力扣力扣力:一文搞定前序遍历的所有方法!
144. 二叉树的前序遍历 - 力扣(LeetCode)
我们先来看最简单的前序遍历也是最符合直觉的一种遍历方式。其实无论是前中后序都是深度优先算法DFS的一种具体的实现,差别就在于递归左右结点的前后顺序而已,所以这里我们重点讲解其中一种,后面两种思路基本一致。
class Solution {
public:void Traversal(TreeNode* cur,vector<int>& vec){if(cur == nullptr){return;}vec.push_back(cur->val);Traversal(cur->left,vec);Traversal(cur->right,vec);}vector<int> preorderTraversal(TreeNode* root){vector<int> res;Traversal(root,res);return res;}
};大家在做到这道题的时候看题解可能第一反应是这里为啥有两个函数(反正我是这样想的),不能在一个函数里面实现嘛?其实在一个函数里面实现也是可以的,但是有看起来不容易懂不利于维护等缺点,我们最后再比较两种写法的优缺点,这里先解释一下递归写法的具体逻辑。
首先第一步肯定还是判空,这已经是做leetcode题的常态了属于是。但是我们注意这里的判空和正常非递归的题目判空有本质的区别,这里的判空实际上也是控制递归深度的判断条件,只有在遍历到空结点后才会停止递归,这也和上面提到的深度优先的思想一致。这其实也是写递归的代码的时候的一种模板,就是一定要有一个判断递归深度的条件,否则会无限递归导致栈溢出也就是经典错误stack overflow。然后将结点push进数组中,接着就是开始递归调用,由于是先序遍历所以是先左后右。下面我举一个具体的例子来说明递归的过程是如何进行的,实际上递归的实现方式本质上是使用了系统的调用栈来管理函数调用,因此前序遍历和 DFS 都会用到栈结构,懂了递归的方式也就懂了栈的非递归遍历,都是相通的。
假设我们有一颗二叉树如下:
让我们通过这个二叉树的例子,逐步说明递归调用 Traversal 的过程,并展示每一步的 vec 内容。
1/ \2 3/ \
4 5
-
1初始调用:
preorderTraversal被调用,root是节点1,res是空的vector。- 调用
Traversal(1, res)。
-
2进入
Traversal(1, res):- 当前节点是
1,res是[](空)。 1不是空节点,将1的值加入到res:res = [1]
- 当前节点是
- 3进入
Traversal(2, res):- 当前节点是
2,res是[1]。 2不是空节点,将2的值加入到res:res = [1, 2]
- 当前节点是
-
4进入
Traversal(4, res):- 当前节点是
4,res是[1, 2]。 4不是空节点,将4的值加入到res:res = [1, 2, 4]- 递归调用
Traversal(nullptr, res),即遍历4的左子树。
- 当前节点是
-
5进入
Traversal(nullptr, res)(遍历4的左子树):- 当前节点是
nullptr(空节点),res是[1, 2, 4]。 - 触发判空条件,返回到上一层的递归调用,即回到
Traversal(4, res)。
- 当前节点是
-
6继续
Traversal(4, res):- 递归调用
Traversal(nullptr, res),即遍历4的右子树。
- 递归调用
-
7进入
Traversal(nullptr, res)(遍历4的右子树):- 当前节点是
nullptr(空节点),res是[1, 2, 4]。 - 触发判空条件,返回到上一层的递归调用,即回到
Traversal(2, res)。
- 当前节点是
-
8继续
Traversal(2, res):- 递归调用
Traversal(5, res),即遍历2的右子树。
- 递归调用
-
9进入
Traversal(5, res):- 当前节点是
5,res是[1, 2, 4]。 5不是空节点,将5的值加入到res:res = [1, 2, 4, 5]- 递归调用
Traversal(nullptr, res),即遍历5的左子树。
- 当前节点是
-
10进入
Traversal(nullptr, res)(遍历5的左子树):- 当前节点是
nullptr(空节点),res是[1, 2, 4, 5]。 - 触发判空条件,返回到上一层的递归调用,即回到
Traversal(5, res)。
- 当前节点是
-
11继续
Traversal(5, res):- 递归调用
Traversal(nullptr, res),即遍历5的右子树。
- 递归调用
-
12进入
Traversal(nullptr, res)(遍历5的右子树):- 当前节点是
nullptr(空节点),res是[1, 2, 4, 5]。 - 触发判空条件,返回到上一层的递归调用,即回到
Traversal(1, res)。
- 当前节点是
-
13继续
Traversal(1, res):- 递归调用
Traversal(3, res),即遍历1的右子树。
- 递归调用
-
14进入
Traversal(3, res):- 当前节点是
3,res是[1, 2, 4, 5]。 3不是空节点,将3的值加入到res:res = [1, 2, 4, 5, 3]- 递归调用
Traversal(nullptr, res),即遍历3的左子树。
- 当前节点是
-
15进入
Traversal(nullptr, res)(遍历3的左子树):- 当前节点是
nullptr(空节点),res是[1, 2, 4, 5, 3]。 - 触发判空条件,返回到上一层的递归调用,即回到
Traversal(3, res)。
- 当前节点是
-
16继续
Traversal(3, res):- 递归调用
Traversal(nullptr, res),即遍历3的右子树。
- 递归调用
-
17进入
Traversal(nullptr, res)(遍历3的右子树):- 当前节点是
nullptr(空节点),res是[1, 2, 4, 5, 3]。 - 触发判空条件,返回到上一层的递归调用,即回到
Traversal(1, res)。
- 当前节点是
-
遍历结束:
此时,所有递归调用已经完成,res中的内容为[1, 2, 4, 5, 3],这就是整个二叉树的前序遍历结果。
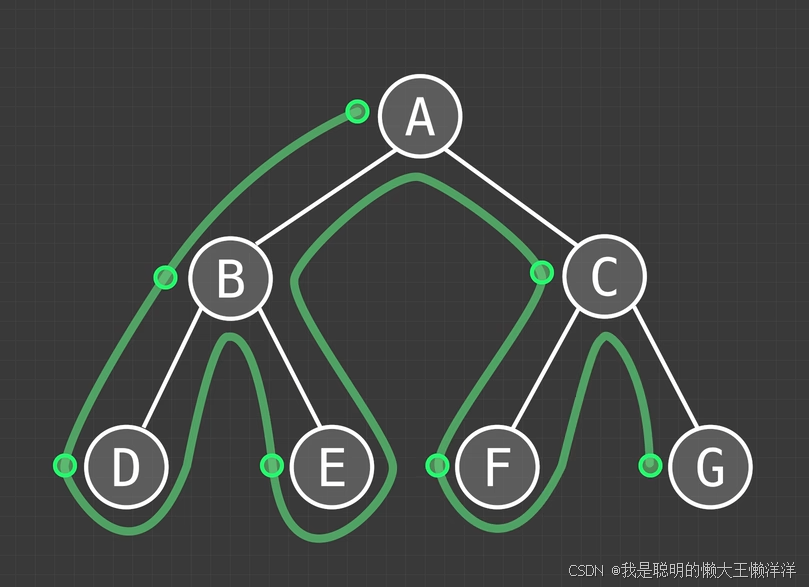
如果实在不能理解也可以按照下面这张图的简单方法拿到递归结点的逻辑顺序,如果是前序就是在每一个结点的左边画上一个点,如果是中序就是下面画点,如果是后序就是右边画点,方法都是从左到右一笔画将所有点相连。
后面的主函数就不做过多解释,就是定义数组传进去,最后返回数组,这里我们回答一下上面的问题,如果不定义函数能不能直接递归实际上也是可以的下面给出实现。
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> res;if (root == nullptr) {return res;}res.push_back(root->val);vector<int> left = preorderTraversal(root->left); // 遍历左子树vector<int> right = preorderTraversal(root->right); // 遍历右子树res.insert(res.end(), left.begin(), left.end());res.insert(res.end(), right.begin(), right.end());return res;}
};
唯一需要注意语法的是下面这两句,这里用到了vector迭代器,具体使用细节不做解释,效果如下
res.insert(res.end(), left.begin(), left.end()):- 这句话的含义是:将
left中从left.begin()到left.end()的所有元素插入到res的末尾。 - 这个过程相当于将
left中的元素依次添加到res的尾部。
- 这句话的含义是:将
res.insert(res.end(), right.begin(), right.end());
逻辑和前一行类似,只不过这次是把 right 子树的遍历结果插入到 res 的末尾。
push back 只能一次插入一个元素。insert 这种迭代器形式可以一次性地插入一个范围的元素,也是一种常用用法,从而更高效地将整个left或right子树的结果合并到 res 中。不需要用循环来逐个插入left和right中的每一个元素,使用 insert 使得代码更加简洁。
对比两种方法
-
独立的辅助函数:
- 优点:清晰地分离了初始化和递归逻辑,使得代码易于维护和阅读。
- 缺点:代码中多了一个函数。
-
直接在
preorderTraversal中实现递归:- 优点:减少了一个函数定义。
- 缺点:如果不定义辅助函数 Traversal,我们在 preorderTraversal 中实现递归时,仍然需要重新定义两个新的vector,这两个 vector 传递给递归调用。这样做会使得函数的结构变得复杂和臃肿,代码变得不够简洁,递归过程和结果处理混在一起,维护性较差。
好了讲了这么多仅仅是递归调用的一种写法,关于本题官方给出的题解中给出了三种写法,还有自己模拟栈和Morris 遍历两种方法,接下来逐一解释。
模拟栈实现:
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> res;if (root == nullptr) return res;stack<TreeNode*> stk;stk.push(root);while (!stk.empty()) {TreeNode* node = stk.top();stk.pop();res.push_back(node->val);// 先压入右子节点,再压入左子节点// 这样出栈时会先访问左子节点,再访问右子节点if (node->right) stk.push(node->right);if (node->left) stk.push(node->left);}return res;}
};
按照前序遍历的顺序(根->左->右),需要先访问左子树,再访问右子树,所以:先将右子节点压入栈,这样就能确保在下一个循环时先访问左子节点。然后将左子节点压入栈。
下面我们还是拿刚刚那个例子来解释:
1/ \2 3/ \
4 5
1. 第一次循环
- 栈顶元素是
1,弹出1并加入到res:res = [1] stk = [] - 将
1的右子节点3压入栈:stk = [3] - 将
1的左子节点2压入栈:stk = [3, 2]
2. 第二次循环
- 栈顶元素是
2,弹出2并加入到res:res = [1, 2] stk = [3] - 将
2的右子节点5压入栈:stk = [3, 5] - 将
2的左子节点4压入栈:stk = [3, 5, 4]
3. 第三次循环
- 栈顶元素是
4,弹出4并加入到res:res = [1, 2, 4] stk = [3, 5] 4没有子节点,因此不需要压入任何新节点。
4. 第四次循环
- 栈顶元素是
5,弹出5并加入到res:res = [1, 2, 4, 5] stk = [3] 5没有子节点,因此不需要压入任何新节点。
5. 第五次循环
- 栈顶元素是
3,弹出3并加入到res:res = [1, 2, 4, 5, 3] stk = [] 3没有子节点,因此不需要压入任何新节点。
6. 结束循环
- 栈
stk为空,退出while循环。 - 最终的前序遍历结果
res为:res = [1, 2, 4, 5, 3]
下面我们来具体对比一下两种写法的优缺点:
1. 代码复杂度与可读性
-
递归实现:
- 代码简洁:递归的代码通常较为简洁,逻辑清晰。前序遍历的递归实现中,只需要一个辅助函数,递归调用左子树和右子树即可。
- 易于理解:对于熟悉递归的人来说,递归实现更符合自然思路(先处理当前节点,然后递归处理左右子树)。
- 隐藏了栈操作:递归本质上是使用系统调用栈来管理递归过程,这部分操作对开发者是“透明的”,不需要手动管理栈。
-
非递归实现:
- 代码复杂度稍高:需要手动管理栈,控制节点的压入和弹出顺序(例如先压入右节点,再压入左节点)。
- 更灵活:手动管理栈可以更灵活地调整遍历顺序,甚至可以在遍历过程中进行一些特殊的操作,比如记录路径、找到某个特定节点时提前退出等。
- 稍难理解:对于初学者,理解非递归的栈操作逻辑可能需要一些时间,因为需要手动维护栈的状态。
2. 性能
-
递归实现:
- 调用栈开销:递归实现会使用系统调用栈,每次递归调用都会在调用栈中增加一帧(stack frame)。对于深度较大的树,如果递归深度很深(如链式二叉树),可能会导致栈溢出(stack overflow)。
- 适合浅树:在处理深度较浅的二叉树时,递归方式性能较好,因为它不需要手动管理栈,系统栈管理的开销是最小的。
-
非递归实现:
- 无栈溢出问题:非递归实现使用手动的显式栈(
stack<TreeNode*>),避免了递归深度过大带来的系统栈溢出问题,适合处理非常深的树。 - 栈操作开销:虽然避免了系统栈的限制,但在栈上进行
push和pop操作仍然会带来一定的性能开销,特别是对于非常大的树,栈的内存消耗可能较高。
- 无栈溢出问题:非递归实现使用手动的显式栈(
3. 内存使用
-
递归实现:
- 系统调用栈:内存的消耗主要来自于系统调用栈。对于树的最大深度为
h的二叉树,递归实现的调用栈深度也是h,系统会在栈中为每一层的递归调用保存数据。 - 隐式栈管理:虽然消耗的内存和显式栈类似,但因为是由系统管理的,程序员不需要手动考虑栈的操作。
- 系统调用栈:内存的消耗主要来自于系统调用栈。对于树的最大深度为
-
非递归实现:
- 显式栈:显式栈的深度和树的最大深度
h成正比。对于深度为h的树,显式栈最多也会保存h个节点的引用。 - 控制力强:显式栈的内存使用是完全可控的,这使得它在需要处理非常深的树时更加适用。
- 显式栈:显式栈的深度和树的最大深度
4. 实际应用场景
-
递归实现:
- 更适合教学和理解树的基本概念。对于需要快速编写和理解树遍历的场景,递归实现是很好的选择。
- 适合树的深度可控且不太深的情况,例如一些操作较小的平衡二叉树。
-
非递归实现:
- 适合处理非常深的树,尤其是在可能出现栈溢出的情况下(如链表形式的二叉树)。
- 适合需要对遍历过程进行更多控制的场景。比如在中途对节点进行特殊处理、提前退出、记录路径等。
- 需要更加精细的性能控制:在某些系统中(如嵌入式环境),手动管理栈有助于减少递归带来的系统开销。
最后是Morris 遍历的实现:
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> res;TreeNode* cur = root;while (cur != nullptr) {if (cur->left == nullptr) {// 当前节点没有左子树,直接访问,并移到右子树res.push_back(cur->val);cur = cur->right;} else {// 找当前节点左子树中最右侧的节点(前驱)TreeNode* predecessor = cur->left;while (predecessor->right != nullptr && predecessor->right != cur) {predecessor = predecessor->right;}// 前驱节点的右指针为空,则建立回链并访问当前节点if (predecessor->right == nullptr) {res.push_back(cur->val); // 前序遍历:访问当前节点predecessor->right = cur; // 建立回链cur = cur->left; // 移到左子树} else {// 前驱节点的右指针指向当前节点,说明回链已建立,恢复树结构predecessor->right = nullptr; // 取消回链cur = cur->right; // 移到右子树}}}return res;}
};
Morris 遍历的核心思路是:
- 对于当前节点,如果它的左子树存在,就找到它左子树中最右侧的节点(称为当前节点的中序前驱)。
- 如果这个前驱节点的右指针为空(表示还未处理过),则将它的右指针指向当前节点(构造一个临时的回链),然后转向左子树。
- 如果前驱节点的右指针已经指向当前节点(表示之前构造的临时回链),则将这个右指针恢复为
nullptr(还原树结构),并访问当前节点,然后转向右子树。 - 如果当前节点没有左子树,则直接访问当前节点并转向右子树。
1. 访问节点 1
cur = 1,它有左子树,所以寻找1的前驱节点。- 前驱节点:
2的右子树最右侧的节点是5,所以predecessor = 5。 5的right是nullptr,建立回链5->right = 1,并访问当前节点1:res = [1]- 然后将
cur移动到1的左子树,即cur = 2。
2. 访问节点 2
cur = 2,它有左子树,所以寻找2的前驱节点。- 前驱节点:
4的右子树最右侧的节点是4,所以predecessor = 4。 4的right是nullptr,建立回链4->right = 2,并访问当前节点2:res = [1, 2]- 然后将
cur移动到2的左子树,即cur = 4。
3. 访问节点 4
cur = 4,它没有左子树,直接访问:res = [1, 2, 4]- 然后移动到
cur的右子树。由于之前建立了回链4->right = 2,所以cur = 2。
4. 回到节点 2,解除回链
cur = 2,此时predecessor = 4,predecessor->right已经指向2(说明之前建立过回链)。- 恢复
4的right指针为nullptr。 - 移动
cur到2的右子树,即cur = 5。
5. 访问节点 5
cur = 5,它没有左子树,直接访问:res = [1, 2, 4, 5]- 然后移动到
cur的右子树。由于之前建立了回链5->right = 1,所以cur = 1。
6. 回到节点 1,解除回链
cur = 1,此时predecessor = 5,predecessor->right已经指向1(说明之前建立过回链)。- 恢复
5的right指针为nullptr。 - 移动
cur到1的右子树,即cur = 3。
7. 访问节点 3
cur = 3,它没有左子树,直接访问:res = [1, 2, 4, 5, 3]- 然后移动到
cur的右子树,即cur = nullptr。
8. 结束遍历
cur = nullptr,遍历结束,最终结果为:res = [1, 2, 4, 5, 3]
Morris 遍历的优缺点
-
优点:
- 空间复杂度低:因为没有使用递归或显式栈,空间复杂度为 O(1),适合内存受限的环境。
- 时间复杂度:时间复杂度为 O(n),因为每个节点最多访问两次(一次是访问自身,另一次是解除回链)。
-
缺点:
- 修改了树的结构:需要临时修改树的右指针(建立和解除回链),这在某些场景下可能不合适。
- 代码复杂性较高:逻辑比普通递归或显式栈的实现要复杂一些,理解和实现难度较大。