1 re模块
re 模块是 Python 中用于正则表达式操作的模块。正则表达式(Regular Expression)是一种强大的文本处理工具,它使用一种特殊的字符序列来表示字符串中的模式,并可以通过模式匹配、查找、替换等操作对文本进行高效处理。
1.1 导入模块
python import re
1.2 编译正则表达式
使用 re.compile() 函数可以编译一个正则表达式,返回一个正则表达式对象。
python pattern = re.compile(r'\d+') # 匹配一个或多个数字
1.3 匹配操作
1.3.1 re.match()
从字符串的起始位置匹配一个模式,如果匹配成功,返回一个匹配对象;否则返回 None。
match = re.match(r'\d+', '123abc') # 匹配成功,返回匹配对象 print(match.group()) # 输出:123
1.3.2 re.search()
扫描整个字符串,返回第一个成功匹配的匹配对象。如果字符串中没有匹配项,则返回 None。
match = re.search(r'\d+', 'abc123def') # 匹配成功,返回匹配对象 print(match.group()) # 输出:123
1.3.3 re.findall()
找到字符串中所有匹配项,并返回一个包含所有匹配项的列表。
matches = re.findall(r'\d+', 'abc123def456') # 返回列表 ['123', '456'] print(matches)
1.3.4 re.finditer()
找到字符串中所有匹配项,并返回一个迭代器,每个迭代元素是一个匹配对象。
matches = re.finditer(r'\d+', 'abc123def456') for match in matches: print(match.group()) # 分别输出:123 和 456
1.4 替换操作
re.sub() 函数用于在字符串中查找匹配正则表达式的部分,并用新的字符串替换它们。
new_string = re.sub(r'\d+', 'NUMBER', 'abc123def456') # 替换数字为 'NUMBER' print(new_string) # 输出:abcNUMBERdefNUMBER
1.5 分割操作
re.split() 函数按照正则表达式的模式分割字符串。
parts = re.split(r'\d+', 'abc123def456') # 按照数字分割字符串 print(parts) # 输出:['abc', 'def', '']
1.6 正则表达式语法
正则表达式语法包括字符集、元字符、量词等,用于构建匹配模式。例如:
-
\d匹配任意数字 -
\.匹配点字符(由于点在正则表达式中是特殊字符,所以需要使用反斜杠进行转义) -
*匹配前面的子表达式零次或多次 -
+匹配前面的子表达式一次或多次 -
?匹配前面的子表达式零次或一次 -
{n}匹配确定的 n 次 -
{n,}匹配至少 n 次 -
{n,m}匹配至少 n 次,但不超过 m 次 -
^匹配字符串的开始 -
$匹配字符串的结束 -
[...]字符集,匹配方括号中的任意字符 -
[^...]否定字符集,匹配不在方括号中的任意字符 -
|或者,匹配 | 两侧的任意一项 -
( )捕获括号,用于分组和提取匹配部分 -
\转义字符,用于匹配特殊字符或转义序列
1.7 案例
案例 1:基础匹配
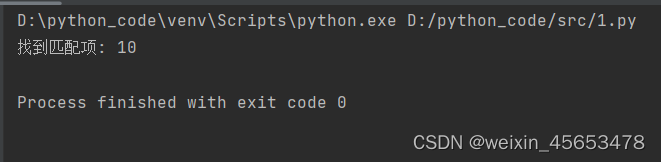
import re # 定义一个简单的正则表达式,匹配数字
pattern = re.compile(r'\d+') # 定义一个字符串
text = "我有10个苹果和5个橙子" # 使用re.search()进行匹配
match = re.search(pattern, text) # 如果匹配成功,输出匹配到的内容
if match: print("找到匹配项:", match.group()) # 输出:找到匹配项: 10
else: print("未找到匹配项")
效果
案例 2:使用边界符匹配完整单词
import re # 匹配完整的单词 "apple"
pattern = re.compile(r'\bapple\b') # 定义一个包含单词 "apple" 的字符串
text = "I like apples and apple pie." # 使用re.findall()查找所有匹配项
matches = re.findall(pattern, text) # 输出所有匹配到的单词
print("找到匹配项:", matches) # 输出:找到匹配项['apple']
效果

案例 3:使用非贪婪匹配
import re # 使用非贪婪匹配,尽可能少地匹配字符
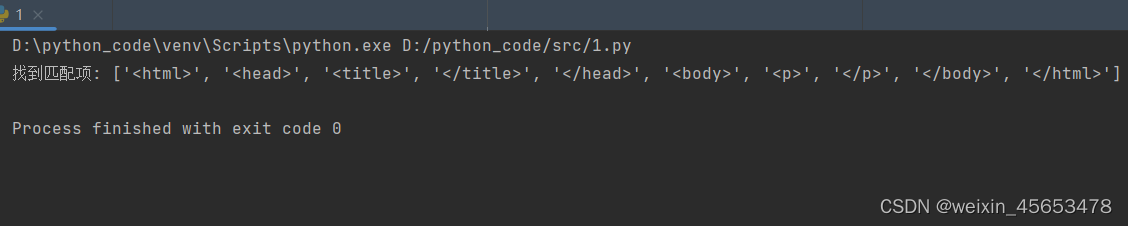
pattern = re.compile(r'<.*?>') # 匹配像 <a> 或 <div> 这样的标签 text = "<html><head><title>Test</title></head><body><p>Hello, world!</p></body></html>" # 使用re.findall()查找所有匹配项
matches = re.findall(pattern, text) # 输出所有匹配到的标签
print("找到匹配项:", matches) # 输出:找到匹配项: ['<html>', '<head>', '<title>', '</title>', '</head>', '<body>', '<p>', '</p>', '</body>', '</html>']
效果
案例 4:使用re.match()从字符串开始处匹配
import re # 使用re.match()从字符串开始处匹配数字
pattern = re.compile(r'\d+') text1 = "123开始的地方"
text2 = "开始的地方123" # 尝试匹配text1
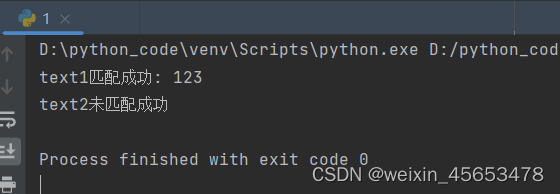
match1 = re.match(pattern, text1)
if match1: print("text1匹配成功:", match1.group()) # 输出:text1匹配成功: 123
else: print("text1未匹配成功") # 尝试匹配text2
match2 = re.match(pattern, text2)
if match2: print("text2匹配成功:", match2.group())
else: print("text2未匹配成功") # 输出:text2未匹配成功
效果
案例 5:使用re.sub()替换字符串中的模式
import re # 使用re.sub()替换字符串中的数字为 'NUMBER'
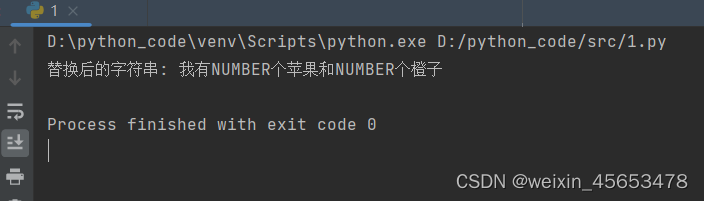
pattern = re.compile(r'\d+') text = "我有3个苹果和2个橙子"
new_text = re.sub(pattern, 'NUMBER', text) # 输出替换后的字符串
print("替换后的字符串:", new_text) # 输出:替换后的字符串: 我有NUMBER个苹果和NUMBER个橙子
效果
案例 6:使用标志位
import re # 使用IGNORECASE标志位忽略大小写进行匹配
pattern = re.compile(r'python', re.IGNORECASE) text = "Python is a great programming language. I love python."
matches = re.findall(pattern, text) # 输出所有匹配到的单词,忽略大小写
print("找到匹配项:", matches) # 输出:找到匹配项: ['Python', 'python']
效果

案例 7:使用分组和提取
import re # 使用分组提取日期中的年、月、日
pattern = re.compile(r'(\d{4})-(\d{2})-(\d{2})') text = "我的生日是2023-09-17"
match = re.search(pattern, text) if match: year, month, day = match.groups() print(f"年份: {year}, 月份: {month}, 日期: {day}") # 输出:年份: 2023, 月份: 09, 日期: 17
else: print("未找到匹配项")
效果

2 subprocess模块
subprocess 模块是 Python 中用于创建新的进程,连接到它们的输入/输出/错误管道,并获取它们的返回码的模块。这个模块提供了一个高级接口来启动子进程,并收集它们的输出。
2.1 基本使用
subprocess 模块中的几个常用函数包括:
-
subprocess.run():运行命令并等待完成,返回一个CompletedProcess实例。 -
subprocess.Popen():更底层的接口,用于启动进程并返回一个Popen对象,通过这个对象可以进一步与子进程交互。
2.2 案例
示例 1:使用 subprocess.run() 运行命令
import subprocess # 运行命令并等待完成 result = subprocess.run(['ls', '-l'], capture_output=True, text=True) # 输出命令执行结果 print(result.stdout) # 捕获的标准输出 print(result.stderr) # 捕获的标准错误输出 print(result.returncode) # 返回码,0通常表示成功
效果
示例 2:使用 subprocess.Popen() 与进程交互
import subprocess # 使用 Popen 创建进程
p = subprocess.Popen(['ping', '-c', '4', 'www.google.com'], stdout=subprocess.PIPE, stderr=subprocess.PIPE) # 等待进程完成并获取输出
stdout, stderr = p.communicate() # 解码输出为字符串
stdout_str = stdout.decode('utf-8')
stderr_str = stderr.decode('utf-8') # 输出结果
print('返回码:', p.returncode)
print('标准输出:', stdout_str)
print('标准错误:', stderr_str)
效果

3 linux日志分析
/var/log/cron 记录系统的定时任务 /var/log/cups 打印信息的日志 /var/log/message 记录的系统重要信息的日志 /var/log/btmp 登录失败 /var/log/lastlog 最后一次登录 /var/log/wtmp 成功登录记录 /var/log/secure 登录日志 /var/log/utmp 目前登录用户的信息
hosts黑名单 /etc/hosts.deny hosts白名单 /etc/hosts.allow
登录成功 Accepted password for root from 192.168.135.130 port 53776 ssh2
登录失败 Failed password for root from 192.168.135.130 port 42404 ssh2
4 linux日志分析技巧
日志分析常见命令
find grep awk sed cat tail head
分析命令
#显示最后十条日志记录 tail -f messages

#显示最后100条日志记录 tail -100f messages

#从第五行开始的日志记录 tail -n-+5 messages

#搜索存在root的字符串 [root@xuegod61 log]# cat /etc/passwd | grep "root" root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
#显示rot前后5行 cat /etc/passwd | grep -C 5 "root"

#显示匹配行以及其前的 5 行 cat /etc/passwd | grep -B 5 "root"
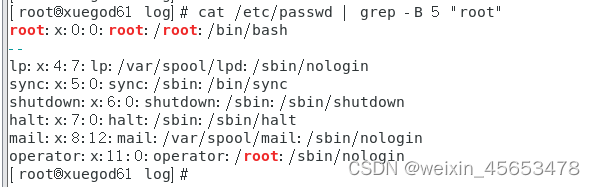
#匹配行以及其后的 5 行 cat /etc/passwd | grep -A 5 "root"

从第10行开始,显示5行,也就是说显示10~15行 cat /etc/passwd | tail -n +10 | head -n 5

只显示/etc/passwd下的账户
cat /etc/passwd | awk -F ':' '{print $1}

/var/log/secure
定位有多少个ip在爆破主机的root账号
grep "Failed password for root" /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr
登录成功的ip有哪些
grep "Accepted" /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr

5 linux黑白名单设置
配置格式
服务:地址:允许/封禁
服务: ssh ftp smb telnet 关键字(all)禁止or运行所有服务
all:192.168.0.10:deny(全封)
all:192.168.0.10:allow(加白) 地址:
192.168.0.10
192.168.0.10/24(整个C段封掉)
192.168.0.*(整个C段封掉)
192.168.0.(整个C段封掉)
6项目梳理
怎么实现暴力破解自动阻断
1、打开安全日志
2、对安全日志进行实时监控
3、解析日志每一行的内容,找出正在爆破的ip
4、设置一个阈值 超过阈值之后 直接封禁(把他的ip放入黑名单中)
7项目实现
代码
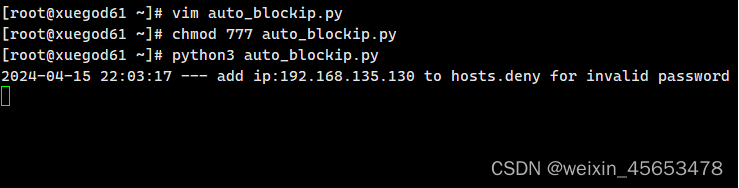
新建auto_blockip.py
#!/usr/bin/env python3
import re
import subprocess
import time
logFile = '/var/log/secure'
hostDeny = '/etc/hosts.deny'
# 允许的密码错误次数,大于该次数,直接拉黑
passwd_wrong_num = 1
# 获取已经加入黑名单的ip,转成字典
def getDenies():deniedDict = {}list = open(hostDeny).readlines()for ip in list:group = re.search(r'(\d+\.\d+\.\d+\.\d+)', ip)if group:deniedDict[group[1]] = '1'return deniedDict
# 监控方法
def monitorLog(logFile):# 统计密码错误次数tempIp = {}# 已拉黑ip名单deniedDict = getDenies()# 读取安全日志popen = subprocess.Popen('tail -f ' + logFile, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)# 开始监控while True:# 1s10次吧time.sleep(0.1)# 按行读line = popen.stdout.readline().strip()if line:# Invalid user: 不合法的用户名的, 直接拉黑group = re.search(r'Invalid user \w+ from (\d+\.\d+\.\d+\.\d+)', str(line))# 理论上,and后面的不用判断,已经在黑名单里面的,secure日志里,直接是refused connect from XXXXif group and not deniedDict.get(group[1]):subprocess.getoutput('echo \'sshd:{}\' >> {}'.format(group[1], hostDeny))deniedDict[group[1]] = '1'time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))print('{} --- add ip:{} to hosts.deny for invalid user'.format(time_str, group[1]))continue
# 用户名合法 密码错误的group = re.search(r'Failed password for \w+ from (\d+\.\d+\.\d+\.\d+) ', str(line))if group:ip = group[1]# 统计错误次数if not tempIp.get(ip):tempIp[ip] = 1else:tempIp[ip] = tempIp[ip] + 1# 密码错误次数大于阈值的时候,直接拉黑if tempIp[ip] > passwd_wrong_num and not deniedDict.get(ip):del tempIp[ip]subprocess.getoutput('echo \'sshd:{}\' >> {}'.format(ip, hostDeny))deniedDict[ip] = '1'time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))print('{} --- add ip:{} to hosts.deny for invalid password'.format(time_str, ip))
if __name__ == '__main__':monitorLog(logFile)
效果
查看黑名单
[root@xuegod61 ~]# vim /etc/hosts.deny



![[Java EE] 计算机工作原理与操作系统简明概要](https://img-blog.csdnimg.cn/direct/990f97548d1d40689b9e5729d1ea75bd.png)






![[lesson35]函数对象分析](https://img-blog.csdnimg.cn/direct/48ebf1f590fb4801bd19c1b8143f8978.png#pic_center)