第Y3周:yolov5s.yaml文件解读
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、导言
YOLOv5模型家族包含了四种不同的版本:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。这些版本在设计时考虑了不同的平衡点,以满足多样化的性能需求。其中,YOLOv5s以其简洁的结构而著称,它提供了较高的推理速度,同时保持了不错的准确率。这种轻量级的特性使它在边缘设备或实时性要求高的场景中非常有用。其余的三个版本(YOLOv5m、YOLOv5l、YOLOv5x)则在结构和深度上有所增加,从而提升了模型的特征提取能力和检测精度。但这种提升也伴随着计算复杂性的增加和资源消耗的提升。在选择合适的YOLOv5版本时,开发者需要在检测效率、模型大小和准确性之间找到最佳的平衡点。
./models/yolov5s.yaml文件是YOLOv5s网络结构的定义文件,如果你想改进算法的网络结构,需要先修改该文件中的相关参数,然后再修改./models/common.py与./models/yolo.py中的相关代码。
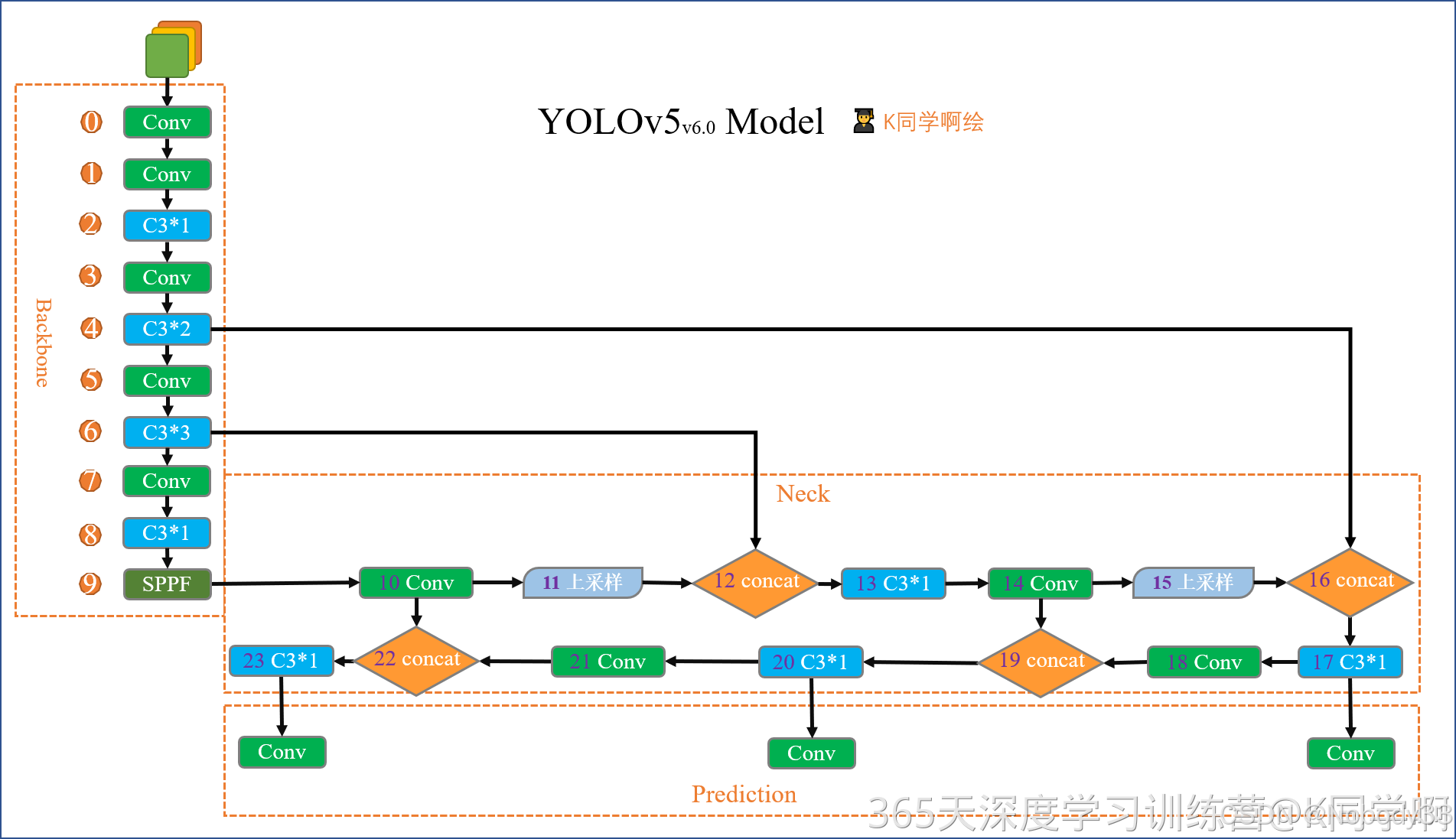
yolov5模型介绍
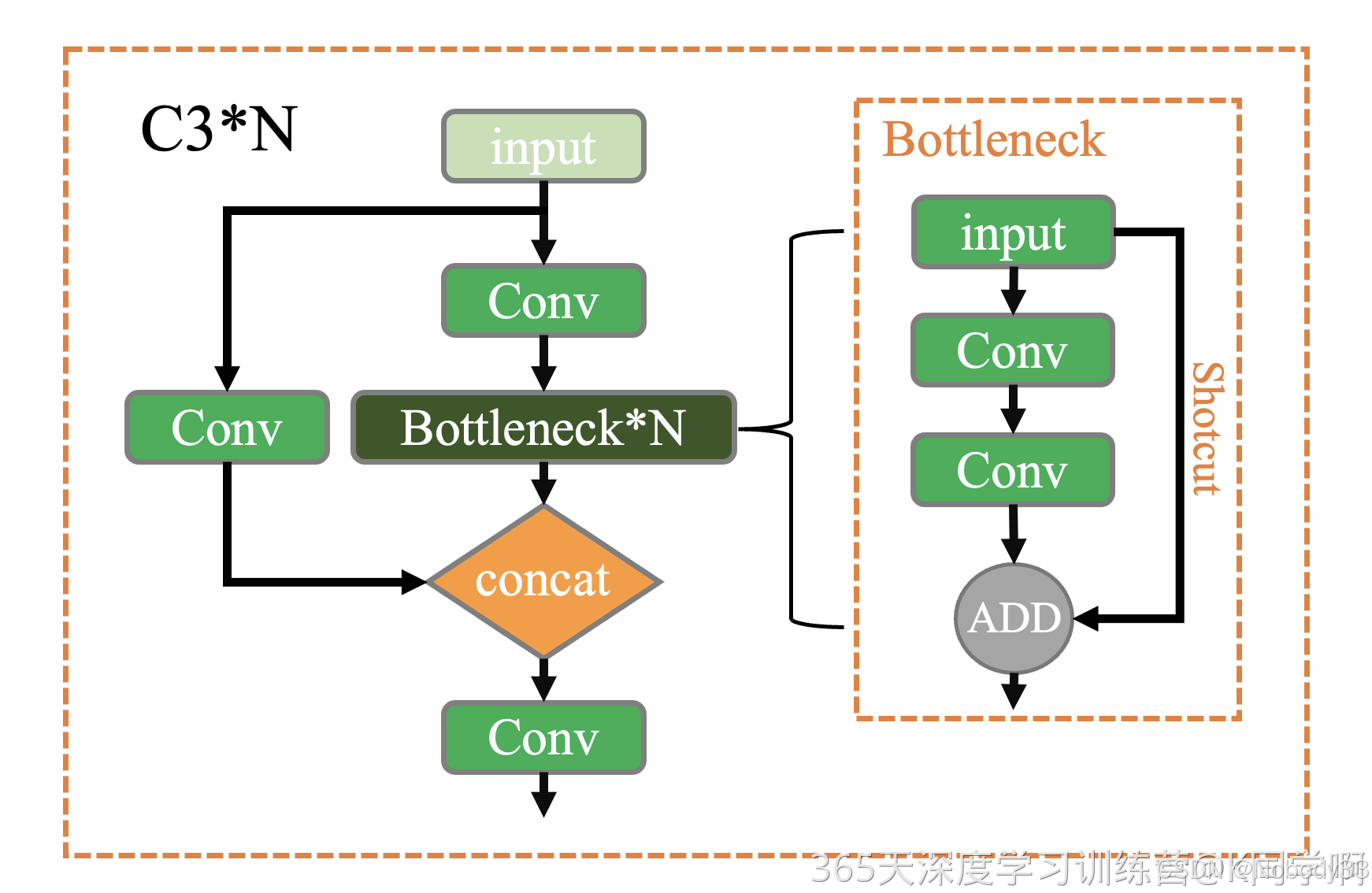
C3模块介绍
YOLOv5中的C3模块是一种神经网络模块,它是Cross Stage Partial networks(CSPNet)的一个变体,旨在提高网络的效率和性能。C3模块的核心思想是通过将输入特征图分成两部分,然后分别进行处理,最后再将这两部分的特征图合并,以此来实现更丰富的特征融合和更有效的信息传递。
下面是C3模块的详细解释:
结构
C3模块的结构可以概括为以下几个步骤:
- 特征图分割:
- 输入特征图被分成两个部分:一部分直接传递到模块的输出部分,另一部分进入下一阶段的处理。
- ** bottleneck 处理**:
- 被分割的那部分特征图会通过多个bottleneck结构。Bottleneck通常由一个1x1的卷积层(用于降维)和一个3x3的深度可分离卷积(用于特征提取)组成,有时候还会跟随一个1x1的卷积层(用于升维)。
- 在C3模块中,这些bottleneck通常是堆叠使用的,即一个bottleneck的输出是下一个bottleneck的输入。
- 特征融合:
- 经过bottleneck处理后的特征图与最初直接传递的那部分特征图在深度方向上进行拼接(concatenate)。
- 全局信息融合:
- 拼接后的特征图通常会通过一个额外的1x1卷积层,以确保不同特征图之间的特征能够有效融合,并减少计算量。
优点
- 计算效率:通过将特征图分割,C3模块减少了需要处理的特征图的数量,从而降低了计算成本。
- 特征融合:C3模块通过在深度方向上拼接特征图,实现了不同层次特征的融合,这有助于网络捕获更丰富的信息。
- 梯度流优化:CSPNet结构有助于改善梯度的流动,减少了训练过程中的梯度消失问题,使得网络能够更好地学习和优化。
在YOLOv5中的应用
在YOLOv5中,C3模块被用作构建网络的主干部分,尤其是在网络的深层部分,以实现有效的特征提取和传递。C3模块的使用有助于YOLOv5在保持较高推理速度的同时,也能够获得不错的检测精度。
yaml文件如图
二、正式开始
yolov5s.yaml 文件是YOLOv5(一个流行的目标检测神经网络)中的一个配置文件,它用于定义模型的结构、超参数以及训练和测试过程中的一些关键设置。具体来说,yolov5s.yaml 文件主要包含以下内容:
- 模型结构:该文件定义了YOLOv5s模型的大小和架构,包括各种层的类型(如卷积层、池化层、C3模块等)和它们的参数(如卷积核大小、步长、填充等)。
- 超参数:它包含了训练过程中的各种超参数,如学习率(lr)、批量大小(batch_size)、权重衰减(weight_decay)、动量(momentum)等。
- 锚点大小:锚点(anchor boxes)是用于预测边界框(bounding boxes)的一组预设框,
yolov5s.yaml文件中定义了这些锚点的尺寸。 - 路径:该文件还可能包含数据集路径、预训练权重路径等。
- 其他设置:比如是否使用多尺度训练(multi-scale training)、是否使用自动锚点检测(autoanchor)、是否启用Cosine学习率调度器等。
YOLOv5提供了多种不同大小的模型配置文件,如yolov5s.yaml(小型)、yolov5m.yaml(中型)、yolov5l.yaml(大型)和yolov5x.yaml(超大型),每种模型在深度和宽度上有所不同,以适应不同的计算资源和性能需求。
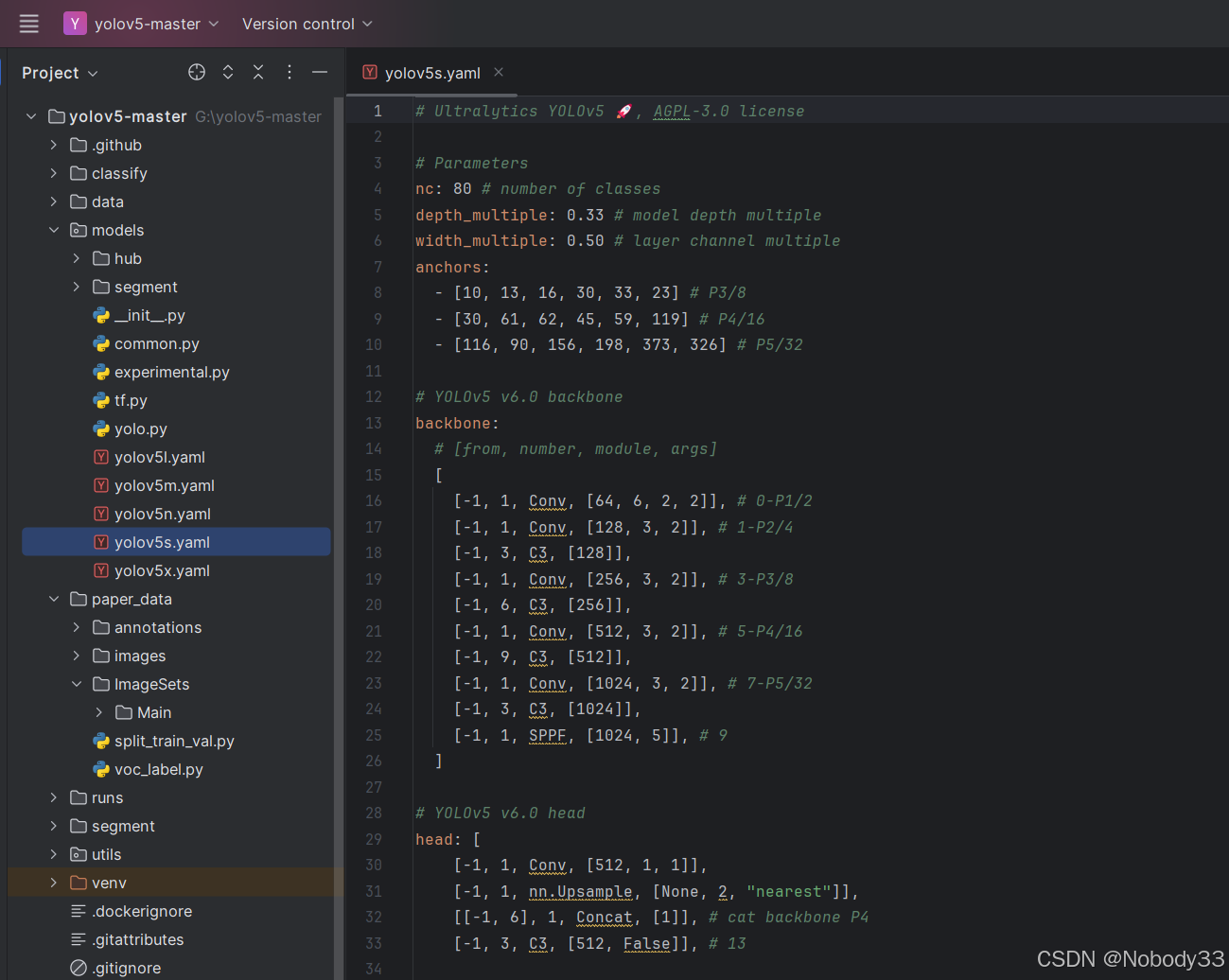
1.参数设置
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
nc是输出类别的个数;
depth_multiple与子模块的数量有关
width_multiple与卷积核的数量有关
yolov5的几个模型的区别就在这两个参数上。
2anchors设置
anchors:- [10, 13, 16, 30, 33, 23] # P3/8- [30, 61, 62, 45, 59, 119] # P4/16- [116, 90, 156, 198, 373, 326] # P5/32
在YOLOv5的配置文件 yolov5s.yaml 中,anchors 部分定义了用于不同特征图层级(也称为检测层级)的锚点(anchor)尺寸。锚点是一组预设的边界框尺寸,模型在预测时会使用这些锚点来帮助定位图像中的对象。以下是这一段内容的详细解释:
- [10, 13, 16, 30, 33, 23]:这一行定义了在YOLOv5网络中最小的特征图层级(P3/8)上使用的锚点尺寸。这里有三个锚点,每个锚点由两个值表示,分别是宽度和高度(按照图像的原始尺寸比例)。例如,第一个锚点是宽10,高13。
- # P3/8:注释说明了这些锚点对应的是经过8倍下采样的特征图层级。在YOLOv5中,输入图像首先被下采样8倍,然后在这些特征图上进行检测。
- [30, 61, 62, 45, 59, 119]:这一行定义了中等大小的特征图层级(P4/16)上使用的锚点尺寸。同样地,这里也有三个锚点,每个锚点由宽度和高度组成。这些锚点对应于经过16倍下采样的特征图层级。
- # P4/16:注释指出了这些锚点是在16倍下采样的特征图上使用的。
- [116, 90, 156, 198, 373, 326]:这一行定义了最大的特征图层级(P5/32)上使用的锚点尺寸。这里也有三个锚点,它们的尺寸最大,适用于检测大尺寸的对象。这些锚点对应于经过32倍下采样的特征图层级。
- # P5/32:注释说明了这些锚点是在32倍下采样的特征图上使用的。
YOLOv5在初始化时设定了9个锚点(anchors),这些锚点被应用于三个检测层,共涉及三个特征图(feature maps)。在每个特征图中,每一个网格单元(grid cell)都被指派了三个锚点用以执行检测任务。锚点的分配遵循以下原则:
- 对于较大的特征图,由于它们在原图上的下采样率较低,感知范围较小,因此更适合探测较小的目标对象。相应地,这些特征图所分配的锚点也较小。
- 相比之下,较小的特征图在原图上的下采样率较高,拥有更大的感知区域,因而更能有效探测较大规模的目靶。故此,这些特征图对应的锚点设置也更大。
YOLOv5通过这种方式,实现了在小特征图上检测大目标和在大特征图上检测小目标的双重可能。尽管YOLOv5预设的这三组锚点在很多数据集上表现良好,但并不意味着它们能完美适应所有情况。为此,YOLOv5还提供了锚点进化的策略:利用K均值聚类和遗传算法,自动寻找与特定数据集最为匹配的新锚点。
3.backbone
# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 3, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 6, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]
在YOLOv5的配置文件 yolov5s.yaml 中,backbone 部分定义了网络的主干结构,即特征提取器。这个主干网络负责从输入图像中提取特征,这些特征随后会被检测头(head)用于生成最终的检测结果。以下是 backbone 部分的详细解释:
backbone是一个列表,其中包含了构建主干网络的层和连接的详细说明。
以下是每一行的具体作用:[-1, 1, Conv, [64, 6, 2, 2]]: 第一个卷积层,使用64个3x3的卷积核,步长为2,对输入图像进行下采样,同时增加深度(通道数)。这里的6表示卷积核的大小是6x6,最后的2表示填充大小。这个层对应于P1/2特征图。[-1, 1, Conv, [128, 3, 2]]: 第二个卷积层,使用128个3x3的卷积核,步长为2,进一步下采样特征图,对应于P2/4特征图。[-1, 3, C3, [128]]: 应用一个C3模块,输入通道数为128,这个模块用于增强特征的表达能力。- 接下来的几个层重复了卷积和C3模块的模式,每次卷积都会将特征图的尺寸减半,同时增加通道数,分别对应于P3/8、P4/16和P5/32特征图。
[-1, 1, Conv, [1024, 3, 2]]: 一个卷积层,使用1024个3x3的卷积核,步长为2,对应于P5/32特征图。[-1, 3, C3, [1024]]: 应用一个C3模块,输入通道数为1024。[-1, 1, SPPF, [1024, 5]]: 应用一个SPPF(Spatial Pyramid Pooling - Fast)模块,输入通道数为1024,5表示池化核的大小。SPPF模块可以有效地增加感受野,同时保持较高的计算效率。
总的来说,backbone的作用是从输入图像中提取多层次的特征,这些特征包含了不同尺度的信息,对于检测不同大小的对象至关重要。通过逐步增加卷积核的数量和减小特征图的尺寸,主干网络能够在保持重要信息的同时减少计算量。最后,SPPF模块进一步丰富了特征的表达,有助于网络在后续的检测头中更准确地预测对象的位置和类别。
4.head
# YOLOv5 v6.0 head
head: [[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, "nearest"]],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, "nearest"]],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]在YOLOv5的配置文件 yolov5s.yaml 中,head 部分定义了网络的检测头(detection head),这是YOLOv5网络结构中用于生成最终检测结果的关键部分。以下是对 head 部分的详细解释:
head是一个列表,其中包含了构建检测头的层和连接的详细说明。
以下是每一行的具体作用:[-1, 1, Conv, [512, 1, 1]]: 使用一个卷积层(Conv)对特征图进行卷积操作,输出通道数为512,卷积核大小为1x1。[-1, 1, nn.Upsample, [None, 2, "nearest"]]: 使用最近邻上采样(nn.Upsample)将特征图的尺寸放大两倍。[[ -1, 6], 1, Concat, [1]]: 将上采样的特征图与网络骨干(backbone)中的第6个模块(对应于P4特征图)的特征图在通道维度上进行拼接(Concat)。[-1, 3, C3, [512, False]]: 应用一个C3模块,该模块具有512个输出通道,不使用残差连接的shortcut。- 接下来的几个类似的层重复了上述的过程,包括卷积、上采样、拼接和C3模块,分别处理不同尺度的特征图。
[-1, 1, Conv, [256, 3, 2]]: 使用一个步长为2的3x3卷积层,将特征图的尺寸缩小一半,同时将通道数减少到256。[[17, 20, 23], 1, Detect, [nc, anchors]]: 这是检测头的最后一部分,它将来自三个不同尺度的特征图(分别标记为17, 20, 23,对应于P3/8-small, P4/16-medium, P5/32-large)连接起来,并传递给Detect层进行最终的检测。nc是类别数量,anchors是之前定义的锚点。
总的来说,head部分的作用是处理来自骨干网络的输出特征图,通过一系列的卷积、上采样、拼接和C3模块来构建不同尺度的特征图,并最终在Detect层进行边界框的预测和类别的识别。这样的设计使得YOLOv5能够同时检测不同大小的对象。
5.模型改动
我们是要将yolov5s.yaml网络模型中第4层的C3 * 2修改为C3 * 1,第6层的C3 * 3修改为C3 * 2。
我们可以知道修改后的第4层和第6层为
[-1,3,C3,[256]]
[-1,6,C3,[512]]
即
# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 3, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 6, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]一定要在自己的路径下运行
python ./train.py --img 900 --batch 16 --epoch 100 --data ./Fruit_test/fruit.yaml --cfg ./models/yolov5s.yaml --weights ./yolov5s.pt --device '0'
前后对比
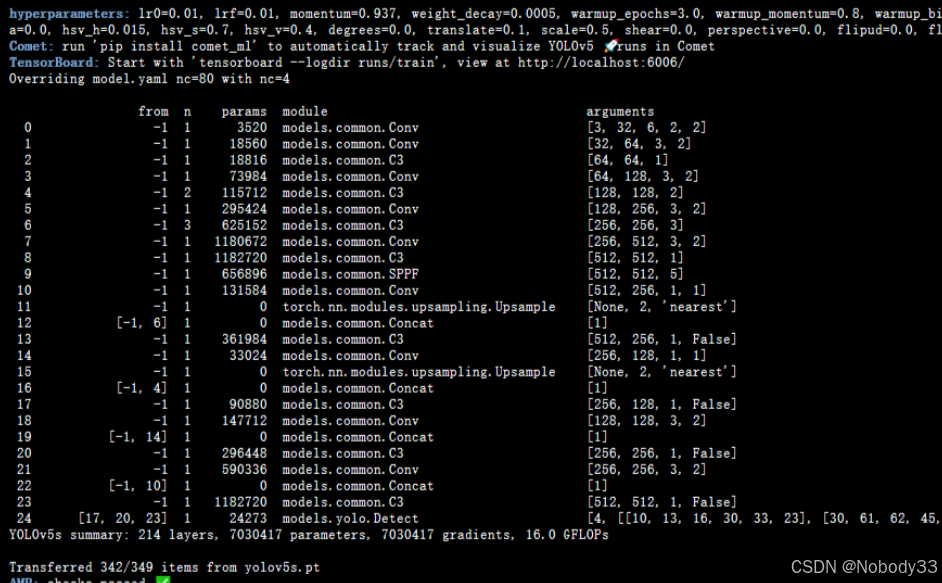
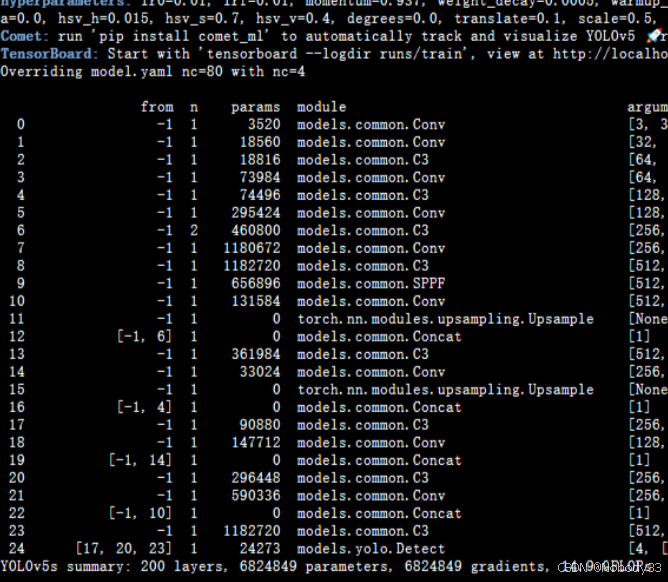
将模块减少后参数量也减少了很多