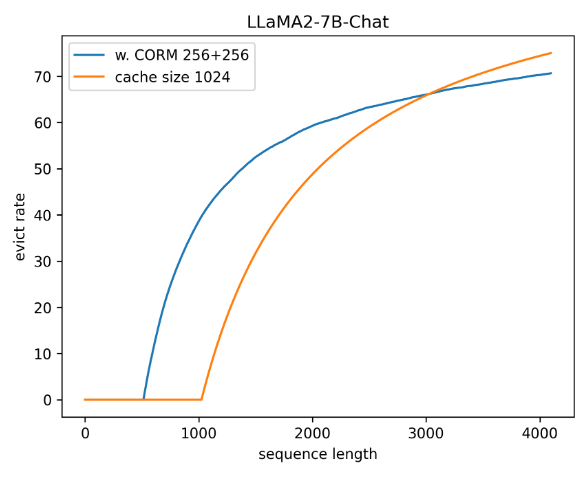
为什么需要做分布式redis
- 水平扩展:
随着业务的发展,单机Redis可能无法满足日益增长的数据存储和访问需求。分布式Redis可以通过将数据分散到多个节点上来实现水平扩展,提高存储容量和处理能力。 - 高可用性:
单点故障是任何系统的一大风险。分布式Redis通过复制和故障转移机制,确保即使某个节点失效,服务仍能继续运行,从而提高了系统的可用性。 - 负载均衡:
分布式Redis可以将读写请求分散到多个节点,减少单个节点的压力,实现负载均衡,提高系统整体性能。 - 数据冗余与安全性:
主从复制机制确保数据有多份副本,即使某个节点出现问题,也可以从其他节点恢复数据,增强了数据的安全性。 - 故障恢复:
当节点出现故障时,分布式Redis可以通过自动或手动的故障转移机制,快速恢复服务,降低业务中断的影响。
更好的地理分布:
就是适应当下的分布式环境来做的分布式redis。
批量启动脚本
# 端口号从7001到7006开始循环
for port in $(seq 7001 7006); \
do \
# 创建node-port的文件夹
mkdir -p /mydata/redis/node-${port}/conf
# 给文件夹创建redis的配置类
touch /mydata/redis/node-${port}/conf/redis.conf
# 给redis.conf文件中写入内容,从EOF开始,到EOF结束。
cat << EOF > /mydata/redis/node-${port}/conf/redis.conf
# 定义端口号
port ${port}
# 开启集群模式
cluster-enabled yes
# 节点信息在nodes.conf保存着
cluster-config-file nodes.conf
# 每个节点的超时时间,超过多长时间连接不上就认为是断线了。超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 5000
# 每个节点在集群中的ip
cluster-announce-ip 192.168.1.119
# 在集群的端口号
cluster-announce-port ${port}
# 跟其他redis进行总线交互用的端口
cluster-announce-bus-port 1${port}
appendonly yes
EOF
# 暴露端口号 端口号 集群交互暴露端口号 集群交互端口号 容器名字
docker run -p ${port}:${port} -p 1${port}:1${port} --name redis-${port} \
# 挂载data目录 redis.conf 目录
-v /mydata/redis/node-${port}/data:/data \
-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \
# -d以后台方式 镜像版本 redis-server启动redis 加载自定义的配置文件
-d redis:5.0.7 redis-server /etc/redis/redis.conf; \
donewindows命令换行符问题
vim进去后
:set ff=unix
:wq
这样子可以改变换行符
注意
需要更换里面的地址ip
三主三从是一个最低配置,以实际情况为准
启动集群命令
# 进入redis-7001内部
docker exec -it redis-7001 bash
# 用redis-cli命令行执行 创建集群 一个副本
redis-cli --cluster create 192.168.1.119:7001 192.168.1.119:7002 192.168.1.119:7003 192.168.1.119:7004 192.168.1.119:7005 192.168.1.119:7006
--cluster-replicas 1