因为简历上写了“熟悉大模型解码”,我被面试官问傻了...
前言
本文基于 llama 模型的源码,学习一些大模型的解码细节,属于初学者比较基础的学习笔记。
首先抛出几个问题:
-
大模型的解码速度和 prompt 长度有关系吗?
-
大模型的解码速度是怎么计算的?
-
大模型的解码超参数在源码中是怎么生效的?
01
解码速度细节
假设我们的 prompt 是:batch_size 为 1 的 10 个 token,那么:
模型计算第一个 token 时
- q,k,v 的形状均为:(1, 10, self.num_heads, self.head_dim)
模型计算第二个 token 时
-
q 的形状为:(1, 1, self.num_heads, self.head_dim)
-
k 的形状为:(1, 11, self.num_heads, self.head_dim)
-
v 的形状为:(1, 11, self.num_heads, self.head_dim)
模型计算第三个 token 时
-
q 的形状为:(1, 1, self.num_heads, self.head_dim)
-
k 的形状为:(1, 12, self.num_heads, self.head_dim)
-
v 的形状为:(1, 12, self.num_heads, self.head_dim)
-
……
-
……

实际应用中,大模型的生成文本都较长,因此我们会有如下结论:大部分场景下,模型的生成速度与 prompt 长度无关,仅与生成文本长度有关。
如果我们使用大模型代替 BERT 做分类任务,即输出很短,那么耗时便与 prompt 的长度有直接关系。
class LlamaAttention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def __init__(self, config: LlamaConfig):"""略"""def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Tuple[torch.Tensor]] = None,output_attentions: bool = False,use_cache: bool = False,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size()query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)kv_seq_len = key_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value[0].shape[-2]cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)# [bsz, nh, t, hd]if past_key_value is not None:# reuse k, v, self_attentionkey_states = torch.cat([past_key_value[0], key_states], dim=2)value_states = torch.cat([past_key_value[1], value_states], dim=2)past_key_value = (key_states, value_states) if use_cache else Noneattn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)"""略"""# upcast attention to fp32attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_output = torch.matmul(attn_weights, value_states)attn_output = attn_output.transpose(1, 2)attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)attn_output = self.o_proj(attn_output)if not output_attentions:attn_weights = Nonereturn attn_output, attn_weights, past_key_value
上面的代码是 modeling_llama.py 的源码,从中可以看出:
模型在解码时,每次都会保存上一次 decode 时留下的 past_key_value[0] 与 past_key_value[1],然后与新的 key_states 和 value_states 进行 cat 操作。
具体可见下面这几行代码:
if past_key_value is not None:# reuse k, v, self_attentionkey_states = torch.cat([past_key_value[0], key_states], dim=2)value_states = torch.cat([past_key_value[1], value_states], dim=2)
past_key_value = (key_states, value_states) if use_cache else None
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
这也就解释了 q, k, v 的形状为什么遵从如下规律:
q 的形状为: (1, 1, self.num_heads, self.head_dim)
k 的形状为:(1, len(prompt的token数量) + len(已生成的token数量), self.num_heads, self.head_dim)
v 的形状为:(1, len(prompt的token数量) + len(已生成的token数量), self.num_heads, self.head_dim)
此外,上述代码还有一个细节,llama 模型在训练的时候用的半精度,但在做 softmax 时候用的是全精度。
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
02
解码参数细节
首先推荐大模型新人都读一下:如何生成文本: 通过 Transformers 用不同的解码方法生成文本,下面的代码均为 huggingface 的源码。
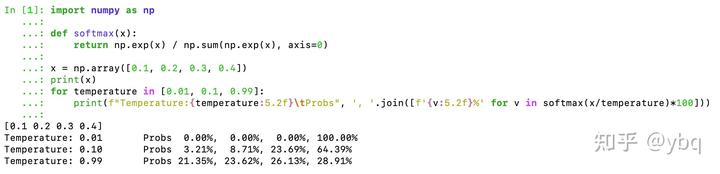
temperature 的生效逻辑:scores 在 softmax 之前除以 temperature。
下图可以清晰地展示出,为什么大家常说:temperature 越高,模型的生成多样性越好。
但需要注意的是:temperature 这一参数不会改变 token 之间的相对大小,因此在 do_sample=False 的情况下,该参数不影响解码结果。
class TemperatureLogitsWarper(LogitsWarper):def __init__(self, temperature: float):if not isinstance(temperature, float) or not (temperature > 0):raise ValueError(f"`temperature` has to be a strictly positive float, but is {temperature}")self.temperature = temperaturedef __call__(self, input_ids: torch.Tensor, scores: torch.Tensor) -> torch.FloatTensor:scores = scores / self.temperaturereturn scores
**top_p的生效逻辑:**先按照概率从大到小排序(源码是记录排序的 index),找到最小 token 数量的集合,使得这些 token 的概率和 > top_p。
top_p 等于 0 代表 greedy:
class TopPLogitsWarper(LogitsWarper):def __init__(self, top_p: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):top_p = float(top_p)if top_p < 0 or top_p > 1.0:raise ValueError(f"`top_p` has to be a float > 0 and < 1, but is {top_p}")self.top_p = top_pself.filter_value = filter_valueself.min_tokens_to_keep = min_tokens_to_keepdef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:sorted_logits, sorted_indices = torch.sort(scores, descending=False)cumulative_probs = sorted_logits.softmax(dim=-1).cumsum(dim=-1)# Remove tokens with cumulative top_p above the threshold (token with 0 are kept)sorted_indices_to_remove = cumulative_probs <= (1 - self.top_p)if self.min_tokens_to_keep > 1:# Keep at least min_tokens_to_keepsorted_indices_to_remove[..., -self.min_tokens_to_keep :] = 0# scatter sorted tensors to original indexingindices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)scores = scores.masked_fill(indices_to_remove, self.filter_value)return scores
**top_k 的生效逻辑:**先按照概率从大到小排序(源码是记录排序的 index),找到前 top_k 个 token。
top_k 等于 1 代表 greedy:
class TopKLogitsWarper(LogitsWarper):def __init__(self, top_k: int, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):if not isinstance(top_k, int) or top_k <= 0:raise ValueError(f"`top_k` has to be a strictly positive integer, but is {top_k}")self.top_k = max(top_k, min_tokens_to_keep)self.filter_value = filter_valuedef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:top_k = min(self.top_k, scores.size(-1)) # Safety check# Remove all tokens with a probability less than the last token of the top-kindices_to_remove = scores < torch.topk(scores, top_k)[0][..., -1, None]scores = scores.masked_fill(indices_to_remove, self.filter_value)return scores
**repetition_penalty 生效逻辑:**已经出现过的 token,在后续计算其概率的时候,要除以 self.penalty。
class RepetitionPenaltyLogitsProcessor(LogitsProcessor):def __init__(self, penalty: float):if not isinstance(penalty, float) or not (penalty > 0):raise ValueError(f"`penalty` has to be a strictly positive float, but is {penalty}")self.penalty = penaltydef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:score = torch.gather(scores, 1, input_ids)# if score < 0 then repetition penalty has to be multiplied to reduce the previous token probabilityscore = torch.where(score < 0, score * self.penalty, score / self.penalty)scores.scatter_(1, input_ids, score)return scores
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇


面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇

