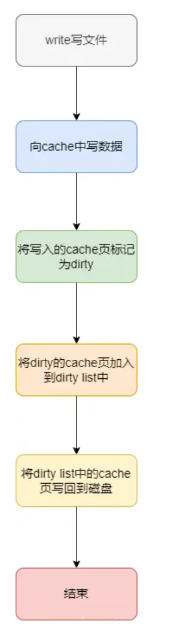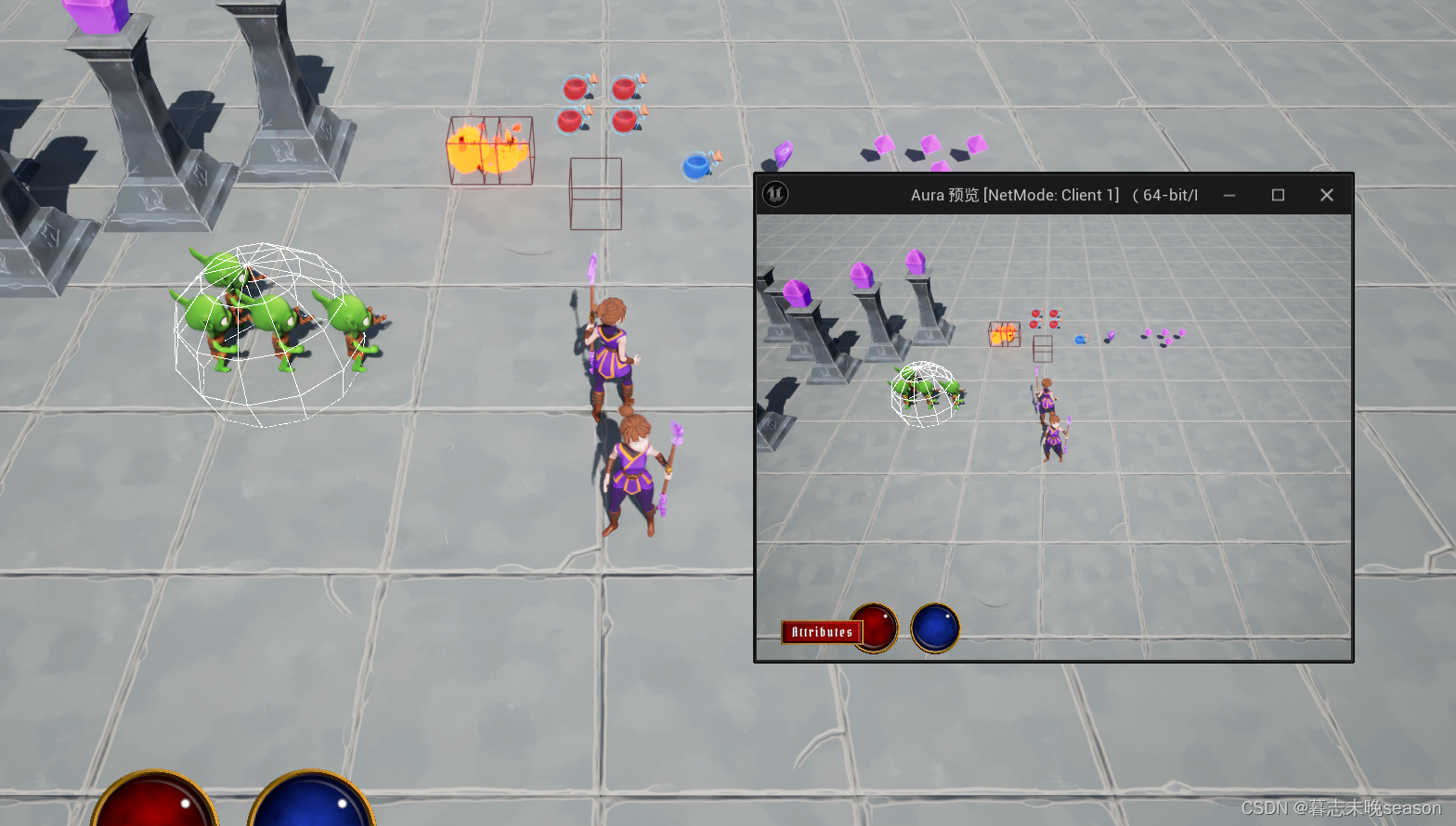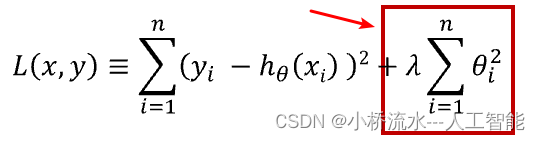
L2正则化是一种用于机器学习和统计建模中的技术,旨在控制模型的复杂度,并防止过拟合。它通过在模型的损失函数中添加一个惩罚项来实现这一目的。这个惩罚项是模型权重的平方和,乘以一个正则化参数
λ。这样可以迫使模型权重趋向于较小的值,从而降低模型的复杂度。
数学上,L2正则化的公式可以表示为:
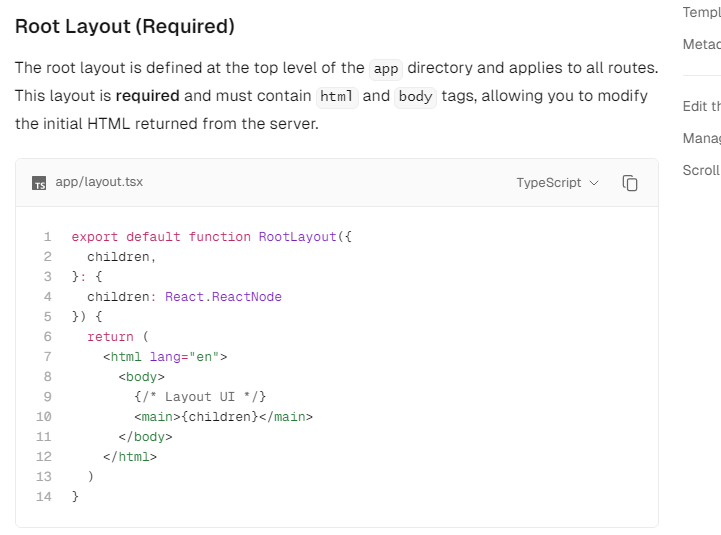
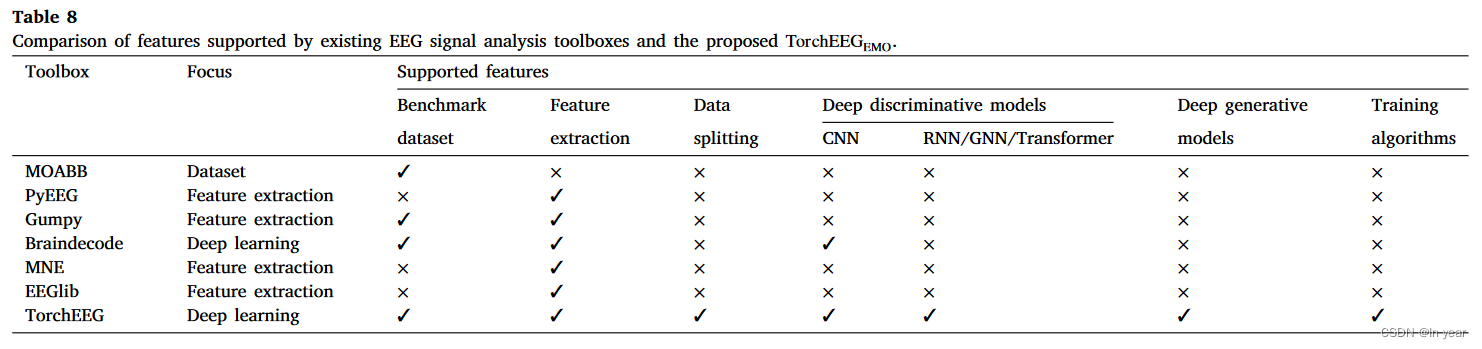
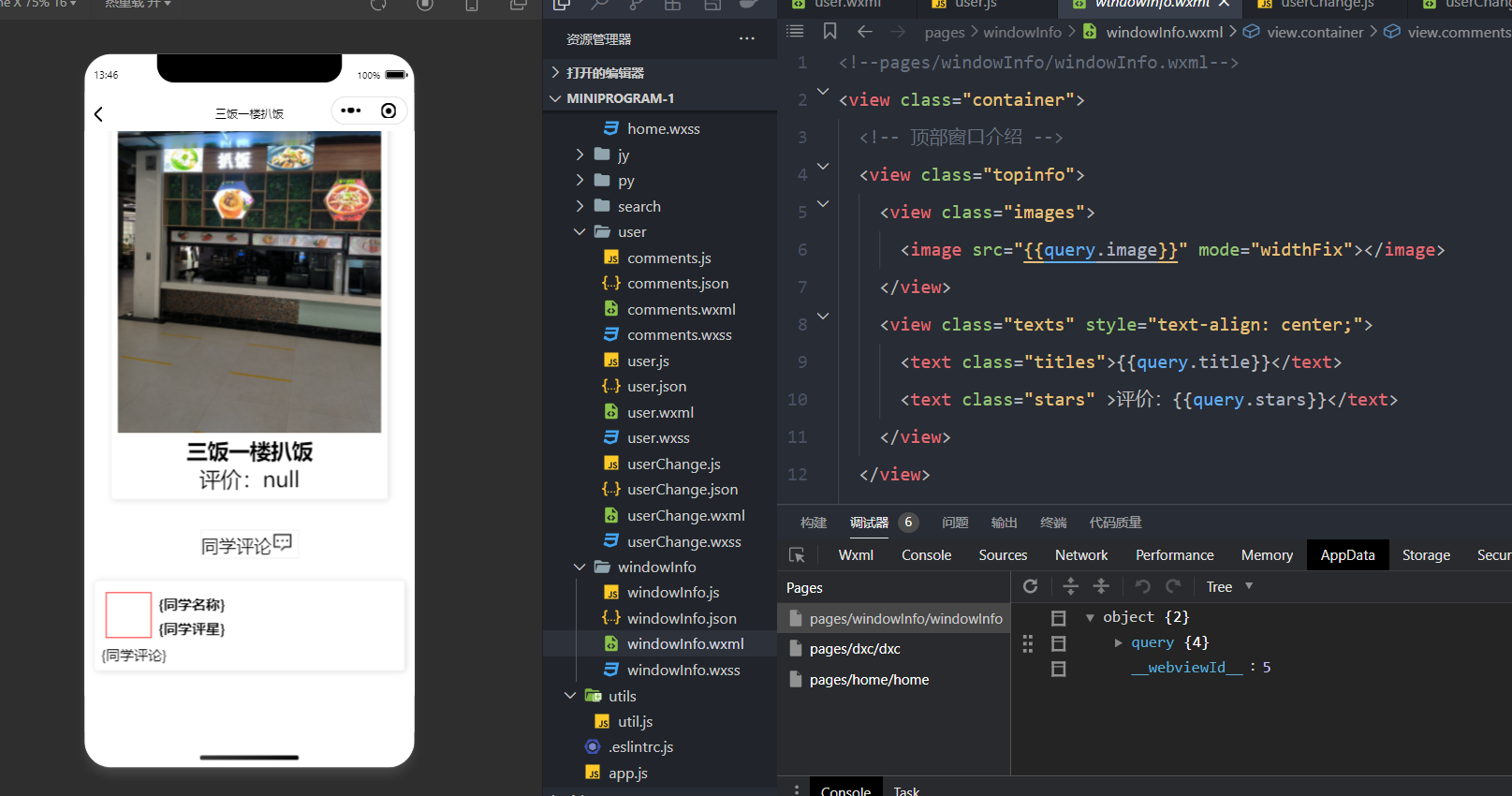
Loss total = Loss data + λ ∑ i = 1 n w i 2 \text{Loss}_{\text{total}} = \text{Loss}_{\text{data}} + \lambda \sum_{i=1}^{n} w_i^2 Losstotal=Lossdata+λi=1∑nwi2
其中:
- Loss total \text{Loss}_{\text{total}} Losstotal是加了正则化项的总损失函数。
- Loss data \text{Loss}_{\text{data}} Lossdata是模型在训练数据上的损失函数,通常是某个损失函数(如均方误差或交叉熵)的值。
- λ \lambda λ是正则化参数,用于控制正则化项的重要程度。它是一个非负实数。
- n n n 是模型中的权重参数数量。
- w i w_i wi 是第 i i i个权重参数。
通过调节 λ \lambda λ 的值,可以在模型的复杂度和拟合训练数据之间取得平衡。较大的 λ \lambda λ 会导致权重趋向于较小的值,从而降低模型的复杂度,而较小的 λ \lambda λ 允许权重更大的值,以更好地拟合训练数据。