本篇文章,我们聊聊如何使用 Docker 来本地部署使用 Stability AI 刚刚推出的 SDXL 1.0,新一代的开源图片生成模型,以及在当前如何高效的使用显卡进行推理。
写在前面
好久没有写 Stable Diffusion 相关的内容了,趁着 SDXL 刚刚推出,写一篇如何使用 Docker 快速上手的教程吧。
这篇文章应该是目前网络上不多的详细的实践内容了,包含如何绕开目前开源组件中的各种坑,快速上手的经验。
相关的代码,我已经上传到了 GitHub。
开源项目地址是:soulteary/docker-sdxl 和以往一样,同样欢迎“一键三连”~
其实,关于 Stable Diffusion 的文章,我之前写过三篇了:《在搭载 M1 及 M2 芯片 MacBook设备上玩 Stable Diffusion 模型》、《使用 Docker 来快速上手中文 Stable Diffusion 模型:太乙》、《八十行代码实现开源的 Midjourney、Stable Diffusion “咒语”作图工具》。最后一篇文章中的开源项目 soulteary/docker-prompt-generator,在上半年微博、Twitter,还有对我来说更重要的同好交流平台 GitHub 上都火了一段时间,上了热榜。感兴趣的同学,也可以自行翻阅,试试看。
本篇文章,我们先聊聊使用显卡来玩 SDXL,CPU 推理和运行优化,我们在后续的文章中再聊。
准备工作
准备工作部分,我们还是只需要做两个工作:准备模型文件和模型运行环境。
关于模型运行环境,我们在之前的文章《基于 Docker 的深度学习环境:入门篇》中聊过,就不赘述了,还不熟悉的同学可以阅读参考。
只要你安装好 Docker 环境,配置好能够在 Docker 容器中调用显卡的基础环境,就可以进行下一步啦。
下载 SDXL 的运行环境代码
模型运行环境和相关的代码,我已经上传到 soulteary/docker-sdxl 项目中了,我们直接下载就好:
# 使用 Git 下载
git clone https://github.com/soulteary/docker-sdxl.git# 或者,下载 Zip 代码包
wget https://github.com/soulteary/docker-sdxl/archive/refs/heads/main.zip
# 解压缩压缩包
unzip main.zip
# 重命名目录
mv docker-sdxl-main docker-sdxl
代码下载完毕,切换工作目录到 docker-sdxl 中,待后续使用。
# 切换工作目录
cd docker-sdxl
下载模型文件
官方发布的模型文件在 HuggingFace,就基础使用而言,我们可以主要关心下面三个模型:
- 基础模型:stabilityai/stable-diffusion-xl-base-1.0
- 精炼模型:stabilityai/stable-diffusion-xl-refiner-1.0
- 超分模型:stabilityai/sd-x2-latent-upscaler
# 确认你已经安装过 Git LFS https://git-lfs.comgit lfs install
# 下载基础模型
git clone https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0# 下载精炼模型
git clone https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0# 下载超分模型
git clone https://huggingface.co/stabilityai/sd-x2-latent-upscaler
如果你下载遇到困难,可以访问项目 soulteary/docker-sdxl 首页,使用网盘地址(网盘地址如果失效,前往 GitHub 提 issue 更新地址)。
当我们下载完毕下面三个模型后,整理下目录结构,将 stabilityai 模型目录放置到上文中的 docker-sdxl 里,准备工作就完成啦。
目录结构类似下面这样:
├── docker
├── LICENSE
├── README.md
├── scripts
│ ├── make-sdxl-base.sh
│ ├── make-sdxl-one-click.sh
│ └── make-sdxl-runtime.sh
├── src
└── stabilityai├── sd-x2-latent-upscaler├── stable-diffusion-xl-base-1.0└── stable-diffusion-xl-refiner-1.0
使用 Docker 容器使用 SDXL
如果你不熟悉也不太想折腾容器构建,可以使用预先构建好的运行环境镜像。
预构建的 SDXL 运行镜像
镜像文件包含了 Nvidia PyTorch 镜像,所以尺寸比较大,大概 20GB 左右。
目录中包含两种镜像,Nvidia PyTorch 镜像和公版 PyTorch 搭配 xformers 的镜像,选择其中一个就行,个人推荐前者。
下载地址:网盘地址(网盘地址如果失效,前往 GitHub 提 issue 更新地址)
完成镜像下载之后,我们使用下面的命令导入镜像,然后可以跳转到 “使用 Docker 运行 SDXL 文章小节”:
docker load -i sdxl-runtime.tar
# 或
docker load -i sdxl-runtime-xformers.tar
成功执行命令后,我们能够看到类似下面的提示:
Loaded image: soulteary/sdxl:runtime
# 或
Loaded image: soulteary/sdxl:runtime-xformers
构建 SDXL 模型应用程序
构建模型的基础应用,我们依旧选择 Nvidia 官方镜像,版本选择最新的稳定版:nvidia/pytorch:23.07-py3。
确保我们的工作目录在 docker-sdxl 中后,分别执行:
# 构建基础镜像
bash scripts/make-sdxl-base.sh
# 构建运行时镜像
bash scripts/make-sdxl-runtime.sh
命令执行后,需要耐心等待一段时间,构建脚本会自动从 Nvidia 下载基础镜像,并完成关键的 PyTorch 生态依赖的安装。
完成后,我们执行 docker images 能够找到类似下面两个镜像文件:
REPOSITORY TAG SIZE
soulteary/sdxl runtime-xformers 25.1GB
soulteary/sdxl runtime 20.2GB
虽然我们会看到还有两个 20G 左右的文件,这里可能有同学会有存储恐慌,但大可不必。
因为Docker 使用分层存储,实际上不会有重复的 4 个 20G 的文件,而是基于一个相同的 20G 文件,4个镜像有各自的增量存储内容。
使用 Docker 运行 SDXL 1.0 正式版
上文中我们构建了运行镜像,也准备好了模型文件,就可以通过 Docker 命令,快速进入可以玩 SDXL 的容器内的交互式命令行啦:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v `pwd`/stabilityai/:/app/stabilityai -p 7860:7860 soulteary/sdxl:runtime
进入终端后,我们有三种玩法(三个 python 程序和一个模型目录):
# ls
basic.py refiner-low-vram.py refiner.py stabilityai
只使用基础模型:python basic.py,默认启动将消耗 7.6G 显存,峰值使用 11G 显存,提供基础的 SDXL 绘图能力。
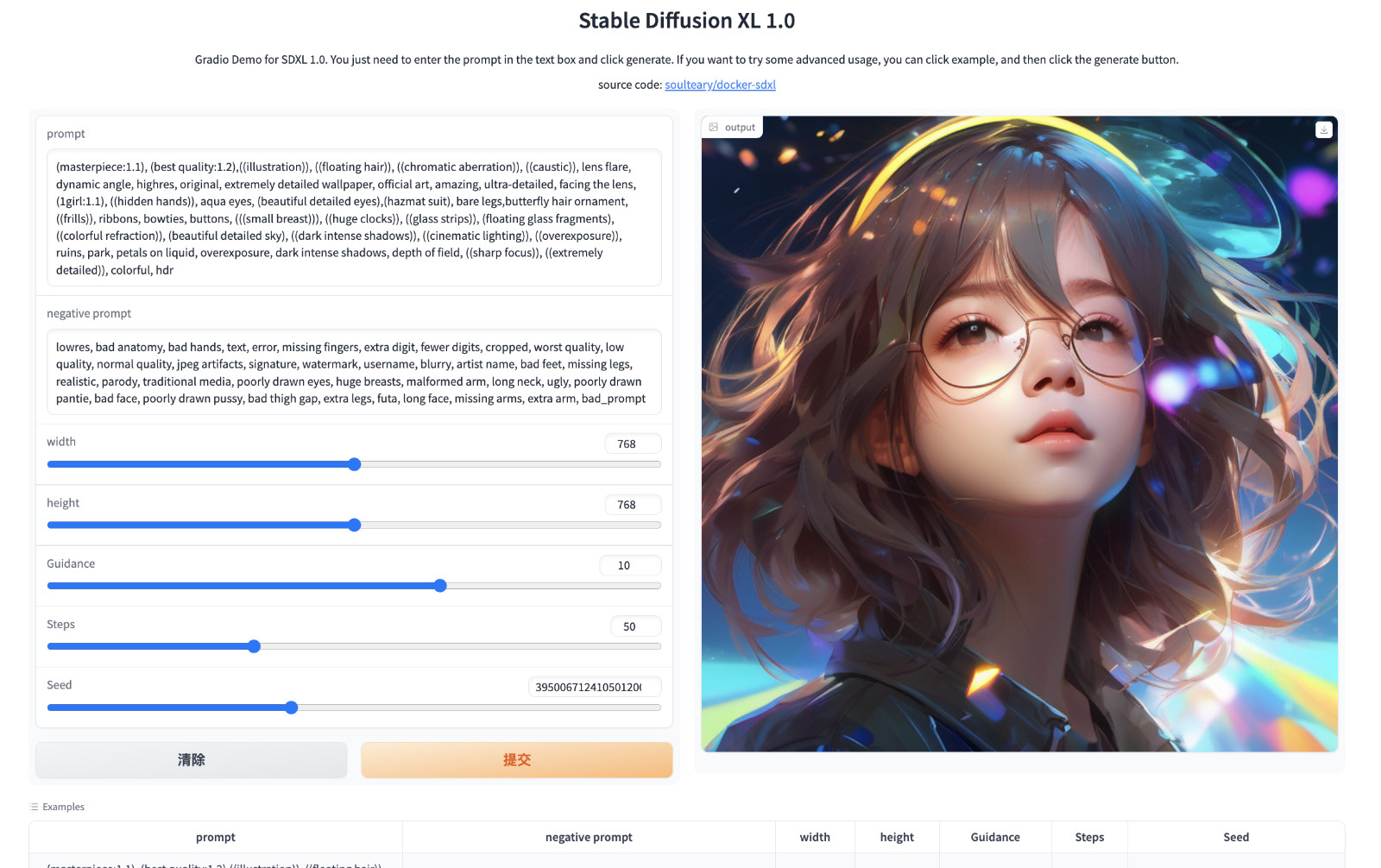
使用 SDXL 全家桶:python refiner.py,默认启动使用 14G 显存,不启用超分辨率,峰值消耗 18G 显存,如果启用超分辩率(upscale),则需要消耗 20G 显存,提供图片绘制、精炼优化、分辨率提升三种能力。
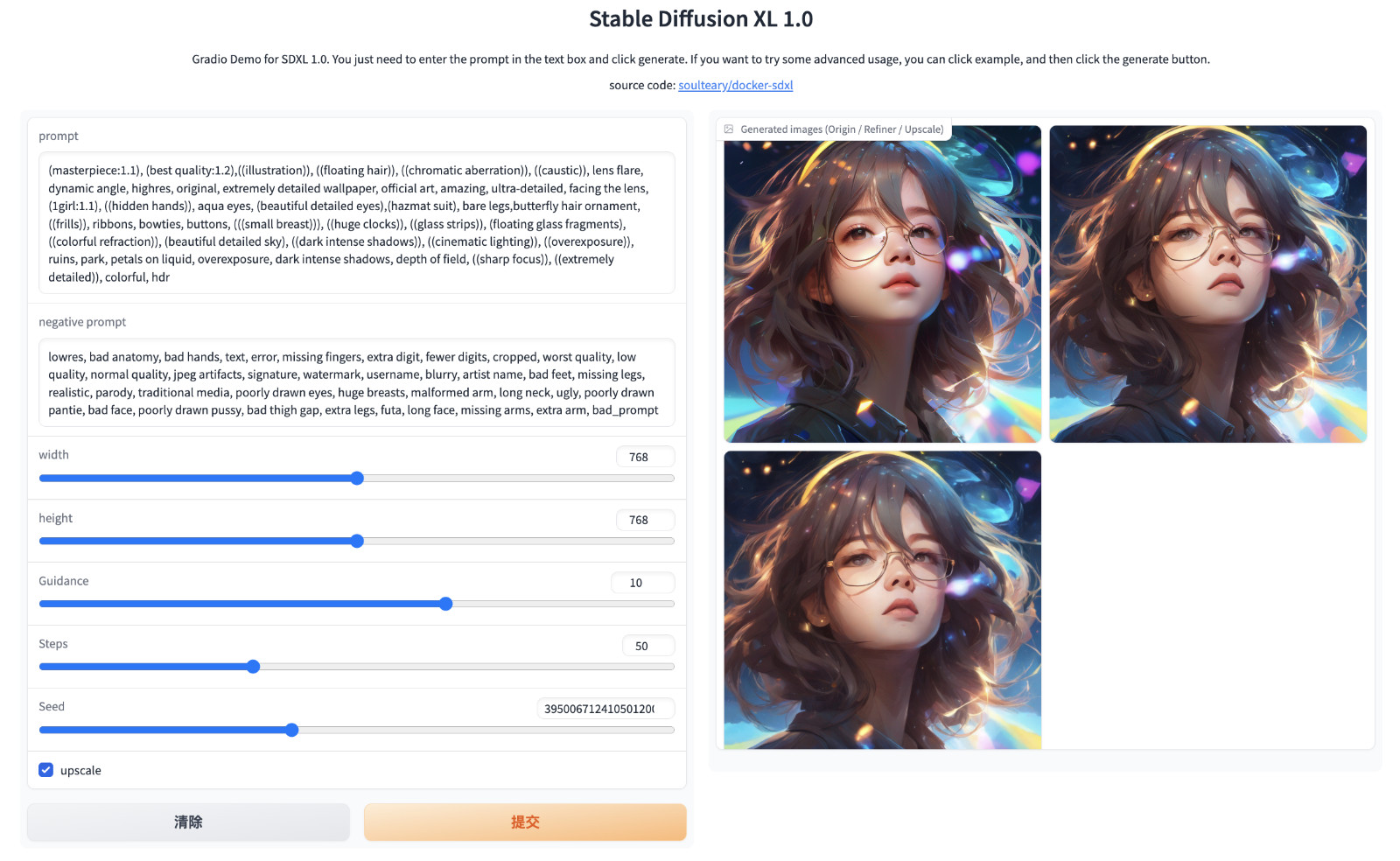
使用节约内存版程序:python refiner-low-vram.py,默认启动 500MB 显存占用,当我们不启用超分时,最多时显存占用 8G,启用超分辨率,则会最多消耗 16GB 显存。当然,省显存的代价就是需要不停的从硬盘或内存中读取模型到显存,存在数据交换的成本,生成图片的时间比前两种方案要长一些。
不论你选择哪一种方式运行 SDXL ,当你看到终端日志输出内容中有类似下面的内容时:
Running on local URL: http://0.0.0.0:7860To create a public link, set `share=True` in `launch()`.
打开浏览器,访问 http://localhost:7860 或者 http://你的IP:7860,就可以开始玩啦。
默认的容器版本,我选择了 Nvidia PyTorch 版本,而 HuggingFace 的 SDXL 依赖 xformers 和“公版” Pytorch,你可以根据自己的喜好选择使用,想使用后者的话,也很简单,只需要调整 Docker 命令种中的镜像名称即可:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v `pwd`/stabilityai/:/app/stabilityai -p 7860:7860 soulteary/sdxl:runtime-xformers
好了,基础的环境准备、镜像构建和镜像运行我们就聊到这里。
SDXL 开源社区踩坑和脱困
在 SDXL 发布几天后,不少开源软件的 Bugs 都有改观,所以这篇文章需要描述和解释的内容少了不少。
不过,依旧存在一些有趣的细节。
提升 Diffusion Pipeline 执行效率
不少开源项目都会将 Diffusion Pipeline 放到 imagine 这类绘图函数中:
def imagine(prompt, negative_prompt, width, height, scale, steps, seed, upscaler):pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0",torch_dtype=torch.float16,variant="fp16",use_safetensors=True,local_files_only=True,).to("cuda")
...
除非搭配 gc 类功能一起使用,起到小内存使用多种模型的作用外,一般来说弊大于利:
- 需要更长时间来进行推理,使用体验不是那么好。
- 模型尺寸一般都比较大,反复读取硬盘,对于质量不是那么好的硬盘,大概率会有一些使用寿命损失。
所以,在实现模型推理程序时,我们可以考虑将 Diffusion Pipeline 缓存在显存内,避免重复加载,以及提升“推理前准备工作的速度”:
def get_base_pipeline():pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0",torch_dtype=torch.float16,variant="fp16",use_safetensors=True,local_files_only=True,).to("cuda")return pipebase_pipeline = get_base_pipeline()def imagine(prompt, negative_prompt, width, height, scale, steps, seed, upscaler):base_image = get_base_image(prompt, negative_prompt, width, height, scale, steps, seed)refiner_image = refiner_pipeline(prompt=prompt, negative_prompt=negative_prompt, image=base_image).images[0]
...
当然,如果你内存比较大,把模型文件扔内存中,或者做一个简单的 ramdisk (过往文章有提)也问题不大。
xformers 带来的暂时性性能劣化
在之前使用 SD 1.0、1.5、2.x 的时候,我们一般会安装 xformers 来进行推理速度提升。
在 Stable diffusion XL 文档中,HuggingFace 的同学,有提醒如果 Torch 版本在 2.0 以下,需要安装 xformers 来启用 xformers attention 来加速推理。
但是漏了提醒,如果使用大于 2.0 版本的 Torch,将会带来性能劣化,默认安装之后,会进行本地编译构建,完成安装后会提醒我们有一些组件版本不兼容:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torch-tensorrt 1.5.0.dev0 requires torch<2.2,>=2.1.dev, but you have torch 2.0.1 which is incompatible.
torchdata 0.7.0a0 requires torch==2.1.0a0+b5021ba, but you have torch 2.0.1 which is incompatible.
torchtext 0.16.0a0 requires torch==2.1.0a0+b5021ba, but you have torch 2.0.1 which is incompatible.
torchvision 0.16.0a0 requires torch==2.1.0a0+b5021ba, but you have torch 2.0.1 which is incompatible.
所以,我们还需要进一步执行命令,安装剩余的依赖:
pip install torchvision torchtext torchdata torch-tensorrt
但即使完成依赖修正,推理速度也会停留在 6.98it/s 左右。而如果使用 Nvidia PyTorch 镜像中的 Torch 版本,则至少能够达到 12.84it/s 左右,性能差距接近一倍。
所以,暂时最好不要安装 xformers。
额外的,如果选择继续使用 xformers ,在执行程序的时候,会看到类似下面的错误提醒:
Traceback (most recent call last):
...
...import transformer_engine_extensions as tex
ImportError: /usr/local/lib/python3.10/dist-packages/transformer_engine_extensions.cpython-310-x86_64-linux-gnu.so: undefined symbol: _ZN3c10ltERKNS_6SymIntE
目前唯一靠谱的解决方案是参考 microsoft/TaskMatrix/issues/116,卸载掉 transformer-engine:
# pip uninstall transformer-engine -yFound existing installation: transformer-engine 0.9.0
Uninstalling transformer-engine-0.9.0:Successfully uninstalled transformer-engine-0.9.0
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
最后
接下来几篇和 SD 相关的内容,我会试着展开聊聊如何低成本进行 finetune,以及更有效率的执行模型。
作为 Midjourney 用户、身边有非常多小伙伴在用 “SD” 创业折腾,看到 Stable Diffusion 在不断进化,感触还是蛮深的:开源世界的技术在真真切切的、快速的推进着这个领域的软件生态、产品形态持续快速进化。
未来一定会有越来越多的人都认可的新技术带来的价值,并投身其中,非常期待更热闹的开源社区和更繁荣的 AI 应用生态。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上的一些问题,也会在群里不定期的分享一些技术资料。
喜欢折腾的小伙伴,欢迎阅读下面的内容,扫码添加好友。
关于“交友”的一些建议和看法
添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
苏洋:关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年07月29日
统计字数: 8600字
阅读时间: 18分钟阅读
本文链接: https://soulteary.com/2023/07/29/get-started-with-stability-ai-sdxl-1-0-release-using-docker.html






![[个人笔记] Windows配置NTP时间同步](https://img-blog.csdnimg.cn/26aa701a39ec4dae8a6552d0c2fbaf48.png)
![[golang gin框架] 40.Gin商城项目-微服务实战之Captcha验证码微服务](https://img-blog.csdnimg.cn/img_convert/57a89a899894d60f20d39f5c84fde3b5.png)