论文
论文信息
题目:Is Mapping Necessary for Realistic PointGoal Navigation?
作者:Ruslan Partsey、 Erik Wijmans
代码地址:rpartsey.github.io/pointgoalnav
来源:CVPR
时间:2022
Abstract
目标:证明显式地图不是成功导航的必要条件。
对比实验
数据集(模拟器):无地图导航模型的标准数据集Gibson。
模拟器和现实世界的区别:本体感知(位置和方向)、观测噪声、动力学噪声。
- 理想环境:位置和方向信息 + 没有RGB-D传感器噪声和驱动噪声:100%
- 现实环境:没有位置和方向信息 + RGB-D传感器噪声和驱动噪声:71.7%
- 实验环境:位置和方向信息 + RGB-D传感器噪声和驱动噪声:97%([39])、99.8%(本论文)
证实了唯一的性能限制因素是智能体的自我定位能力。
Introduction
特点:
- 通过动作嵌入进行动作调节。
- 训练时数据增强。
- 用于集成的测试时数据增强。
- 增加了数据集大小和模型大小。
PointGoal Navigation
任务定义
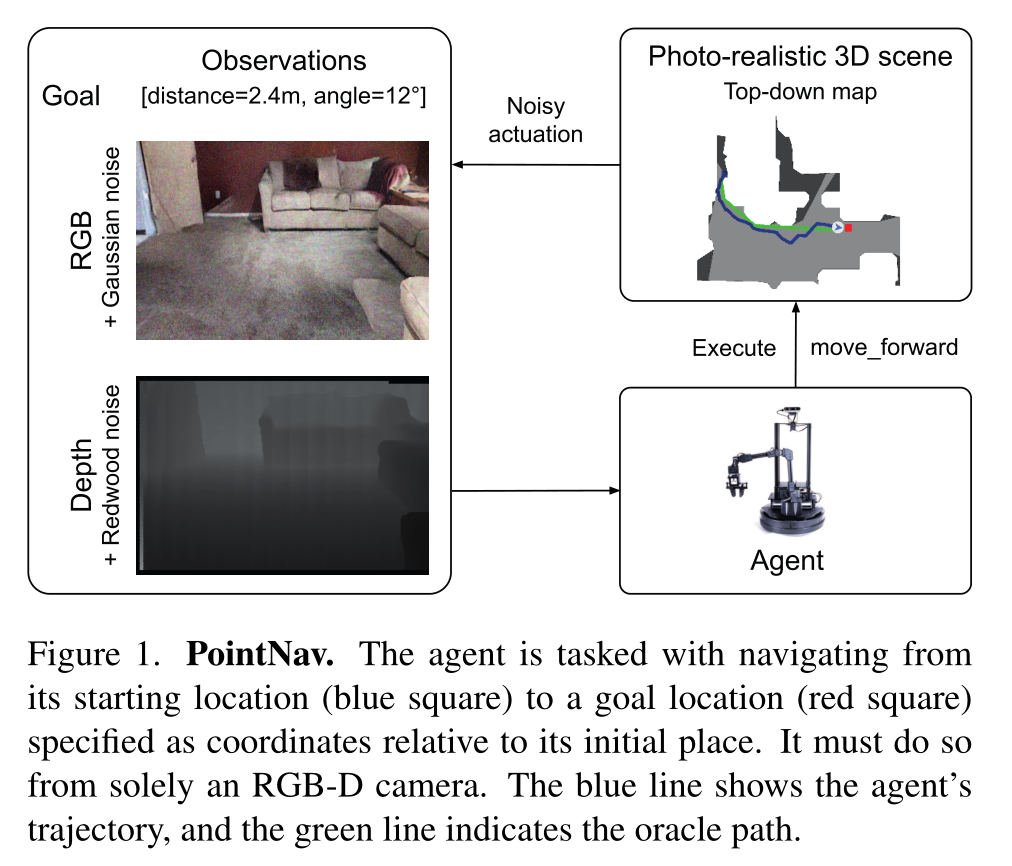
在PointNav中,智能体在以前未见过的环境中初始化,并被分配到相对于其起始位置指定的目标。动作空间是离散的,由四种类型的动作组成:停止(结束episode),向前移动0.25m,以α角向左转弯和向右转弯。
评估指标
Agent通过三个主要指标进行评估:
- Success: 如果智能体在距离目标0.36m (2倍agent半径)的范围内发出停止命令,则 e p i s o d e i episode\space i episode i被认为是成功的。
- Success weight by (inverse normalized) Path Length (SPL):
形式上,对于 e p i s o d e i episode\space i episode i,设 S i S_i Si为成功的二进制指示器, p i p_i pi为智能体路径的长度, l i l_i li为最短路径(测地线距离)的长度,那么对于N个episode:
S P L = 1 N ∑ i = 1 N S i ⋅ l i m a x ( p i , l i ) SPL=\frac{1}{N}\sum_{i=1}^{N}S_i \cdot \frac{l_i}{max(p_i,l_i)} SPL=N1i=1∑NSi⋅max(pi,li)li - SoftSPL: 即二元的成功状态 S i S_i Si被目标的完成过程所取代。形式上,对于 e p i s o d e i episode i episodei,设 d 0 i d_{0_i} d0i为到目标的初始距离, d T i d_{T_i} dTi为episode结束时到目标的距离(包括成功和失败),则
S o f t S P L = 1 N ∑ i = 1 N ( 1 − d T i d 0 i ) ⋅ ( l i m a x ( p i , l i ) ) SoftSPL=\frac{1}{N}\sum_{i=1}^{N}\left(1-\frac{d_{T_i}}{d_{0_i}} \right) \cdot \left ( \frac{l_i}{max(p_i,l_i)}\right ) SoftSPL=N1i=1∑N(1−d0idTi)⋅(max(pi,li)li)
PointNav-v1: Idealized (Noise-less) Setting
智能体配备了无噪声 RGB-D 摄像头,可以访问地面实况定位(通过 GPS+罗盘传感器),并且运动是确定性/无噪声的(意味着右转 10° 总是使代理正好旋转 10°)。该代理还可以沿着墙壁“滑动”——这是视频游戏中的常见行为,可以提高人类控制能力,但后来发现会降低模拟到真实的性能。
用强化学习的效果已经很好了
PointNav-v2: Realistic (Noisy) Setting
引入驱动噪声(通过对 LoCoBot 机器人进行基准测试建模 )、移除 GPS+Compass 以及向 RGB-D 相机添加噪声来解决 v1 的这些缺点。为了模拟真实世界的相机 RGB 和深度,使用了 [8] 中的噪声模型(向RGB 中加高斯噪声模型;向Depth中加 Redwood 噪声)。
Navigation Policy
模块结构
由两个组件构成:
一个导航策略(nav-police):在时间步 t t t给出观测值 O t O_t Ot,决定采取哪种操作来达到目标;
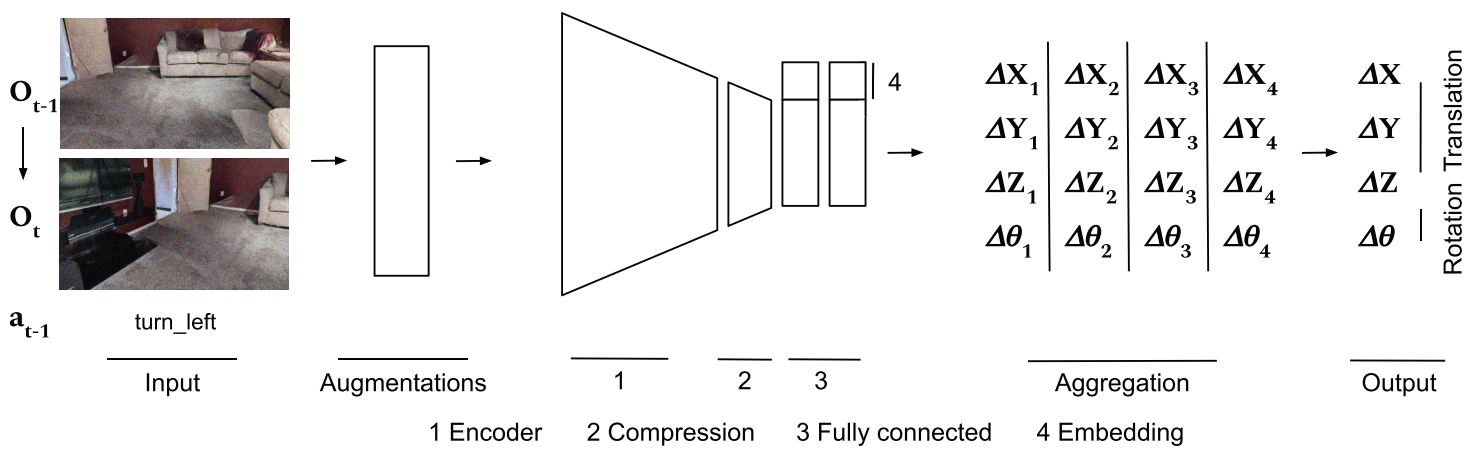
一个视觉里程计(VO):一个视觉测程(VO)模块,输入一对180×360 RGB-D帧,作为两个连续观测值 ( O t − 1 , O t ) (O_{t-1},O_t) (Ot−1,Ot),并输出相对位姿变化 ( Δ x , Δ y , Δ z , Δ θ ) (\Delta x,\Delta y,\Delta z,\Delta \theta) (Δx,Δy,Δz,Δθ),其中 Δ x , Δ y , Δ z \Delta x,\Delta y,\Delta z Δx,Δy,Δz 表示摄像机中心的三维平移, Δ θ \Delta \theta Δθ表示围绕重力矢量的旋转。然后用于更新目标相对于机器人的位置,更新后的目标位置将与 O t O_t Ot一起提供给导航策略,以预测下一个行动。初始目标位置估计等于实际目标位置(根据任务规范)。
- 输入
- g t − 1 g_{t-1} gt−1:目标前一步的坐标
- O t − 1 O_{t-1} Ot−1:前一步的观测值
- O t O_t Ot:当前的观测值
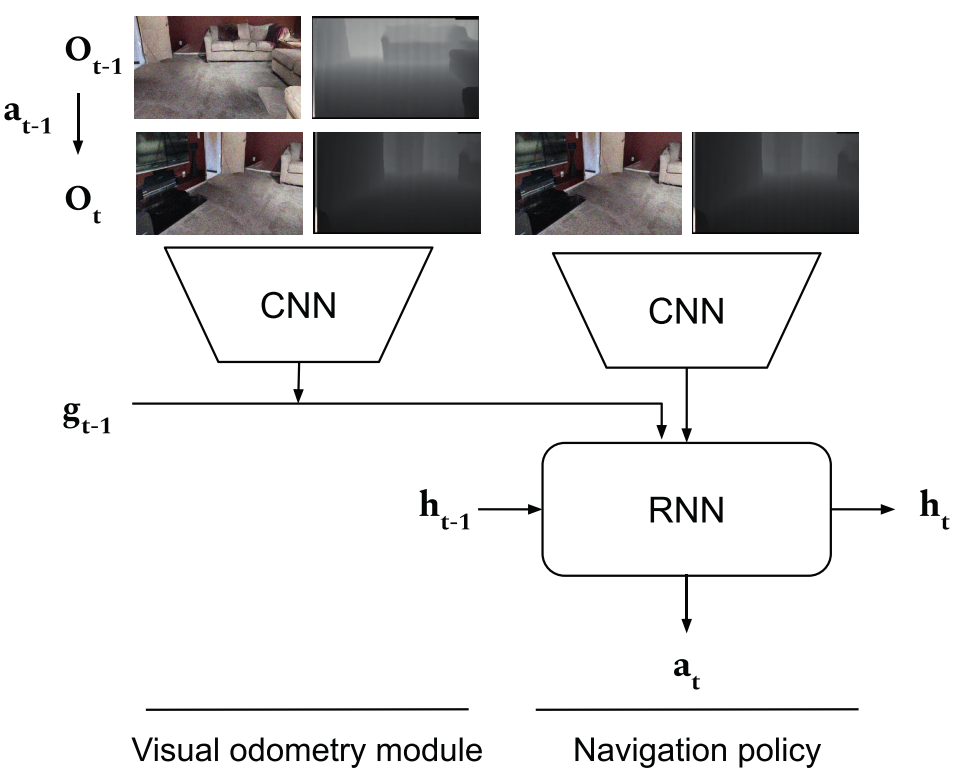
首先,VO 预测 t − 1 和 t 之间的变化,然后将目标更新为 wrt。当前姿势。更新后的目标位置与 Ot 一起提供给导航策略,以预测下一个动作。初始目标位置估计等于地面真实目标位置(根据任务规范)
网络结构
导航策略的网络结构
我们的导航策略由两层长短期存储器(LSTM)和半宽ResNet50编码器组成。
在每个时间步,策略被给予来自噪声深度传感器(导航策略的常见做法)和位置方向(训练时来自ground-truth,测试时来自视觉测程模块)的输出。
在通过特征编码器之前,视觉观察使用ResizeShortestEdge和CenterCrop观察转换进行转换;前者将输入的最短边调整为256像素,同时保持纵横比,后者将输入的中心裁剪为256 × 256像素。
视觉测程模块的网络结构
视觉测程模块表示为ResNet编码器后加一个压缩块和两个全连接(FC)层。
我们将BatchNorm替换为GroupNorm,并使用宽度的一半。压缩块由3×3 Conv2d+GroupNorm+ReLU组成。我们在全连接层之间应用DropOut,概率为0.2。完整的VO管道如图3所示。
训练细节
我们还实现了分布式VO训练管道。在8个节点上训练(每个节点有8个GPU,共64个GPU)比在1个节点上训练快6.4倍。
训练导航策略
我们利用分散式分布式近端策略优化(DD-PPO)和Wijmans等人的奖励结构来训练策略。
奖励函数设定
对于episode i i i,智能体接受 ‘terminal’ reward: r T = 2.5 ⋅ S u c e s s i r_T=2.5\cdot Sucess_i rT=2.5⋅Sucessi以鼓励它停在正确的位置(并保持有效的路径),和一个shaped reward: r t ( a t , s t ) = − Δ g e o _ d i s t − 0.01 r_t(a_t,s_t)=-\Delta geo\_dist-0.01 rt(at,st)=−Δgeo_dist−0.01以鼓励它向目标执行动作(同时保持高效), Δ g e o _ d i s t \Delta geo\_dist Δgeo_dist是在状态 s t s_t st 执行操作时到目标的测地距离的变化。
我们在Gibson 4+上训练了25亿步,然后在Gibson 0+上训练了25亿步,最后在终止奖励由SPL加权的Gibson 0+上训练了25亿步。在整个实验过程中,每个阶段我们都使用前一阶段中最好的策略开始。
训练视觉里程计模块
我们在静态数据集 D = { ( O t − 1 , O t , a t − 1 , Δ p o s e ) } D=\left\{(O_{t-1},O_t,a_{t-1},\Delta pose)\right\} D={(Ot−1,Ot,at−1,Δpose)}上训练视觉测程模型。该数据集是通过使用oracle path来创建的,从这些轨迹中对具有关于所采取的行动和自我运动的元信息的RGB-D帧进行统一采样。我们使用Gibson 4+场景(和Gibson-v2 PointGoal导航集)来生成VO数据集。我们通过从训练场景中统一采样20%的观测对(总共500k到5M个训练示例)来收集训练数据集,通过从验证场景中采样75%的观测对(总共34k个)来收集验证数据集。
oracle path指的是一个理想化的路径规划方法,它假设智能体已经知道了完整的环境地图,并且没有任何感知或执行误差。在这种情况下,智能体可以通过简单地计算最短路径来找到目标位置。因此,oracle path可以被认为是一种最优的路径规划方法。
该模型的批处理大小为32,Adam优化器的学习率为 1 0 − 4 10^{-4} 10−4,平移和旋转的均方误差(MSE)损失。
训练视觉测程(VO)模块的优化手段
- 通过action embeddings进行动作调节。视觉测程(VO)模块根据图像和所执行的动作进行测程。我们发现,将动作的one-hot(独热码)表示转换为continuous embeddings,并将它们连接到VO网络中的最后两个全连接层,显著提高了+8 Success/+5 SPL的性能。
continuous embeddings和one-hot的区别:在one-hot编码中,每个动作都被表示为一个只有一个元素为1的向量,其余元素为0。而continuous embeddings则是将每个动作类型映射到一个固定长度的向量空间中,并使用该向量来表示该动作。相比之下,continuous embeddings可以更好地捕捉不同动作之间的相似性和差异性,并且可以通过embedding层来学习这些特征。因此,在某些情况下,使用continuous embeddings可以提高神经网络的性能。
-
训练时的数据增强。当智能体产生观测值 O t − 1 O_{t-1} Ot−1和 O t O_t Ot 时,我们可以通过反向姿势和动作创建一个新的训练图像,将 O t − 1 O_{t-1} Ot−1和 O t O_t Ot 联系起来。我们还提出了一种新的增强,称为Flip。累积起来,它们可以通过+2 Success/+1 SPL来提高性能。
视觉测程模块接收到两个用于向前移动的观测对(原始和翻转)和四个用于转向{左,右}动作的观测对(原始,翻转,交换(原始),交换(翻转))。在聚合阶段,通过对每个增强应用逆变换,将输出转换回原始坐标坐标系,然后求平均值以产生最终的自我运动估计。

-
用于集成的测试时数据扩充。为了提高稳健性,我们在测试时执行所有增强,并对所有组合进行汇总预测。这提高了+3 Success/+3 SPL的性能。
-
增加数据集大小和模型大小。最后,我们研究了数据集规模从500k增加到1.5M观测对(+8 Success/+7 SPL),更大的模型规模(+3 Success/+3 SPL),以及数据集规模从1.5M增加到5M (+8 Success/+6 SPL)的影响。
实验
Habitat Challenge 挑战赛2021 PointNav项目
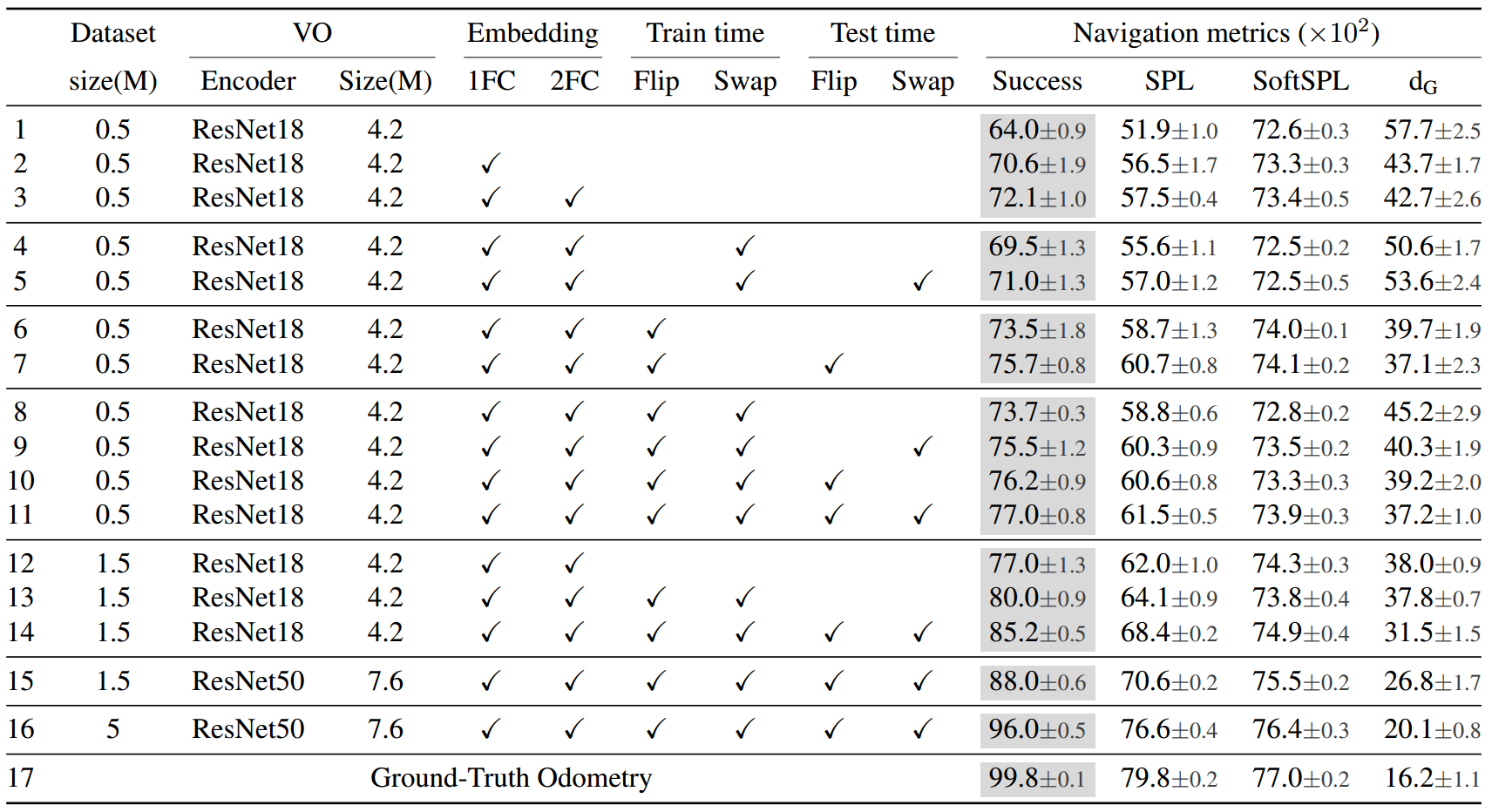
我们在Habitat Challenge 挑战赛基准测试标准中评估了性能最佳的智能体(表1,第16行)。我们的智能体在测试标准拆分中达到94%的成功率和74%的SPL。与之前发表的最先进技术相比,这增加了+16%的成功率/+15%的SPL。超过了当时的冠军智源机器人的成功。

物体目标导航 (Object Navigation) 是智能机器人的基本任务之一。在此任务中,智能机器人在一个未知的新环境中主动探索并找到人指定的某类物体。物体目标导航任务面向未来家庭服务机器人的应用需求,当人们需要机器人完成某些任务时,例如拿一杯水,机器人需要先寻找并移动到水杯的位置,进而帮人们取到水杯。
虽然我们的结果不能有效地“解决”现实设置下的PointGoal导航,但它们显著地提高了性能,并提供了更多的证据,表明即使在严酷的现实条件下,也可以在不构建显式映射的情况下进行导航。
消融
-
action embeddings:我们分析了两种可能的整合元信息的方法:将embeddings连接到编码器之后的第一个FC层(表1,将action embeddings到第一个FC层,与基线(第2行与第1行)相比,性能提高了+7 Success/+5 SPL。将action embeddings到所有FC层,性能进一步提高了+1 Success/+1 SPL(第3行与第2行)。我们相信,这允许FC层接收更多的上下文,以使用共享编码器为每个动作类型学习更准确的自我运动。
-
训练时间:通过应用Flip来丰富VO数据集多样性可以提高+2 Success/+1 SPL(第6行对第3行)的性能。有趣的是,我们发现Swap会降低-2 Success/-2 SPL(第4行对第3行)的性能。
-
更大的数据集:为了研究大规模训练的影响,我们按照第4.4节所述的相同的数据集收集协议,将训练数据集大小增加了3倍(从500k增加到1.5M训练对)。在没有增强的情况下,增加数据集大小3×可以提高性能+5 Success/+4 SPL(第12行对第3行)和+8 Success/+4 SPL(第14行对第11行)。
我们还使用这个更大的数据集检查了增强的影响。令人惊讶的是,我们发现它们在更大的训练数据集上更有影响力。 -
更深层次的编码器:我们发现,使用更复杂的编码器架构(ResNet50而不是ResNet18)进行训练,可以进一步提高导航性能+3 Success/+3 SPL(第15行vs第14行)。
sim to sim
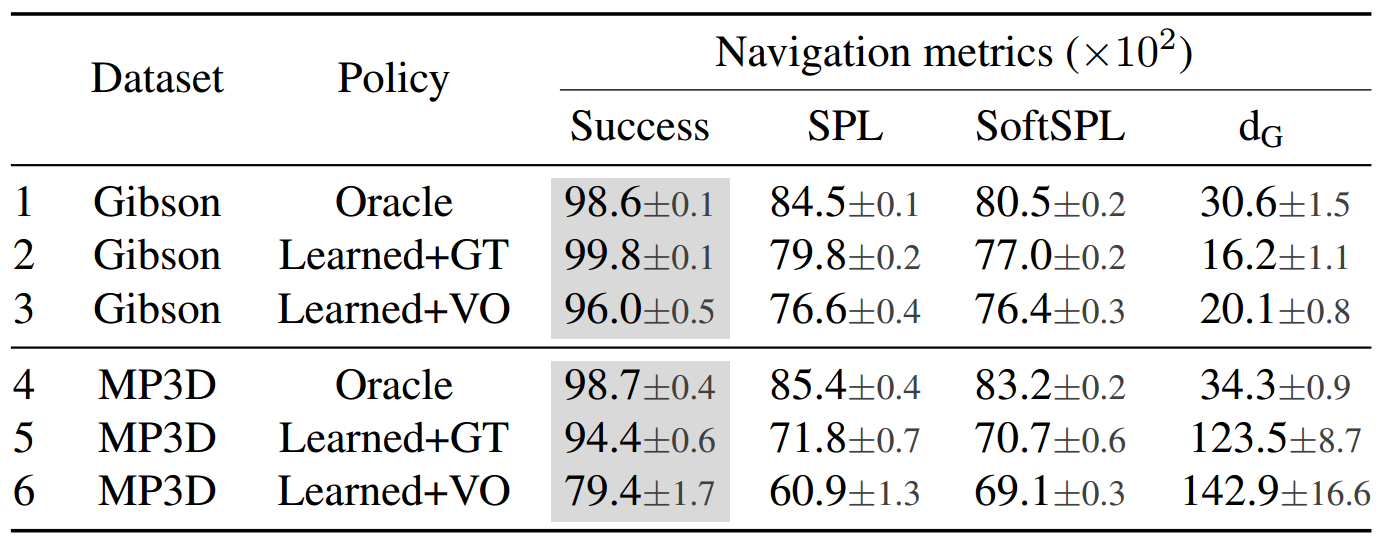
我们研究了智能体的两个组件如何从训练数据集Gibson转移到Matterport3D数据集。我们发现在智能体的性能日渐本地化由只有 -6 Success/-6 SPL(表2、行5 vs 行2),智能体的性能与视觉测程法降低更多,-19 Success/-18 SPL(行6 vs 行3)。
这就留下了一个问题——是否存在通用(跨数据集)VO模块?我们预计,创建这样一个系统需要在多个大规模数据集上进行训练。
sim to real
我们在现实中对我们的方法进行了初步探索,并将我们的学习代理部署在没有sim2real适应的LoCoBot上。在9个episodes中,它获得了11%的成功,71%的SoftSPL,并完成了通往目标道路(SoftSuccess)的92%。根据网站上提供的导航视频,该代理可以很好地避开障碍物。这些初步结果显示出希望,适应性方法可以提高性能。
结束语
虽然我们的结果不能有效地“解决”现实环境中的PointGoal导航,但它们显著地提高了性能,并提供了更多的证据,表明即使在严酷的现实条件下,也可以在不构建显式映射的情况下进行导航。
局限性
虽然我们的工作在现实条件下的无地图导航方法方面取得了重大进展,但它有几个局限性。
- 体现特异性。虽然我们的VO模型和训练过程是策略不可知的,但它们不是实现不可知的。action embeddings的重要性意味着放松这将是一个挑战,这意味着VO模型可能需要为每个实施例重新训练,这是浪费的。
- 数据集特异性。同样,我们学习的VO模型在数据集之间不能很好地传输,可能需要为每个数据集重新训练。我们相信大规模多数据集训练可能是一个解决方案,但这仍然是一个悬而未决的问题。
- 计算需求。我们的最佳导航策略使用了总共75亿步的经验。训练我们最好的VO模型首先需要生成5M个训练对,然后在64个GPU上训练(总共约5000个GPU小时)。PointNav-v1[26,32,36]的高计算需求迅速降低,我们预计PointNav-v2的计算需求也会降低,但这仍然是一个开放的方向。
其余细节
确定SPL的上限
为了将导航策略的性能与视觉测程模块隔离开来,我们通过访问ground-truth位置和方向来检查智能体的性能。在Gibson val数据集上,我们的智能体在PointNav-v2设置中实现了99.8%的成功和80%的SPL。这一结果表明,即使有嘈杂的观测和驱动,也可以在不建立明确的地图的情况下实现近乎完美的成功。
为了回答近乎完美的SPL是否也可以实现,我们需要在现实环境中对SPL设置一个严格的上限。回想一下,在现实设置驱动是有噪声的。因此,即使是一个对环境完全了解的oracle智能体也可能无法遵循最短路径并实现100%的SPL。例如如果智能体按照最短路径靠近障碍物,噪声驱动可能会使其与障碍物接触,此时需要进行避让,因此增加了其路径长度。
为了确定SPL的更严格的上限,我们实现了一个启发式规划器,它使用ground-truth映射来选择运动原语(转{左,右}×N,然后向前移动)。规划器选择使用真实地测地线距离(因此使用真实地图)最好地减少到目标的距离的原语,在选定的原语中执行第一个操作,然后重新运行选择过程,直到达到目标。在Gibson验证中,oracle达到84%的SPL。因此,在现实环境中,我们不应该期望100%的SPL。
然后,我们通过考虑给予神谕的特权信息(ground-truth map)来进一步收紧上限。考虑理想的设置,在这种设置中,智能体的挑战是未知环境中的路径规划,而不是额外满足于有噪声的驱动和观察。这种设置也被认为是Gibson数据集上的“解决”,使其成为量化地面真相地图影响的理想设置。在理想的设置中,在Gibson val上,oracle实现了99%的SPL,而对于一个学习智能体,最广为人知的结果是97%的SPL[33]。使用绝对或相对差异,我们预计在现实环境中,当oracle达到84%的SPL时,学习智能体可以达到大约82%的SPL。虽然80%并不是82%,但这表明视觉测程模块是限制因素(视觉测程模块的最佳结果是63% SPL),我们将在本文的其余部分将重点放在这个组件上
参考
文章链接:https://blog.csdn.net/weixin_42856843/article/details/129798138