1. 下载Ubuntu20.04.6镜像
登录阿里云官方镜像站:阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区
2. 测试环境
Server OS:Ubuntu 20.04.6 LTS
Kernel: Linux 5.4.0-155-generic x86-64
Docker Version:24.0.5, build ced0996
docker-compose version:1.25.0
Docker OS:Ubuntu 20.04.5 LTS
Nvidia GPU Version:NVIDIA-SMI 470.161.03
CUDA Version: 12.1
TensorFlow Version:1.15.1
python Version:3.8.10
3. Ubuntu下安装pip3 python3
Ubuntu下用apt命令安装
apt install python3-pip
4. Ubuntu下安装docker
curl https://get.docker.com | sh && sudo systemctl --now enable docker
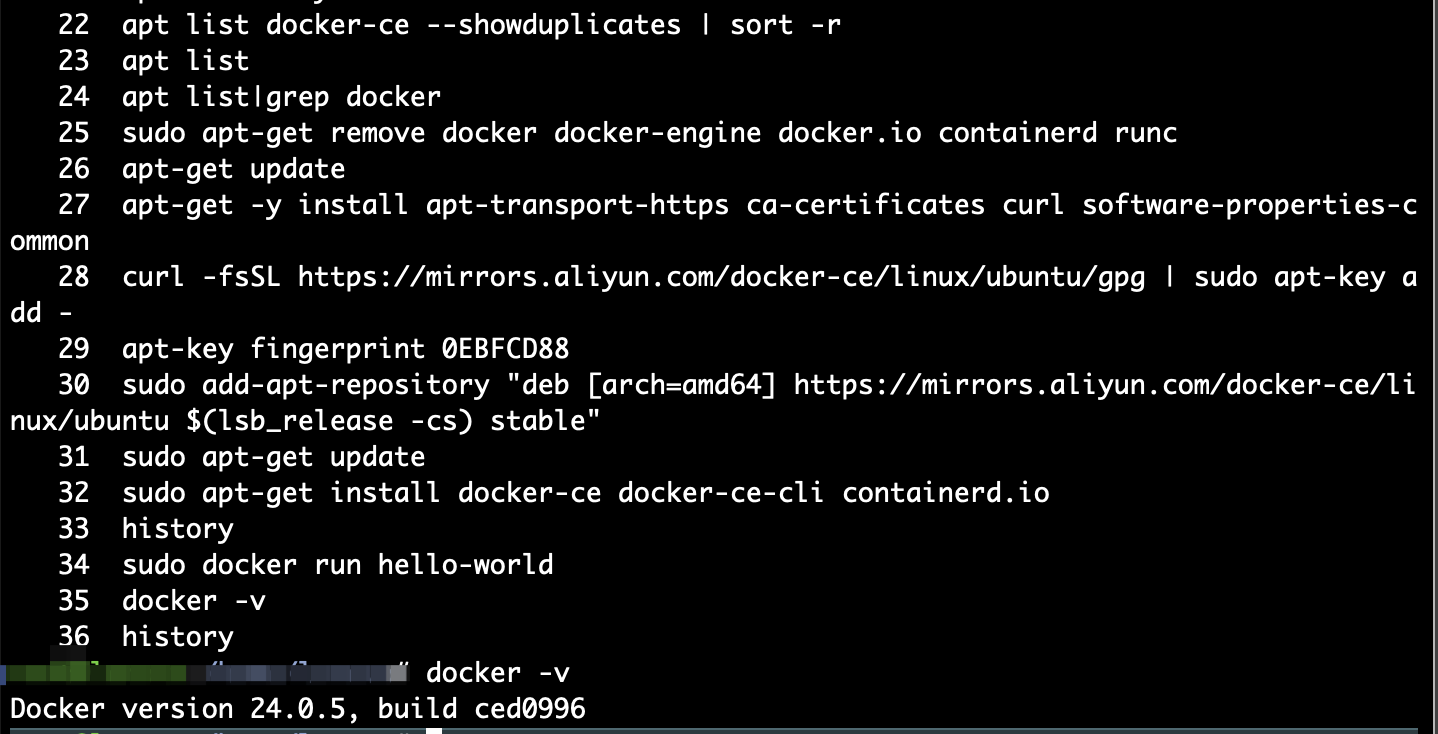
测试
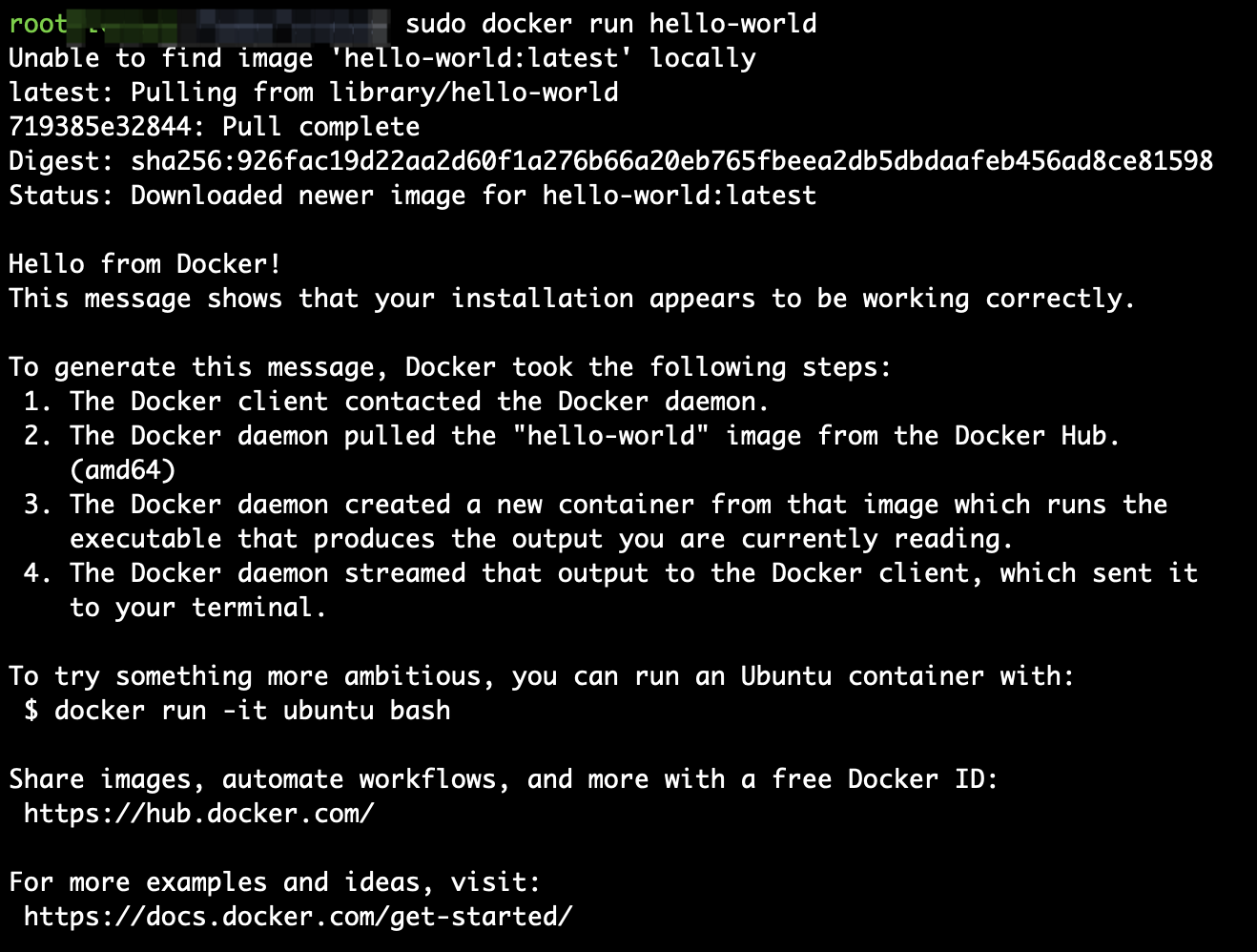
sudo docker run hello-world
提示:显示以下结果,表示安装成功
5.启动
systemctl start docker
6.停止
systemctl stop docker
7.重启
systemctl restart docker
8.设置开机启动
sudo systemctl enable docker
5. Ubuntu下安装Docker Compose
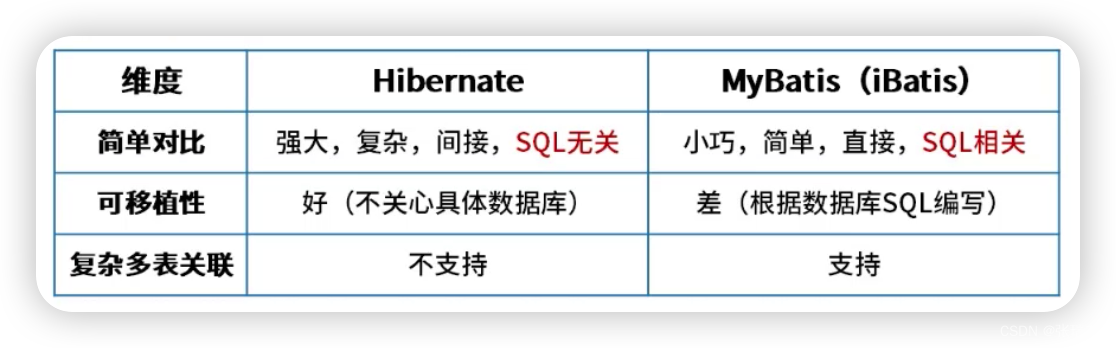
一个使用Docker容器的应用,通常由多个容器组成。使用Docker Compose不再需要使用shell脚本来启动容器。Compose 通过一个配置文件来管理多个Docker容器,在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用,和应用中的服务以及所有依赖服务的容器,非常适合组合使用多个容器进行开发的场景
1. 卸载旧版本Docker Compose
如果之前安装过Docker Compose的旧版本,可以先卸载它们:
sudo rm /usr/local/bin/docker-compose
2. 下载Docker Compose最新版
从Docker官方网站下载Docker Compose最新版本的二进制文件:
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
3. 授权Docker Compose二进制文
授予Docker Compose二进制文件执行权限
sudo chmod +x /usr/local/bin/docker-compose
4. 检查Docker Compose版本
docker-compose --version
docker-compose version 1.25.0, build unknown
6. Ubuntu下安装NVIDIA Docker
官网地址搜索Installing on Ubuntu and DebianInstalling on Ubuntu and Debian — container-toolkit 1.13.5 documentation
错误处理
Troubleshooting — container-toolkit 1.13.5 documentation

$ curl https://get.docker.com | sh \ && sudo systemctl --now enable docker
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/experimental/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list$ sudo apt-get update
执行sudo apt-get update -y 报错如下
E: Conflicting values set for option Signed-By regarding source https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/amd64/ /: /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg !=
E: The list of sources could not be read.
解决办法:docker和nvidia-docker的安装以及错误记录_小白tb的博客-CSDN博客

# grep "nvidia.github.io" /etc/apt/sources.list.d/*
/etc/apt/sources.list.d/nvidia-container-toolkit.list:deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/$(ARCH) /
/etc/apt/sources.list.d/nvidia-container-toolkit.list:#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://nvidia.github.io/libnvidia-container/experimental/ubuntu18.04/$(ARCH) /
# cd /etc/apt/sources.list.d
# rm -rf *
# sudo apt-get install -y nvidia-container-toolkit
# sudo nvidia-ctk runtime configure --runtime=docker
# sudo systemctl restart docker
# sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
执行最后一个命令行遇到,解决“docker: Error response from daemon: Unknown runtime specified nvidia”问题
解决方法:
重启就行
sudo systemctl daemon-reload
sudo systemctl restart docker
如遇
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: initialization error: nvml error: driver not loaded: unknown.
root@lenovo:/home/lenovo# sudo apt-get update
5. 查看所有docker所有进程
# docker ps -all
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
79c75f07de8a nvidia/cuda:11.6.2-base-ubuntu20.04 "/bin/bash" 50 minutes ago Exited (0) 50 minutes ago wonderful_euler
docker ps 显示的是运行起来的进程,docker ps -all是全部进程
进程没有起来。。。。
查看日志 发现无进程日志
# docker logs 79c75f07de8a
解决办法 # apt install nvidia-cuda-toolkit
安装速度较慢,大约2.5个小时。。。。。
6. 如果还是不行,参考官网报错分析(处理重大问题)
Troubleshooting — container-toolkit 1.13.5 documentation
# ausearch -c 'nvidia-docker' --raw | audit2allow -M my-nvidiadocker
# semodule -X 300 -i my-nvidiadocker.pp
# nvidia-docker run -d nvidia/cuda:12.2.0-base-ubuntu22.04
如果正常,再次查看docker进程发现有nvidia docker进程了
发现还是错误报错如下:
使用命令行 # nvidia-container-cli -k -d /dev/tty info 排查
I0729 14:45:17.678470 181027 nvc.c:395] dxcore initialization failed, continuing assuming a non-WSL environment
W0729 14:45:17.679863 181027 nvc.c:258] failed to detect NVIDIA devices

启动nvidia-docker
# systemctl start nvidia-docker.service
报错如下:
Job for nvidia-docker.service failed because the control process exited with error code.
See "systemctl status nvidia-docker.service" and "journalctl -xe" for details.

# systemctl status nvidia-docker.service
Process: 185483 ExecStart=/usr/bin/nvidia-docker-plugin -s $SOCK_DIR (code=exited, status=217/US>
Process: 185484 ExecStartPost=/bin/sh -c /bin/mkdir -p $( dirname $SPEC_FILE ) (code=exited, sta>
Process: 185485 ExecStopPost=/bin/rm -f $SPEC_FILE (code=exited, status=217/USER)
输入 # journalctl -xe
Jul 29 14:43:47 xx systemd[1]: Failed to start NVIDIA Docker plugin.
-- Subject: A start job for unit nvidia-docker.service has failed
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- A start job for unit nvidia-docker.service has finished with a failure.
--
-- The job identifier is 5063 and the job result is failed.
Jul 29 15:00:52 xx su[171964]: pam_unix(su:session): session closed for user root
Jul 29 15:01:34 xx sudo[183078]: pam_unix(sudo:session): session opened for user root by xx(>
Jul 29 15:01:35 xx sudo[183078]: pam_unix(sudo:session): session closed for user root

解决办法:
vim模式下::%s/\/sbin\/nologin/\/bin\/bash/g

解决办法:Ubuntu开启ssh服务及允许root登录
1)安装ssh服务器端
Ubuntu默认没有安装ssh的server,需要安装
apt-get install openssh-server
ssh客户端是默认安装的,连接其它ssh服务器用的,使用 apt install openssh-client安装
2)允许远程使用root账号ssh连接本机
修改/etc/ssh/sshd_config文件
vim /etc/ssh/sshd_config
修改如下:允许root账户登录
#PermitRootLogin prohibit-password
PermitRootLogin yes
3)需要重启系统或者sshd服务
sudo /etc/init.d/ssh stop
sudo /etc/init.d/ssh start
sudo service ssh restart
4)安装ssh服务后,系统默认开启系统sshd,查看sshd状态如果不是默认启动,修改服务为enable
sudo systemctl enable ssh
依然报错:
# journalctl -xeu docker.service
7. 基于NVIDIA-Docker安装Tensorflow2.13版本
1. 查看下载的镜像
# docker image ls
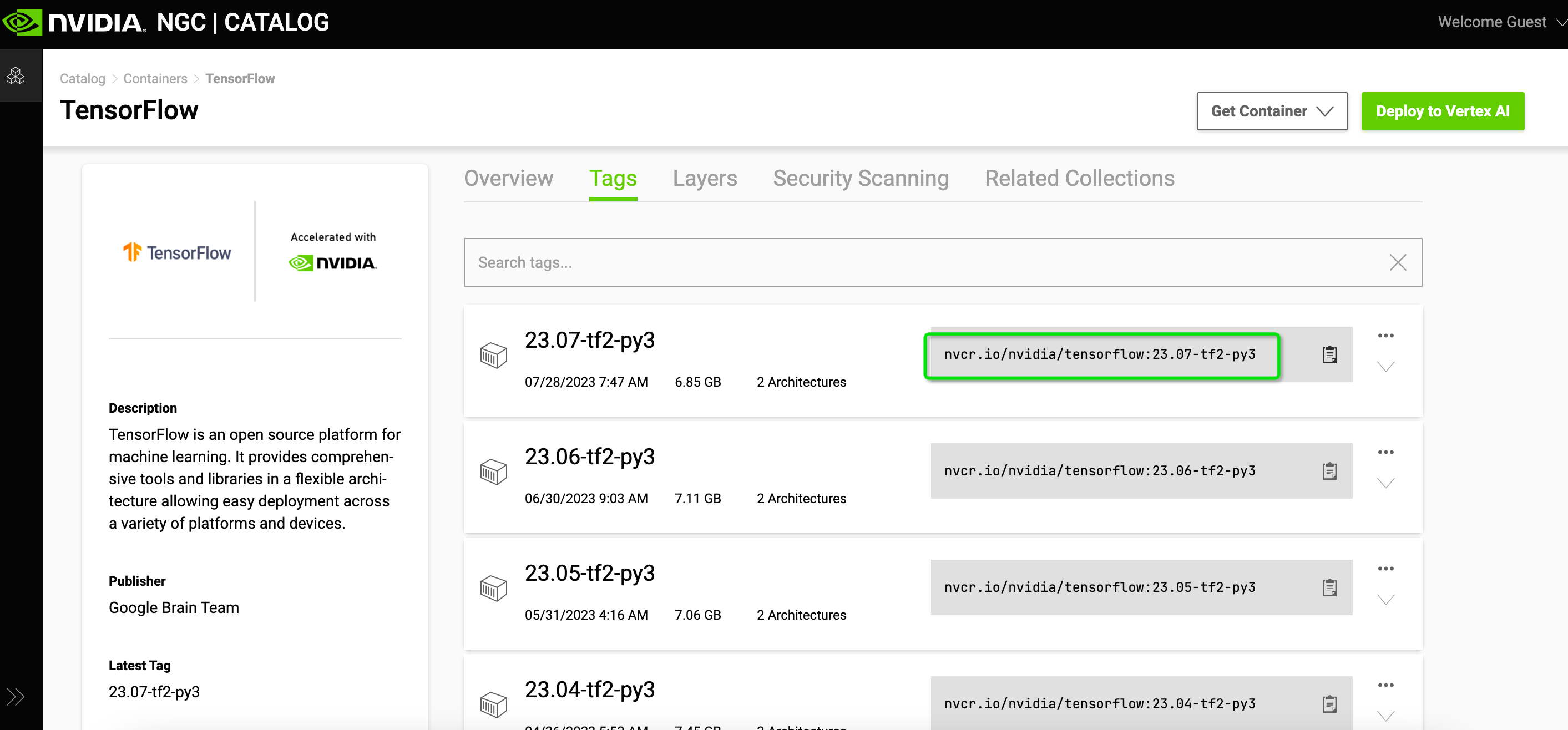
2. 下载tensorflow v2.13版本的镜像
官网地址:TensorFlow | NVIDIA NGC
# docker pull nvcr.io/nvidia/tensorflow:23.06-tf2-py3
3. 再次查看下载的镜像
# docker image ls
4. 进入tensorflow容器
nvidia-docker run --rm -it nvcr.io/nvidia/tensorflow:18.03-py3 (清除镜像)
# nvidia-docker run -it nvcr.io/nvidia/tensorflow:23.03-tf1-py3
格式:nvidia-docker run -it {REPOSITORY容器名称:TAG号}
7. docker和nvidia-docker的安装以及错误记录
错误一:sudo apt-get update出现
问题二:docker run --runtime=nvidia --rm nvidia/cuda:8.0-devel nvidia-smi出现
问题三:sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi出现
问题四 sudo docker run --runtime=nvidia --rm nvidia/cuda:10.0-base nvidia-smi 出现
最终安装成功啦!
参考链接:
nvidia-docker的安装
错误一:sudo apt-get update出现
参考链接
E: Conflicting values set for option Signed-By regarding source https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/amd64/ /: /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg !=
E: The list of sources could not be read.
解决方法
grep "nvidia.github.io" /etc/apt/sources.list.d/*
会列出1个或者2个文件
然后进入/etc/apt/sources.list.d/文件夹中终端打开,将列出来的文件删除即可。
问题二:docker run --runtime=nvidia --rm nvidia/cuda:8.0-devel nvidia-smi出现
docker: Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/create: dial unix /var/run/docker.sock: connect: permission denied. code example
解决方法
docker前加sudo就行了
问题三:sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi出现
“–gpus” requires API version 1.40, but the Docker daemon API version is 1.39
解决方法
docker版本和nvidia-docker版本不匹配,将两个全删除了,再安装即可。
参考链接:
ubuntu中docker彻底卸载
ubuntu16.04离线安装与卸载docker和nvidia-docker
低版本Docker升级高版本Docker【详细教程、成功避坑】
问题四 sudo docker run --runtime=nvidia --rm nvidia/cuda:10.0-base nvidia-smi 出现
docker: Error response from daemon: unknown or invalid runtime name: nvidia.
解决“docker: Error response from daemon: Unknown runtime specified nvidia”问题
解决方法:
重启就行
sudo systemctl daemon-reload
sudo systemctl restart docker
最终安装成功啦!
100. 参考资料
Ubuntu18.04 下载与安装(阿里云官方镜像站)_ubuntu18.04下载_smartvxworks的博客-CSDN博客
什么是 TensorFlow? | 数据科学 | NVIDIA 术语表
TensorFlow核心 | TensorFlow中文官网 | TensorFlow CoreUbuntu系统安装Docker_ubuntu安装docker_流觞浮云的博客-CSDN博客
docker和nvidia-docker的安装以及错误记录_小白tb的博客-CSDN博客
docker failed to create task for container: failed to create shim task: OCI runtime create failed:_wangjun5159的博客-CSDN博客
nvidia-docker无法启动问题_failed to start nvidia docker plugin._星辰大海在梦中的博客-CSDN博客
Linux开启ssh并允许root登录(ubuntu、centos、kalilinux)_ssh允许root远程登录_Crayon Lin的博客-CSDN博客