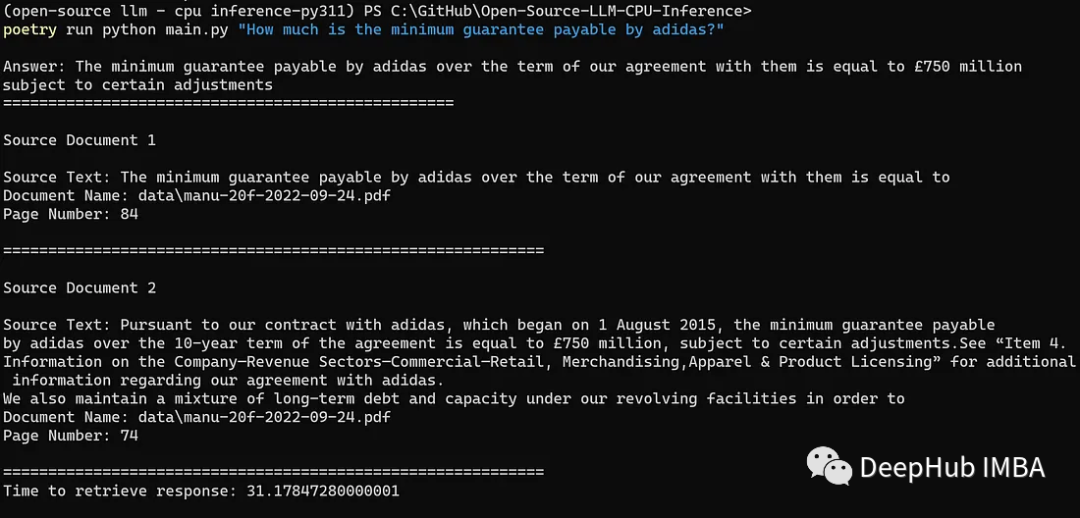
前言:
通常,如果进程运行时间超过3分钟,则会考虑使用并行处理。
这听起来可能很复杂,但是并行计算很简单。
- 当你有一个重复的任务,它占用了你太多宝贵的时间,为什么不使用并行计算来节省时间呢?
- 即使你有一个单一的任务,你也可以通过将任务分成更小的部分来从并行处理中受益。
两个广泛使用的并行处理包是parallel和foreach。
1-并行计算准备阶段:
在R中使用并行计算的主要目的 提高运行速度,由于R是单核运行的程序,现在的计算机都是多核,如果只用一个核跑程序,让计算机的其他核空闲,势必是一种资源的浪费。
library(parallel)# 设置并行计算的核心数
num_cores <- detectCores()
cl <- makeCluster(num_cores)# 执行并行计算的任务
result <- parLapply(cl, data, your_function)# 关闭并行计算的集群
stopCluster(cl)流程:设置并行计算的核数-->执行并行计算-->关闭并行计算的集群。
无论使使用哪种并行计算包,都是基于上述三个步骤,1-设置并行计算的核数;2 执行并行计算 3 关闭并行计算的集群。
2-各种方法对比
2.0生成数据:
# create test data
set.seed(1234)
df <- data.frame(matrix(data = rnorm(1e7), ncol = 1000))
dim(df)目标:对这个矩阵每行求和。
2.1使用For循环
运行事件3.83mins
# for Example 1
times1 <- Sys.time()
results <- c()for (i in 1:dim(df)[1]) {results <- c(results, sum(df[i,]))
}times2 <- Sys.time()
print(times2 - times1)
#2.77314 mins#for Example 2
times1 <- Sys.time()
results <- c()for (i in 1:dim(df)[1]) {results[i] <- sum(df[i,])
}times2 <- Sys.time()
print(times2 - times1)
#2.404386 mins2.2使用apply函数
当提到循环的时候,我们想到的是For、while循环和apply函数族,可以说apply函数族是代替循环的好方法。
#2
times1 <- Sys.time()
apply(df,1,sum)times2 <- Sys.time()
print(times2 - times1)
#0.5269971 secs2.3使用baseR中自带的函数rowSums()
#3
times1 <- Sys.time()
rowSums(df)
times2 <- Sys.time()
print(times2 - times1)
#0.146533 secs 2.4使用parallel包
这里用到了对数据进行分割,按照核数1:8进行分割,分割成8份,得到一个list列表对象。然后使用parLapply()函数进行计算。
#4
# load R Package
library(parallel)
# check cores numbers
detectCores()
# set cores numbers
num_cores <- 8
# start times
times1 <- Sys.time()
# split data
chunks <- split(df, f = rep(1:num_cores, length.out = nrow(df)))
class(chunks) #list 列表
length(chunks)
# create parallel
cl <- makeCluster(num_cores)# computed in parallel
results <- parLapply(cl, chunks, function(chunk){apply(chunk, 1, sum)
})# Turn off the cluster for parallel computing
stopCluster(cl)# combine result
final_result <- unlist(results)times2 <- Sys.time()print(times2 - times1)
#3.047416 secs2.5使用foreach包
install.packages("foreach")
install.packages("doParallel")
library(foreach)
library(doParallel)
# 创建一个集群并注册
cl <- makeCluster(8)
registerDoParallel(cl)# 启动并行计算
time1 <- Sys.time()
x2 <- foreach(i = 1:dim(df)[1], .combine = c) %dopar% {sum(df[i,])
}
time2 <- Sys.time()
print(time2-time1)# 在计算结束后别忘记关闭集群
stopImplicitCluster()
stopCluster(cl)
# 53.63808 secs参考:
Rtips 多核心并行计算
![[JavaScript游戏开发] 2D二维地图绘制、人物移动、障碍检测](https://img-blog.csdnimg.cn/086495efd69c4446a328ac88a51238bd.png)