完胜V8的SOTA模型Yolov9(论文阅读笔记)内容 点击即可跳转
当今的YOLO系列武林盟主YOLOV9:
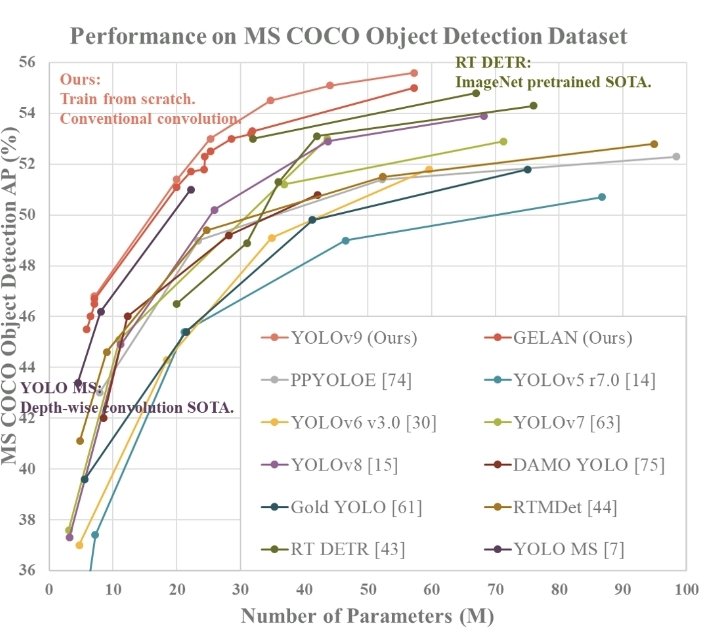
YOLOv9的优秀表现:

环境:
ubuntu20.04,无GPU,使用anaconda3创建的虚拟环境yolov9。
- 环境安装:
conda create -n yolov9 python=3.8# 激活yolov9 envconda activate yolov9- YOLOv9源码下载:
cd 到想要放置yolov9源码的路径git clone https://github.com/WongKinYiu/yolov9.gitcd yolov9pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
1 数据准备
可以使用开源的数据集,也可以自己准备数据集。
①标注工具
⒈labelme
安装方法:pip install labelme
使用方法:终端输入labelme
标注后生成的标记文件是json文件。
⒉labelimg
安装方法: pip install labelimg
使用方法:
cd到labelImg所在路径;
python3 labelImg.py
标注后生成的标记文件是xml文件。
②数据集整理
原始数据集格式如下图所示:

Annotations里面存放标签xml文件。
JPEGImage 里面存放原始图片。
labels文件夹里面存放的是标签txt文件。这个文件夹里的文件是通过脚本XmlToTxt.py生成的。
XmlToTxt.py的代码如下:
import xml.etree.ElementTree as ET
import os
import os
import random
# TODO 这里按照类别去修改
classes = ['fire']
# TODO 这里按照实际XML文件夹路径去修改
xml_filepath = 'dataset_fire/Annotations/'
# TODO 这里按照实际想要保存结果txt文件夹的路径去修改
labels_savepath = 'dataset_fire/labels/'
abs_path = os.getcwd()def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open(xml_filepath + '%s.xml' % (image_id), encoding='UTF-8')out_file = open(labels_savepath + '%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')def run():total_xml = os.listdir(xml_filepath)num = len(total_xml)names = []for xml in total_xml:names.append(xml[:-4])for name in names:convert_annotation(name)passif __name__ == '__main__':run()pass然后,根据JPEGImage 文件夹和labels文件夹通过脚本deal_dataset.py将数据集划分为如下结构。

deal_dataset.py的代码如下:
import os
import random
import shutil# 原数据集目录
root_dir = 'dataset_fire/'
# 划分比例
train_ratio = 0.8
valid_ratio = 0.1
test_ratio = 0.1# 设置随机种子
random.seed(42)# TODo 这里按照实际数据集路径去修改
split_dir = 'dataset_fire_split/'
os.makedirs(os.path.join(split_dir, 'train/images'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'train/labels'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'val/images'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'val/labels'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'test/images'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'test/labels'), exist_ok=True)# TODo 这里按照实际数据集路径去修改
imgpath = "JPEGImages"
labelpath = "labels"
image_files = os.listdir(os.path.join(root_dir, imgpath))
label_files = os.listdir(os.path.join(root_dir, labelpath))# 随机打乱文件列表
combined_files = list(zip(image_files, label_files))
random.shuffle(combined_files)
image_files_shuffled, label_files_shuffled = zip(*combined_files)# 根据比例计算划分的边界索引
train_bound = int(train_ratio * len(image_files_shuffled))
valid_bound = int((train_ratio + valid_ratio) * len(image_files_shuffled))# 将图片和标签文件移动到相应的目录
for i, (image_file, label_file) in enumerate(zip(image_files_shuffled, label_files_shuffled)):if i < train_bound:shutil.move(os.path.join(root_dir, imgpath, image_file), os.path.join(split_dir, 'train/images', image_file))shutil.move(os.path.join(root_dir, labelpath, label_file), os.path.join(split_dir, 'train/labels', label_file))elif i < valid_bound:shutil.move(os.path.join(root_dir, imgpath, image_file), os.path.join(split_dir, 'valid/images', image_file))shutil.move(os.path.join(root_dir, labelpath, label_file), os.path.join(split_dir, 'valid/labels', label_file))else:shutil.move(os.path.join(root_dir, imgpath, image_file), os.path.join(split_dir, 'test/images', image_file))shutil.move(os.path.join(root_dir, labelpath, label_file), os.path.join(split_dir, 'test/labels', label_file))至此,数据集准备好啦!
2 配置文件
在yolov9/data目录下新建数据的配置文件fire.yaml,内容如下:
path: data/images/dataset_fire_split # dataset root dir
train: train/ # train images
val: val/ # val images
test: test/ # test images# Classes
names:0: fire
找到yolov9/models/detect/yolov9-c.yaml文件后,修改里面的内容,如下图:

3 训练
下载预训练的模型后放到yolov9项目路径下,如下图:

- train:主分支。
- train_dual:一个辅助分支 + 一个主分支。
- triple_branch: 1个主分支 + 2个辅助分支。
训练相关的参数解析如下:
# train
parser.add_argument('--weights', type=str, default='',help='权重初始化的路径')
parser.add_argument('--cfg', type=str, default='models/detect/gelan.yaml',help='模型的配置文件,可以根据自己需求配置yaml文件')
parser.add_argument('--data', type=str, default='',help='数据集yaml文件地址')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch-high.yaml',help='超参数文件,yaml文件用于配置各种超参数')
parser.add_argument('--epochs', type=int, default=150,help='训练的轮次')
parser.add_argument('--batch-size', type=int, default=4,help='训练的批次大小,决定了一次向模型里输入多少张图片')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640,help='输入模型里的图像尺寸,YOLO系列默认都是640')
parser.add_argument('--rect', action='store_true',help='矩形训练或验证,是一种数据处理技术,在训练或验证过程中,输入数据会被调整为具有相同宽高比的矩形形状')
parser.add_argument('--resume', nargs='?', const=True, default=False,help='如果设置为True,那么会根据最新一次没有训练完成的权重进行继续训练')
parser.add_argument('--nosave', action='store_true',help='只保存之后一次训练的权重文件地址,即得到的那个权重,默认')
parser.add_argument('--noval', action='store_true',help='设置时,只在最后一个周期(epoch)进行验证,而不是在每个周期都进行验证')
parser.add_argument('--noautoanchor', action='store_true',help='设置时,禁用自动锚定(AutoAnchor)')
parser.add_argument('--noplots', action='store_true',help='设置时,不保存任何绘图文件,就是runs下面的训练结果产物')
parser.add_argument('--evolve', type=int, nargs='?', const=300,help='允许超参数的进化优化,参数是进化的代数。')
parser.add_argument('--bucket', type=str, default='',help='指定一个gsutil存储桶的路径')
parser.add_argument('--cache', type=str, nargs='?', const='ram',help='设置图像缓存方式,可以是内存(ram)或磁盘(disk),默认是内存')
parser.add_argument('--image-weights', action='store_true',help='使用加权图像选择进行训练,简单的说就是,处理一些复杂或不平衡的数据集')
parser.add_argument('--device', default='',help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true',help='设置时,图像大小会在训练过程中变化,上下浮动50%')
parser.add_argument('--single-cls', action='store_true',help='设置时,将多类别数据作为单类别数据训练,一般都设置为False')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW', 'LION'], default='SGD',help='优化器的选择,默认为SGD优化器')
parser.add_argument('--sync-bn', action='store_true',help='设置时,使用同步批处理归一化(SyncBatchNorm)')
parser.add_argument('--workers', type=int, default=0,help='Linux系统可以设置工作的线程,Windows系统必须设置0否则会导致各种问题')
parser.add_argument('--project', default='runs/train',help='设置项目保存路径,就是训练结果产物保存路径')
parser.add_argument('--name', default='exp',help='保存的项目名称,类似于runs/train/exp/训练的产物')
parser.add_argument('--exist-ok', action='store_true',help='设置时,如果项目/名称已存在则不会报错,不会自动增加编号')
parser.add_argument('--quad', action='store_true',help='使用四边形数据加载器, 默认开启')
parser.add_argument('--cos-lr', action='store_true',help='使用余弦学习率调度器, 默认开启')
parser.add_argument('--flat-cos-lr', action='store_true',help='启用一个平坦余弦学习率调度器(Flat Cosine Learning Rate Scheduler')
parser.add_argument('--fixed-lr', action='store_true',help='启用一个固定学习率调度器(Fixed Learning Rate Scheduler)')
parser.add_argument('--label-smoothing', type=float, default=0.0,help='参数是用来设置标签平滑的 epsilon 值的,用来提高模型的泛化能力')
parser.add_argument('--patience', type=int, default=100,help='早停机制,损失超过多少个回合变化的较小就停止训练')
parser.add_argument('--freeze', nargs='+', type=int, default=[0],help='用于在神经网络训练过程中“冻结”一部分层,不对它们进行更新')
parser.add_argument('--save-period', type=int, default=-1,help='每隔x个周期保存一次检查点,如果小于1则禁用')
parser.add_argument('--seed', type=int, default=0,help='随机数种子,根据随机数种子来演变出来的随机数')
parser.add_argument('--local_rank', type=int, default=-1,help='自动设置用于多GPU DDP训练的局部排名,通常不需要手动修改')
parser.add_argument('--min-items', type=int, default=0,help='Experimental,实验功能')
parser.add_argument('--close-mosaic', type=int, default=0,help='关闭mosaic数据增强的参数,比如设置0则不关闭mosaic数据增强''如果设置100则在训练后100轮关闭mosaic增强')
# Logger arguments
parser.add_argument('--entity', default=None,help='设置实体,用于日志记录')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False,help='设置是否上传数据集,如果指定“val”,则上传验证集')
parser.add_argument('--bbox_interval', type=int, default=-1,help='设置边界框图像记录间隔')
parser.add_argument('--artifact_alias', type=str, default='latest',help='设置要使用的数据集工件的版本,默认为latest')
训练示例
cd yolov9项目路径python3 train_dual.py --weights=yolov9-c.pt --cfg=models/detect/yolov9-c.yaml --data=data/fire.yaml --epoch=50 --batch-size=4 --imgsz=640 --hyp=data/hyps/hyp.scratch-high.yaml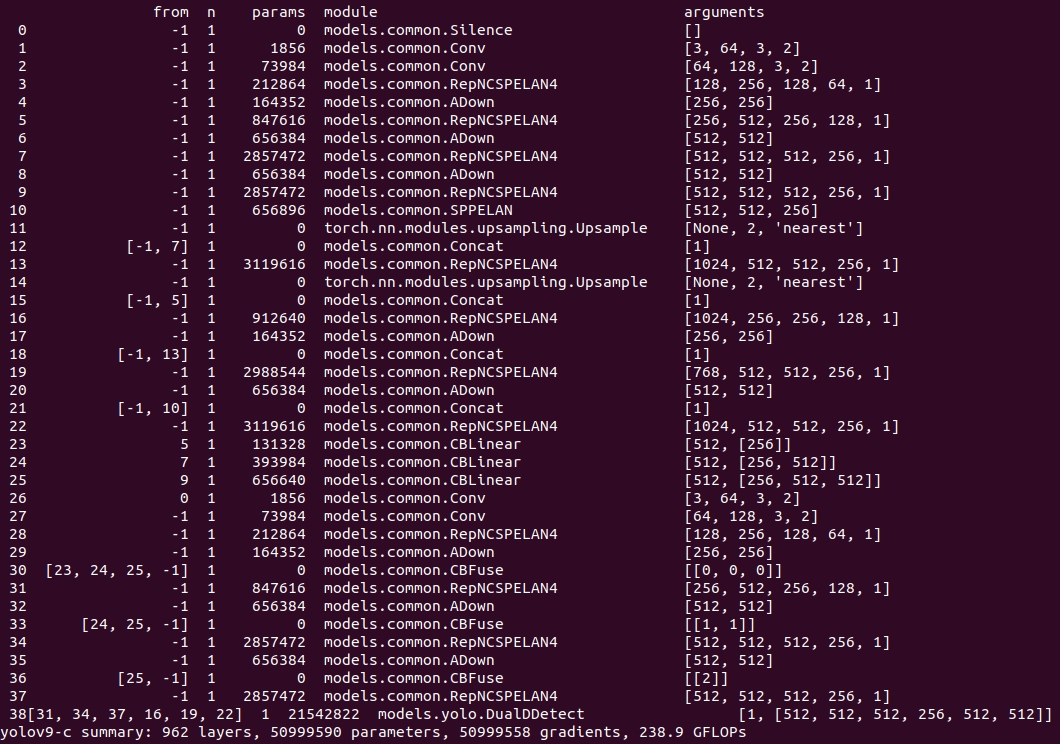
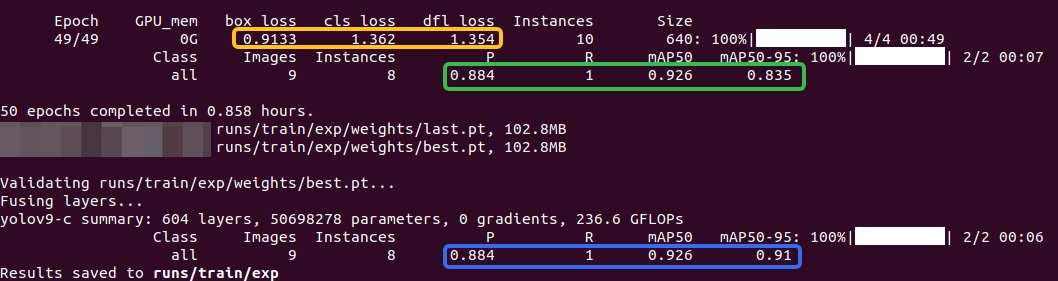
训练过程的产物如下所示:
模型保存在这个路径runs/train/exp/weights下,文件如图:

4 验证
验证相关的参数解析如下:
# val
parser.add_argument('--data', type=str, default='数据集的yaml文件地址',help='数据集配置文件路径')
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp12/weights/best.pt',help='trained模型权重文件路径')
parser.add_argument('--batch-size', type=int, default=4,help='批处理大小')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640,help='推理时的图像大小')
parser.add_argument('--conf-thres', type=float, default=0.001,help='置信度阈值')
parser.add_argument('--iou-thres', type=float, default=0.7,help='非最大抑制(NMS)的交并比(IoU)阈值')
parser.add_argument('--max-det', type=int, default=300,help='每张图像的最大检测数量')
parser.add_argument('--task', default='val',help='任务类型,可以是train, val, test, speed或study')
parser.add_argument('--device', default='',help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--workers', type=int, default=0,help='最大工作线程数,Windows系统建议0。Linux系统根据需求设置即可')
parser.add_argument('--single-cls', action='store_true',help='将数据集视为单类别。')
parser.add_argument('--augment', action='store_true',help='使用增强的推理。')
parser.add_argument('--verbose', action='store_true',help='按类别详细报告mAP数值')
parser.add_argument('--save-txt', action='store_true',help='将结果保存为文本文件')
parser.add_argument('--save-hybrid', action='store_true',help='将标签和预测的混合结果保存为文本文件')
parser.add_argument('--save-conf', action='store_true',help='在保存的文本标签中包含置信度。')
parser.add_argument('--save-json', action='store_true',help='保存COCO-JSON格式的结果文件')
parser.add_argument('--project', default='runs/val',help='结果保存的项目路径')
parser.add_argument('--name', default='exp',help='保存结果的子目录名称exp')
parser.add_argument('--exist-ok', action='store_true',help='如果项目名称已存在,则不递增编号。')
parser.add_argument('--half', action='store_true',help='使用FP16半精度推理,半精度会降低精度,但是推理速度快')
parser.add_argument('--dnn', action='store_true',help='使用OpenCV DNN进行ONNX推理')
parser.add_argument('--min-items', type=int, default=0,help='Experimental,实验功能')验证示例
cd yolov9项目路径python3 val_dual.py --data data/fire.yaml --weights runs/train/exp/weights/best.pt --batch-size 4 --imgsz 640 --conf-thres 0.5 --iou-thres 0.8
5 预测
预测相关的参数解析如下:
# predict
parser.add_argument('--weights', nargs='+', type=str, default='',help='模型权重的路径')
parser.add_argument('--source', type=str, default='data/images',help='预测数据的来源,可以是文件、目录、URL、glob模式、屏幕捕获或网络摄像头')
parser.add_argument('--data', type=str, default='data/coco128.yaml',help='数据集配置文件的路径,默认为ROOT/data/coco128.yaml')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640],help='推理时的图像大小')
parser.add_argument('--conf-thres', type=float, default=0.25,help='检测的置信度阈值。默认为0.25')
parser.add_argument('--iou-thres', type=float, default=0.45,help='非最大抑制(NMS)的交并比(IoU)阈值。默认为0.45')
parser.add_argument('--max-det', type=int, default=1000,help='每张图像的最大检测框数量。默认为1000')
parser.add_argument('--device', default='',help='指定运行设备,CUDA设备(0或0,1,2,3)或CPU')
parser.add_argument('--view-img', action='store_true',help='设置时,展示检测结果。')
parser.add_argument('--save-txt', action='store_true',help='设置时,将检测结果保存为文本文件')
parser.add_argument('--save-csv', action='store_true',help='设置时,将检测结果保存为CSV格式')
parser.add_argument('--save-conf', action='store_true',help='设置时,保存置信度信息')
parser.add_argument('--save-crop', action='store_true',help='设置时,保存被检测对象的裁剪图像')
parser.add_argument('--nosave', action='store_true',help='设置时,不保存图像或视频结果')
parser.add_argument('--classes', nargs='+', type=int,help='过滤指定的类别,例如0或 0 2 3 4')
parser.add_argument('--agnostic-nms', action='store_true',help='设置时,使用与类别无关的NMS')
parser.add_argument('--augment', action='store_true',help='设置时,使用增强的推理')
parser.add_argument('--visualize', action='store_true',help='设置时,可视化')
parser.add_argument('--update', action='store_true',help='设置时,更新所有模型')
parser.add_argument('--project', default='runs/detect',help='设置结果保存的项目目录,默认为ROOT/runs/detect')
parser.add_argument('--name', default='exp',help='设置保存结果的子目录名称,默认为exp')
parser.add_argument('--exist-ok', action='store_true',help='设置时,允许已存在的项目/名称,不自动增加编号')
parser.add_argument('--line-thickness', default=3, type=int,help='设置边界框的线条粗细')
parser.add_argument('--hide-labels', default=False, action='store_true',help='设置时,隐藏标签')
parser.add_argument('--hide-conf', default=False, action='store_true',help='设置时,隐藏置信度')
parser.add_argument('--half', action='store_true',help='设置时,使用FP16半精度推理(精度会下降),推理速度快')
parser.add_argument('--dnn', action='store_true',help='设置时,使用OpenCV DNN模块进行ONNX推理')
parser.add_argument('--vid-stride', type=int, default=1,help='设置视频帧率步长,默认值为1')预测示例
python detect_dual.py --source 'data/images/test.jpg' --img 640 --weights 'runs/train/exp/weights/best.pt' --name yolov9_c_640_detect
检测的结果如下图所示:

6 报错处理
【报错】
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
【解决方法】
pip install Pillow==9.5 -i https://pypi.tuna.tsinghua.edu.cn/simple其他
RepNCSPELAN4结构
class RepNCSPELAN4(nn.Module):# csp-elandef __init__(self, c1, c2, c5=1): # c5 = repeatsuper().__init__()c3 = int(c2 / 2)c4 = int(c3 / 2)self.c = c3 // 2self.cv1 = Conv(c1, c3, 1, 1)self.cv2 = nn.Sequential(RepNCSP(c3 // 2, c4, c5), Conv(c4, c4, 3, 1))self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend((m(y[-1])) for m in [self.cv2, self.cv3])return self.cv4(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in [self.cv2, self.cv3])return self.cv4(torch.cat(y, 1))SPPELAN结构
class SP(nn.Module):def __init__(self, k=3, s=1):super(SP, self).__init__()self.m = nn.MaxPool2d(kernel_size=k, stride=s, padding=k // 2)def forward(self, x):return self.m(x)class SPPELAN(nn.Module):# spp-elandef __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = c3self.cv1 = Conv(c1, c3, 1, 1)self.cv2 = SP(5)self.cv3 = SP(5)self.cv4 = SP(5)self.cv5 = Conv(4*c3, c2, 1, 1)def forward(self, x):y = [self.cv1(x)]y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])return self.cv5(torch.cat(y, 1))YOLOv9的yaml文件
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
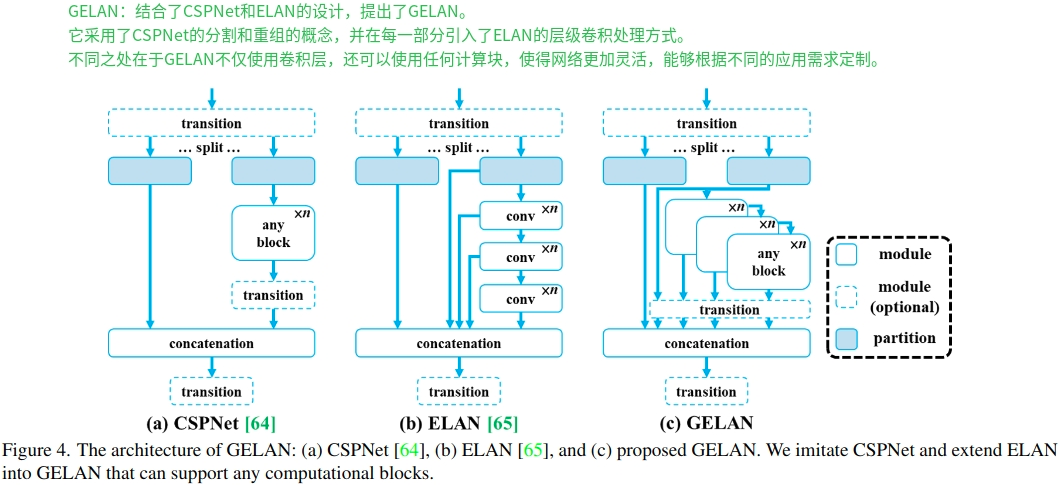
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]GELAN允许支持多种类型的计算块,这使得它可以更好地适应各种不同的计算需求和硬件约束。
YOLOv9-GELAN版本yaml文件
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# gelan backbone
backbone:[# conv down[-1, 1, Conv, [64, 3, 2]], # 0-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 1-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 2# avg-conv down[-1, 1, Conv, [256, 3, 2]], # 3-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 4# avg-conv down[-1, 1, Conv, [512, 3, 2]], # 5-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 6# avg-conv down[-1, 1, Conv, [512, 3, 2]], # 7-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 8]# gelan head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 9# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 12# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 15 (P3/8-small)# avg-conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 12], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 18 (P4/16-medium)# avg-conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 9], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 21 (P5/32-large)# detect[[15, 18, 21], 1, DDetect, [nc]], # Detect(P3, P4, P5)]训练
1 Single GPU training
# train yolov9 modelspython train_dual.py --workers 8 --device 0 --batch 16 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15# train gelan modelspython train.py --workers 8 --device 0 --batch 32 --data data/coco.yaml --img 640 --cfg models/detect/gelan-c.yaml --weights '' --name gelan-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 152 Multiple GPU training
# train yolov9 modelspython -m torch.distributed.launch --nproc_per_node 8 --master_port 9527 train_dual.py --workers 8 --device 0,1,2,3,4,5,6,7 --sync-bn --batch 128 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15# train gelan modelspython -m torch.distributed.launch --nproc_per_node 4 --master_port 9527 train.py --workers 8 --device 0,1,2,3 --sync-bn --batch 128 --data data/coco.yaml --img 640 --cfg models/detect/gelan-c.yaml --weights '' --name gelan-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15验证Evaluation
# evaluate yolov9 modelspython val_dual.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './yolov9-c.pt' --save-json --name yolov9_c_640_val# evaluate gelan modelspython val.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './gelan-c.pt' --save-json --name gelan_c_640_valtensorboard 的使用
tensorboard的使用方法示例如下:
cd 解析文件的上一级目录
tensorboard --logdir=exp
具体情况见下图:
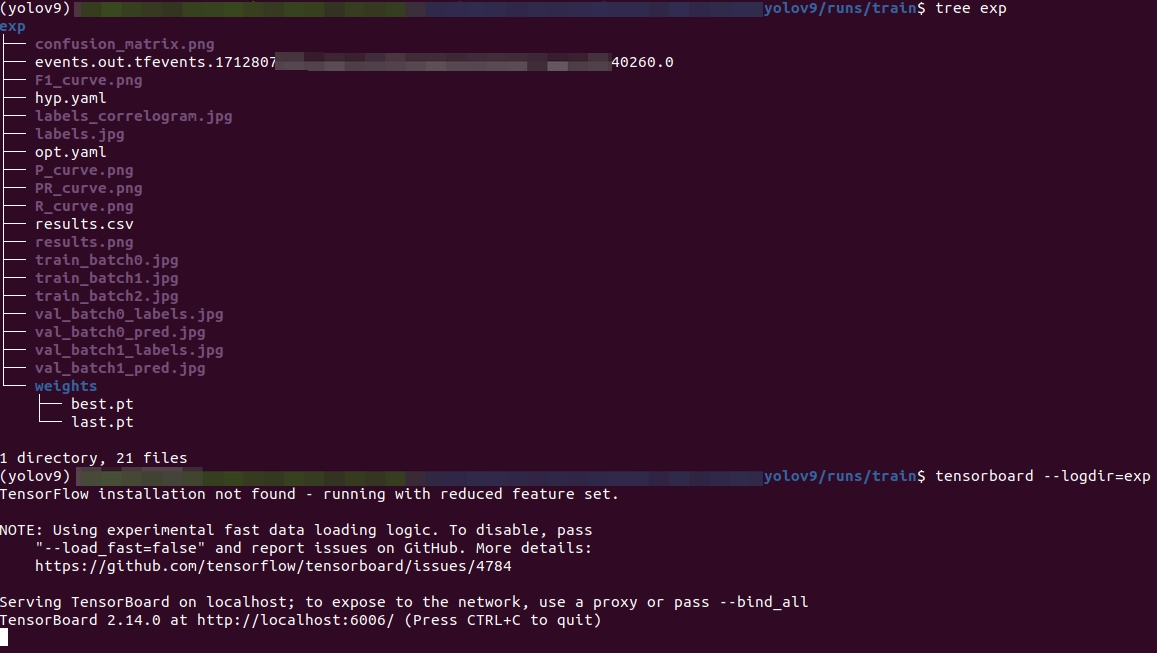
然后,打开链接:http://localhost:6006/
【报错】💔💔💔
TypeError: MessageToJson() got an unexpected keyword argument 'including_default_value_fields'
同时没有显示图像。
【分析】💜💜💜
tensorboard的版本过高,降低即可。
【解决方法】💚💚💚
pip install tensorboard==2.12.0
问题解决啦!!!🌺🌺🌺