目录
1、面试官:Kafka是如何保证消息不丢失
2、面试官:Kafka中消息的重复消费问题如何解决的
3、面试官:Kafka是如何保证消费的顺序性
4、面试官:Kafka的高可用机制有了解过嘛
5、面试官:解释一下复制机制中的ISR
6、面试官:Kafka数据清理机制了解过嘛
7、面试官:Kafka中实现高性能的设计有了解过嘛
1、面试官:Kafka是如何保证消息不丢失
候选人:
嗯,这个保证机制很多,在发送消息到消费者接收消息,在每个阶段都有可能会丢失消息,所以我们解决的话也是从多个方面考虑
第一个是生产者发送消息的时候,可以使用异步回调发送,如果消息发送失败,我们可以通过回调获取失败后的消息信息,可以考虑重试或记录日志,后边再做补偿都是可以的。同时在生产者这边还可以设置消息重试,有的时候是由于网络抖动的原因导致发送不成功,就可以使用重试机制来解决
第二个在broker中消息有可能会丢失,我们可以通过kafka的复制机制来确保消息不丢失,在生产者发送消息的时候,可以设置一个acks,就是确认机制。我们可以设置参数为all,这样的话,当生产者发送消息到了分区之后,不仅仅只在leader分区保存确认,在follwer分区也会保存确认,只有当所有的副本都保存确认以后才算是成功发送了消息,所以,这样设置就很大程度了保证了消息不会在broker丢失
第三个有可能是在消费者端丢失消息,kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提价偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
2、面试官:Kafka中消息的重复消费问题如何解决的
候选人:
kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提价偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
为了消息的幂等,我们也可以设置唯一主键来进行区分,或者是加锁,数据库的锁,或者是redis分布式锁,都能解决幂等的问题
3、面试官:Kafka是如何保证消费的顺序性
候选人:
kafka默认存储和消费消息,是不能保证顺序性的,因为一个topic数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性
如果有这样的需求的话,我们是可以解决的,把消息都存储同一个分区下就行了,有两种方式都可以进行设置,第一个是发送消息时指定分区号,第二个是发送消息时按照相同的业务设置相同的key,因为默认情况下分区也是通过key的hashcode值来选择分区的,hash值如果一样的话,分区肯定也是一样的
4、面试官:Kafka的高可用机制有了解过嘛
候选人:
嗯,主要是有两个层面,第一个是集群,第二个是提供了复制机制
kafka集群指的是由多个broker实例组成,即使某一台宕机,也不耽误其他broker继续对外提供服务
复制机制是可以保证kafka的高可用的,一个topic有多个分区,每个分区有多个副本,有一个leader,其余的是follower,副本存储在不同的broker中;所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader,保证了系统的容错性、高可用性
5、面试官:解释一下复制机制中的ISR
候选人:
ISR的意思是in-sync replica,就是需要同步复制保存的follower
其中分区副本有很多的follower,分为了两类,一个是ISR,与leader副本同步保存数据,另外一个普通的副本,是异步同步数据,当leader挂掉之后,会优先从ISR副本列表中选取一个作为leader,因为ISR是同步保存数据,数据更加的完整一些,所以优先选择ISR副本列表
6、面试官:Kafka数据清理机制了解过嘛
候选人:
嗯,了解过~~
Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment
每个分段都在磁盘上以索引(xxxx.index)和日志文件(xxxx.log)的形式存储,这样分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理。
在kafka中提供了两个日志的清理策略:
第一,根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时( 7天)
第二是根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。这个默认是关闭的
这两个策略都可以通过kafka的broker中的配置文件进行设置
7、面试官:Kafka中实现高性能的设计有了解过嘛
候选人:
Kafka 高性能,是多方面协同的结果,包括宏观架构、分布式存储、ISR 数据同步、以及高效的利用磁盘、操作系统特性等。主要体现有这么几点:
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
顺序读写:磁盘顺序读写,提升读写效率
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
零拷贝:减少上下文切换及数据拷贝
消息压缩:减少磁盘IO和网络IO
分批发送:将消息打包批量发送,减少网络开销
八股kafka(一)
news/2024/5/21 2:44:59
相关文章

单词反转字符串函数设计
简单设计一个以单词为个体的字符串翻转函数/*************************************************** file name:ReverseWorld.c* author :eon4051@163.com* date :2024/05/11* brief :单词反转字符串函数设计* note :None** CopyRight (c) 2024 eon…
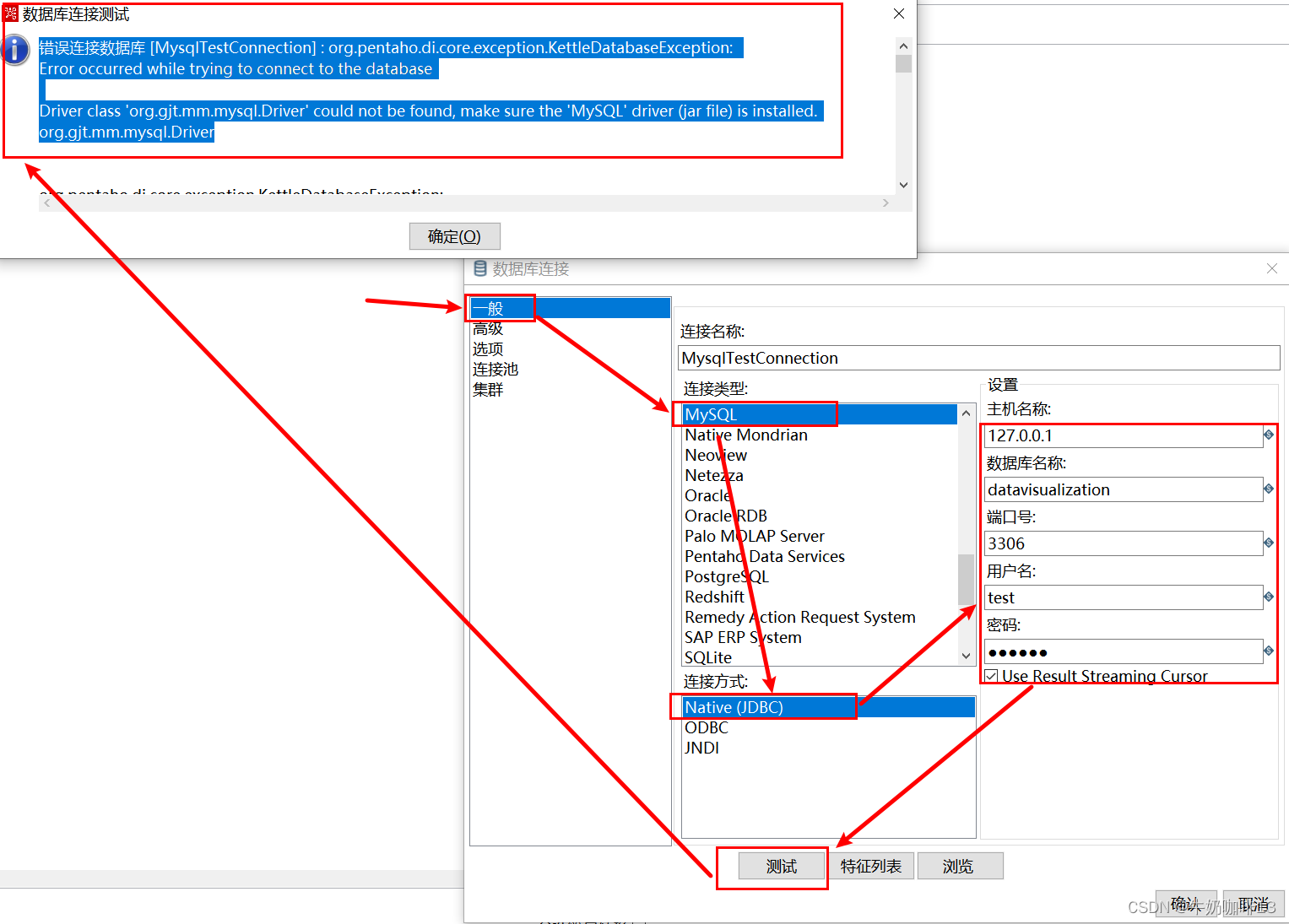
Kettle连接Mysql数据库时报错——Driver class ‘org.gjt.mm.mysql.Driver‘ could not be found
一、问题描述 当我们使用ETL工具Kettle需要连接Mysql数据库进行数据清洗操作,在配置好Mysql的连接串内容后,点击【测试】按钮时报错【错误连接数据库 [MysqlTestConnection] : org.pentaho.di.core.exception.KettleDatabaseException: Error occurred while trying to conne…

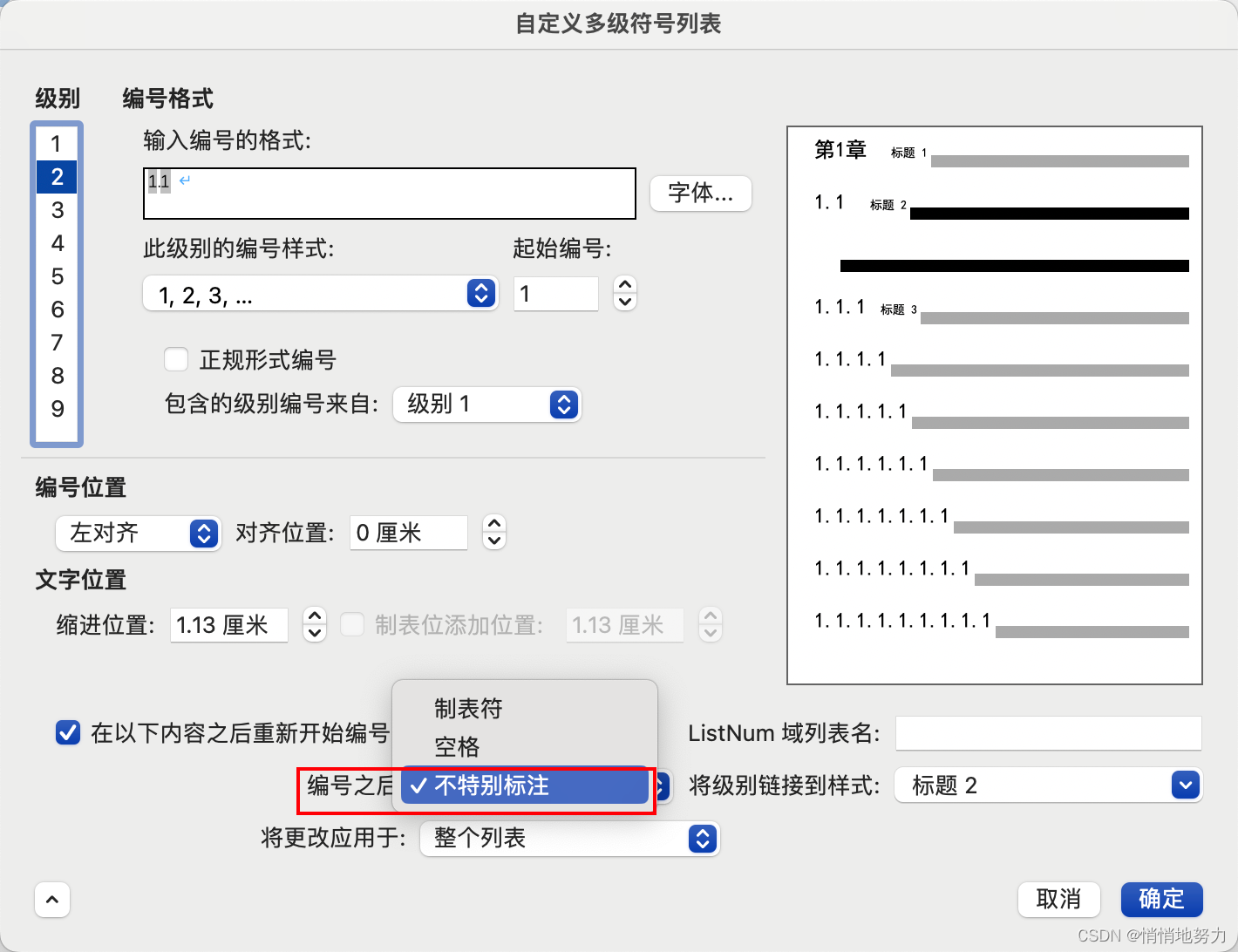
word 毕业论文格式调整
添加页眉页脚
页眉
首先在页面上端页眉区域双击,即可出现“页眉和页脚”设置页面:
页眉左右两端对齐
如果想要页眉页脚左右两端对齐,可以选择添加三栏页眉,然后将中间那一栏删除,即可自动实现左右两端对齐&#x…
Java毕设之学院党员管理系统的设计与实现
运行环境
环境说明: 开发语言:java 框架:springboot,vue JDK版本:JDK1.8 数据库:mysql5.7(推荐5.7,8.0也可以) 数据库工具:Navicat11 开发软件:idea/eclipse(推荐idea) Maven包:Maven3.3.9
系统实现
管理员功能实现
党员管理
管理员进入指定功能操作…
element ui的table多选
使用el-table的selection-change事件来获取选中的值; 例:
html代码:
<el-button type"primary" click"openTableSet">列表设置</el-button><!-- 列表设置弹框 -->
<el-dialog :close-on-click-mo…
【专题】中国银行业2023年发展回顾及2024年展望报告合集PDF分享(附原数据表)
原文链接 :https://tecdat.cn/?p=36145
原文出处:拓端数据部落公众号
2023年,尽管面临全球经济复杂多变与国内经济多重挑战,中国银行业依然稳健前行,不仅圆满完成了社会经济发展的主要任务,还以“稳进相济,进而有为”的姿态,为实体经济的高质量发展提供了有力支撑,展望…
Docker 加持的安卓手机:随身携带的知识库(一)
这篇文章聊聊,如何借助 Docker ,尝试将一台五年前的手机,构建成一个随身携带的、本地化的知识库。
写在前面
本篇文章,我使用了一台去年从二手平台购入的五年前的手机,K20 Pro。 为了让它能够稳定持续的运行…

现代移动端网络短连接的优化手段总结:请求速度、弱网适应、安全保障
1、前言
众所周之,通常开发一个移动端应用,会直接调用系统提供的网络请求接口去服务端请求数据,再针对返回的数据进行一些处理。
但对于追求用户体验的应用来说,还会针对移动网络的特性做进一步优化,包括:
1)速度优化:网络请求的速度怎样能进一步提升?
2)弱网适应:移…
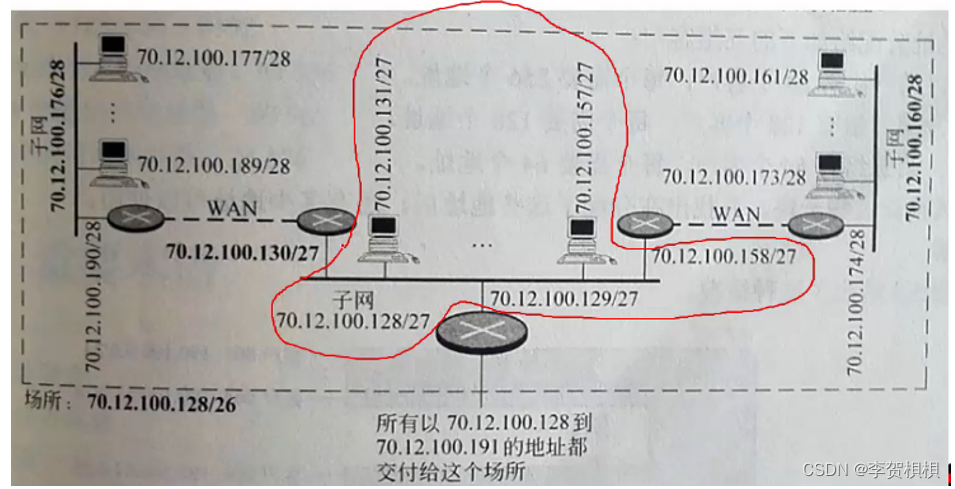
第08章 IP分类编址和无分类编址
8.1 本章目标
了解IP地址的用途和种类了解分类编址和无分类编址区别掌握IP地址、子网掩码、网关概念及使用掌握子网划分及超网划分方法掌握无分类编址的改变和使用
8.2 IP地址的用途和种类 分类编址:造成地址的浪费,以及地址不够用;无分类编…

JavaScript数字分隔符
● 如果现在我们用一个很大的数字,例如2300000000,这样真的不便于我们进行阅读,我们希望用千位分隔符来隔开它,例如230,000,000;
● 下面我们使用_当作分隔符来尝试一下
const diameter 287_266_000_000;
console.log(diameter)…

手机H5页面在IOS系统中无法获取Geolocation
需求
在开发H5页面的时候希望获取用户的地理位置信息,这里演示在用户上传图片的时候将用户的地理位置信息作为水印显示。
问题
在安卓手机使用vant-upload组件是没问题的,但是在IOS手机上有,报下面的提示信息。原因
苹果的IOS做了限制,如果需要使用IOS的服务,必须是HTTS协…
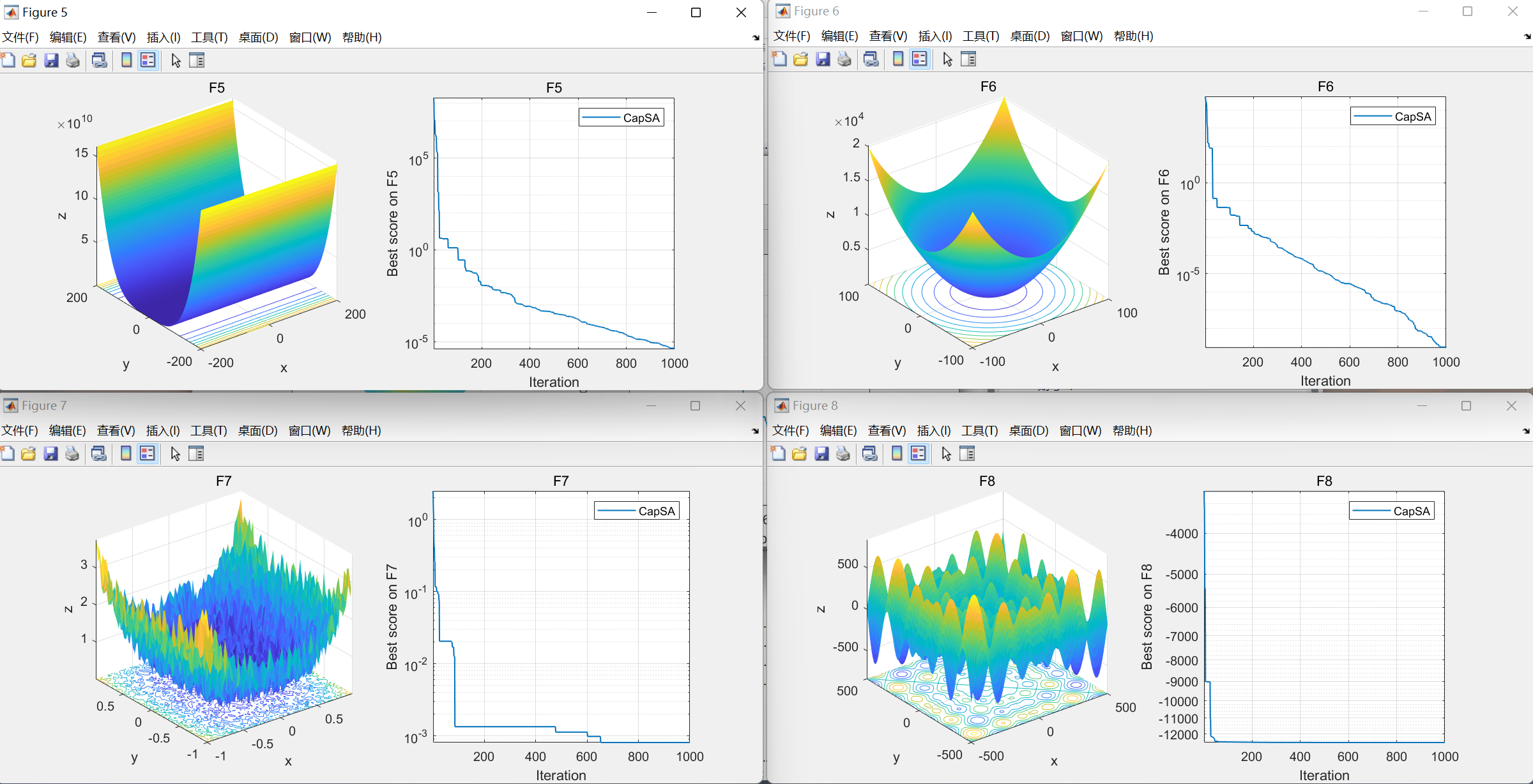
【智能优化算法】卷尾猴搜索算法(Capuchin search algorithm,CapSA)
【智能优化算法】卷尾猴搜索算法(Capuchin search algorithm,CapSA)是期刊“NEURAL COMPUTING & APPLICATIONS”(IF 6.0)的2021年智能优化算法
01.引言
【智能优化算法】卷尾猴搜索算法(Capuchin search algorithm,CapSA)用于解决约束和全局优化问…
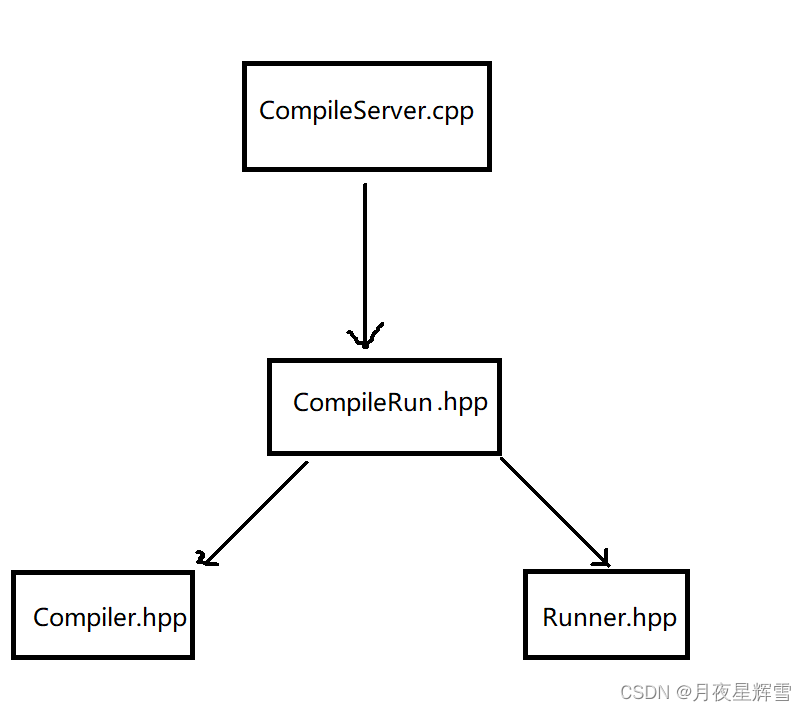
【负载均衡式在线OJ项目day4】编译运行功能整合及打包网络服务
一.前言
前面两天完成了编译和运行两个子模块,今天的任务是完成CompileRun模块,它的任务如下: 解析来自客户端的Json字符串,反序列化提取编译运行需要的数据,即代码,时间限制和空间限制把代码写入临时文件…
25-有参转录组实战11-上传转录组到NCBI
上传转录组到NCBI登录NCBI>点击submit>选SRA>选Project>点New submission
1 SUBMITTER
填写名字,邮件,no group,学校学院,街道邮编国家,continue
2 GENERAL INFO
填no BioProject, no BioSample,立马释放数据。
3 PROJECT INFO
填个title和description,no…


MySQL面试必备二之binlog日志
本文首发于公众号:Hunter后端
原文链接:MySQL面试必备二之binlog日志关于 binlog,常被问到几个面试问题如下:binlog 是什么
binlog 都记录什么数据
binlog 都有哪些类型,都有什么特点
如何使用 binlog 恢复数据
binlog 都有哪些作用
binlog 属于逻辑日志还是物理日志基于上…

Transformers中加载预训练模型的过程剖析
使用HuggingFace的Transformers库加载预训练模型来处理下游深度学习任务很是方便,然而加载预训练模型的方法多种多样且过程比较隐蔽,这在一定程度上会给人带来困惑。因此,本篇文章主要讲一下使用不同方法加载本地预训练模型的区别、加载预训练模型及其配置的过程,藉此做个记…
推荐文章
- 记录计全支付切换到RabbitMQ时启动报错的问题
- go的web开发框架gin(一)
- 计算机视觉全系列实战教程:(二)Opencv4+VS2022开发环境搭建
- tensorrtx-yolov5-v6.0部署在windows系统
- RPA的实施过程通常包括哪些步骤?
- Unity 模拟放大镜局部放大UI 效果实现
- 车道线检测|利用边缘检测的原理对车道线图片进行识别
- JavaScript--生成器函数
- Redis系列一:介绍
- web自动化测试-PageObject 设计模式
- 设计模式学习之开闭原则
- AVFoundation - 视频过渡
- 如何构建一个系统
- 06--加密逻辑
- 初步学习密码系统的安全性
- 05--抓包工具、PyExecjs模块
- 放逐过去 疗愈自己 (回忆录暂定)
- 5.21