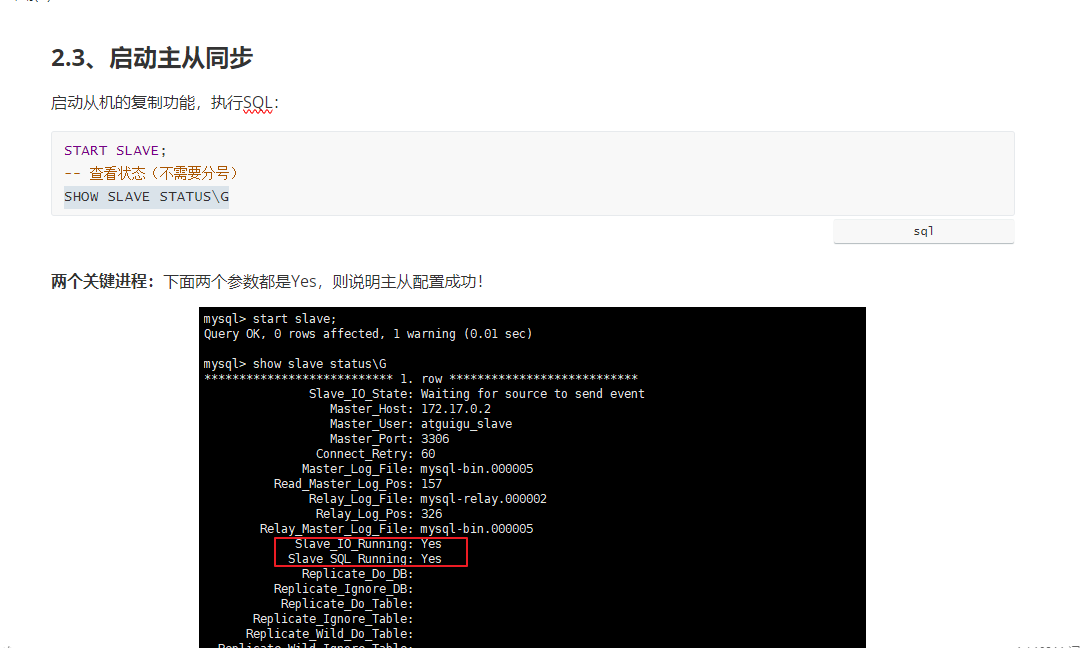
一堆JB配置+错误
牛魔的,主机的position变化了
那我就要重写配置了
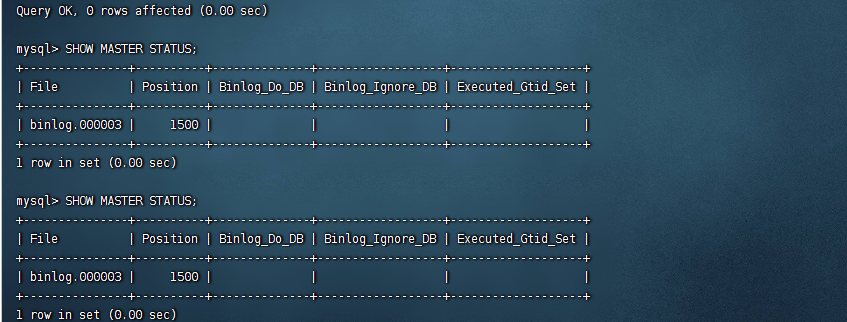
你妈的,还有其他原因导致连接失败
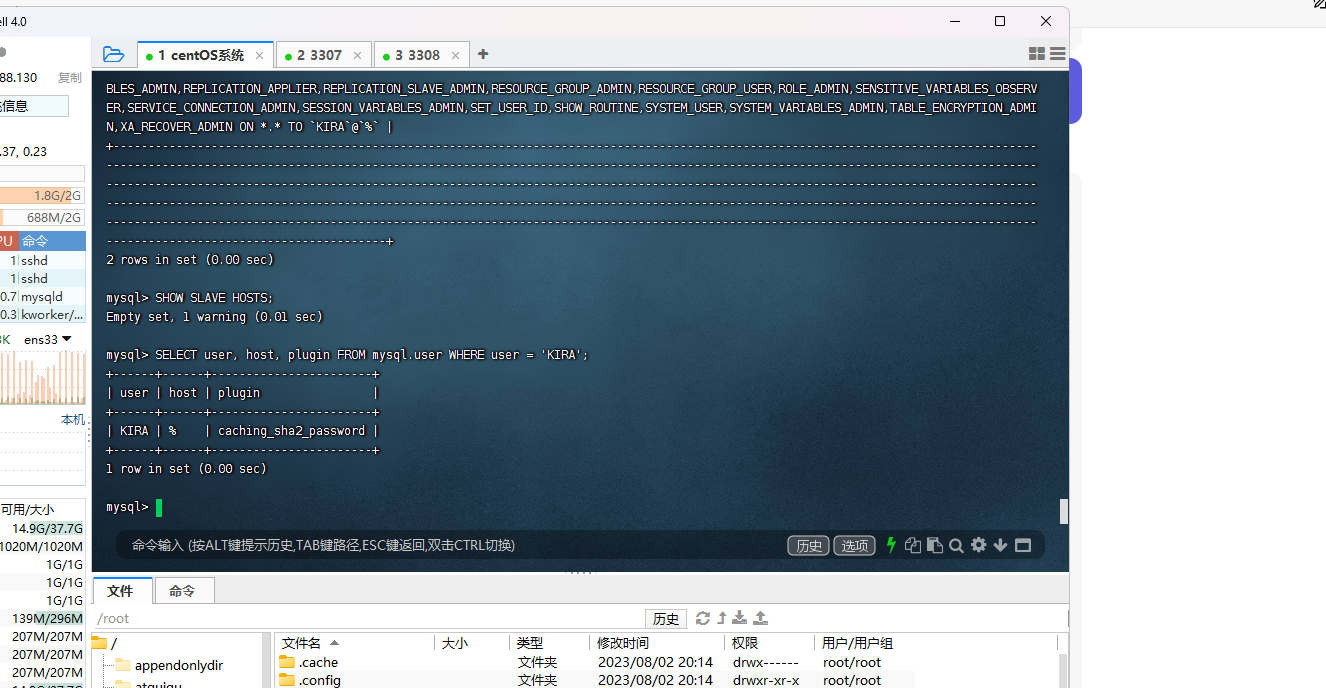
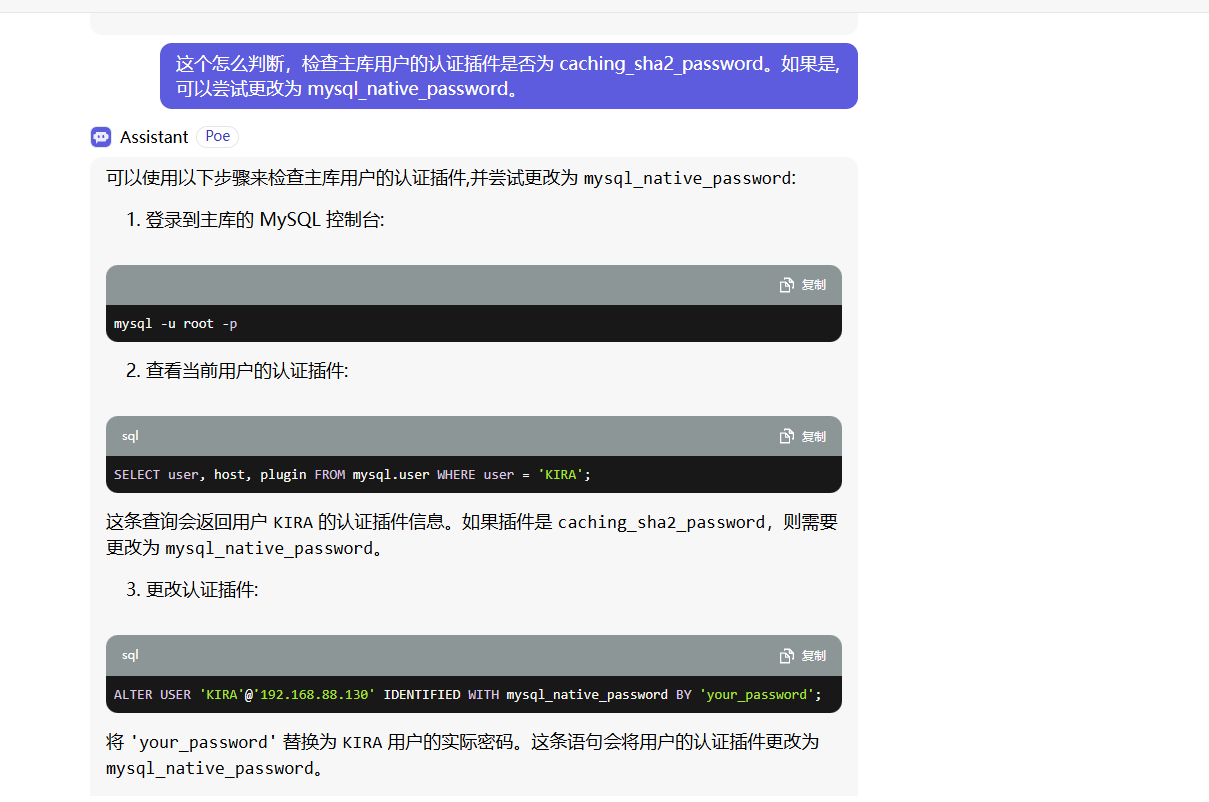
wtf,好讲究啊,主机名如果是任意%而不是192.168.88.130的话我也会错,
所以就是创建用户那几步出了大问题
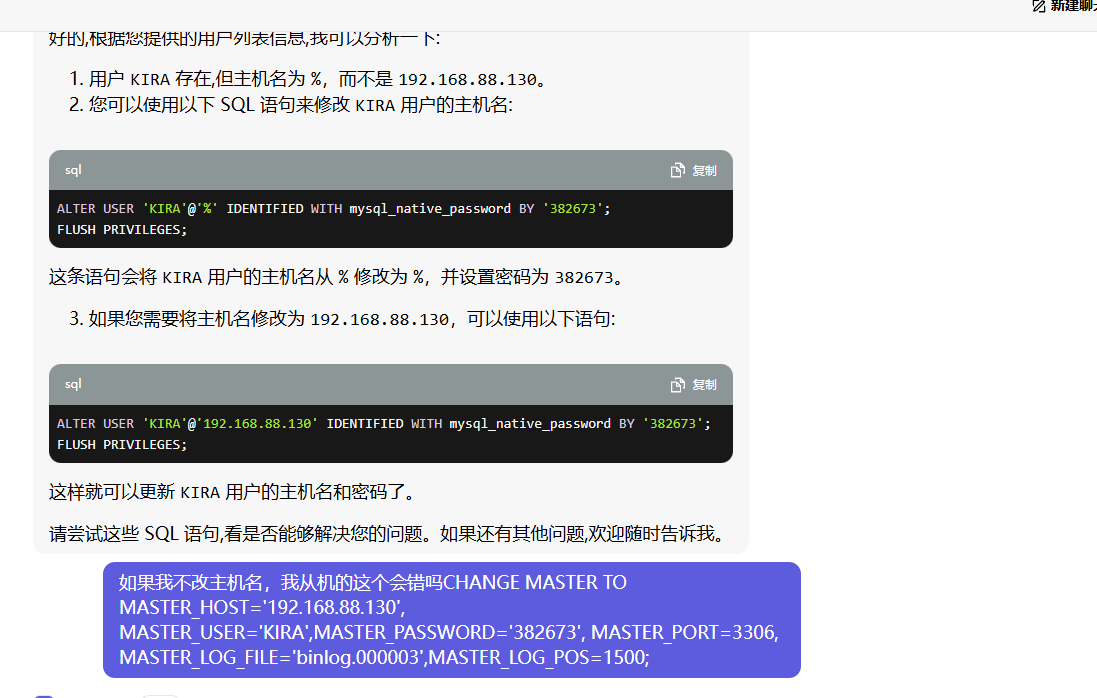
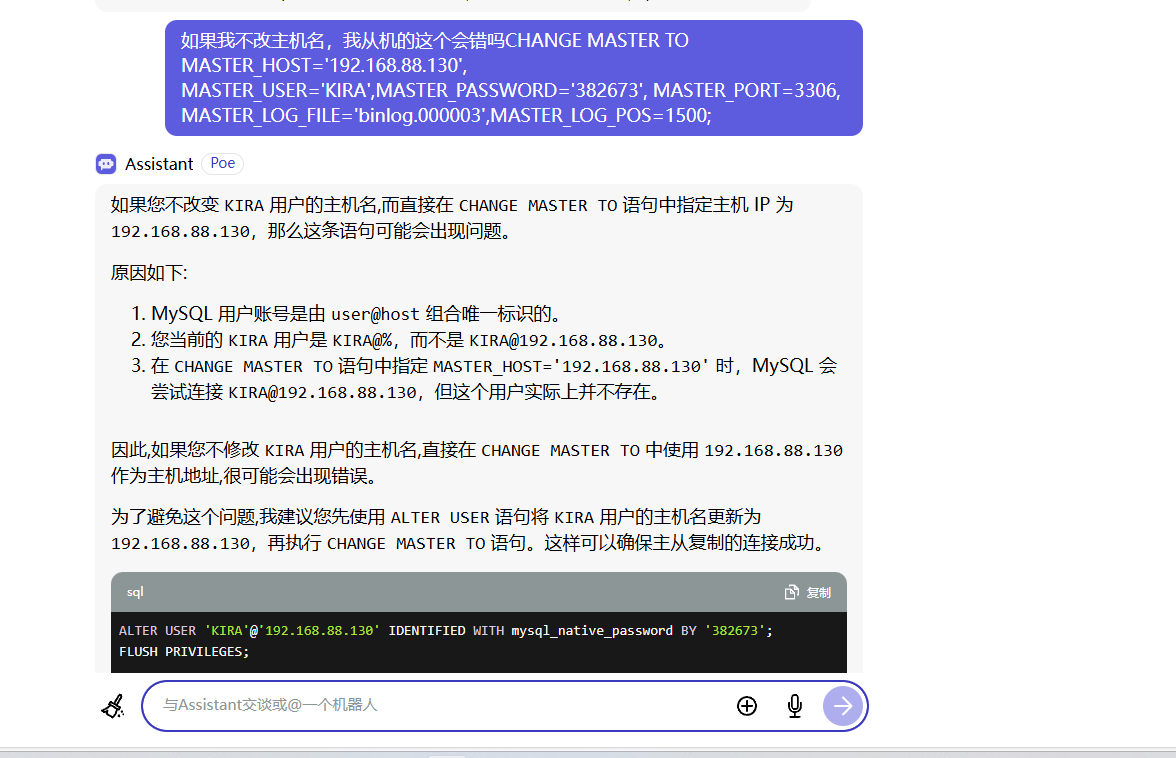
因为我之前的多次错误操作,导致我的主库变成了从库
所以我要让我的主库变回来
可能一开始我的主库是从库所以它一直在复制?我stop slave后,它的position变了?
ok你妈的,我的主库的position又变了,导致我的从库又连不上
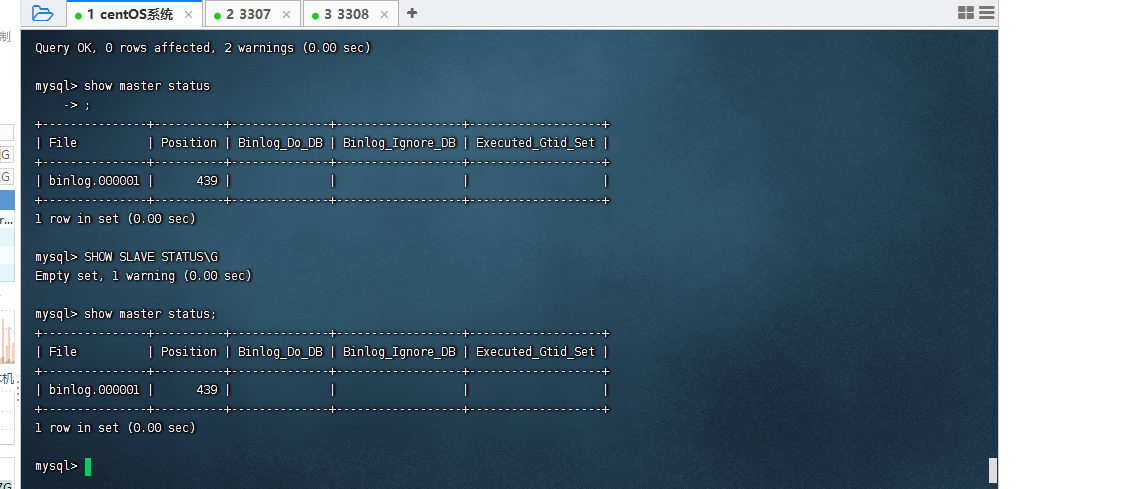
然后这次把从库那些东西全都配好,就弄好了
show slave hosts 我们的两个从库也是成功连接主库了
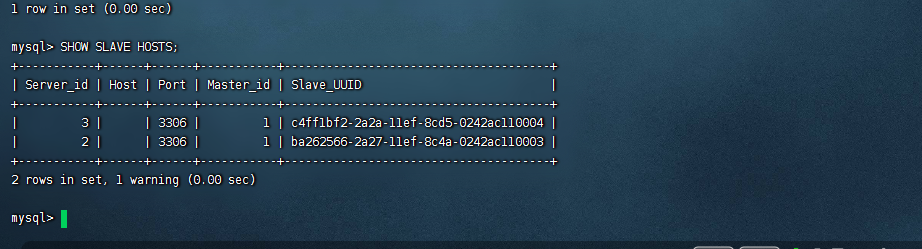
然后我们在主库创建我们的数据库
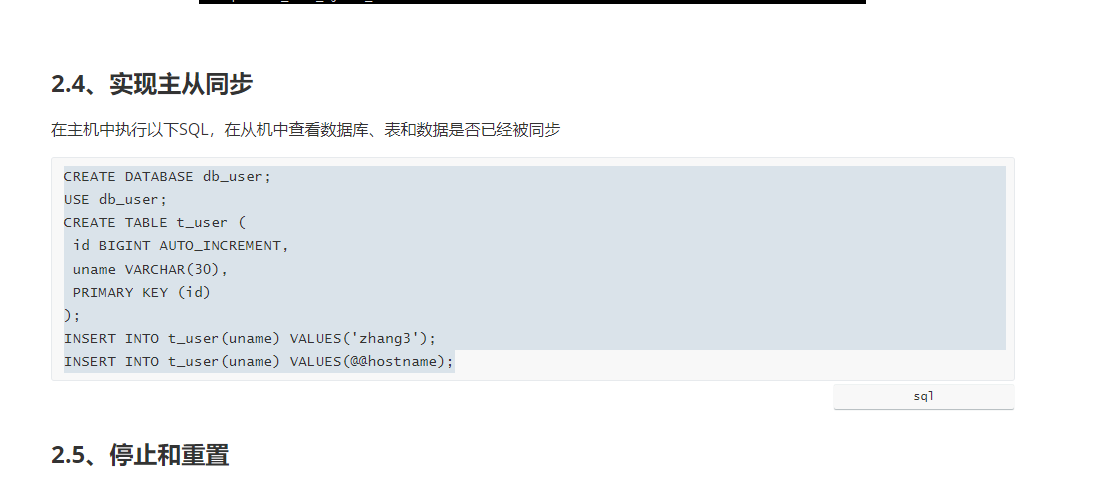
主从同步复制
然后我们的从服务器里面,我们的主服务器创建的数据库也进来了,所以我们主从复制了
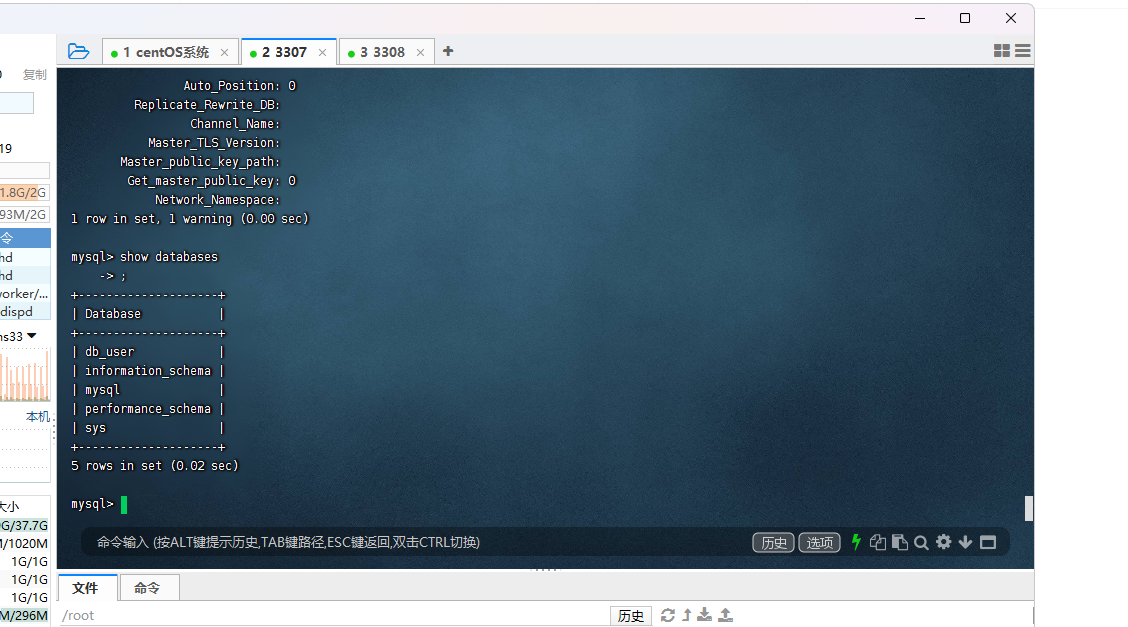
一些slave和master的命令

常见问题
你妈的,我遇到的两个问题是最离谱的
一个是IO_RUNNING在Connection
然后好像是我的主机我把它变成slave了,要变回master才行
还有那个KIRA用户的权限问题,一个是%,一个是192.168.88.130本机
好像不同用户权限也不同
然后就是IO成功了但SQL失败了
然后就停止slave然后重启就行
但是你妈的那个主机的binglog的版本号还有position
随着我弄bug还会变更,弄得我后面又变成了原来的那个
slave指定master错误了
草泥马弄了我3个小时,你妈死了
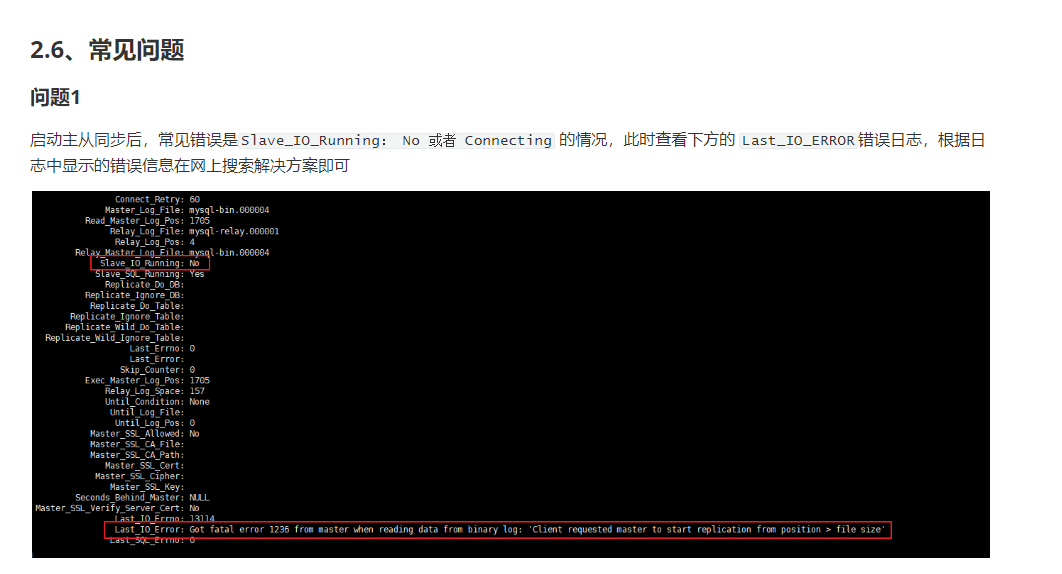
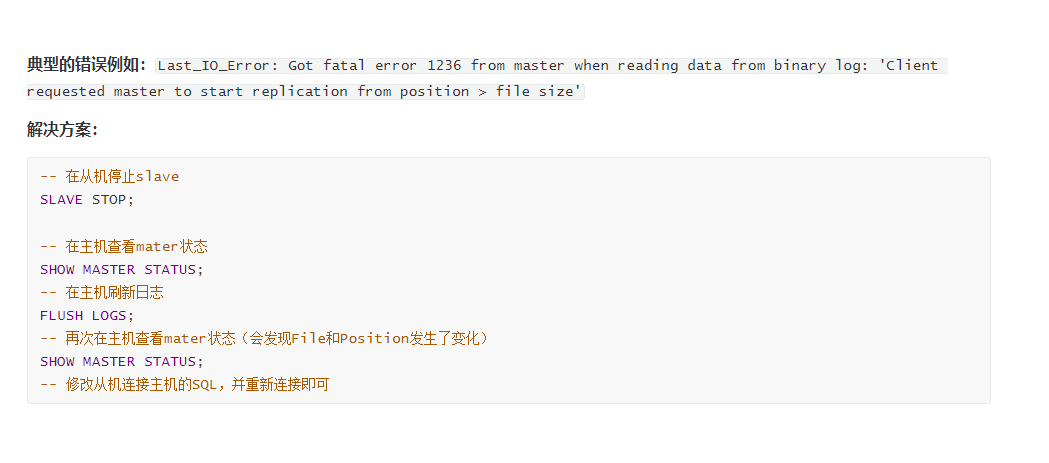
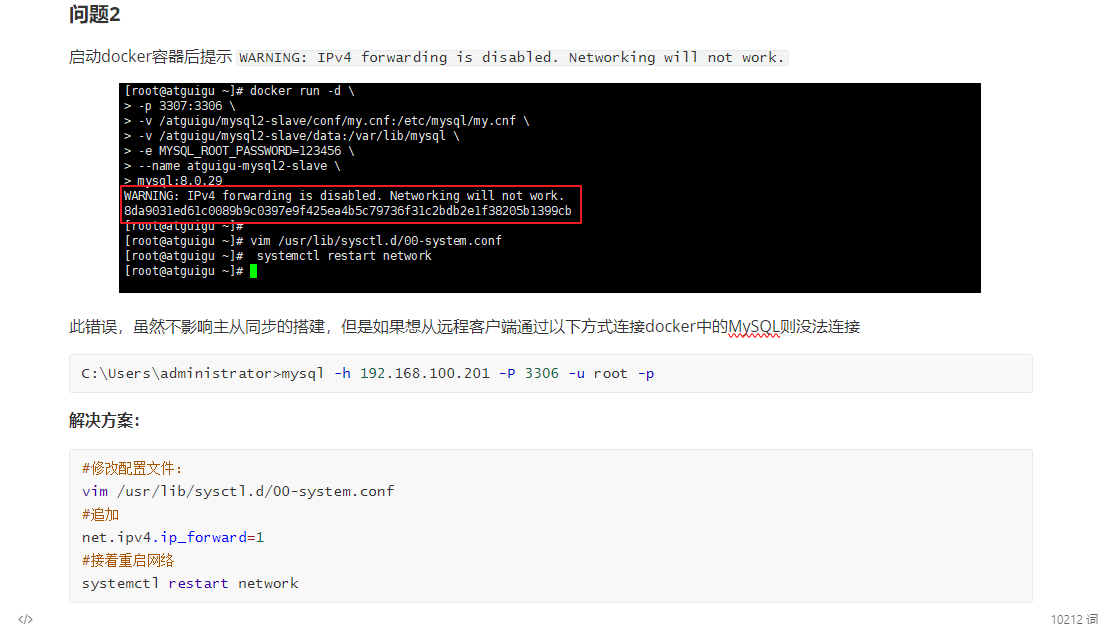
docker启动后我们才关闭防火墙,这个出的问题
binglog_format
这个共有三个值

statement记录的是我们的写指令
row记录的是邂逅的数据 这个每次都要动态计算,所以性能比较差
mixed是上面两种的混合,帮助我们在主从复制的时候,保证数据的绝对一致
binglog-ignore-db和binlog-do-db
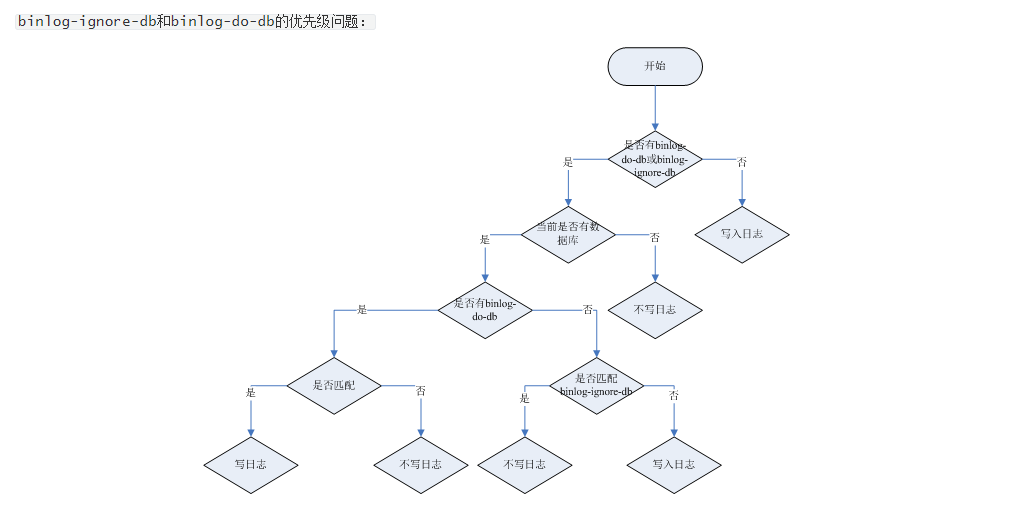
如果我们这两个值没有设置的话,我们的从库复制默认是全复制
我们配置的话,就是有些数据库我们从库写入,有些数据库我们从库没有必要写入
JDBC-读写分离
实体类+mapper
略
这个版本是5.1.1,内存模式以及很多东西在最新版本就没有了
配置
模式
我们看一下我们的官网,我们有三种模式
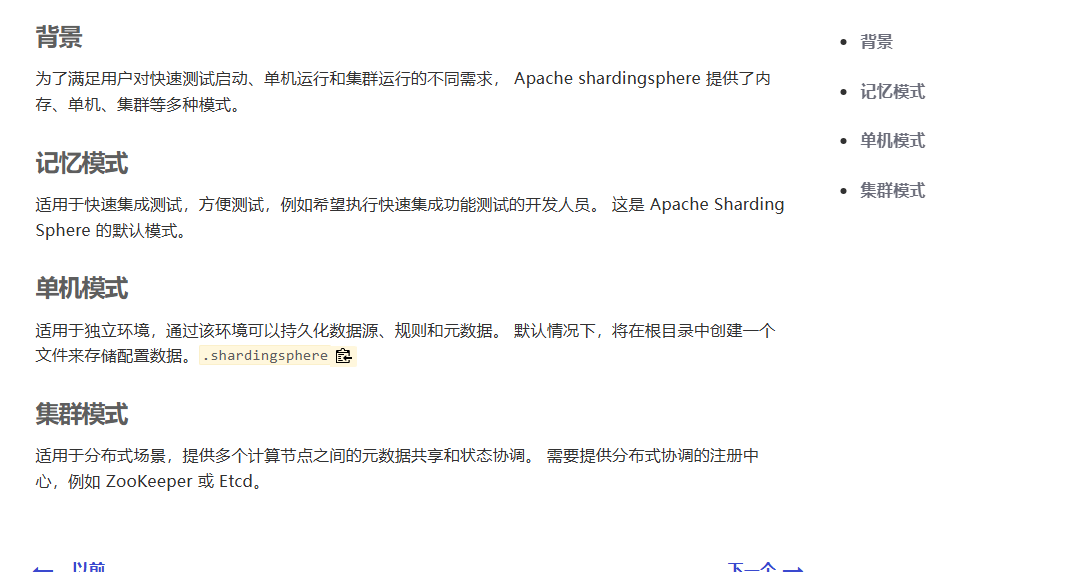
内存模式
单机模式
集群模式
=
我们选择使用内存模式
数据源
yaml配置,就是对应的是yaml文件那种配置模式及
springboot启动器就是这种配置模式
然后把数据源粘贴到我们的配置文件当中
我们弄三个数据源 master slave1 slave3
三个数据源分别对应我们之前弄的主从集群
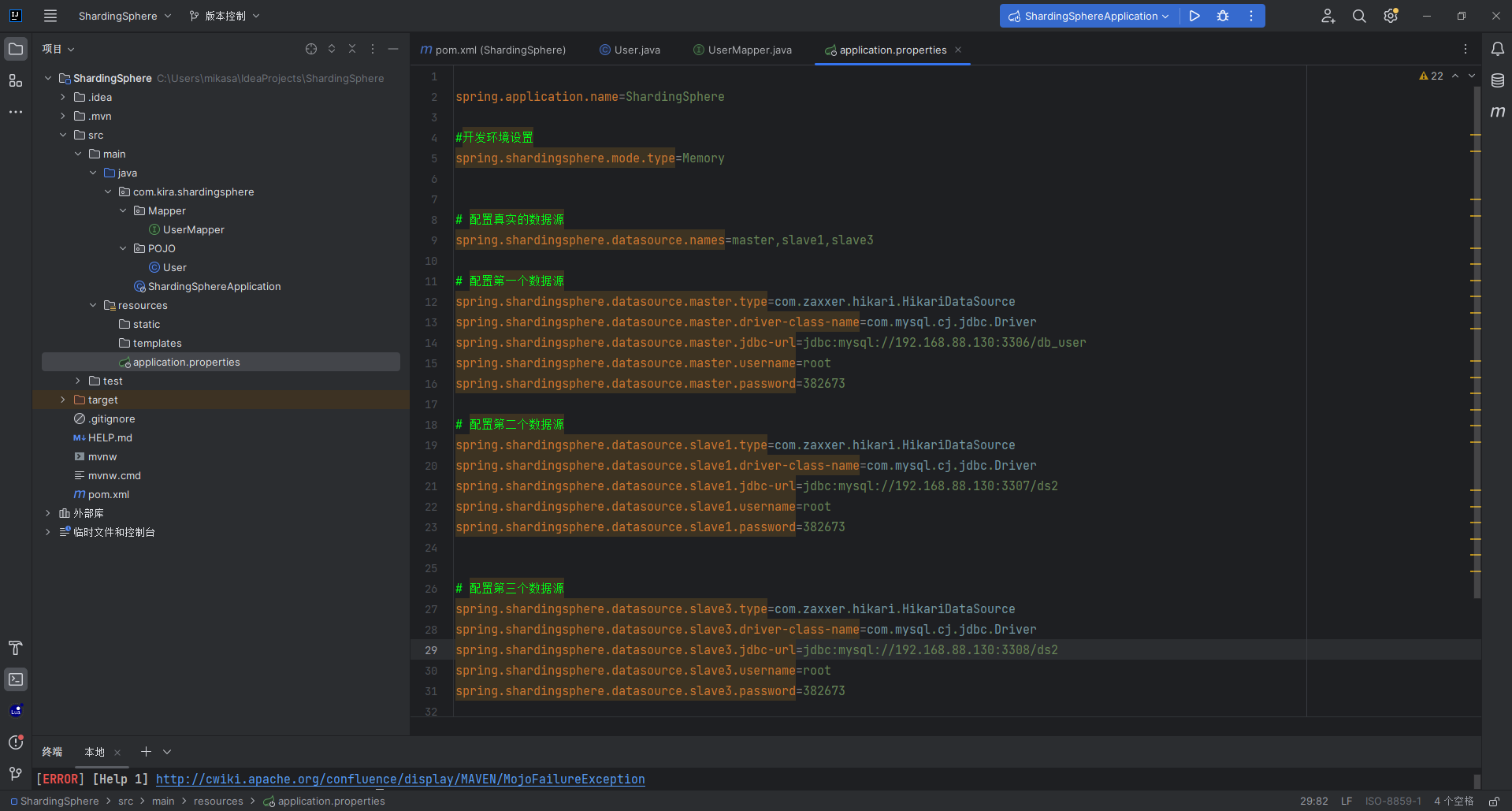
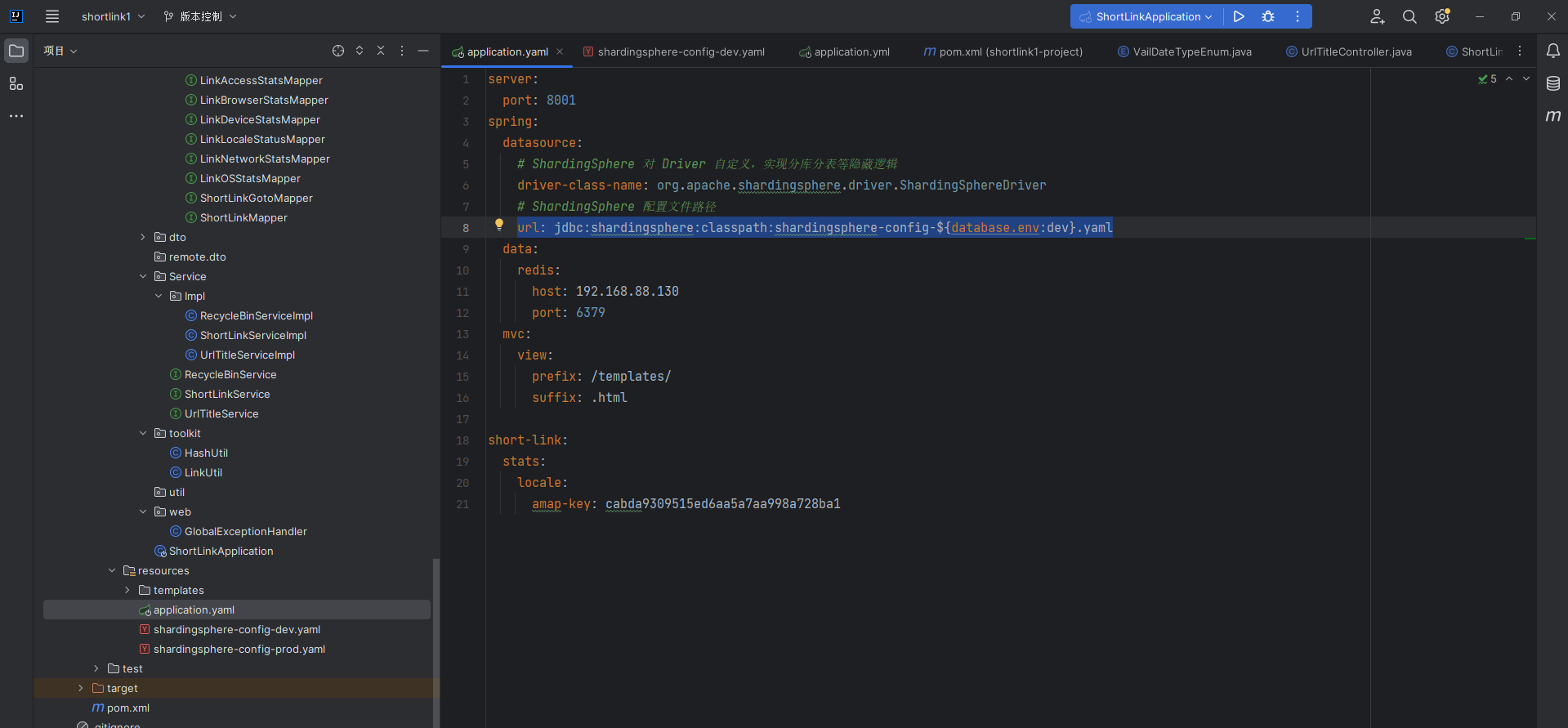
这个是我们的对应的数据源的配置
这个是我短链接项目的时候写的配置,有一些不同,这个driver,我们是用另一个文件来配置的
读写分离的类型
我们读写分离的类型分为静态和动态
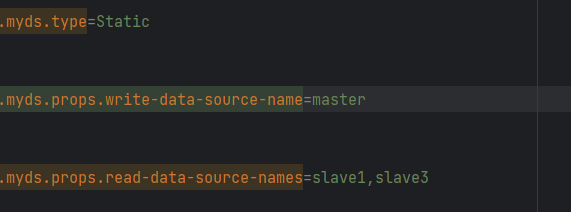
这个是给我们当前的数据源起名字

弄个名字 myds

下面那一段是我们数据源是动态的时候,我们才需要配置的

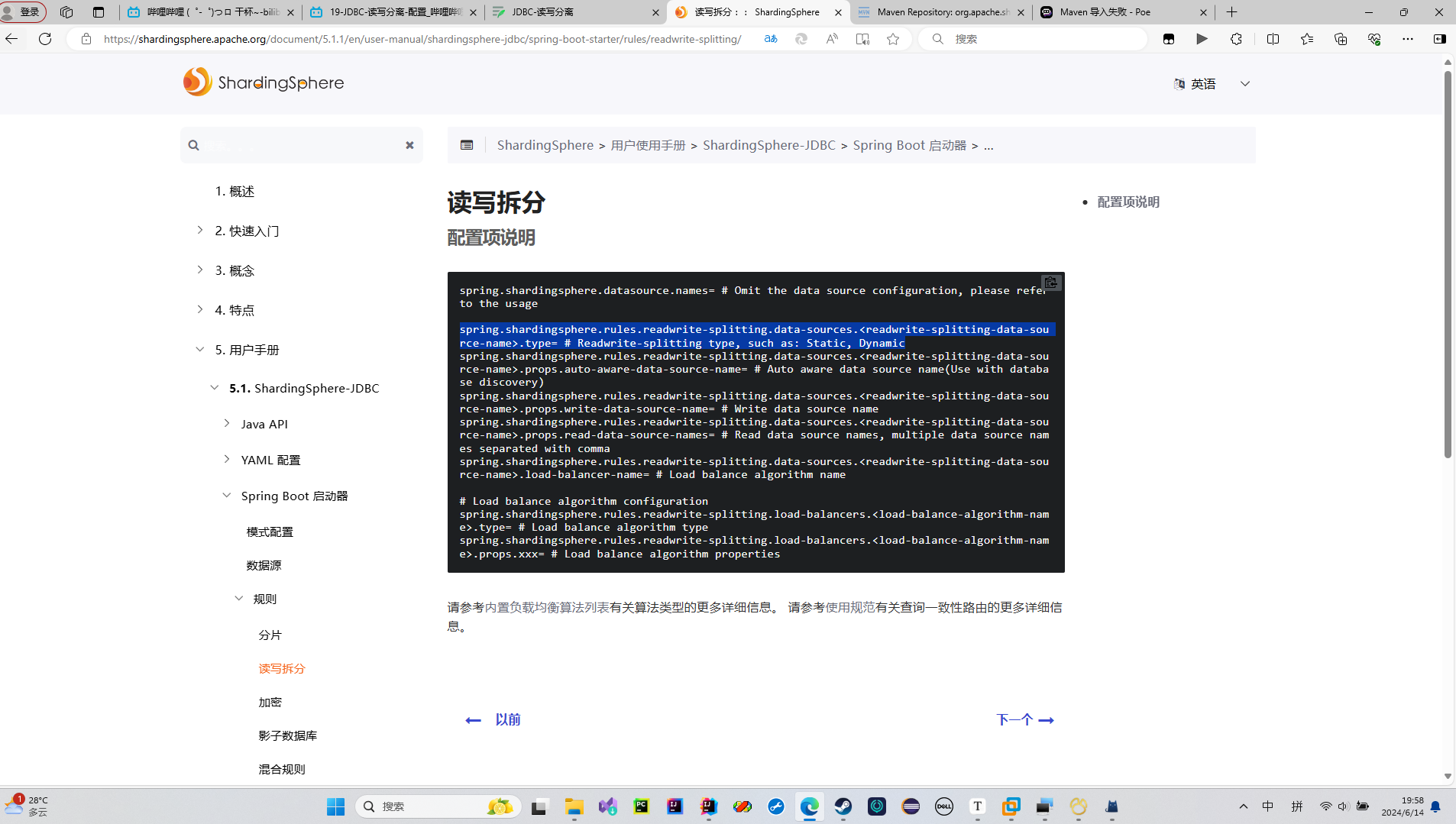
读写数据源
然后跟着官方文档配置我们的读数据源和写数据源
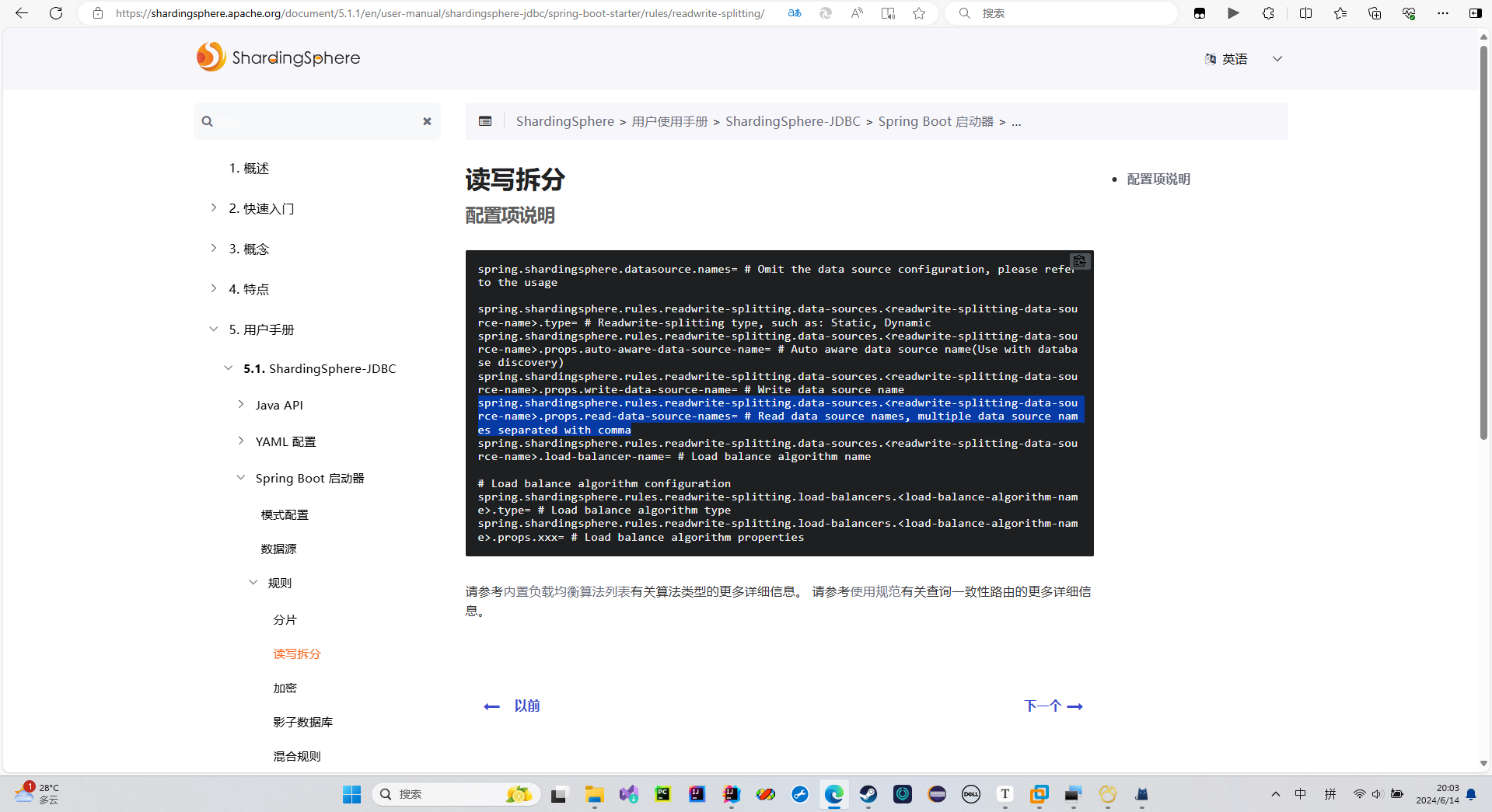
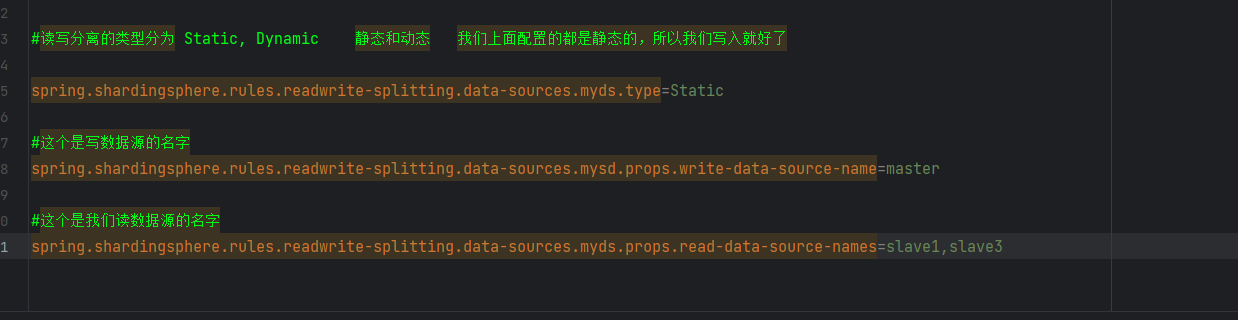
这三个的自定义名字要一致,例如我这里就全都是myds
注意事项
注意我们这种配置的后面不要有空格,有空格的话就运行不起来了
![]()
负载均衡算法配置
这个是我们的负载均衡算法配置
我们可以在文档的内置算法里面,来查找我们的算法类型
属性配置
我们进入属性配置
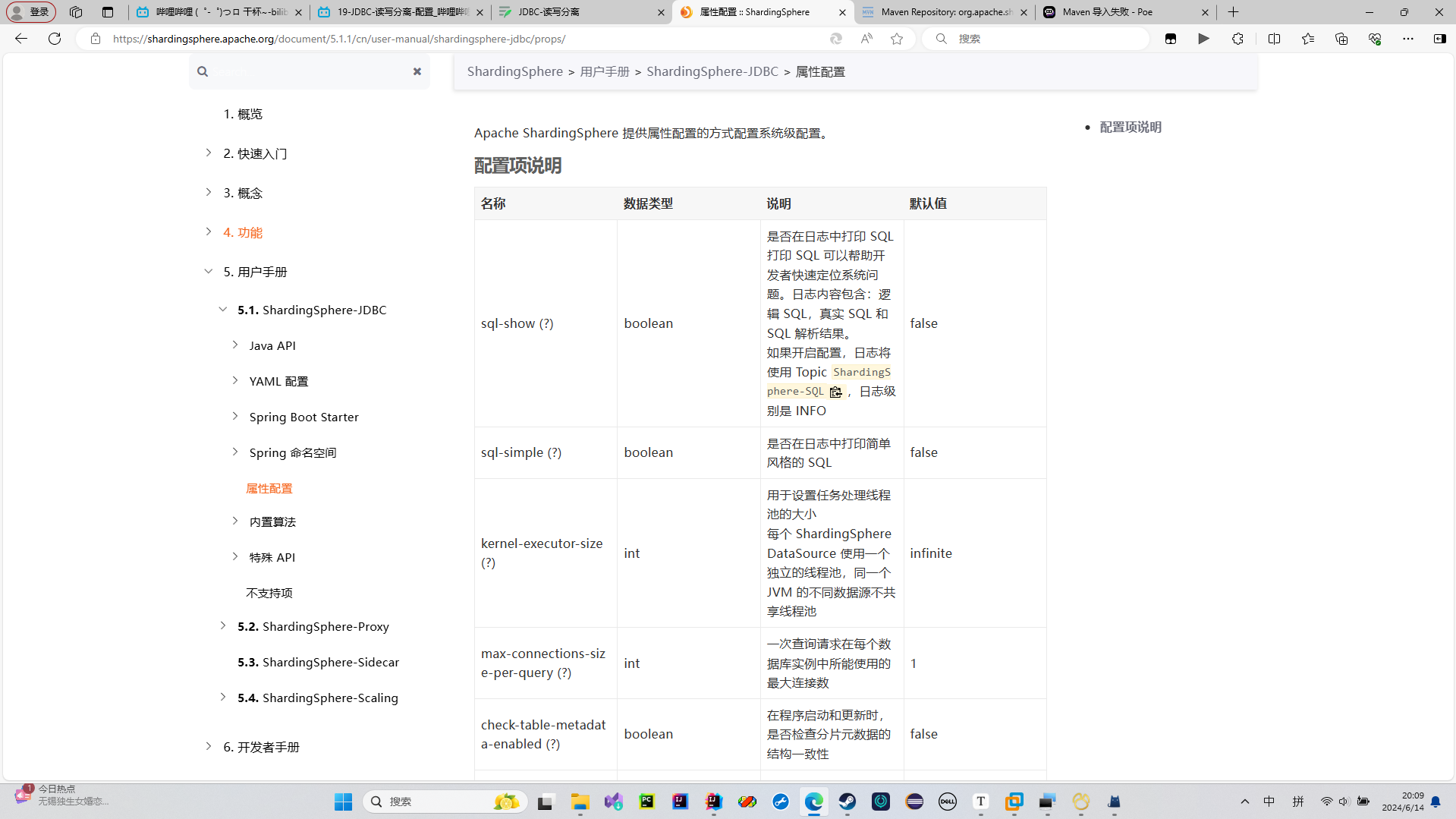

我们的props.sql-show设置为true

测试
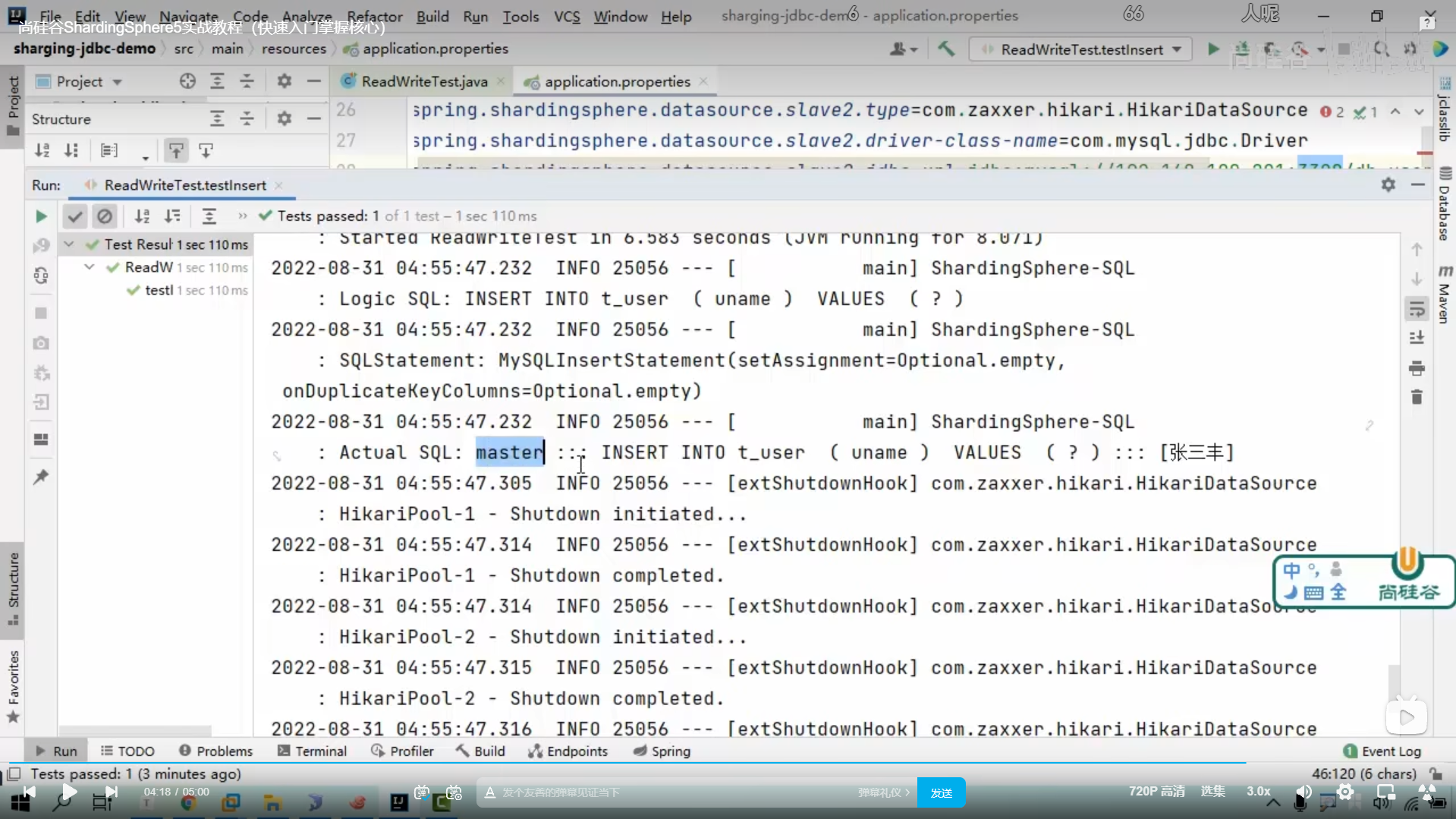
我们这里是逻辑sql
然后我们的shardingsphere会帮我们找到写数据库
然后就有了真实SQL
事务测试
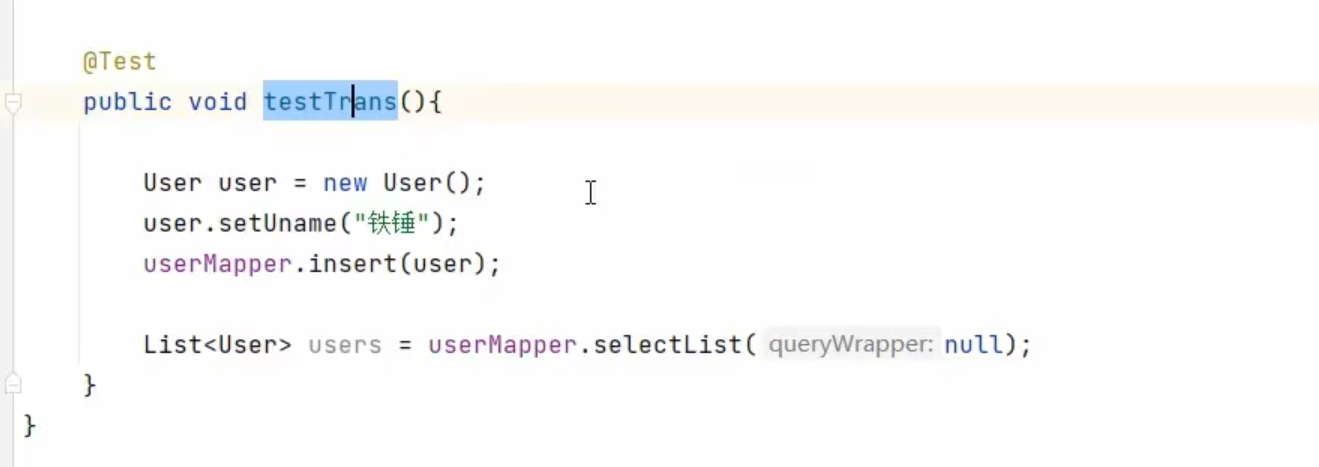
我们和之前一样,有逻辑sql和真实sql
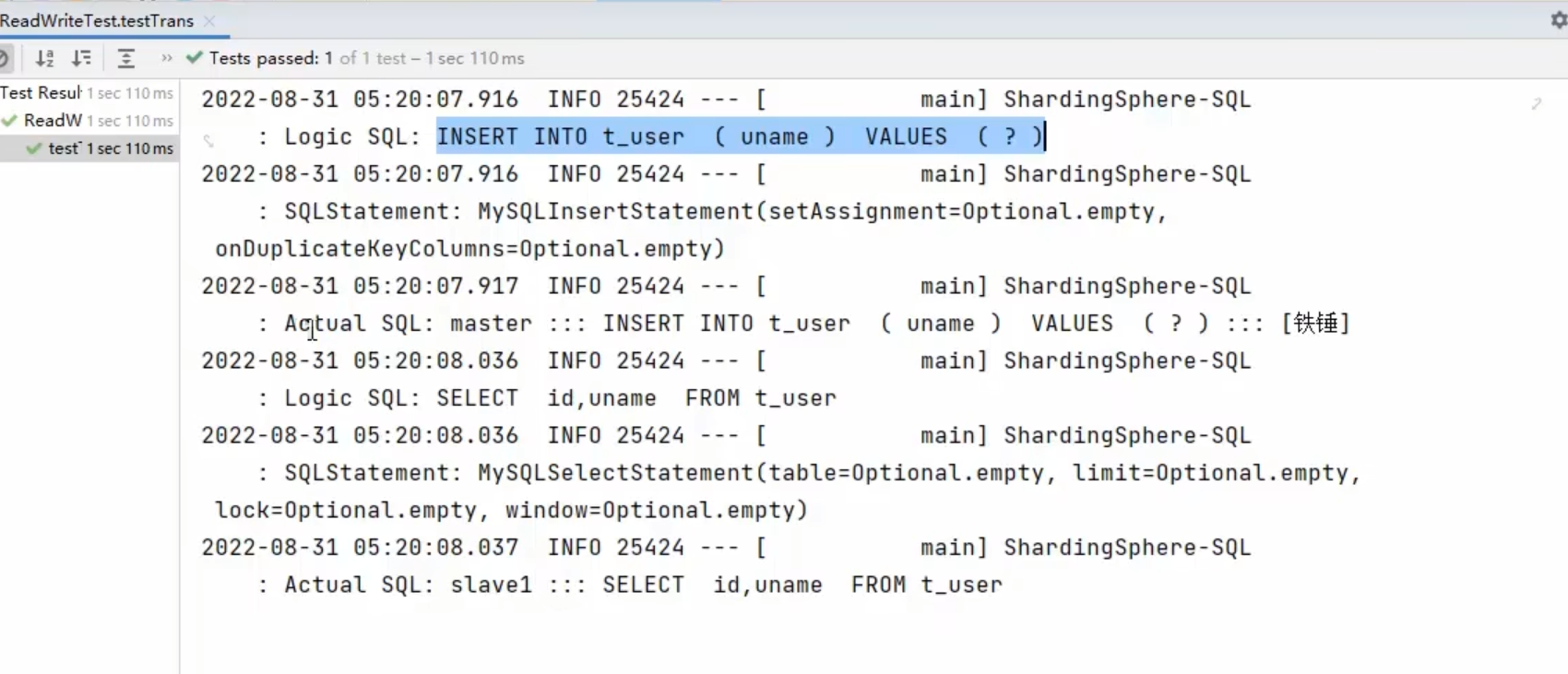
我们发现
写数据会在主库中执行
查数据会在从库中执行
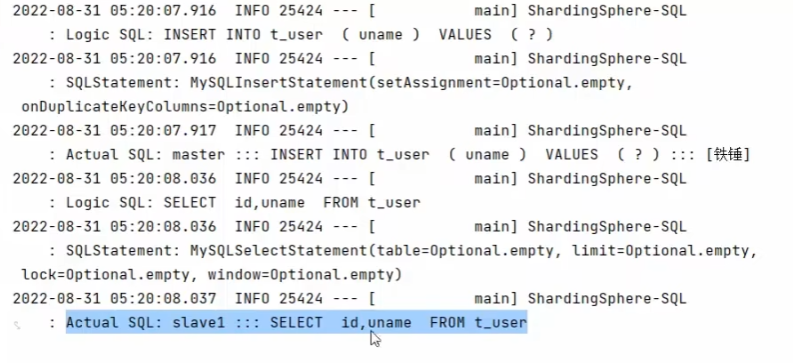
小重点

为了防止跨服务的分布式事务
所以我们事务中,不管读取,我们都是在我们的主数据库中进行的
而且JUnit环境下,默认会对事务进行回滚

负载均衡测试
我们每次测试都是新建的,所以我们轮询一直是slave1
为了体现轮询,所以我们执行两次
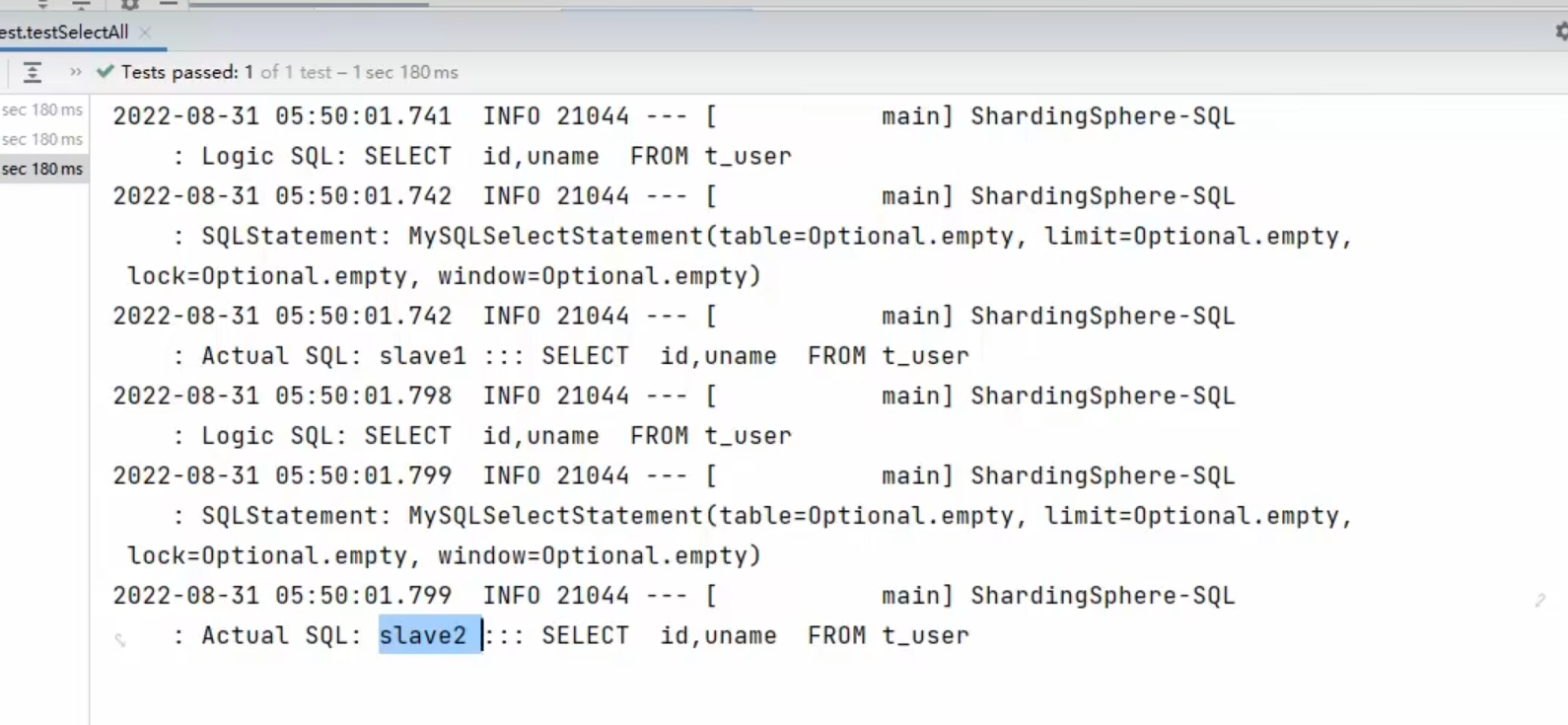
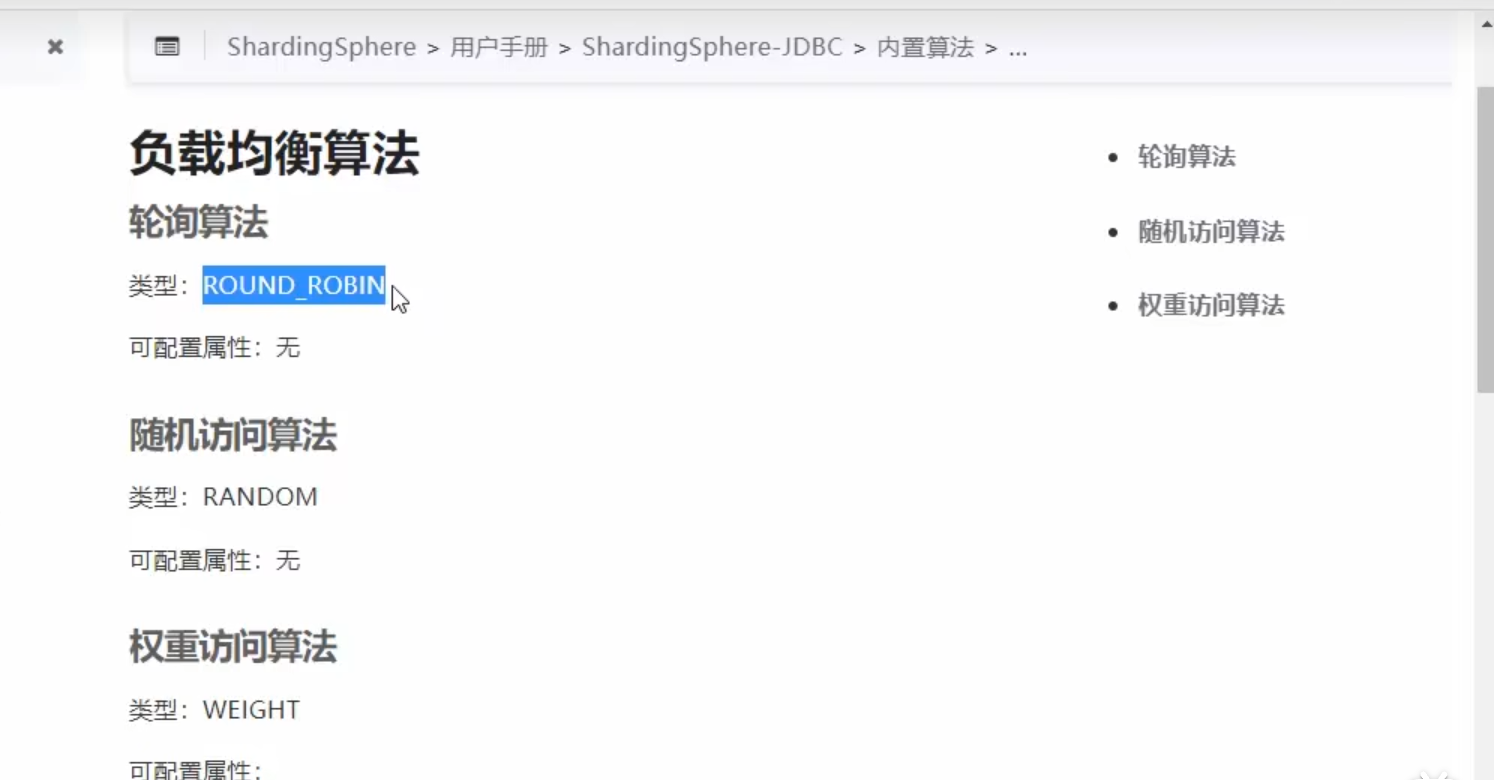
负载均衡算法
轮询算法
随机算法
权重算法
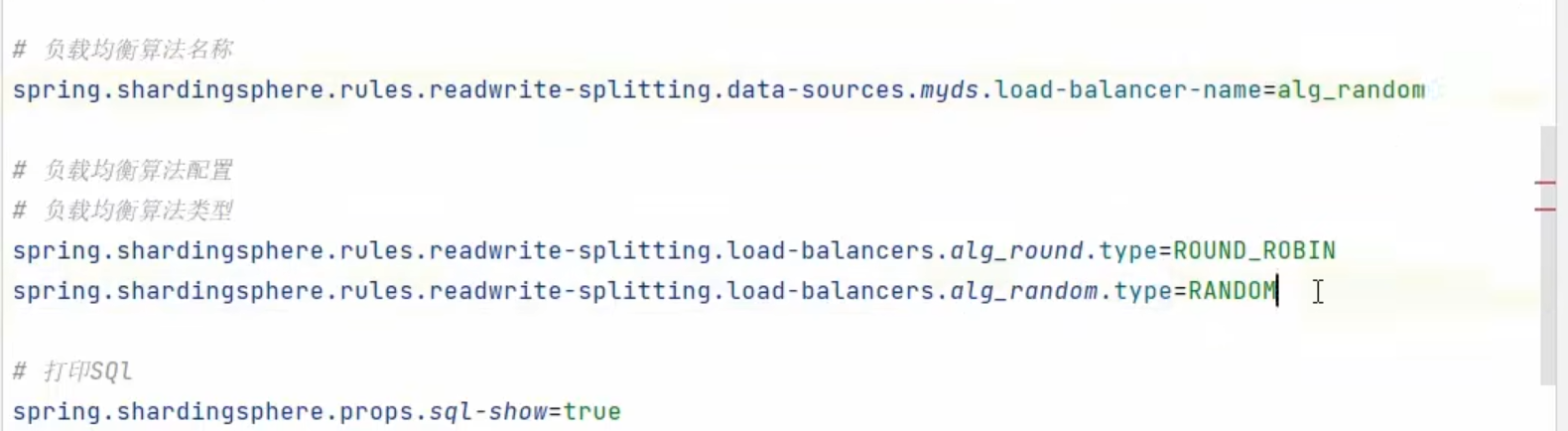


我们不同的算法弄不同的名字,然后要使用的时候,把使用的算法指定一下名字就好了

我们prop配置属性,例如我们这样子来配置我们的权重
JDBC垂直分片
这个数据库表拆分后,他们之间的联系也是十分密切的
所以为了避免跨服务的事务性操作
我们一般情况下不会把他们分散到不同的数据库当中
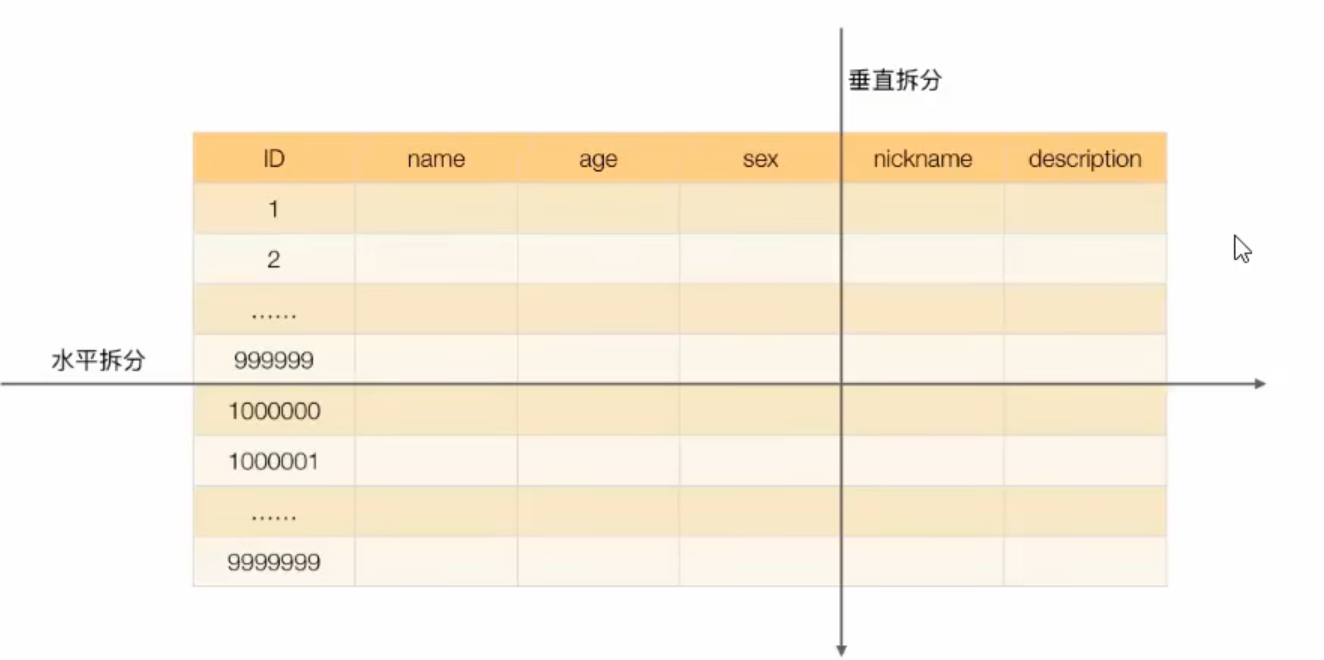
垂直分库

我们把涉及不同的业务的表,分散到不同的数据库当中

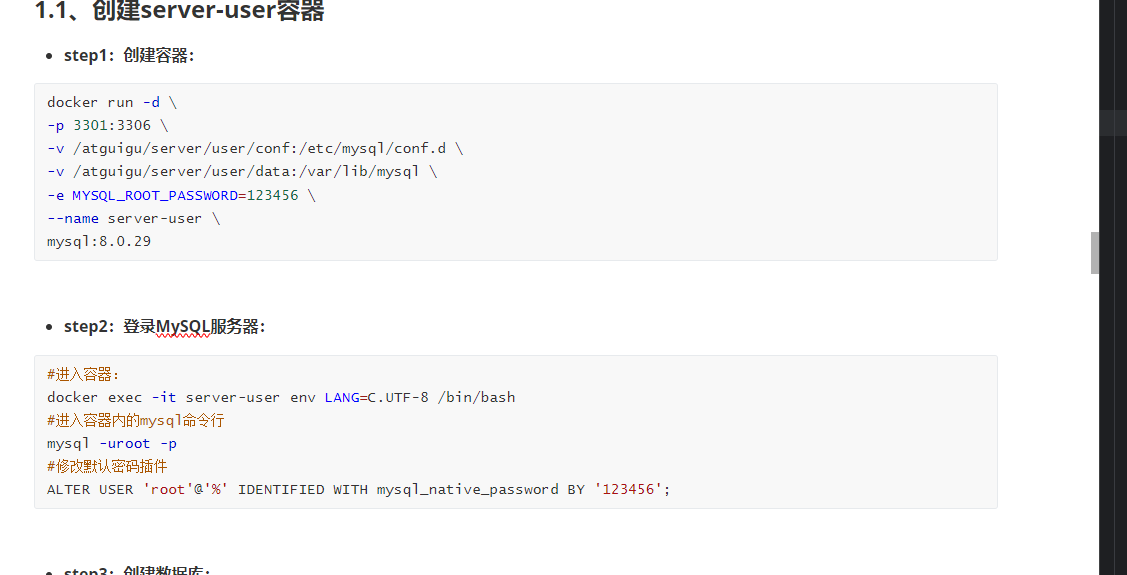
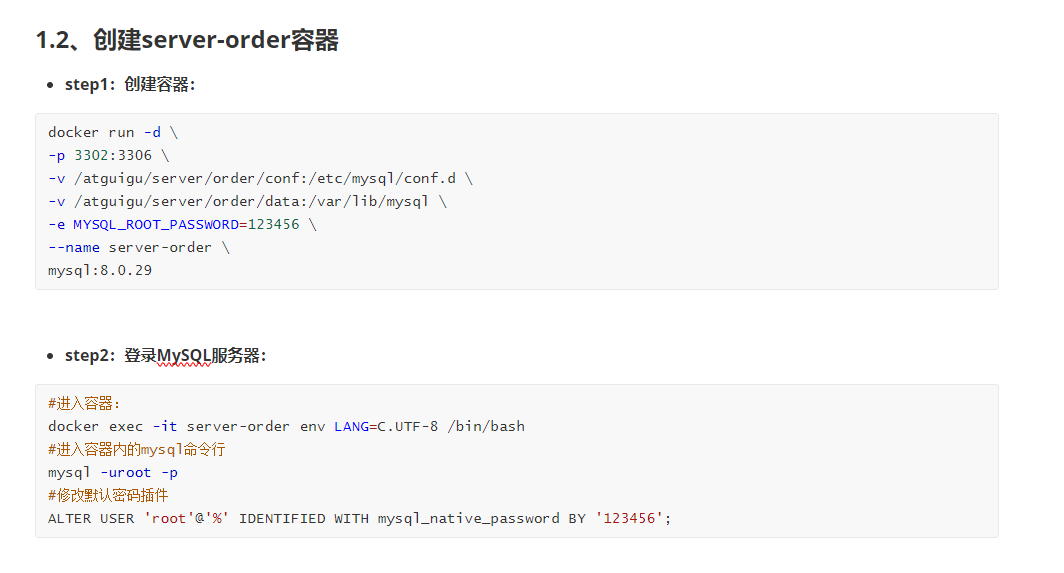
创建docker容器
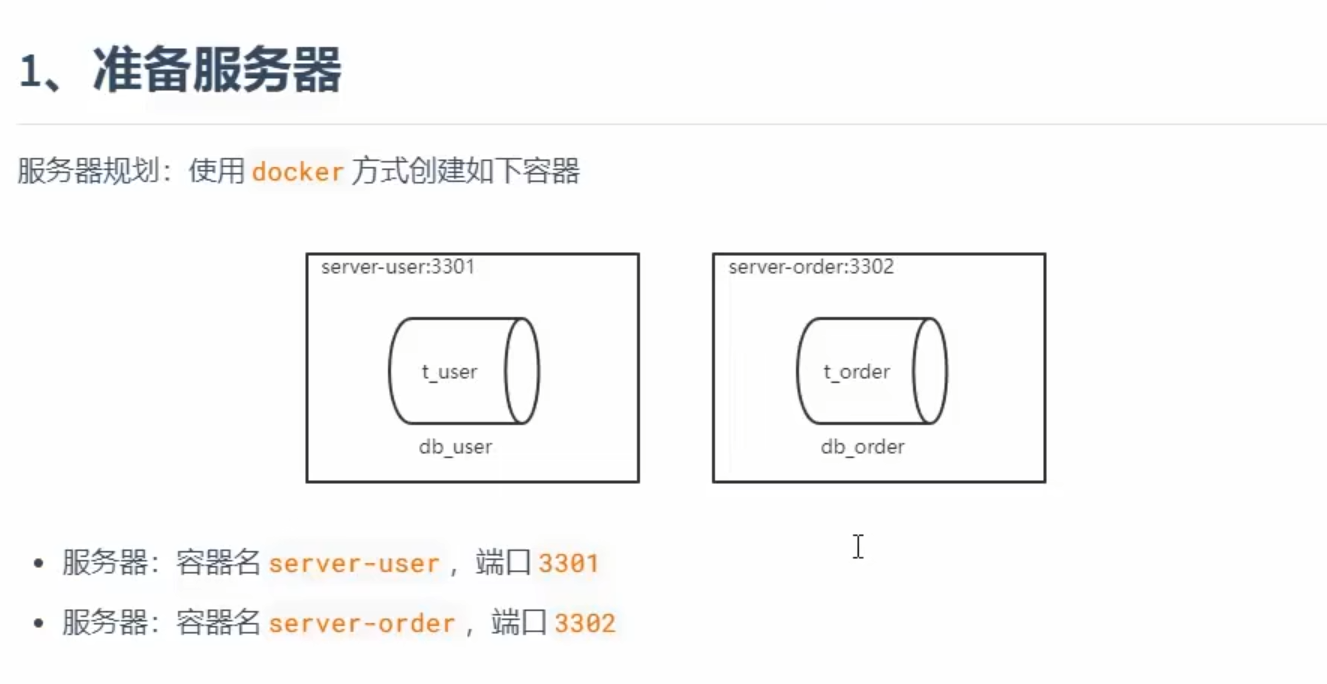
我们先把我们之前运行的3个docker的mysql给停掉
然后步骤和之前一样创建docker容器

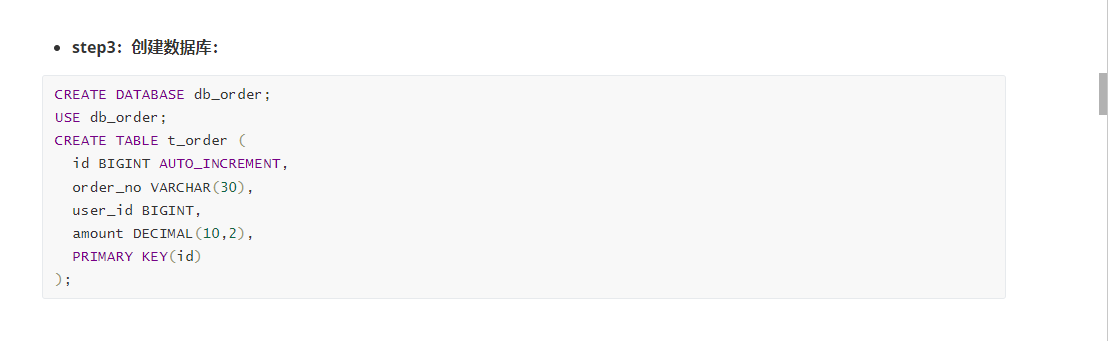
然后和之前一样创建Mapper和实体类
垂直分片配置
我们先重新弄一个垂直分片的配置
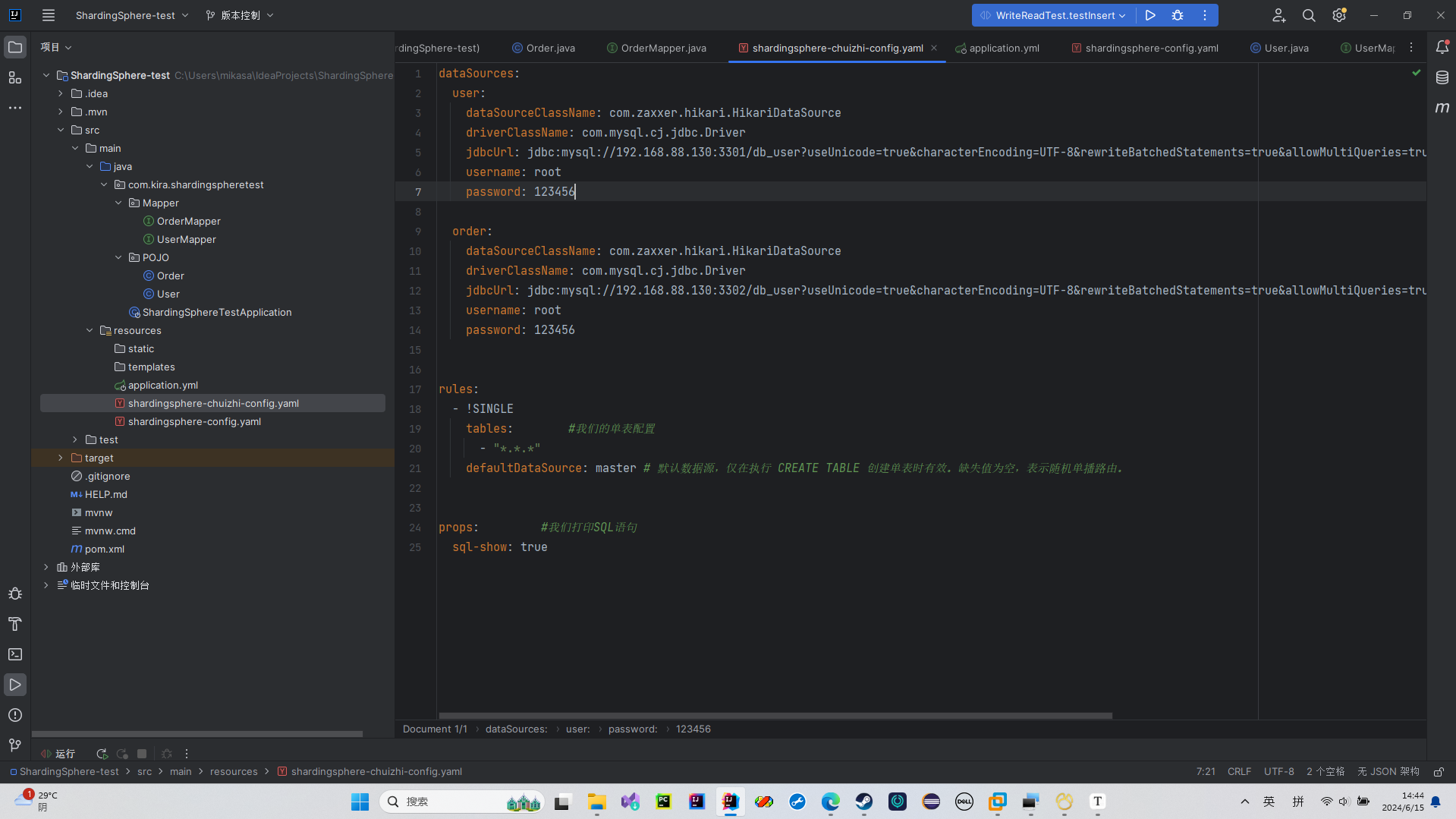
然后我们根据我们的数据分片来进行配置
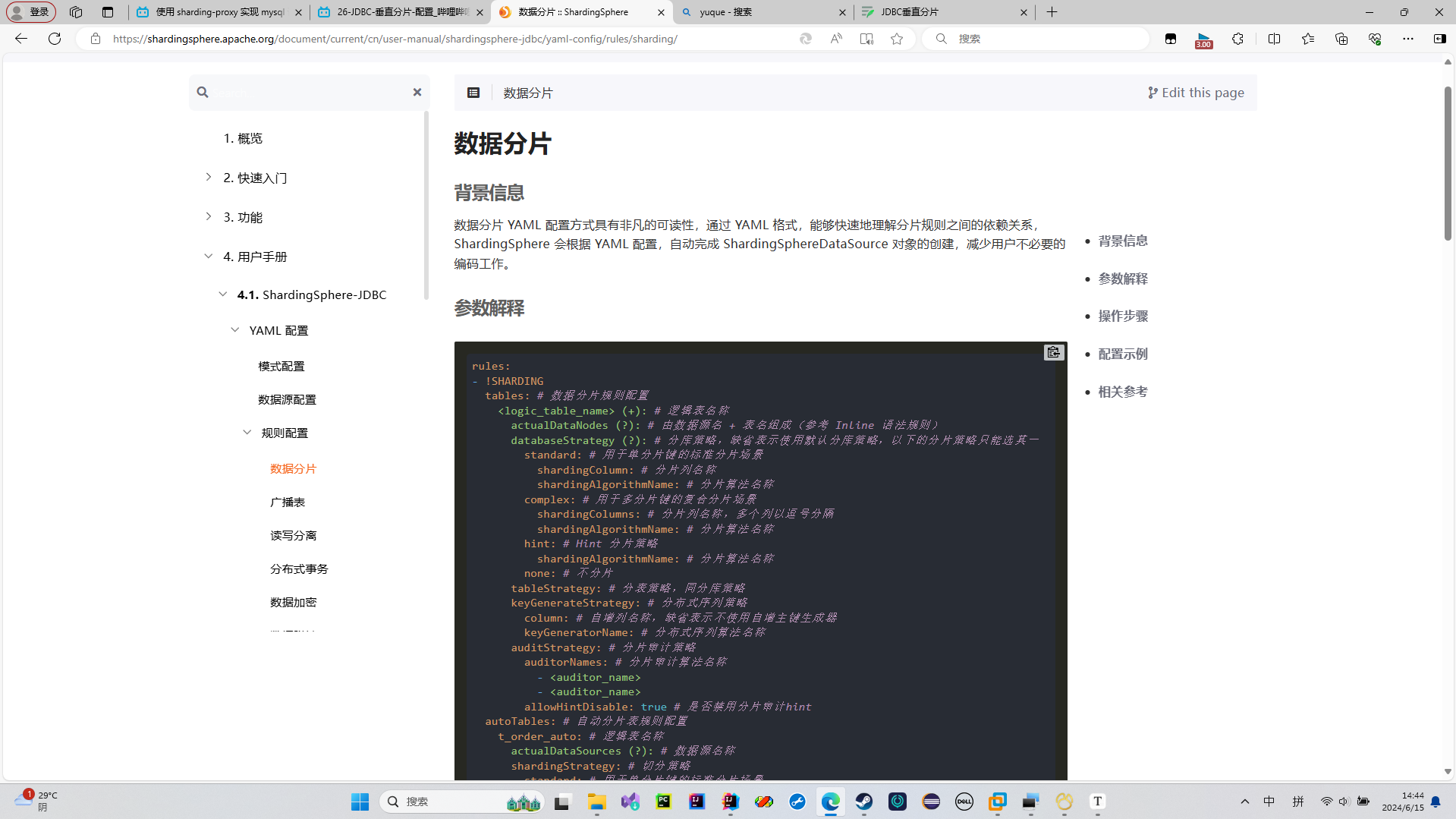
配置逻辑表
我们在这个sharing来配置我们的逻辑表
我们要这样子来配置我们的逻辑表
数据源+真实表名称

这个是我们的官网文档的配置,我们要这样子照着来
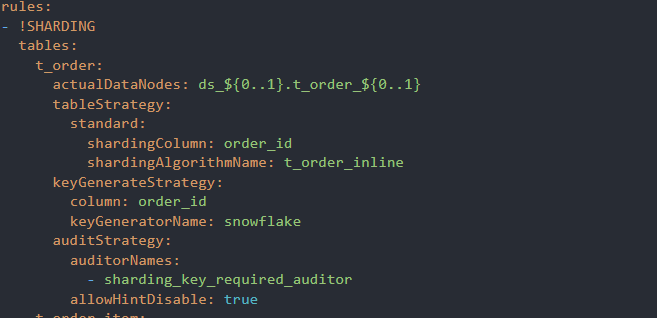
垂直分片的配置文件
dataSources:user:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.DriverjdbcUrl: jdbc:mysql://192.168.88.130:3301/db_user?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: 123456order:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.DriverjdbcUrl: jdbc:mysql://192.168.88.130:3302/db_order?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: 123456rules:- !SINGLEtables: #我们的单表配置- "*.*.*"defaultDataSource: user # 默认数据源,仅在执行 CREATE TABLE 创建单表时有效。缺失值为空,表示随机单播路由。- !SHARDINGtables:t_user: #逻辑表actualDataNodes: user.t_user #不同的表在不同的数据源,配置我们对应的数据源 这样我们就把逻辑表和真实节点映射了t_order: #逻辑表actualDataNodes: order.t_order #不同的表在不同的数据源,配置我们对应的数据源 这样我们就把逻辑表和真实节点映射了props: #我们打印SQL语句sql-show: trueJDBC水平分片
先和之前一样创建两个docker容器
略
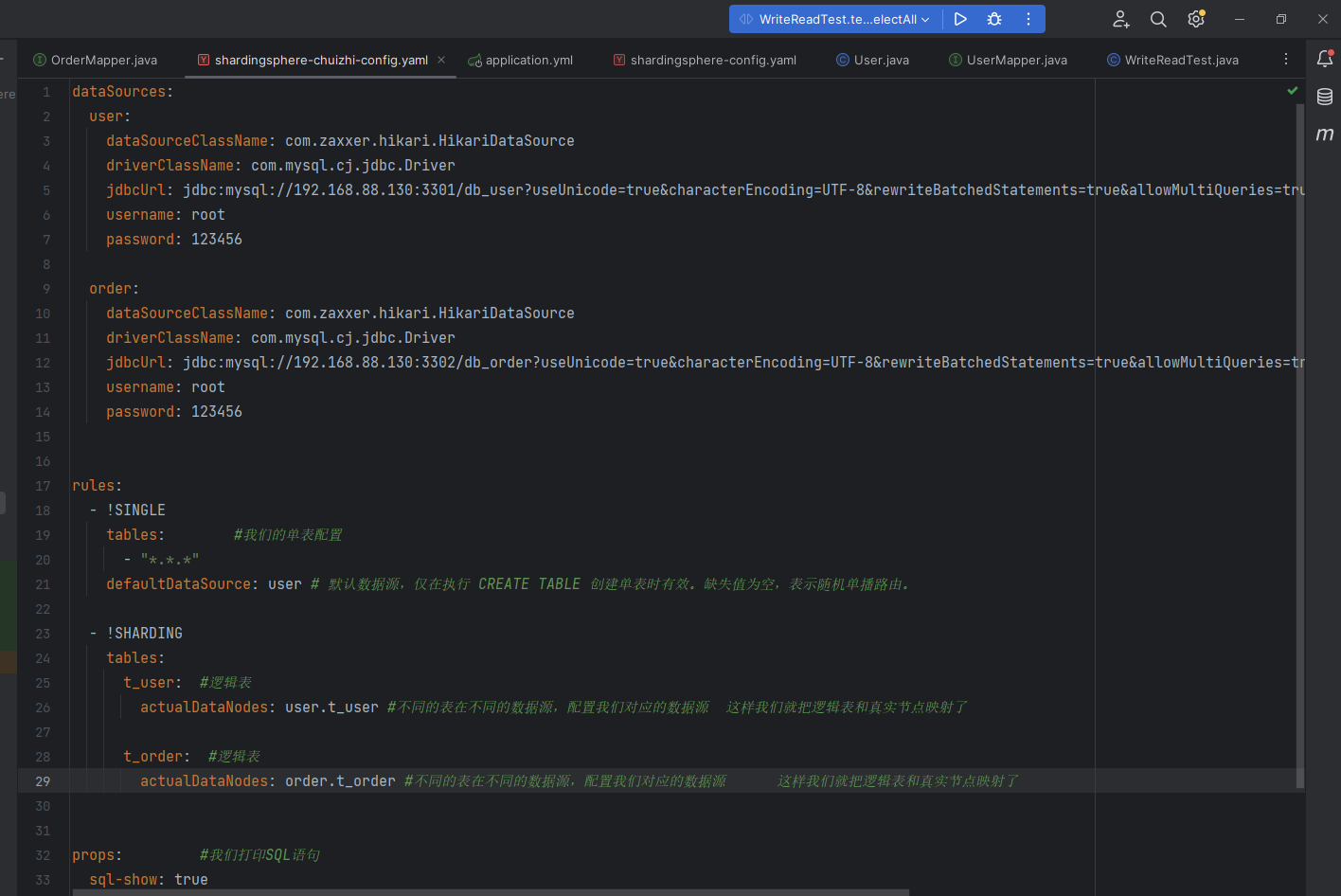
配置标准分片表
我们的这个逻辑表配置了多个数据库以及里面的多个表
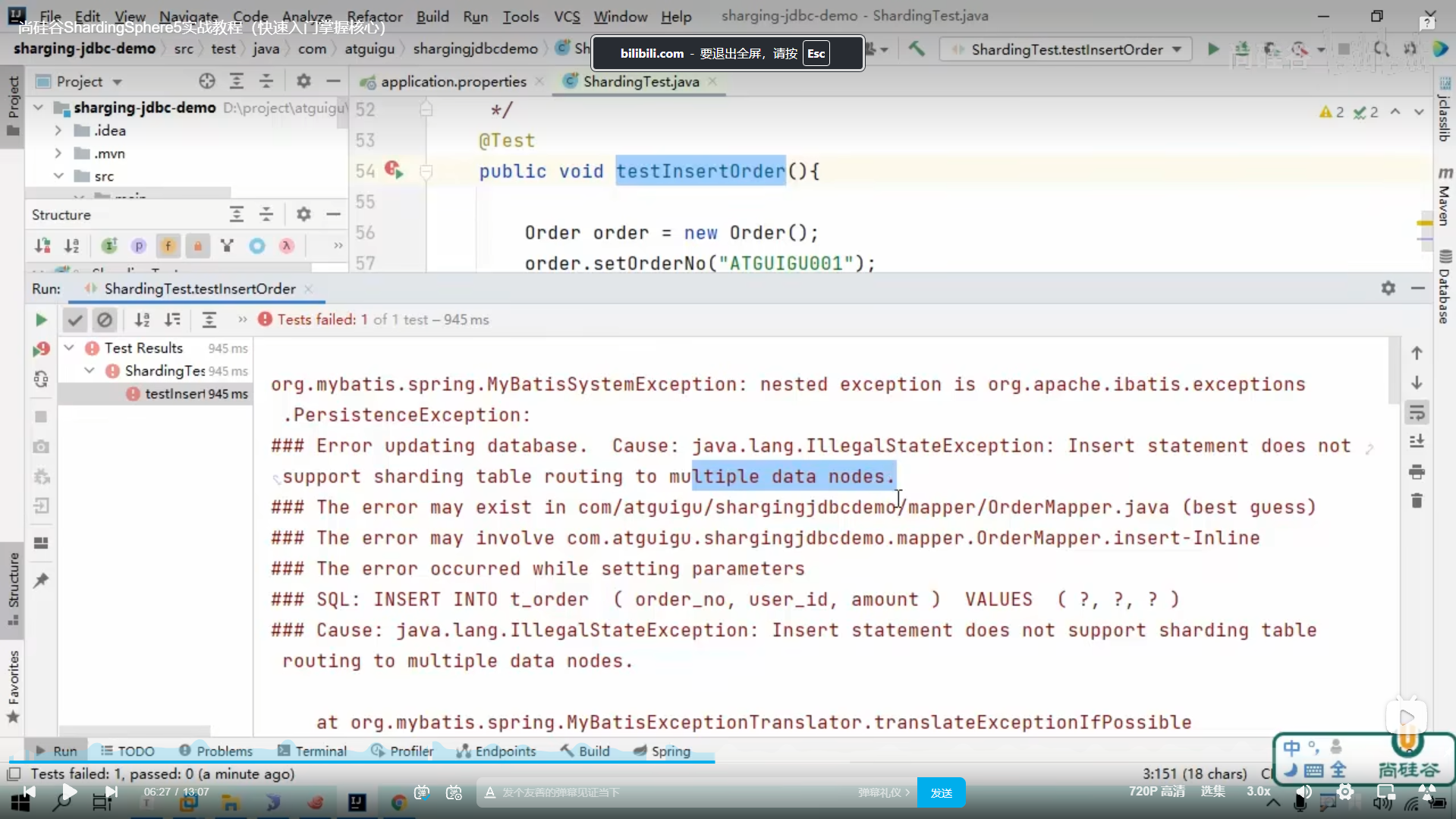
报错了
它不支持将分片数据路由都不同的数据节点中
我们的应用程序无法判断我们到底插入的是
order0数据库里面的oder1和oder2表
还是order1数据库里面的order1和order2表
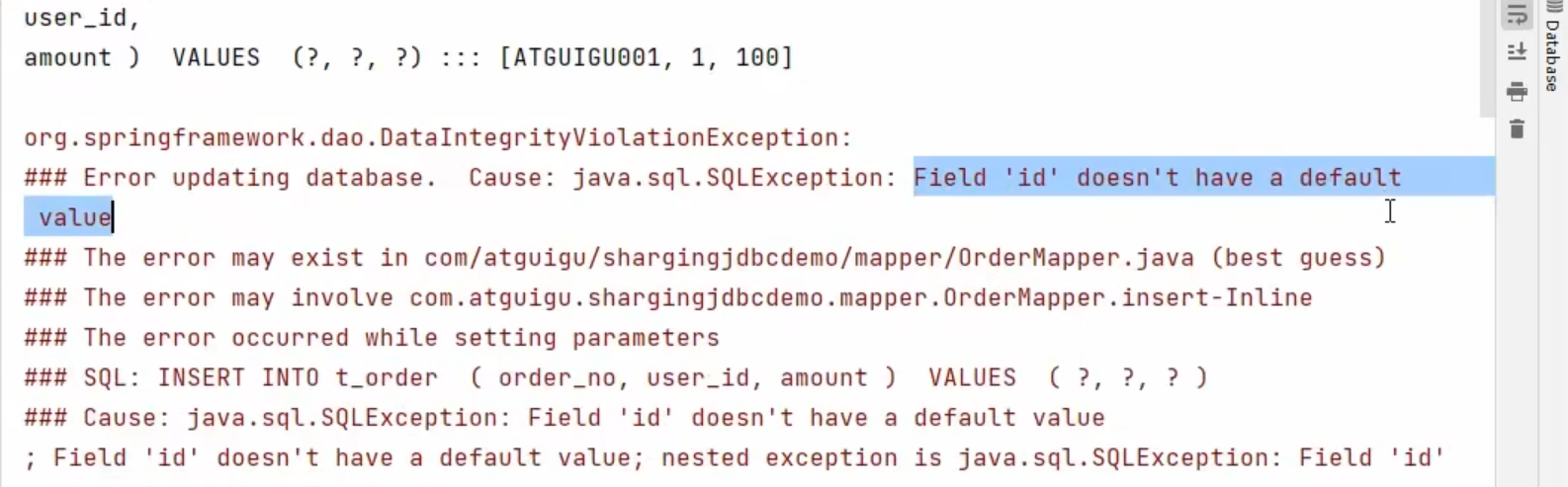
然后我们测试单个ID也会出错
这个报错是我们的ID没有默认值
因为我们创建的表里面,我们没有给ID生成我们的自增策略
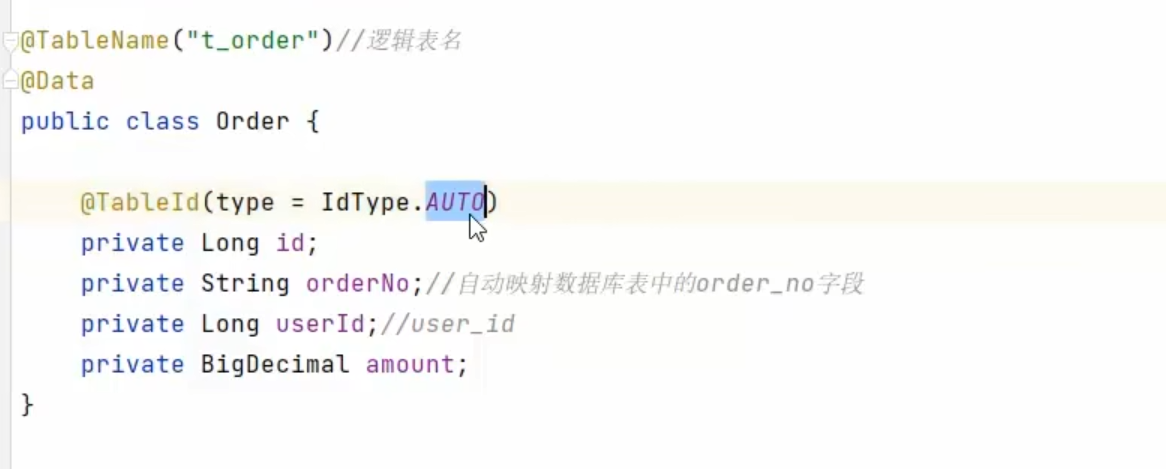
而且我们测试类添加的时候没有指定id
而且我们的实体类还指定了我们的ID是自增的
所以报错了
这个注解依赖于数据库的主键自增策略,但是我们的数据库没有设置我们的主键自增策略

我们先把这个ID换一个类型
换成我们的ASSIGN_ID,分布式ID
依赖mybatisplus自己的策略来生成ID
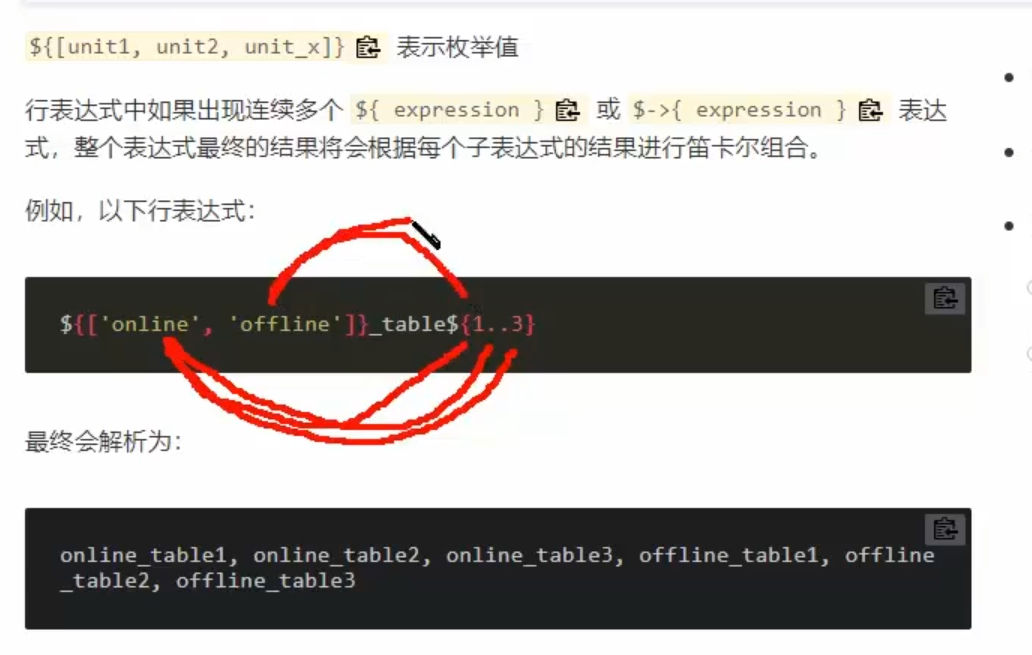
行表达式
两种写法
这个是笛卡尔积
这个是我们的均匀分布的时候的写法
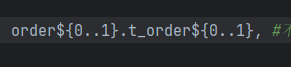
分片算法配置
分库配置
我们要看我们的数据分片文档
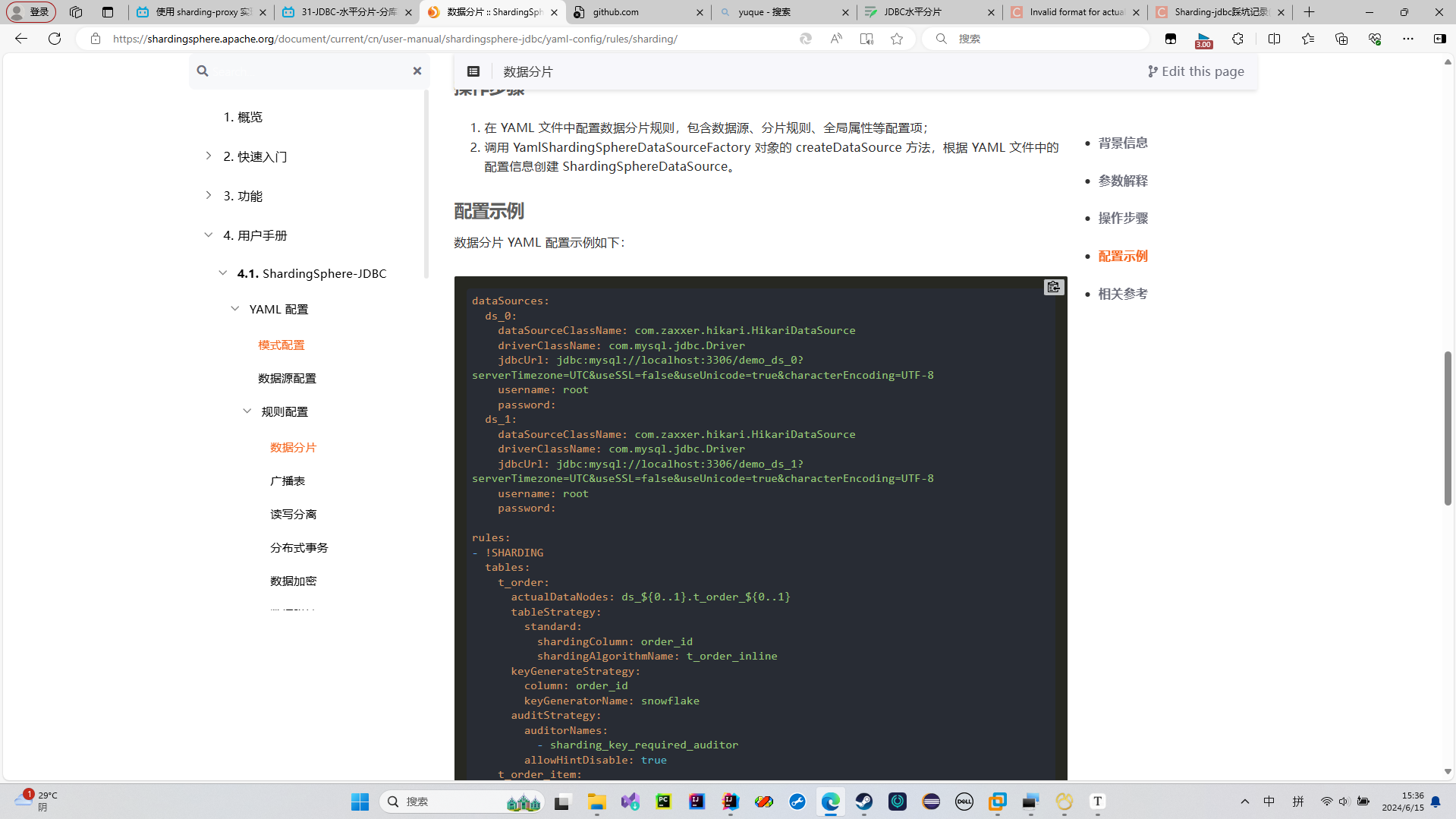
分表策略和分库策略,是一样的操作方式
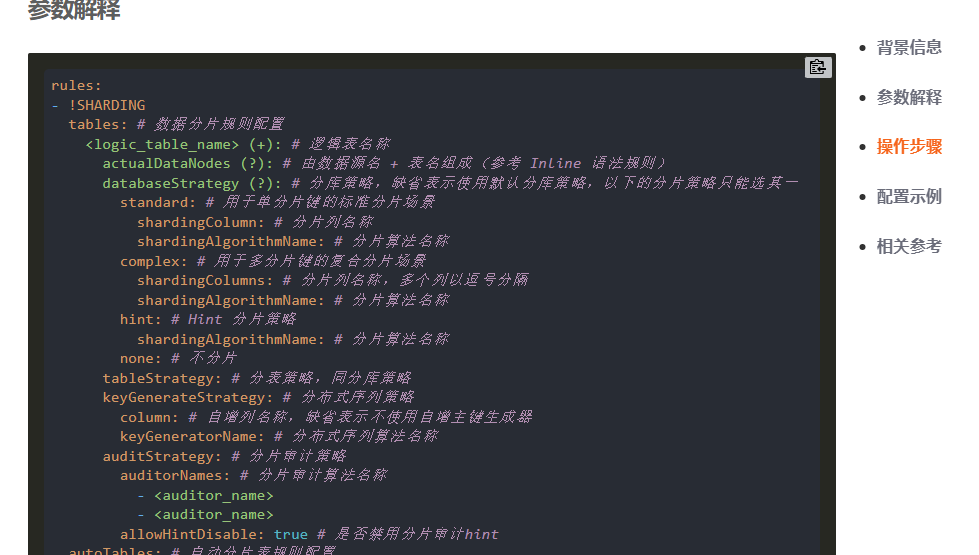
我们要分片,所以看看我们的分片算法
分片算法 :: ShardingSphere
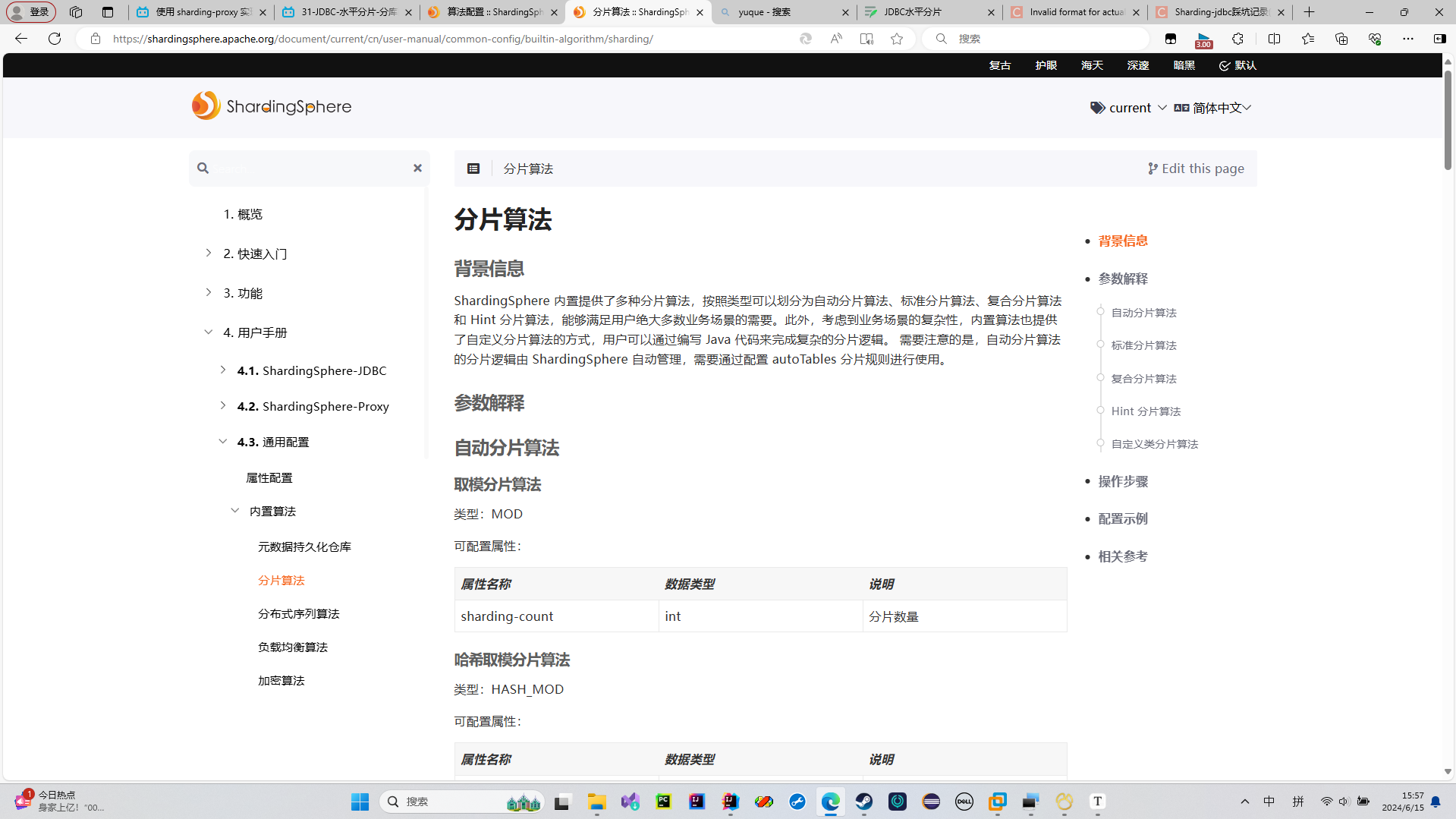
行表达式的分片算法类型叫 INLINE
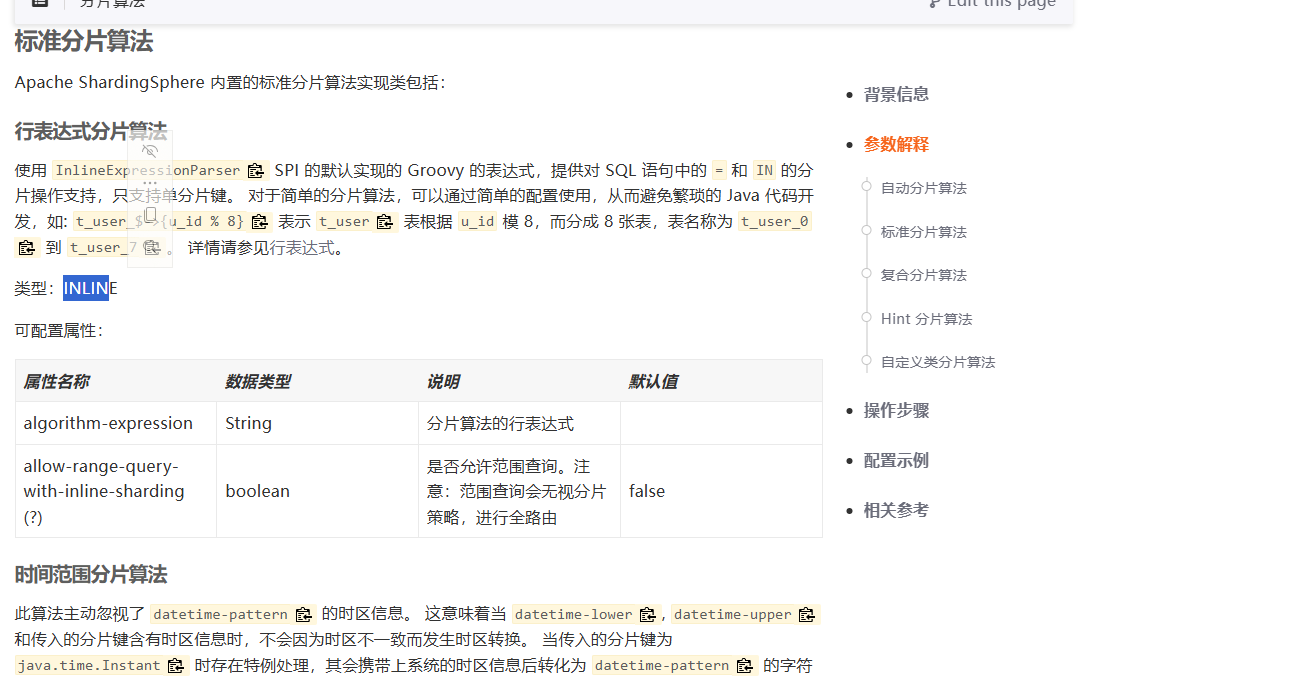
这个分片算法的具体的行表达式是什么?我们用这两个属性来配置
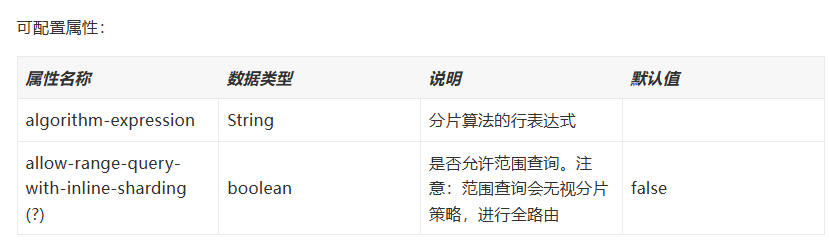
一般来说,我们的分库是固定的,所以我们要设置默认使用的分库策略
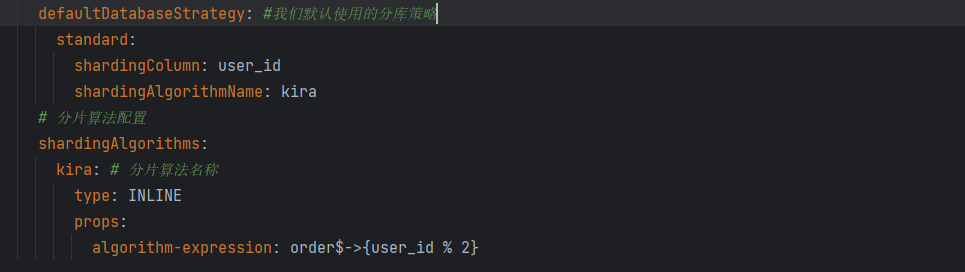
一般来说,这种策略配置和算法配置,要和我们的tables字段对齐
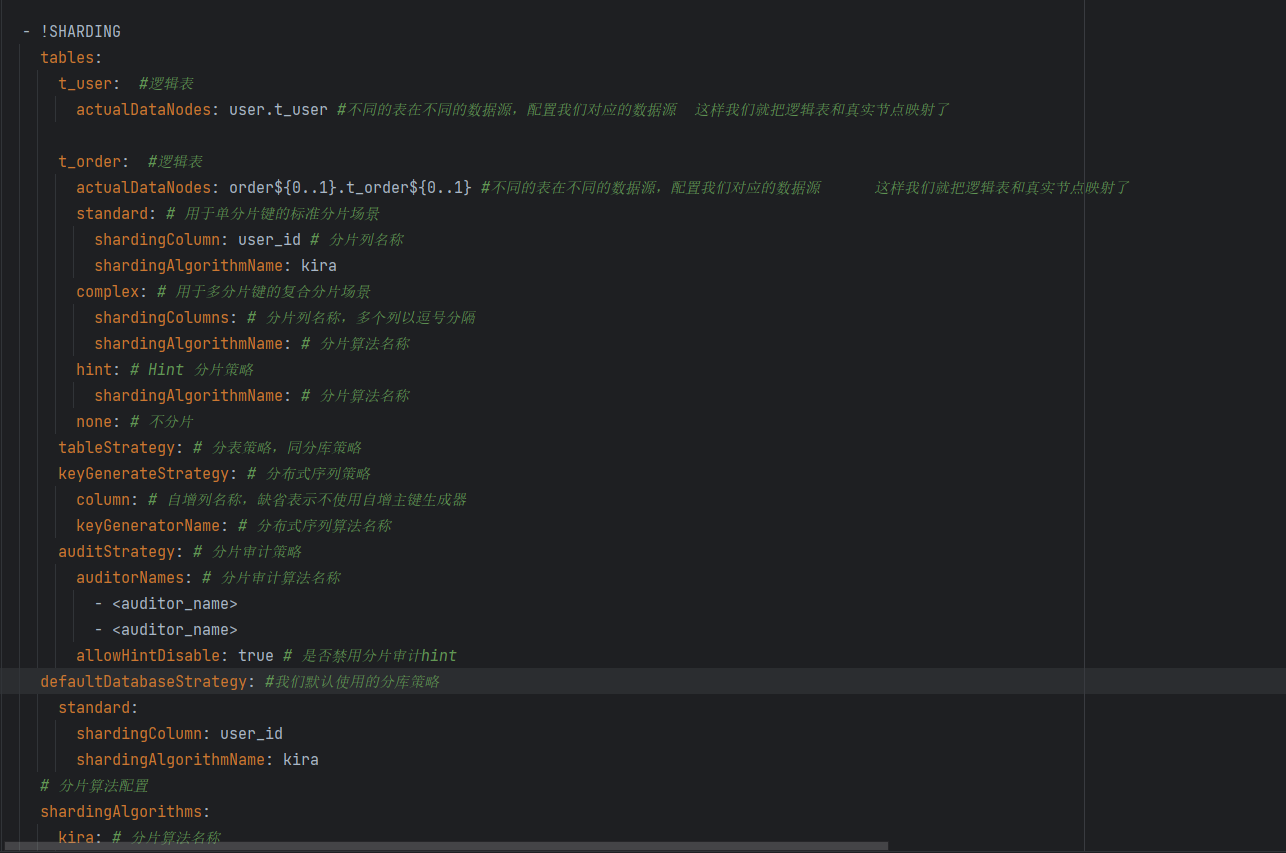
我们看看取模分片算法

有个sharding-count属性

我们的短链接项目就是用这个HASH_MOD算法来配置我们的分片数量的

分表配置
我们指定了分库策略不指定分表策略,那么我们一样运行会报错
所以我们来指定分表策略
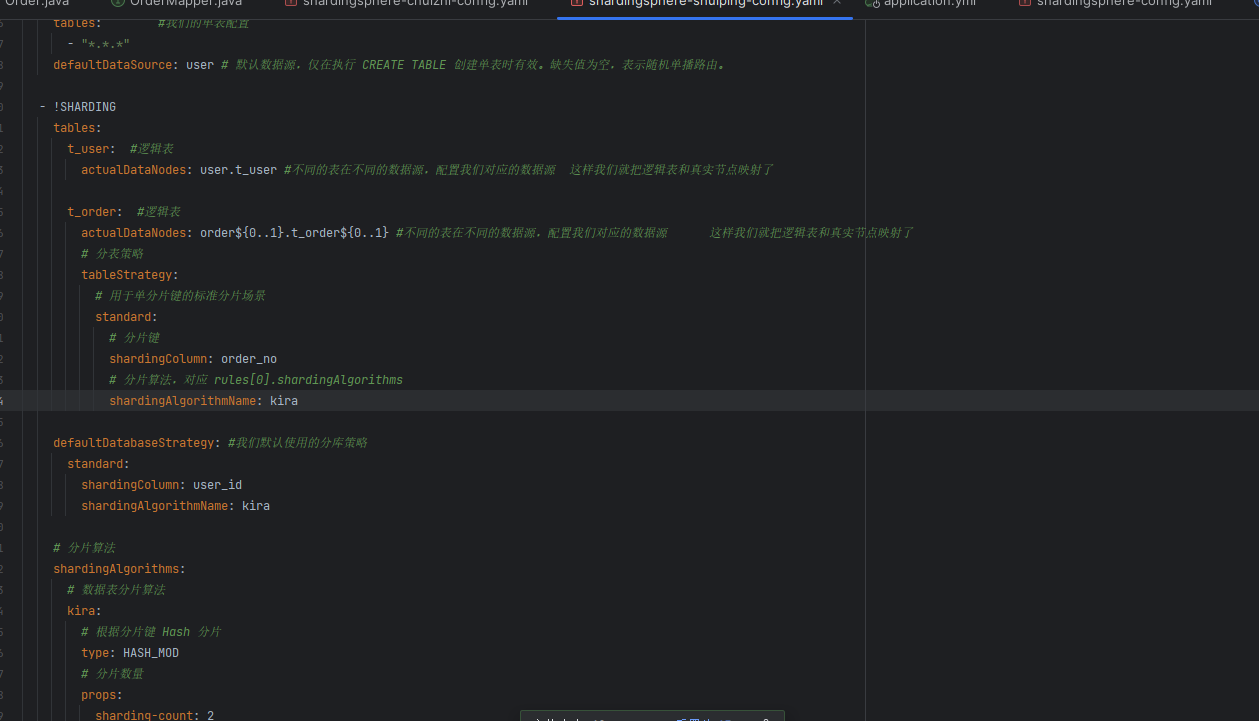
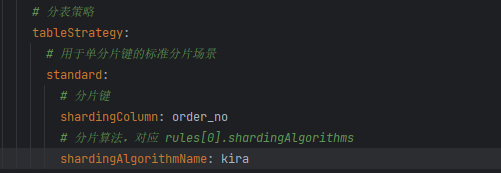
他妈的,配置里面少写了一个tableStrategy,弄得我找了半小时错误,草泥马的
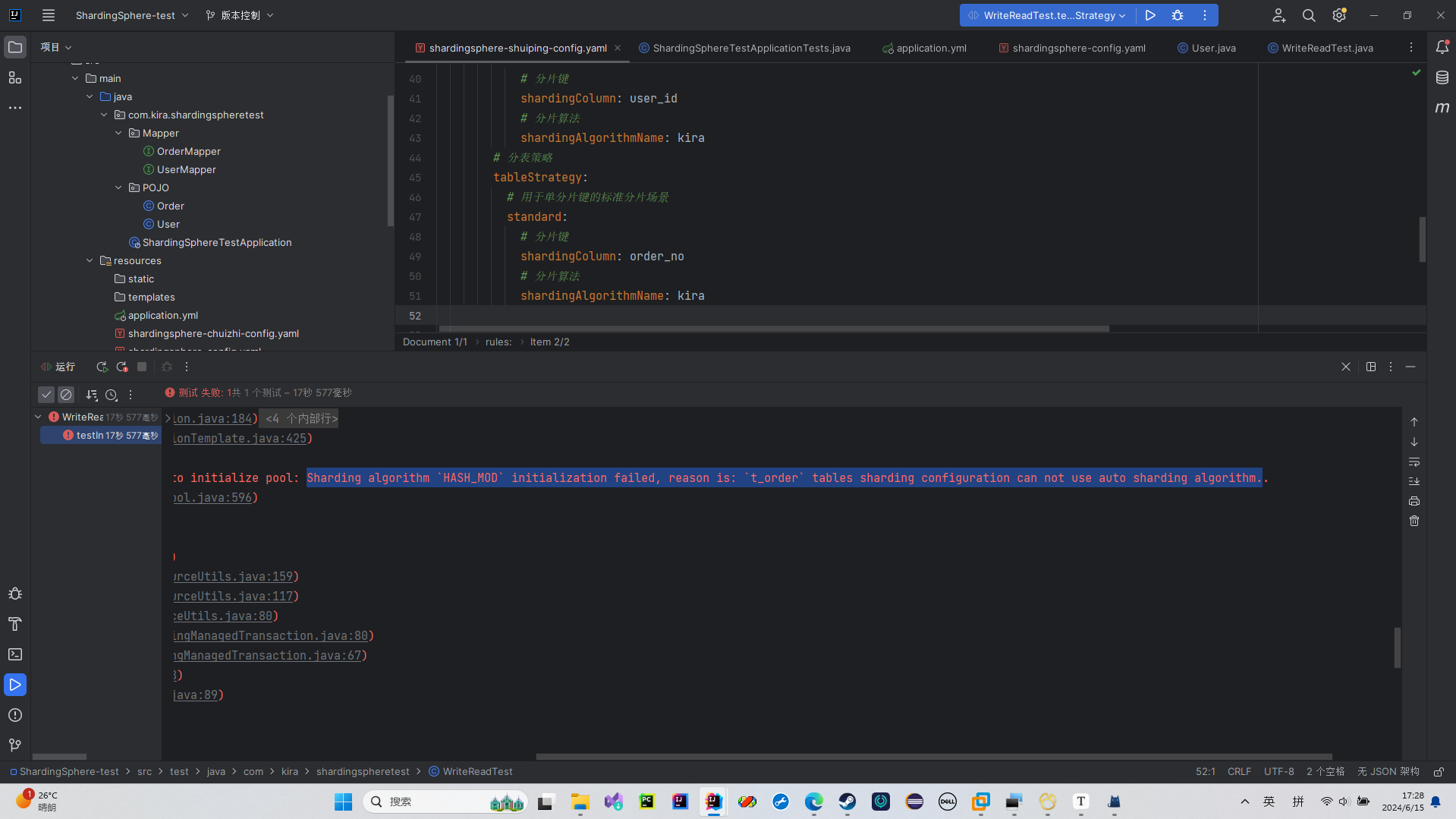
我们是使用order_no这个string类型来取模,所以失败了
string类型不能进行取模运算
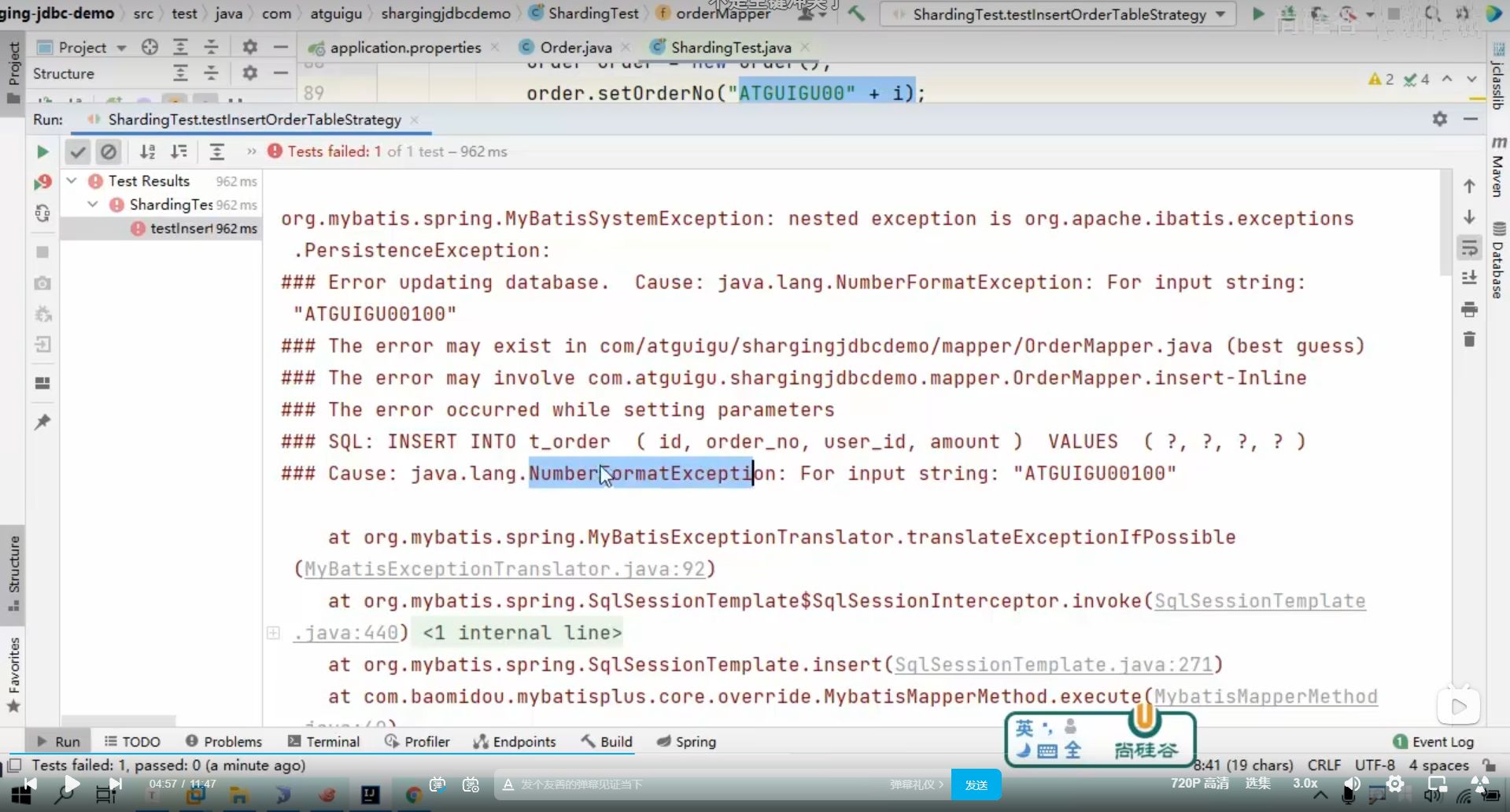
HashMod
如果我们使用HASHMOD,我们也可以根据用字符串取模
这个测试可以看出来
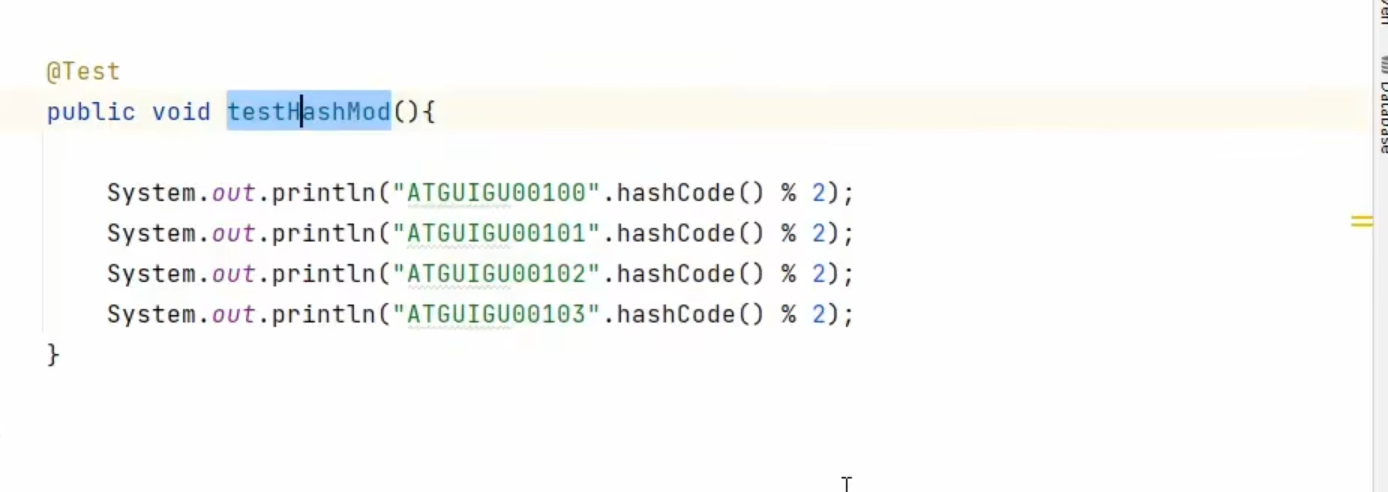
它说我这个表不能使用自动分片算法,所以我又卡住了
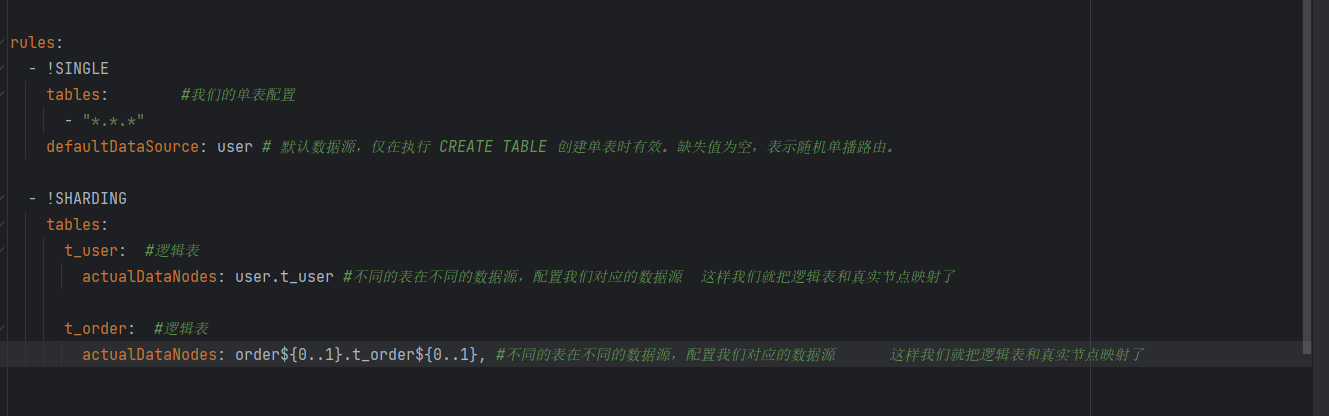
这个是我们的分库分表配置文件
但是我这个报错一直解决不了,所以我不看了,继续往下看吧
dataSources:user:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.DriverjdbcUrl: jdbc:mysql://192.168.88.130:3301/db_user?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: 123456order0:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.DriverjdbcUrl: jdbc:mysql://192.168.88.130:3310/db_order?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: 123456order1:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.DriverjdbcUrl: jdbc:mysql://192.168.88.130:3311/db_order?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: 123456rules:- !SINGLEtables: #我们的单表配置- "*.*.*"defaultDataSource: user # 默认数据源,仅在执行 CREATE TABLE 创建单表时有效。缺失值为空,表示随机单播路由。- !SHARDINGtables:t_user: #逻辑表actualDataNodes: user.t_user #不同的表在不同的数据源,配置我们对应的数据源 这样我们就把逻辑表和真实节点映射了t_order:#逻辑表actualDataNodes: order${0..1}.t_order${0..1} #不同的表在不同的数据源,配置我们对应的数据源 这样我们就把逻辑表和真实节点映射了databaseStrategy :# 用于单分片键的标准分片场景standard:# 分片键shardingColumn: order_no# 分片算法shardingAlgorithmName: kira# 分表策略tableStrategy:# 用于单分片键的标准分片场景standard:# 分片键shardingColumn: user_id# 分片算法shardingAlgorithmName: kira# 分片算法shardingAlgorithms:# 数据表分片算法kira:# 根据分片键 Hash 分片type: HASH_MOD# 分片数量props:sharding-count: 16props: #我们打印SQL语句sql-show: true雪花算法
看看mybatisplus的主键id生成算法
也有雪花算法和UUID算法
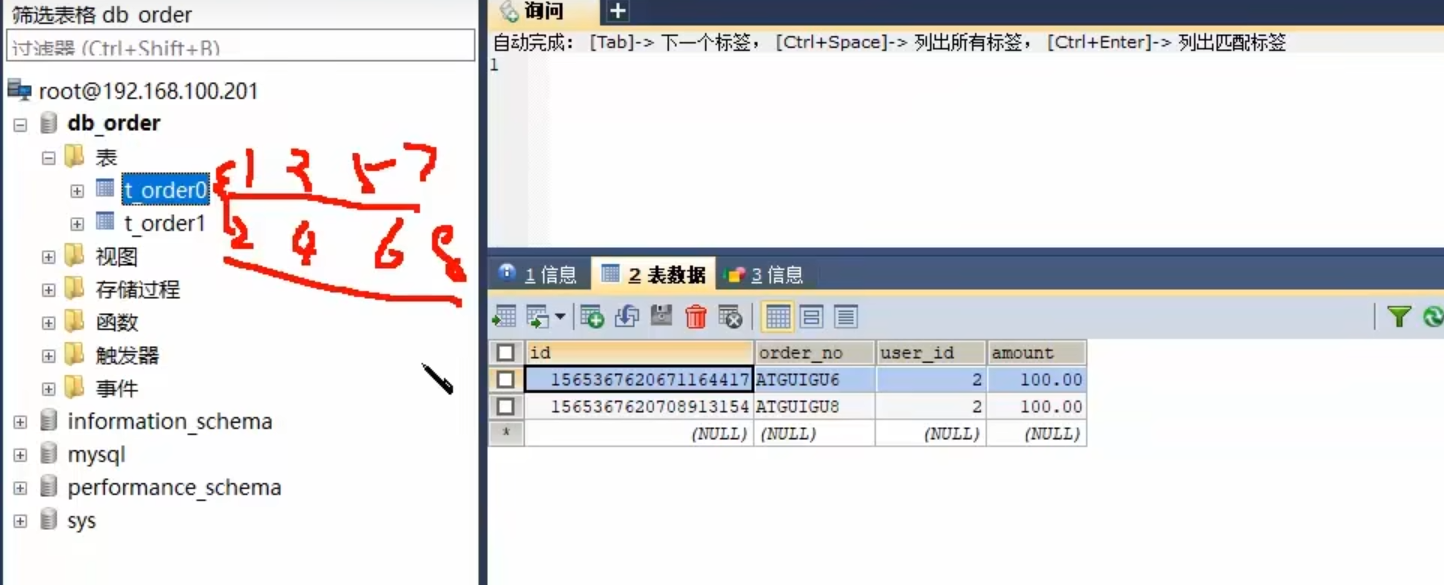
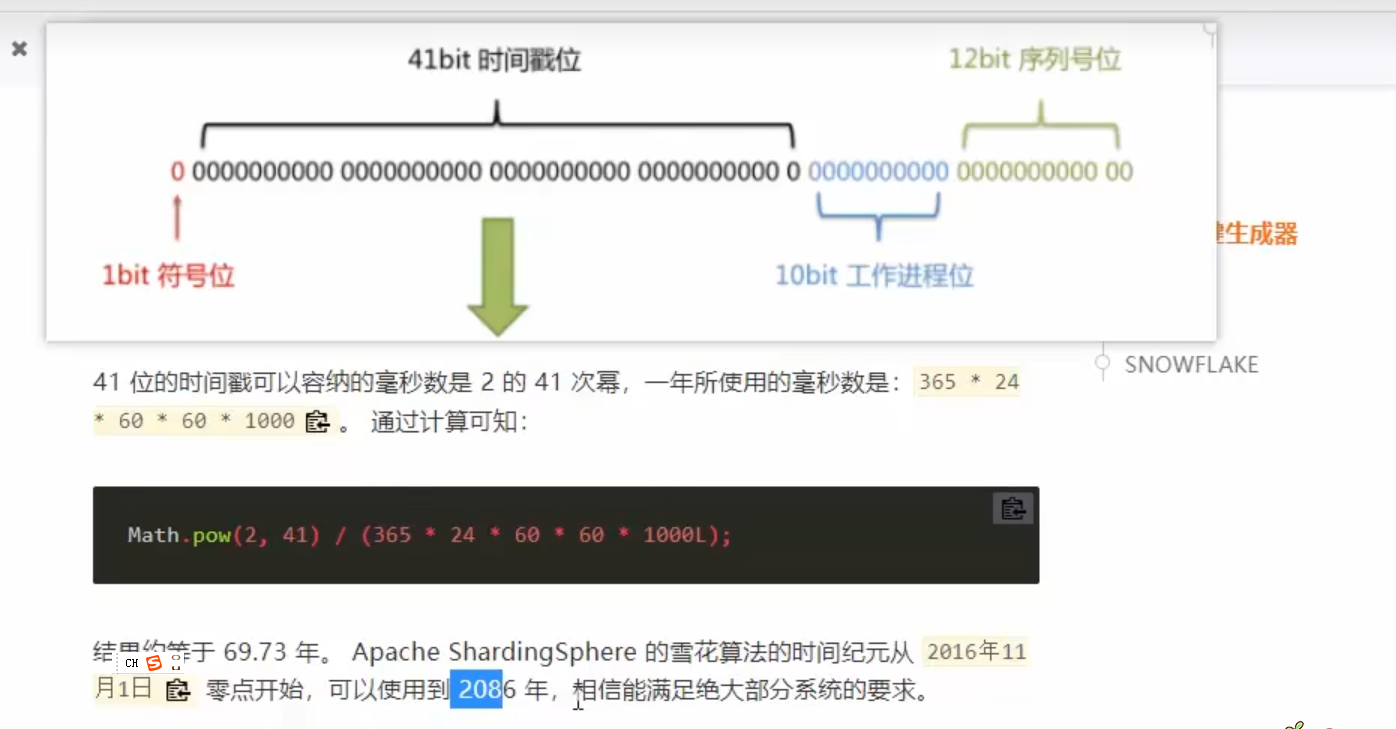
我们为了防止多个数据库出现主键同步
所以我们可以设置步长
例如
1开始和2开始
一个是 1 3 5 7
一个是 2 4 6 8
分布式序列配置(配置主键决策)
我们的分布式序列配置,是用来配置我们的主键生成策略的
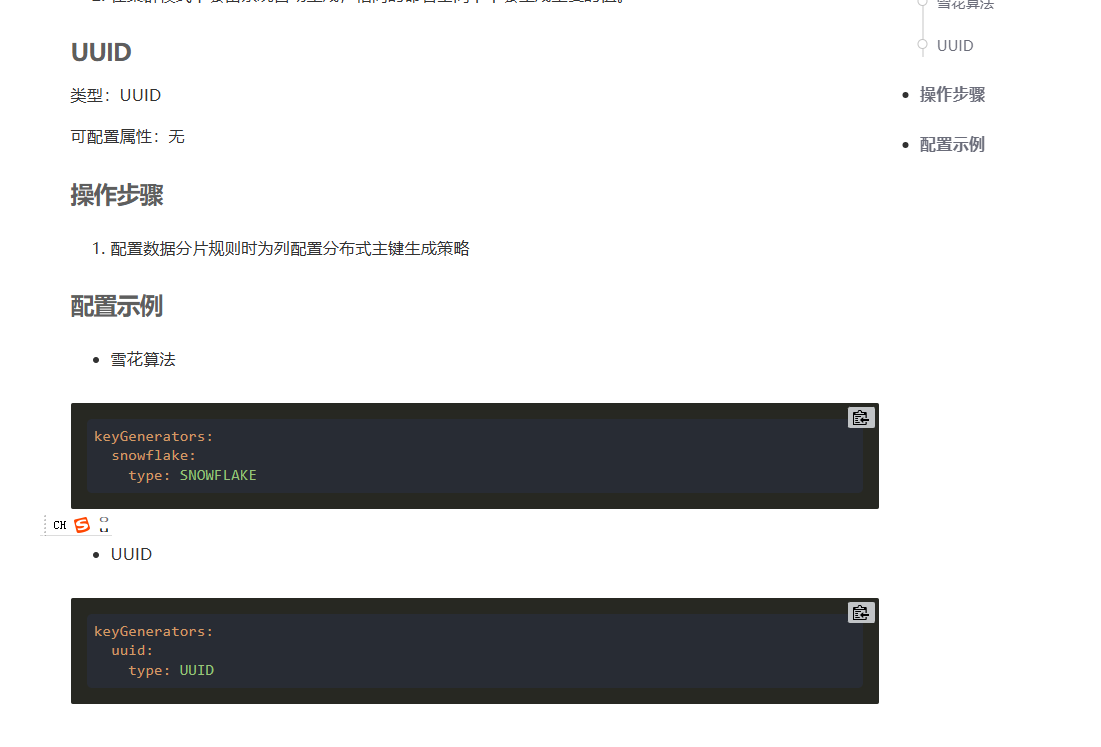
小问题
我们这里要指定类型为IdType.AUTO
如果是其他的话,它会默认使用mybatisplus的生成主键策略
我们这样子的话,就可以使用我们shardingsphere自己配置的策略
例如学法算法

多表关联和绑定表和广播表
小问题

数据插入
我们为了避免这两个表插入数据后,在不同的数据库里面
所以这两个分库和分表
我们要使用相同的分片策略
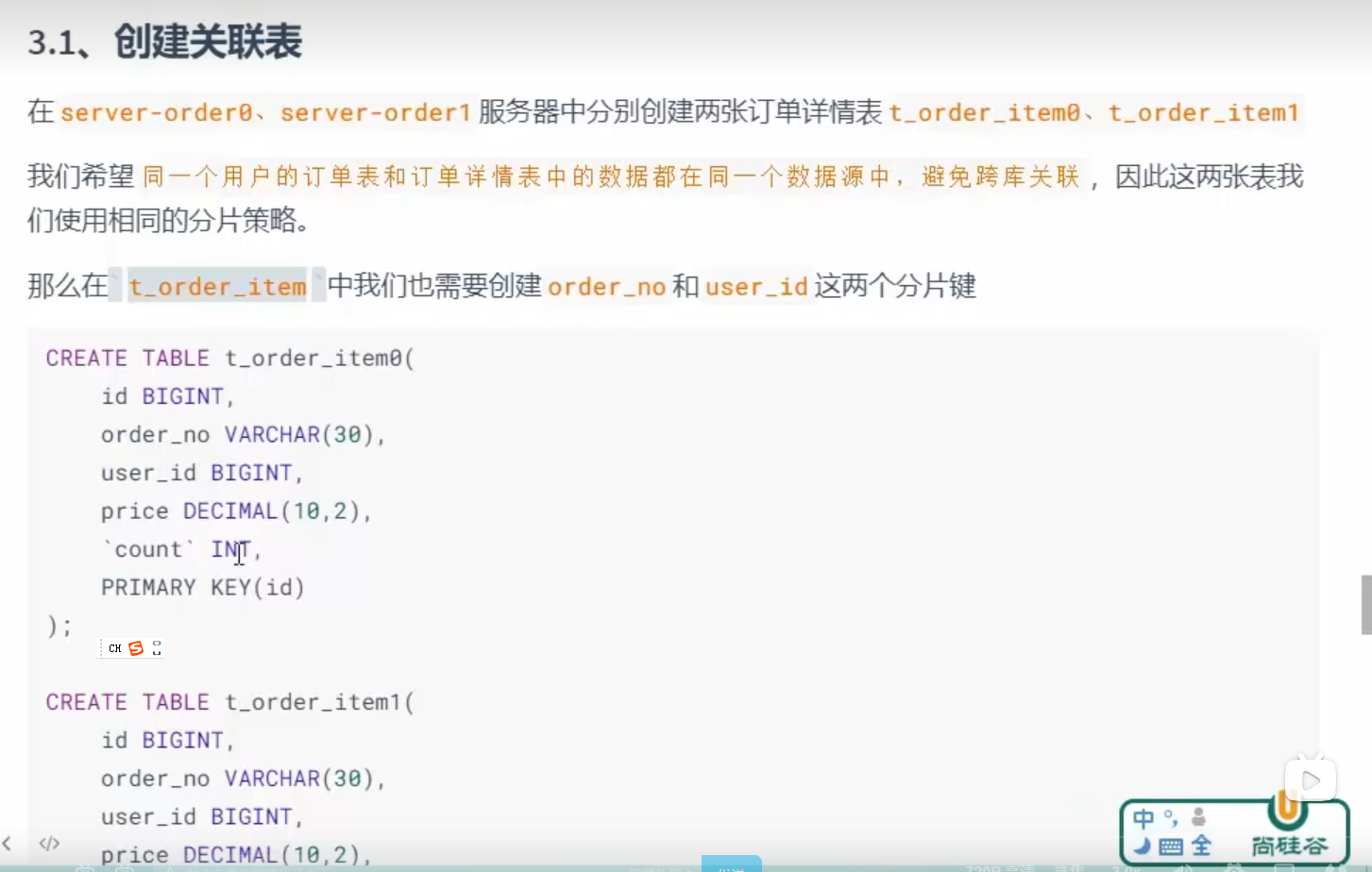
多表关联查询的问题
我们弄相同的分片策略,就可以查询到
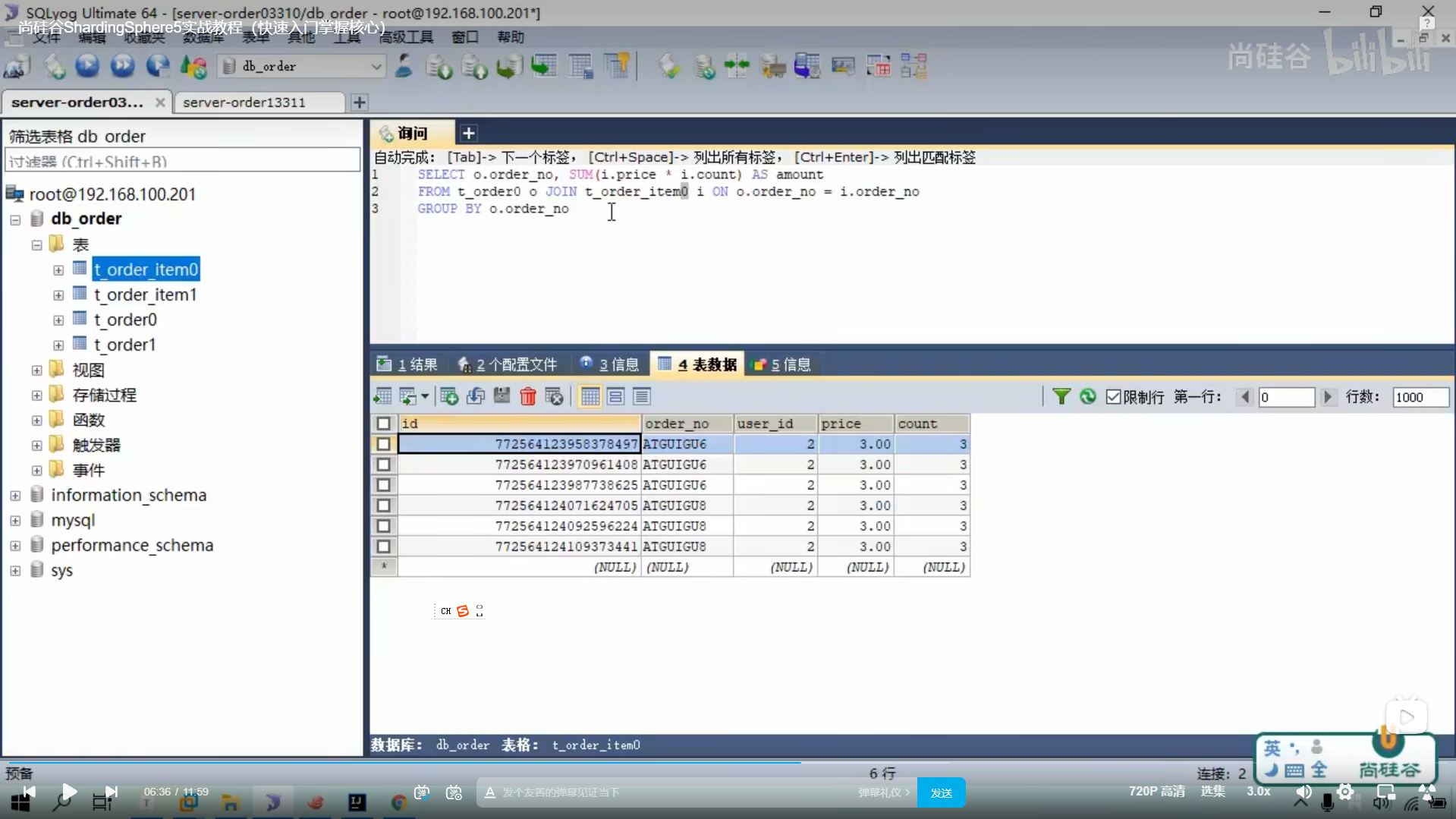
这样子我们才能形成在相同数据库里面的笛卡尔积查询
如果我们不配置相同的分片策略
那么我们就不能做到这种在相同数据库里面多表联查
到时候我们的多表联查甚至要跨数据库
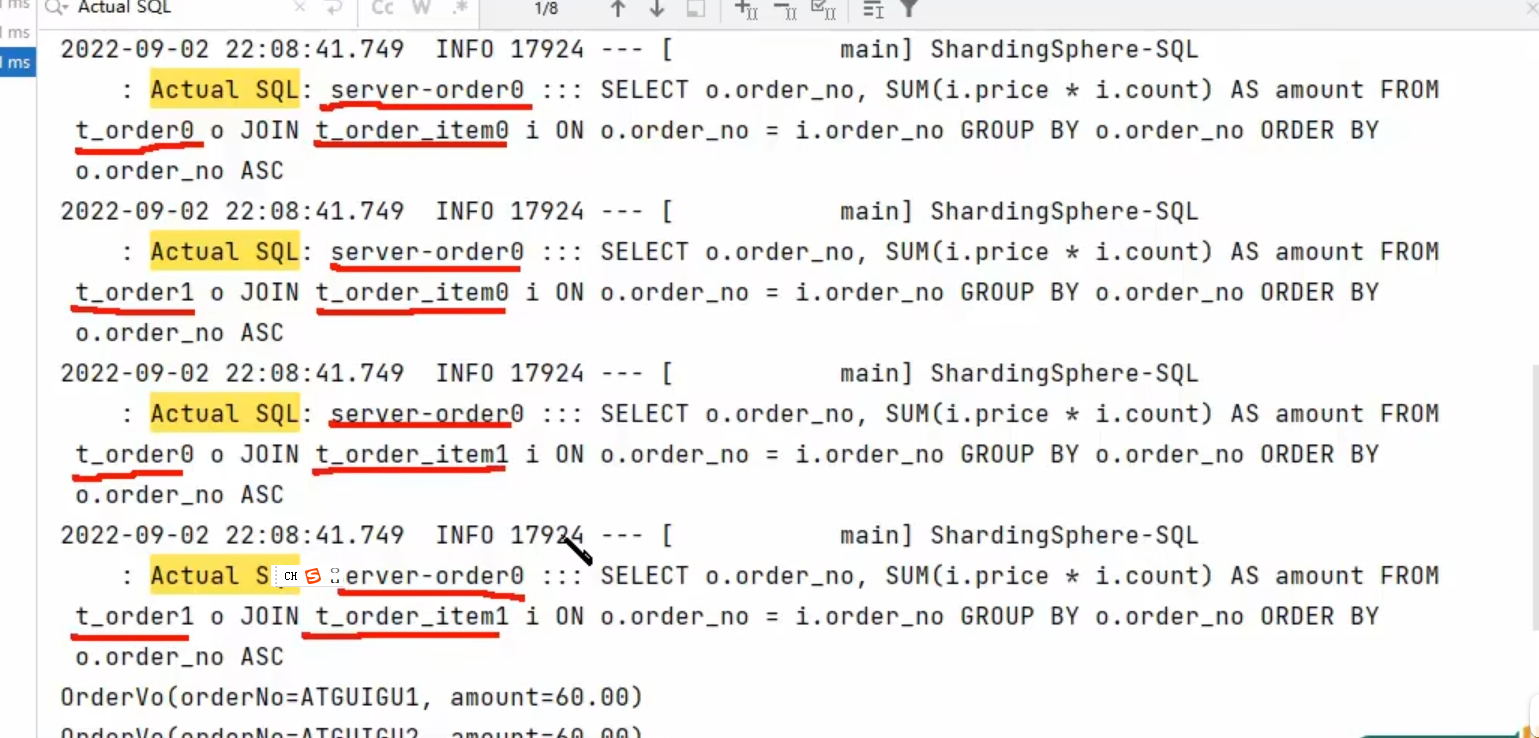
绑定表
因为我们是笛卡尔积查询
有些查询是没用的
这时候就有了一个概念
绑定表
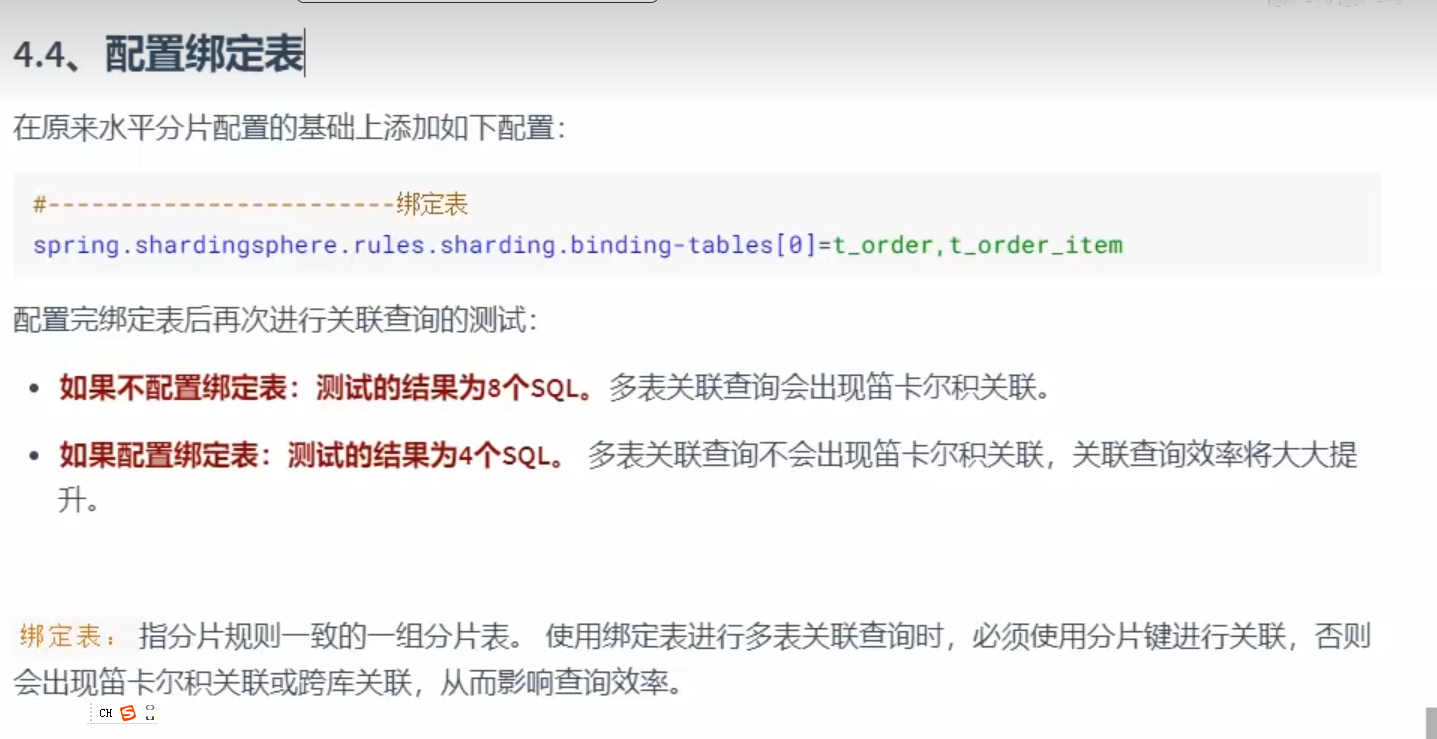
我们可以看官方文档配置里面
有一个绑定表配置
然后配置我们的逻辑表的表名就行了
使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则就会出现跨库关联和笛卡尔积关联,从而影响我们的查询效率
广播表
所有分片数据源中都存在的表

例如我们的3个数据库都有这个dict表
然后我们配置的时候要把这三个数据库的dict表都弄上去
例如这样子

和这种差不多

然后我们不配置分片策略
这样子它只要是插入这个表,那么我们的三个数据库的dict表都会插入数据