本文首发于公众号:机器感知
https://mp.weixin.qq.com/s/KiyNfwYWU-wBiCO-hE9qkA
苏

The devil is in the object boundary: towards annotation-free instance segmentation using Foundation Models

Foundation models, pre-trained on a large amount of data have demonstrated impressive zero-shot capabilities in various downstream tasks. However, in object detection and instance segmentation, two fundamental computer vision tasks heavily reliant on extensive human annotations, foundation models such as SAM and DINO struggle to achieve satisfactory performance. In this study, we reveal that the devil is in the object boundary, \textit{i.e.}, these foundation models fail to discern boundaries between individual objects. For the first time, we probe that CLIP, which has never accessed any instance-level annotations, can provide a highly beneficial and strong instance-level boundary prior in the clustering results of its particular intermediate layer. Following this surprising observation, we propose $\textbf{Zip}$ which $\textbf{Z}$ips up CL$\textbf{ip}$ and SAM in a novel classification-first-then-discovery pipeline, enabling annotation-free, complex-scene-capable, open-vocab......
LD-Pruner: Efficient Pruning of Latent Diffusion Models using Task-Agnostic Insights

Latent Diffusion Models (LDMs) have emerged as powerful generative models, known for delivering remarkable results under constrained computational resources. However, deploying LDMs on resource-limited devices remains a complex issue, presenting challenges such as memory consumption and inference speed. To address this issue, we introduce LD-Pruner, a novel performance-preserving structured pruning method for compressing LDMs. Traditional pruning methods for deep neural networks are not tailored to the unique characteristics of LDMs, such as the high computational cost of training and the absence of a fast, straightforward and task-agnostic method for evaluating model performance. Our method tackles these challenges by leveraging the latent space during the pruning process, enabling us to effectively quantify the impact of pruning on model performance, independently of the task at hand. This targeted pruning of components with minimal impact on the output allows for faster co......
EdgeFusion: On-Device Text-to-Image Generation

The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices......
SKIP: Skill-Localized Prompt Tuning for Inference Speed Boost-Up
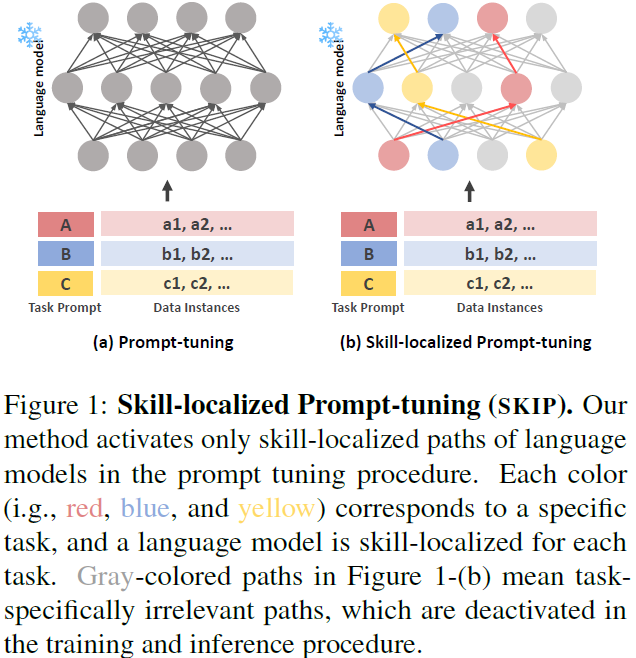
Prompt-tuning methods have shown comparable performance as parameter-efficient fine-tuning (PEFT) methods in various natural language understanding tasks. However, existing prompt tuning methods still utilize the entire model architecture; thus, they fail to accelerate inference speed in the application. In this paper, we propose a novel approach called SKIll-localized Prompt tuning (SKIP), which is extremely efficient in inference time. Our method significantly enhances inference efficiency by investigating and utilizing a skill-localized subnetwork in a language model. Surprisingly, our method improves the inference speed up to 160% while pruning 52% of the parameters. Furthermore, we demonstrate that our method is applicable across various transformer-based architectures, thereby confirming its practicality and scalability. ......
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
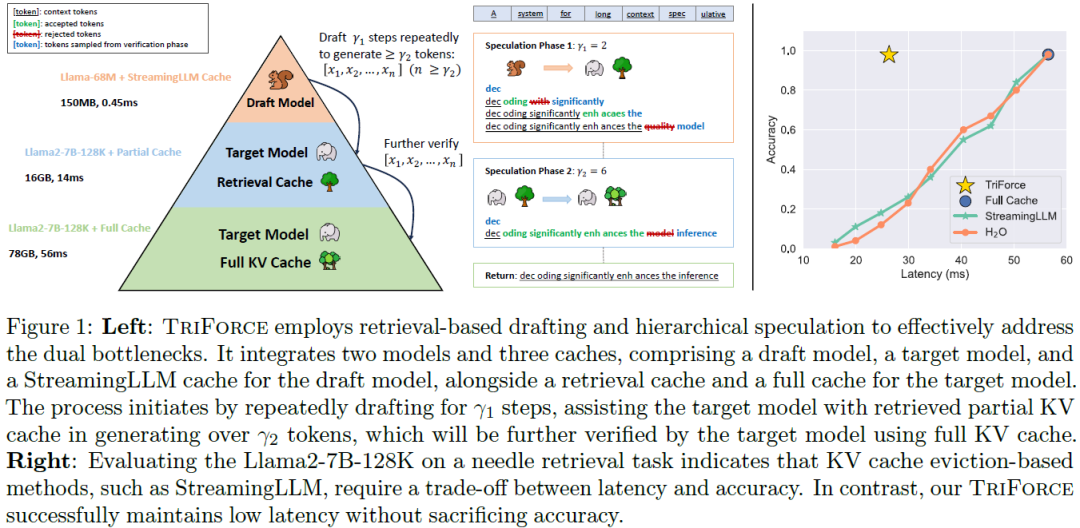
With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cache, which is stored to avoid re-computation, has emerged as a critical bottleneck by growing linearly in size with the sequence length. Due to the auto-regressive nature of LLMs, the entire KV cache will be loaded for every generated token, resulting in low utilization of computational cores and high latency. While various compression methods for KV cache have been proposed to alleviate this issue, they suffer from degradation in generation quality. We introduce TriForce, a hierarchical speculative decoding system that is scalable to long sequence generation. This approach leverages the original model weights and dynamic sparse KV cache via retrieval as a draft model, which serves as an intermediate layer in the hierarchy and is further speculated by a smaller model to reduce its......
FreeDiff: Progressive Frequency Truncation for Image Editing with Diffusion Models

Precise image editing with text-to-image models has attracted increasing interest due to their remarkable generative capabilities and user-friendly nature. However, such attempts face the pivotal challenge of misalignment between the intended precise editing target regions and the broader area impacted by the guidance in practice. Despite excellent methods leveraging attention mechanisms that have been developed to refine the editing guidance, these approaches necessitate modifications through complex network architecture and are limited to specific editing tasks. In this work, we re-examine the diffusion process and misalignment problem from a frequency perspective, revealing that, due to the power law of natural images and the decaying noise schedule, the denoising network primarily recovers low-frequency image components during the earlier timesteps and thus brings excessive low-frequency signals for editing. Leveraging this insight, we introduce a novel fine-tuning free a......
TextCenGen: Attention-Guided Text-Centric Background Adaptation for Text-to-Image Generation

Recent advancements in Text-to-image (T2I) generation have witnessed a shift from adapting text to fixed backgrounds to creating images around text. Traditional approaches are often limited to generate layouts within static images for effective text placement. Our proposed approach, TextCenGen, introduces a dynamic adaptation of the blank region for text-friendly image generation, emphasizing text-centric design and visual harmony generation. Our method employs force-directed attention guidance in T2I models to generate images that strategically reserve whitespace for pre-defined text areas, even for text or icons at the golden ratio. Observing how cross-attention maps affect object placement, we detect and repel conflicting objects using a force-directed graph approach, combined with a Spatial Excluding Cross-Attention Constraint for smooth attention in whitespace areas. As a novel task in graphic design, experiments indicate that TextCenGen outperforms existing methods with......
Visual Prompting for Generalized Few-shot Segmentation: A Multi-scale Approach
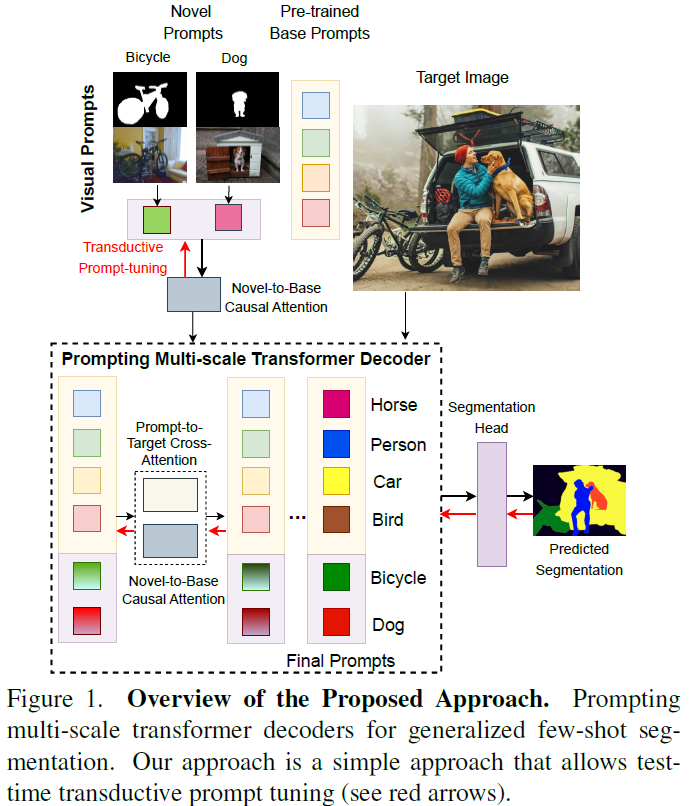
The emergence of attention-based transformer models has led to their extensive use in various tasks, due to their superior generalization and transfer properties. Recent research has demonstrated that such models, when prompted appropriately, are excellent for few-shot inference. However, such techniques are under-explored for dense prediction tasks like semantic segmentation. In this work, we examine the effectiveness of prompting a transformer-decoder with learned visual prompts for the generalized few-shot segmentation (GFSS) task. Our goal is to achieve strong performance not only on novel categories with limited examples, but also to retain performance on base categories. We propose an approach to learn visual prompts with limited examples. These learned visual prompts are used to prompt a multiscale transformer decoder to facilitate accurate dense predictions. Additionally, we introduce a unidirectional causal attention mechanism between the novel prompts, learned with ......
MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
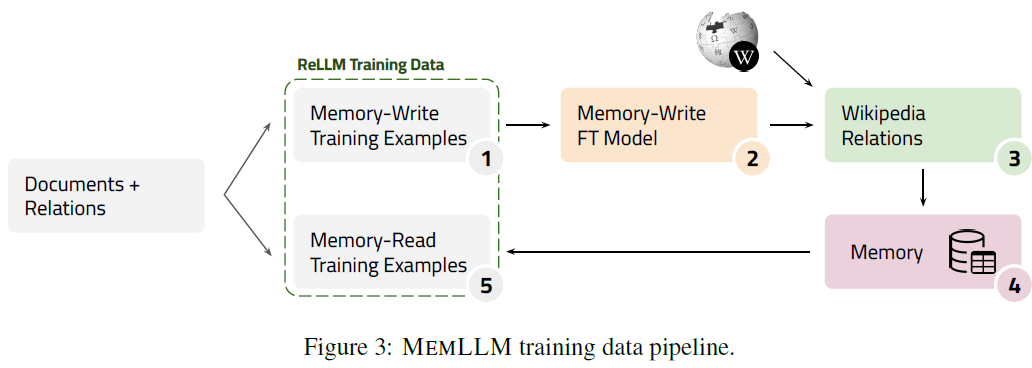
While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $\unicode{x2013}$ though non-parametric $\unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our......
SNP: Structured Neuron-level Pruning to Preserve Attention Scores
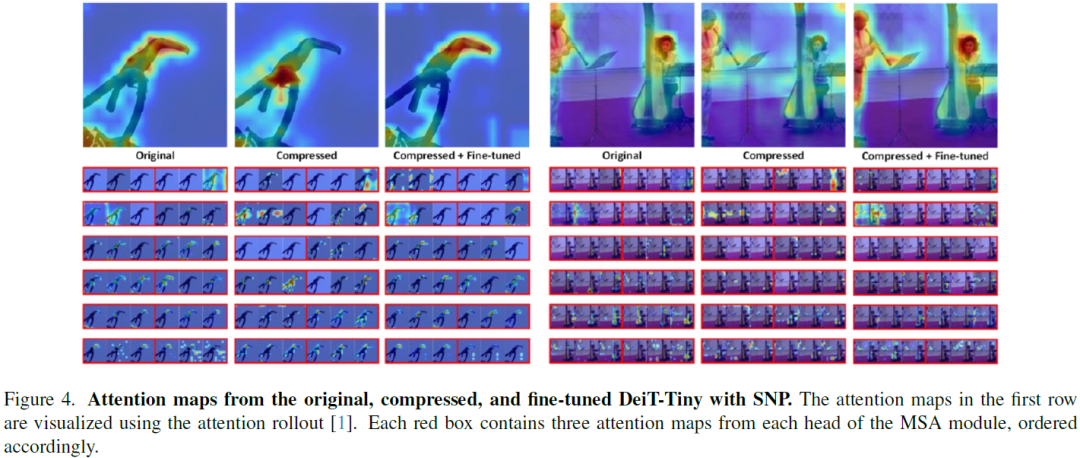
Multi-head self-attention (MSA) is a key component of Vision Transformers (ViTs), which have achieved great success in various vision tasks. However, their high computational cost and memory footprint hinder their deployment on resource-constrained devices. Conventional pruning approaches can only compress and accelerate the MSA module using head pruning, although the head is not an atomic unit. To address this issue, we propose a novel graph-aware neuron-level pruning method, Structured Neuron-level Pruning (SNP). SNP prunes neurons with less informative attention scores and eliminates redundancy among heads. Specifically, it prunes graphically connected query and key layers having the least informative attention scores while preserving the overall attention scores. Value layers, which can be pruned independently, are pruned to eliminate inter-head redundancy. Our proposed method effectively compresses and accelerates Transformer-based models for both edge devices and server......