本博客给出AutoGPT-forge四个教程的翻译与理解,使用GPT4翻译,
参考官方教程https://aiedge.medium.com/autogpt-forge-a-comprehensive-guide-to-your-first-steps-a1dfdf46e3b4
使用AutoGPT Github代码日期2024/4/22;
博客开始编辑日期2024/4/22,最后编辑日期2024/4/24
初始安装与使用
-
下载autogpt
git clone https://github.com/Significant-Gravitas/AutoGPT.git -
进入目录并进行设置
cd AutoGPT ./run setup -
如果出现红字,那么需要配置GitHub access token,步骤如下:
1. Ensure you are logged into your GitHub account 2. Navigate to https://github.com/settings/tokens 3. Click on 'Generate new token'. 4. Click on 'Generate new token (classic)'. 5. Fill out the form to generate a new token. Ensure you select the 'repo' scope. 6. Open the '.github_access_token' file in the same directory as this script and paste the token into this file. 7. Save the file and run the setup command again.出现如下提示,则表示设置正确
🚀 Setup initiated...✅ Git is configured with name 'wzh009888' and email 'wzh009888@outlook.com' ✅ GitHub access token loaded successfully. ✅ GitHub access token has the required permissions. -
创建你的agent,替换YOUR_AGENT_NAME为你想要的名字
./run agent create YOUR_AGENT_NAME -
启动你的agent,替换YOUR_AGENT_NAME为你想要的名字
./run agent start YOUR_AGENT_NAME -
使用浏览器访问你的agent,网址如下所示,此时的对话并没有嵌入LLM
http://localhost:8000/ -
退出agent的指令如下所示:
./run agent stop
了解AutoGPT Forge:
什么是LLM-Based AI Agent
大型语言模型(LLMs)是最先进的机器学习模型,它们利用了大量的网络知识。但当你将这些LLM和自主Agent相结合会发生什么?你将得到基于LLM的Ai Agent —— 一种新的人工智能,承诺提供更人性化的决策。
传统的自主Agent操作的知识有限,通常限于特定的任务或环境。它们就像计算器——高效但仅限于预定义的函数。然而,基于LLM的Agent就像将百科全书和计算器相结合。它们不仅进行计算;它们理解、推理,然后行动,从大量的信息中获取。
Agent Landscape Survey强调了这种演变,详细描述了LLM在实现人类智能方面所展现出的显著潜力。它们不仅关注更多的数据;它们代表了对AI的更全面的方法,弥合了孤立任务知识和广泛网页信息之间的差距。
在此基础上,进一步扩展, The Rise and Potential of Large Language Model Based Agents: A Survey将LLM视为下一代Ai Agent的基础模块。这些Agent感知、决策和行动,全部由LLM的全面知识和适应性支持。这是一个关于Ai Agent研究的知识的不可思议的来源,参考了近700篇研究论文,并按照研究领域进行了组织。
LLM-Based AI Agent的剖析
深入研究LLM-Based AI Agent的核心,我们发现它的结构很像人类,具有类似于个性、记忆、思维过程和能力的独特组件。让我们来分析一下:
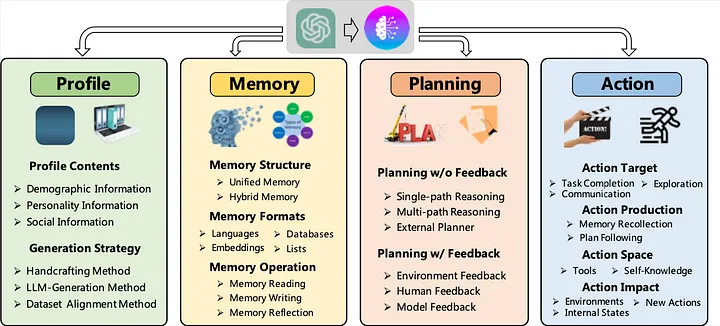
1. Profile
当我们人类专注于各种任务时,我们会为这些任务做好准备。无论我们是在写作、切菜、驾驶还是运动,我们都会集中注意力,甚至采取不同的心态。这种适应性就是讨论Agent时,个人特征概念所暗示的。研究表明,简单地告诉一个Agent它是一个特定任务的专家,就可以提高其性能。
特征模块的潜在应用超越了单纯的提示工程。它可以用于调整Agent的记忆功能、可用行动,甚至是驱动Agent的底层大型语言模型(LLM)。
2. Memory
对于Agent来说,记忆不仅仅是存储——它是其身份、能力的基础,也是其学习的基础。就像我们的记忆决定了我们的决策、反应,甚至我们的个性一样,Agent的记忆是其过去互动、学习和反馈的累积记录。两种主要类型的记忆塑造了Agent的认知:长期记忆和短期记忆。
长期记忆类似于Agent的基础知识,是一个包含了跨越长时间段的数据和互动的巨大储备。它是Agent的历史档案,指导其核心行为和理解。
另一方面,短期(或工作)记忆关注即时情况,处理短暂记忆,就像我们记忆近期事件一样。尽管对于实时任务来说至关重要,但并非所有的短期记忆都会进入Agent的长期存储。
在这个领域中,一个新兴的概念是记忆反思。在这里,Agent不仅存储记忆,而且主动回顾它们。这种内省让Agent可以重新评估、优先处理,甚至丢弃信息,就像人们回顾和从过去的经历中学习一样。
3. Planning
规划是Agent解决问题的路线图。面对复杂的挑战时,人类本能地将其分解成小而易管理的任务——这是LLM-basedAgent所反映的策略。这种有条理的方法使Agent能以结构化的心态导航问题,确保全面和系统的解决方案。
Agent的规划工具包中有两种主导策略。第一种,反馈规划,是一种适应性方法。在这里,Agent根据结果优化其策略,就像根据用户反馈迭代设计版本一样。
第二种,无反馈规划,将Agent视为策略家,完全依赖于其预先存在的知识和预见力。这就像一场国际象棋比赛,Agent预见挑战并提前准备几步。
4. Action
在记忆的内省和规划的策略制定之后,就到了最后一步:行动。这是Agent使用其能力将认知过程具体化为实际结果的地方。每一个决策,每一个思考,在行动阶段都会得到体现,把抽象的概念转化为明确的结果。
无论是撰写回应,保存文件,还是启动新的过程,行动组成部分都是Agent决策旅程的结尾。它是数字认知和现实世界影响的桥梁,将Agent的电子脉冲转化为有意义和有目的的结果。
Agent Protocal: 人工智能通信的语言学
在深入研究Agent的组成结构,理解其核心组成部分之后,有一个关键的问题浮现出来:我们如何有效地与这些多样化、精心设计的Agent进行沟通?答案就在Agent Protocal。
理解Agent Protocal
从本质上讲,Agent协议是一个标准化的通信接口,是每一个Ai Agent,无论其底层结构或设计如何,都能理解的通用“语言”。可以将其想象为确保Agent与开发者、工具甚至其他Agent之间顺畅对话的外交使者。
在一个每个开发者都可能有自己独特的构建Agent方法的生态系统中,Agent协议充当一个统一的桥梁。它就像一个标准化的插头可以插入任何插座,或者一个通用的翻译器可以解码无数种语言。
AutoGPT Forge:窥探LLM Agent模板内部
Forge的目录结构可以比作一个组织良好的图书馆,每本书(文件或目录)都有其指定的位置:
agent.py:Forge的核心,Agent的逻辑驻留在此。prompts:预定义模板的宝库,对于指导LLM的回应至关重要。sdk:样板代码以及Forge的基础基石。
让我们来检查一下这些核心部分。
Unraveling the SDK
sdk目录是Forge的控制中心。你可以将其想象为一艘船的引擎室,包含了驱动整个船只的齿轮和机制。以下是它的组成部分:
- 核心组件: SDK包含了Forge的重要部分,比如Memory、Abilities和Planning。这些组件对于Agent的认知和行为至关重要。
- Agent协议路由: 在
routes子目录中,你会发现我们之前讨论的Agent协议的实现。正是在这里,标准的通信接口被赋予生命。 - 数据库(
db.py): Agent的记忆库。它存储了经验、学习和其他重要的数据。 - Prompting引擎(
prompting.py): 这个引擎利用prompts目录中的模板为LLM制定查询,确保了一致性和恰当的交互。 - Agent类: 充当一座桥,将Agent的逻辑与Agent协议路由连接起来。
配置与环境
配置对于保证我们的Agent无缝运行是关键。.env.example文件为设置必要的环境变量提供了一个模板。在深入Forge之前,开发者需要将这个文件复制到一个新的.env文件中,并调整设置:
- API 密钥:
OPENAI_API_KEY是你插入OpenAI API密钥的地方。 - 日志级别: 通过
LOG_LEVEL来控制日志的详细程度。 - 数据库连接:
DATABASE_STRING确定Agent数据的存储位置和方式。 - 端口:
PORT指定了Agent服务器的监听端口。 - 工作空间:
AGENT_WORKSPACE指向了Agent的工作目录。
Challenge界面会报错,原因不明,此处不做介绍,报错为:KeyError: ‘…’
下面会开始介绍具体的Agent编写
AutoGPT Forge: 构建智能Agent逻辑
打开你的编辑器,然后打开你autogpts/your_agent/forge/agent.py
任务的声明周期 The Task Lifecycle
任务的生命周期,从创建到执行,都在Agent协议中有所概述。简单来说:一个任务被启动,其步骤被有系统地执行,一旦完成就会结束。
想让你的Agent执行一个动作?首先发起一个create_task请求。这个关键步骤包括指定任务细节,就像你使用输入字段向ChatGPT发送提示一样。如果你自己尝试这个,用户界面是你最好的朋友;它会毫不费力地代你处理所有的API调用。
一旦你的Agent接收到这个,它会触发create_task函数。方法super().create_task(task_request)毫不费力地代你管理所有必要的协议记录。随后,它简单地记录任务的创建。对于本教程来说,没必要调整这个函数。
下面的这个函数应该和你的这个函数相同:
async def create_task(self, task_request: TaskRequestBody) -> Task:"""The agent protocol, which is the core of the Forge, works by creating a task and thenexecuting steps for that task. This method is called when the agent is asked to createa task.We are hooking into function to add a custom log message. Though you can do anything youwant here."""task = await super().create_task(task_request)LOG.info(f"📦 Task created: {task.task_id} input: {task.input[:40]}{'...' if len(task.input) > 40 else ''}")return task
一旦任务启动,execute_step 函数将被反复调用,直到最后一步执行完毕。下面是 execute_step 的初始界面,请注意,我省略了冗长的docstring解释以简洁为主,但你会在项目中碰到它。
async def execute_step(self, task_id: str, step_request: StepRequestBody) -> Step:# An example thatstep = await self.db.create_step(task_id=task_id, input=step_request, is_last=True)self.workspace.write(task_id=task_id, path="output.txt", data=b"Washington D.C")await self.db.create_artifact(task_id=task_id,step_id=step.step_id,file_name="output.txt",relative_path="",agent_created=True,)step.output = "Washington D.C"LOG.info(f"\t✅ Final Step completed: {step.step_id}")return step
你在这里看到的是一个巧妙的方式来通过’写文件’的测试,它分为四个明确的阶段:
- **数据库步骤创建:**第一阶段全部关于在数据库中创建一个步骤,这是Agent协议的一个基本环节。你会注意到,当我们设置这一步骤时,我们标记它为
is_last=True。这向Agent协议发送了一个信号,表示没有更多的步骤在等待。为了这个指南的目的,让我们假设我们的Agent只会处理单步任务。然而,未来的教程我们会进一步,让Agent确定其完成点。 - **文件写入:**接下来,我们使用
workspace.write函数写下了“华盛顿特区”。简单,对吧? - **工件数据库更新:**一旦文件被写入,就该记录这个文件在Agent的工件数据库中了,确保一切都被记录下来。
- **设置步骤输出并记录:**为了整理完毕,我们将步骤的输出与我们在文件中写下的内容对齐,记录下我们的步骤已经被执行,然后启动步骤对象。
现在我们已经揭示了通过’写文件’测试的过程,是时候进一步了。让我们把这个变成一个真正的智能Agent,让它能够自主地导航和征服挑战。准备好开始了吗?
构建我们智能Agent的根基
好的,首先,让我们摆脱那个狡猾的 excuse_step 函数的迷惑逻辑,为我们智能Agent打下基础。记住,当我们的 execute_step 函数收到调用时,它对手头的具体任务一无所知。所以,我们的初步任务是纠正这一点。
为了弥合这个知识差距,我们将使用提供的 task_id 来召唤任务详情。以下是实现这一点的代码魔法:
task = await self.db.get_task(task_id)
此外,我们没有忘记创建数据库记录这个关键步骤。像之前一样,我们会强调这是一个一次性的任务,将is_last设为True:
step = await self.db.create_step(task_id=task_id, input=step_request, is_last=True
)
有了这些添加,你的execute_step函数应该现在有一个极简但至关重要的结构:
async def execute_step(self, task_id: str, step_request: StepRequestBody) -> Step:# Firstly we get the task this step is for so we can access the task inputtask = await self.db.get_task(task_id)# Create a new step in the databasestep = await self.db.create_step(task_id=task_id, input=step_request, is_last=True)return step
Prompting的艺术
提示就像一个工匠精心塑造专为强大的语言模型(如ChatGPT)定制的信息。由于这些模型高度敏感于输入的细微差别,设计出能产生令人惊叹行为的完美提示可能是一个复杂的挑战。这时就需要PromptEngine。
虽然“PromptEngine”听起来可能很高深,但其实质却简洁优雅。它让你可以将你的提示存放在文本文件中,或者更准确地说,是在Jinja2模板中。其中的优点?你可以在不深入代码的情况下,改善你给Agent的提示。此外,它还提供了为特定LLM定制提示的灵活性。让我们来详细解释一下。
首先,从SDK中集成PromptEngine:
from .sdk import PromptEngine
接下来,在你的execute_step函数中,为比如gpt-3.5-turbo这样的LLM初始化引擎:
prompt_engine = PromptEngine("gpt-3.5-turbo")
加载prompt非常直观。例如,加载系统格式prompt(该prompt决定了LLM的响应格式)就非常简单:
system_prompt = prompt_engine.load_prompt("system-format")
对于需要参数的复杂用例,如task-step prompt,可以采用以下方法:
# Define the task parameters
task_kwargs = {"task": task.input,"abilities": self.abilities.list_abilities_for_prompt(),
}# Load the task prompt with the defined task parameters
task_prompt = prompt_engine.load_prompt("task-step", **task_kwargs)
深入了解一下,让我们看看prompts/gpt-3.5-turbo/task-step.j2中的task-step提示模板:
{% extends "techniques/expert.j2" %}
{% block expert %}Planner{% endblock %}
{% block prompt %}
Your task is:{{ task }}Answer in the provided format.Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and
pursue simple strategies with no legal complications.{% if constraints %}
## Constraints
You operate within the following constraints:
{% for constraint in constraints %}
- {{ constraint }}
{% endfor %}
{% endif %}{% if resources %}
## Resources
You can leverage access to the following resources:
{% for resource in resources %}
- {{ resource }}
{% endfor %}
{% endif %}{% if abilities %}
## Abilities
You have access to the following abilities you can call:
{% for ability in abilities %}
- {{ ability }}
{% endfor %}
{% endif %}{% if best_practices %}
## Best practices
{% for best_practice in best_practices %}
- {{ best_practice }}
{% endfor %}
{% endif %}
{% endblock %}
这个模板是模块化的杰作,它使用了强大的jinja2格式。通过使用extends指令,它在基础的expert.j2模板上进行建设。各种不同的模块 - 约束,资源,能力和最佳实践 - 为一个根据上下文变化的动态提示。它就像一个对话蓝图,引导LLM理解任务,遵守约束,并运用资源和能力来实现期望的结果。
PromptEngine为我们提供了与大型语言模型无缝对话的强大工具。通过把提示外部化并使用模板,我们可以确保我们的Agent保持灵活性,适应新挑战而无需翻新代码。在我们向前迈进的同时,记住这个基础 - 它是我们Agent智能的基石。
Engaging with your LLM
要充分利用LLM的能力,不仅仅是发送一个孤独的提示。而是要给模型分配一系列的结构化指令。要做到这一点,我们需要将我们的提示结构化成我们的LLM准备处理的消息列表的格式。使用我们之前准备的 system_prompt 和 task_prompt 创建消息列表:
messages = [{"role": "system", "content": system_prompt},{"role": "user", "content": task_prompt}
]
在我们的提示整理准备好之后,现在是时候让我们的LLM开始工作了!虽然这个阶段需要一些基础的代码,但是关注点在于chat_completion_request。这个关键的函数分派任务给LLM并获取其输出。相邻的代码只是打包我们的请求和解析模型的反馈:
try:# Define the parameters for the chat completion requestchat_completion_kwargs = {"messages": messages,"model": "gpt-3.5-turbo",}# Make the chat completion request and parse the responsechat_response = await chat_completion_request(**chat_completion_kwargs)answer = json.loads(chat_response["choices"][0]["message"]["content"])# Log the answer for debugging purposesLOG.info(pprint.pformat(answer))except json.JSONDecodeError as e:# Handle JSON decoding errorsLOG.error(f"Unable to decode chat response: {chat_response}")except Exception as e:# Handle other exceptionsLOG.error(f"Unable to generate chat response: {e}")Step 7: Executing the Derived Ability
在LLM输出中导航,以提取清晰可处理的消息可能是一项微妙的工作。我们目前的方法简单,通常适用于GPT-3.5和GPT-4。然而,未来的教程将扩展你的视野,提供更复杂的方法来处理LLM的输出。目标是什么?确保你不仅限于使用JSON,尤其是当一些LLM擅长处理其他类型的响应模式时。敬请期待!
使用和创建能力 Ability
对于那些对细节非常关注的人,你可能已经在我们讨论创建task-step提示时注意到了对Agent能力的引用。能力是齿轮和杠杆,使Agent能够与手头的任务进行交互。让我们来解开这些能力背后的机制,以及你如何可以利用甚至扩展它们。
注,我并没有这个文件夹,而且所有的文件中也不再包括“@ability”,推测应该是在action文件夹下
在SDK中,有一个名为abilities的专用文件夹。在撰写此文时,它内含registry.py, finish.py和一个名为file_system的子文件夹。而且还有扩展的空间-也许你自己的创新能力很快就会在这里找到它的位置!
文件registry.py扮演着关键的角色。它为能力提供了基础的蓝图,整合了必要的@ability装饰器和AbilityRegister类。这个类不仅仅是一个被动的列表;它是一个活跃的目录,记录了可用的能力,并列出了执行这些能力所必需的函数。更为重要的是,一个默认的能力注册器无缝地集成到基础的Agent类中,通过self.abilities句柄就可以轻松访问。这是在Agent类的init函数中添加的,像这样:
self.abilities = AbilityRegister(self)
虽然AbilityRegister内含许多实用的方法,但有两个尤其显眼。list_abilities_for_prompt方法策划和构建能力,以便集成到提示中。相反,run_ability让指定的能力付诸实践,将它从代码转化为行动。
一个能力的DNA由一个使用@ability装饰器修饰的函数组成,并强制与参数配对,特别是agent和task_id。
@ability(name="write_file",description="Write data to a file",parameters=[{"name": "file_path","description": "Path to the file","type": "string","required": True,},{"name": "data","description": "Data to write to the file","type": "bytes","required": True,},],output_type="None",
)
async def write_file(agent, task_id: str, file_path: str, data: bytes) -> None:pass
在这里,@ability装饰器不仅是一种装饰,更是一种功能指定符。它包含了能力的元数据:其身份(name),功能(description)和运行参数。每个参数都被精确定义,包含其身份,数据类型和操作必要性。
自定义能力的例子:网页获取器
import requests@ability(name="fetch_webpage",description="Retrieve the content of a webpage",parameters=[{"name": "url","description": "Webpage URL","type": "string","required": True,}],output_type="string",
)
async def fetch_webpage(agent, task_id: str, url: str) -> str:response = requests.get(url)return response.text
这个能力,“fetch_webpage”,接受一个URL作为输入,返回网页的HTML内容作为一个字符串。如你所见,自定义能力允许你无缝扩展你的Agent的核心功能,集成外部工具和库以增强其能力。
制定一个自定义能力需要对架构理解和技术实力的综合。这涉及到定义一个功能,列举出其操作参数,并与@ability装饰器的规格精密地结合。有了像"fetch_webpage"这样的自定义能力,Agent的潜力只受到你想象力的限制,使其准备好以熟练的能力处理复杂的任务。
运行一个能力
现在你已经对能力的本质有了深入的了解,并且有了制定它们的能力,是时候将这些技能付诸实践了。我们的拼图的最后一块是execute_step函数。我们的目标?解读Agent的回应,找出所需的能力,并将其实现。
首先,我们从Agent的响应中获取能力的细节。这让我们清楚地了解手头的任务:
# Extract the ability from the answer
ability = answer["ability"]
With the ability details at our fingertips, the next step is to mobilize it. This involves calling our previously discussed run_ability function
有了能力的详细信息在手,下一步是调动它。这涉及到调用我们之前讨论的run_ability函数。
# Run the ability and get the output
# We don't actually use the output in this example
output = await self.abilities.run_ability(task_id, ability["name"], **ability["args"]
)
在这里,我们正在调用指定的能力。task_id确保了连续性,ability['name']精确地指出了函数,而参数(ability["args"])则提供了必要的上下文。
最后,我们将设计步骤的输出以呼应Agent的想法。这不仅提供了透明度,还让我们能够一窥Agent的决策过程:
# Set the step output to the "speak" part of the answer
step.output = answer["thoughts"]["speak"]# Return the completed step
return step
就是这样!您的第一个智能Agent,精雕细琢,准备好应对挑战了。舞台已经准备好了。开始表演吧!
以下是您的函数应该是什么样的:
async def execute_step(self, task_id: str, step_request: StepRequestBody) -> Step:# Firstly we get the task this step is for so we can access the task inputtask = await self.db.get_task(task_id)# Create a new step in the databasestep = await self.db.create_step(task_id=task_id, input=step_request, is_last=True)# Log the messageLOG.info(f"\t✅ Final Step completed: {step.step_id} input: {step.input[:19]}")# Initialize the PromptEngine with the "gpt-3.5-turbo" modelprompt_engine = PromptEngine("gpt-3.5-turbo")# Load the system and task promptssystem_prompt = prompt_engine.load_prompt("system-format")# Initialize the messages list with the system promptmessages = [{"role": "system", "content": system_prompt},]# Define the task parameterstask_kwargs = {"task": task.input,"abilities": self.abilities.list_abilities_for_prompt(),}# Load the task prompt with the defined task parameterstask_prompt = prompt_engine.load_prompt("task-step", **task_kwargs)# Append the task prompt to the messages listmessages.append({"role": "user", "content": task_prompt})try:# Define the parameters for the chat completion requestchat_completion_kwargs = {"messages": messages,"model": "gpt-3.5-turbo",}# Make the chat completion request and parse the responsechat_response = await chat_completion_request(**chat_completion_kwargs)answer = json.loads(chat_response["choices"][0]["message"]["content"])# Log the answer for debugging purposesLOG.info(pprint.pformat(answer))except json.JSONDecodeError as e:# Handle JSON decoding errorsLOG.error(f"Unable to decode chat response: {chat_response}")except Exception as e:# Handle other exceptionsLOG.error(f"Unable to generate chat response: {e}")# Extract the ability from the answerability = answer["ability"]# Run the ability and get the output# We don't actually use the output in this exampleoutput = await self.abilities.run_ability(task_id, ability["name"], **ability["args"])# Set the step output to the "speak" part of the answerstep.output = answer["thoughts"]["speak"]# Return the completed stepreturn step
注,上述代码需要import合适的库,才可以运行,在我的当前版本中,ability也需要更改为action才可以正确运行,因为博主的代码并不一定正确,此处仅放出官方在2023年8月的代码,请自行学习,深入理解
与你的Agent交互
在我们完成了智能代理的大部分设计工作之后,现在是时候看到它的运行情况了。用这个命令启动代理以开始工作:
./run agent start your_agent
数字游乐场设置好后,终端会显示如下信息:
d8888 888 .d8888b. 8888888b. 88888888888 d88888 888 d88P Y88b 888 Y88b 888 d88P888 888 888 888 888 888 888 d88P 888 888 888 888888 .d88b. 888 888 d88P 888 d88P 888 888 888 888 d88""88b 888 88888 8888888P" 888 d88P 888 888 888 888 888 888 888 888 888 888 d8888888888 Y88b 888 Y88b. Y88..88P Y88b d88P 888 888
d88P 888 "Y88888 "Y888 "Y88P" "Y8888P88 888 888 8888888888 888 888 8888888 .d88b. 888d888 .d88b. .d88b. 888 d88""88b 888P" d88P"88b d8P Y8b 888 888 888 888 888 888 88888888 888 Y88..88P 888 Y88b 888 Y8b. 888 "Y88P" 888 "Y88888 "Y8888 888 Y8b d88P "Y88P" v0.1.0[2023-09-27 15:39:07,832] [forge.sdk.agent] [INFO] 📝 Agent server starting on http://localhost:8000