【大模型实战篇】华为信创环境采用vllm部署QwQ-32B模型
1. 背景
本文分享在华为昇腾机器上部署QwQ-32B模型的实践。
首先华为自己是提供了一套在信创机器(NPU)上部署模型的方案【1】,但是部署之后,测试发现会有输出截断的现象。QwQ-32B本身是支持128k的最大上下文长度,定位可能是max-model-len的设置没有生效,但是华为的启动参数中只有maxSeqLen以及maxInputTokenLen参数,修改后也不奏效。
因此我们希望采用更通用更可靠的部署方案。vllm是一种比较通用可靠的推理框架,我们发现vllm已经可以原生支持Ascend【2,3】。
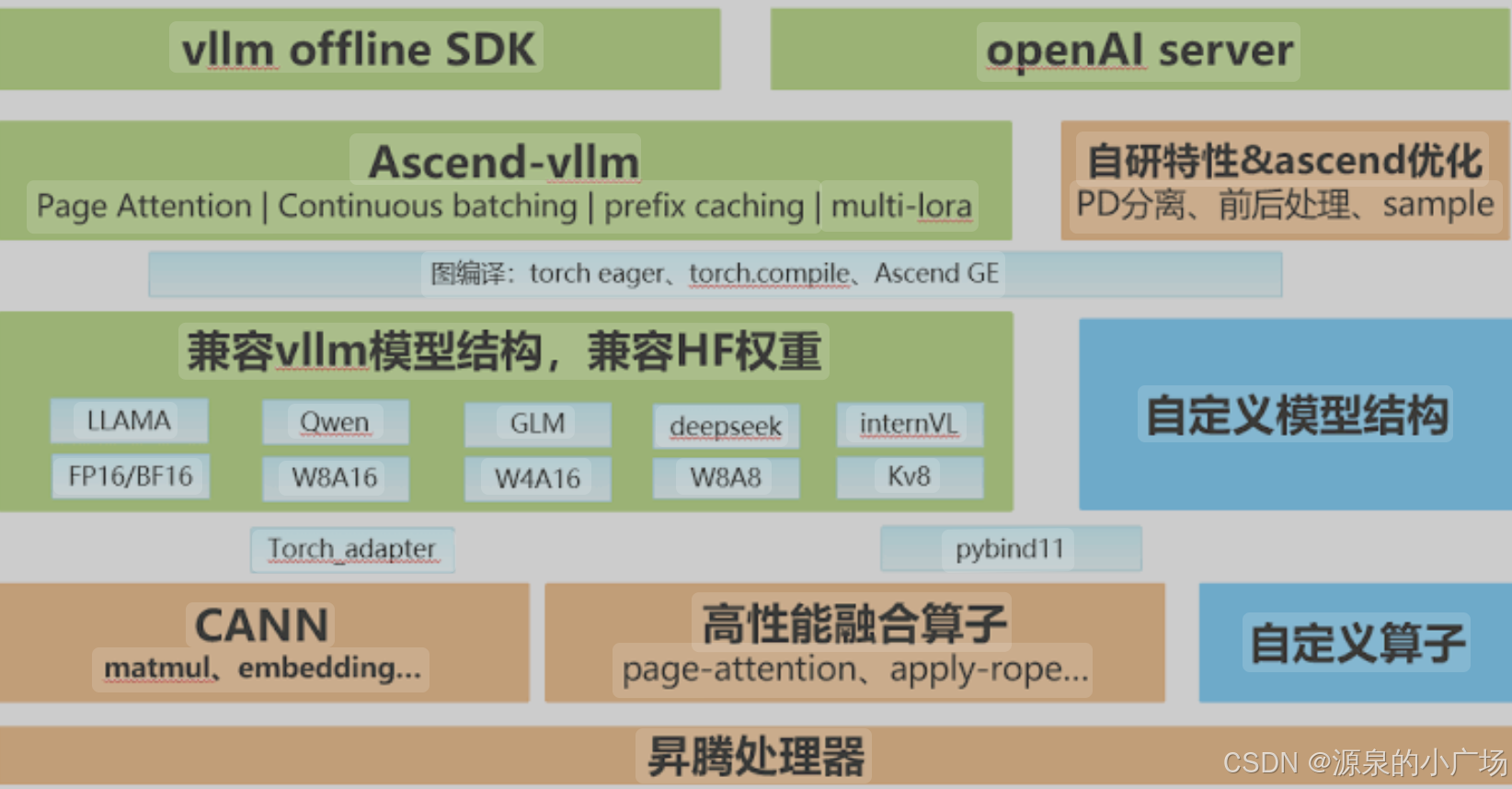
2. 部署及测试
(1)拉取vllm-ascend镜像,为了速度快,可以使用国内镜像地址:
quay.io/ascend/vllm-ascend:v0.8.4rc2-openeuler - 镜像下载 | quay.io
docker pull https://docker.aityp.com/image/quay.io/ascend/vllm-ascend:v0.8.4rc2-openeuler?platform=linux/arm64
(2)docker启动命令
拉取完成后,启动docker镜像,相关的配置修改如下:
docker run -itd --name vllm-QWQ-32B \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/common \
-v /usr/local/Ascend/driver/lib64/driver:/usr/local/Ascend/driver/lib64/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/vnpu.cfg:/etc/vnpu.cfg \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /data/qwq:/qwq \
--privileged=true \
-e ASCEND_RT_VISIBLE_DEVICES=0,1 \
-p 40928:40928 \
-it swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/ascend/vllm-ascend:v0.8.4rc2-openeuler-linuxarm64 bash(3)进入docker镜像
docker exec -it vllm-QWQ-32B /bin/bash
(4)镜像中,配置QwQ-32B模型的启动脚本
cd /qwq/
vi run_vllm.sh
run_vllm.sh文件脚本如下:
export ASCEND_RT_VISIBLE_DEVICES=0,1
vllm serve "/qwq/model" \
--port 40928 \
--served-model-name QwQ-32B \
--dtype auto \
--kv-cache-dtype auto \
--max-model-len 32768 \
--tensor-parallel-size 2(5)启动模型脚本
sh run_vllm.sh
(6)测试脚本(宿主机执行)
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"model": "QwQ-32B",
"messages": [{
"role": "system",
"content": "帮我写一首诗"
}],
"max_tokens": 8192
}' 127.0.0.1:40928/v1/chat/completions
3. 参考材料
【1】昇腾镜像仓库详情
【2】Installation — vllm-ascend
【3】Ascend-vLLM