1 selenium简介
2 使用selenium爬取百度案例
3 selenium窗口设置
1 selenium简介
'''
【一】web自动化
随着互联网的发展,前端技术也在不断变化,数据的加载方式也不再是单纯的服务端渲染了。
现在你可以看到很多网站的数据可能都是通过接口的形式传输的,
或者即使不是接口那也是一些 JSON 的数据,然后经过 JavaScript 渲染得出来的。
这时,如果你还用 requests 来爬取内容,那就不管用了。
因为 requests 爬取下来的只能是服务器端网页的源码,这和浏览器渲染以后的页面内容是不一样的。
因为,真正的数据是经过 JavaScript 执行后,渲染出来的,数据来源可能是 Ajax,也可能是页面里的某些 Data,或者是一些 ifame 页面等。
不过,大多数情况下极有可能是 Ajax 接口获取的。
所以,很多情况我们需要分析 Ajax请求,分析这些接口的调用方式,通过抓包工具或者浏览器的“开发者工具”,找到数据的请求链接,然后再用程序来模拟。
但是,抓包分析流的方式,也存在一定的缺点。
因为有些接口带着加密参数,比如 token、sign 等等,模拟难度较大;
那有没有一种简单粗暴的方法,
这时 Puppeteer、Pyppeteer、Selenium、Splash 等自动化框架出现了。
使用这些框架获取HTML源码,这样我们爬取到的源代码就是JavaScript 渲染以后的真正的网页代码,数据自然就好提取了。
同时,也就绕过分析 Ajax 和一些 JavaScript 逻辑的过程。
这种方式就做到了可见即可爬,难度也不大,同时适合大批量的采集。
【二】Selenium
作为一款知名的Web自动化测试框架,支持大部分主流浏览器,提供了功能丰富的API接口,常常被我们用作爬虫工具来使用。
然而selenium的缺点也很明显
速度太慢
对版本配置要求严苛
最麻烦是经常要更新对应的驱动
selenium最初是一个自动化测试工具,
而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,
比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
'''
【一】使用selenium需要安装第三方框架包
pip install selenium【二】chorme驱动
http://chromedriver.storage.googleapis.com/index.html?path=114.0.5735.90/
https://googlechromelabs.github.io/chrome-for-testing/#stable
下载并解压 ---> chromedriver.exe# 复制到当前文件夹下from selenium import webdriver
import time# 实例化得到一个 chrome 对象
browser = webdriver.Chrome()# 调用 browser 对象打开网页
browser.get('https://www.baidu.com/')time.sleep(10)# 这里点击代码运行后发现没有调用浏览器并且控制台无反应,夯住了
# 原因是因为 selenium 第一次调用 驱动的时候会很慢2 使用selenium爬取百度案例
from selenium import webdriver
from selenium.webdriver.common.by import By
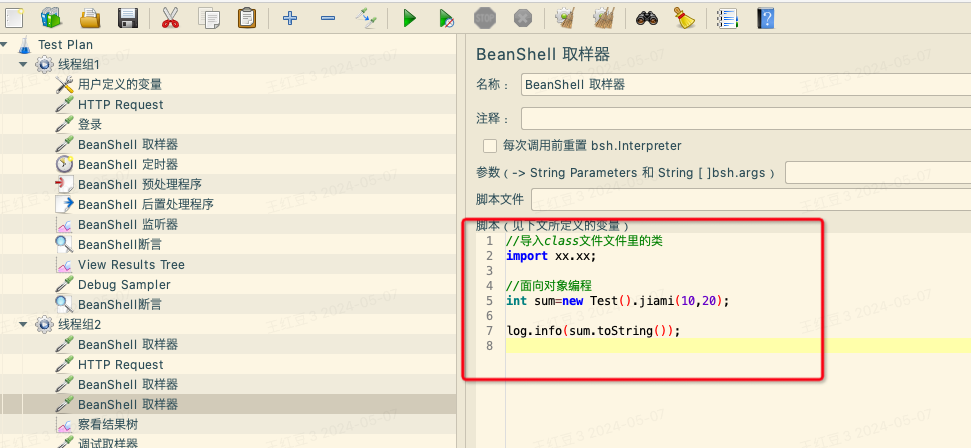
from fake_useragent import UserAgentclass BaseBrowser:def __init__(self):self.browser = webdriver.Chrome()self.headers = {'User-Agent': UserAgent().random}class SpiderBaidu(BaseBrowser):def __init__(self):super(SpiderBaidu, self).__init__()self.index_url = 'https://www.baidu.com/'def spider_baidu_index(self):# 1.打开百度首页self.browser.get(self.index_url)# 2.解析页面数据抓取页面数据# 【二】解析页面数据抓取页面数据# 【1】css选择器# find_element :类似于 find 只能招一个标签# self.browser.find_element()# find_elements : find_all 找很多个标签# self.browser.find_elements()# 以前是 tree ---> xpath# soup ---》 css'''find_elements 里面有一个参数 叫 byfrom selenium.webdriver.common.by import By一共有以下几种选择器ID = "id"XPATH = "xpath"LINK_TEXT = "link text"PARTIAL_LINK_TEXT = "partial link text"NAME = "name"TAG_NAME = "tag name"CLASS_NAME = "class name"CSS_SELECTOR = "css selector"'''# li_list = self.browser.find_elements(By.CSS_SELECTOR, '#hotsearch-content-wrapper > li')# print(li_list)# 2)xpath语法li_list = self.browser.find_elements(By.ID, 'hotsearch-content-wrapper')print(li_list)if __name__ == '__main__':s = SpiderBaidu()s.spider_baidu_index()3 selenium窗口设置
'''注意:把驱动chromedriver.exe放在你的环境变量(python解释器),这样可以直接初始化页面
'''import random# 【一】驱动位置的问题
# 确保你有驱动并且,在当前路径下最好
# 可以放到在系统环境变量中存在的指定的路径下
# 我将驱动添加到了 Python解释器路径下tag_url = 'https://www.baidu.com/'
from selenium import webdriver
import timebrowser = webdriver.Chrome()browser.get(tag_url)def sleep_time():time.sleep(random.randint(1, 3))# 【二】访问页面
# 浏览器对象.get(目标地址) ---> 打开网页
# 浏览器.close() ---> 关闭浏览器窗口# 【三】设置当前浏览器窗口的大小# 设置当前浏览器的窗口
browser.set_window_size(400,400)
# 打开窗口至全屏
browser.maximize_window()# 【四】前进和后退browser.get('https://www.baidu.com')
sleep_time()browser.get('https://www.jd.com/')
sleep_time()# 回退到百度页面
browser.back()
sleep_time()# 回到京东页面
browser.forward()
sleep_time()# 关闭浏览器
browser.close()# 【五】获取当前浏览器的基础属性
browser.get(tag_url)# 网页标题
print(browser.title)
# 百度一下,你就知道# 网页的当前网址
print(browser.current_url)
# https://www.baidu.com/# 当前浏览器的名称
print(browser.name)
# chrome# 查看网页的源码
print(browser.page_source)
# 我正常通过 requests 模块携带 UA 请求过返回的响应的页面源码数据# 【六】切换选项卡
browser.get(tag_url)
sleep_time()# 打印当前浏览器的句柄对象
print(browser.window_handles)
# ['73FE2519DFCC0953B45DC3094C835139']# 控制selenium 在当前窗口打开一个新的窗口
# 执行js代码
browser.execute_script('window.open("https://www.jd.com/")')
sleep_time()# 切换当前窗口至另一个窗口
# 当前浏览器的句柄对象
all_handles = browser.window_handles
print(all_handles)browser.switch_to.window(all_handles[0])
sleep_time()# 再打开新的网页
browser.get('https://pic.netbian.com/')
sleep_time()