MySQL --索引(下)
文章目录
- 6.索引操作
- 6.1 创建主键索引
- 6.2 创建唯一索引
- 6.3 创建普通索引
- 6.4 创建全文索引
- 6.5 查询索引
- 6.6 删除索引
- 6.7 索引创建原则
- 6.8 复合索引
- 6.9 索引最左匹配原则
- 6.10 索引覆盖
6.索引操作
6.1 创建主键索引
第一种方式:
– 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));
第二种方式:
– 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));
第三种方式
– 创建表以后再添加主键
create table user3(id int, name varchar(30));
alter table user3 add primary key(id);
主键索引的特点:
一个表中,最多有一个主键索引,当然可以使符合主键
主键索引的效率高(主键不可重复)
创建主键索引的列,它的值不能为null,且不能重复
主键索引的列基本上是int
6.2 创建唯一索引
第一种方式
– 在表定义时,在某列后直接指定unique唯一属性。
create table user4(id int primary key, name varchar(30) unique);
第二种方式
– 创建表时,在表的后面指定某列或某几列为unique
create table user5(id int primary key, name varchar(30), unique(name));
第三种方式
create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);
唯一索引的特点:
一个表中,可以有多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,等价于主键索引
6.3 创建普通索引
第一种方式
create table user8(id int primary key,
name varchar(20),
email varchar(30),
index(name) --在表的定义最后,指定某列为索引
);
第二种方式
create table user9(id int primary key, name varchar(20), email varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引
第三种方式
create table user10(id int primary key, name varchar(20),
email varchar(30));
-- 创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);
普通索引的特点:
一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
6.4 创建全文索引
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。如果对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
查询有没有database数据:
如果使用如下查询方式,虽然查询出数据,但是没有使用到全文索引
select * from articles where body like '%database%';
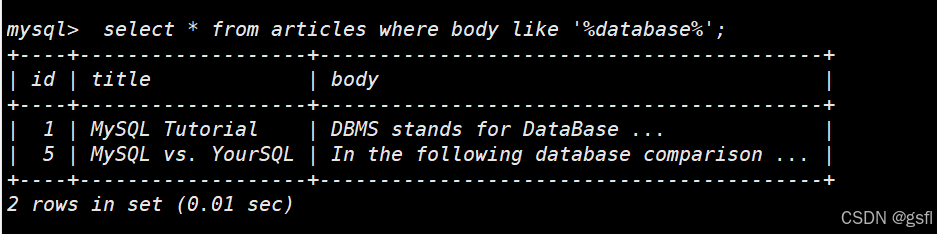
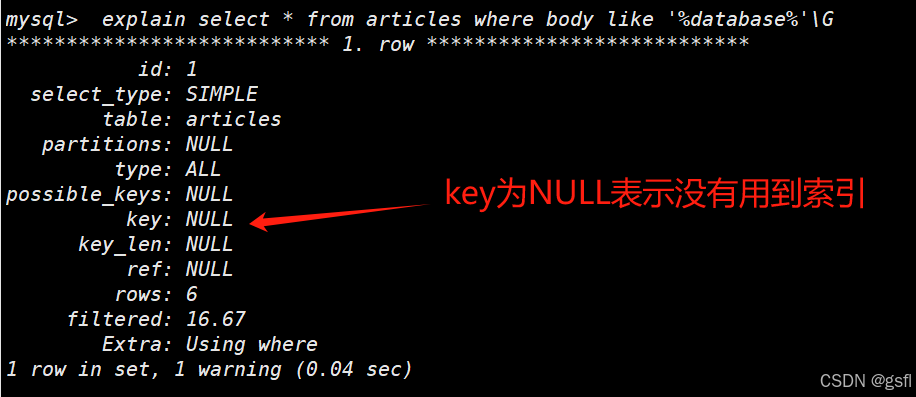
可以用explain工具看一下,是否使用到索引
explain select * from articles where body like '%database%'\G
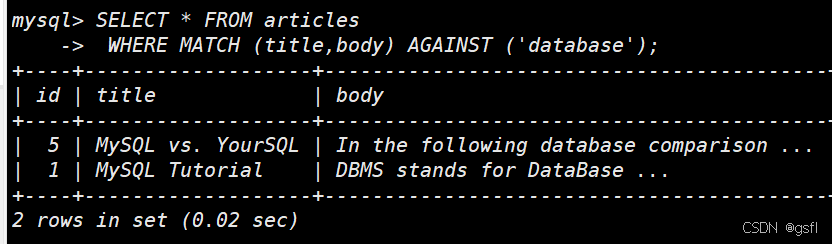
使用全文索引:
SELECT * FROM articlesWHERE MATCH (title,body) AGAINST ('database');
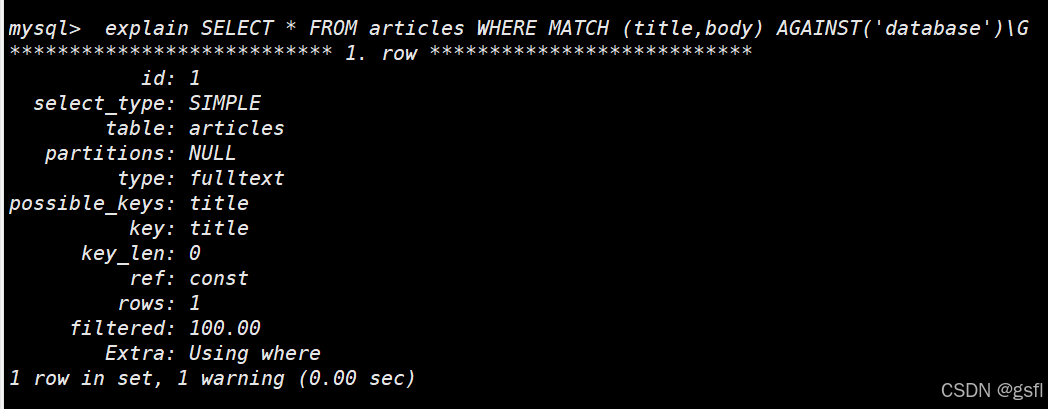
通过explain来分析这个sql语句
explain SELECT * FROM articles WHERE MATCH (title,body) AGAINST('database')\G
6.5 查询索引
第一种方法: show keys from 表名
show keys from goods\G

第二种方法: show index from 表名;
第三种方法(信息比较简略): desc 表名;

6.6 删除索引
第一种方法-删除主键索引: alter table 表名 drop primary key;
第二种方法-其他索引的删除: alter table 表名 drop index 索引名; 索引名就是show keys from 表名中的 Key_name 字段
第三种方法方法: drop index 索引名 on 表名
6.7 索引创建原则
比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合作创建索引
不会出现在where子句中的字段不该创建索引
6.8 复合索引
复合索引(也称为组合索引、联合索引或多列索引)是数据库索引的一种形式,它允许数据库系统根据两个或更多列的值来快速检索数据。与单列索引相比,复合索引可以更有效地处理那些经常基于多个列进行搜索、排序或分组操作的查询。
工作原理:
复合索引的创建方式是在表的多个列上定义一个索引,这些列的组合顺序在索引定义时指定。当数据库执行查询时,它会检查查询条件是否可以利用到复合索引。如果可以利用,数据库就会按照索引中列的顺序来检索数据,直到找到一个不满足条件的列或查询条件全部满足为止。
示例:
假设有一个名为employees的表,包含last_name、first_name和department_id三个列。如果经常需要根据员工的姓氏和名字来搜索员工,并且偶尔还需要根据部门ID来过滤结果,那么可以创建一个复合索引,如CREATE INDEX idx_employee_name ON employees(last_name, first_name, department_id);。这个索引将首先按照last_name排序,然后在每个last_name内按照first_name排序,最后在每个first_name内按照department_id排序。
6.9 索引最左匹配原则
索引的最左匹配原则(Leftmost Prefix Principle)是数据库索引优化中的一个重要概念,特别是在处理复合索引(联合索引或多列索引)时尤为重要。该原则的基本含义是,当数据库执行查询操作时,如果查询条件中使用了复合索引,那么索引的使用将遵循从左到右的顺序,即索引中的第一列(最左边的列)是查询条件中必须包含的,如果查询条件中只包含了索引的一部分列,并且这些列不是从索引的最左边开始,那么索引可能无法被有效利用。
具体内容:
列的顺序:复合索引中的列顺序至关重要。查询条件中必须包含索引的最左边列,否则索引可能不会被使用。例如,如果有一个(A, B, C)的复合索引,那么查询条件为A或A AND B或A AND B AND C时,都可以利用这个索引。但如果查询条件仅为B或B AND C,那么这个索引就不会被使用。
范围查询的影响:如果查询条件中包含了范围查询(如>、<、BETWEEN、LIKE等),那么范围查询右边的列将停止使用索引。例如,在(A, B, C)的复合索引上,查询条件A = 1 AND B > 2时,只有A和B会利用到索引,而C则不会。
优化器的自动调整:虽然查询条件中的列顺序需要遵循索引的最左匹配原则,但数据库的查询优化器会尝试自动调整查询条件中列的顺序以匹配索引,但这并不是总能成功的,特别是在复杂查询和涉及多个表连接的情况下。
应用场景:
复合索引的设计:在设计复合索引时,应该根据查询的实际情况来确定索引中列的顺序。通常,将选择性较高的列放在索引的最前面可以提高索引的效率。
查询优化:在编写查询语句时,应该尽量遵循索引的最左匹配原则,以充分利用索引提高查询性能。如果查询条件无法完全匹配索引的最左边列,可以考虑通过调整查询条件或创建额外的索引来优化查询。
索引维护:随着数据库数据的增加和查询模式的变化,可能需要定期审查和调整索引策略,以确保索引始终能够高效地支持查询操作。
6.10 索引覆盖
索引覆盖(Covering Index)是数据库索引优化中的一种重要技术,它指的是一个索引包含了查询所需的所有列,使得数据库在执行查询时能够直接从索引中获取所需的数据,而无需再回表到主表中获取额外的数据。
定义:索引覆盖是指索引上的信息足够满足查询请求,不需要再回到主键或数据表中去取数据。当查询可以完全利用索引中的数据满足查询需求时,就称之为索引覆盖。
原理:在数据库中,索引是用于加快数据检索速度的数据结构。通常情况下,当执行查询时,数据库需要根据查询条件在索引中找到匹配的行,并通过索引中的指针回表到主表中获取完整的数据。这个过程称为回表操作或二次查询。如果索引中已经包含了查询所需的所有列,那么就不需要进行回表操作,可以直接从索引中获取到所需的数据,这就是索引覆盖的原理。
实现方式:
联合索引:通过创建包含多个列的联合索引来实现索引覆盖。当查询条件中的列与联合索引中的列顺序一致,并且查询的字段全部包含在联合索引中时,就可以实现索引覆盖。
选择合适的列:在设计索引时,需要仔细考虑哪些列应该包含在索引中。通常,应该选择那些经常出现在查询条件、排序和分组操作中的列作为索引的组成部分。