千万级的大表,是如何产生的?
千万级的大表,是如何产生的?
我们小公司没有大表。。。
大家好,我是皇子。
前面的文章在介绍了《设计支持千万级的大表,有哪些数据库规范?》,实际上不管是否到达千万级,这些规范都是适用的。
那有人会觉得,我们的公司的业务、用户都没起来,千万级的数据量?不可能、绝对不可能,暂时不需要考虑。
…这么说,一点毛病没有,把时间精力花在重要的业务核心上才是重要的。
而我想从3个方面说一下,其实千万级的数据产生会有很多原因的。
除了我们常知道的业务的快速增长是常见的原因之一。例如:一个电商平台中,随着用户数量的不断增加,订单量呈爆发式增长,订单表的数据量就会迅速累积。假设每天新增十万笔订单,一年下来订单表的数据量就很容易达到千万级别。
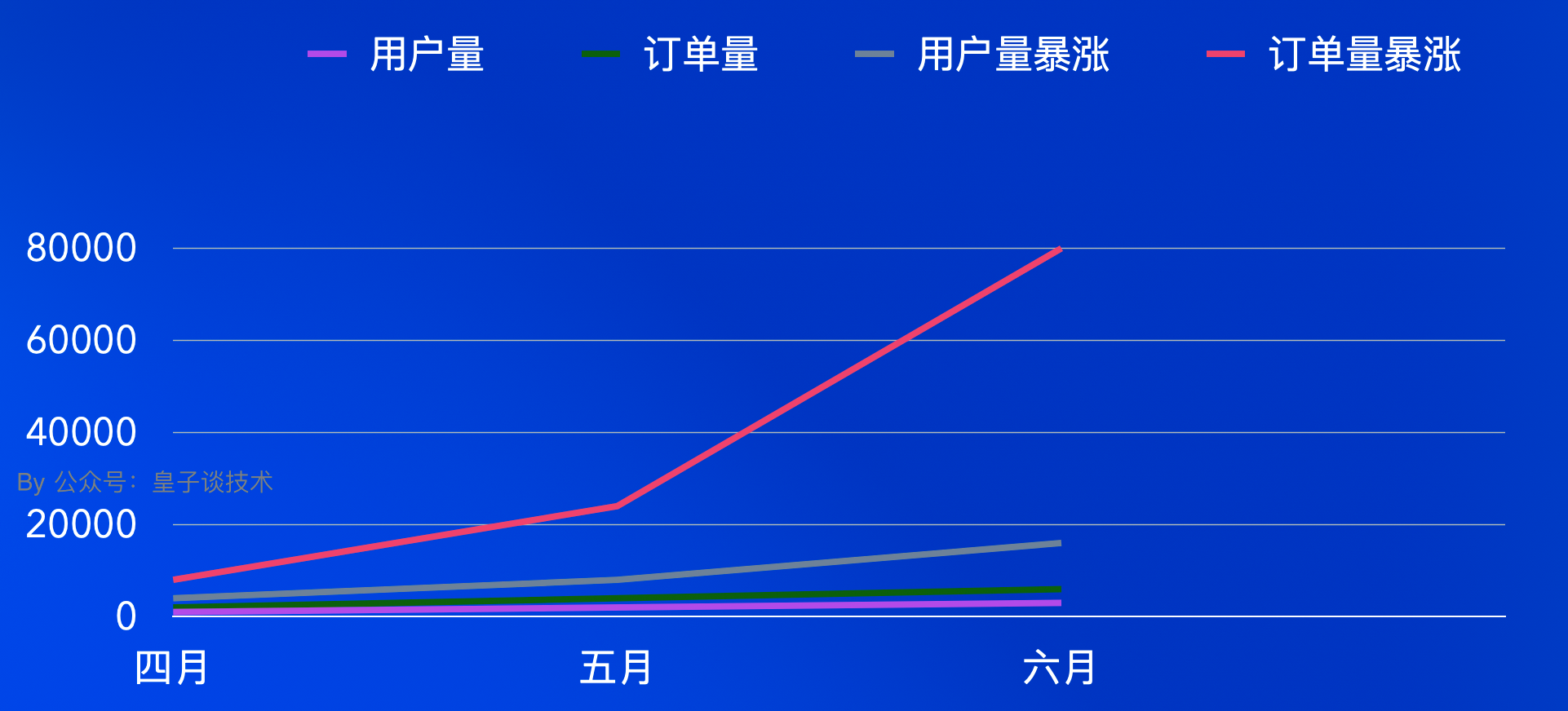
还有一种是业务设计不合理导致的。比如
- 产品要求你说你要把用户的所有操作都进行保留下来,在没有对数据的
保留周期进行合理规划后,就将所有用户的增删改查操作一股脑地都往一个表里面丢并长期保存。那1000个活跃用户,每天操作20次,每次操作平均涉及10个接口,一年也能轻松干到千万级数据。
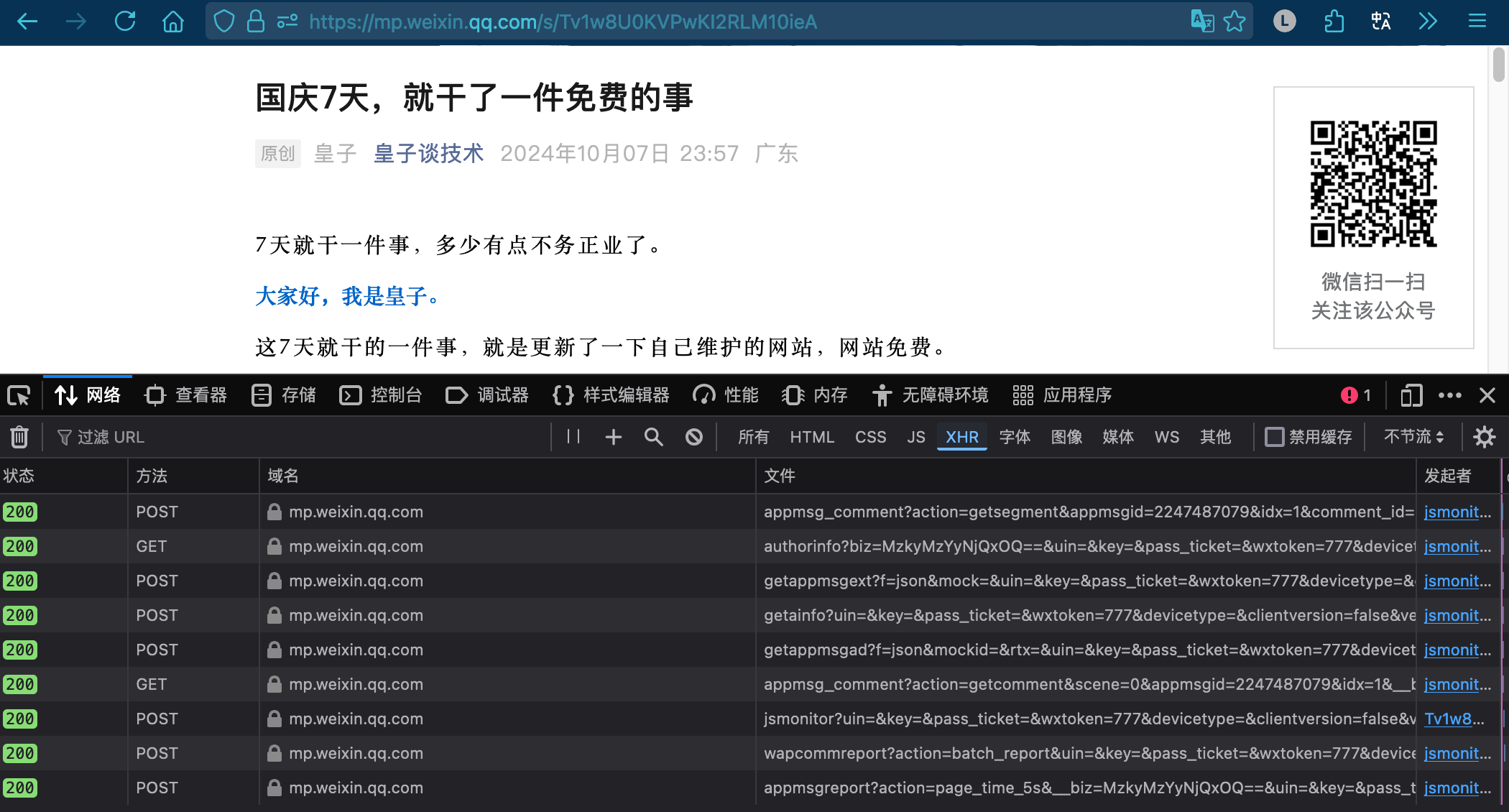
大家猜猜,一篇公众号文章复制链接后在浏览器上打开,共发生了几次接口调用?
这篇文章是复制链接后在浏览器上打开的,共发生了88次网络请求,其中共9个
XHR(XMLHttpRequest)请求,也就是这9个请求是会到达应用层的,包含获取登录态、获取发表者、原创者、关联的文章、包含的广告数等接口。如果是在微信打开只会更多,因为还需要获取广告信息、评论信息,那调用接口只会更多。
- 还有一种情况是
数据过度采集,一个物联网系统为例,传感器可能会频繁地采集大量数据并全部存储,而其中很多数据可能并不具有实际的分析价值,但却被不加筛选地存入了数据库表中。那100个设备,每5秒进行一次数据上报,在不包括用户操作设备的情况下,1千万的数据一年就干到了。
最后是在缺乏对表数据进行数据清理和归档机制的情况下,随着时间的增长数据也在不断稳中增长,1年不到一千万,再过几年呢?所以这也是为什么有些系统会把7天、30天、半年维度的时间周期数据作为一个统一入口去查询历史数据,其他时间维度通过自定义的方式到另外一个入口(接口)去查询的原因,或者干脆是其他时间维度的数据不再支持查询。
这样做的目的有两个:第一个做冷热数据的隔离,提高查询效率,同时提高系统的可靠性和稳定性;另外就是做数据归档,降低数据存储的成本。
以上,点亮【赞与在看】让我们心中充满力量、披荆斩棘、不惧未来!
推荐的学习网站:https://itgogogo.cn
关于作者:一位热爱技术,并在职场与自媒体间探索的实践者,希望通过分享个人经验和见解,帮助更多人实现自我成长和价值。