1.VAE的直观理解
先简单了解一下自编码器,也就是常说的Auto-Encoder。Auto-Encoder包括一个编码器(Encoder)和一个解码器(Decoder)。其结构如下:

自编码器是一种先把输入数据压缩为某种编码, 后仅通过该编码重构出原始输入的结构. 从描述来看, AE是一种无监督方法.
AE的结构非常明确, 需要有一个压缩编码的Encoder和就一个相应解码重构的Decoder
那么VAE的目标是什么?为什么VAE呢?
-------VAE作为一个生成模型,其基本思路是很容易理解的:把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。
为什么要用VAE,原来的Auto Encoder有什么问题呢?那面下面是一个直观的解释。
下图是 AutoEncoder 的简单例子:我们把一张满月的图片 Encoder 后得到 code,这个code被decoder 后又转换为满月图,弦月图也是如此。注意它们直接的一对一关系。图片左边那个问号的意思是当对 AE 中的code进行随机采样时,它介于满月与弦月之间的数据,decoder后可能会输出什么?
-------------可能会输出满月,可能会输出弦月,但是最有可能输出的是奇奇怪怪的图片。
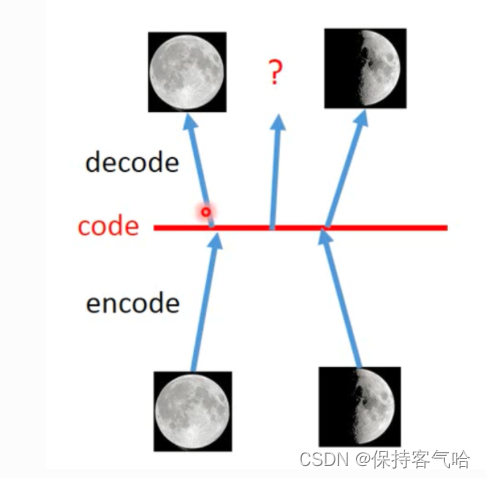
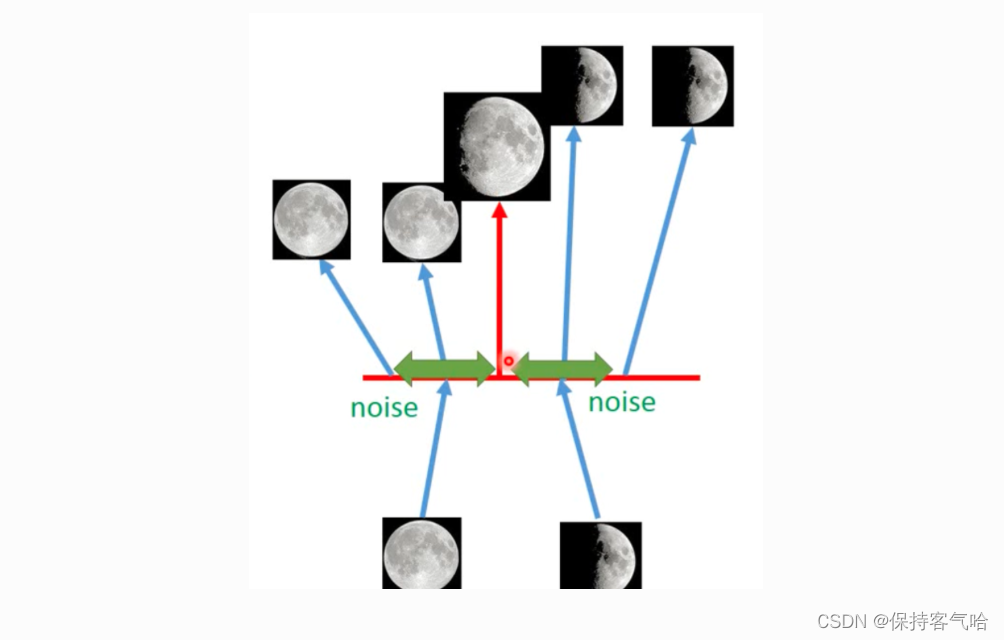
下图是 VAE 的简单例子,我们在 code 中添加一些 noise,这样可以让在满月对应 noise 范围内的code 都可以转换为满月,弦月对应的noise 范围内的code也能转换成弦月。但当我们在不是满月和弦月对应的noise的code中采样时,decoder出来的图片可能是介于满月和弦月之间的图。也就是说,VAE 产生了输入数据中不包含的数据,(可以认为产生了含有某种特定信息的新的数据),而 AE 只能产生尽可能接近或者就是以前的数据(当数据简单时,编码解码损耗少时)。
2.VAE的模型直观展示
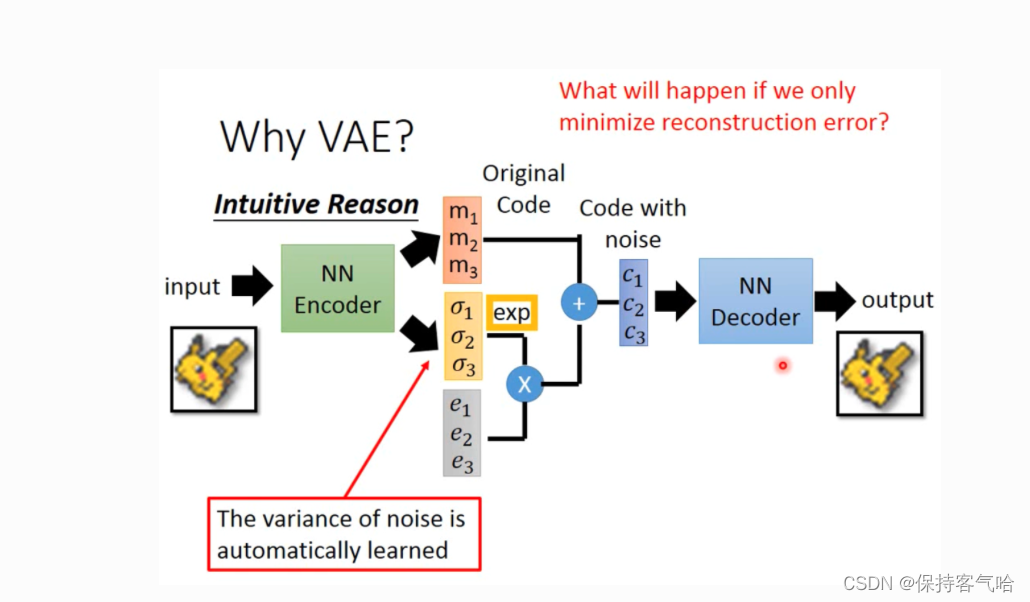
在VAE中,为了给编码添加合适的噪音,编码器会输出两个编码,一个是原有编码 m 1 , m 2 , m 3 m_1,m_2,m_3 m1,m2,m3,另外一个是控制噪音干扰程度的编码 σ 1 , σ 2 , σ 3 \sigma_1,\sigma_2,\sigma_3 σ1,σ2,σ3,第二个编码其实很好理解,就是为随机噪音码 e 1 , e 2 , e 3 e_1,e_2,e_3 e1,e2,e3分配权重,然后加上exp的目的是为了保证这个分配的权重是个正值,最后将原编码与噪音编码相加,就得到了VAE在code层的输出结果 c 1 , c 2 , c 3 c_1,c_2,c_3 c1,c2,c3。
损失函数方面,除了必要的重构损失外,VAE还增添了一个损失函数,这同样是必要的部分,因为如果不加的话,整个模型就会出现问题:为了保证生成图片的质量越高,编码器肯定希望噪音对自身生成图片的干扰越小,于是分配给噪音的权重越小,这样只需要将 σ 1 , σ 2 , σ 3 \sigma_1,\sigma_2,\sigma_3 σ1,σ2,σ3赋为接近负无穷大的值就好了。所以,第二个损失函数就有限制编码器走这样极端路径的作用,这也从直观上就能看出来, e x p ( σ i ) − ( 1 + σ i ) exp(\sigma_i)-(1+\sigma_i) exp(σi)−(1+σi)在x=0处取得最小值,于是 σ 1 , σ 2 , σ 3 \sigma_1,\sigma_2,\sigma_3 σ1,σ2,σ3就会避免被赋值为负无穷大。
3.VAE的基本原理
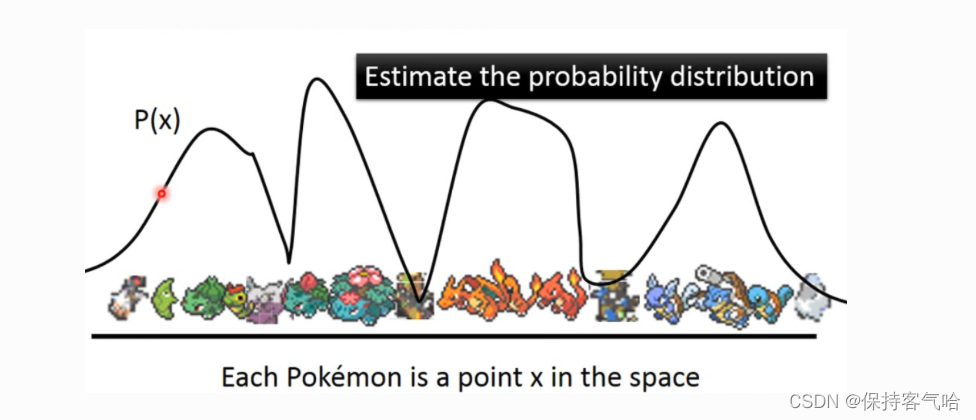
那先回到我们到底想做什么?我们现在是想要生成图片,就拿下图距离,每张图片可以看做高维空间的一个点,然后这些图片符合一个分布P(x),我们要做的事情就是去预测这个高维空间的概率分布P(x),只要我们知道这个分布我们就可以从中sample然后得到图片。
那如何去知道这个分布呢?我们先了解一下什么是高斯混合模型?------------即任何一个数据的分布,都可以看作是若干高斯分布的叠加。
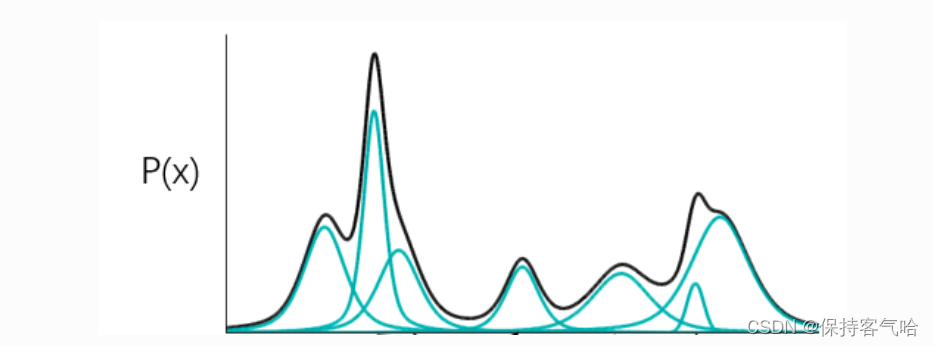
上图中黑色代表的是P(x)分布,蓝色的线都是不同的高斯分布,我们可以用若干个高斯分布去拟合P(x),那如果我们想要从P(x)去sample一个东西,那我们就要去考虑我们是从哪个高斯分布中去sample。然后这个这个过程可以表示为下图

其中最下面的代表的是高斯分布,m代表的是第几个高斯分布,蓝色的柱状图即P(m)代表的是去选择某一个高斯分布(m)的概率,所以P(x)可以表示为黄色标记所示,每个m对应的高斯分布有自己的均值和方差。
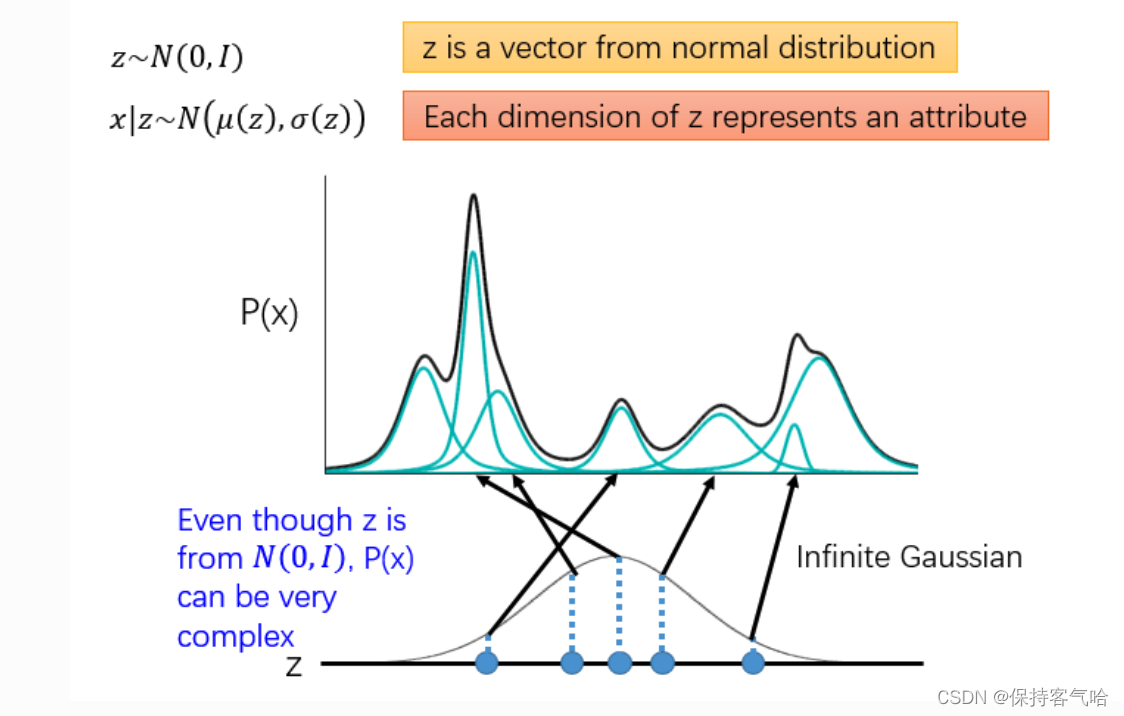
现在我们借助一个变量$ z\sim N(0,I)$ ,(注意z是一个向量,生成自一个高斯分布),找一个映射关系,将向量z映射成这一系列高斯分布的参数向量 μ ( z ) \mu (z) μ(z)和$ \sigma (z)$。有了这一系列高斯分布的参数我们就可以得到叠加后的P(x)的形式。也就是说我们只要知道每个高斯分布的参数,我们就能用它拟合P(x)
那么现在 P ( x ) = ∫ P ( z ) P ( x ∣ z ) d z ( 1 ) P(x) = ∫P(z)P(x∣z)dz \quad(1) P(x)=∫P(z)P(x∣z)dz(1) , 其中 z ∼ N ( 0 , I ) , x ∣ z ∼ N ( μ ( z ) , σ ( z ) ) z \sim N(0,I), \quad x|z \sim N \big(\mu(z), \sigma(z)\big) z∼N(0,I),x∣z∼N(μ(z),σ(z))
接下来就可以求解这个式子。由于P(z)是已知的,P(x|z)未知,而 x ∣ z ∼ N ( μ ( z ) , σ ( z ) ) x|z \sim N \big(\mu(z), \sigma(z)\big) x∣z∼N(μ(z),σ(z)),于是我们真正需要求解的,是 μ ( z ) \mu (z) μ(z)和$ \sigma (z)$两个函数的表达式。很难直接计算积分部分,因为我们很难穷举出所有的向量z用于计算积分,我们需要引入两个神经网络来帮助我们求解。
-
第一个神经网络在VAE叫做Decoder,它求解的 μ ( z ) \mu (z) μ(z)和$ \sigma (z)$和两个函数,这等价于求解P(x|z)。

-
第二个神经网络在VAE叫做Encoder,它求解的结果是 q ( z ∣ x ) , z ∣ x ∼ N ( μ ′ ( x ) , σ ′ ( x ) ) q(z∣x), z|x \sim N\big(\mu^\prime(x), \sigma^\prime(x)\big) q(z∣x),z∣x∼N(μ′(x),σ′(x)),q可以代表任何分布。它主要是用来得到给定一个 x 然后得到对应 z 的 μ ′ ( x ) , σ ′ ( x ) \mu^\prime(x), \sigma^\prime(x) μ′(x),σ′(x)

这儿引入第二个神经网络Encoder的目的是,辅助第一个Decoder求解P(x|z)
现在梳理一下我们的目的,我们需要求P(x),然后P(x)可以表示为:
P ( x ) = ∫ P ( z ) P ( x ∣ z ) d z P(x) = ∫P(z)P(x∣z)dz P(x)=∫P(z)P(x∣z)dz
我们希望P(x)越大越好,等价于求
M a x m i z e L = ∑ x l o g P ( x ) Maxmize L = \sum_x logP(x) MaxmizeL=x∑logP(x)
又因为
log P ( x ) = ∫ z q ( z ∣ x ) log P ( x ) d z \log P(x) = \int_z q(z|x) \log P(x) dz logP(x)=∫zq(z∣x)logP(x)dz
因为 ∫ z q ( z ∣ x ) d z = 1 \int_z q(z|x) dz = 1 ∫zq(z∣x)dz=1
所以
log P ( x ) = ∫ z q ( z ∣ x ) log P ( z , x ) P ( z ∣ x ) d z = ∫ z q ( z ∣ x ) log P ( z , x ) q ( z ∣ x ) q ( z ∣ x ) P ( z ∣ x ) d z = ∫ z q ( z ∣ x ) log P ( z , x ) q ( z ∣ x ) d z + ∫ z q ( z ∣ x ) log q ( z ∣ x ) P ( z ∣ x ) d z = D K L ( q ( z ∣ x ) ∣ ∣ P ( z ∣ x ) ) + ∫ z q ( z ∣ x ) log P ( z , x ) q ( z ∣ x ) d z ≥ ∫ z q ( z ∣ x ) log P ( x ∣ z ) P ( z ) q ( z ∣ x ) d z since D K L ( q ∣ ∣ P ) ≥ 0 \begin{aligned} \log P(x) &= \int_z q(z|x) \log \frac{P(z,x)}{P(z|x)} dz \\ &= \int_z q(z|x) \log \frac{P(z,x)q(z|x)}{q(z|x)P(z|x)} dz \\ &= \int_z q(z|x) \log \frac{P(z,x)}{q(z|x)} dz + \int_z q(z|x) \log \frac{q(z|x)}{P(z|x)} dz \\ &= D_{KL}(q(z|x) || P(z|x)) + \int_z q(z|x) \log \frac{P(z,x)}{q(z|x)} dz \\ &\geq \int_z q(z|x) \log \frac{P(x|z)P(z)}{q(z|x)} dz \quad \text{since } D_{KL}(q||P) \geq 0 \end{aligned} logP(x)=∫zq(z∣x)logP(z∣x)P(z,x)dz=∫zq(z∣x)logq(z∣x)P(z∣x)P(z,x)q(z∣x)dz=∫zq(z∣x)logq(z∣x)P(z,x)dz+∫zq(z∣x)logP(z∣x)q(z∣x)dz=DKL(q(z∣x)∣∣P(z∣x))+∫zq(z∣x)logq(z∣x)P(z,x)dz≥∫zq(z∣x)logq(z∣x)P(x∣z)P(z)dzsince DKL(q∣∣P)≥0
我们将 ∫ z q ( z ∣ x ) log P ( x ∣ z ) P ( z ) q ( z ∣ x ) d z \int_z q(z|x) \log \frac{P(x|z)P(z)}{q(z|x)} dz ∫zq(z∣x)logq(z∣x)P(x∣z)P(z)dz 称为 log P ( x ) \log P(x) logP(x) 的 (variational) lower bound (变分下界),简称为 L b L_b Lb。
即 原式化简为 l o g P ( x ) = L b + K L ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) log P(x) = L_b + KL(q(z|x)||p(z|x)) logP(x)=Lb+KL(q(z∣x)∣∣p(z∣x))
原本,我们需要求 P ( x ∣ z ) P(x|z) P(x∣z) 使得 l o g P ( x ) log P(x) logP(x) 最大,现在引入了一个 q ( z ∣ x ) q(z|x) q(z∣x),变成了同时求 P ( x ∣ z ) P(x|z) P(x∣z)和 q ( z ∣ x ) q(z|x) q(z∣x)使得 l o g P ( x ) log P(x) logP(x)最大。实际上,因为后验分布 P ( z ∣ x ) P(z|x) P(z∣x) 很难求 (intractable),所以才用 q ( z ∣ x ) q(z|x) q(z∣x) 来逼近这个后验分布。在优化的过程中我们发现,首先 q ( z ∣ x ) q(z|x) q(z∣x) 跟 log P ( x ) \log P(x) logP(x) 是完全没有关系的, log P ( x ) \log P(x) logP(x) 只跟 P ( z ∣ x ) P(z|x) P(z∣x) 有关,调节 q ( z ∣ x ) q(z|x) q(z∣x) 是不会影响似然也就是 log P ( x ) \log P(x) logP(x) 的。所以,当我们固定住 P ( x ∣ z ) P(x|z) P(x∣z) 时,调节 q ( z ∣ x ) q(z|x) q(z∣x) 最大化下界 L b L_b Lb,KL 则越小。当 q ( z ∣ x ) q(z|x) q(z∣x) 逼近后验分布 P ( z ∣ x ) P(z|x) P(z∣x) 时,KL 散度趋于为 0, log P ( x ) \log P(x) logP(x) 就和 L b L_b Lb 等价。所以最大化 log P ( x ) \log P(x) logP(x) 就等价于最大化 L b L_b Lb。
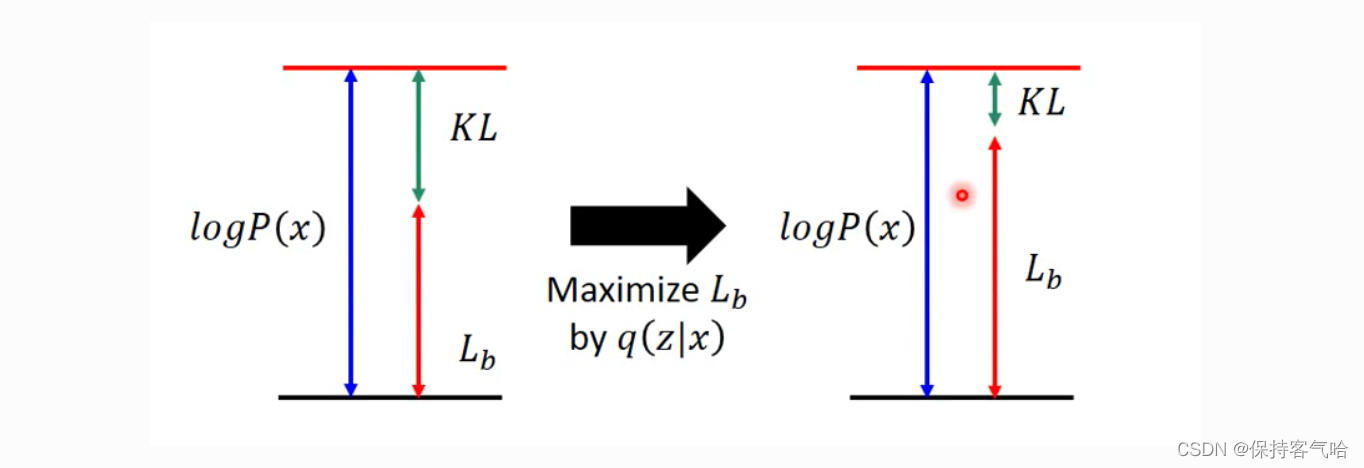
现在我们来求 Maxmize L b L_b Lb
L b = ∫ z q ( z ∣ x ) log P ( z , x ) q ( z ∣ x ) d z = ∫ z q ( z ∣ x ) log P ( x ∣ z ) P ( z ) q ( z ∣ x ) d z = ∫ z q ( z ∣ x ) log P ( z ) q ( z ∣ x ) d z + ∫ z q ( z ∣ x ) log P ( x ∣ z ) d z = − D K L ( q ( z ∣ x ) ∣ ∣ P ( z ) ) + E q ( z ∣ x ) [ log P ( x ∣ z ) ] \begin{aligned} L_b &= \int_z q(z|x) \log \frac{P(z,x)}{q(z|x)} dz \\ &= \int_z q(z|x) \log \frac{P(x|z)P(z)}{q(z|x)} dz \\ &= \int_z q(z|x) \log\frac {P(z)}{q(z|x)} dz +\int_z q(z|x) \log P(x|z) dz \\ &= -D_{KL}(q(z|x) || P(z)) + E_{q(z|x)}[\log P(x|z)] \end{aligned} Lb=∫zq(z∣x)logq(z∣x)P(z,x)dz=∫zq(z∣x)logq(z∣x)P(x∣z)P(z)dz=∫zq(z∣x)logq(z∣x)P(z)dz+∫zq(z∣x)logP(x∣z)dz=−DKL(q(z∣x)∣∣P(z))+Eq(z∣x)[logP(x∣z)]
所以,求解 Maxmize L b L_b Lb,等价于求解KL(q(z|x)||P(z))的最小值和==$ E_{q(z|x)}[\log P(x|z)]$的最大值。==
-
我们先来求第一项,其实 − D K L ( q ( z ∣ x ) ∣ ∣ P ( z ) ) -D_{KL}(q(z|x) || P(z)) −DKL(q(z∣x)∣∣P(z))的展开式刚好等于: ∑ i = 1 J ( e x p ( σ i ) − ( 1 − σ i ) + ( m i ) 2 ) \sum _{i=1}^J (exp(\sigma_i)-(1-\sigma_i)+(m_i)^2) ∑i=1J(exp(σi)−(1−σi)+(mi)2),于是,第一项式子就是第二节VAE模型架构中第二个损失函数的由来,其实就是去调节NN’使得到的q(z|x)与标准正态分布约接近越好
-
接下来求第二项,注意到Maxmize$ E_{q(z|x)}[\log P(x|z)]$,也就是表明在给定求q(z|x)(编码器输出)的情况下p(x|z)(解码器输出)的值尽可能高,这其实就是一个类似于Auto-Encoder的损失函数(方差忽略不计的话),过程如下图所示:
-

-
我们要想从q(z|x)中sample一个data,就将x输入到NN中,产生 μ ′ ( x ) , σ ′ ( x ) \mu^\prime(x), \sigma^\prime(x) μ′(x),σ′(x),然后产生z,接下来我们要maxmize z产生x的几率,即要想输出maxmize log P(x|z)就需要让NN的输出 μ ( x ) \mu(x) μ(x) 与 x越接近越好
-