目前各类大模型都支持长文本,例如 kimi chat 以及 gemini pro,都支持 100K 以及更高的上下文长度。但越长的上下文,在推理过程中需要存储的 kv cache 也越多。假设,数据的批次用 b 表示,输入序列的长度仍然用 s 表示,输出序列的长度用 n 表示,隐藏层维度用 h 表示,层数用 l 表示。kv cache 的峰值显存占用大小 = b ∗ ( s + n ) ∗ h ∗ l ∗ 2 ∗ 2 = 4 b l h ( s + n ) b * (s + n) * h * l * 2 * 2 = 4blh(s + n) b∗(s+n)∗h∗l∗2∗2=4blh(s+n),这里的第一个 2 表示 k 和 v cache,第二个 2 表示 float16 数据格式存储 kv cache,每个元素占 2 bytes。
然而,目前的大多数 LLM 会使用 GQA 而非 MHA,因此 kv cache 的占用量会更少,以 transformers 的 modeling_llama.py 脚本中的实现为例:
class LlamaAttention(nn.Module):def __init__(self, config: LlamaConfig, layer_idx: Optional[int] = None):super().__init__()# ...self.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.hidden_size // self.num_headsself.num_key_value_heads = config.num_key_value_headsself.num_key_value_groups = self.num_heads // self.num_key_value_heads# ...def forward(#...) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:# ...key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)# ...
其中,q_len = s + n,bsz = b,self.hidden_size = h,然而,self.num_key_value_heads 会小于 self.num_heads,以 Llama3-8B 为例:
"hidden_size": 4096,
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
k 和 v 的注意力头是 q 的 1/4,因此 kv cache 的峰值显存占用大小还可以继续除以 4,在这里暂时表示为 b l h ( s + n ) blh(s + n) blh(s+n)(注意,不同模型的比例不同,需要根据情况调整计算公式)。
示例:我们继续以 Llama3-8B 为例,来计算不同长度时的 kv cache 显存占用。令 b = 1,n = 32。
- s = 512: 32 × 4096 × ( 512 + 32 ) = 71 , 303 , 168 ≈ 0.066 G B 32 \times 4096 \times (512 + 32) = 71,303,168 \approx 0.066GB 32×4096×(512+32)=71,303,168≈0.066GB。
- s = 16,384: 32 × 4096 × ( 1024 + 32 ) = 71 , 303 , 168 ≈ 2.004 G B 32 \times 4096 \times (1024+ 32) = 71,303,168 \approx 2.004GB 32×4096×(1024+32)=71,303,168≈2.004GB。
- s = 327,680: 32 × 4096 × ( 1024 + 32 ) = 71 , 303 , 168 ≈ 40.004 G B 32 \times 4096 \times (1024+ 32) = 71,303,168 \approx 40.004GB 32×4096×(1024+32)=71,303,168≈40.004GB。
可以看到,随着 context 长度的增加,kv cache 的显存占用量也随之呈线性增长,成为推理的主要瓶颈。在论文《Sequence can Secretly Tell You What to Discard》中,作者介绍了一种优化 KV 缓存的新方法,它能显著减少 KV 缓存的内存占用。通过综合研究,发现在 LLaMA2 系列模型上:
- 相邻 token 的 query 向量之间的相似度非常高;
- 当前 query 的注意力计算可以完全依赖于一小部分前面 query 的注意力信息。
基于这些观察结果,作者提出了一种 KV 缓存驱逐策略 CORM,它能在不对模型进行微调的情况下动态保留重要的 kv 对进行推理。
观察实验与结果
LLMs 中的注意力稀疏性
首先探讨 LLM 注意力层的稀疏性,这是减少 KV 缓存大小的有效前提和依据。具体来说,用重要 key 的比例来表示注意力稀疏性。让 q t ∈ R 1 × d q_t \in \R^{1 \times d} qt∈R1×d 表示第 t 步的 query state 向量, k i ∈ R 1 × d k_i \in \R^{1 \times d} ki∈R1×d 表示第 i ( 1 < i < t) 步的 key state 向量,其中 d 是隐藏层维度(为简单起见,这里只考虑单个注意力头)。 q t q_t qt 对 k i k_i ki 的归一化注意力分数的计算公式:
α t , i = e x p ( q t k i T / d ) ∑ j = 1 t e x p ( q t k j T / d ) . (2) \alpha_{t, i} = \frac{exp(q_t k_i^T / \sqrt{d})}{\sum_{j=1}^t exp(q_t k_j^T / \sqrt{d})}. \tag{2} αt,i=∑j=1texp(qtkjT/d)exp(qtkiT/d).(2)
定义 1(重要 key):当且仅当 α t , i ≥ 1 t \alpha_{t, i} \geq \frac{1}{t} αt,i≥t1,key k i k_i ki 在步骤 t 中被视为重要 key,否则被视为 minor(次要)key。
作者在 PG-19 测试集上使用 LLaMA2-7B 模型进行 zero-shot 推断。绘制了注意力区块内的 layer-wise 稀疏度和head-wise 稀疏度,结果如图 1 所示。

图 1:LLaMA2-7B 的注意力稀疏度。(a) layer-wise 注意力稀疏度。(b) 第 0 层和第 1 层的 head-wise 注意力稀疏度。
结果显示,底层相对密集,而其他层高度稀疏,稀疏度超过 90%。这说明在生成过程中只需要使用一小部分 kv cache 就可以尽量维持原始的生成结果。
相似的 query 对 key 有相似的关注
考虑 token 长度为 T 的序列(i < j ≤ T)中的第 i 和第 j 个 query state 向量 q i q_i qi 和 q j q_j qj。它们的余弦相似度可计算为:
c o s i n e _ s i m i l a r i t y ( q i , q j ) = q i q j T ∣ ∣ q i ∣ ∣ ⋅ ∣ ∣ q j ∣ ∣ . (3) cosine\_similarity(q_i, q_j) = \frac{q_iq_j^T}{||q_i|| \cdot ||q_j||}. \tag{3} cosine_similarity(qi,qj)=∣∣qi∣∣⋅∣∣qj∣∣qiqjT.(3)
考虑第 i 个 key 之前的所有 key states k 1 , k 2 , … , k i − 1 k_1, k_2, \ldots, k_{i-1} k1,k2,…,ki−1。假设 c o n s i n e _ s i m i l a r i t y ( q i , q j ) = 1 consine\_similarity(q_i, q_j) = 1 consine_similarity(qi,qj)=1,则 q i = m ⋅ q j , m ∈ R + q_i = m \cdot q_j, m \in \R^+ qi=m⋅qj,m∈R+。 q i q_i qi 对前 i - 1 个 key 的关注权重(attention weight)可以表示为:
a t t e n t i o n _ w e i g h t = 1 d ( q i k 1 T , q i k 2 T , … , q i k i − 1 T ) = m d ⋅ ( q j k 1 T , q j k 2 T , … , q j k i − 1 T ) ⋅ (4) attention\_weight = \frac{1}{\sqrt{d}}(q_ik_1^T, q_ik_2^T, \ldots, q_ik_{i-1}^T) = \frac{m}{\sqrt{d}} \cdot (q_jk_1^T, q_jk_2^T, \ldots, q_jk_{i-1}^T)\cdot \tag{4} attention_weight=d1(qik1T,qik2T,…,qiki−1T)=dm⋅(qjk1T,qjk2T,…,qjki−1T)⋅(4)
注意,m 是一个正数,不会影响注意力权重的相对顺序。例如,对于 q i q_i qi 而言,如果 q i k 1 T ≥ q i k 2 T q_ik_1^T \ge q_ik_2^T qik1T≥qik2T,那么 q j q_j qj 一定是 q j k 1 T ≥ q j k 2 T q_jk_1^T \ge q_jk_2^T qjk1T≥qjk2T。这意味着,如果某个 key 对 q i q_i qi 很重要,那么它对 q j q_j qj 也很重要,尽管重要程度可能会因 softmax 函数而不同。
虽然在实际情况中, c o s i n e _ s i m i l a r i t y ( q i , q j ) = 1 cosine\_similarity(q_i, q_j) = 1 cosine_similarity(qi,qj)=1 几乎是不可能的,但可以提出这样的假设:两个相似的 query 可能对 key 有相似的关注。为了验证这一假设,使用 LLaMA2-7B 提供了两个从 PG-19 中随机抽取的句子的注意力图,如图 2 所示。

图 2:相似的 query 对 key 有相似的关注。作者绘制了一个句子中两个不同层的注意力图。将注意力分数离散化,重要的 key 显示为亮绿色。每个注意力图都有两条红色边框,底边显示当前 query 实际关注的重要 key,另一条边框显示最相似 query 关注的重要 key。
重要 key 以亮绿色标出,观察到,假设是正确的,相似的 query 对重要 key 的关注也是相似的。同时,重要 key 只占很小一部分,尤其是在较深(离输出近的层,下图)的注意力层中,这与上一节中发现的较深层较稀疏的情况是一致的。
另外,下图中序列开头位置处的 key 都是亮绿色,表示这些 key 是重要的 key,这与先前的一些研究,例如 LM-infinite 和 Attention Sink 有着相同的结论。
问题:什么是 Attention Sink?
回答:在标准的注意力机制中,模型会计算输入序列中每个元素(如单词或token)对其他元素的重要性,并据此分配不同的注意力权重。然而,在某些情况下,模型可能会对输入序列中的某些特定元素赋予异常高的注意力权重,这种现象有时被称为 “Attention Sink” —— 摘自 kimi chat 的回答。
问题:LM-infinite 提出了什么观点?
回答:开头的⼏个 Token 是绝对位置的“锚点”:顾名思义,相对位置编码原则上只能识别相对位置,但有些任务可能⽐较依赖绝对位置,通过开头⼏个绝对位置约等于 0 的 Token 作为“锚点”,每个 Token 就能够测出⾃⼰的绝对位置,⽽去掉开头⼏个 Token 后则缺失了这⼀环,从⽽完全打乱了注意⼒模式,导致 PPL 爆炸 —— 摘自前同事龙哥的调研结果;
query 向量的相似性探索
上一节已经验证了两个相似的 query 对 key 有相似的关注,因此还需要验证,在每一步中,是否能找到与当前 query state 足够相似的同层同头的前一个 query state。为了验证这一点,作者对同一序列中 query 向量的余弦相似度进行了可视化处理,如图 3 所示。

图 3:一个长度为 1024 的句子的 query 向量余弦相似度可视化图。图中第 i 行表示第 i 个 query 与之前所有 query 的余弦相似度。该图显示,在大多数情况下,当前 query 与最近的 query 最为相似。
观察到一个有趣的现象,许多图像都显示出明显的斜向颜色分割,最上面的斜向块最接近暗红色,这意味着当前 query 与最近的 query 最为相似。
CORM 方法
在本节中,介绍 CORM,一种无需任何微调过程就能根据最近的 query 注意力信息来减少 KV Cache 的方法。
直观地说,可以直接存储所有 query 及其注意力信息,以备将来参考。在每个生成步骤中,使用当前 query 从之前 queries 中找出最相似的 query’,并使用其保存的注意力信息单独计算重要的 key。然而,这种方法会产生很大的成本:
- 首先,存储所有 query 会大幅增加内存开销。
- 其次,每一步都需要进行相似性计算,这也增加了计算开销。
由于大多数情况下当前 query 与最近 query 最为相似,因此可以只使用最近 query 的注意力信息。从图 2 中还可以观察到,只有一小部分 key 被最近的 query 认为是重要的。因此,即使保存了所有在前几步中被认为重要的 key,也能节省大量内存。
定义 2(Long-term Minor Key):只有在最近的所有 r 步(从 t - r + 1 到 t)中都被认为是 minor key 的情况下, k i k_i ki才被认为是 long-term minor key。
CORM 将有一个大小为 w 的最近窗口来记录最近 w 次的 query 信息,并将始终保持最近 r 个 key 不被删除,以防止因观察不足而过早丢弃。在生成过程中,一旦 k i k_i ki 被视为 long-term minor key, k i , v i k_i, v_i ki,vi 将被丢弃。直观地说,w 越大,保存的 key 和 value 越多,压缩率越小,性能越好;反之,w 越小,保存的 key 和 value 越少,压缩率越大,性能越差。因此,性能和压缩率之间需要权衡。
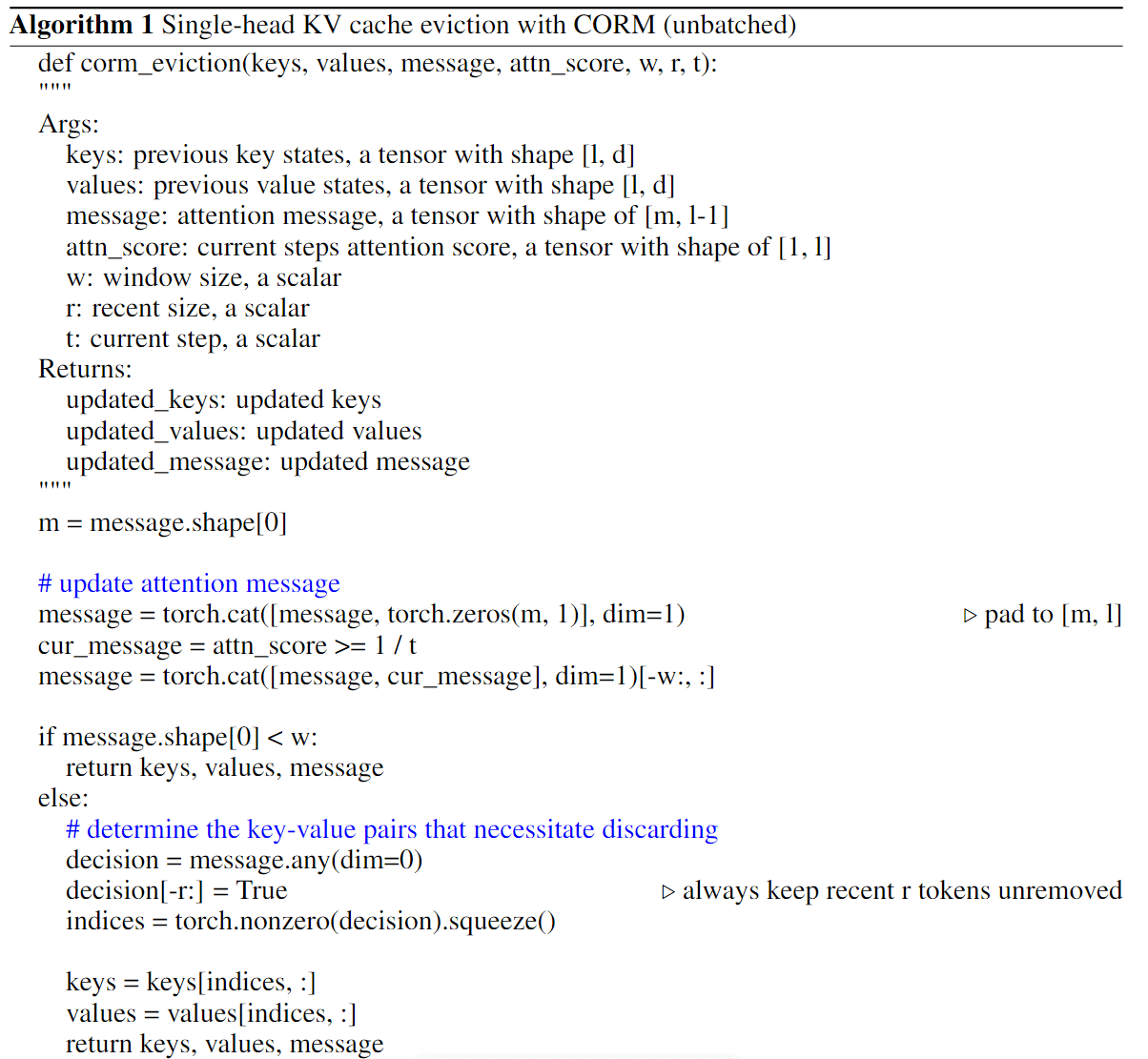
判断某一位置的 key 是否与未来(滑动窗口大小)query 的注意力分数都低于定义 1 的阈值,如果是则说明该 key 是个 minor key,它对于生成提供的信息有限,那么它就可以被“驱逐”。被“驱逐”的 key(value 也一同被“驱逐”)越多,需要参与到注意力计算的 key 也就越少,需要缓存的 kv 对也就越少。
实验结果
对 4K 长文本的 LLaMA2-7B-Chat 进行了评估。表 1 和表 2 总结了 LLaMA2-7B-Chat 的结果。
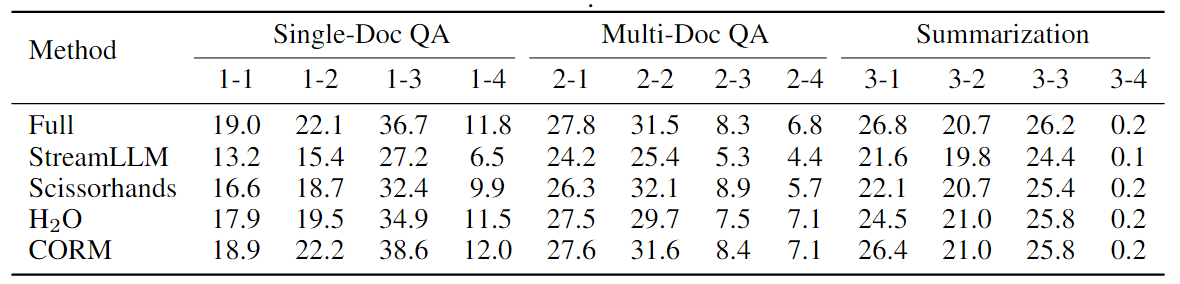
表 1: 单文档 QA、多文档 QA 和摘要任务的结果(%)。“Full”指使用完整 KV Cache 的 LLaMA2-7B-Chat,“StreamLLM”配置为 4+1020,“Scissorhands”配置为 768+256(窗口大小 = 256),“H2O”配置为 768+256,“CORM”配置为 256+256,以便进行公平比较。为简洁起见,在此使用 ID 表示数据集,ID 与数据集的映射关系见附录 B。
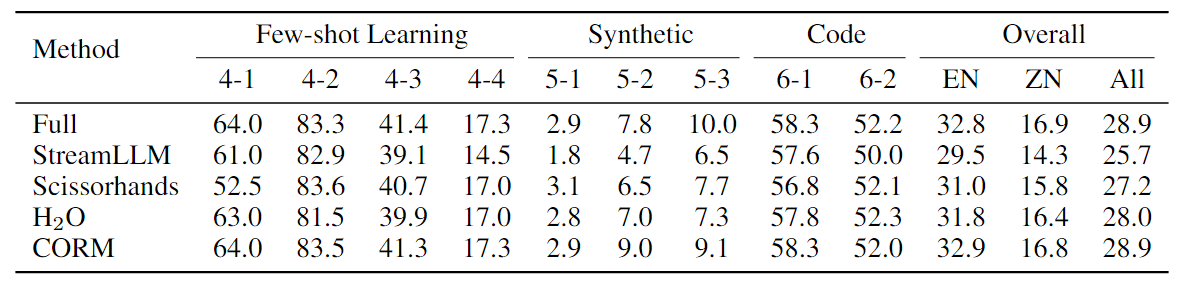
表 2: few-shot learning、合成和代码任务的结果(%)。“Overall”按主要任务类别的宏观平均值计算。这是按英文(EN)任务、中文(ZH)任务和所有(All)任务计算的,两种语言都包括代码任务。
可以得出以下结论:
- 在各种任务中,CORM 在相同的压缩率下始终优于以前的方法。
- 在减少 70% 以上 KV Cache 的情况下,CORM 的性能与使用全 KV Cache 的模型相当,甚至在某些任务上超过了它。作者推测这是因为全 KV Cache 中存在一些影响模型输出的噪声,而 CORM 通过丢弃部分 KV Cache 可以在一定程度上消除这些噪声。
看实验的结果很棒,但是否存在某个 key 与未来一段时间(滑动窗口)内的 query 的相似度都很低,在这之后才出现较高的相似度?而此时,如果将该 key 认为是不重要而进行丢弃的话,未来的 query 可能获取不到这部分信息。
看到这篇论文,联想起去年的 EMNLP 的最佳论文《Label Words are Anchors:An Information Flow Perspective for Understanding In-Context Learning》,大家有兴趣的可以去阅读下。同时,似乎也能和 prompt 压缩相关的方法产生关联(具体如何联系,我得重温下相关的论文,看看它们是如何过滤 token),例如 selective context 和微软的 LLMLingua。它们更多地是减少 prompt 的长度,降低调用 API 的费用,在过滤低信息的 token 时,也会改变保留后 token 的相对位置。在实际使用过程中,性能会有所损失。
这篇论文讲述推理阶段,最近另一篇论文《RHO-1:Not All Tokens Are What You Need》,则从训练角度论证了“并非语料库中的所有 token 对语言模型训练都同样重要”,初步分析深入研究了语言模型的 token 级训练动态,揭示了不同 token 的不同损失模式。利用这些见解,推出了一种名为 RHO-1 的新语言模型,采用了选择性语言建模 (SLM),即有选择地对符合预期分布的有用 token 进行训练。这与最近的数据子集挑选方法(论文阅读:A Survey on Data Selection for LLM Instruction Tuning,以对话、文本为粒度挑选高质量训练子集)和 selective context 也能关联上。
内存开销分析
为了减少 KV Cache 的内存开销,最近信息缓存引入了额外的内存开销。我们需要存储最近的 query 信息,这增加了内存开销。不过,这些开销远小于压缩 KV Cache,我们可以使用一小部分内存来避免维持完整的 KV Cache 内存,而不会明显降低性能。另一方面,如图 4 所示,压缩率会随着序列长度的增加而增加,因此相比之下,该组件的内存开销较低。
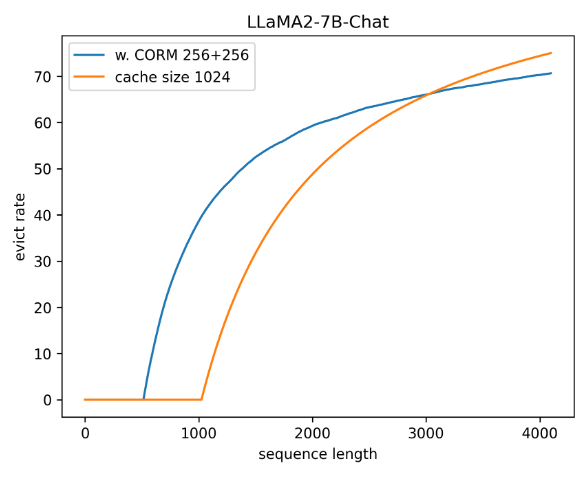
图 4:压缩率与序列长度之间的关系。从图中可以看出,LLaMA2-7B-Chat 在 CORM 为“256+256”和预算 = 1024 时的压缩率比较接近。
总结
本文研究了 LLM 部署中的一个关键内存瓶颈——KV Cache。受相似 query 对 key 有相似关注以及最近 query 足够相似的启发,作者提出了一种无预算的 KV Cache 驱逐策略 CORM,通过重复使用最近的 query 注意力信息来显著减少显存占用。通过广泛的评估,作者证明 CORM 可以将 KV Cache 的推理显存使用量减少多达 70%,而在各种任务中不会出现明显的性能下降。