Being-0——集操作、导航、运动为一体的机器人Agent框架:GPT4o高层感知并推理规划、低层VLM导航适配,最终执行技能库
前言
想让人形机器人真正在工厂里干好活,下肢运动、上肢操作、定位导航缺一不可,考虑到我司接到越来越多这方面的订单,故我对这块的前沿工作越来越关注,而非只是之前那般更多关注上半身操作
故本文来了,解读PKU、BAAI、BeingBeyond等机构的研究者(包括Haoqi Yuan、Zongqing Lu等9人),于25年3月联合推出的Being-0
- 其项目地址:beingbeyond.github.io/being-0
- 其paper地址《Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills》
而本文的价值在于,不管你是在原Being-0论文之前 先读的本文,还是在原Being-0论文之后 后读的本文,本文都会让你对Being-0的理解 更进一层或几层
PS,如正在做人形运动控制的,欢迎私我一两句自我简介(比如在哪个公司做什么,或在哪个高校的什么专业),邀你入交流群
第一部分 Being-0——集操作、导航、运动为一体的机器人Agent框架
1.1 提出背景与问题定义
1.1.1 提出背景
为了实现让类人机器人自主执行类似人类任务的最终目标
- 当前的研究主要集中在改进单项技能上,包括运动能力locomotion
Radosavovic等,2024-Real-world humanoid locomotion with reinforcement learning
Zhuang等,2024- Humanoid parkour learning
双手操作manipulation
Ze等,2024a,即iDP3,Generalizable humanoid manipulation with improved 3d diffusion policies

以及全身控制whole-body control
He等,2024a,即Omnih2o,详见此文《H2O与OmniH2O——全身远程操作且RL训练的人形机器人(含师生学习与策略蒸馏详解)》
Fu等,2024a,即Mobile aloha - 最近的研究中
Firoozi等,2023,即Foundation models in robotics: Applications, challenges, and the future
Hu等,2023,即 Toward general-purpose robots via foundation models: A survey and meta-analysis
机器人代理将基础模型(Foundation Models, FMs)与基于学习的机器人技能相结合,利用FMs在通用视觉语言理解中的能力,用于
Ahn等,2022,即Do as i can, not as i say: Grounding language in robotic affordances
Chen等,2024,即Commonsense reasoning for legged robot adaptation with vision-language models
Huang等,2022,即Inner monologue: Embodied reasoning through planning
with language models
虽然这些方法在为
机械臂(Liang等,2023-Code as policies: Language model programs for embodied control)
轮式机器人(Ahn等,2022-Do as i can, not as i say)
和四足机器人(Chen等,2024),即Commonsense reasoning for legged robot adaptation with vision-language models
构建代理方面取得了一些成功,但能否将同样的成功复制到人形机器人上?
在本文中,介绍了Being-0,一种为人形机器人设计的分层代理框架,总计三层:低层技能库、高层FM、中层连接器
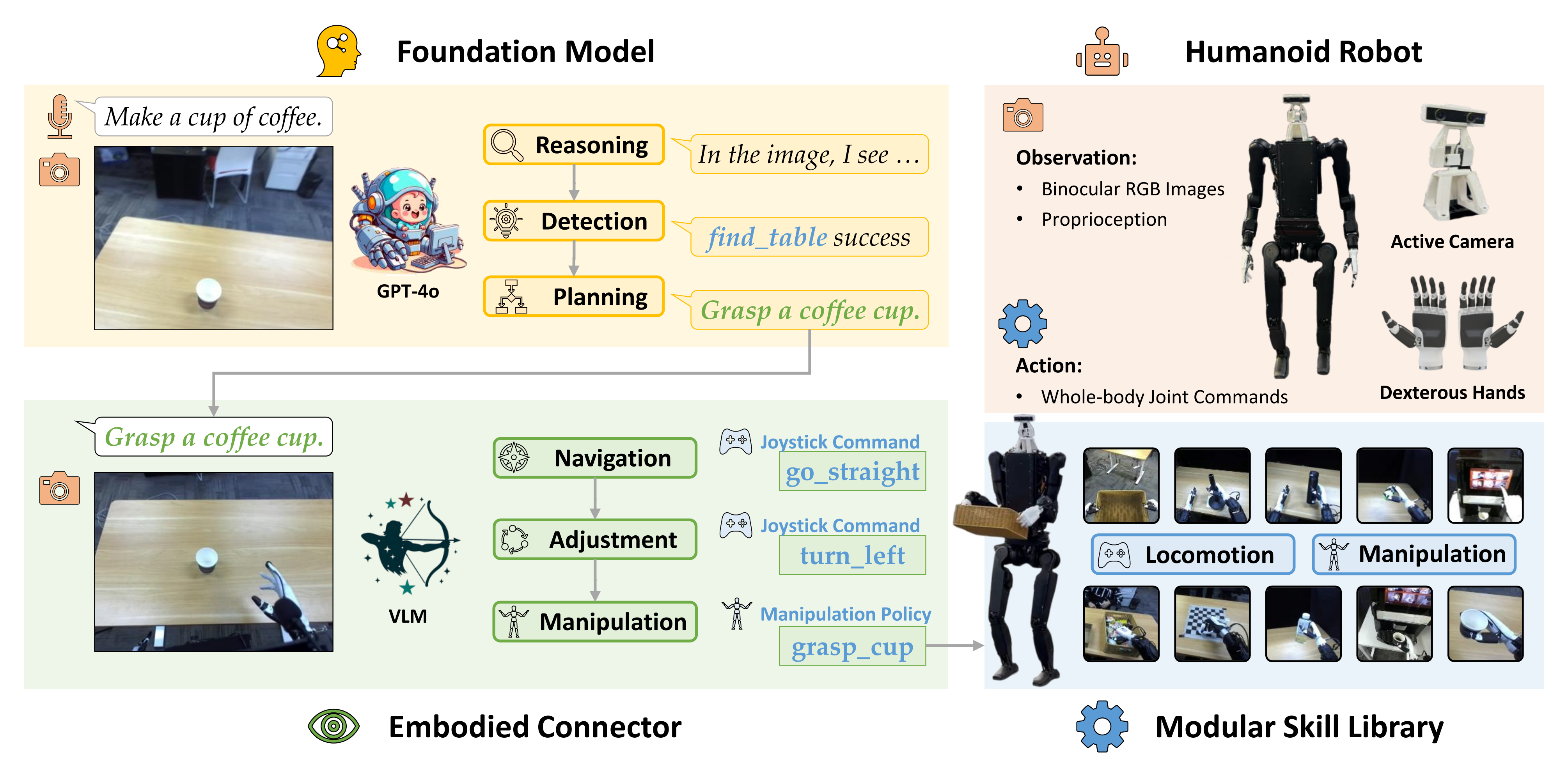
- 低层技能库
作者首先为一个基于通用 FM 的智能体框架「Tan 等人2024 年-Cradle: Empowering foundation agents towards general computer control(一个基于GPT-4o构建的代理框架)——下文的 “1.2.2 高层:基础模型Foundation Model” 还会再次提到」
配备了一个模块化的机器人技能库
We begin by equipping a universal FM-based agent frame-work (Tan et al., 2024) with a modular robotic skill library.
该技能库包含一个基于操纵杆指令的稳健移动技能,以及一组通过最先进的遥操作(Cheng 等人,2024 年 b-Opentelevision),和模仿学习(Zhao 等人2023 年-ALOHA ACT)方法获取的语言描述的操作技能
This skill library includes a robust locomotion skill basedon joystick commands and a set of manipulation skills withlanguage descriptions, acquired through state-of-the-art tele-operation (Cheng et al., 2024b) and imitation learning (Zhaoet al., 2023) methods.
这些技能使机器人能够根据语言指令行走和操作物体

- 高层FM,比如基于GPT-4o构建的代理框架
原则上,FM代理可以基于图像观测以闭环方式调用这些技能来解决长时间任务
然而,与轮式机器人不同,轮式机器人可以精确地遵循规划的导航轨迹并停在特定位置进行物体操作,而人形机器人在双足行走中面临固有的不稳定性
这种不稳定性要求频繁调整行走指令以进行误差修正
然而,现有的功能模型,例如 GPT-4o,在推理效率和具身场景理解方面存在局限性,这使得人形智能体在长时任务中导航和操作交替进行的阶段反应性较差且不够稳健
However, existing FMs, such as GPT-4o, suf-fer from limitations in inference efficiency and embodiedscene understanding, making humanoid agents less reactive and robust during the alternating phases of navigation and manipulation in long-horizon tasks. - 中层连接器(轻量级VLM)
为了解决这些挑战,作者提出了一个新颖的连接器模块,该模块作为Being-0中FM和技能库之间的中间层
具体而言,对于该中间连接器
- 其根据FM的语言计划和视觉观察,为运动和操作技能生成实时命令
将连接器建模为一种视觉语言模型(VLM),并使用带有语言指令、对象标签和边界框注释的第一人称室内导航图像对其进行训练
We model the Connector as a vision-language model(VLM) and train it using first-person images of indoor navi-gation annotated with language instructions, object labels,and bounding boxes. - 这种训练方案将视觉-语言导航数据中的具体知识提取到基于轻量级VLM的连接器中,从而实现准确的技能规划和更高控制频率下的高效导航
此外,为了无缝衔接导航和操作技能,连接器可以发送运动命令以调整人形机器人的姿态,从而改善后续操作任务的初始化状态
结果表明,通过在机载计算设备上部署所有模块(云端仅部署 FM),Being-0在导航方面的效率比完全基于 FM 的代理高出 4.2 倍——详见下文的2.1.3 消融研究:导航调整、主动视觉、效率
1.1.2 问题定义:先做任务拆解、后顺序执行
如下图图1所示,他们考虑一个具有41个自由度(DoFs)的仿人机器人,其中包括13个自由度的下半身(两条腿和一个躯干)、两只7自由度的手臂、两只6自由度的灵巧手以及一个2自由度的颈部
这些多指灵巧手使复杂且类似人类的操作成为可能,而配备了双目RGB摄像头的可动颈部则提供了主动视觉
一个自主代理旨在通过控制机器人的全身关节完成用自然语言描述的现实任务。形式上,在任何时候,代理都可以获取任务描述 ——例如“ 制作一杯咖啡 ”,并可以查询机器人的观测信息,包括
- 本体感知:
,其中
表示下半身、上半身和颈部的关节位置;
表示关节速度;
是从IMU 获取的根部速度和角速度
- 视觉输入:来自左摄像头和右摄像头的双目RGB 图像
代理可以采取动作,分别为下半身、上半身和颈部的PD控制器指定目标关节位置
考虑到人类在解决现实世界任务时,并不是直接将任务描述和观察映射到肌肉驱动上,而是依赖于一个分层系统
- 例如,任务 “制作咖啡” 首先会基于以往经验被分解为详细的计划,例如“找到一个杯子,抓住杯子,找到咖啡机……”——相当于先做任务拆解
- 接着,经过练习的运动技能,例如行走和抓取,被重新用于顺序执行
Huang等人2022年「Inner monologue: Embodied reasoning through planning with language models」通过将高层规划器与低层技能库集成的方法采用了这一方法,而Being-0旨在为人形机器人构建这样的代理
1.2 三层代理框架:高层GPT4o、中层连接器(VLM)、低层技能库
1.2.1 低层:模块化技能库
要解决的第一个挑战是:如何为人形机器人获取多样的、稳健的低层技能,以支持解决现实世界中的长远任务?
- 在关于全身控制的文献中「Fu等人2024a-Humanplus;He等人2024a-Omnih2o」,针对单个技能的策略通常将观察结果映射到全身目标关节位置,同时控制腿部运动和手臂操作——由于实现精确操作、稳定运动以及通过单一策略进行仿真到现实的部署的复杂性,现有方法尚未发展出广泛的操作技能
- 对于大多数任务,下半身和上半身具有不同的功能:下半身主要用于导航,而上半身用于操作「Cheng等人2024a,即Exbody」
这一观察促使我们开发分别用于稳定下半身运动和上半身操作的技能,毕竟最近的进展「Kim等人2024-Openvla;Cheng等人2024b-Opentelevision」,已证明在固定下半身的情况下获取丰富的上半身操作技能的可行性
首先,如何使用操纵杆命令实现稳定运动呢
- 想让对应的运动技能控制下肢关节,必须能够实现多方向导航并在操控任务期间保持稳定站立
对此,作者采用强化学习RL方法「Ha et al., 2024-Learning-based legged locomotion: State of the art and future perspectives」来训练
_______
先在仿真中使用条件本体感知策略(Makoviychuk等,2021- Isaac gym: High performance gpu-based physics simulation for robot learning),然后以50 Hz的控制频率进行仿真到现实的部署
其中,表示操纵杆的速度命令。通过在仿真期间引入域随机化和外部力,此技能使机器人能够根据操纵杆命令行走,同时保持平衡
- 为了将其集成到技能库中,作者基于不同的操纵杆命令定义了一组运动技能,以及用于主动视觉的头部调整技能:{无动作,直行,后退,左转,右转,左侧步,右侧步,头部倾斜,头部转动}
其次,如何进一步获取操控技能呢
远程操作和模仿学习已成为以低成本获取多样化机器人操控技能的有希望的方法「Teleoperation and imitation learning have emerged as promising approaches for acquiring diverse robotic manipulation skills at low cost」
为了为人形机器人(该机器人配备两只灵巧的手和主动视觉)收集高质量、类人的操作数据,采用苹果 VisionPro 进行遥操作,这与近期的研究「Cheng等2024b-Opentelevision」相一致
- 双目图像观测结果或投影到 Vision-Pro 上,所捕捉到的人类头部、手腕和手指的动作以10 Hz的控制频率重新定位到机器人动作上
Binoc-ular image observations ol, or are projected to the Vision-Pro, and the captured human motions of the head, wrists,and fingers are retargeted to robot actions at a control fre-quency of 10 Hz
对于每项技能,都记录了遥操作轨迹
其中包括机器人观测值和动作(不包括下身动作) - 接着,使用 ACT「Zhao等人2023,即ALOHA ACT,详见此文」来训练与诸如“抓取瓶子”之类的语言描述相关联的每种操作技能
的策略
We use ACT (Zhao et al., 2023), a behavior-cloning method with a Transformer architecture, to train the pol-icy πMi �[auj , ahj ]t+Kj=t |olt, ort, qut , qht�for each manipulationskill Mi, associated with a language description such as“grasp bottle”.
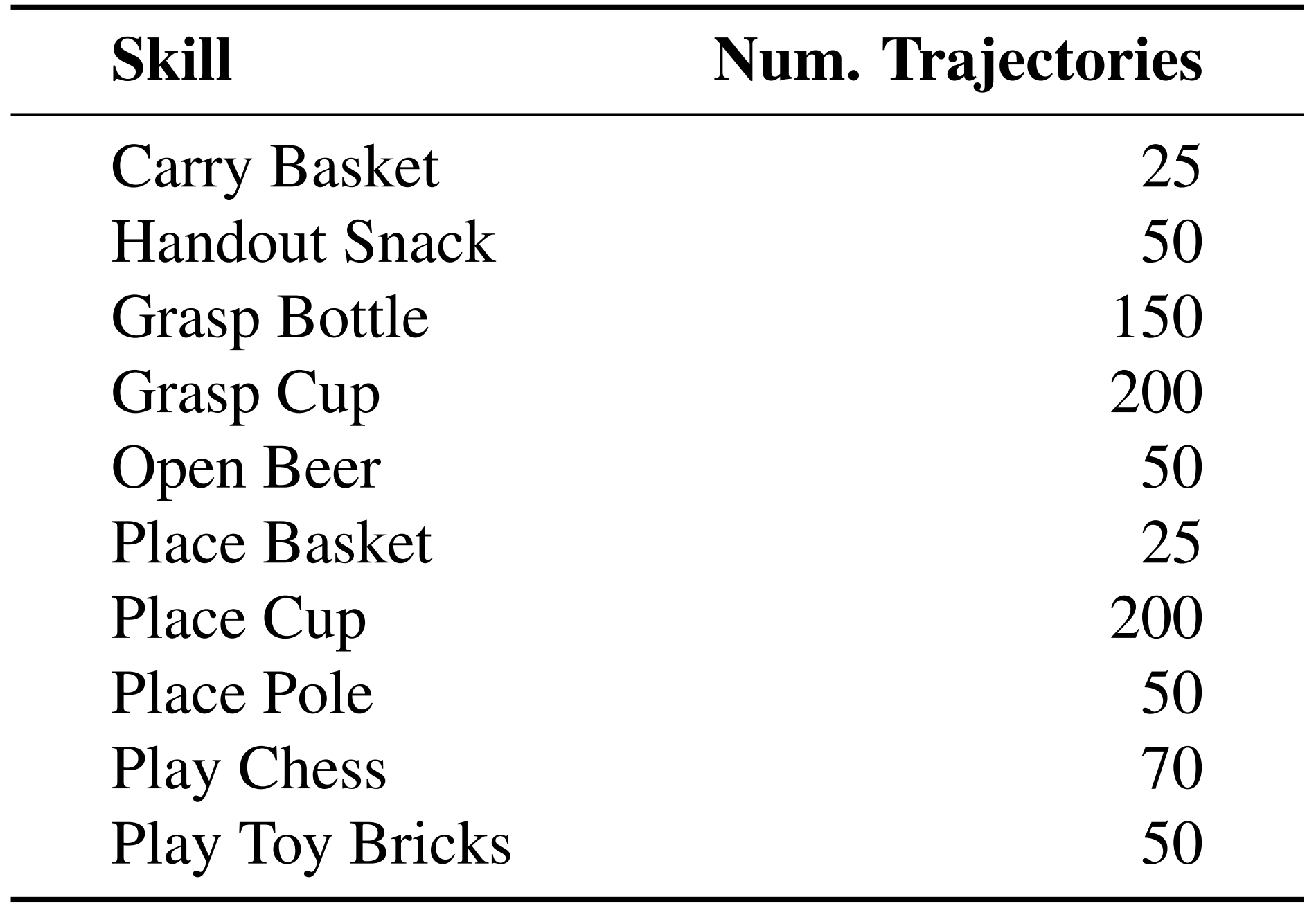
在训练期间,预测动作序列的长度 K 设为 30,在部署期间设为 10。这种方法确保了技能库的可扩展性,因为新技能可以通过 50 至 150 条轨迹获得,所需远程操作时间不到 1 小时
- 首先,表8展示了通过远程操作收集的各项技能成功轨迹数量
- 其次,在各项技能的ACT策略中,作者采用在ImageNet上预训练的ResNet-50主干网络处理双目图像
为增强对视觉扰动的鲁棒性,采用了随机裁剪、旋转及颜色抖动等数据增强方法
包括预训练编码器在内的整个模型均在训练过程中进行更新
表9列出了训练ACT所用的超参数

1.2.2 高层:基础模型Foundation Model——Cradle(基于GPT-4o构建的代理框架)
由于高级规划器会经常在各种任务和环境中进行技能级别的决策,使得其需要在通用的视觉-语言理解和推理方面具有强大的能力
- 好在基础模型(FMs)在这些领域表现出色,并且在最近关于人工智能代理的研究中被广泛采用
Wang等人,2024-A survey on large language model based autonomous agents
Tan等人,2024-Cradle: Empowering foundation agents towards general computer control
其项目地址为:baai-agents.github.io/Cradle
其GitHub地址:github.com/BAAI-Agents/Cradle
例如,Cradle「Tan等人,2024」,一个基于GPT-4o构建的代理框架,已经成功应用于开放世界游戏和软件使用,基于图像观察操作键盘和鼠标技能 - 受该工作的启发,作者调整了Cradle框架以构建一个通用的人形机器人代理,使机器人能够从技能库中操作技能并解决现实世界中的任务
具体而言,给定一个指令和图像观察,FM(GPT-4o)执行决策的三个关键功能:
- 推理:FM生成对观察到的图像和指令的描述,有助于任务理解和识别当前执行阶段
- 检测:FM评估最近执行技能的成功情况,识别失败和异常以便于任务规划
- 规划:基于推理和检测结果,FM从技能库中选择下一个要执行的技能。FM的详细提示设计可以在附录B.3中找到
然事情总不是一帆风顺的,当直接将FM与技能库集成时,作者们遇到了几个严重阻碍系统性能的挑战
- 双足运动的固有不稳定性使得人形机器人的位置在短时间行走后变得不可预测,这需要频繁调整操纵杆命令,而不是执行开环指令序列
The inherent instability of bipedal lo-comotion makes the humanoid’s position unpredictable aftershort periods of walking, necessitating frequent adjustmentsto joystick commands rather than executing open-loop com-mand sequences - 此外,现有的FM(包括GPT-4o)在准确的3D场景理解方面存在困难,常常无法正确估计导航目标的方向和深度,这可能导致错误的技能规划
参见下图图3中的实验结果——在长期任务“准备咖啡”中,对未配备连接器的 Being-0 与配备连接器的 Being-0 进行对比
其中,第一行展示了未配备连接器的 Being-0 的记录,而第二行则展示了配备连接器的 Being-0 的记录。未配备连接器的 Being-0 经常向 FM 查询,但由于其对所处场景的理解有限,FM 往往无法提供正确的计划。相比之下,配备连接器的 Being-0 能够完成任务,仅需向 FM 进行少量查询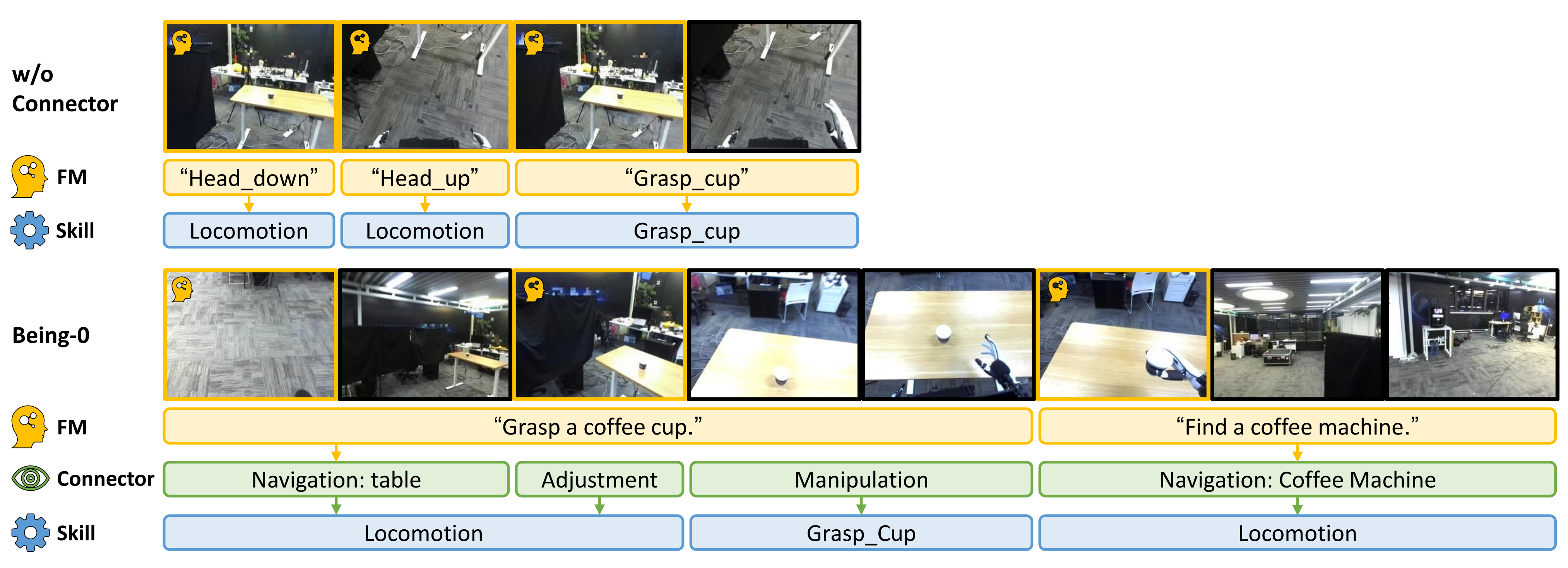
- 即使代理成功导航到目标位置(例如,一张桌子),其最终站立位置可能无法为后续的操作技能(例如,“抓取杯子”)提供合适的初始状态,从而导致任务失败
见下图图5「Being-0在涉及导航和操作的两阶段任务中,使用和不使用调整方法的比较。每一行对应一个特定任务,左侧三张图显示了未使用调整方法的Being-0的结果,右侧三张图显示了使用调整方法的Being-0的结果。在未使用调整方法的情况下,代理可能会以不正确的姿势结束导航,导致操作失败」

- 此外,大型FM的低推理速度显著降低了系统效率,使机器人移动缓慢且对动态环境的反应不够及时
然功夫不负有心人,为了解决这些挑战,他们在Being-0中提出了一种新颖的连接器模块,该模块弥合了FM与技能库之间的差距,增强了实时的具身决策能力
1.2.3 中层:具身连接器(轻量级VLM)——上连GPT4o、下连低层技能库
连接器的主要目标是将由任务规划器生成的基于高级语言的任务计划,可靠且高效地转换为可执行的技能指令「The primary goal of the Connector is to translate high-level language-based plans generated by the FM into executables kill commands reliably and efficiently」
- 连接器的核心是一个基于注释导航数据训练的轻量级视觉语言模型(VLM),它增强了代理的具身能力
At the core of theConnector is a lightweight vision-language model (VLM)trained on annotated navigation data, which enhances theagent’s embodied capabilities. - 该 VLM 实现了多项下游功能,包括基于场景的技能规划、闭环导航以及在长时任务执行期间导航与操作之间的平滑过渡
This VLM enables severaldownstream functionalities, including grounded skill plan-ning, closed-loop navigation, and improved transitions be-tween navigation and manipulation during long-horizon taskexecution
1.3 二谈中层:具身连接器(轻量级VLM)的训练、规划
1.3.1 视觉-语言模型VideoLLaMA2:先感知环境、后拆解任务
为了使VLM具备空间和对象理解能力,以及根据上下文预测未来技能的能力,作者在一个包含第一人称导航图像的数据集上对其进行训练。这些图像附有语言描述、技能、对象标签和边界框的注释
- 且最终采用VideoLLaMA2「Cheng et al., 2024c-Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms」作为主干架构——其使用图像观察和文本指令作为输入
该模型通过多任务学习进行优化,包括图像描述、技能预测和目标检测 - 训练后的视觉语言模型(VLM)在所有任务中,在板载设备上的平均推理时间约为1秒,显著优于云服务上的GPT-4o的延迟
有关数据集和训练过程的更多详细信息,请参见附录B.2
具体而言,数据集包含两类主要任务:视觉理解VLU任务和动作规划AP任务
一方面,对于视觉理解,训练好的模型通过生成边界框坐标来预测图像中目标对象的边界框,若无目标对象则输出“None”。 视觉语言模型的视觉理解能力为机器人提供了环境的具体信息,使其能够有效导航,并为合理的技能规划决策奠定基础
二方面,视觉理解任务包括边界框检测、是/否问答以及图像描述
- 他们共收集了3,177个样本,图像共计3,177张,其中2,483张用于视觉理解任务,694张用于动作规划任务
其中
图像描述任务最初由GPT-4o标注,随后由人工标注员进行校正以确保准确性- 视觉理解标注任务的示例见表10,涉及边界框、物品识别、图像描述、
描述地面并识别其过渡
表11汇总了各类任务的样本数量
表12和表13分别展示了边界框任务和是/否任务的数据统计情况
此外,为提升视觉定位能力,他们还引入了一个通用视觉定位数据集。从三个开源视觉定位数据集中筛选出30万条数据样本(Krishna et al., 2016;Tian et al., 2024;Shao et al., 2024)。 这些数据在训练他们的VLU和AP数据集之前输入模型



进一步而言,作者基于VideoLLaMA2框架,采用多节点分布式训练策略,对视觉-语言模型进行了微调
- 训练采用全局批量大小128,每个设备本地批量大小为2,梯度累积步数根据节点数量及每节点处理单元动态计算
模型训练了三个epoch,学习率为 2 × 10−5,使用余弦学习率调度器,预热比例为0.03。优化器采用AdamW,权重衰减为零 - 为提升计算效率,启用了bfloat16(BF16)与TensorFloat32(TF32)混合精度训练
且采用梯度检查点技术以降低内存消耗,最大序列长度设定为4096个token - 视觉编码器基于SigLIP
投影模块则采用多层感知机MLP实现
且根据模态长度对多模态样本进行分组,选取倒数第二层的视觉特征,并通过图像填充保持宽高比
每个样本包含16帧图像
总之,整体训练过程分为两个阶段
- 首先,基于VideoOrion+(Feng et al., 2024)提供的检查点,对筛选后的30万条通用视觉定位数据集进行微调,该模型架构与VideoLLaMA2相同,但具备更优的面向对象理解能力
考虑训练效率,对VideoOrion进行了修改,去除了面向对象的分支 - 随后,使用包含视觉语言理解(VLU)任务和动作规划(AP)任务的自采集数据集对模型进行微调
该训练方案确保了高效的视觉语言建模,结合优化的数据处理、节省内存的技术及分布式计算以提升性能
1.3.2 基于场景的技能规划:在环境下的物理约束中拆解「高层GPT4o」给的任务规划
VLM 的主要用途是将 FM 的基于语言的计划和实时图像观测转换为可执行的技能计划,例如导航目标或操作技能
通过利用其对相对 3D 物体位置的更深入理解,VLM不仅将功能模型的计划转化为可执行的技能,而且在必要时对其进行修正或完善
- 例如:如果 FM 生成了“抓住杯子”的计划,但机器人仍然离桌子很远
VLM 会将“抓住杯子”解释为一个长期目标,并输出可行的技能(例如,“向前移动(桌子)”) - 反之,如果 FM 计划“寻找桌子”,但机器人已经在桌子旁边,VLM 的导航功能(很快,下一节1.3.3节 会详述)会向FM 发出成功信号,促使其通过推理进入下一个技能
这种能力确保计划的技能与物理环境保持一致,从而减少错误并提高任务成功率
针对技能规划
- 给定整体任务与子任务,模型预测机器人应执行的适当技能代码,该代码来源于模块化技能库或复合导航技能。技能规划通过使模型基于环境中对象的存在、相对距离及位置做出决策,促进空间及具身知识的获取
- 通过训练,模型学会评估这些空间关系,并根据目标对象的距离和朝向选择合适的技能,如导航与操作。该具身理解使机器人能够实时调整动作,确保将高层任务指令准确转化为符合上下文的具体可执行技能
1.4 三谈中层:具身连接器如何完成视觉导航任务:先向目标移动(含搜索)、后调整姿态
1.4.1 使用运动技能进行视觉导航
为了使机器人能够到达视觉导航目标(例如一张桌子),连接器利用视觉语言模型(VLM)的视觉理解和物体检测能力「To enable the robot to reach visual navigation goals (e.g.,a table), the Connector leverages the VLM’s visual under-standing and object detection capabilities」
- 当目标物体在机器人视野范围内时,连接器使用检测到的边界框和双目图像的合成深度来估计其相对位置
When the goalobject is within the robot’s field of view, the Connector esti-mates its relative position using the detected bounding boxand synthetic depth from binocular images
基于此估计,VLM 选择最合适的运动技能向物体方向移动
Based on this es-timation, the VLM selects the most appropriate locomotionskill to move towards the object’s direction.
可将“向目标移动”定义为帮助机器人导航至视野中目标对象的技能。该技能利用视觉语言模型生成的边界框来判断目标对象的角度及其是否存在,该技能的伪代码如算法1所示

- 如果物体不可见,VLM 触发探索程序,结合运动技能和主动相机移动来搜索目标。这种方法与固定相机的系统相比,显著提高了机器人定位物体的能力。实现细节见附录 B.2
If the object isnot visible, the VLM triggers an exploration routine, com-bining locomotion skills with active camera movements tosearch for the goal. This approach significantly enhancesthe robot’s ability to locate objects compared to systemswith fixed cameras. Implementation details are provided inAppendix B.2.
通过将 VLM 的高效推理能力与模块化运动技能相结合,此方法加快了人形机器人导航速度,同时在动态环境中保持了稳健性
By integrating the VLM’s efficient inferencecapabilities with modular locomotion skills, this methodaccelerates humanoid robot navigation while maintainingrobustness in dynamic environments.
可将搜索技能定义为持续向一个方向转动,直到视野中发现目标对象。该技能利用视觉-语言模型生成的边界框判断目标对象的存在。该技能的伪代码如算法2所示

1.4.2 协调导航与操作——比如通过调整机器人的姿态
为了解决导航过程可能以不利于后续操作技能的次优姿态结束这一挑战——To address the challenge that navigation processes may ter-minate in suboptimal poses for subsequent manipulation skills
- 作者提出了一种使用视觉语言模型(VLM)的姿态调整方法。即在导航过程中,VLM 不仅预测物体的边界框,还预测机器人相对于物体的位置的最佳对齐方向
- 如果机器人的当前朝向与该对齐方向存在偏差,VLM将触发一个复合技能,结合头部旋转和前进运动来调整机器人的姿态。这使机器人能够沿弧形路径接近目标物体,确保其达到一个适合操作的最佳位置。更多细节见附录B.2
为实现导航过程中的调整
- 作者对前进技能进行了修改,使机器人先将头部转向目标物体所在方向的侧面,再根据调整后的视角决定转向或继续前进侧头方向由视觉语言模型预测
- 该方法使机器人能够沿弧形路径逐步接近目标对象,最终达到最优位置,该技能的伪代码如算法3所示

下图图2展示了Being-0的工作流程,重点突出了Connector模块的作用

总之,该具身Connector为执行长时间跨度任务提供了几个关键优势,其通过利用轻量级视觉语言模型(VLM),连接器确保了实时响应能力,使机器人能够动态适应环境变化
- 这种实时能力对于高效任务执行至关重要,因为连接器能够动态选择和排列模块化技能,显著降低操作延迟
与功能模块(FM)不同,VLM 增强的空间理解能力使机器人能够准确感知并响应周围环境,将基于抽象语言的计划与实时视觉输入相结合
这种空间推理能力在复杂任务中尤为宝贵,连接器的稳健性确保了其能够适应意外障碍或环境变化- 此外,连接器通过调整机器人的姿态来促进导航和操作之间的平滑过渡,确保机器人到达后续技能所需的正确位置
这些特性共同使具身连接器成为 Being-0 的基石,使其能够应对复杂环境中需要导航和操作的具有挑战性的长期任务
第二部分 一系列实验、相关工作
2.1 实验
2.1.1 真实世界设置
作者在一台 Unitree H1-2 人形机器人上进行实验用于颈部运动的namixel电机,以及安装在颈部用于主动视觉的ZED-mini摄像头
- NVIDIA Jetson AGX板载设备用于部署连接器和所有模块化技能
- 作者的实验环境是一个大型办公室场景,覆盖了20×20(米)的区域,包含多个办公隔间、一张木桌、一台咖啡机,以及连接接待室和会议室的走廊
- 为了构建操作技能库,作者收集了多种日常操作任务的数据,包括单手和双手的任务,例如抓取和放置物品,操作装有物品的篮子、使用咖啡机、以及玩玩具积木和国际象棋游戏
数据收集和训练细节在附录B.1中给出
作者评估了智能体在一组多样化的长时间任务上的表现,这些任务旨在测试系统在任务规划和技能执行方面的鲁棒性。这些任务包括:
- 取瓶并送篮任务:这些任务要求机器人导航到一个遥远的木桌并执行操作任务
- 准备咖啡、制作咖啡和递送咖啡:这些是特别具有挑战性的任务,由多个子任务组成,包括精确的操作技能,例如按下咖啡机上的按钮以及将杯子放置在正确的位置
有关任务设置的更多详细信息,请参见附录A.3
2.1.2 解决长时间范围的具体任务
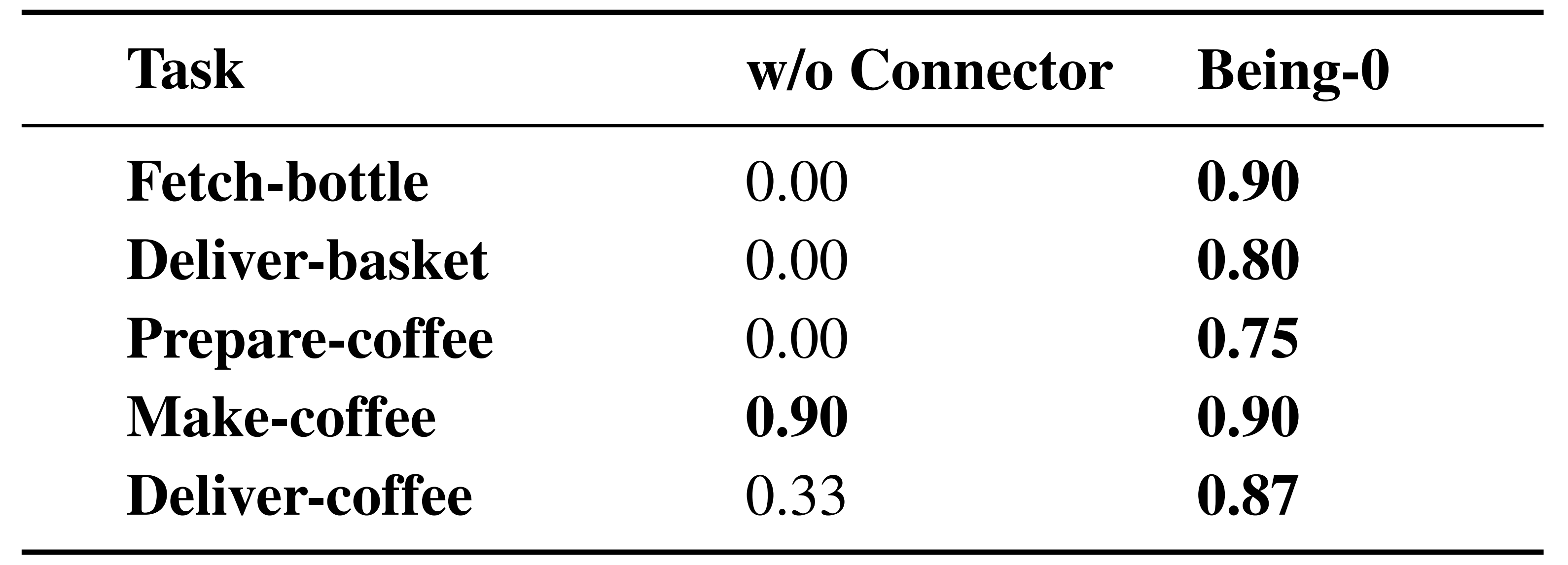
我们评估了 Being-0 在长时序具身任务中的表现,主要结果见表 1「在各种长周期任务中,有无连接器的 Being-0 的任务完成率。结果表明,使用连接器时性能有显著提升」
这些任务旨在测试机器人在现实环境中执行复杂技能序列的能力,需要高级认知与低级技能之间进行精准协调
结果表明,当使用连接器Connector模块时,性能显著提升,特别是在需要多步骤和整合不同技能的任务中
- 例如,在取瓶任务中,基线系统(没有连接器)得分为0.00,而带有连接器的系统得分达到显著的0.90
- 同样,在递送篮子和准备咖啡等任务中,性能也有显著提升,从0.00分别提高到0.80和0.75
这些发现突出了连接器在使机器人有效完成长时间任务中的关键作用。通过弥合功能模块与技能库之间的差距,连接器提高了任务成功率,特别是在需要复杂、顺序技能的场景中
总体而言,结果证实了Being-0在执行长视距任务方面具有高度的能力,并表现出稳健和可靠的性能
2.1.3 消融研究:导航调整、主动视觉、效率
第一,对于导航调整
作者评估了所提出的涉及导航然后操作的两阶段任务。在此设置中,操作任务的成功率直接反映了机器人在导航后终止状态的质量
表2展示了比较Being-0有和没有调整的结果
- 对于抓取任务,例如抓取瓶子和抓取咖啡,使用调整的Being-0显著优于消融基线,成功率提高了超过0.4。这种改进可以归因于机器人能够在有利于抓取的位置终止导航
- 没有调整时,机器人可能停得离物体太远,或者将物体放置在抓取手后面,导致后续的抓取技能失败(见下图图5)
- 将任务放置在桌子上,包括放置篮子和放置咖啡(t),对调整的敏感度较低。这是因为只要机器人到达桌子,它就可以成功地放置物体,而无需考虑其相对于桌子的站立姿势
然而,对于放置咖啡(m),需要将杯子放置在可用面积非常小的咖啡机上,带有调整的Being-0表现显著更好
这些结果表明,所提出的调整方法在顺序导航和操作任务中提高了性能,特别是在操作任务中,成功率很大程度上取决于机器人相对于物体的初始状态
第二,对于主动视觉
主动摄像头是他们系统的核心硬件组件,显著增强了机器人在各种技能上的灵活性。他们进行了一个消融研究,以评估Being-0在使用具有不同俯仰角的固定摄像头与主动摄像头时的性能差异
且鉴于相机的俯仰角会影响导航和操作性能,作者在不同角度的固定相机设置下测试了代理
表3展示了在不同任务中的结果
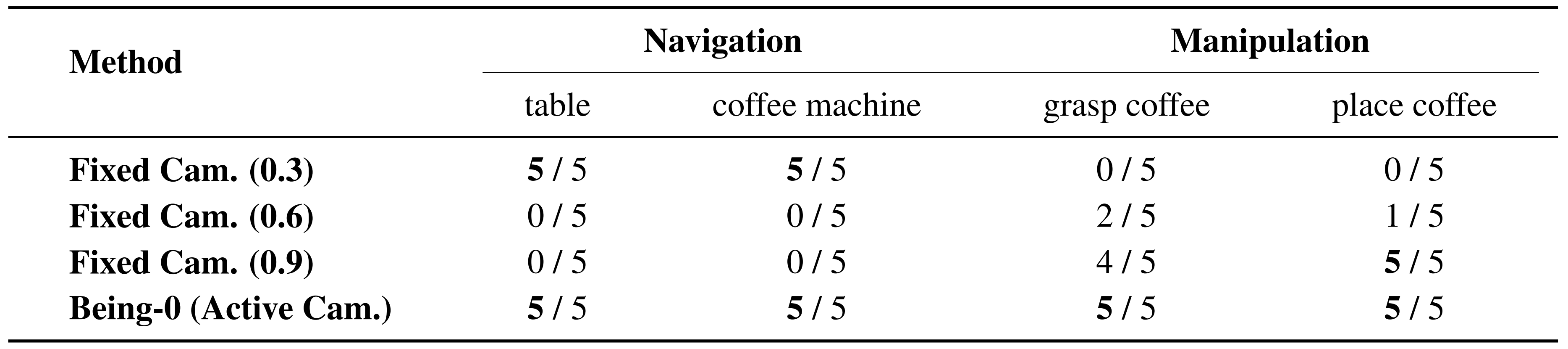
- 对于导航任务,作者观察到较小的俯仰角「固定相机 (0.3)」表现良好,而较大的俯仰角会导致失败。这是因为具有较大俯仰角的相机主要观察地面,导致代理无法看到导航目标
- 相比之下,对于桌面操作任务,较高的俯仰角提高了成功率,因为机器人需要向下看以定位桌面上的物体。然而,没有固定的相机配置能够同时在导航和操作任务中达到高成功率
- 相比之下,配备主动相机的Being-0在所有任务中始终实现了完美的成功率。这些结果突出了主动相机的显著优势,使机器人能够动态调整其视野以满足各种任务的需求

第三,对于效率
Being-0 展现了显著的优势连接器模块。为了评估这一点,作者对任务“导航到木桌”进行了消融研究,结果如表4所示「该表报告了不同代理配置的平均移动速度(厘米/秒)和成功率」

- 结果表明,配备连接器的Being-0在移动速度上比没有连接器的配置提高了4.2倍,同时达到了5/5的完美成功率
- 相比之下,没有连接器的代理始终无法到达远距离目标。这是因为单独使用GPT-4o经常在规划移动方向时出错,导致导航路径效率低下或不正确
这些发现突出了连接器模块在提升Being-0框架效率方面的关键作用
2.1.4 稳健性与可扩展性:评估导航、操作技能
首先,对于导航
为了评估 Being-0 在导航方面的稳健性,作者在各种场景配置和任务中对其进行了测试。结果如表5所示,表明 Being-0在所有设置中始终实现了高成功率

- 在同一房间内导航到目标时,Being-0 达到了1.0 的完美成功率。当适应带有障碍物的未见布局时,其性能仍然很强,仅出现了 0.2 的成功率下降
- 此外,Being-0 成功地完成了跨房间导航任务,达到了 0.83 的高成功率。这些任务需要FM 进行多步推理和规划。例如,为了找到接待桌,机器人必须首先识别并导航到房间的出口,然后继续前进
其次,对于操作技能
表6展示了性能在处理未见过的物体或遇到视觉扰动时,性能略有下降,展示了所学操作策略的鲁棒性和泛化能力
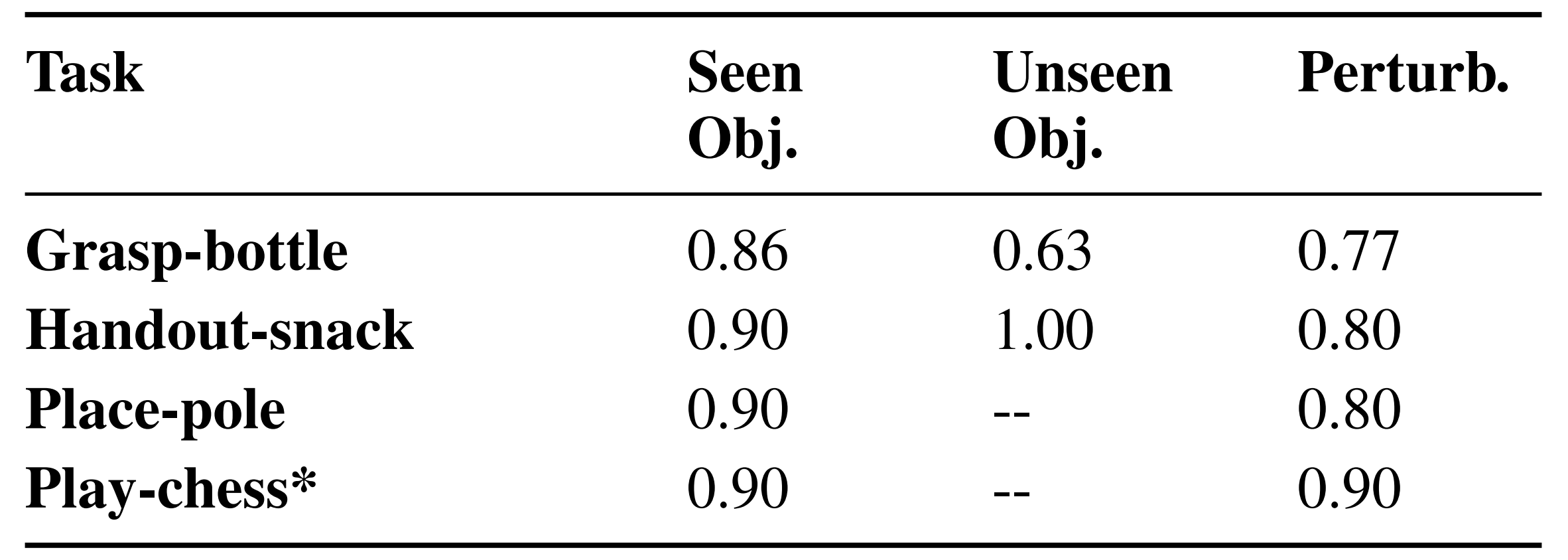
此外,用于获取操作技能的同一框架可以扩展到配备触觉传感器的灵巧手(表6中的下棋任务)以及需要精确操作小物体的任务(见图6),展示了技能库的可扩展性——支持更复杂和更具挑战性的操作任务

2.2 相关工作
2.2.1 人形机器人行走和操作
人形机器人(Goswami &Vadakkepat,2018;Gu et al.,2025)被认为是适合人类设计环境的理想形态,其中行走和操作是基本技能
对于行走
- 早期的方法侧重于使用最优控制进行行走
Miura & Shimoyama,1984,Dynamic walk of a biped
Dariush etal.,2008,Whole body humanoid control from human motion descriptors
Wensing et al.,2023, Optimization-based control for dynamic legged robots - 而最近的进展通过强化学习RL和sim-to-real技术
Ha et al.,2024,Learning-based legged locomotion: State of the art and future perspectives
且成功地训练了行走策略,实现了在平地上的稳健行走
Xie etal.,2020,Learning locomotion skills for cassie: Iterative design and sim-to-real
包括复杂地形
Siekmann etal.,2021,Blind bipedal stair traversal via sim-to-real reinforcement learning
Radosavovic et al.,2024
Li et al.,2024b, Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
以及高级跑酷技能
Zhuang et al.,2024,Humanoid parkour learning
对于操作,尽管基于RL的方法(Yuan et al.,2024;Huanget al.,2024)面临显著的模拟到现实间隙
- 基于模仿学习的遥操作数据的方法由于其简单性和有效性成为主流
研究探索了多种遥操作方案,利用
VR
Cheng et al.,2024b,Opentelevision
外骨骼
Fu etal.,2024b,Mobile aloha
Yang et al.,2024,Ace: A cross-platform visualexoskeletons system for low-cost dexterous teleoperation
或摄像头
Fu etal.,2024a,Humanplus - 改进的模仿学习方法,如
Diffusion Policies
Chi et al.,2023,Diffusion policy
Ze et al.,2024b;a
和ACT
Zhao et al.,2023,即ALOHA ACT
进一步提升了训练性能
最近,整身控制
- Fu et al.,2024a,Humanplus
- He etal.,2024a;b,即 Omnih2o、Hover
- Ji et al.,2024,Exbody2
因其在单一策略中整合行走和操作的能力而受到关注
然而,由于两个领域的复杂性结合,这仍然是一个挑战
2.2.2 具身代理
具身代理(Firoozi 等人,2023;Hu 等人,2023)在机器人领域不仅需要低级技能,还需要在高层次决策中具备强大的常识推理能力
最近的研究探讨了利用基础模型(Foundation Models,FMs)构建具身代理的两种主要方法
- 第一种方法是直接将预先在互联网规模数据集上训练的现有基础模型应用于机器人任务,而无需额外的微调。这些模型利用其强大的通用视觉语言理解能力用于执行具身任务的能力,例如规划
Ahn 等,2022, Do as i can, not as i say
Yuan 等,2023,Skill reinforcement learning and planning for open-world long-horizon tasks
Chen 等,2024,Commonsense reasoning for legged robot adaptation with vision-language models
Kannan等,2024,Smartllm: Smart multi-agent robot task planning using large
language models
和推理
Huang 等,2022,Inner monologue: Embodied reasoning through planning with language models
Zhang 等,2023a,Creative agents: Empowering agents with imagination for creative
tasks
Liu 等,2024b,Rl-gpt: Integrating reinforcement learning and code-as-policy
这些方法通常依赖于预定义的技能库来进行低级别的执行 - 第二种方法关注于使用大量的机器人数据集来训练机器人基础模型(FMs)。值得注意的工作包括机器人transformer
Brohan 等,2022;2023,即RT-1、RT-2
视觉-语言-动作(VLA)模型
Jiang 等,2022, Vima:General robot manipulation with multimodal prompts
Kim 等,2024,Openvla
Team 等,2024,Octo
Liu 等,2024a,Rdt-1b
Black 等,2024,π0
Cheang 等,2024,Gr-2
以及视频-语言规划模型
Yang等,2023,Learning interactive real-world simulators
Du 等,2023, Video language planning
尽管这些方法对于配备夹爪的机械臂已显示出前景,但针对人形机器人(尤其是那些拥有灵巧双手和主动摄像头的人形机器人)的大规模数据集的缺乏,仍然是开发人形机器人功能模型的一个重大障碍
2.2.3 视觉-语言模型VLMs:本Being-0中用的VideoLLaMA2
基于大型语言模型(Achiam et al., 2023)的显著成功,发展了多模态理解和推理的能力
最近的进展包括文本-图像VLMs
- Alayrac et al., 2022,Flamingo: a visual language model for few-shot learning
- Chen et al.,2023,Minigpt-v2
- Li et al., 2023,BLIP-2
- Bai et al., 2023,Qwen-vl
- Liu etal., 2023,Visual instruction tuning
和文本-视频VLMs
- Zhang et al.,2023b,Video-llama: An instructiontuned audio-visual language model for video understanding
- Shu et al., 2023,Audiovisual llm for video understanding
- Maaz et al., 2024,Videochatgpt: Towards detailed video understanding via large vision and language models
- Jin et al., 2024,Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization
的开发
在本Being-0的工作中,作者利用开源的VideoLLaMA2「Cheng et al., 2024c-Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms」来训练人形代理中的连接器模块,从而提高效率并使决策过程更贴近实际任务
第三部分 prompt设计与制作咖啡的示例
3.1 prompt设计
3.1.1 使基础模型实现多层次智能体能力的提示设计:信息收集、进度跟踪、反思评估
- 首先是信息收集流程采用的提示模板

- 其次是用于总结任务进度并提出新子任务的提示模板

- 再其次是用于任务反思和成功评估的提示语

3.1.2 使用具身连接器时的动作规划提示:决策制定、动作执行
- 首先是人形机器人任务中决策制定与行动执行的提示
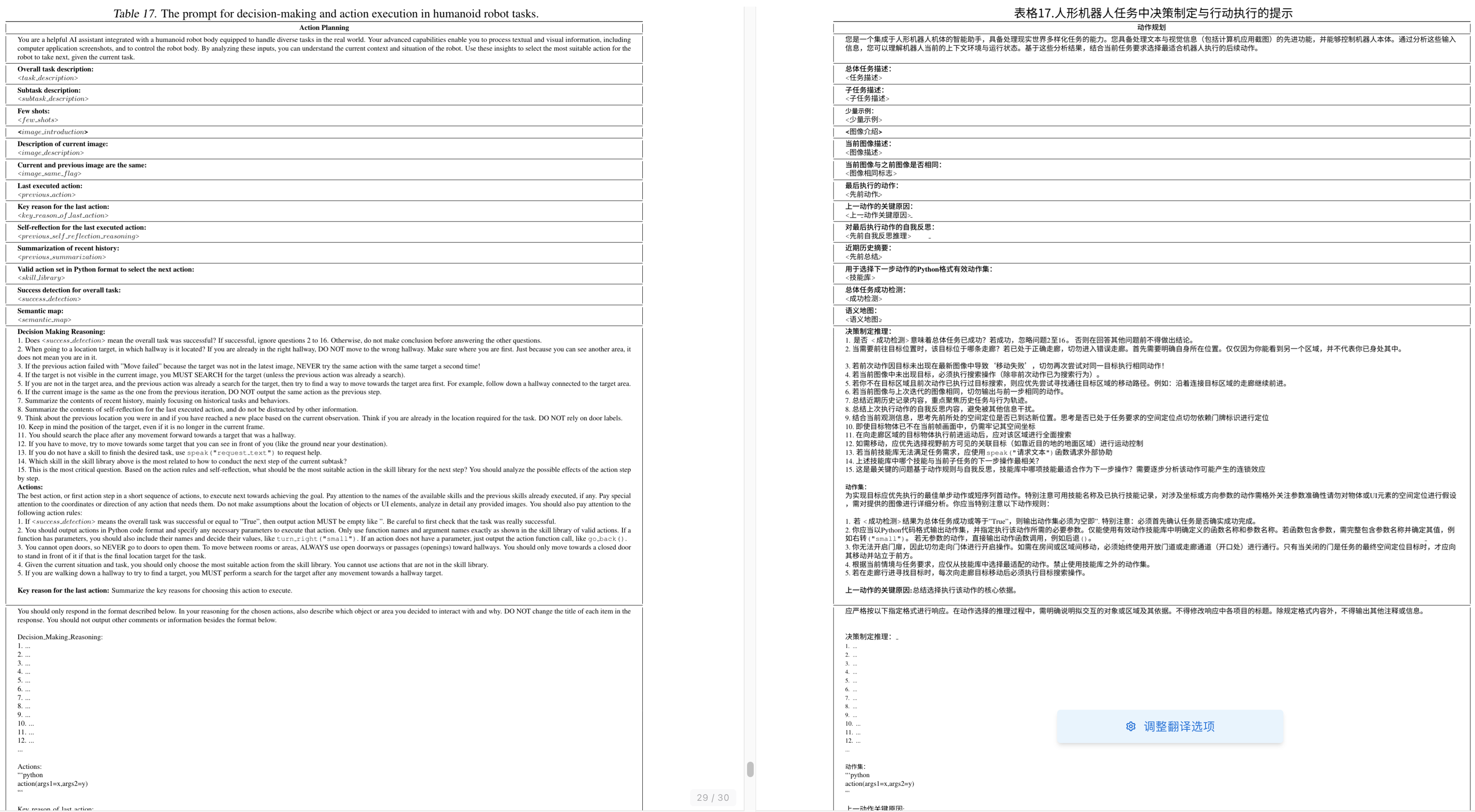
- 其次是用于人形机器人决策与动作执行的简化版提示模板

3.2 让人形机器人制作咖啡的全流程:基础模型规划轨迹
3.2.1 导航到带杯子的桌子旁
目标任务是从桌子上取一个杯子并从咖啡机获取咖啡,故当前子任务是搜索机器人实验室以定位带杯子的木制桌子
从下图的第二个子图可以看出,整体任务尚未完成,因为机器人虽已成功移动至带杯子的桌子旁,但仍需抓取杯子并从咖啡机获取咖啡

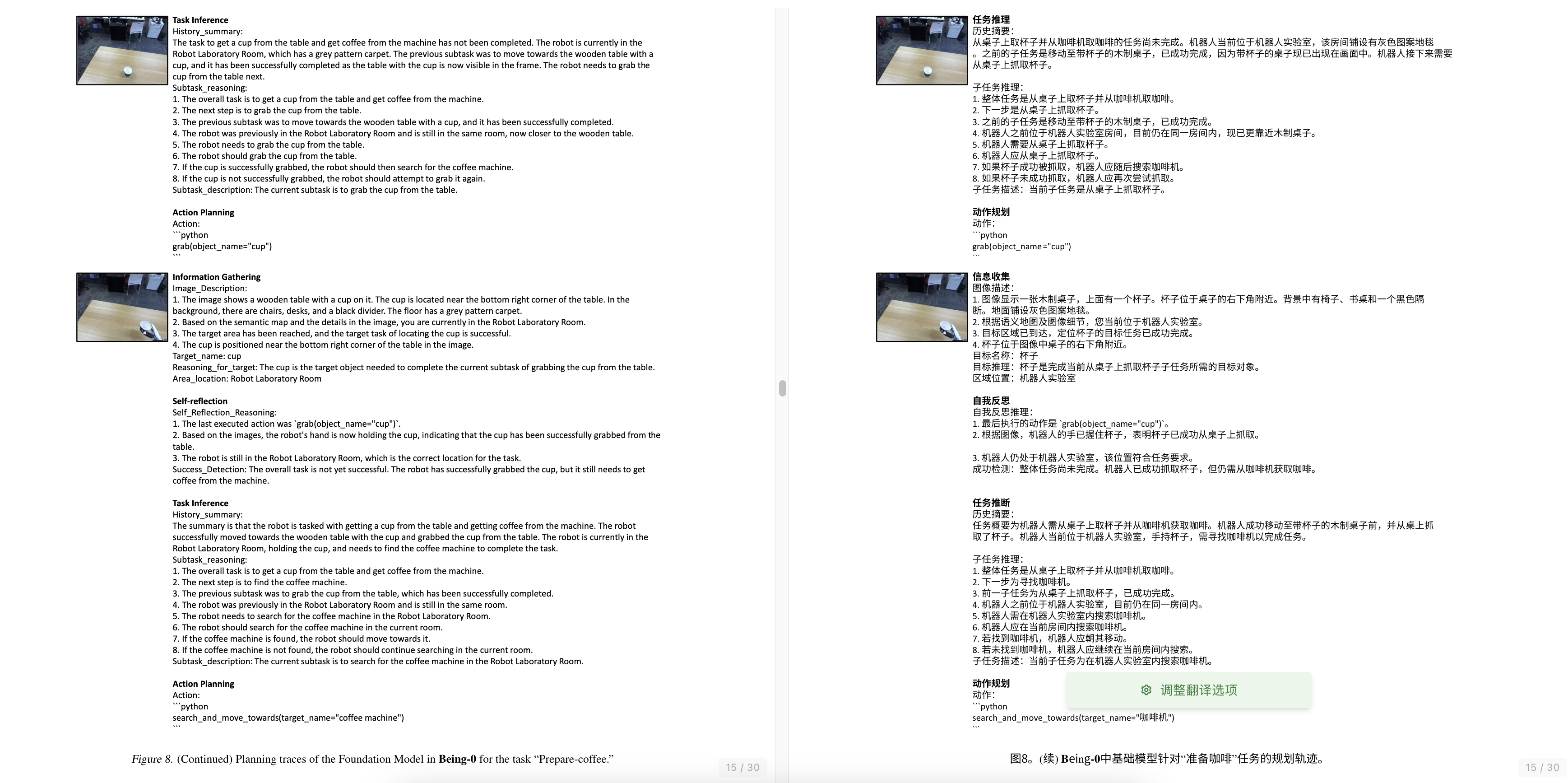
3.2.2 从桌子上抓取杯子
当前子任务是从桌子上抓取杯子
3.2.3 在机器人实验室中搜索咖啡机,并把杯子放置在咖啡机上
当前任务是在机器人实验室中搜索咖啡机,找到咖啡机之后,则把杯子放置在咖啡机上

3.2.4 在咖啡机数字显示屏上选择咖啡选项以获取咖啡