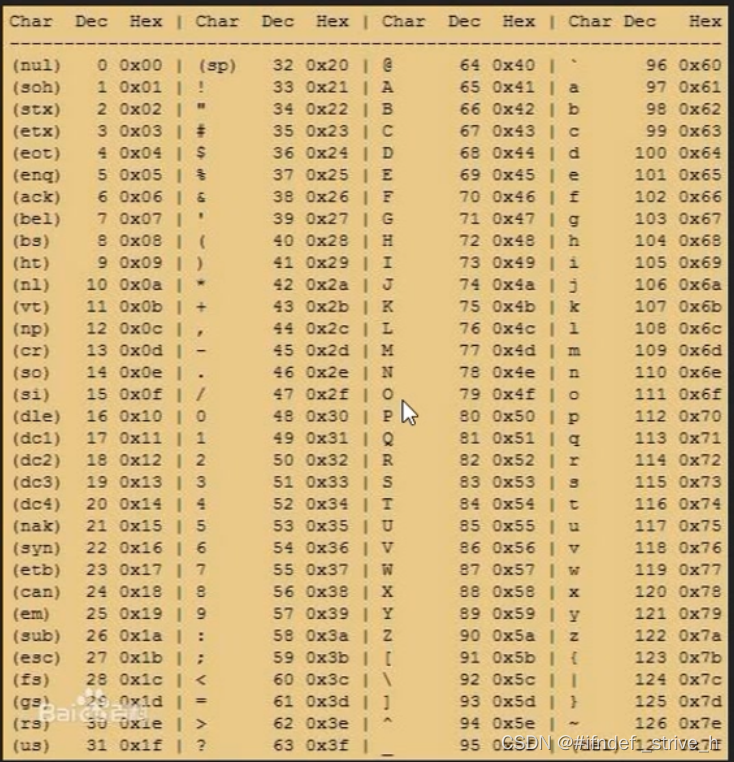
论文题目:Descriptor Distillation for Efficient Multi-Robot SLAM
中文题目:高效多机器人SLAM蒸馏描述符
作者:Xiyue Guo, Junjie Hu, Hujun Bao and Guofeng Zhang
作者机构:浙江大学CAD&CG国家重点实验室 香港中文大学(深圳)
论文链接:https://arxiv.org/pdf/2303.08420.pdf
本文通过生成具有最小推理时间的紧凑且具有判别性的特征描述符来解决多机器人探索过程中保持低水平通信带宽的同时进行精确定位的问题;文中将描述符生成转化为老师-学生框架下的学习问题。首先设计一个紧凑的学生网络,通过从预训练的大型教师模型中转移知识来学习它。为了减少从教师到学生的描述符维度,文中提出了一种新的损失函数,使知识在两个不同维度的描述符之间转移。
1 前言
多机器人SLAM系统(MR-SLAM系统)相比单机器人系统最主要的限制是:通信带宽的限制。在MR-SLAM系统中,为了整合整个团队的所有轨迹,团队中的每个机器人都需要共享其关键帧数据(包括关键帧姿态和观察到的特征点),以处理机器人间的闭环和全局定位。这种类型的数据交换占用了很高的通信容量,很可能降低实时性能。
一些工程上的解决方案比如降低频率、减少关键点数量可以降低通信带宽,但会导致定位精度降低;提高精度则会导致带宽升高;如果降低描述符维度会导致匹配性能变差。
卷积神经网络(CNN)方法已经显示出对手工描述符的优越性能,但基于CNN的方法多适用于单机器人系统(SR-SLAM),高模型复杂性和描述符维度是阻碍基于学习的方法在MR-SLAM中应用的两个主要障碍。
本文提出了一个基于知识蒸馏(KD)的描述符学习框架。该框架是一个经典的师生组合,其中学生是我们要学习的紧凑模型,而教师是一个预训练的更大的网络,其预测用于监督学生的学习。为了解决老师和学生之间输出维度的不同,本文还设计了一种新的损失函数。
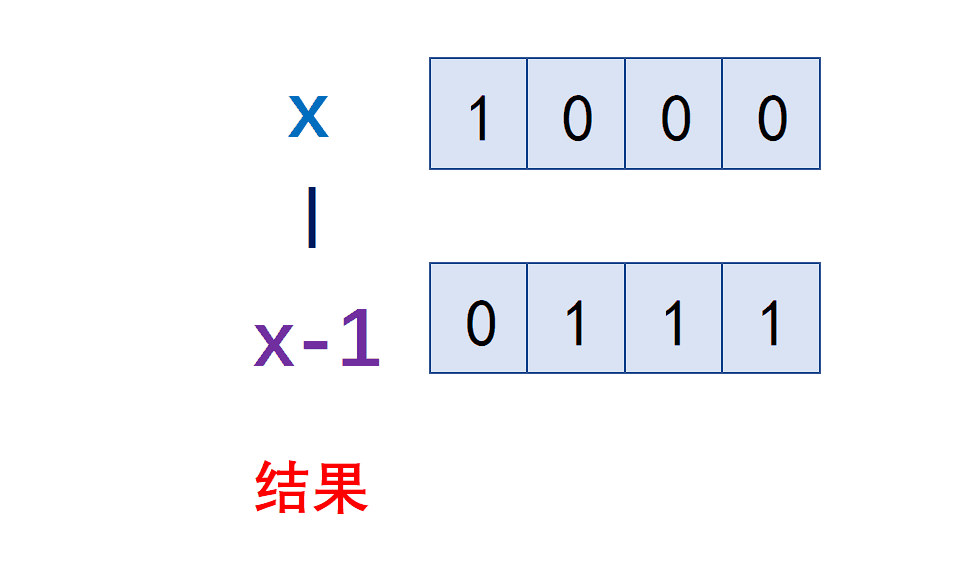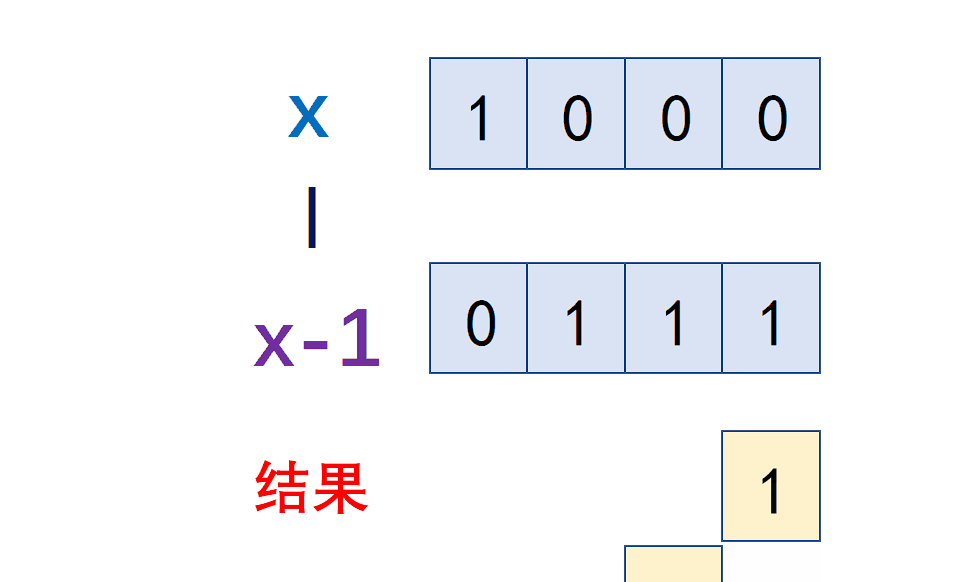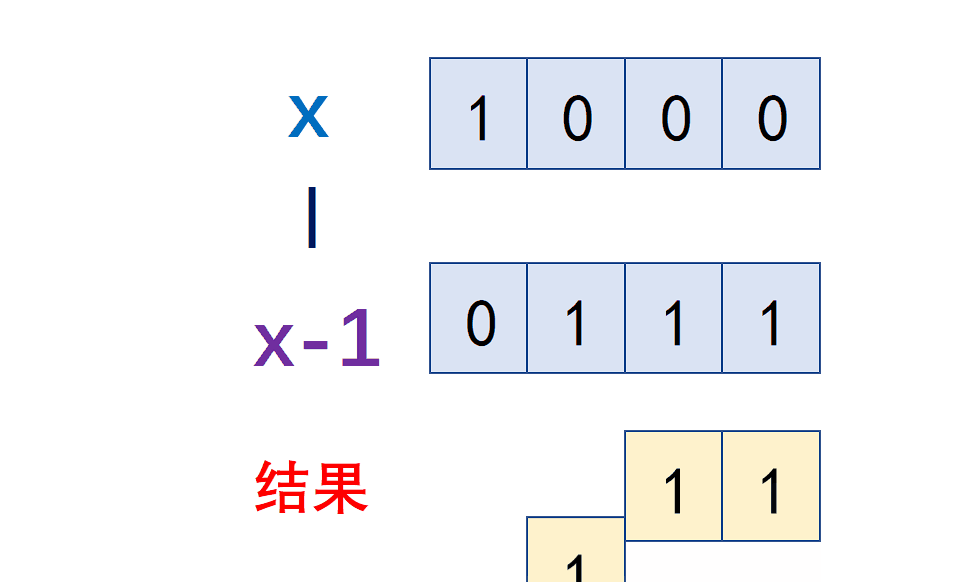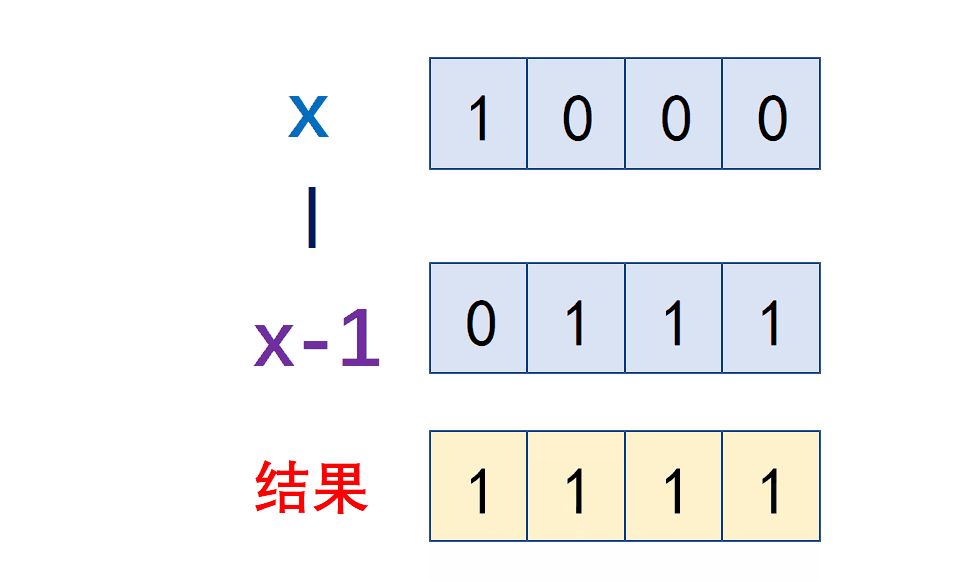
本文模型与传统模型的比较如下图所示:
本文主要贡献如下:
- 设计了一个师生模型来生成紧凑的二进制描述符。
- 提出了一种新的基于距离的蒸馏损失,它允许具有不同输出维度的模型之间的知识转移。
- 开发了一个基于新描述符模型的MR-SLAM系统作为评估平台。
2 算法框架
2.1 基于学习的描述符生成
本文类似于主流的CNN方法,通过Siamese框架结构学习描述符。它是一个双胞胎模型,在训练过程中共享相同的权重。在Siamese框架下,每个训练阶段都准备两批。批次中的每个图像块对另一个都是负的,同一时代的两个批是一一对应的。
它有两个主要的损耗用于训练:
- Triplet loss:它强制匹配的对尽可能接近,而不匹配的对尽可能远。最近的方法大多遵循HardNet策略,只提取包含最小距离的负对进行训练:
L T = ∑ i N m a x ( 0 , t + d i s ( R i , R p ) − d i s ( R i , R n ∗ ) ) L_{T}=\sum_i^N max(0,t+dis(R_{i},R_{p})-dis(R_{i},R_{n}^{*})) LT=i∑Nmax(0,t+dis(Ri,Rp)−dis(Ri,Rn∗))
R i R_i Ri为当前实值描述子, R p R_p Rp为对应的正描述子, R n ∗ R_{n}^{*} Rn∗为最接近的负描述子,n为批大小。dis计算两个描述符之间的L2距离。
- Binarization loss:它旨在最小化实值描述符与对应的二进制描述符之间的差异:
L B = ∑ i N ∑ k D 1 D ( R i ( k ) − B i ( k ) ) 2 L_{B}=\sum_i^N \sum_k^D \frac{1}{D}\sqrt{(R_{i}(k)-B_{i}(k))^2} LB=i∑Nk∑DD1(Ri(k)−Bi(k))2
B(k)为二进制描述子B的第k个值,R(k)为实值描述子R的第k个值,D为描述子的维数。
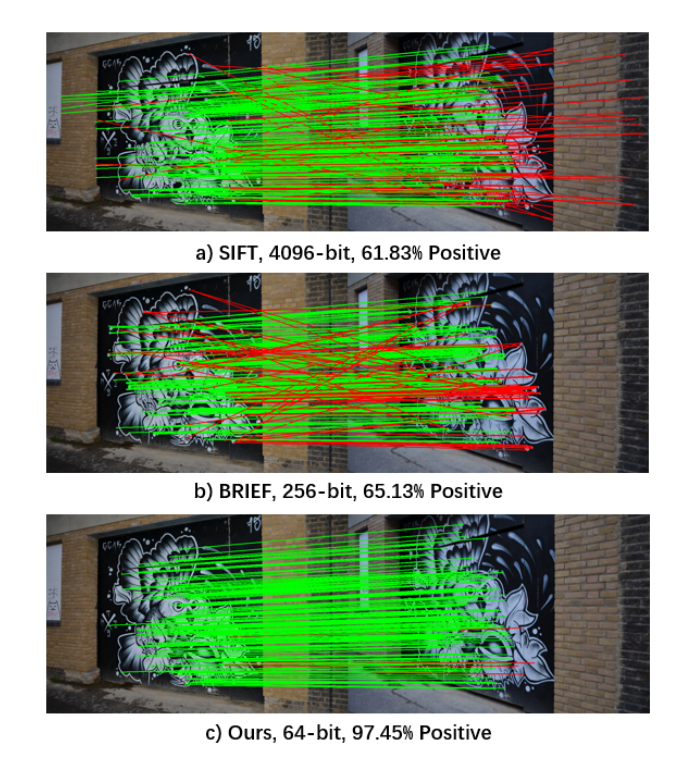
2.2 老师-学生蒸馏框架
如上图所示,所有的老师卷积层之后是滤波响应归一化(FRN)和阈值线性单元(TLU)。批处理归一化(BN)和l2归一化放在最后的卷积层之后。
学生卷积层第一部分是深度卷积,它对每个输入通道应用一个卷积滤波器。第二部分是1×1卷积,称为逐点卷积。
基于该体系结构,每个模型都能够将图像补丁嵌入到实值描述符中。为了得到二进制描述符,使用以下方程对实值描述符进行二值化:
B ( k ) = { − 1 , i f R ( k ) ≤ 0 1 , i f R ( k ) ≥ 0 B\left(k \right) =\left\{ \begin{array}{l} -1,\ \ \ \ if\ R(k)≤0\\ 1, \ \ \ \ \ \ \ if\ R(k)≥0\\ \end{array} \right. B(k)={−1, if R(k)≤01, if R(k)≥0
2.3 蒸馏损失函数
它由一个实值项和一个二元值项组成,它们分别强制学生模型的描述符批在实值和二元空间上具有与教师模型相似的分布。
实值项负描述符损失项:
L r e a l = ∑ i N ∑ n N n ( λ r d i s ( R i t , R n t ) − d i s ( R i s , R n s ) ) 2 L_{real}=\sum_i^N \sum_n^{N_{n}} \sqrt{(\lambda _{r}dis(R_{i}^{t},R_{n}^{t})-dis(R_{i}^{s},R_{n}^{s}))^2} Lreal=i∑Nn∑Nn(λrdis(Rit,Rnt)−dis(Ris,Rns))2
其中 N n N_n Nn是相对于当前描述符的负描述符的总数。 R t i R_t^i Rti和 R s i R_s^i Rsi分别是教师和学生产生的当前重估描述符, R t n R_t^n Rtn和 R s n R_s^n Rsn是相应的负描述符。此外,由于教师和学生之间的维度不同,我们增加了一个系数λr,设置为0.95来调整教师侧距离的尺度
二值项负描述符损失项:
L b i n = ∑ i N ∑ n N n 1 N n ( λ b d i s ( B i t , B n t ) − d i s ( B i s , B n s ) ) 2 L_{bin}=\sum_i^N \sum_n^{N_{n}} \frac{1}{N_n} \sqrt{(\lambda _{b}dis(B_{i}^{t},B_{n}^{t})-dis(B_{i}^{s},B_{n}^{s}))^2} Lbin=i∑Nn∑NnNn1(λbdis(Bit,Bnt)−dis(Bis,Bns))2
其中λb是缩放系数,通常设置为两个模型的输出维度之间的比率:Ds/Dt。在训练阶段的到二进制描述符计算公式:
B i = R i a b s ( R i ) + ϵ B_{i}=\frac{R_i}{abs(R_i)+\epsilon} Bi=abs(Ri)+ϵRi
这里 ϵ \epsilon ϵ是防止被0整除的系数,设为1e-5。
最后,将这两个损失项合并为蒸馏损失函数:
L d i s t i l l a t i o n = L r e a l + γ L b i n L_{distillation}=L_{real}+\gamma L_{bin} Ldistillation=Lreal+γLbin
其中 γ \gamma γ是二值项的加权系数。
2.4 学生训练
第一阶段,使用学习率为0.01的ADAM优化器训练教师模型。这个过程使模型能够生成高质量的128维描述符。基本损耗函数为:
L b a s i c = L T + α B L B L_{basic}=L_{T}+\alpha _BL_{B} Lbasic=LT+αBLB
其中 α B \alpha _B αB是控制二值化损失 L B L_B LB的加权系数。
在第二阶段,在老师的监督下训练学生模型,学习率设为0.01。因此,目标函数既包括基本损失Lbasic,也包括蒸馏损失Ldistillation,可表示为:
L t r a i n = L b a s i c + β L d i s t i l l a t i o n L_{train}=L_{basic}+\beta L_{distillation} Ltrain=Lbasic+βLdistillation
其中 β \beta β为蒸馏损失加权系数,在训练时设置为2。
3 实验与结果
3.1 特征匹配实验
使用UBC数据集:整个数据集包含大约400k个64×64个带标签的补丁,在一个子集上训练模型,并在另外两个子集上测试它。通过报告95%召回率(FPR95)的假阳性率来展示匹配性能。
采用几种方法作为基准方法。第一类是基于cnn的方法,包括HardNet、SOSNet、HyNet等。第二类方法是一些传统的方法,包括SIFT、BRIEF、LDAHash、BinBoost。还报告了每种CNN方法的参数数量和时间消耗(生成500个描述符),以可视化描述符生成效率。
此外,为了测试泛化能力,文章评估了在HPatches数据集上训练并在UBC数据集上测试的CNN方法的性能。
实验结果如下表所示:

- 由表1可以看出,基于cnn的方法明显优于传统方法。另一方面,匹配结果表明,即使没有蒸馏,所提出的方法也可以与大多数基于cnn的方法相媲美。此外,在KD方法的帮助下,文中的网络能够优于所有基线方法。
- 由表2可以看出,文中的模型比基线CNN模型轻30%左右,运行速度也比基线方法快。
- 由表3可以看出,因为尽管在不同的数据集上训练,但它的性能与CNN方法相当。
3.2 MR-SLAM实验
MR-VINS的详细框架如下图所示:
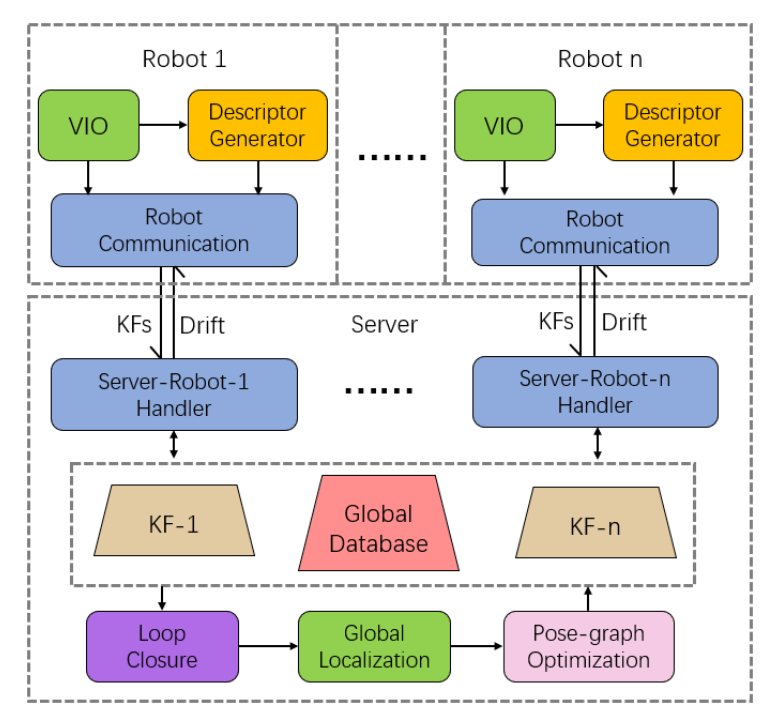
整个系统采用集中式架构,即MR-SLAM系统由多个机器人和一个中央服务器组成。将视觉惯性里程计模块放在机器人上,而将后端模块放在服务器上。在此框架的基础上,在机器人一侧添加了CNN描述符模型,主要将描述符用于循环闭合和全局定位。作者将描述符模型放在机器人通信模块之前,以便描述符可以集成到发送到服务器的关键帧消息中。
使用公共EuRoC数据集,采用定位精度和通信带宽两项指标进行评价。
SLAM精度的定量结果如下表所示。
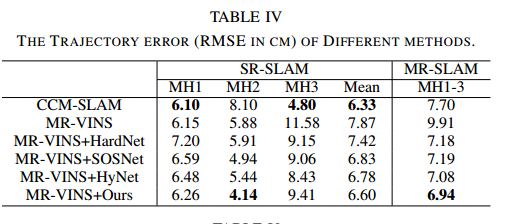
与原始MR-VINS相比,可以看出,基于cnn的方法能够提高定位性能,尤其是MR-SLAM。此外,在单机器人和多机器人任务上,文中的方法总体上达到了与CNN方法相当的精度。然而,由于SLAM的性能不仅仅取决于图像匹配,定位精度优势并不像特征匹配结果那么明显。
下表显示了不同SLAM系统的带宽。
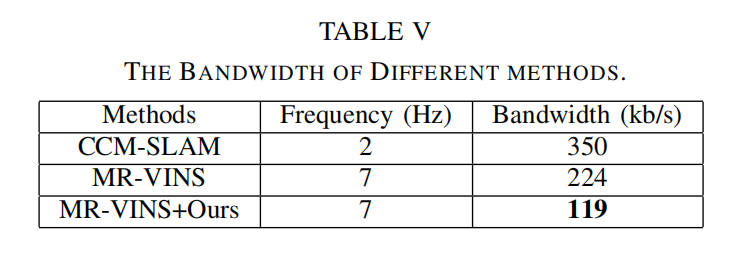
结果表明,文中的方法比原来的MR-VINS和CCM-SLAM具有更低的带宽。由于文中模型的消息频率是CCM-SLAM的3倍,所以文中模型的关键帧信息的大小比CCM-SLAM小10倍左右。窄带宽归因于文中的描述符极其紧凑的尺寸(普通BRIEF描述符的1/4)。此外,由于关键帧尺寸紧凑,就不需要在MR-SLAM任务期间专门降低关键帧频率。
4 总结
在本文中,探讨了如何学习MR-SLAM的紧凑描述符的问题。本文提出了一个师生框架,该框架利用紧凑的学生模型来估计低维描述符。由于教师和学生之间的输出维度不同,作者提出了一个基于距离的蒸馏损失函数,使知识在不同的维度描述符之间蒸馏传递。通过特征匹配实验和MR-SLAM系统的实验,验证了本文所提出算法的有效性。