LQR 入门:以 “倒立摆” 仿真案例建模( LQR 是 MPC 的基础模块 - MPC 是 LQR 的泛化)
目录
1. 案例实战:不稳定的倒立摆
2. LQR 是什么?
3. 状态空间方程:LQR 的输入、输出
3.1 以倒立摆为例
4. LQR 如何解决问题:优化目标与方法
4.1 优化问题是什么?
4.2 补充:正定 / 半正定 矩阵
4.3 优化中的假设条件
4.4 LQR 是怎么优化的?(Riccati)
4.5 补充:LQR优化 vs 梯度下降
5. 代码实现 ( MATLAB + Python )
5.1 Python 实现 LQR 优化
5.2 输出结果 + 可视化
5.3 LQR 调试技巧
5.4 可观测 / 闭环稳定性分析
5.4.1 构造可观测性矩阵 O
5.4.2 计算秩并判断
5.4.3 闭环稳定性分析
5.4.4 直通通道 D (Feedthrough)
5.4.5 小结
6. 补充:LQR 的适用场景与条件
7. 小结
8. 番外篇:LQR vs MPC
8.1 LQR 优化的提出
8.2 MPC 优化的发展历史
8.3 LQR是MPC概念上的基石
8.4 总结 LQR 与 MPC 的关键异同
8.5 何时选择 LQR?何时选择 MPC?
机器人为何能够像杂技演员一样精确地平衡身体,甚至能后空翻?

LQR(线性二次调节器)则是 MPC(模型预测控制)提供了重要的理论基础和核心思想来源之一)
自动驾驶汽车是如何平稳地沿着车道行驶和避障变道的?

这背后往往隐藏着强大的控制理论,而 LQR(线性二次调节器)就是其中非常经典且实用的一种
- LQR(线性二次调节器)为 MPC(模型预测控制)提供了重要的理论基础和核心思想来源
大多数 LQR 的教程一上来就是复杂的数学公式,和教科书类似,让人望而却步。我们不妨换个方式,从一个有趣的物理模型——倒立摆——入手,用案例来理解公式。读完本篇,能够更好理解以下问题:
- LQR 到底是个啥?它控制的是什么?
- LQR 的“语言”:状态、输入、输出都是什么?
- LQR 是如何巧妙地解决控制问题的?
- LQR 为了“最优”做了哪些假设?优化的是什么?怎么优化的?
- 什么情况下可以用 LQR?(它的使用条件)
-
LQR vs MPC 有何关联?(番外篇)
本文部分参考自(这篇文章里还有倒立摆仿真教学,非常推荐进阶阅读):
LQR的理解与运用 第一期——理解篇-CSDN博客
1. 案例实战:不稳定的倒立摆
想象一下我们手掌上立着一根扫帚,是不是需要不停地移动手掌来保持平衡?我们今天要讨论的倒立摆模型就和这个类似:
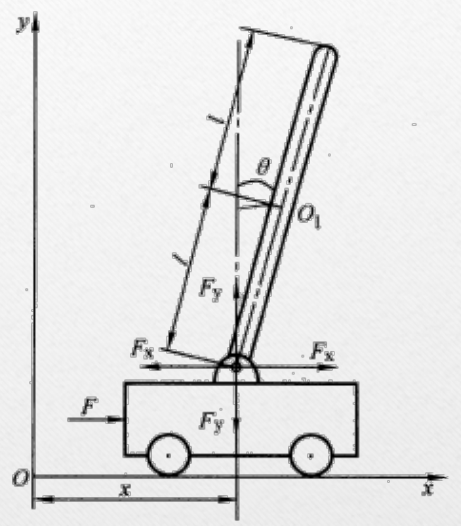
如图所示,我们有一个可以在水平轨道上移动的小车(质量 M),车上通过一个无摩擦的转轴连接着一根摆杆(质量 m,长度 L)。我们可以通过给小车施加一个水平力 F 来控制整个系统
目标: 我们希望小车能最终停在轨道的原点 (x=0),同时摆杆能稳定地保持在垂直向上的位置 (θ=0)
难点: 这个系统天生就是不稳定的。稍有扰动,摆杆就会倒下。我们需要设计一个聪明的控制器,根据当前的状态(小车位置、速度,摆杆角度、角速度)来实时计算出合适的控制力 F,让系统稳定在 目标 (摆杆稳定竖立) 的状态
2. LQR 是什么?
LQR (Linear Quadratic Regulator),线性二次调节器,顾名思义:
- Linear (线性): 它主要适用于线性系统,或者可以在某个工作点附近线性化的系统。也就是说,描述系统行为的数学方程是线性的(后面会讲倒立摆如何处理)
- Quadratic (二次): 它通过最小化一个二次型的代价函数(Cost Function)来评价控制效果的好坏。这个代价函数同时考虑了“任务完成得怎么样”(比如摆杆是否垂直,小车是否归位)和“付出了多少努力”(比如用了多大的力 F)
- Regulator (调节器): 它的目标通常是让系统从任意初始状态回到一个期望的平衡点(比如 x=0,θ=0),并维持在这个状态,抵抗扰动(各种误差)
所以,LQR 控制的是什么?
LQR 本身是一种设计控制器的方法。它最终的目标是计算出一个最优反馈增益矩阵 K。控制器利用这个 K,根据实时测量到的系统状态 x,计算出需要施加到系统上的控制输入 u,计算公式通常是 u = −Kx
![]()
在倒立摆案例中:
状态 x:小车位置、速度,摆杆角度、角速度
控制输入 u:给小车施加一个水平力 F
最优反馈增益矩阵 K:LQR 需要计算出的目标
对于倒立摆: LQR 会帮我们找到一个最佳的 K,让控制器根据小车的位置 (x)、速度 (x˙)、摆杆的角度 (θ) 和角速度 (θ˙) 这四个状态,计算出最优的水平力 F
3. 状态空间方程:LQR 的输入、输出
让我们明确一下 LQR 世界里的基本元素,以倒立摆为例:
- 一组线性微分方程(状态空间方程)来描述我们的系统: x˙ = Ax + Bu
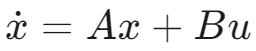
3.1 以倒立摆为例
- 控制输入 u (Control Input)
- 我们能施加给系统以改变其状态的外部作用
- 对于倒立摆,就是施加在小车上的水平力 F
- 因此,控制输入向量为 u = [F](这里只有一个输入)
- 状态向量 x (State Vector)
- 状态向量的时间导数 x˙ (Time Derivative of State Vector)
- x˙ 是状态向量 x 中每个元素对时间的导数。它表示系统状态随时间变化的速率
- 系统矩阵 A (System Matrix / State Matrix)
- A 矩阵描述了系统内部状态之间的相互影响,即在没有外部输入(u=0)的情况下,当前状态如何影响状态的变化率
- 它是一个 4×4 的矩阵,因为在倒立摆案例中,状态向量 x 有 4 个元素
- A 的计算需要基于倒立摆的物理模型:
- 系统组成: 一个质量为 M 的小车可以在水平轨道上移动,其上通过一个无摩擦的转轴连接一根长度为 L(指转轴到质心的距离)、质量为 m 的摆杆
倒立摆图片来源: LQR的理解与运用 第一期——理解篇-CSDN博客 - 关于导出 运动方程 (EoM) 和 线性化,咱这里就不展开推导 A 啦,直接基于常用物理建模给出 A 的一种可能的推导结果作为参考
- 这个矩阵的具体数值取决于倒立摆的物理参数(如小车质量 M、摆杆质量 m、摆杆长度 L、重力加速度 g、摩擦系数等)以及线性化的过程。举例来说:
- 第一行 [0 1 0 0] 表示 x˙cart=1⋅x˙cart,即第一个状态的导数(速度)就是第二个状态(速度)
- 第三行 [0 0 0 1] 表示 θ˙=1⋅θ˙,即第三个状态的导数(角速度)就是第四个状态(角速度)
- 第二行和第四行的元素 (a21,a22,...,a44) 则描述了小车加速度 (x¨cart) 和摆杆角加速度 (θ¨) 如何依赖于所有四个状态变量 (xcart,x˙cart,θ,θ˙)
- 例如,a23 不为零,表示摆杆角度 θ 的偏差会通过重力分量等引起小车的加速度
- a43 也不为零,表示角度偏差 θ 会引起恢复力矩或倾覆力矩,从而影响角加速度
- 在倒立摆例子中,类似地,a22,a42 也与系统中的阻尼或摩擦有关
- 输入矩阵 B (Input Matrix / Control Matrix)
- B 矩阵描述了外部控制输入 u 如何影响系统状态的变化率 x˙
- 在倒立摆例子中,控制输入是施加在小车上的水平力 F
- 因此,输入向量 u 是一个标量 (或者说 1x1 向量):
- B 矩阵则是一个 4×1 的列向量,因为它将 1 个输入映射到 4 个状态导数上
,与 A 类似,就不详细推导了,直接给一种结果:
- b1=0: 力 F 不直接影响小车的位置 x˙cart (它影响加速度)
- b2: 力 F 直接影响小车的加速度 x¨cart。这个值通常与小车和摆杆的总质量有关 (类似 1/(M+m) 的形式,基于如何建模)
- b3=0: 力 F 不直接影响摆杆的角度 θ˙ (它影响角加速度)
- b4: 力 F 通过作用在小车上,间接影响摆杆的角加速度 θ¨。这个值与质量、长度等参数有关,并且通常与 b2 的符号相反 (推小车会让杆向后倒)
- 具体的 B 矩阵元素同样取决于 物理参数 和 线性化,与 A 类似
- 将这些放在一起,x˙=Ax+Bu 这个方程展开就是:
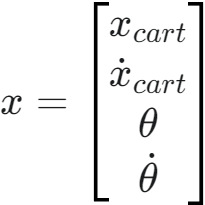



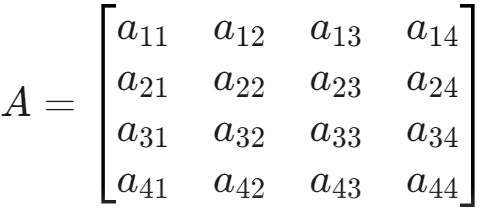
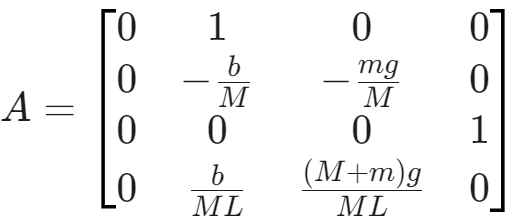
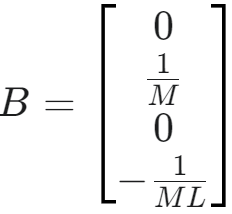
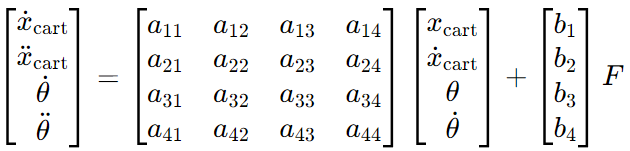
- 补充1:
- 通常情况下,对于一个特定的物理系统和选定的工作点(平衡点),A 和 B 是通过系统建模和线性化得到的,一旦计算出来,就被视为描述该系统在该工作点附近动态特性的 常量 矩阵,具体的计算过程就不展开啦
- 补充2:A 和 B 在某些情况下会“变化” (是题外话,可跳过)
- 物理参数变化:
- 如果倒立摆的物理参数改变了(比如摆杆上增加了负载导致质量 m 或质心位置改变),那么描述其动态特性的 A 和 B 矩阵 实际上 也应该相应改变
- 如果您仍然使用旧的 (A,B) 计算 K,控制效果可能会变差。这时,需要用新的物理参数重新计算 A 和 B,并可能需要重新计算 K
- 这就是鲁棒控制和自适应控制研究的问题
- 工作点漂移:
- 线性化是在一个特定的平衡点进行的。如果系统实际运行状态偏离这个平衡点太远,线性模型 (A,B) 可能就不再能准确地描述系统的非线性行为了
- 这时,基于这个 (A,B) 计算出的 K 可能效果不佳
- 一种处理方法是增益调度(Gain Scheduling),即在不同的工作点计算不同的 (A,B) 和对应的 K,并根据当前系统状态切换使用哪个 K
- 系统本身是时变的:
- 如果系统本身的参数就随时间变化(例如,火箭燃料消耗导致质量变化),那么系统模型就是线性时变(LTV)的,即 x˙(t)=A(t)x(t)+B(t)u(t)
- 这种情况下需要使用时变 LQR 理论,计算出的增益 K 也会是时变的 K(t)
- 补充3:
- 在标准的 LQR 设计流程中,我们首先确定一个描述系统的、固定的(时不变的) A 和 B 矩阵,然后基于它们来设计控制器
- LQR 的输出 (Controller Output / LQR Result): 具体怎么得到 K 在下一小节(四、优化目标)马上有展开
- 最核心的输出: 最优反馈增益矩阵 K。对于倒立摆,因为 x 是 4×1,u 是 1×1,所以 K 是一个 1×4 的行向量,记作 K = [k1, k2, k3, k4]
- 控制器的实时输出: 最优控制指令 u。它是通过 K 和当前状态 x 计算得到的:
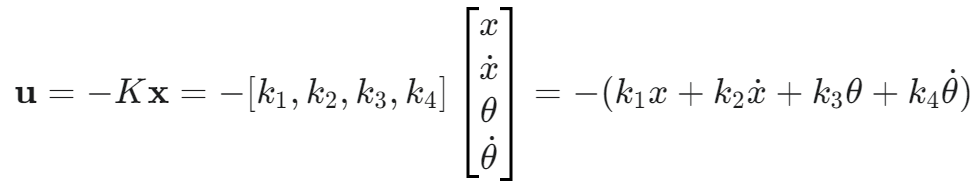
- 这个 u 就是我们需要施加的力 F
4. LQR 如何解决问题:优化目标与方法
LQR 的核心思想是优化 (Optimization)
4.1 优化问题是什么?
- 找到一个控制策略(即找到最优的 K),使得一个预先定义的 代价函数 J (Cost Function) 达到最小值
- 这个代价函数量化了我们对系统性能的要求
对于无限时间调节问题,标准的 LQR 代价函数 是:
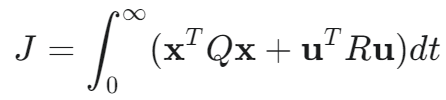
![]() :表示我们考虑从初始时刻到无穷远未来的整个过程的总代价
:表示我们考虑从初始时刻到无穷远未来的整个过程的总代价
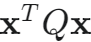 :状态代价项
:状态代价项 - 它惩罚状态 x 对平衡点 (0) 的偏离
- Q 是一个半正定的对称权重矩阵(通常是对角矩阵)
- Q 矩阵对角线上的元素 qii 越大,表示我们越不希望对应的状态 xi 偏离 0
- 对于倒立摆 x=[x,x˙,θ,θ˙]T, Q 可以是 diag(q1,q2,q3,q4)
- 如果 q3 很大,意味着我们非常在意摆杆角度 θ 的偏差,希望它尽快回零
- 如果 q1 很大,意味着我们很在意小车位置 x 的偏差
- 它惩罚状态 x 对平衡点 (0) 的偏离
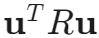 :控制代价项
:控制代价项 - 它惩罚控制输入 u 的大小(即控制能量的消耗)
- R 是一个正定的对称权重矩阵(对于单输入系统,R 是一个大于 0 的标量)
- R 越大,表示我们越不希望使用过大的控制力 F,倾向于更平缓、更节能的控制
- 它惩罚控制输入 u 的大小(即控制能量的消耗)
4.2 补充:正定 / 半正定 矩阵
- 正定 (Positive Definite)
- 半正定 (Positive Semi-definite)



4.3 优化中的假设条件
- 系统是线性的(或已成功线性化)
- 代价函数是二次型的
- 所有状态变量都是已知的(可测量或准确估计)
- 系统是可控(且可稳)的
- Q≥0 (半正定), R>0 (正定)
4.4 LQR 是怎么优化的?(Riccati)
LQR 理论运用了 变分法 或 动态规划(特别是 Hamilton - Jacobi - Bellman 方程)来求解这个优化问题
最优反馈增益 K 由以下公式给出:(这里的 B 就是上面 状态空间方程 的 B 矩阵,A 也是)
![]()
这里的 P 是一个 对称正定矩阵,它是下面这个著名的 代数里卡提方程 (Algebraic Riccati Equation, ARE) 的唯一正定解:
![]()
好消息是: 我们通常不需要手动去解这个复杂的矩阵方程!强大的数学软件库(如 MATLAB 中的 lqr() 函数,Python control 库中的 lqr() 函数)可以帮我们输入 A,B,Q,R 矩阵,然后直接计算出最优的 K 和 P
4.5 补充:LQR优化 vs 梯度下降
虽然 LQR 也是在寻找一个最优解来最小化代价函数:
![]()
但它的求解方式与典型的梯度下降有显著不同:
求解方式不同:
- 梯度下降 (Gradient Descent): 是一种迭代优化算法。它从一个初始猜测值开始,计算代价函数关于参数(比如神经网络的权重,或者这里的控制增益 K)的梯度,然后沿着梯度的反方向更新参数,步长由学习率控制。这个过程不断重复,直到收敛到(可能是局部的)最优解。它通常用于无法直接求解最优解的复杂、非线性问题
- LQR 优化: 对于给定的线性系统 (x˙=Ax+Bu) 和二次型代价函数,LQR 有一个解析解(或可以通过专门的数值方法精确求解)。它通过求解代数里卡提方程 (Algebraic Riccati Equation, ARE) 来直接计算出最优的反馈增益矩阵 K (u=−Kx)。这个解是全局最优的,不需要像梯度下降那样迭代搜索
没有"学习率":
- 因为 LQR 不是通过迭代逼近的方式来优化增益 K 本身,所以它没有类似于梯度下降中的“学习率”这个概念来控制优化步骤的大小。最优的 K 是根据系统的 A,B 矩阵以及我们设定的 Q,R 权重矩阵,通过解 ARE 直接计算出来的
可以类比的地方:
- 目标相似: 两者都是为了最小化某个代价函数。
- 参数调整(间接): 在 LQR 中,你调整的是 Q 和 R 矩阵。这类似于在梯度下降中调整模型结构或正则化项,但 Q 和 R 的调整通常是基于经验或试错,而不是像梯度下降那样自动化的迭代过程。改变 Q 和 R 会导致计算出的最优 K 不同。
5. 代码实现 ( MATLAB + Python )
MATLAB 中的 lqr() 函数 的用法可以参考:LQR的理解与运用 第一期——理解篇-CSDN博客
- 想进一步学习可咨询GPT:用python/MATLAB 完整实现倒立摆的LQR优化
- 这里以 Python 为例
5.1 Python 实现 LQR 优化
import numpy as np
import scipy.linalg
import matplotlib.pyplot as plt
import control # control 系统库, 需要安装 pip install control# --- 系统参数定义 ---
M = 0.5 # 小车质量 (kg)
m = 0.2 # 摆杆质量 (kg)
b = 0.1 # 小车摩擦系数 (N/m/s) # 这里我们加入摩擦力使模型更实际
I = 0.006 # 摆杆转动惯量 (kg*m^2)
g = 9.8 # 重力加速度 (m/s^2)
l = 0.3 # 摆杆长度(到质心的距离) (m)# 系统状态空间表达式 x_dot = Ax + Bu
# 状态向量 x = [x, x_dot, theta, theta_dot]^T
# x: 小车位置
# x_dot: 小车速度
# theta: 摆杆角度 (与垂直方向的夹角, 向上为0)
# theta_dot: 摆杆角速度# 基于以上参数推导线性化模型 (在 theta=0 附近)
# 参考文献: http://ctms.engin.umich.edu/CTMS/index.php?example=InvertedPendulum§ion=SystemModeling
# 注意: 不同文献推导结果可能因符号定义或简化假设略有不同, 这里采用一种常见的形式
p = I*(M+m) + M*m*l**2 # Denominator term
A = np.array([[0, 1, 0, 0],[0, -(I+m*l**2)*b/p, (m**2*g*l**2)/p, 0],[0, 0, 0, 1],[0, -(m*l*b)/p, m*g*l*(M+m)/p, 0]
])B = np.array([[0],[(I+m*l**2)/p],[0],[m*l/p]
])# 定义输出 C 和 D 矩阵 (如果需要, 这里我们假设直接观测所有状态)
C = np.eye(4) # 观测所有状态
D = np.zeros((4,1))print("系统矩阵 A:\n", A)
print("\n输入矩阵 B:\n", B)# --- LQR 控制器设计 ---
# LQR 代价函数 J = integral(x'Qx + u'Ru) dt
# Q 矩阵: 状态误差权重矩阵 (对角阵)
# 值越大, 表示越希望对应的状态变量快速收敛到0
# R 矩阵: 控制输入权重 (通常为标量或对角阵)
# 值越大, 表示越希望消耗更少的控制能量 (输入 u 更小)Q = np.diag([1.0, 0.1, 10.0, 0.1]) # 对位置误差、角度误差给予较高权重
# Q = np.diag([10.0, 1.0, 100.0, 1.0]) # 另一个例子,更强调角度稳定
R = np.array([[0.01]]) # 控制输入的权重# 使用 control 库求解连续时间代数里卡提方程 (CARE)
# K, S, E = control.lqr(A, B, Q, R) # control 库直接计算 LQR 增益
# 或者使用 scipy.linalg 手动计算
# 求解 CARE: A'P + PA - PBR^-1B'P + Q = 0
P = scipy.linalg.solve_continuous_are(A, B, Q, R)
# 计算 LQR 增益 K = R^-1 * B' * P
K = np.linalg.inv(R) @ B.T @ Pprint("\nLQR 增益矩阵 K:\n", K)# 闭环系统矩阵 A_cl = A - B*K
A_cl = A - B @ K
print("\n闭环系统矩阵 A_cl = A - BK:\n", A_cl)# 检查闭环系统的极点 (特征值), 确保稳定 (所有实部为负)
eigenvalues, _ = np.linalg.eig(A_cl)
print("\n闭环系统特征值 (极点):\n", eigenvalues)
if np.all(np.real(eigenvalues) < 0):print("闭环系统稳定!")
else:print("警告: 闭环系统可能不稳定!")# --- 仿真设置 ---
dt = 0.02 # 仿真步长 (s)
T = 10.0 # 总仿真时间 (s)
n_steps = int(T / dt) # 仿真步数
time = np.linspace(0, T, n_steps + 1) # 时间向量# 初始状态 [x, x_dot, theta, theta_dot]
# x0 = np.array([0.0, 0.0, 0.1, 0.0]) # 初始角度偏差 0.1 rad (约 5.7 度)
x0 = np.array([0.5, 0.0, np.pi/6, 0.0]) # 初始位置 0.5m, 初始角度偏差 pi/6 rad (30度)# 记录状态和控制输入的历史
x_history = np.zeros((4, n_steps + 1))
u_history = np.zeros((1, n_steps))
disturbance_history = np.zeros((4, n_steps)) # 记录动态误差历史x_history[:, 0] = x0 # 设置初始状态# --- 动态误差(扰动)参数 ---
# 假设扰动主要作用在加速度上 (x_ddot 和 theta_ddot)
# 这对应于状态向量的第2和第4个导数
# 我们将扰动直接加到状态导数上: x_dot = Ax + Bu + d
disturbance_mean = np.array([0.0, 0.0, 0.0, 0.0]) # 扰动均值 (可以设为非零模拟持续干扰)# 扰动标准差,控制扰动幅度
# 只在前两个状态(位置和速度相关)和后两个状态(角度和角速度相关)上施加不同扰动
disturbance_std_dev = np.array([0.0, 0.5, 0.0, 0.8]) # 例如: 对速度和角速度施加扰动# --- 仿真循环 ---
x_current = x0.reshape(4, 1) # 当前状态 (列向量)for i in range(n_steps):# 1. 计算当前控制输入 u = -Kxu_current = -K @ x_current# --- (可选) 增加控制输入饱和限制 ---# max_force = 10.0 # 最大控制力# u_current = np.clip(u_current, -max_force, max_force)# ----------------------------------# 2. 生成当前时间步的动态误差 (扰动)# disturbance = np.random.normal(disturbance_mean, disturbance_std_dev).reshape(4, 1)# 更真实一点:扰动通常影响系统的物理动态,即影响加速度项# 这里我们简化处理,直接加在状态导数上,选择性地加在某些分量上noise = np.random.randn(4) * disturbance_std_dev # 生成符合标准差的随机数disturbance = noise.reshape(4, 1)# 3. 计算状态导数 x_dot = Ax + Bu + disturbancex_dot = A @ x_current + B @ u_current + disturbance# 4. 使用欧拉法更新状态 x_next = x_current + dt * x_dotx_next = x_current + dt * x_dot# 5. 记录历史数据x_history[:, i+1] = x_next.flatten() # 存为行向量的一维形式u_history[:, i] = u_current.flatten()disturbance_history[:, i] = disturbance.flatten() # 记录当前步施加的扰动# 6. 更新当前状态x_current = x_next# --- 结果可视化 ---
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用于正常显示负号fig, axs = plt.subplots(3, 1, figsize=(10, 12), sharex=True)# 图1: 小车位置和摆杆角度
axs[0].plot(time, x_history[0, :], label='小车位置 x (m)')
axs[0].plot(time, x_history[2, :], label='摆杆角度 theta (rad)')
axs[0].set_ylabel('位置 / 角度')
axs[0].set_title('倒立摆 LQR 控制仿真 (带动态扰动)')
axs[0].legend()
axs[0].grid(True)# 图2: 控制输入 (力)
axs[1].plot(time[:-1], u_history[0, :], label='控制力 u (N)')
axs[1].set_ylabel('控制力 (N)')
axs[1].legend()
axs[1].grid(True)# 图3: 施加的动态误差 (扰动)
# 只绘制我们施加了非零标准差的扰动分量
if disturbance_std_dev[1] > 0:axs[2].plot(time[:-1], disturbance_history[1, :], label=f'速度扰动 (std={disturbance_std_dev[1]:.2f})', alpha=0.7)
if disturbance_std_dev[3] > 0:axs[2].plot(time[:-1], disturbance_history[3, :], label=f'角速度扰动 (std={disturbance_std_dev[3]:.2f})', alpha=0.7)
axs[2].set_xlabel('时间 (s)')
axs[2].set_ylabel('扰动值')
axs[2].set_title('施加的动态误差(过程噪声)')
axs[2].legend()
axs[2].grid(True)plt.tight_layout()
plt.show()# --- (可选) 打印最终状态 ---
print("\n仿真结束时状态:")
print(f" 小车位置 x: {x_history[0, -1]:.4f} m")
print(f" 小车速度 x_dot: {x_history[1, -1]:.4f} m/s")
print(f" 摆杆角度 theta: {x_history[2, -1]:.4f} rad ({(x_history[2, -1]*180/np.pi):.2f} 度)")
print(f" 摆杆角速度 theta_dot: {x_history[3, -1]:.4f} rad/s")5.2 输出结果 + 可视化
系统矩阵 A:[[ 0. 1. 0. 0. ][ 0. -0.18181818 2.67272727 0. ][ 0. 0. 0. 1. ][ 0. -0.45454545 31.18181818 0. ]]输入矩阵 B:[[0. ][1.81818182][0. ][4.54545455]]LQR 增益矩阵 K:[[-10. -10.94574442 59.59388424 10.3435379 ]]闭环系统矩阵 A_cl = A - BK:[[ 0. 1. 0. 0. ][ 18.18181818 19.7195353 -105.67978952 -18.80643255][ 0. 0. 0. 1. ][ 45.45454545 49.29883825 -239.69947381 -47.01608136]]闭环系统特征值 (极点):[-12.29704127+0.95268219j -12.29704127-0.95268219j-1.35123177+1.04994761j -1.35123177-1.04994761j] 闭环系统稳定!仿真结束时状态:小车位置 x: 0.0117 m小车速度 x_dot: -0.0318 m/s摆杆角度 theta: -0.0030 rad (-0.17 度)摆杆角速度 theta_dot: -0.0167 rad/s
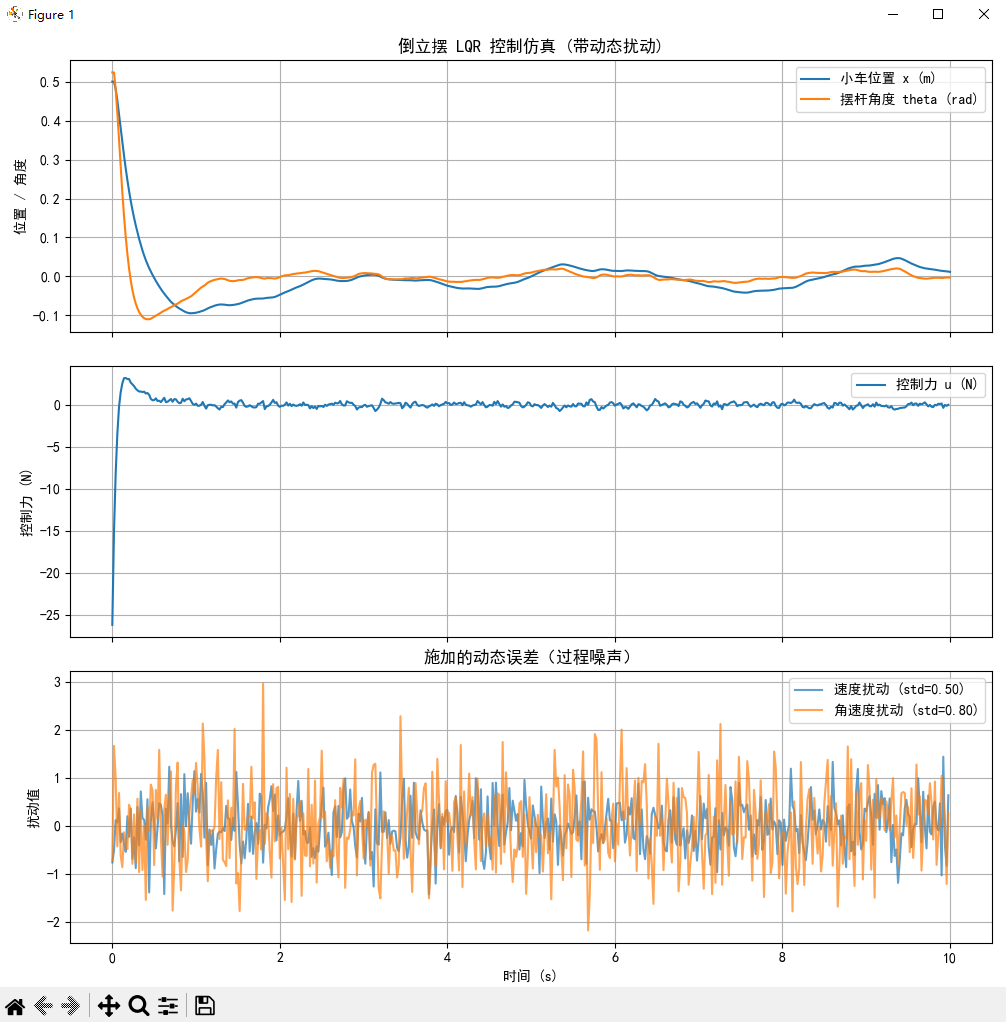
- LQR控制器成功地将倒立摆从小车位置和摆杆角度的初始偏差(约0.5m和0.5rad)快速稳定到平衡点(零附近)
- 控制力在初始阶段作用较大以迅速纠正偏差,随后减小并持续作用以抵消扰动,保持系统稳定
- 尽管存在持续的动态随机扰动(速度和角速度噪声),系统状态(位置和角度)仍能保持在零值附近小幅波动,显示了控制器的鲁棒性
5.3 LQR 调试技巧
- 建模与线性化: 建立倒立摆的非线性动力学方程,然后在目标平衡点 x=0,u=0 处进行线性化,得到系统矩阵 A 和 B
- 选择权重 Q 和 R: 这是 LQR 设计中最具工程艺术的一步!我们需要根据控制目标来“调试” Q 和 R 的值
- 想让摆杆 θ 快速稳定?增大 Q 中对应 θ 和 θ˙ 的权重 q3,q4
- 想让小车 x 精确归位?增大 Q 中对应 x 和 x˙ 的权重 q1,q2
- 想让控制力 F 更平缓,节省能量?增大 R 的值
- 通常需要反复试验和仿真,观察系统响应,找到一组满意的 Q 和 R。
- 求解 K: 使用软件工具,输入 A,B,Q,R,调用 lqr 函数,得到最优增益 K=
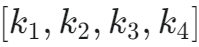
- 实施控制: 在我们的控制程序中,实时读取传感器测量的状态 x,x˙,θ,θ˙,然后计算控制力
F =![]() ,并将这个力施加到小车上
,并将这个力施加到小车上
5.4 可观测 / 闭环稳定性分析
5.4.1 构造可观测性矩阵 O
对于 n 维系统,
x˙ = Ax + Bu, y = Cx + Du
![]()
可观测性矩阵定义为
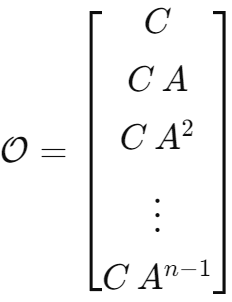
在我们上面的 Python 仿真倒立摆中,n=4,且我们设定
C = np.eye(4)所以
O = np.vstack([C,C @ A,C @ A @ A,C @ A @ A @ A
])
5.4.2 计算秩并判断
系统可观测的充要条件是
rank(O) = n.
![]()
在 NumPy 中可以这样写:
import numpy as np# 构造可观测性矩阵
O = np.vstack([C @ np.linalg.matrix_power(A, i) for i in range(4)])
rank_O = np.linalg.matrix_rank(O)print("可观测性矩阵 O:\n", O)
print("秩 rank(O) =", rank_O)
if rank_O == 4:print("系统可观测 ✅")
else:print("系统不可观测 ⚠️")由于我们用了 C=,O 自然有满秩 4,系统是可观测的
5.4.3 闭环稳定性分析
设计完 LQR 控制器后,我们已经在代码里计算了闭环系统矩阵
Acl=A−B K,
![]()
并求出了它的特征值(极点):
A_cl = A - B @ K
eigenvalues, _ = np.linalg.eig(A_cl)
print("闭环系统极点:", eigenvalues)判断闭环系统是否稳定,就是看这些极点的实部是否都小于零:
if np.all(np.real(eigenvalues) < 0):print("闭环系统稳定 ✅")
else:print("闭环系统可能不稳定 ⚠️")-
实部 < 0:系统对任何初始偏差都会指数收敛到平衡点,闭环稳定
-
存在实部 ≥ 0:说明某些模式不衰减或发散,需要调整 Q、R 或加饱和/滤波等措施
5.4.4 直通通道 D (Feedthrough)
在完整的“可观测性 → 闭环稳定性”检查流程中, D 矩阵(直通矩阵)的角色虽然不像 C 那样直接影响可观测性,也不像闭环极点那样决定稳定性,但它在建模、仿真和控制器设计中依然有以下关键作用:
如果某些输出分量对输入 u “立刻”发生响应(没有经过状态动态),就要通过 D 来描述
例如在电路系统中,电压传感器可能会瞬间反映给定的输入电压
在机械系统中,力的变化可能瞬时通过测力计反馈到测量值
- D 不影响可观测性:即使 D≠0,只要 C 满足秩条件,系统依然可观测
- D 不参与极点计算,故不影响闭环稳定性判据
虽然我们的 Python 仿真代码里把
D = np.zeros((4,1))设置为了全零(意味着没有直通分量),但如果你想观察带直通的输出,可以这样做:
# 假设 u_history 和 x_history 已记录
y_history = C @ x_history + D @ u_history然后将 y_history 画出,或传给滤波/辨识算法做进一步分析
-
若 D ≠ 0,
y_history中就会立刻包含每一步的控制输入成分,输出曲线会“叠加”一条与 u(t) 同步的直通响应 -
若 D = 0(本例情况),输出就是纯粹的状态映射,完全由 x(t) 决定
5.4.5 小结
-
可观测性分析:
-
用输出矩阵 C 和系统矩阵 A 构造可观测性矩阵 O
-
检查 rank(O) 是否等于状态维度
-
-
闭环稳定性分析:
-
先用 LQR 算得反馈增益 K,构造闭环矩阵 Acl=A−BK
-
计算其特征值,验证所有特征值实部均为负
-
这样,我们就完成了从“能否看清系统状态”(可观测性)到“加上 LQR 控制后系统是否稳定”(闭环性/闭环稳定性)的完整检查流程
仿真与传递函数
- D 不影响可观测性,也不参与极点计算
- D 决定了输出对输入的“零延迟”响应和高频增益,当我们在仿真或设计前馈滤波时需要特别注意它的值
6. 补充:LQR 的适用场景与条件
要想使用 LQR,需要满足一些前提条件:
- 系统模型已知且线性(或可线性化):我们需要能够用一组线性微分方程(状态空间方程)来描述我们的系统: x˙ = Ax + Bu
- x 是系统的状态向量
- u 是控制输入向量
- A 和 B 是描述系统动力学特性的矩阵
(公式中每个字母的对应倒立摆案例的具体内容在4小节有展开讲,这也是理解LQR的关键)
- 重要提示: 倒立摆的物理模型本质上是非线性的。但 LQR 要求线性模型。怎么办?我们通常在目标平衡点(θ=0)附近对非线性模型进行线性化处理,得到适用于该点附近的线性模型 A 和 B。这意味着 LQR 控制器在摆杆角度偏差不大时效果最好
- 系统可控 (Controllable): 必须保证我们的控制输入 u 确实能够影响到我们关心的所有系统状态 x。对于倒立摆,力 F 必须能够影响小车的位置/速度和摆杆的角度/角速度。幸运的是,倒立摆系统通常是可控的
- 状态可测或可估计: 标准的 LQR 假设系统的所有状态 x 都是可以实时测量得到的。如果某些状态无法直接测量,则需要设计状态观测器(State Estimator,如卡尔曼滤波器)来估计它们,但这会引出更复杂的 LQG(线性二次高斯)控制问题,我们入门篇暂不深入
- 代价函数为二次型: 性能指标 J 必须是状态 x 和控制 u 的二次函数形式(代价函数J在五小节有展开)
7. 小结
- LQR 是强大而优雅的控制设计工具
- 它通过最小化一个综合考虑状态误差和控制能耗的二次型代价函数,为线性系统(或可线性化的系统)找到最优的线性状态反馈控制器
- 其核心在于通过求解代数 里卡提 (Riccati) 方程来获得最优反馈增益 K
- 虽然背后的数学推导复杂,但借助现代软件工具,应用 LQR 变得相对容易
- 通过调整 Q 和 R 权重矩阵,工程师可以在 系统响应速度 和 控制能量消耗 之间进行权衡,实现期望的控制效果
8. 番外篇:LQR vs MPC
8.1 LQR 优化的提出
LQR(Linear Quadratic Regulator,线性二次型调节器)是现代控制理论中发展最早且最为成熟的状态空间设计方法之一
- 理论形成:LQR 的理论基础建立在状态空间法和最优控制理论之上。随着 20 世纪 50 年代末至 60 年代现代控制理论的兴起,线性系统的最优控制问题被深入研究
- 发展与应用:LQR 理论成熟后,借助 Matlab 等工具强大的仿真能力,得以广泛应用于航空航天、机器人控制等领域
8.2 MPC 优化的发展历史
MPC(Model Predictive Control,模型预测控制)是一种基于模型的先进控制策略,通过预测系统未来状态并滚动优化控制序列来实现目标
- 起源与早期探索(20 世纪 70 年代):MPC 的早期概念形成于 20 世纪 70 年代,如 J. Richalet 和 A. Rault 提出的动态矩阵控制(DMC)算法,成为 MPC 的前身之一。这一阶段,MPC 在工业过程控制中初步尝试,解决简单的预测与优化问题
- 理论发展与推广(20 世纪 80-90 年代):80 年代,MPC 开始受到更广泛关注,Qin Shen 和 John MacGregor 提出模型算法控制(MAC)。随着计算机技术发展,80 年代末 MPC 在化工、石油等工业领域实际应用。90 年代,MPC 理论进一步丰富,出现有限时域控制、无限时域控制等多种算法,明确处理输入输出约束,提升了对复杂系统的适应性
- 多领域应用与现代化(21 世纪至今):2000 年后,MPC 在汽车、航空、能源等领域广泛应用。2010 年以来,伴随计算能力提升与优化算法改进,MPC 变得更高效灵活,拓展至非线性系统(如非线性 MPC)、混合系统(混合 MPC)等场景,在航天器对接、智能车辆控制、工业过程优化等前沿领域发挥重要作用,成为处理复杂动态系统控制问题的主流技术之一
8.3 LQR是MPC概念上的基石
我们已经看到 LQR 如何为倒立摆设计出一个优雅的反馈控制器。在控制领域,我们可能还经常听到另一个“明星级”选手——模型预测控制 (Model Predictive Control, MPC)。它和 LQR 有什么不同?难道仅仅是一个离线算好 K,一个需要在线不停计算吗?
LQR(线性二次调节器)为MPC(模型预测控制)提供了重要的理论基础和核心思想来源
可以说LQR是MPC概念上的基石或前身之一,原因如下:
-
最优控制思想的传承: LQR 是最优控制理论中一个非常经典和基础的成果。它系统地解决了如何为线性系统设计一个能最小化二次型性能指标(代价函数)的反馈控制器的问题。MPC 正是继承和发展了这种基于模型进行预测并优化控制输入以最小化未来代价的核心思想
-
代价函数的设计: MPC 中最常用的代价函数形式仍然是二次型的,这直接借鉴了LQR的设计思路,因为它能很好地平衡跟踪误差和控制能量消耗,并且在数学上性质良好(尤其是在与线性模型结合时)
-
线性MPC与LQR的直接联系: 如前所述,当MPC应用于线性系统,采用二次型代价函数,并且没有有效约束时,其在每个时间步求解的优化问题本质上就是一个有限时域的LQR问题。这显示了两者在特定情况下的紧密联系
8.4 总结 LQR 与 MPC 的关键异同
- 线性 vs. 非线性/约束: LQR 基本上是为无约束线性系统设计的“甜点”,而 MPC 更像是能处理复杂地形(非线性、带约束)的“越野车”。约束处理是 MPC 的“杀手锏”
- 全局 vs. 滚动局部: LQR 着眼于整个未来的全局最优(特定条件下),给出固定策略;MPC 则不断地“向前看一小段路”,在当前状态下做出局部最优决策,并持续修正。这种滚动优化的方式让 MPC 对模型误差和扰动有更好的适应性
- 离线 vs. 在线 (计算量差异): LQR 的核心计算(求 K)可以离线完成,运行时计算负担轻。MPC 的核心计算(求解优化问题)必须在线进行,计算量大得多。所以,在线/离线确实是一个重要区别,但这源于它们解决问题的根本方法不同,特别是 MPC 需要在线预测和处理约束的能力
- 代价函数灵活性: MPC 的代价函数形式更灵活,更容易匹配一些非标准的性能要求
8.5 何时选择 LQR?何时选择 MPC?
- 选择 LQR:
- 系统基本是线性的,或在工作点附近线性化足够精确
- 主要目标是调节(稳定在某个点)
- 系统约束不严格,或可以通过饱和等简单方式处理
- 计算资源有限,或者对实时性要求非常高(控制周期极短)
- 作为 MPC 或其他更复杂控制器的设计基础或性能基准
- 选择 MPC:
- 系统存在显著的非线性。
- 系统有严格的状态或输入约束必须满足(例如执行器饱和、安全边界)
- 需要进行轨迹跟踪控制,而不仅仅是点稳定
- 性能要求很高,愿意投入更多的计算资源
- 系统模型会随时间变化或存在不确定性(MPC 的滚动优化有一定适应能力)
有趣的关系: 某种程度上,可以认为无约束、无限时域的线性 MPC 问题,其解会趋近于 LQR 的解。LQR 可以看作是 MPC 的一个非常特殊的基础情况。在设计 MPC 时,其代价函数中的 Q 和 R 矩阵也常常借鉴 LQR 的调参思想