目标检测篇---faster R-CNN
目标检测系列文章
第一章 R-CNN
第二篇 Fast R-CNN
目录
- 目标检测系列文章
- 📄 论文标题
- 🧠 论文逻辑梳理
- 1. 引言部分梳理 (动机与思想)
- 📝 三句话总结
- 🔍 方法逻辑梳理
- 🚀 关键创新点
- 🔗 方法流程图
- RPN网络梳理
- RoIHeads网络
- 一、select_training_samples 函数
- 二、box_roi_pool函数
- 三、box_head() 函数
- 四、box_predictor() 函数
- 五、 fastrcnn_loss(...)
- 关键疑问解答
- Q1、 Anchor 的来源、生成与训练中的作用?
- Q2 Anchor 尺寸大于感受野如何工作?
📄 论文标题
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick(fast R-CNN作者), and Jian Sun
团队:Microsoft Research
🧠 论文逻辑梳理
1. 引言部分梳理 (动机与思想)
| Aspect | Description (Motivation / Core Idea) |
|---|---|
| 问题背景 (Problem) | Fast R-CNN 已经很快了,但是它依赖的外部区域提议算法(如 Selective Search)运行在 CPU 上,速度很慢,成为了整个目标检测系统的性能瓶颈。而且,区域提议的计算与下游的检测网络是分离的,没有共享计算。 |
| 目标 (Goal) | 创建一个完全基于深度学习的、端到端的目标检测系统。具体来说,要设计一个内部的区域提议网络,使其能够与检测网络共享卷积特征,从而消除外部区域提议的瓶颈,实现高速且统一的检测框架。 |
| 核心思想 (Core Idea) | Faster R-CNN: 提出 区域提议网络 (Region Proposal Network, RPN)。RPN 是一个小型全卷积网络,它直接作用于主干网络(如 VGG/ResNet)输出的共享卷积特征图上,利用 Anchors 高效地预测出物体边界框提议及其“物体性”得分。这些提议随后被送入 Fast R-CNN 检测网络(使用同一份共享特征图)进行精确分类和位置修正。 |
| 核心假设 (Hypothesis) | 通过让 RPN 与检测网络共享底层的卷积计算,并将区域提议也用神经网络实现,可以构建一个统一、高效的框架,显著提升目标检测的速度(达到近实时),同时保持甚至提高检测精度。 |
📝 三句话总结
| 方面 | 内容 |
|---|---|
| ❓发现的问题 |
|
| 💡提出的方法 (R-CNN) |
|
| ⚡该方案的局限性/可改进的点 |
|
🔍 方法逻辑梳理
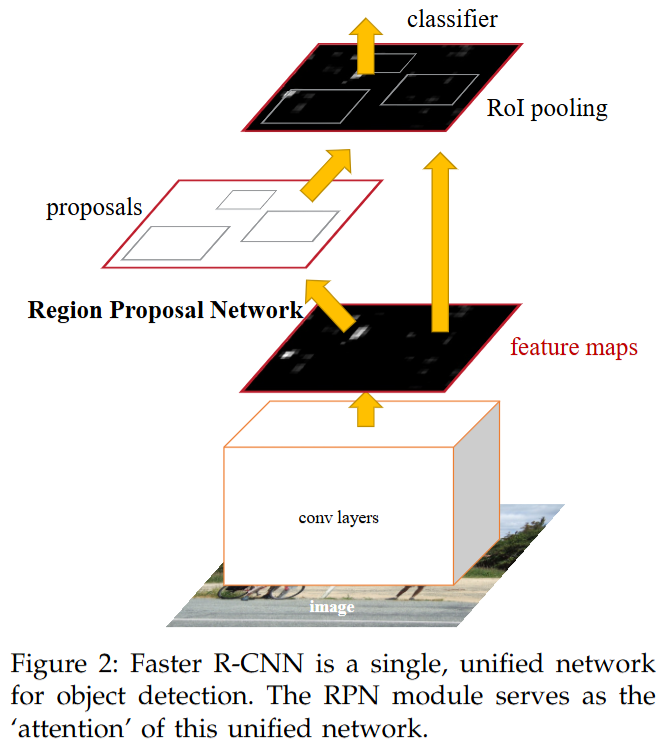
Faster R-CNN 是一个高度整合的统一网络。
-
模型输入:
- 一张
RGB图像。(不再需要外部 RoIs)
- 一张
-
处理流程 (Unified Network):
- 共享主干网络 (Shared Conv Backbone - Encoder 角色):
- 输入: 整张图像。
- 处理: 图像通过一系列卷积和池化层(如
VGG,ResNet的conv部分)。 - 输出: 整张图像的共享卷积特征图 (Shared Feature Map)。
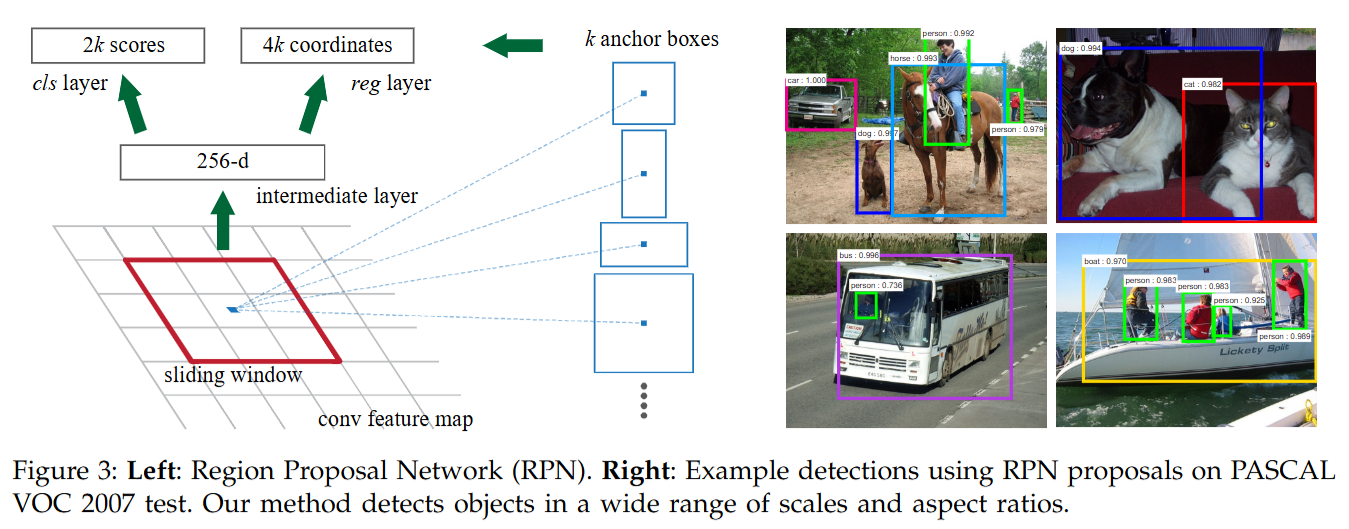
- 区域提议网络 (Region Proposal Network - RPN - 特殊模块):
- 输入: 来自步骤 1 的共享特征图。
- 处理:
- 在特征图上滑动一个小型的卷积网络(如 3x3 卷积)。
- 在滑窗的每个位置,考虑 k 个预定义的 Anchors (不同尺度面积(128²、256²、512²)、长宽比(0.5、1、2))。
- 通过两个并行的 1x1 卷积(分类头和回归头)对每个 Anchor 进行预测:
- 预测 2k 个物体性得分 (Objectness Scores:
objectvs.background)。 - 预测 4k 个边界框回归偏移量 (relative to anchor)。
- 预测 2k 个物体性得分 (Objectness Scores:
- 基于物体性得分筛选
Anchors,应用回归偏移量修正坐标,得到初步的 Proposals。 - 对 Proposals 应用 NMS (非极大值抑制) 以减少冗余。【第一次使用NMS剔除多余的Anchors】
- 输出: 一组候选区域 RoIs (例如 ~300 或 ~2000 个,坐标是相对于原始图像的)。
- RoI Pooling / RoI Align 层 (特殊模块):
- 输入: 共享特征图 (来自步骤 1) + RPN 生成的 RoIs (来自步骤 2)。
- 处理: 对每个 RoI,从共享特征图中提取一个固定大小 (e.g., 7x7xC) 的特征图块。(
RoI Align效果通常更好) - 输出: 为每个 RoI 输出一个固定大小的特征图块。
- 检测头 (Detection Head - Fast R-CNN 部分 - Decoder/Prediction 角色):
- 输入: 来自
RoI Pooling/Align的固定大小特征图块。 - 处理:
- 通过全连接层 (
FClayers) 或卷积层进一步处理特征。 - 送入两个并行的输出层:
- Softmax 分类器 (输出 K+1 类概率 p p p)。
- 边界框回归器 (输出 K 类对应的 4 K 4K 4K 个回归偏移量 t k t^k tk)。
- 通过全连接层 (
- 输出: 对每个输入的 RoI,输出其最终的类别概率 p p p 和类别相关的回归偏移量 t k t^k tk。
- 输入: 来自
- 后处理 (Post-processing - NMS):
- 使用最终的类别分数和应用了回归偏移量后的边界框,再次进行
NMS(通常按类别进行)。 - 输出: 最终检测结果列表。
- 使用最终的类别分数和应用了回归偏移量后的边界框,再次进行
- 共享主干网络 (Shared Conv Backbone - Encoder 角色):
-
模型输出:
- 图像中检测到的物体列表,每个物体包含:类别标签、置信度分数、精修后的边界框坐标。
-
训练过程:
- 目标: 训练 RPN 网络学会生成高质量的 Proposals,同时训练检测头学会对这些 Proposals 进行精确分类和定位。
- 损失函数: 联合优化 RPN 的损失 ( L c l s R P N + λ 1 L r e g R P N L_{cls}^{RPN} + \lambda_1 L_{reg}^{RPN} LclsRPN+λ1LregRPN) 和 Fast R-CNN 检测头的损失 ( L c l s F a s t + λ 2 [ u > 0 ] L r e g F a s t L_{cls}^{Fast} + \lambda_2 [u>0] L_{reg}^{Fast} LclsFast+λ2[u>0]LregFast) 。总损失是这两部分损失的和(可能有权重因子)。
- 训练策略:
- 4步交替训练 (Alternating Training - 原始论文提出): 比较复杂,步骤间有权重固定和微调。
- 训练 RPN (用
ImageNet预训练模型初始化)。 - 训练 Fast R-CNN 检测网络 (用
ImageNet预训练模型初始化,使用第1步 RPN 生成的 proposals)。此时 ConvNet 独立训练。 - 固定共享的 ConvNet 层,只微调 RPN 的独有层。
- 固定共享的 ConvNet 层,只微调 Fast R-CNN 的独有层 (
FCs等)。
- 训练 RPN (用
- 近似联合训练 (Approximate Joint Training - 更常用): 在一次前向传播中计算 RPN 和 Fast R-CNN 的 proposals 和损失,然后将它们的损失加起来一起反向传播更新所有权重(包括共享卷积层)。实现上有一些细节处理 RPN proposal 对后续 loss 的影响。
- 端到端联合训练 (End-to-End Joint Training): 一些现代框架支持更彻底的端到端训练。
- 4步交替训练 (Alternating Training - 原始论文提出): 比较复杂,步骤间有权重固定和微调。
🚀 关键创新点
-
创新点 1: 区域提议网络 (Region Proposal Network - RPN)
- 为什么要这样做? 为了摆脱对外部、缓慢、与网络分离的区域提议算法(如
Selective Search)的依赖。 - 不用它会怎样? 目标检测系统的速度会被区域提议步骤严重拖慢,无法实现高速检测,且提议过程无法从深度特征学习中受益。RPN 是实现速度和整合的关键。
- 为什么要这样做? 为了摆脱对外部、缓慢、与网络分离的区域提议算法(如
-
创新点 2: 卷积特征共享 (Shared Convolutional Features)
- 为什么要这样做? 区域提议和物体检测都需要对图像进行特征提取,分开做是巨大的计算浪费。这两项任务可以基于相同的底层视觉特征。
- 不用它会怎样? 计算成本会高得多(如 R-CNN 或即使是将 SS 搬上 GPU 但仍独立计算的方案)。特征共享是 Faster R-CNN 实现效率飞跃的核心原因。
-
创新点 3: Anchor 机制
- 为什么要这样做? 需要一种方法让 RPN(一个相对简单的全卷积网络)能够高效地在特征图上直接预测出不同尺度、不同长宽比的物体提议。
- 不用它会怎样? RPN 可能难以直接预测如此多样化的边界框。Anchor 提供了一组有效的、多样的参考基准,极大地简化了 RPN 的预测任务,使其可以在单一尺度的特征图上工作,避免了图像金字塔或滤波器金字塔的复杂性。
-
创新点 4: 统一网络与端到端训练趋势
- 为什么要这样做? 将整个目标检测流程(除了
NMS等后处理)尽可能地统一到一个深度网络中,可以简化系统、提高效率,并可能通过联合优化提升性能。 - 不用它会怎样? 系统会保持多阶段、多模块的状态,训练和部署更复杂,速度也受限。Faster R-CNN 代表了向更整合、更端到端的检测系统迈出的决定性一步。
- 为什么要这样做? 将整个目标检测流程(除了
总结来说,Faster R-CNN 通过革命性的 RPN 和 Anchor 机制,并将 RPN 与 Fast R-CNN 检测器基于共享的卷积特征进行整合,最终构建了一个高效、准确且相对统一的目标检测框架,成为了后续许多现代检测器的基础。
🔗 方法流程图
RPN网络梳理
参考资料:
保姆级 faster rcnn 源码逐行解读 (二)RPN 生成锚框
关于目标检测中bounding box编码和解码时weight参数的理解
class RegionProposalNetwork(torch.nn.Module):def __init__(self,anchor_generator, # 生成anchor head, # 生成置信度objectness和预测框相对于anchor的偏移量pred_box_deltasfg_iou_thresh, # fg表示frontgroud即目标,若anchor与gt的iou大于fg_iou_thresh,则被认为目标,默认为0.7bg_iou_thresh, # bg表示backgroud即背景,若anchor与gt的iou小于bg_iou_thresh,则被认为背景,默认为0.3batch_size_per_image, # training时,需要正负样本平衡,表示每张图片采样batch_size_per_image个样本positive_fraction, # 表示正负样本平衡的正样本比例,正样本数=batch_size_per_image*positive_fractionpre_nms_top_n, # 在nms前,按置信度排序,最多选取前pre_nms_top_n个proposals送入到nmspost_nms_top_n, # nms后,按置信度排序,最多选取前post_nms_top_n个proposals送入到roi_headnms_thresh # nms时,设定的置信度的阈值):super(RegionProposalNetwork, self).__init__()self.anchor_generator = anchor_generatorself.head = headself.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0)) # boxcoder用来解码编码偏移量 self.box_similarity = box_ops.box_iou # 用iou来衡量box之间的相似度self.proposal_matcher = det_utils.Matcher( # 为每个anchor匹配groud truthfg_iou_thresh,bg_iou_thresh,allow_low_quality_matches=True, # 允许低质量的匹配,后面讲Matcher时再讲,见part2)self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler( # 顾名思义正负样本平衡采样,因为目标检测负样本数量要远多于正样本数量。# 平衡方法也很简单,就是随机采样,使得正负样本比例满足positive_fractionbatch_size_per_image, positive_fraction)self._pre_nms_top_n = pre_nms_top_n #注意这里training和testing时,取值不同,training取值为2000,testing取值为1000self._post_nms_top_n = post_nms_top_n #注意这里training和testing时,取值不同,training取值也为2000,testing取值也为1000self.nms_thresh = nms_threshself.min_size = 1e-3 # 当proposal的面积小于min_size,去除该proposaldef pre_nms_top_n(self):if self.training:return self._pre_nms_top_n['training']return self._pre_nms_top_n['testing']def post_nms_top_n(self):if self.training:return self._post_nms_top_n['training']return self._post_nms_top_n['testing']def concat_box_prediction_layers(box_cls, box_regression):# type: (List[Tensor], List[Tensor])box_cls_flattened = []box_regression_flattened = []for box_cls_per_level, box_regression_per_level in zip(box_cls, box_regression):N, AxC, H, W = box_cls_per_level.shapeAx4 = box_regression_per_level.shape[1]A = Ax4 // 4C = AxC // Abox_cls_per_level = permute_and_flatten(box_cls_per_level, N, A, C, H, W) # 转换为(B,A*H*W,1)box_cls_flattened.append(box_cls_per_level)box_regression_per_level = permute_and_flatten(box_regression_per_level, N, A, 4, H, W) # 转换为(B,A*H*W,4)box_regression_flattened.append(box_regression_per_level)box_cls = torch.cat(box_cls_flattened, dim=1).flatten(0, -2)box_regression = torch.cat(box_regression_flattened, dim=1).reshape(-1, 4)# 最后box_cls:tensor(B*levels*A*H*W,1),box_regression:tensor(B*levels*A*H*W,4)return box_cls, box_regressiondef forward(self, images, features, targets=None):# type: (ImageList, Dict[str, Tensor], Optional[List[Dict[str, Tensor]]])features = list(features.values()) # RPN使用所有的feature_maps,注意:roi_head将不使用P6 featureobjectness, pred_bbox_deltas = self.head(features)# objectness为List[tensor(B,1*A,H,W)*levels],# pred_bbox_deltas为List[tensor(B,4*A,H,W)*levels]# levels为FPN的不同尺度特征图的个数,这里就是P2到P6,共5个特征图anchors = self.anchor_generator(images, features)# anchors:List[tensor(levels*A*H*W,4)*B],4即x1,y1,x2,y2(左上角和右下角),A表示每个grid有多少个先验框# 注意这里每个level的H,W不全相同,所以H1 * W1 + H2 * W2……简写成levels * A * H * Wnum_images = len(anchors)num_anchors_per_level = [o[0].numel() for o in objectness] # numel求数组中元素数量,即H*W*Aobjectness, pred_bbox_deltas = concat_box_prediction_layers(objectness, pred_bbox_deltas)# concat_box_prediction_layers转换格式# objectness:tensor(B*levels*A*H*W,1),pred_bbox_deltas:tensor(B*levels*A*H*W,4)# 注意这里每个level的H,W不全相同,所以H1*W1+H2*W2……简写成levels*A*H*W# levels是FPN的不同尺度特征图的个数,A表示每个grid的anchor数量proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)# 注意这里pred_bbox_deltas用detach阻断梯度!!# 为什么要阻断梯度呢,因为proposal将被送入roi_head层,这里阻断了梯度,那么在训练roi_head层时,就不会更新rpn层的参数!!# faster rcnn这里采用的是分开的串行训练,先训练rpn,再冻结rpn去训练roi_headproposals = proposals.view(num_images, -1, 4) # tensor(B,levels*A*H*W,4)boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)# 先按置信度排序,选最大的前pre_nms_topn个,然后clip对越界的proposals进行剪裁,去除面积太小的proposals,最后进行nms# 返回的boxes为List[[post_nms_top_n*4]*B]losses = {}if self.training:assert targets is not Nonelabels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets)'''这个类主要实现将RPN生成的所有锚框(anchor)与标注的基准边框(ground truth box)进行匹配。每一个anchor都会匹配一个与之对应的gt,当anchor与gt的iou小于low_iou_threshold(=bg_iou_thresh)时,认定其为背景。当anchor与gt的iou大于high_iou_threshold(=fg_iou_thresh)时,认定其为目标。这个匹配操作是基于anchor与gt之间的iou的MxN矩阵(match_quality_matrix)来进行的。其中M为gt的个数,N为anchor的个数。iou矩阵的每一列表示某个anchor与所有各个gt之间的iou,每一行表示每个gt与所有各个anchor之间的iou。返回的labels为长度为N的向量,其表示每一个anchor的类型:最后取值为0、-1、1。0表示背景,1表示目标,-1表示介于背景和目标。'''regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)# regression_target为gt相对于anchors的偏移量loss_objectness, loss_rpn_box_reg = self.compute_loss(objectness, pred_bbox_deltas, labels, regression_targets)losses = {"loss_objectness": loss_objectness,"loss_rpn_box_reg": loss_rpn_box_reg,}return boxes, losses
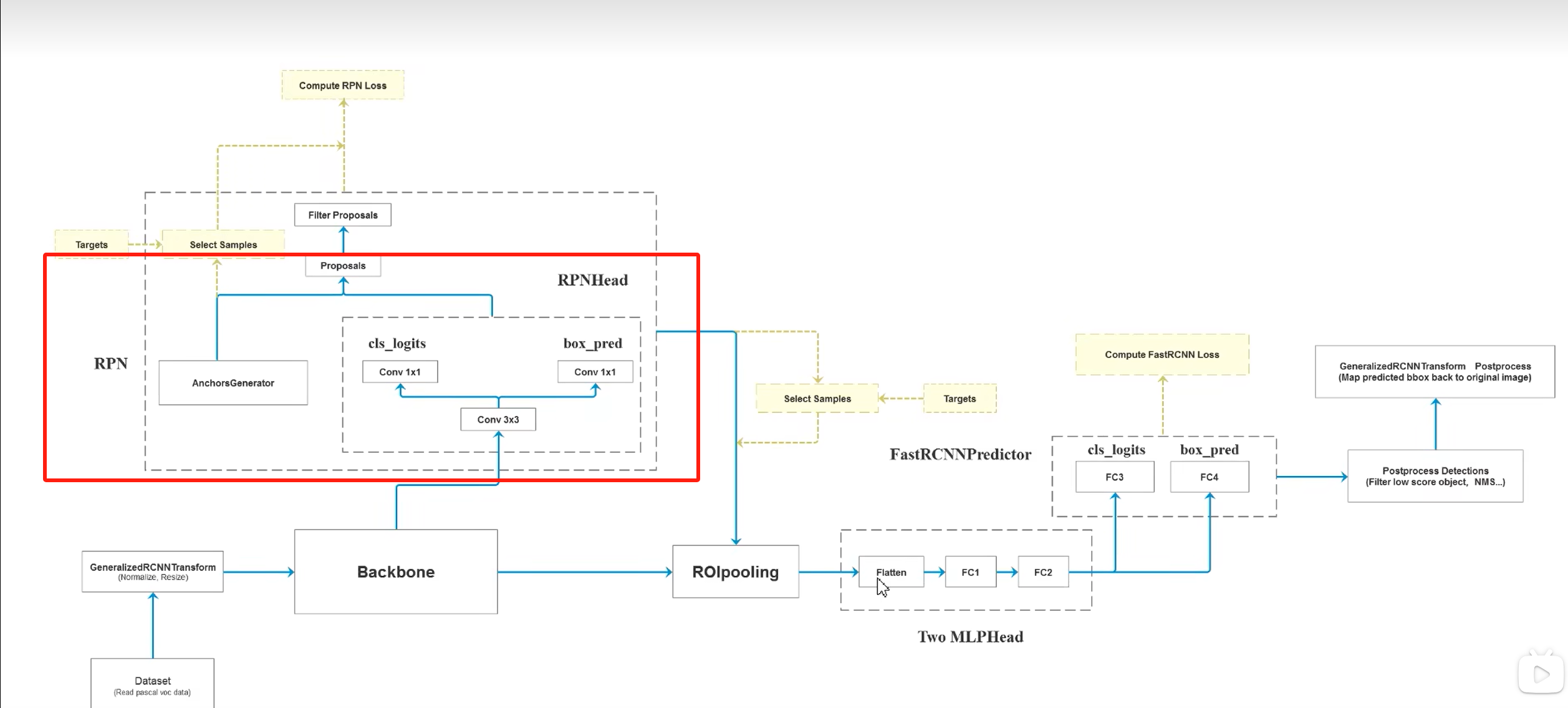
Region Proposal Network的 forword 主要包括:
rpn_head: 根据特征图经过一层3 * 3卷积和两个并行的1 * 1卷积,获得类别概率、预测的边界框偏移量(dx,dy,dh,dw)anchor_generator: 根据特征图和原图的步长关系,在原图中生成K个anchor。concat_box_prediction_layers: 因为neck是FPN,会有多个特征层级,因此会对多层级预测结果的汇合与格式统一,最后输出一个是 [所有图片所有层级总Anchor数, 类别数] 的分类得分,另一个是 [所有图片所有层级总Anchor数, 4] 的回归偏移量。box_coder.decode: 将rpn_head得到的预测偏移量 ( d x , d y , d w , d h ) (dx,dy,dw,dh) (dx,dy,dw,dh) 转化成 图像上的实际像素坐标 ( x 1 , y 1 , x 2 , y 2 ) (x1,y1,x2,y2) (x1,y1,x2,y2),得到原图上Proposal (anchor偏移之后的)边界框坐标 ( x 1 , y 1 , x 2 , y 2 ) (x1,y1,x2,y2) (x1,y1,x2,y2) 。filter_proposals: 先按置信度排序,选最大的前pre_nms_topn个,然后clip对越界的proposals进行剪裁,去除面积太小的proposals,最后进行nms,得到最终的输出proposals(也是ROIpooling的输入)
如果是
training还需要
assign_targets_to_anchor: 将RPN生成的所有锚框(anchor)与标注的真值边框(ground truth box)进行匹配,选出正负样本,方便计算损失(计算损失的时候只算正样本)box_coder.encode:获取anchor相对于GT的真实偏移量compute_loss
RoIHeads网络
参考资料:
保姆级 faster rcnn 源码逐行解读 (五)roi_head part1
class RoIHeads(torch.nn.Module):__annotations__ = {'box_coder': det_utils.BoxCoder,'proposal_matcher': det_utils.Matcher,'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler,}def __init__(self,box_roi_pool,box_head,box_predictor,# Faster R-CNN 训练时用到的参数fg_iou_thresh, bg_iou_thresh,batch_size_per_image, positive_fraction,bbox_reg_weights,# Faster R-CNN 推理时用到的参数score_thresh,nms_thresh,detections_per_img,…………):super(RoIHeads, self).__init__()self.box_similarity = box_ops.box_iou# 为每个proposal匹配一个gt,在训练时要用到,这个Matcher在rpn源码part3文章的5.assign_targets_to_anchor有详解self.proposal_matcher = det_utils.Matcher(fg_iou_thresh,bg_iou_thresh,allow_low_quality_matches=False) # !!在rpn层中该参数为True,roi_head为False# 正负样本平衡,在rpn源码part3文章的6.compute_loss有讲到self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler(batch_size_per_image,positive_fraction)if bbox_reg_weights is None:bbox_reg_weights = (10., 10., 5., 5.)self.box_coder = det_utils.BoxCoder(bbox_reg_weights)self.box_roi_pool = box_roi_poolself.box_head = box_headself.box_predictor = box_predictorself.score_thresh = score_threshself.nms_thresh = nms_threshself.detections_per_img = detections_per_img…………def forward(self, features, proposals, image_shapes, targets=None):# type: (Dict[str, Tensor], List[Tensor], List[Tuple[int, int]], Optional[List[Dict[str, Tensor]]])"""输入:features (List[Tensor]),即backbone输出的多尺度特征图proposals (List[Tensor[N, 4]]),即rpn输出的proposalsimage_shapes (List[Tuple[H, W]])targets (List[Dict])"""………………if self.training:# training时,进行正负平衡采样,以及为proposal匹配gt,届时计算proposal与匹配的gt之间的loss。proposals, matched_idxs, labels, regression_targets = self.select_training_samples(proposals, targets)else:labels = Noneregression_targets = Nonematched_idxs = Nonebox_features = self.box_roi_pool(features, proposals, image_shapes) # box_roi_pool定义为MultiScaleRoIAlign,将每个proposal转换为channels*7*7(channel为feature_maps的通道数)维的特征向量 box_features = self.box_head(box_features)# box_head定义为TwoMLPhead,将channels*7*7转换为1024维的特征向量,就是两层的全连接层nn.Linearclass_logits, box_regression = self.box_predictor(box_features)# box_predictor定义为FastRCNNPredictor,将1024维的特征向量分别转换为cls(num_class维)和bbox_reg(num_class*4维)result = torch.jit.annotate(List[Dict[str, torch.Tensor]], [])losses = {}if self.training:assert labels is not None and regression_targets is not Noneloss_classifier, loss_box_reg = fastrcnn_loss(class_logits, box_regression, labels, regression_targets) # training则计算roi_head层的损失函数losses = {"loss_classifier": loss_classifier,"loss_box_reg": loss_box_reg}else:# testing则对神经网络的输出进行后处理,返回最终预测的分类和bboxboxes, scores, labels = self.postprocess_detections(class_logits, box_regression, proposals, image_shapes)num_images = len(boxes)for i in range(num_images):result.append({"boxes": boxes[i],"labels": labels[i],"scores": scores[i],})……………………return result, losses
ROIHead Network的 forword 主要包括:
select_training_samples:正负样本平衡采样以及为proposal匹配gt(训练时才用到)MultiScaleRoIAlign:将rpn生成的proposal转换为channels77维的特征向量TwoMLPhead:将channels * 7 * 7维转换为1024维的特征向量FastRCNNPredictor:将1024维的特征向量分别转换为cls(num_class维)和bbox_reg(num_class * 4维)fastrcnn_loss:计算roi_head层的损失函数postprocess_detections:返回最终预测的类别、bbox和score(分类的概率)
其实上面的流程和RPN差不多,只不过一个是处理的
anchor,一个是处理的proposal
下面重点讲讲这几个函数干了啥吧,代码上有的还不清楚
一、select_training_samples 函数
proposals, labels, regression_targets = self.select_training_samples(proposals, targets)
此函数目标: 从输入的 2000 个 proposals 中,根据与真实物体框 (gt_boxes) 的重叠度 (IoU),挑选出一批用于训练的样本(正样本和负样本),并为它们确定好真实的类别标签和真实的回归目标。
-
add_gt_proposals为了确保训练时能学习到真实物体,通常会先把 每张图片中的 gt_boxes 也加入到 proposals 列表中。现在我们有 100 + 2 = 102 个候选框(假设)需要考虑。 -
assign_targets_to_proposals:计算这 102 个候选框与 2 个 gt_boxes 的 IoU 矩阵**【类似下面的矩阵】** 根据IoU的大小,标记正负样本。matched_idxs(每个候选框匹配的 gt 索引,或 -1, -2) 和labels(每个候选框的初步标签,0 代表背景,正数代表物体类别,-1 代表忽略)
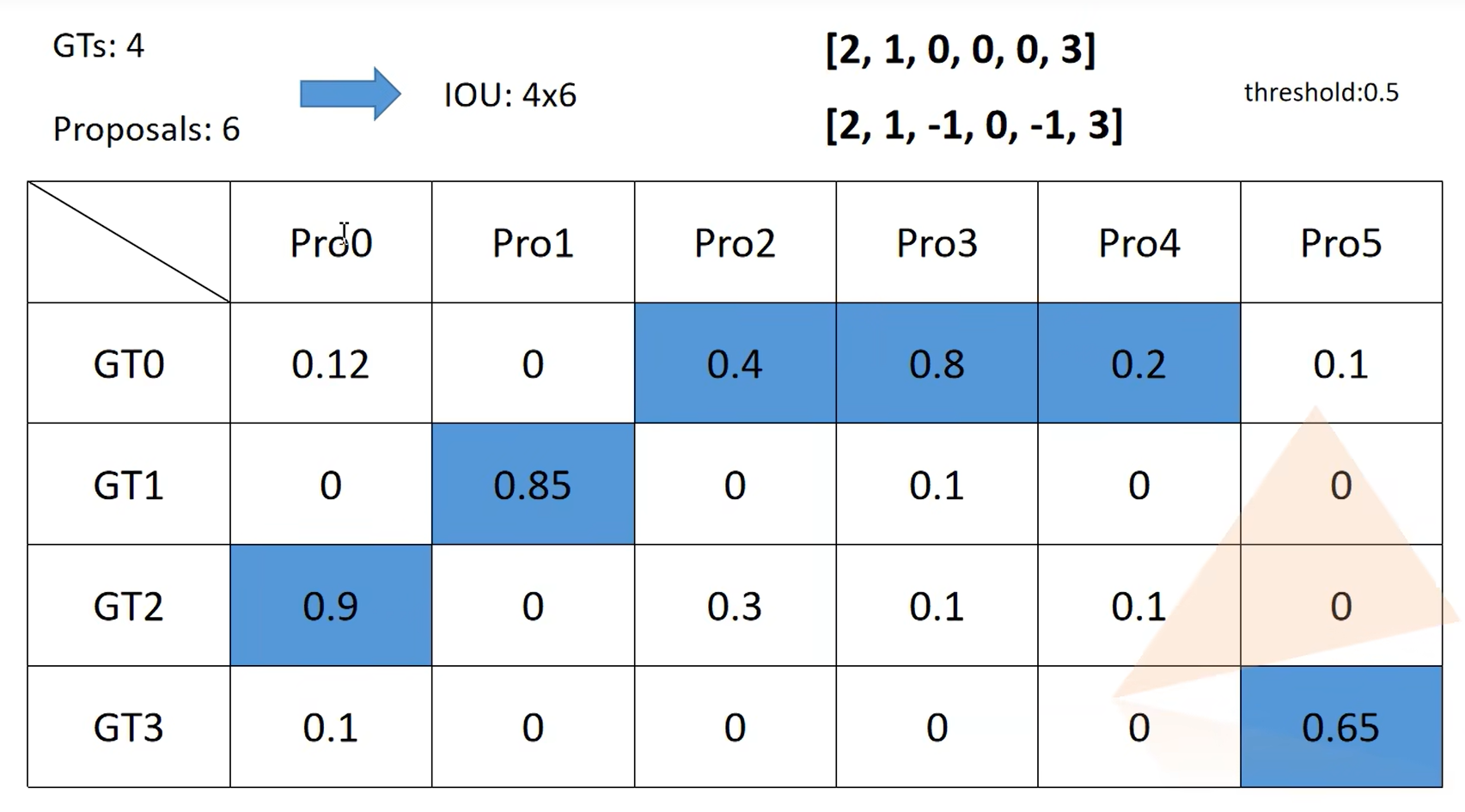
-
subsample:使用self.fg_bg_sampler从这 102 个已标记的候选框中进行采样,目标是得到batch_size_per_image = 64个样本,且其中正样本比例尽量接近positive_fraction = 0.25(即最多 16 个正样本)。【数值上是假设的!!就是不全取所有的候选框,只去一部分】 假设我们有 8 个正样本,90 个负样本。采样器可能会选择全部 8 个正样本,然后从 90 个负样本中随机选择 64−8=56 个负样本。输出:sampled_inds,这是一个包含 64 个被选中样本在原始 102 个候选框中索引的列表。 -
只对被选中的 8 个正样本,使用
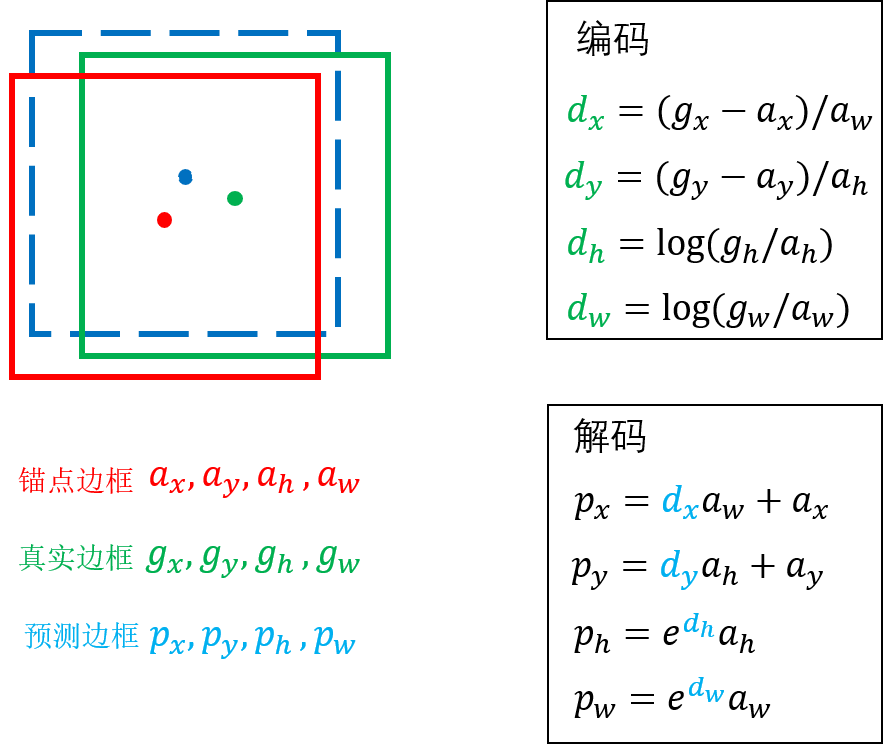
self.box_coder.encode计算它们相对于其匹配的gt_box的真实回归目标 v = ( v x , v y , v w , v h ) v=(vx,vy,vw,vh) v=(vx,vy,vw,vh) 这个v就是网络需要学习预测的目标偏移量。 -
函数最终返回:
proposals(形状 [64, 4]),labels(形状 [64]),regression_targets(形状 [8, 4],只包含正样本的目标)
proposals, labels, regression_targets = self.select_training_samples(proposals, targets)
二、box_roi_pool函数
box_features = self.box_roi_pool(features, proposals, image_shapes)
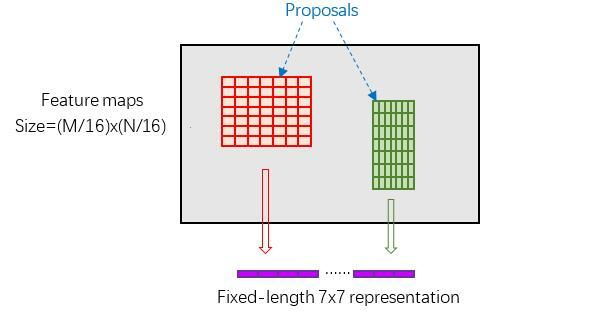
对这 64 个 proposals 中的每一个,执行 RoI Pooling (或 RoI Align) 操作(将每个proposal对应的feature map区域水平分为 pool_w(7)*pool_h (7)的网格;对网格的每一份都进行max pooling处理。) 从共享特征图 features 中提取出固定大小 (如 7x7xC) 的特征图块。【这64 个 proposals 大小都不一样】
三、box_head() 函数
box_features = self.box_head(box_features)
输入的是上一步得到的box_features ,然后将每个 7x7xC 的特征图块送入 box_head(通常包含 Flatten 操作和几个全连接层,如 TwoMLPHead),box_features 形状变为 [64, representation_size],比如 [64, 1024]。这是每个 RoI 最终的特征表示。
class TwoMLPHead(nn.Module):"""就是两个全连接层"""def __init__(self, in_channels, representation_size):# in_channel=channels*7*7 (roi_align对每个proposal的输出)# representation_size=1024# 将channels*7*7维转换为1024维的特征向量super(TwoMLPHead, self).__init__()# nn.Linear(输入维度数,输出维度数)self.fc6 = nn.Linear(in_channels, representation_size) self.fc7 = nn.Linear(representation_size, representation_size)def forward(self, x):x = x.flatten(start_dim=1) # 扁平化矩阵x = F.relu(self.fc6(x))x = F.relu(self.fc7(x))return x
四、box_predictor() 函数
class_logits, box_regression = self.box_predictor(box_features)
class FastRCNNPredictor(nn.Module):"""输入TwoMLPhead产生的1024维,通过全连接层,输出分别转换为cls(num_class维)和bbox_reg(num_class*4维)"""def __init__(self, in_channels, num_classes):super(FastRCNNPredictor, self).__init__()self.cls_score = nn.Linear(in_channels, num_classes)self.bbox_pred = nn.Linear(in_channels, num_classes * 4)def forward(self, x):if x.dim() == 4:assert list(x.shape[2:]) == [1, 1]x = x.flatten(start_dim=1)scores = self.cls_score(x)bbox_deltas = self.bbox_pred(x)return scores, bbox_deltas
faster rcnn总共进行了
两次微调,第一次是rpn层对anchor进行微调得到proposal,第二次是roi-head层对proposal进行微调得到最终的result["boxes"]预测框。
提问: 对一个proposal进行微调,那返回 [dpx,dpy,dph,dpw] 4维输出就可以了呀,为什么要num_class4维输出呢?*
RPN vs RoI Head 的回归目标不同:
RPN: 它的任务是判断 Anchor 里有没有物体(二分类),以及大致修正 Anchor 的位置。它不关心里面具体是什么物体。所以,对于一个可能包含物体的 Anchor,RPN 只需要预测一组 4 个偏移量 (dx,dy,dw,dh) 就够了。
RoI Head (FastRCNNPredictor): 它的任务更精细。它不仅要判断 Proposal(来自 RPN)里具体是哪一类物体(比如“猫”、“狗”、“汽车”还是“背景”),还要对这个 Proposal 进行第二次、更精确的位置修正。
针对不同类别的物体,最佳的边界框调整方式可能是不同的。比如:
1、调整一个细长的“人”的框,可能主要需要调整 Y 方向和高度 H。
2、调整一个扁平的“汽车”的框,可能主要需要调整 X 方向和宽度 W。
如果只预测一组 4 个偏移量,就相当于给所有类别的物体都用同一套“均码”调整逻辑。
而预测 num_classes * 4(实际上通常是 K 个物体类别 * 4 = 4K 个)偏移量,就相当于网络为每一种可能出现的物体类别都量身定做了一套调整方案。这就像是为“猫”、“狗”、“汽车”等分别准备了不同的“服装修改指南”。
五、 fastrcnn_loss(…)
loss_classifier, loss_box_reg = fastrcnn_loss(...)
def fastrcnn_loss(class_logits, box_regression, labels, regression_targets):# type: (Tensor, Tensor, List[Tensor], List[Tensor])# labels和regression_target是真实值,由select_training_samples函数产生,在part1文章中讲解labels = torch.cat(labels, dim=0)regression_targets = torch.cat(regression_targets, dim=0)classification_loss = F.cross_entropy(class_logits, labels) # 类别loss交叉熵损失函数sampled_pos_inds_subset = torch.nonzero(labels > 0).squeeze(1)# label=0为背景,大于0为目标labels_pos = labels[sampled_pos_inds_subset]N, num_classes = class_logits.shapebox_regression = box_regression.reshape(N, -1, 4)box_loss = F.smooth_l1_loss( # 只对目标计算lossbox_regression[sampled_pos_inds_subset, labels_pos],regression_targets[sampled_pos_inds_subset],reduction="sum",)box_loss = box_loss / labels.numel()return classification_loss, box_loss
-
classification_loss计算: 使用F.cross_entropy(class_logits, labels)。所有 64 个样本都参与分类损失计算。网络需要正确区分 8 个正样本的类别,并将 56 个负样本识别为背景 (标签 0)。 -
box_loss计算:
sampled_pos_inds_subset = torch.where(torch.gt(labels, 0))[0]:找到 64 个样本中那 8 个正样本的索引 。
labels_pos = labels[sampled_pos_inds_subset]:获取这 8 个正样本的真实类别标签 (值 > 0)。
box_regression = box_regression.reshape(N, -1, 4):将预测的回归值整理成 [64, 21, 4] 的形状,方便按类别索引。
det_utils.smooth_l1_loss(...):计算这 8 个预测偏移量与regression_targets(形状也是 [8, 4]) 之间的Smooth L1损失。只有 8 个正样本参与回归损失计算。
输出: 返回计算得到的 classification_loss 和 box_loss。
关键疑问解答
Q1、 Anchor 的来源、生成与训练中的作用?
- 来源:
Anchors是预先定义好的超参数 (不同的尺度Scales和长宽比Aspect Ratios),不是根据当前数据集实时生成的。其设定基于经验或常见物体特性。 - 生成:
Anchors概念上是在 CNN 输出的最后一个特征图的每一个空间位置上生成的。每个位置都有一整套 (k 个) 不同规格的Anchors,它们的中心对应于特征图位置映射回原图的位置。这个生成发生在每次前向传播时。 - 训练作用:
Anchors作为参考基准。训练RPN的目标是:
1、分类: 判断每个 Anchor 是否覆盖了一个物体 (Objectness Score),通过与 Ground Truth Boxes 计算IoU来标记Anchor (正/负/忽略样本),并计算分类损失。
2、回归: 对于被标记为正样本的 Anchor,学习预测出将其精确调整到对应Ground Truth Box所需的4 个偏移量 (dx, dy, dw, dh),并计算回归损失 (通常用 Smooth L1 Loss)。网络学习的是预测“修正量”,而不是修改 Anchor 本身。
Q2 Anchor 尺寸大于感受野如何工作?
Anchor 是预测的参考框架,RPN 的预测是基于其感受野内的特征进行的。
网络学习的是将感受野内的局部特征与“应该使用哪种规格的 Anchor”以及“应该如何对该 Anchor 进行相对调整”这两者关联起来。
即使感受野小于 Anchor,内部特征也可能足够指示一个大物体的存在及大致的调整方向。对于大物体,多个相邻位置的预测会共同作用。【管中窥豹,可知豹外貌】