从零开始掌握YOLOv11:一文读懂损失函数的奥秘(源码+实操)
相关文章:
YOLOv1–v11: 版本演进及其关键技术解析-CSDN博客
YOLOv11:重新定义实时目标检测的未来-CSDN博客
Yolo v11目标检测实战1:对象分割和人流跟踪(附源码)-CSDN博客
YOLOv11目标检测实战2:人流统计、车流统计和跟踪(附源码)-CSDN博客
YOLO11项目实战2:道路缺陷检测系统优化【Python源码+数据集+界面】
YOLO11项目实战1:道路缺陷检测系统设计【Python源码+数据集+运行演示】
一、模型训练监控界面:
问题:每个损失函数的意义是什么?代表什么样的业务含义?
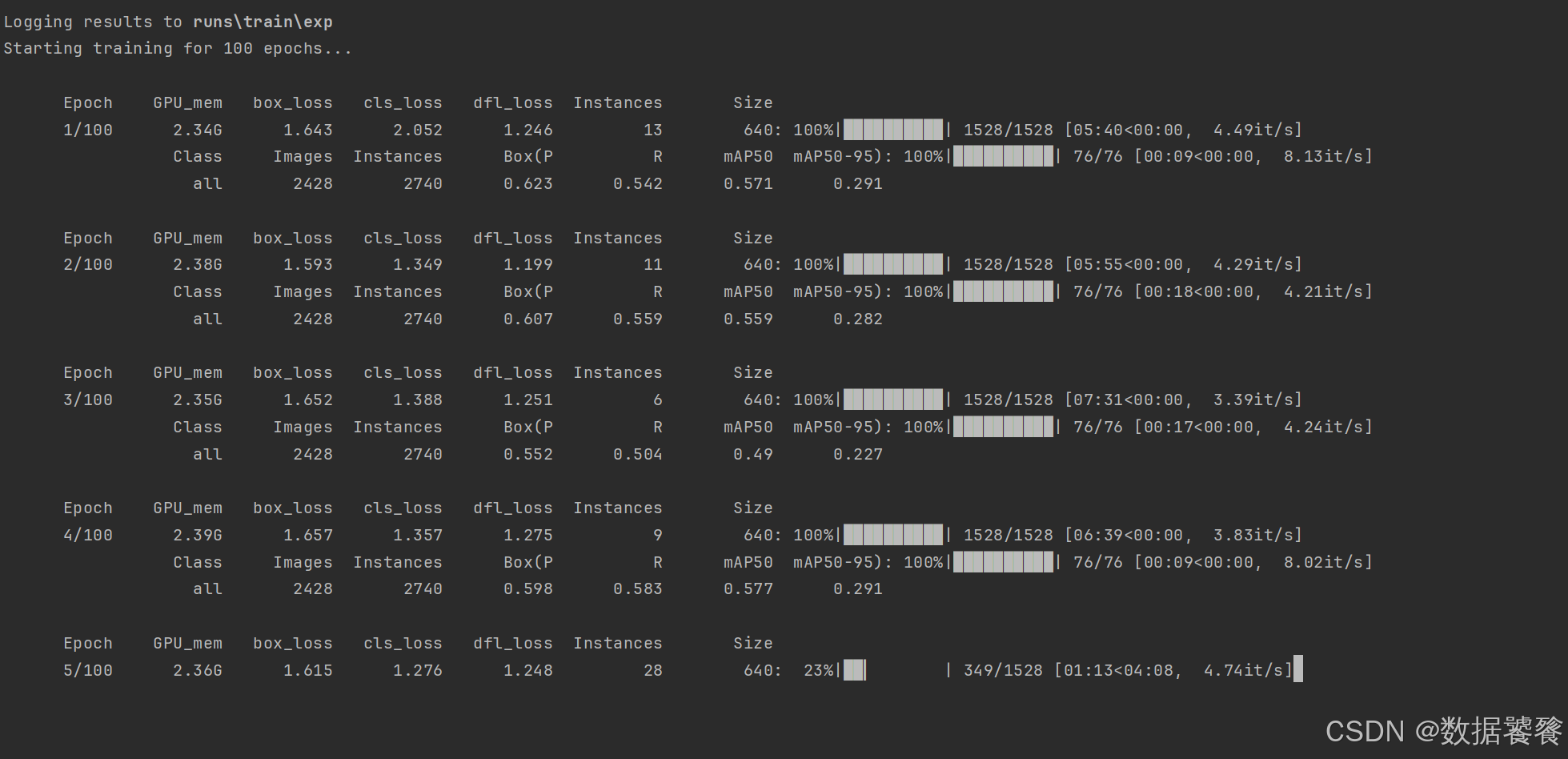

上述损失函数各自代表什么样的意义?具有什么样的业务含义呢?请听我慢慢道来。
二、Yolo11 三大损失函数
YOLO(You Only Look Once)是一种流行的目标检测算法,其损失函数设计用于同时优化分类和定位任务。YOLO的损失函数通常包括几个部分:分类损失、定位损失(边界框回归损失)和置信度损失。其中,
-
box_loss(边界框回归损失)是用于优化预测边界框与真实边界框之间的差异的部分。
-
cls_loss(分类损失)是用于优化模型对目标类别的预测准确性的部分。分类损失确保模型能够正确地识别出图像中的对象属于哪个类别。
-
dfl_loss(Distribution Focal Loss)是YOLO系列中的一种损失函数,特别是在一些改进版本如YOLOv5和YOLOv7中被引入。它的主要目的是解决目标检测中的类别不平衡问题,并提高模型在处理小目标和困难样本时的性能。
三、边界框回归损失详解
box_loss(边界框回归损失)是用于优化预测边界框与真实边界框之间的差异的部分。

3.1 box_loss 的具体意义

3.2 为什么需要 box_loss
- 精确定位:通过最小化中心点坐标损失和宽高损失,模型能够更准确地预测目标的位置和大小。
- 平衡不同类型的目标:使用平方根来处理宽高损失,可以更好地平衡不同大小的目标,确保小目标也能得到足够的关注。
- 稳定训练:适当的损失函数设计有助于模型的稳定训练,避免梯度爆炸或消失等问题。
四、分类损失详解
在YOLO(You Only Look Once)目标检测算法中,cls_loss(分类损失)是用于优化模型对目标类别的预测准确性的部分。分类损失确保模型能够正确地识别出图像中的对象属于哪个类别。下面是关于cls_loss的详细解读:
4.1 分类损失 (cls_loss) 的具体意义
分类损失通常使用交叉熵损失(Cross-Entropy Loss)来计算。交叉熵损失衡量的是模型预测的概率分布与真实标签之间的差异。在YOLO中,分类损失的具体形式如下:

4.2 为什么需要 cls_loss
-
类别识别:cls_loss 确保模型能够正确识别出图像中的目标属于哪个类别。这对于目标检测任务至关重要,因为不仅需要知道目标的位置,还需要知道目标的类型。
-
多类别支持:通过最小化分类损失,模型可以处理多个类别的目标检测任务。例如,在道路缺陷检测中,可能需要识别裂缝、坑洞、路面破损等多种类型的缺陷。
-
提高准确性:分类损失有助于提高模型的分类准确性,从而提升整体检测性能。通过优化分类损失,模型可以更好地学习不同类别之间的特征差异。
五、分布损失详解
dfl_loss(Distribution Focal Loss)是YOLO系列中的一种损失函数,特别是在一些改进版本如YOLOv5和YOLOv7中被引入。它的主要目的是解决目标检测中的类别不平衡问题,并提高模型在处理小目标和困难样本时的性能。下面是对dfl_loss的详细解读:
5.1 DFL Loss 的背景
在目标检测任务中,类别不平衡是一个常见的问题。某些类别的样本数量可能远远多于其他类别,这会导致模型在训练过程中对常见类别的学习效果较好,而对罕见类别的学习效果较差。此外,小目标和困难样本的检测也是一个挑战,因为这些目标通常具有较少的特征信息,容易被忽略或误分类。
为了应对这些问题,研究者们提出了多种改进方法,其中之一就是dfl_loss。dfl_loss通过引入分布焦点损失来增强模型对困难样本的关注,并改善类别不平衡问题。
5.2 DFL Loss 的定义
DFL Loss 通常与传统的交叉熵损失结合使用,以增强模型对困难样本的学习能力。其核心思想是通过对每个类别的预测概率进行加权,使得模型更加关注那些难以正确分类的样本。
DFL Loss 的公式可以表示为:

5.3 DFL Loss 的具体意义
- 类别不平衡:通过引入平衡因子 α,DFL Loss 可以更好地处理类别不平衡问题。对于少数类别的样本,可以通过增加其权重来提升其重要性,从而提高模型对这些类别的检测性能。
- 困难样本:通过聚焦参数 γ,DFL Loss 可以让模型更加关注那些难以正确分类的样本。当
- γ 较大时,模型会对那些预测概率较低的样本给予更多的关注,从而提高这些样本的分类准确性。
- 提高整体性能:DFL Loss 结合了传统交叉熵损失的优势,并通过加权机制增强了模型对困难样本的学习能力,从而提高了整体的检测性能。
六、总结
YOLO的三大损失函数分别针对不同的任务进行优化:
- 边界框回归损失 (Box Loss):确保模型能够准确地定位目标。
- 置信度损失 (Objectness Loss):优化预测边界框的置信度,提高模型对目标存在与否的判断能力。
- 分类损失 (Classification Loss):确保模型能够正确识别出图像中的对象属于哪个类别。
通过这三个损失函数的组合,YOLO能够在保持高效性的同时,提供高精度的目标检测结果。希望这些详细的解释对你有所帮助!如果你有更多问题或需要进一步的说明,请告诉我。