Spark知识总结
spark RDD
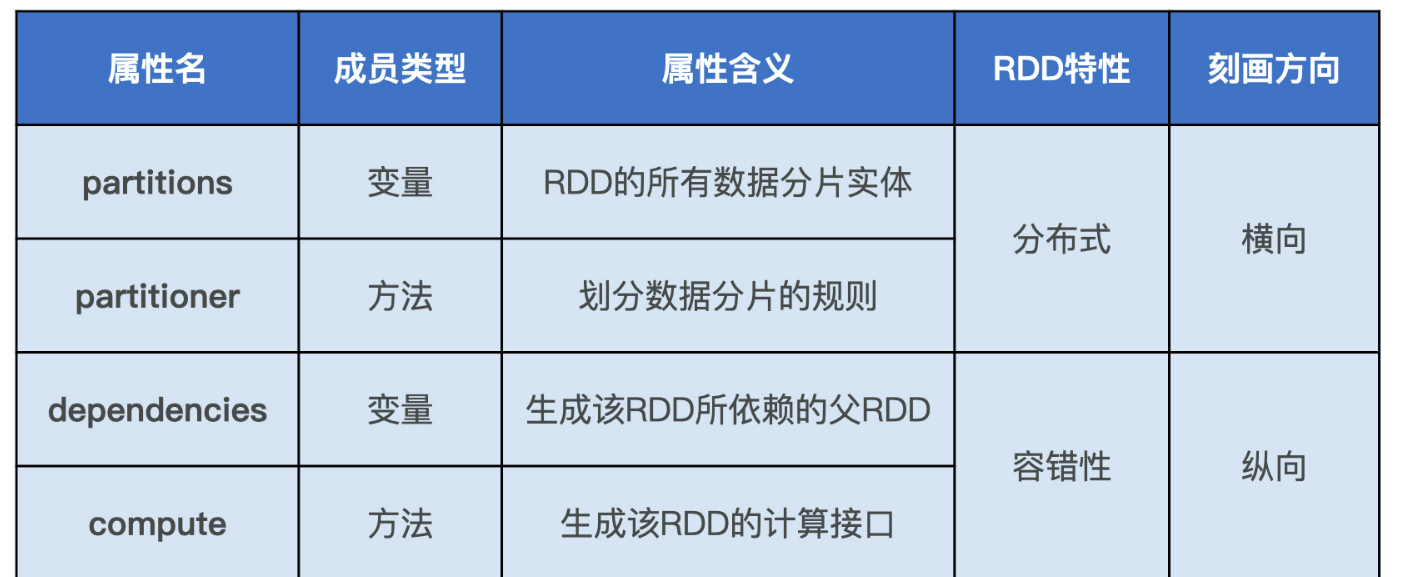
spark中的内存计算
1.RDD cache确实是Spark分布式计算引擎的一大亮点,分布式缓存数据集合
2.内部的流水线式计算模式
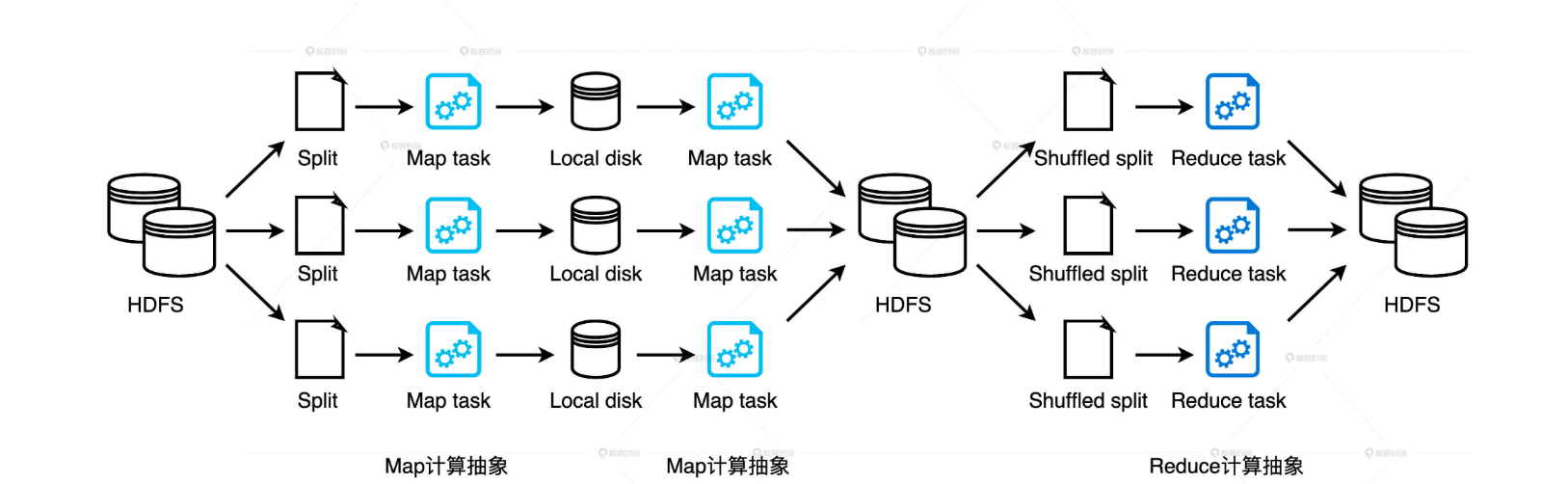
我们需要先搞清楚DAG和Stages划分,从开发者的视角出发,DAG的构建是通过在分布式数据集上不停地调用算子来完成的,DAG以Actions算子为起点,从后向前回溯,以Shuffle操作为边界,划分出不同的Stages。
最后,我们归纳出内存计算更完整的第二层含义:同一Stage内所有算子融合为一个函数,Stage的输出结果由这个函数一次性作用在输入数据集而产生。
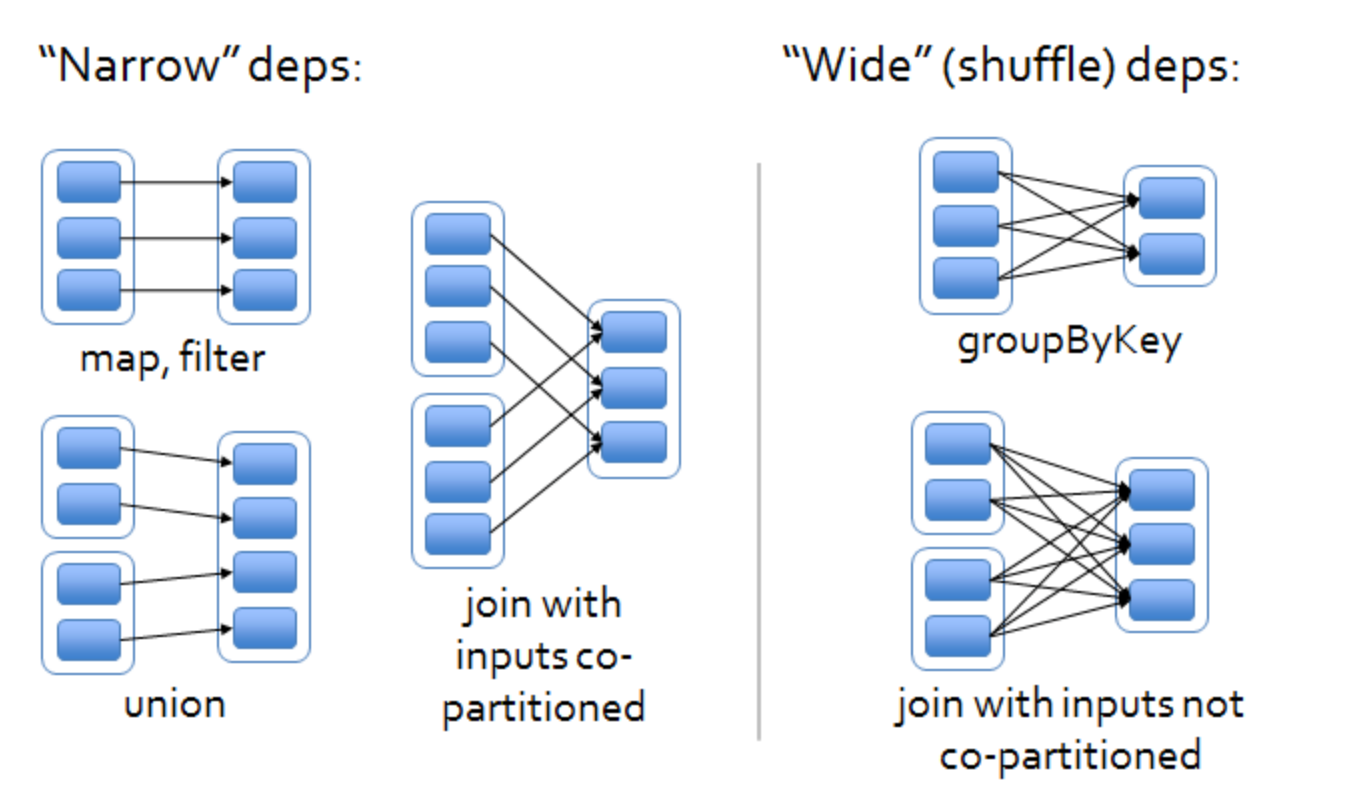
宽窄依赖:父RDD的分区只对应下面子RDD的一个分区,为窄依赖。其余为宽依赖
| 维度 | 窄依赖 | 宽依赖 |
|---|---|---|
| 数据传输 | 无shuffle,本地处理14 | 需shuffle,跨节点传输14 |
| 并行度 | 高(允许流水线并行)57 | 低(需等待父任务完成)28 |
| 容错恢复成本 | 仅需重算单个父分区57 | 需重算多个父分区8 |
| 典型操作 | map、filter、union4 | groupByKey、join4 |
其实就是父RDD的一个分区会被传到几个子RDD分区的区别。如果被传到一个子RDD分区,就可以不需要移动数据(移动计算);如果被传到多个子RDD分区,就需要进行数据的传输。
宽依赖:join(非hash-partitioned)、groupByKey、partitionBy;
窄依赖的算子 :map、filter、union、join(hash-partitioned)、mapPartitions;
如何计算job, stage, task可以参考这篇博客:[Spark] 手撕Job、Stage、Task划分机制_spark根据什么分task-CSDN博客
spark调度
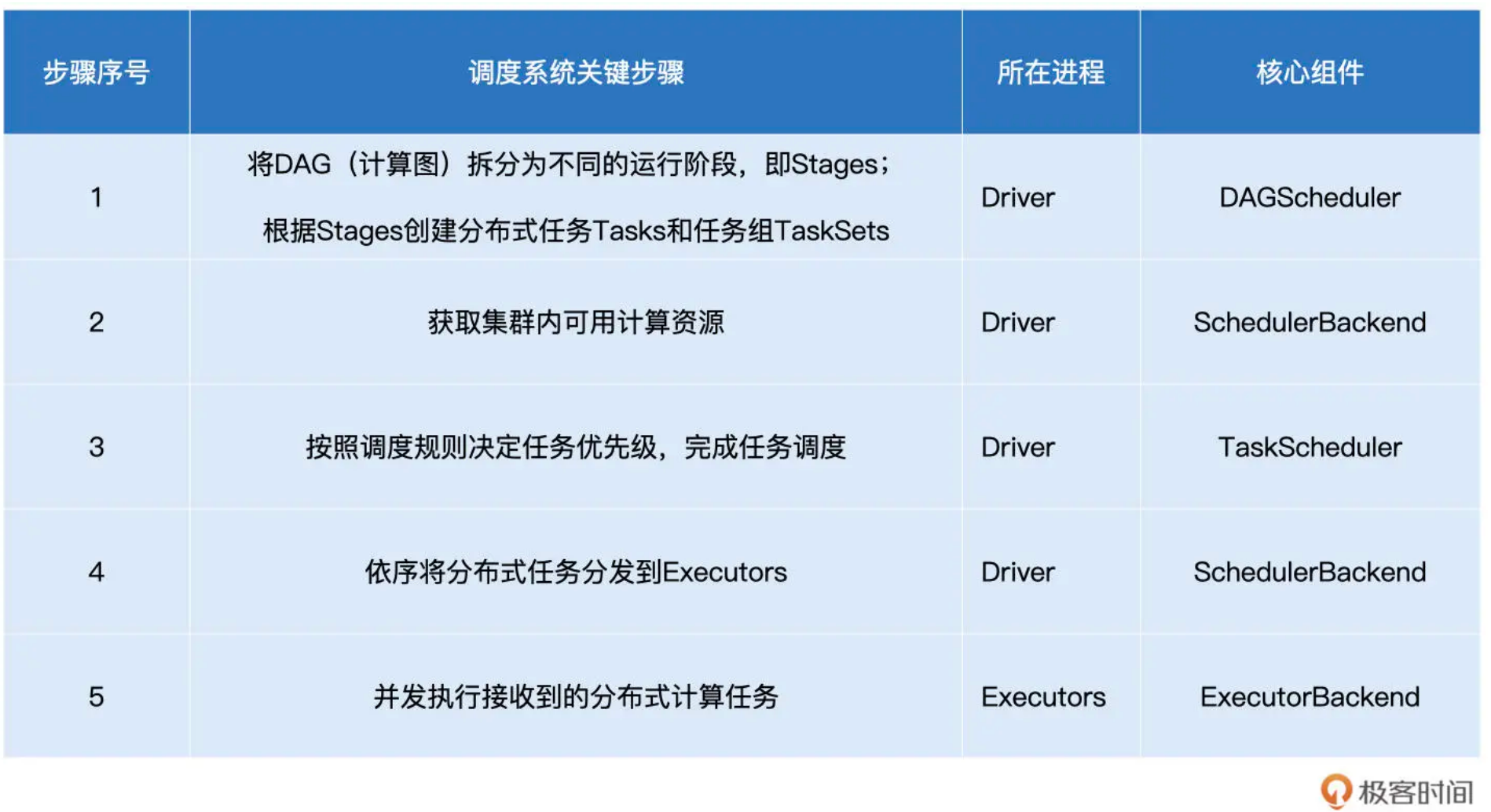
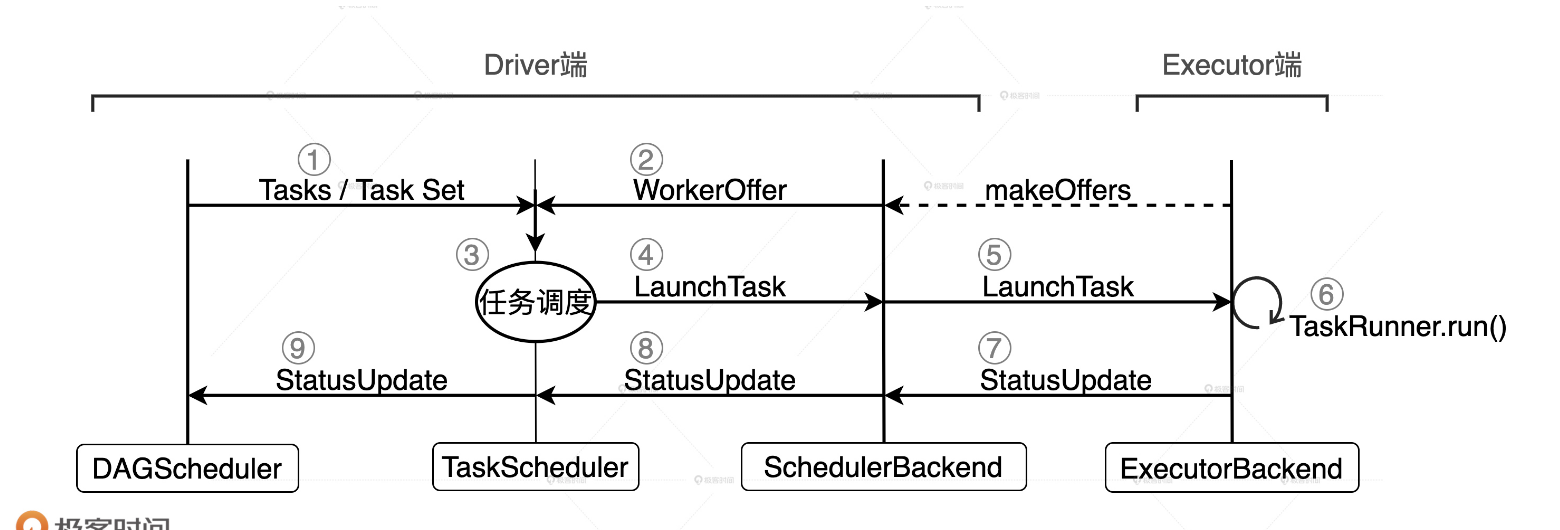
DAGScheduler 以 Shuffle 为边界,将开发者设计的计算图 DAG 拆分为多个执行阶段 Stages,然后为每个 Stage 创建任务集 TaskSet。
SchedulerBackend 通过与 Executors 中的 ExecutorBackend 的交互来实时地获取集群中可用的计算资源,并将这些信息记录到 ExecutorDataMap 数据结构。
与此同时,SchedulerBackend 根据 ExecutorDataMap 中可用资源创建 WorkerOffer,以 WorkerOffer 为粒度提供计算资源。
对于给定 WorkerOffer,TaskScheduler 结合 TaskSet 中任务的本地性倾向,按照 PROCESS_LOCAL、NODE_LOCAL、RACK_LOCAL 和 ANY 的顺序,依次对 TaskSet 中的任务进行遍历,优先调度本地性倾向要求苛刻的 Task。
被选中的 Task 由 TaskScheduler 传递给 SchedulerBackend,再由 SchedulerBackend 分发到 Executors 中的 ExecutorBackend。Executors 接收到 Task 之后,即调用本地线程池来执行分布式任务。
调度优化,具体怎么做的?
spark有三个Schedule
1、DAGScheduler 图构建和拆分 根据用户代码构建 DAG,DAG中根据action算子划分成多个job,
SchedulerBackend 资源调度和分发
2TaskScheduler Task分发 按照任务的本地倾向性,来遴选出 TaskSet 中适合调度的 Tasks定向到节点,定向的策略有:进程(Executor)、机架、任意地址。
3.Spark默认是FIFO调度,但是我们同时有IO任务和CPU任务,在一个分区内进行,因此用future异步和Fair调度实现了更快的IO任务和CPU任务调度形态。改了TaskScheduler这部分的代码
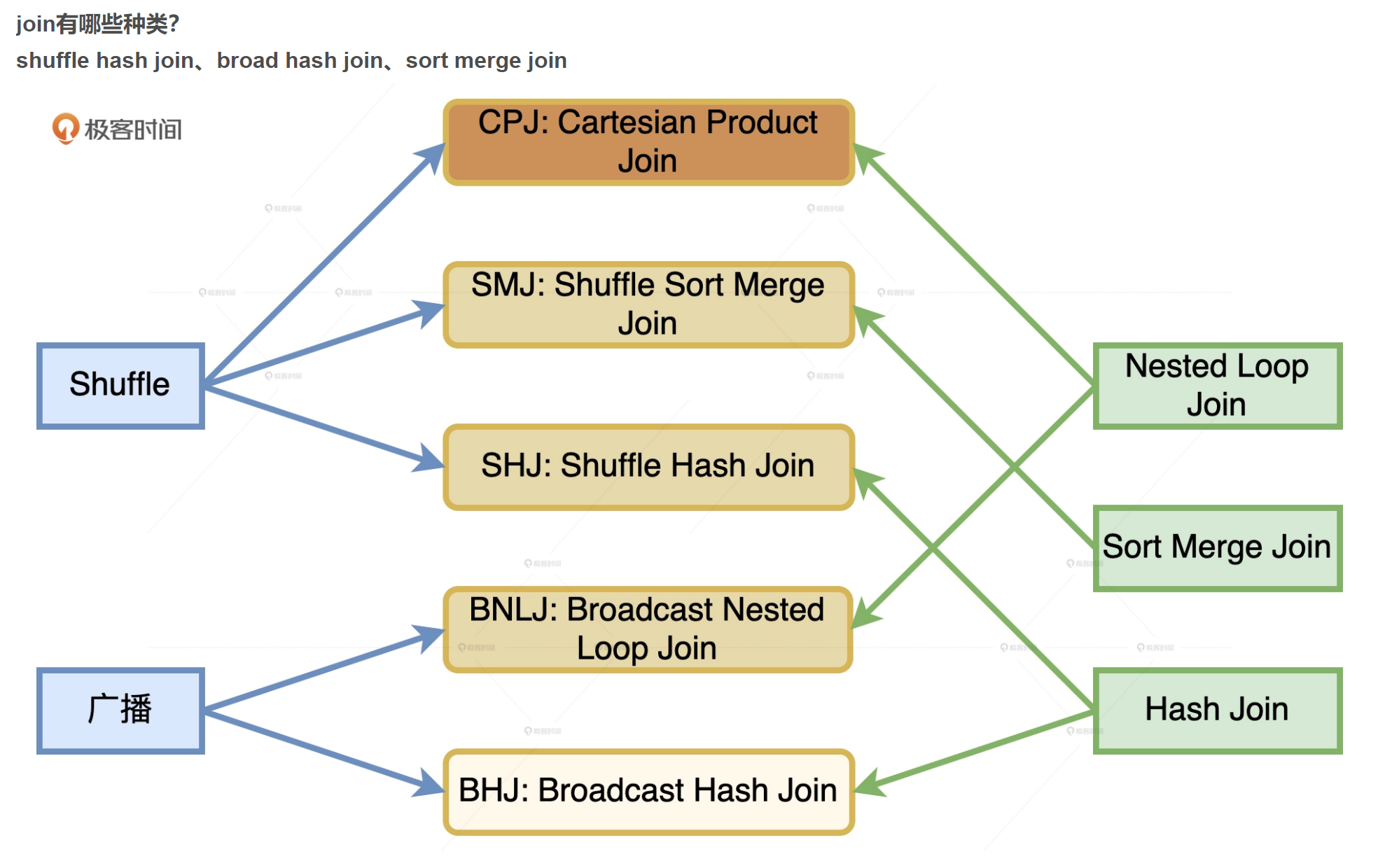
join有哪些种类?
shuffle hash join、broad hash join、sort merge join
如何解决数据倾斜问题
1.暴力加并行度 repartition(指标不治本,大多数情况下很可能没用)(200MB为好,如果有问题的话,可能导致有些副本小,有些副本很大)
2.两阶段聚合 第一阶段加随机前缀,然后聚合,第二阶段去掉前缀,然后做一轮聚合(解决不了join问题, 需要对应hash到同一个task)**
3. 过滤倾斜的key
4. 转换成map join(广播变量发送小表 只适合小表和大表join)
5. 使用AQE AQE能处理task粒度的问题,能够减少reduce阶段的数据消耗
大表join大表怎么优化
1、能转换的转换为broadcast hash join 内表有分区键的时候 分治,把大表拆分成小表 转化为broadcast hash join
2.不能转换的转换成shuffle hash join 没有分区键但是两个表的数据均匀的时候 使用shuffle hash join ,使用 /*+ shuffle_hash(orders) */ 保证数据分片能放入内存
3.有倾斜的先处理倾斜 两个表的数据有倾斜 先处理倾斜(1)依赖AQE,减少reduce阶段的数据消耗(以Task为粒度,改善不了executer的负载问题) (2)通过处理倾斜的手段
AQE有哪些优化?
join策略调整 如果过滤后小于广播变量阈值,那么使用broadcast hash join
自动分区合并 合并shuffle后过小的数据分区
自动倾斜处理 拆分reduce阶段的数据分区 降低task工作负载 (不能减少map阶段shuffle文件的开销)
Spark怎么做容错的
(1)Stage输出失败,上层调度器DAGScheduler重试。
(2)Spark计算中,Task内部任务失败,底层调度器重试。
(3)RDD Lineage血统中窄依赖、宽依赖计算。
(4)Checkpoint缓存。
spark算子分为transformer算子和action算子,transformer算子进行数据形态变化,action算子进行收集
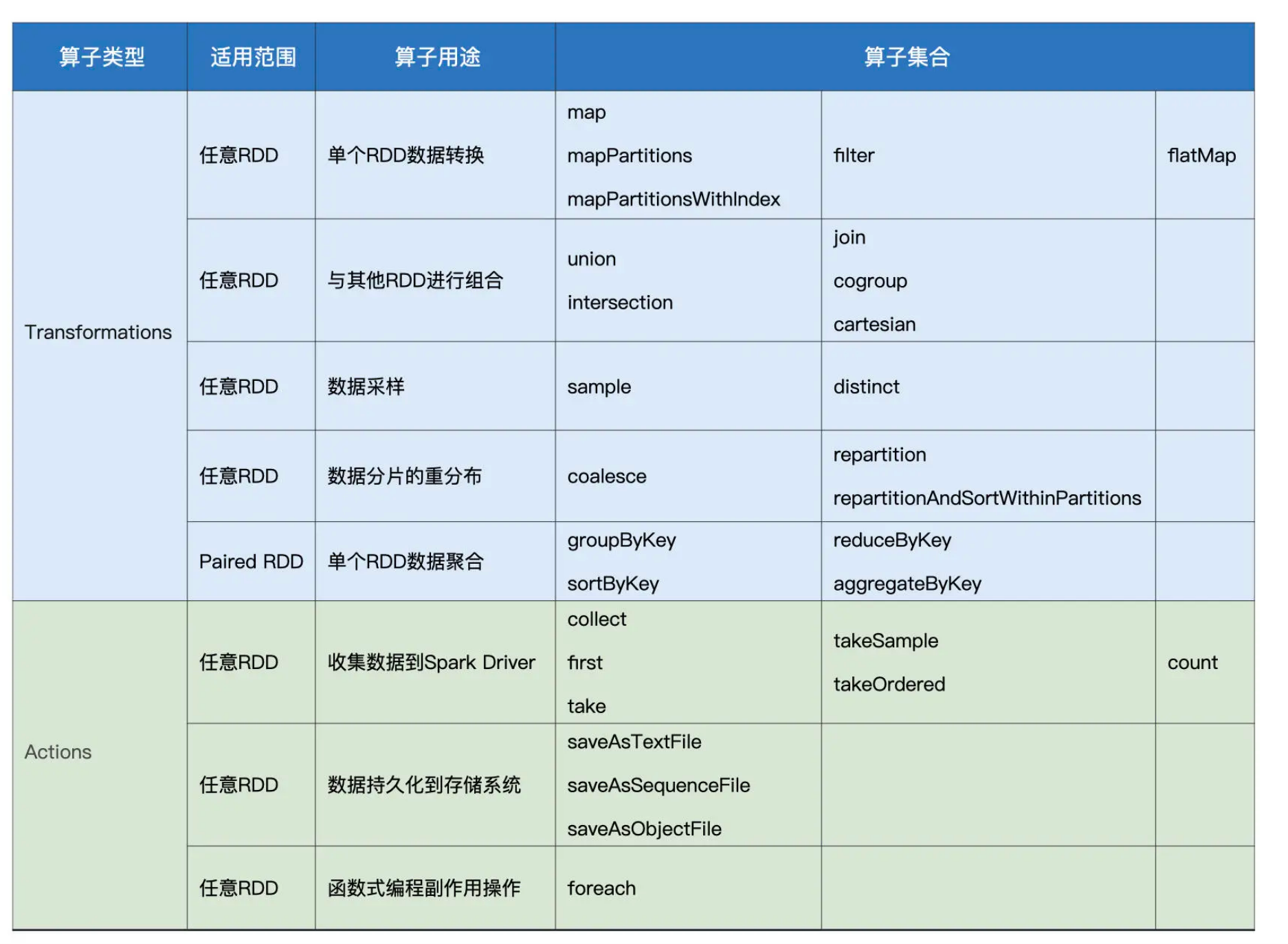
什么时候使用map?什么时候使用mapPartitions?
以每条数据为粒度时使用map,以每个分区为粒度时使用mapPartitions
shufffle过程
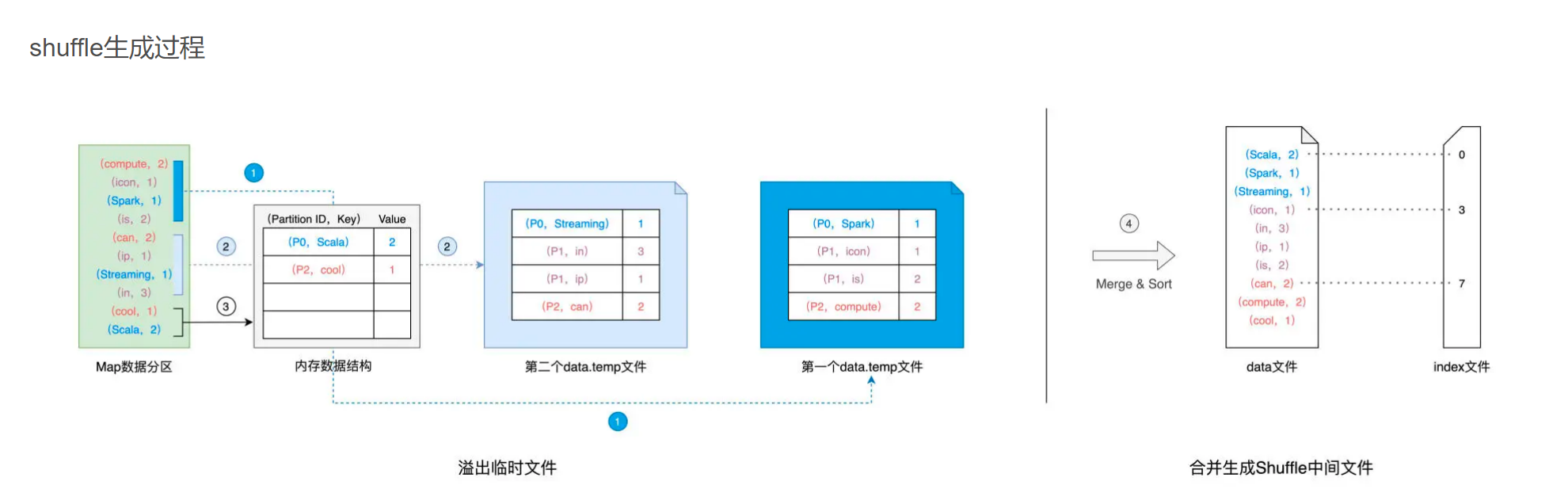
在生成中间文件的过程中,**Spark 会借助一种类似于 Map 的数据结构,来计算、缓存并排序数据分区中的数据记录。**这种 Map 结构的 Key 是(Reduce Task Partition ID,Record Key),而 Value 是原数据记录中的数据值,如图中的“内存数据结构”所示。
对于数据分区中的数据记录,Spark 会根据我们前面提到的公式 1 逐条计算记录所属的目标分区 ID,然后把主键(Reduce Task Partition ID,Record Key)和记录的数据值插入到 Map 数据结构中。当 Map 结构被灌满之后,Spark 根据主键对 Map 中的数据记录做排序,然后把所有内容溢出到磁盘中的临时文件,如图中的步骤 1 所示。
随着 Map 结构被清空,Spark 可以继续读取分区内容并继续向 Map 结构中插入数据,直到 Map 结构再次被灌满而再次溢出,如图中的步骤 2 所示。就这样,如此往复,直到数据分区中所有的数据记录都被处理完毕。
到此为之,磁盘上存有若干个溢出的临时文件,而内存的 Map 结构中留有部分数据,Spark 使用归并排序算法对所有临时文件和 Map 结构剩余数据做合并,分别生成 data 文件、和与之对应的 index 文件,如图中步骤 4 所示。Shuffle 阶段生成中间文件的过程,又叫 Shuffle Write。
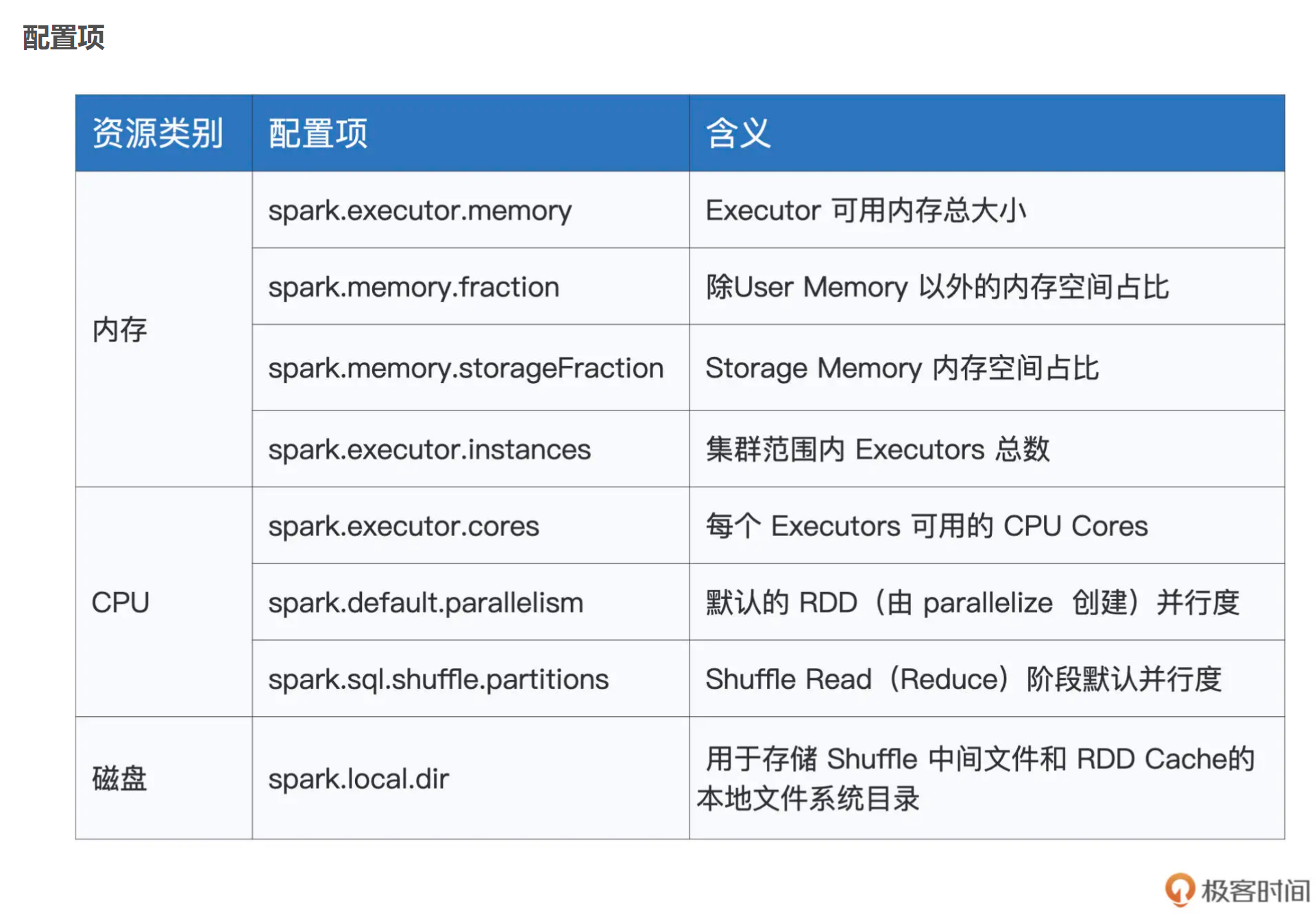
内存

Catalyst
Catalyst 优化器,它的职责在于创建并优化执行计划,它包含 3 个功能模块,分别是创建语法树并生成执行计划、逻辑阶段优化和物理阶段优化。
在 Catalyst 优化环节,Spark SQL 首先把用户代码转换为 AST 语法树,又叫执行计划,然后分别通过逻辑优化和物理优化来调整执行计划。逻辑阶段的优化,主要通过先验的启发式经验,如谓词下推、列剪枝,对执行计划做优化调整。而物理阶段的优化,更多是利用统计信息,选择最佳的执行机制、或添加必要的计算节点。
Tungsten
Tungsten 用于衔接 Catalyst 执行计划与底层的 Spark Core 执行引擎,它主要负责优化数据结果与可执行代码。
Tungsten 设计并实现了一种叫做 Unsafe Row 的二进制数据结构。Unsafe Row 本质上是字节数组,它以极其紧凑的格式来存储 DataFrame 的每一条数据记录,大幅削减存储开销,从而提升数据的存储与访问效率。
Unsafe Row模仿了操作系统的寻址方式,记录物理地址和页偏移,在堆区获取对象。
Spark 存储系统用于存储 3个方面的数据,分别是RDD 缓存、Shuffle 中间文件、广播变量。我们一个一个来说。
- RDD缓存:一些计算成本和访问频率较高的RDD,可以以缓存的形式物化到内存或磁盘中。这样一来,既可以避免DAG频繁回溯的计算开销,也能有效提升端到端的执行性能
- Shuffle:Shuffle中间文件的位置信息,都是由Spark存储系统保存并维护的,没有存储系统,Shuffle是玩不转的
- 广播变量:利用存储系统,广播变量可以在Executors进程范畴内保存全量数据,让任务以Process local的本地性级别,来共享广播变量中携带的全量数据。
今天,我们围绕RDD的核心痛点,探讨了DataFrame出现的必然性,Spark Core的局限性,以及它和Spark SQL的关系,对Spark SQL有了更深刻的理解。
RDD的核心痛点是优化空间有限,它指的是RDD高阶算子中封装的函数对于Spark来说完全透明,因此Spark对于计算逻辑的优化无从下手。
相比RDD,DataFrame是携带Schema的分布式数据集,只能封装结构化数据。DataFrame的算子大多数都是普通的标量函数,以消费数据列为主。但是,DataFrame更弱的表示能力和表达能力,反而为Spark引擎的内核优化打开了全新的空间。
根据DataFrame简单的标量算子和明确的Schema定义,借助Catalyst优化器和Tungsten,Spark SQL有能力在运行时,构建起一套端到端的优化机制。这套机制运用启发式的规则与策略和运行时的执行信息,将原本次优、甚至是低效的查询计划转换为高效的执行计划,从而提升端到端的执行性能。
在DataFrame的开发模式下,所有子框架、以及PySpark,都运行在Spark SQL之上,都可以共享Spark SQL提供的种种优化机制,这也是为什么Spark历次发布新版本、Spark SQL占比最大的根本原因。