享元模式
享元模式(Flyweight Pattern)是一种用于性能优化的设计模式,它通过共享尽可能多的相似对象来减少内存使用,尤其是在大量对象的情况下非常有效。这个模式是在对象数量多而对象状态大部分可共享的情况下实现的。
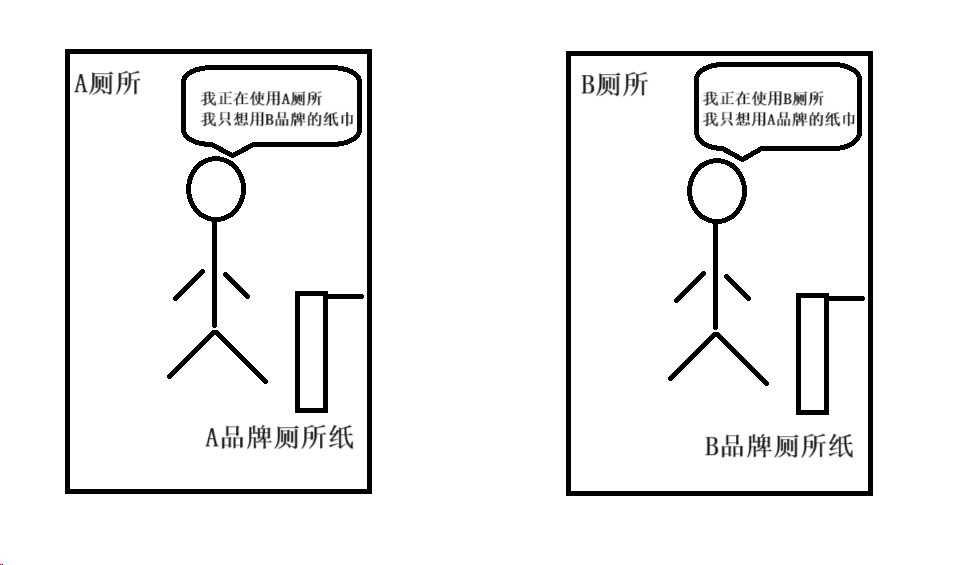
享元模式的核心在于区分内部状态和外部状态:
- 内部状态(Intrinsic State):这些状态是对象共享的,不随具体情境改变,通常存储在享元对象内部。
- 外部状态(Extrinsic State):这些状态依赖于具体的情境,并在享元对象的客户端维护和计算。
结构组成
- 享元接口(Flyweight):定义实现享元接口的对象的方法。
- 具体享元(Concrete Flyweight):实现享元接口的具体类,存储内部状态。
- 享元工厂(Flyweight Factory):创建和管理享元对象,确保合理地共享对象。
优点
- 减少对象的创建:通过共享大量细粒度的对象,减少系统中对象的数量。
- 降低内存占用:共享对象减少了内存占用,提高了性能。
- 更好的数据结构共享:通过分离变与不变,享元模式能在多个对象间更好地共享数据。
缺点
- 增加了系统的复杂度:需要分离内部和外部状态,这可能使系统设计更加复杂。
- 状态管理:外部状态必须由客户端来维护,这可能导致客户端代码变得复杂。
- 线程安全问题:在多线程环境下,享元对象的线程安全需要特别注意。
使用场景
- 大量相似对象的系统:在系统中存在大量相似对象,且它们的大部分状态可以外部化时。
- 内存约束较大的应用:如在移动设备或嵌入式系统中。
- 性能要求较高的场景:当应用需要高效地处理大量对象时。
- 对象状态大部分可共享:当对象的大多数状态可以共享,并且可以外部化时。
实际应用举例
- 字符串常量池(String Pool):Java中的String Pool是享元模式的一个经典例子。相同的字符串常量只存储一次。
- 图形编辑器中的形状对象:如在绘图程序中,同一种形状(如圆形、方形)的多个实例可以共享其形状相关的数据。
- 数据库连接池:数据库连接池中的连接对象可以被多个客户端共享,以减少频繁创建和销毁连接的开销。
在Java中经常遇到的面试题其实就是Integer中用到的享元模式了。
Integer 缓存机制
- Java 在 Integer 类中对介于 -128 到 127 之间的整数实现了缓存。当您使用 Integer.valueOf() 方法时,对于这个范围内的数字,它不会创建新的对象,而是返回预先创建的对象。
- 这种做法是享元模式的一个经典应用。在这个范围内的 Integer 对象是不变的,它们的内部状态(即整数值)是共享的。
为什么使用享元模式
- 对于小的整数,使用非常频繁,因此预先创建并重用这些对象可以显著减少总体内存占用,并避免频繁的对象创建和垃圾回收。
- 在很多程序中,特定范围的小整数被频繁使用,因此这种优化可以带来显著的性能提升。
特别注意
- 这种缓存机制只适用于通过 Integer.valueOf() 方法创建的 Integer 对象。如果你直接使用 new Integer() 构造函数,每次都会创建一个新的对象,即使数值相同。
- 自动装箱(例如,将 int 类型直接赋值给 Integer 对象)通常使用的是 Integer.valueOf() 方法,因此也会受益于这种缓存机制。
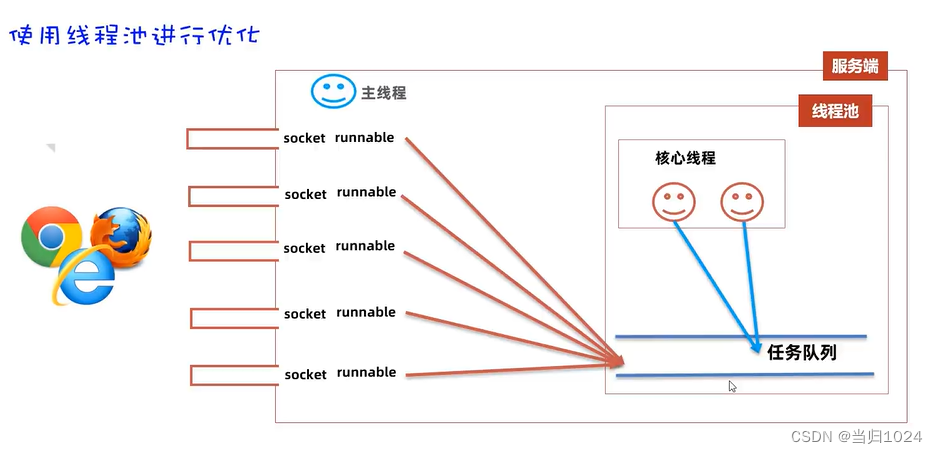
这里我们考虑实现一个简单的线程池来演示享元模式。
- 线程重用:创建线程是昂贵的。通过重用现有线程来执行多个任务,可以减少创建和销毁线程的开销。
- 资源管理:线程池允许更好地管理和限制线程的数量,从而防止资源耗尽。
- 线程池类(ThreadPool):管理固定数量的线程(享元对象)。
- 工作线程类(WorkerThread):执行实际任务的线程。
- 任务接口(Task):代表要执行的任务,由客户端提交。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;// 任务接口
interface Task {void execute();
}// 工作线程类
class WorkerThread extends Thread {private final BlockingQueue<Task> taskQueue;public WorkerThread(BlockingQueue<Task> taskQueue) {this.taskQueue = taskQueue;}@Overridepublic void run() {while (true) {try {Task task = taskQueue.take();task.execute();} catch (InterruptedException e) {break; // 允许线程退出}}}
}// 线程池类
class ThreadPool {private final BlockingQueue<Task> taskQueue = new LinkedBlockingQueue<>();private final WorkerThread[] workerThreads;public ThreadPool(int numberOfThreads) {workerThreads = new WorkerThread[numberOfThreads];for (int i = 0; i < numberOfThreads; i++) {workerThreads[i] = new WorkerThread(taskQueue);workerThreads[i].start();}}public void execute(Task task) {try {taskQueue.put(task);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}// 关闭线程池public void shutdown() {for (WorkerThread worker : workerThreads) {worker.interrupt();}}
}// 客户端使用
public class ThreadPoolDemo {public static void main(String[] args) {ThreadPool pool = new ThreadPool(3); // 创建一个有3个线程的线程池// 提交任务for (int i = 0; i < 10; i++) {int taskNo = i;pool.execute(() -> System.out.println("执行任务 " + taskNo + " 在线程 " + Thread.currentThread().getName()));}pool.shutdown(); // 关闭线程池}
}
- 在这个实现中,ThreadPool 类维护了一个固定数量的工作线程(享元对象)。这些线程是在线程池创建时实例化的,并且在其生命周期内被重复使用来执行提交给线程池的任务。
- 每个 WorkerThread 不断从共享的 taskQueue 中取出任务并执行。这意味着相同的线程可以用于多个不同的任务。
- 这个模型有效地利用了有限数量的线程资源,避免了为每个任务创建和销毁线程的开销,从而提高了资源利用率和性能。
组合模式
组合模式
组合模式(Composite Pattern)是一种用于表示和管理对象的部分-整体层次结构的设计模式。其核心作用是允许客户端以统一的方式对待单个对象和对象的组合。这种模式特别适用于那些对象可以生成树形结构的场景,其中每个节点都可能是一个单独的对象或者是由多个对象组成的一个集合。
核心概念
- 部分-整体关系:组合模式让你可以将对象组织成树形结构,以表示部分与整体的层次关系。
- 统一接口:在这种层次结构中,单个对象(叶子)和组合对象(容器)通过实现相同的接口或继承同一个抽象类,对外提供统一的行为接口。
作用和好处
- 统一处理对象和对象集合:客户端代码可以一致地对待独立对象和组合对象。这意味着,使用单个对象的代码无需改变就可以处理对象的组合。
- 简化客户端代码:客户端不必关心它正在处理的是单个对象还是整个对象的集合。这简化了客户端代码,尤其是在遍历或操作树形结构时。
- 灵活性和扩展性:新的组件类型可以被添加进系统,而无需改变现有代码。这使得组合模式非常适合于创建可扩展的框架。
实际应用场景
- 图形界面组件:在图形用户界面中,组件(如按钮、文本框)和容器(如面板、窗口)都可能有一些共同的操作(如渲染、启用/禁用)。容器可以包含组件或者其他容器,但对于用户来说,他们看起来和操作起来都是统一的。
- 文件系统:如前面例子中所述,文件和文件夹可以分别看作是叶子和容器。但对于执行操作(如计算大小)来说,它们表现得一样。
在文件系统中,我们有两种基本类型的项:文件和文件夹。文件是基本的数据单位,而文件夹可以包含多个文件或其他文件夹。这正好符合组合模式的结构,即部分-整体的层次结构。在这个例子中,文件和文件夹可以被视为树形结构的不同节点。
组件接口:文件系统项
- 组件接口(FileSystemItem)定义了文件和文件夹共同的操作,比如 getSize() 获取大小。
叶子:文件
- 叶子节点(File)表示文件系统中的文件。它有自己的大小,并实现了 getSize() 方法。
组合:文件夹
- 组合节点(Directory)表示文件夹,可以包含其他文件或文件夹。它同样实现了 getSize() 方法,该方法计算其包含的所有项的总大小。
// 组件接口
interface FileSystemItem {int getSize();
}// 叶子:文件
class File implements FileSystemItem {private int size;public File(int size) {this.size = size;}@Overridepublic int getSize() {return size;}
}// 组合:文件夹
class Directory implements FileSystemItem {private List<FileSystemItem> children = new ArrayList<>();public void add(FileSystemItem item) {children.add(item);}@Overridepublic int getSize() {int totalSize = 0;for (FileSystemItem item : children) {totalSize += item.getSize();}return totalSize;}
}// 客户端代码
public class FileSystemDemo {public static void main(String[] args) {File file1 = new File(100);File file2 = new File(200);Directory directory = new Directory();directory.add(file1);directory.add(file2);System.out.println("文件夹的大小: " + directory.getSize()); // 输出文件夹的总大小}
}
场景分析
- 在这个文件系统的例子中,无论是单个文件还是一个文件夹(包含其他文件或文件夹),客户端都以统一的方式来查询大小,即调用 getSize() 方法。
- 文件(叶子节点)和文件夹(组合节点)共享相同的接口 FileSystemItem,使得客户端代码可以统一处理它们,而不需要关心当前处理的是单个文件还是整个文件夹。
- 这里其实可以继续编写,比如在接口中添加额外方法,比如创建文件夹方法,那么目录我们就正常重写这个方法,而如果是文件,我们就选择报错,而不是在文件中创建目录。
- 这样子,我们就为目录和文件提供了相同的方法。
委派模式
委派模式是一种行为型设计模式,它允许对象将某些任务委托给其他对象来处理。在这种模式中,一个对象包含对另一个对象的引用,并将客户端的请求委派给这个对象处理。委派模式基于组合的原则,可以看作是一种特殊情况的静态代理,但与代理模式的目的不同。
工作机制
- 委派者(Delegator):持有服务提供者的引用,并将客户端请求委托给服务提供者。
- 服务提供者(Delegate):实际执行任务的对象。
- 客户端(Client):使用委派者来完成某项任务。
目的和作用
- 解耦:委派模式可以减少系统中对象间的依赖关系,使得控制和工作分离。
- 简化对象:委派模式可以使得委派者对象变得简单,只需转发请求,而不需要知道请求的具体实现。
- 增强灵活性和可复用性:通过改变委派者指向的具体实现对象,可以灵活地更换和复用功能。
与代理模式的区别
虽然委派模式在结构上与静态代理模式类似,但它们的目的不同。代理模式通常用于控制对对象的访问,而委派模式则专注于任务的分发和委托。
委派模式最经典的两个使用就是:
1. Java Servlet的DispatcherServlet
在Spring MVC框架中,DispatcherServlet充当前端控制器(Front Controller),它接收所有的HTTP请求,并根据请求的URL将其委派给相应的处理器(Controller)。这里的DispatcherServlet使用委派模式来决定由哪个控制器来处理传入的请求,并将请求细节委派给选定的控制器。
2. JDK中的ClassLoader机制
Java的ClassLoader机制也是一个委派模式的例子。当请求加载一个类时,ClassLoader会首先委派给它的父类加载器尝试加载该类,只有在父类加载器无法加载时,它才尝试自己加载该类。这种委派机制确保了Java类加载的正确性和安全性。
这里我们就以DispatcherServlet为例,写一个简单的demo。
要模拟Java Servlet中的DispatcherServlet行为,我们可以创建一个简化版的前端控制器(Front Controller)模式,它将HTTP请求委派给不同的处理器(handler)。在这个简化的示例中,我们将模拟处理不同类型的请求(例如GET和POST请求)的逻辑。
实现思路
-
定义处理器接口:创建一个处理器接口,定义处理请求的方法。
-
实现具体的处理器:实现该接口,创建针对不同请求的处理器。
-
创建前端控制器:创建一个DispatcherServlet类,它决定哪个处理器应该处理给定的请求。
-
路由逻辑:DispatcherServlet根据请求类型(这里简化为一个字符串)来调用相应的处理器。
-
处理器接口
interface Handler {void handleRequest(String requestType);
}
- 具体的处理器实现
// 处理GET请求的处理器
class GetRequestHandler implements Handler {@Overridepublic void handleRequest(String requestType) {System.out.println("Handling GET request");}
}// 处理POST请求的处理器
class PostRequestHandler implements Handler {@Overridepublic void handleRequest(String requestType) {System.out.println("Handling POST request");}
}
- 前端控制器(DispatcherServlet)
class DispatcherServlet {private Map<String, Handler> handlerMap = new HashMap<>();public DispatcherServlet() {handlerMap.put("GET", new GetRequestHandler());handlerMap.put("POST", new PostRequestHandler());}public void doDispatch(String requestType) {Handler handler = handlerMap.get(requestType.toUpperCase());if (handler != null) {handler.handleRequest(requestType);} else {System.out.println("Unsupported request type: " + requestType);}}
}
在DispatcherServlet中,我们预先注册了处理GET和POST请求的处理器。根据请求类型的不同,调用相应的处理器。
4. 模拟请求
public class DispatcherDemo {public static void main(String[] args) {DispatcherServlet dispatcher = new DispatcherServlet();// 模拟不同类型的请求dispatcher.doDispatch("GET");dispatcher.doDispatch("POST");dispatcher.doDispatch("PUT"); // 将输出"Unsupported request type: PUT"}
}
在这个简化的示例中,我们实现了一个基本的前端控制器模式。DispatcherServlet充当请求的中央入口,根据请求的类型委派给相应的处理器。这种模式的优点在于集中了请求处理的决策逻辑,使得添加新的请求处理器或修改现有逻辑变得更加简单,同时也使系统的各个部分更加解耦。
这里其实会觉得委派模式和策略模式很像,但是他们还是有一些区别。
委派模式
- 意图:委派模式的核心在于任务的委托。在这个模式中,一个对象(委派者)接受外部的请求并将这些请求委托给另一个对象(服务提供者)来处理。
- 使用场景:委派模式通常用于组合和委派的场景,其中委派者将自己的一部分责任委派给被委派者。委派者本身不关心如何实现这部分责任,只负责转发请求。
- 实现方式:在委派模式中,委派者通常持有被委派者的引用,并在接收到请求时调用被委派者的方法。
策略模式
- 意图:策略模式的焦点在于算法的替换。这个模式定义了一系列的算法,并将每个算法封装起来使它们可以互换。
- 使用场景:当有多种相似的算法或行为,且希望在运行时能够选择使用哪一种时,策略模式提供了一种将算法封装起来并使它们可以互换的方法。
- 实现方式:策略模式通常通过定义一个公共接口来实现不同的算法,客户端选择使用哪种算法,并将其作为一个策略传递给上下文对象。
区别总结
- 关注点:委派模式关注于任务的委派和转发,而策略模式关注于算法的选择和替换。
- 设计层次:委派模式更多用于设计模式的结构层次,而策略模式更多关注行为层面。
- 控制流程:在委派模式中,委派者控制着整个流程,只是将任务的执行委派给其他对象;在策略模式中,客户端可以控制选择哪种策略,并且完全委托给策略对象执行。
装饰器模式
装饰器模式是一种结构型设计模式,它允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有类的一个包装。
这种模式创建了一个装饰类,用来包装原有的类,并在保持原类方法签名完整性的前提下提供了额外的功能。
基本原理:
- 组件接口(Component):定义了一个对象的接口,可以给这些对象动态地添加职责(功能)。
- 具体组件(Concrete Component):定义了一个对象,可以给这个对象添加一些额外的职责。
- 装饰类(Decorator):持有一个指向组件对象的引用,并定义了与组件接口一致的接口。
- 具体装饰类(Concrete Decorator):负责给组件添加新的职责。
优点:
- 装饰器模式提供了比继承更有弹性的替代方案。通过使用不同的具体装饰类以及这些装饰类的排列组合,可以实现不同效果。
- 可以通过一种动态的方式来扩展一个对象的功能,而且可以根据需要扩展多个功能。
- 可以用多个不同的装饰类来装饰同一类对象,实现不同的行为。
缺点:
- 使用装饰器模式会增加很多小类,数量过多会使系统变得复杂。
- 装饰链的设置比较复杂。
Java框架中的装饰器模式应用
- Java I/O Streams:
- Java 的输入输出流(java.io)是装饰器模式的经典应用。例如,FileInputStream、BufferedInputStream、ObjectInputStream 等都是 InputStream 的子类。您可以根据需要来组合这些流,以提供额外的功能(如缓冲、对象序列化等)。
- 例如,new BufferedReader(new InputStreamReader(System.in)) 这个组合就是使用装饰器模式。InputStreamReader 是转换流(装饰者),将字节流 System.in 转换为字符流,BufferedReader 又给字符流添加了缓冲功能。
- Java Servlet API:
- 在 Java Servlet API 中,HttpServletRequestWrapper 和 HttpServletResponseWrapper 是装饰器模式的实现。它们提供了一种方便的方法来扩展 Servlet 请求和响应的功能,而不用修改原始的 HttpServletRequest 和 HttpServletResponse 对象。
- Spring Framework:
- 在 Spring 框架中,装饰器模式被用于多种场景,例如在 AOP(面向切面编程)中,代理类(Proxy)装饰了原始类,以添加横切关注点(如日志、事务管理)。
- 另一个例子是在 Spring Security 中,UserDetailsService 的实现通常被装饰来提供额外的安全功能,如密码加密。
装饰器模式的关键在于“包装”原有对象,并提供额外的功能,而不是修改原有对象本身。对于 HttpServletRequestWrapper 和 HttpServletResponseWrapper 的情况,它们并不是直接修改原始的 HttpServletRequest 或 HttpServletResponse 对象,而是通过“包装”这些对象,然后在调用它们的方法时提供额外的或改变的行为。
让我们用一个简单的例子来说明这一点。假设我们想要创建一个 HttpServletRequestWrapper 的子类,该子类能够修改请求参数:
步骤 1: 创建自定义的 HttpServletRequestWrapper
javaCopy code
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.util.HashMap;
import java.util.Map;public class CustomHttpServletRequestWrapper extends HttpServletRequestWrapper {private final Map<String, String[]> modifiableParameters;public CustomHttpServletRequestWrapper(HttpServletRequest request, Map<String, String[]> additionalParams) {super(request);modifiableParameters = new HashMap<>();modifiableParameters.putAll(request.getParameterMap());modifiableParameters.putAll(additionalParams);}@Overridepublic String getParameter(String name) {if (modifiableParameters.containsKey(name)) {return modifiableParameters.get(name)[0];}return super.getParameter(name);}@Overridepublic Map<String, String[]> getParameterMap() {return modifiableParameters;}// 其他方法...
}
这个自定义的 CustomHttpServletRequestWrapper 类扩展了 HttpServletRequestWrapper 并允许传入一个包含额外请求参数的 Map。它重写了 getParameter 和 getParameterMap 方法,以返回修改后的请求参数。
步骤 2: 在过滤器中使用自定义的 HttpServletRequestWrapper
javaCopy code
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;public class CustomFilter implements Filter {@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)throws IOException, ServletException {HttpServletRequest httpRequest = (HttpServletRequest) request;// 添加或修改请求参数Map<String, String[]> additionalParams = new HashMap<>();additionalParams.put("newParam", new String[]{"value1", "value2"});// 使用自定义的 HttpServletRequestWrapperCustomHttpServletRequestWrapper customRequest = new CustomHttpServletRequestWrapper(httpRequest, additionalParams);// 将自定义的请求对象传递给过滤器链chain.doFilter(customRequest, response);}// 其他方法...
}
在这个例子中,CustomFilter 使用了 CustomHttpServletRequestWrapper 来修改传入的 HTTP 请求。它添加了一个新的请求参数 newParam。当请求通过过滤器链时,任何后续的过滤器或 Servlet 都将看到这个修改后的请求。
如何生效
- 当请求通过 CustomFilter 时,它使用 CustomHttpServletRequestWrapper 来“包装”原始的请求对象。
- 由于 CustomHttpServletRequestWrapper 重写了 getParameter 方法,当请求的参数被访问时,它会返回修改后的参数值。
- 这样,您可以在不修改原始请求对象的情况下,动态地添加、删除或修改请求参数。
代理模式
定义与作用
代理模式是一种结构型设计模式,它为其他对象提供了一种代理(或称为替身),以控制对这个对象的访问。在代理模式中,代理对象插入到实际对象和访问者之间,作为中介,执行某些操作(如访问控制、延迟初始化、日志记录等),然后将调用传递给实际对象。代理模式的主要作用如下:
- 访问控制:代理可以控制对原始对象的访问,适用于需要基于权限的访问控制或保护目标对象的场景。
- 延迟初始化(虚拟代理):如果一个对象的创建和初始化非常耗时,代理模式可以延迟该对象的创建到真正需要的时候进行。
- 日志记录和审计:代理可以记录对目标对象的操作,用于审计或确保合规性。
- 智能引用:代理可以在对象被访问时执行额外的动作,如计数引用次数、检测对象是否已被释放等。
- 远程代理:代理可以隐藏一个对象存在于不同地址空间的事实,如在网络另一侧的对象。
静态代理
静态代理是指在编译期间就创建好代理类的一种代理模式。在这种模式下,代理类和目标对象实现相同的接口或继承相同的类,代理类持有目标对象的引用,并在调用目标对象的方法前后可以执行一些附加操作。
以一个简单的例子来说明,假设有一个接口和一个实现了这个接口的类,我们将创建一个代理类来增强这个实现类的功能:
javaCopy code
// 接口
interface Service {void doSomething();
}// 实现类
class RealService implements Service {public void doSomething() {System.out.println("Doing something in RealService");}
}// 静态代理类
class StaticProxy implements Service {private Service realService;public StaticProxy(Service realService) {this.realService = realService;}public void doSomething() {System.out.println("Before RealService doSomething");realService.doSomething();System.out.println("After RealService doSomething");}
}// 使用示例
public class Main {public static void main(String[] args) {Service service = new StaticProxy(new RealService());service.doSomething();}
}
优点
- 编译时创建:静态代理的代理类在编译时就已经确定,代码中显式定义了代理类。
- 简单直观:实现起来相对简单,容易理解。
- 代码冗余:对于每个需要代理的类,都需要显式地创建一个代理类。
适用场景
- 当目标对象的行为不经常变化时,静态代理是一个不错的选择。
- 在需要对某个对象的方法调用进行统一的处理(如安全检查、事务处理、日志记录等)时使用。
缺点
- 代码量大:如果需要代理的方法很多,代理类的代码量会非常大。
- 灵活性差:由于代理类在编译期就已经确定,对代理的修改可能需要修改代理类的源代码,并重新编译。
静态代理模式在应用较为简单且目标对象稳定的情况下是非常有用的,但在需要大量动态代理的方法或目标对象经常变化的情况下,可能会导致代码的冗余和维护难度增加。在这种情况下,可以考虑使用动态代理模式。
JDK动态代理
JDK动态代理是Java提供的一种动态生成代理对象的机制,它允许开发者在运行时创建代理对象,而无需为每个类编写具体的代理实现。JDK动态代理主要通过java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来实现。
实现原理
JDK动态代理工作原理是利用InvocationHandler来关联代理对象和实际对象,当通过代理对象调用方法时,这个调用会被转发到InvocationHandler的invoke方法。在invoke方法内,开发者可以在调用实际对象的方法前后添加自定义逻辑。
下面是一个使用JDK动态代理的例子:
package blossom.project.designmode.proxy;import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import sun.misc.ProxyGenerator;
// 接口
interface Service {void doSomething();
}// 实现类
class RealService implements Service {public void doSomething() {System.out.println("Doing something in RealService");}
}// 调用处理器
class ServiceInvocationHandler implements InvocationHandler {//被代理的实际对象private Object target;public ServiceInvocationHandler(Object target) {this.target = target;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {//代理前置处理System.out.println("Before method " + method.getName());//被代理对象的方法被调用Object result = method.invoke(target, args);//代理后置处理System.out.println("After method " + method.getName());return result;}
}// 使用示例
public class JdkProxy {public static void main(String[] args) {RealService realService = new RealService();//创建代理对象 然后调用代理对象的方法即可Service proxyService = (Service) Proxy.newProxyInstance(RealService.class.getClassLoader(),new Class<?>[] {Service.class},new ServiceInvocationHandler(realService));proxyService.doSomething();//生成字节码文件byte[] classFile = ProxyGenerator.generateProxyClass("$Proxy0", new Class[]{Service.class});// 保存到文件系统try (FileOutputStream out = new FileOutputStream("D://desktop//" + "$Proxy.class")) {out.write(classFile);} catch (IOException e) {e.printStackTrace();}}
}
在这个例子中,Service是一个接口,RealService是它的一个实现。ServiceInvocationHandler是一个InvocationHandler,在invoke方法中添加了在执行方法前后的逻辑。我们使用Proxy.newProxyInstance方法创建了RealService的代理对象。
优点
- 灵活性:可以在运行时为多个接口动态创建代理,无需为每个接口编写专门的代理类。
- 减少冗余代码:通过处理器类(如ServiceInvocationHandler)来集中处理代理逻辑,减少了重复代码。
缺点
- 只支持接口:JDK动态代理只能代理接口,不支持类。
- 性能开销:由于使用反射机制,可能会有一定的性能开销。
适用场景
JDK动态代理适用于需要代理的对象实现了一个或多个接口的场景。它在AOP(面向切面编程)、事务代理、日志记录等场景中非常有用。
面试的时候有被问到JDK动态代理的底层实现源码,所以这里我也简单的介绍一下它的源码实现。
JDK动态代理原理
运行我们上面的代码并且进入debug状态,可以看到如下状态。
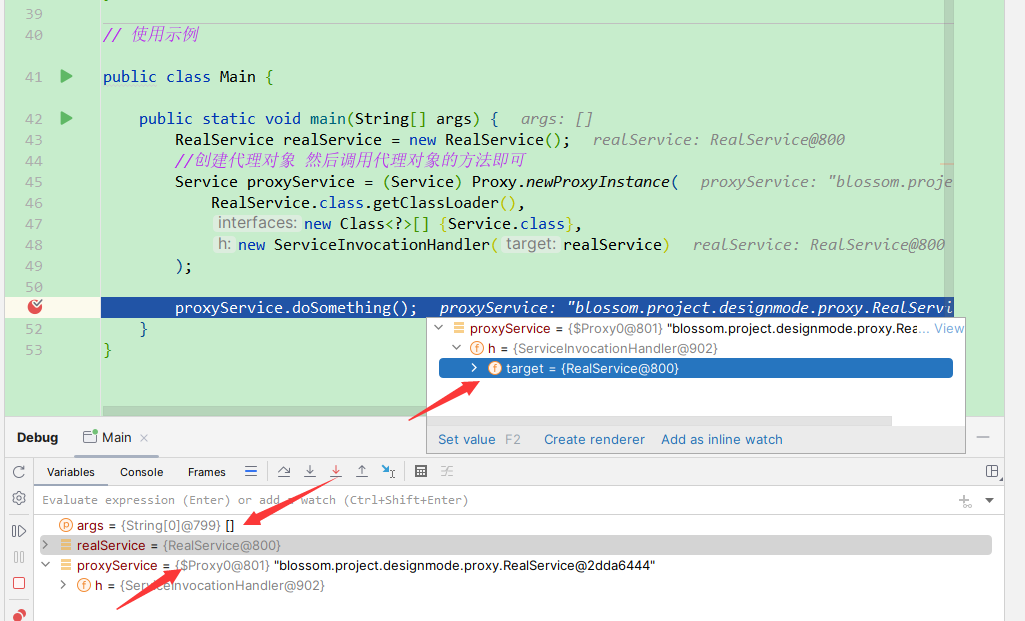
首先是我们的proxyService的内部的target就是我们一开始new出来的那个需要被代理的对象。
但是最后的这个proxyService可以发现它的类型是 P r o x y ,我们知道,使用 Proxy,我们知道,使用 Proxy,我们知道,使用代表的是他是一个子类或者内部类的意思。而这里用 P r o x y 开头代表的是他是一个代理类,在外面看不到只能在内存中看到。而这里的 0 代表的是 J d k 自增的一个序号。这里我们知道,动态代理的底层其实就是为我们再运行的时候生成了一个类,那么我们只需要看看这个类的代码,我们就能大概知道他是如何实现的了。接下来我们来获取动态代理生成的类的字节码文件,运行上面的代码:这里特别注意需要用 J D K 8 哦。此时我们会得到一个 c l a s s 文件,不用打开看了,你啥也看不懂的。 ! [ i m a g e . p n g ] ( h t t p s : / / i m g − b l o g . c s d n i m g . c n / i m g c o n v e r t / 3791 d 546 d c 83969 a 5 b 5910 f d b e 3 a b e 4 a . p n g ) 然后我们使用 J A D 来进行反编译,如果没有下载 J A D 的可以下载一个,链接如下: [ J A D 反编译工具 ] ( h t t p s : / / v a r a n e c k a s . c o m / j a d / ) ! [ i m a g e . p n g ] ( h t t p s : / / i m g − b l o g . c s d n i m g . c n / i m g c o n v e r t / 5041 a 0213554 b 37 c 99 a 4 b f f b c 515 f 41 b . p n g ) 之后就得到了反编译以后的文件了。上面的代码编译后如下:其中可以看到我们的被代理的方法,调用的是 s u p e r . h . i n v o k e 方法,那么我们就得了解一下这个 h 到底是什么了。我们进入到 P r o x y 类的源码进行查看。因为这里 Proxy开头代表的是他是一个代理类,在外面看不到只能在内存中看到。而这里的0代表的是Jdk自增的一个序号。 这里我们知道,动态代理的底层其实就是为我们再运行的时候生成了一个类,那么我们只需要看看这个类的代码,我们就能大概知道他是如何实现的了。 接下来我们来获取动态代理生成的类的字节码文件,运行上面的代码: 这里特别注意需要用JDK8哦。 此时我们会得到一个class文件,不用打开看了,你啥也看不懂的。  然后我们使用JAD来进行反编译,如果没有下载JAD的可以下载一个,链接如下: [JAD反编译工具](https://varaneckas.com/jad/)  之后就得到了反编译以后的文件了。 上面的代码编译后如下: 其中可以看到我们的被代理的方法,调用的是super.h.invoke方法,那么我们就得了解一下这个h到底是什么了。我们进入到Proxy类的源码进行查看。 因为这里 Proxy开头代表的是他是一个代理类,在外面看不到只能在内存中看到。而这里的0代表的是Jdk自增的一个序号。这里我们知道,动态代理的底层其实就是为我们再运行的时候生成了一个类,那么我们只需要看看这个类的代码,我们就能大概知道他是如何实现的了。接下来我们来获取动态代理生成的类的字节码文件,运行上面的代码:这里特别注意需要用JDK8哦。此时我们会得到一个class文件,不用打开看了,你啥也看不懂的。然后我们使用JAD来进行反编译,如果没有下载JAD的可以下载一个,链接如下:[JAD反编译工具](https://varaneckas.com/jad/)之后就得到了反编译以后的文件了。上面的代码编译后如下:其中可以看到我们的被代理的方法,调用的是super.h.invoke方法,那么我们就得了解一下这个h到底是什么了。我们进入到Proxy类的源码进行查看。因为这里Proxy0是继承了Proxy的,所以进入Proxy类。
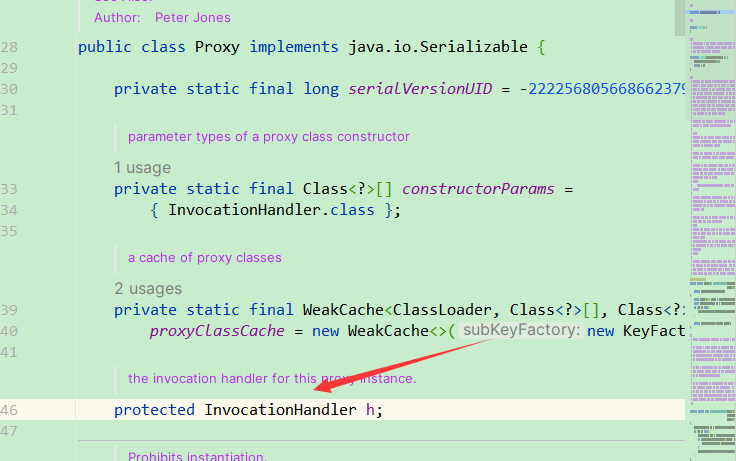
可以发现,这里的h应该就是我们传入的InvocationHadnler的对象了。也就是我们的代理类。
// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
// Jad home page: http://www.kpdus.com/jad.html
// Decompiler options: packimports(3) import blossom.project.designmode.proxy.Service;
import java.lang.reflect.*;public final class $Proxy0 extends Proxyimplements Service
{public $Proxy0(InvocationHandler invocationhandler){super(invocationhandler);}public final boolean equals(Object obj){try{return ((Boolean)super.h.invoke(this, m1, new Object[] {obj})).booleanValue();}catch(Error _ex) { }catch(Throwable throwable){throw new UndeclaredThrowableException(throwable);}}public final void doSomething(){try{super.h.invoke(this, m3, null);return;}catch(Error _ex) { }catch(Throwable throwable){throw new UndeclaredThrowableException(throwable);}}public final String toString(){try{return (String)super.h.invoke(this, m2, null);}catch(Error _ex) { }catch(Throwable throwable){throw new UndeclaredThrowableException(throwable);}}public final int hashCode(){try{return ((Integer)super.h.invoke(this, m0, null)).intValue();}catch(Error _ex) { }catch(Throwable throwable){throw new UndeclaredThrowableException(throwable);}}private static Method m1;private static Method m3;private static Method m2;private static Method m0;static {try{m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[] {Class.forName("java.lang.Object")});m3 = Class.forName("blossom.project.designmode.proxy.Service").getMethod("doSomething", new Class[0]);m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);}catch(NoSuchMethodException nosuchmethodexception){throw new NoSuchMethodError(nosuchmethodexception.getMessage());}catch(ClassNotFoundException classnotfoundexception){throw new NoClassDefFoundError(classnotfoundexception.getMessage());}}
}那么到此为止我们就大概知道JDK动态代理的实现了。
我们现在来手写一个JDK动态代理。
手写一个JDK动态代理
CGLIB动态代理
CGLIB(Code Generation Library)是一个功能强大的高性能代码生成库,它允许在运行时动态地扩展Java类和实现Java接口。在代理模式中,CGLIB常被用于实现动态代理,特别是当被代理的对象没有实现任何接口时。
实现原理
CGLIB动态代理通过继承要代理的类并在运行时生成子类来实现。CGLIB通过拦截所有对代理对象的方法调用,将这些调用转发到一个方法拦截器(Method Interceptor)中,从而实现代理逻辑。
要使用CGLIB,需要引入CGLIB库。如果你使用Maven,可以添加以下依赖:
<dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version>
</dependency>
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;// 被代理的类(不需要实现接口)
class RealService {public void doSomething() {System.out.println("Doing something in RealService");}
}// 方法拦截器
class ServiceMethodInterceptor implements MethodInterceptor {@Overridepublic Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {System.out.println("Before method " + method.getName());Object result = proxy.invokeSuper(obj, args);System.out.println("After method " + method.getName());return result;}
}// 使用示例
public class Main {public static void main(String[] args) {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(RealService.class);enhancer.setCallback(new ServiceMethodInterceptor());RealService proxyService = (RealService) enhancer.create();proxyService.doSomething();}
}
优点
- 不需要接口:与JDK动态代理不同,CGLIB可以代理没有实现任何接口的类。
- 高性能:CGLIB使用字节码生成技术,生成的代理类性能通常比JDK动态代理高。
缺点
- 外部依赖:使用CGLIB需要引入CGLIB库。
- 无法代理final方法:由于CGLIB通过继承方式实现代理,因此无法代理final修饰的方法。
- 可能的类加载问题:在某些应用服务器中,CGLIB动态生成的类可能导致类加载器的问题。
适用场景
CGLIB代理非常适合以下场景:
- 需要代理的对象没有实现任何接口。
- 需要最大化代理性能。
在Spring框架中,当AOP需要代理没有实现接口的Bean时,通常会使用CGLIB代理。
代理模式实现多数据源切换
我们知道项目开发的时候一般会用到多数据源,而多数据源的实现也是依赖于我们的代理模式。
对于多数据源的切换,我们得考虑如下几点:
- 当前线程切换数据源不会影响其他线程
- 切换数据源应该在调用实际操作的数据库方法之前执行
- 当前线程处理完毕之后应该恢复为使用默认数据源
按照如上的几点,我们可以写出如下的代码:
首先创建一个动态数据源类,其中使用ThreadLocal来实现线程隔离切换数据源。
public class DynamicDataSource {public final static String DEFAULE_DATA_SOURCE = "DB_2022";private final static ThreadLocal<String> local = new ThreadLocal<String>();private DynamicDataSource(){}public static String get(){return local.get();}public static void reset(){local.set(DEFAULE_DATA_SOURCE);}public static void set(String source){local.set(source);}public static void set(int year){local.set("DB_" + year);}}
然后我们实现InvocationHandler接口。
要做的就是在执行具体的被代理增强的方法之前切换一下数据源即可。
public class UserServiceDynamicProxy implements MyInvocationHandler {private SimpleDateFormat yearFormat = new SimpleDateFormat("yyyy");Object proxyObj;public Object getInstance(Object proxyObj) {this.proxyObj = proxyObj;Class<?> clazz = proxyObj.getClass();return MyProxy.newProxyInstance(new MyClassLoader(),clazz.getInterfaces(),this);}public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {before(args[0]);Object object = method.invoke(proxyObj,args);after();return object;}private void after() {System.out.println("Proxy after method");//还原成默认的数据源DynamicDataSource.reset();}//target 应该是订单对象Orderprivate void before(Object target) {try {//进行数据源的切换System.out.println("Proxy before method");//约定优于配置Long time = (Long) target.getClass().getMethod("getCreateTime").invoke(target);Integer dbRouter = Integer.valueOf(yearFormat.format(new Date(time)));System.out.println("静态代理类自动分配到【DB_" + dbRouter + "】数据源处理数据");DynamicDataSource.set(dbRouter);}catch (Exception e){e.printStackTrace();}}
}public class DbRouteProxyTest {public static void main(String[] args) {try {User user = new User();// user.setCreateTime(new Date().getTime());SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd");Date date = sdf.parse("2023/03/01");user.setCreateTime(date.getTime());IUserService orderService = (IUserService)new UserServiceDynamicProxy().getInstance(new UserService());
// IOrderService orderService = (IOrderService)new UserServiceStaticProxy(new UserService());orderService.createUser(user);}catch (Exception e){e.printStackTrace();}}}
区别
JDK动态代理和CGLIB动态代理是Java中实现动态代理的两种主要方法,它们各有特点和适用场景。下面详细比较这两种动态代理方式:
JDK动态代理
底层实现
- JDK动态代理是基于接口的代理方式,它使用Java原生的反射API实现代理功能。
- 代理对象是在运行时动态生成的,它们实现了目标对象所实现的接口。
- JDK动态代理使用java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来创建和管理代理。
优点
- 接口导向:只要目标对象实现了接口,就能使用JDK代理。
- 无需第三方依赖:使用标准Java API,不需要引入额外的库。
- 更轻量级:不需要创建新的类文件,比CGLIB消耗的资源更少。
缺点
- 仅限接口:只能代理实现了接口的类,对于没有实现接口的类不能直接使用。
- 性能问题:反射操作相比直接方法调用有性能开销。
CGLIB动态代理
底层实现
- CGLIB(Code Generation Library)是一个强大的高性能代码生成库,它在运行时动态生成目标对象的子类。
- 代理对象是目标对象的子类,它覆盖了目标对象的方法。
- CGLIB通过操作字节码实现代理,使用了net.sf.cglib.proxy.Enhancer和net.sf.cglib.proxy.MethodInterceptor等类。
优点
- 无需接口:可以代理没有实现任何接口的类。
- 性能较好:在代理类的生成和方法调用方面,通常比JDK动态代理快。
- 灵活性:提供了比JDK更多的代理控制功能。
缺点
- 第三方依赖:需要引入CGLIB库。
- 类的生成:动态生成的代理类是目标类的子类,如果目标类是final的,就无法使用CGLIB代理。
- 可能的兼容性问题:CGLIB动态生成的类可能会和某些JVM不兼容。
总结
- 选择JDK代理还是CGLIB代理? 如果目标对象实现了接口,推荐使用JDK代理,因为它更简单,不需要额外依赖,并且资源消耗较少。如果目标对象没有实现接口,或者你需要一个功能更强大、性能更高的代理,可以选择CGLIB代理。
- 性能考虑:虽然通常认为CGLIB性能优于JDK代理(尤其是在代理类的初始化阶段),但在实际应用中,这种性能差异可能非常小,不足以成为选择代理方式的决定性因素。代码的清晰性和维护性通常更为重要。
在实际的软件开发中,具体选择哪种代理方式取决于具体的应用场景和需求。在Spring框架中,当AOP代理需要被应用时,如果目标对象实现了接口,默认会使用JDK动态代理;如果目标对象没有实现接口,或者显式配置使用CGLIB代理,则会使用CGLIB。
外观模式
外观模式(Facade Pattern)是一种使用频率较高的结构型设计模式,其主要目标是提供一个统一的接口来访问子系统中的一群接口。外观定义了一个更高层次的接口,使得子系统更容易使用。
优点:
- 简化接口:外观模式对外提供一个简单的接口,隐藏了子系统的复杂性,使子系统更易使用。
- 解耦:将客户端和子系统的实现解耦,使得子系统的变化不会直接影响到客户端。
- 易于维护和扩展:封装了子系统的功能,使得维护和扩展更加方便。
缺点:
- 可能成为与子系统所有类的依赖点:如果外观类变得过于复杂,它本身可能成为一个难以维护的大类。
- 不符合开闭原则:在系统变化时,可能需要修改外观类。
使用场景:
- 为复杂的子系统提供一个简单的接口。
- 客户端与多个子系统之间存在很大的依赖性。
- 分层结构中,可以使用外观作为每个子系统的入口点,以简化它们之间的依赖关系。
其实外观模式是我们开发过程中没有意识到但是用的最多的一种方法。比如我们的SpringMVC的三层开发结构就符合外观模式。
下面我简单列举一个我项目中的多OSS服务代码,它依靠与外观模式和策略模式。
首先是先展示策略模式的结构
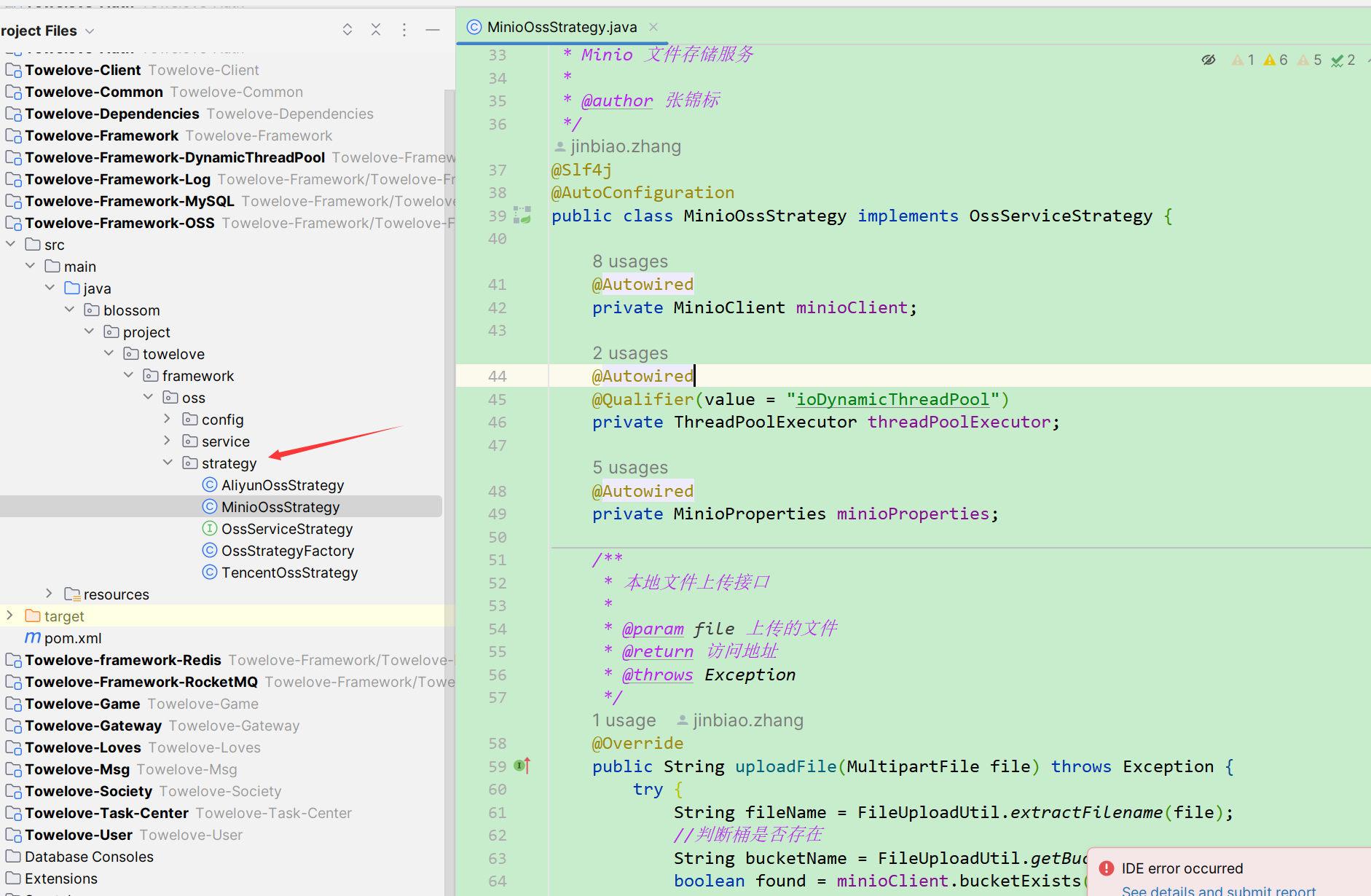
在这里我让他们实现一个公共的接口,用来提供对应的OSS服务。
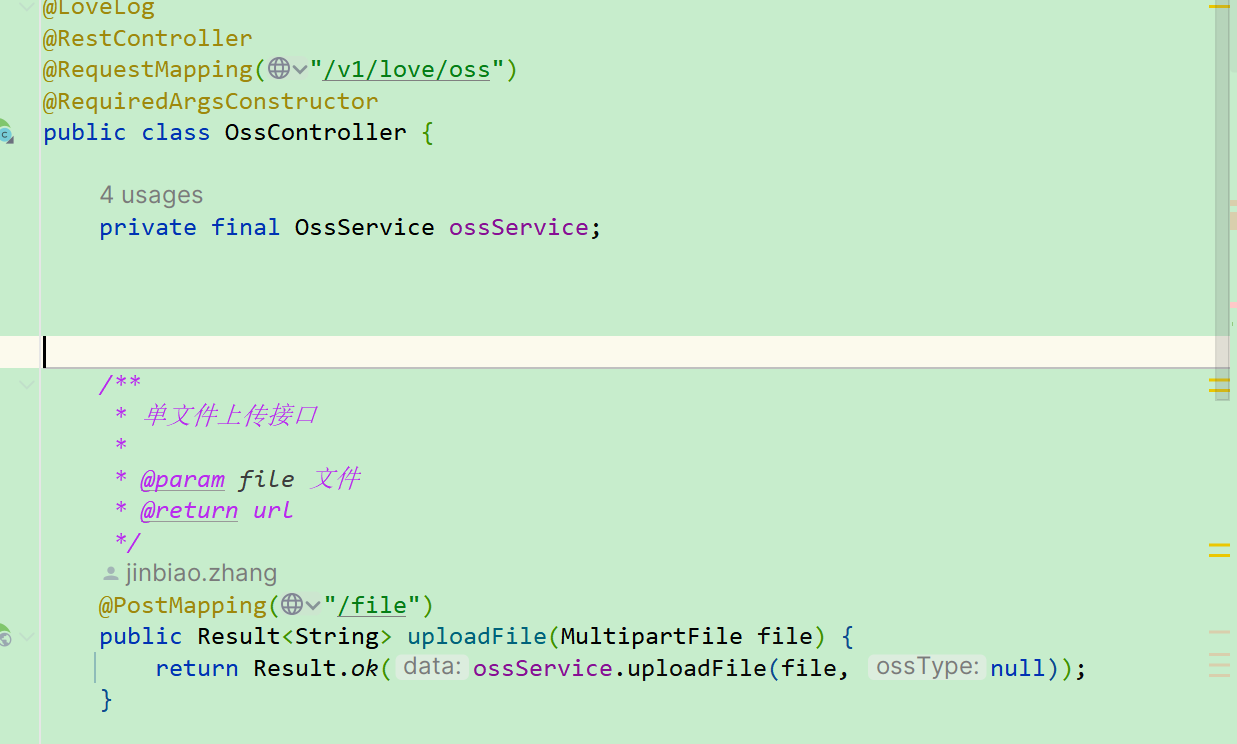
之后,我对外提供一个OssService用来统一提供Oss服务。

这样子再需要使用到Oss服务的地方引入依赖,然后使用通用接口,就可以完成文件的上传,而外部并不需要了解文件上传的细节,只需要根据参数提示进行使用即可,
适配器模式
适配器模式是一种结构型设计模式,它允许不兼容的接口之间进行交互。适配器模式通常用于使现有类的接口与其他类兼容,而不需要修改其源代码。
适配器模式不是软件设计阶段考虑的设计模式,是随着软件维护,由于不同产品、不同厂家造成功能类似而接口不相同情况下的解决方案。
类适配器
类适配器模式是适配器模式的一种实现方式,它通过继承来实现适配。在类适配器模式中,适配器直接继承被适配者,并实现目标接口。由于Java不支持多重继承,因此类适配器模式在Java中不常见,但可以在支持多重继承的语言(如C++)中实现。
实现机制
- 继承:适配器继承自被适配者类。
- 实现接口:适配器实现目标接口。
假设我们有一个已存在的类Adaptee和一个目标接口Target,我们的目标是使Adaptee适应Target接口。
// 被适配者
class Adaptee {public void specificRequest() {System.out.println("Specific request");}
}// 目标接口
interface Target {void request();
}// 类适配器
class ClassAdapter extends Adaptee implements Target {@Overridepublic void request() {specificRequest();}
}
在这个例子中,ClassAdapter继承自Adaptee并实现了Target接口。在request()方法中,适配器调用了Adaptee的specificRequest()方法,从而使Adaptee能够适应Target接口。
public class AdapterDemo {public static void main(String[] args) {Target target = new ClassAdapter();target.request(); // 输出: Specific request}
}
类适配器适用于以下场景:
- 当你想要使用某个类,但其接口与你的接口不兼容时。
- 当你想创建一个可重用的类,该类可以与其他不相关的类或不可预见的类(即接口可能不兼容的类)协同工作。
优点
- 适配器可以重写被适配者的行为:由于适配器继承了被适配者,它可以重写被适配者的行为。
缺点
- 过度使用继承:类适配器使用继承而非组合,这可能导致过度使用继承的问题,使得系统更难理解和维护。而且由于使用了继承,使用适配器的时候甚至可以直接调用父类的方法,违背最小知道原则哦。
- 不够灵活:由于Java的单继承限制,类适配器可能无法同时适配多个类。
对象适配器
对象适配器是适配器模式的另一种实现方式,它使用组合而非继承来实现适配功能。在对象适配器模式中,适配器包含一个被适配者的引用,并实现目标接口。
实现机制
- 组合:适配器持有被适配者的引用。
- 实现接口:适配器实现目标接口,转发调用到被适配者。
假设我们有一个现存的类Adaptee和一个目标接口Target,我们的目标是使Adaptee适应Target接口。
// 被适配者
class Adaptee {public void specificRequest() {System.out.println("Specific request");}
}// 目标接口
interface Target {void request();
}// 对象适配器
class ObjectAdapter implements Target {private Adaptee adaptee;public ObjectAdapter(Adaptee adaptee) {this.adaptee = adaptee;}@Overridepublic void request() {adaptee.specificRequest();}
}
在这个例子中,ObjectAdapter实现了Target接口,并包含了一个Adaptee类型的成员变量。在request()方法中,适配器调用了Adaptee的**specificRequest()**方法。
public class AdapterDemo {public static void main(String[] args) {Adaptee adaptee = new Adaptee();Target target = new ObjectAdapter(adaptee);target.request(); // 输出: Specific request}
}
对象适配器适用于以下场景:
- 当你想要使用一些现有的类,但它们的接口不符合你的需求时。
- 当你想创建一个可重用的类,该类可以与其他不相关或不可预见的类协同工作,这些类可能没有兼容的接口。
优点
- 单一职责原则:通过将接口适配的职责委托给一个独立的对象,适配器只关心适配工作,而被适配者只关心自己的业务逻辑。
- 更大的灵活性:由于使用组合,可以在运行时动态地适配和替换被适配者。
缺点
- 代码复杂度:相对于类适配器,对象适配器可能会增加代码的复杂性。
对象适配器是适配器模式的一种常用实现方式,它提供了良好的灵活性和扩展性,同时符合组合优于继承的设计原则。在实际应用中,对象适配器模式因其灵活性和应用广泛性而被广泛采用。
接口适配器/ 缺省适配器
接口适配器模式,也称为缺省适配器模式,是适配器模式的一种特殊形式。这种模式常用于当你需要实现一个接口,但只需要其中一部分方法时。
实现机制
- 定义一个抽象类:该抽象类实现了目标接口,并为该接口中的所有方法提供默认实现(通常是空实现)。
- 继承抽象类:具体的适配器类继承这个抽象类,并重写感兴趣的方法。
假设有一个接口TargetInterface,它定义了多个方法。我们不想在适配器类中实现所有这些方法,只对其中一部分感兴趣。
// 目标接口,包含多个方法
interface TargetInterface {void methodA();void methodB();void methodC();
}// 接口适配器/缺省适配器,为接口提供默认实现
abstract class InterfaceAdapter implements TargetInterface {@Overridepublic void methodA() { }@Overridepublic void methodB() { }@Overridepublic void methodC() { }
}// 具体实现类,只需覆盖感兴趣的方法
class ConcreteAdapter extends InterfaceAdapter {@Overridepublic void methodA() {System.out.println("Method A implementation");}// 方法B和C使用默认实现(无操作)
}
在这个例子中,InterfaceAdapter为TargetInterface中的所有方法提供了默认实现。ConcreteAdapter类继承自InterfaceAdapter,只重写了methodA,而methodB和methodC保留了默认实现。
public class AdapterDemo {public static void main(String[] args) {TargetInterface adapter = new ConcreteAdapter();adapter.methodA(); // 输出: Method A implementationadapter.methodB(); // 无输出adapter.methodC(); // 无输出}
}
适用场景
接口适配器适用于以下场景:
- 当不需要实现接口的所有方法时。
- 当一个抽象类可以作为多个方法的默认实现,并由子类选择性地重写某些方法时。
优点
- 灵活性:提供了一种方式,使得你可以只关注你感兴趣的方法。
- 减少子类负担:不需要实现接口中的每个方法,子类可以选择性地重写方法。
缺点
- 增加类的数量:每个接口都需要一个对应的抽象适配器类。
接口适配器模式是一种实用的设计模式,特别适合于那些拥有多个方法的接口,但实现类只需要一部分方法的场景。通过提供一个中间的抽象类来简化实现过程,这种模式使得代码更加清洁和可维护。
适配器模式实现多种登录方式
在实际的应用中,处理不同登录方式通常涉及不同的流程和用户交互。例如,常规的用户名和密码登录可能直接通过HTTP请求处理,而第三方登录(如微信、QQ、抖音)可能涉及到OAuth授权、重定向到第三方登录页面、扫码等流程。为了处理这些不同的登录方式,我们可以在后端设计一个统一的入口(Controller),然后根据登录方式的不同,委托给不同的处理器(适配器)来完成具体的登录流程。
以下是基于适配器模式的设计和代码示例:
- 定义通用的登录服务接口
interface LoginService {void login(Map<String, String> parameters);
}
- 实现不同的登录服务
// 用户名密码登录服务
class UsernamePasswordLoginService implements LoginService {@Overridepublic void login(Map<String, String> parameters) {String username = parameters.get("username");String password = parameters.get("password");System.out.println("Username and password login: " + username);// 实现具体的登录逻辑}
}// 微信登录服务
class WeChatLoginService implements LoginService {@Overridepublic void login(Map<String, String> parameters) {String token = parameters.get("token");System.out.println("WeChat login with token: " + token);// 实现微信登录逻辑,可能涉及重定向到微信登录页面等}
}// QQ登录服务
class QQLoginService implements LoginService {// 类似地实现QQ登录逻辑// ...
}// 抖音登录服务
class TikTokLoginService implements LoginService {// 类似地实现抖音登录逻辑// ...
}
- Controller层处理登录请求
@RestController
@RequestMapping("/auth")
public class LoginController {private Map<String, LoginService> loginServices;public LoginController() {// 初始化不同的登录服务loginServices = new HashMap<>();loginServices.put("usernamePassword", new UsernamePasswordLoginService());loginServices.put("wechat", new WeChatLoginService());loginServices.put("qq", new QQLoginService());loginServices.put("tiktok", new TikTokLoginService());}@PostMapping("/login")public ResponseEntity<?> login(@RequestParam String type, @RequestBody Map<String, String> parameters) {LoginService loginService = loginServices.get(type);if (loginService == null) {return ResponseEntity.badRequest().body("Unsupported login type: " + type);}loginService.login(parameters);return ResponseEntity.ok().body("Login successful for type: " + type);}
}
在这个示例中,LoginController定义了一个**/auth/login端点来处理登录请求。它支持多种登录类型,每种类型对应一个特定的LoginService实现。根据请求参数type**,Controller将委托给相应的LoginService来处理具体的登录逻辑。
- 常规登录:客户端发送HTTP POST请求到**/auth/login**,带上type为usernamePassword,以及username和password作为请求体。
- 第三方登录:例如,微信登录,客户端发送HTTP POST请求到**/auth/login**,带上type为wechat,以及必要的参数(如token)作为请求体。服务端的WeChatLoginService将处理登录逻辑,可能包括重定向到微信登录页面等。
桥接模式
定义
桥接模式(Bridge Pattern)是一种结构型设计模式,用于将抽象部分与其实现部分分离,使它们都可以独立地变化。这种模式通过提供一个桥接结构,来实现两个或多个不同类或接口的合作。
- 目的:将抽象与实现解耦,使得两者可以独立地变化。
- 组成:包括一个抽象类(Abstraction)和一个实现类接口(Implementor)。抽象类中包含一个对实现类接口的引用,这就是“桥”。
优点
- 分离接口及其实现部分:使得它们可以独立地进行改变。
- 扩展性强:不仅可以扩展抽象类,也可以独立地扩展实现类。
- 符合开闭原则:可以独立地对抽象和实现部分进行扩展,而不会相互影响,从而遵循了开闭原则。
- 隐藏实现细节:用户只关心接口的抽象部分,不需要关心具体的实现。
- 符合合成复用原则:不使用继承使用组合。
缺点
- 增加了系统的理解和设计难度:由于分离了抽象和实现,理解这种分离的概念可能需要一定的时间。
- 增加了代码量:可能会导致系统中类的数量增加,增加了系统的复杂性。
使用场景
- 当一个类存在多个独立变化的维度时:例如,如果一个系统需要在不同的操作系统上运行,并且有多种不同的数据库支持,那么操作系统和数据库的支持就可以作为两个独立变化的维度。
- 避免继承带来的固化关系:如果使用继承,一旦接口改变,所有的实现类都要跟着变化。
- 当一个实现可能需要在多个对象之间共享时:通过桥接模式,可以共享实现,而不需要在每个对象中重复。
我将使用操作系统(OS)和数据库(DB)作为不同的维度来构建这个例子。
桥接模式的关键组成部分
- Implementor(实现者接口):这是一个接口,定义了实现类的方法。在我们的例子中,这将是一个代表数据库操作的接口。
- ConcreteImplementor(具体实现者):这些是实现了 Implementor 接口的具体类。对于数据库,我们可以有 MySQL、Oracle 等具体实现。
- Abstraction(抽象类):这是一个抽象层,持有 Implementor 的引用。在我们的例子中,这将是代表操作系统的类。
- RefinedAbstraction(扩展抽象类):这些是扩展了 Abstraction 的类。例如,不同类型的操作系统,如 Windows 或 Linux。
- Client(客户端):这是使用桥接模式的类。
示例实现
Step 1: Implementor - Database Interface
首先,我们定义一个数据库接口,它将是我们桥接模式中的 Implementor。
public interface Database {void connect();void executeQuery(String query);
}
Step 2: Concrete Implementors - Specific Databases
然后,我们为具体的数据库实现这个接口,这些类是 ConcreteImplementors。
// MySQL 数据库实现
public class MySQLDatabase implements Database {@Overridepublic void connect() {System.out.println("Connecting to MySQL database...");}@Overridepublic void executeQuery(String query) {System.out.println("Executing MySQL Query: " + query);}
}// Oracle 数据库实现
public class OracleDatabase implements Database {@Overridepublic void connect() {System.out.println("Connecting to Oracle database...");}@Overridepublic void executeQuery(String query) {System.out.println("Executing Oracle Query: " + query);}
}
Step 3: Abstraction - OperatingSystem
接下来,我们定义一个操作系统类(OperatingSystem),它将持有数据库的引用。这是桥接模式中的 Abstraction 部分。
public abstract class OperatingSystem {// 持有数据库的引用protected Database database;public OperatingSystem(Database database) {this.database = database;}public abstract void start();public abstract void stop();// 使用数据库执行查询public void executeDatabaseQuery(String query) {database.connect();database.executeQuery(query);}
}
Step 4: Refined Abstractions - Specific Operating Systems
现在,我们为特定的操作系统创建类,这些类是 RefinedAbstraction。
// Windows 操作系统
public class WindowsOS extends OperatingSystem {public WindowsOS(Database database) {super(database);}@Overridepublic void start() {System.out.println("Starting Windows OS...");}@Overridepublic void stop() {System.out.println("Stopping Windows OS...");}
}// Linux 操作系统
public class LinuxOS extends OperatingSystem {public LinuxOS(Database database) {super(database);}@Overridepublic void start() {System.out.println("Starting Linux OS...");}@Overridepublic void stop() {System.out.println("Stopping Linux OS...");}
}
Step 5: Client - Demo
最后,我们创建一个客户端类来演示桥接模式的使用。
public class BridgePatternDemo {public static void main(String[] args) {// 创建一个 MySQL 数据库实例Database mysql = new MySQLDatabase();// 创建一个 Windows 操作系统实例,使用 MySQL 数据库OperatingSystem windows = new WindowsOS(mysql);windows.start();windows.executeDatabaseQuery("SELECT * FROM users");windows.stop();// 创建一个 Oracle 数据库实例Database oracle = new OracleDatabase();// 创建一个 Linux 操作系统实例,使用 Oracle 数据库OperatingSystem linux = new LinuxOS(oracle);linux.start();linux.executeDatabaseQuery("SELECT * FROM employees");linux.stop();}
}
桥接模式的核心思想
- 分离抽象与实现:在此例中,操作系统(抽象)和数据库(实现)是分开的,它们可以独立变化而不会影响到对方。
- 灵活性和扩展性:可以轻松地添加新的数据库或操作系统类型,而无需修改现有的类。
这个简单的例子展示了桥接模式的核心概念:通过分离抽象和实现,使得两者可以独立发展,增加了代码的灵活性和可维护性。
其实我总结一下,可以发现桥接模式的使用方法有点像多对多的情况。
比如我们有一个OS,然后这个OS其实有多种不同的数据库可以选择去使用,那么这里如果我们让OS去实现(也可以用继承,如果用继承的话就要将DB类型同时都继承同一个父类)DB的接口,那么我们每次新出现一个DB类型,就要去修改OS,这很明显违法了开闭原则。
因此,我们尽可能的考虑将变化DB作为OS的属性,这样子就将DB和OS进行了关联,OS想要使用那个DB,只要在创建的时候进行选择即可。
桥接模式特别适合用于要将两个不同维度的东西用于建立链接。
如果还有一点抽象,我们就来举个例子:
Java中最经典的例子就是,我们的JDBC的例子。
我们知道,JDBC只是提供了一套连接数据库的接口,并没有提供具体的实现,而具体的实现则由厂商进行实现。
我们一般会编写如下代码来链接数据库:
//建桥
Class.forName("com.mysql.cj.jdbc.Driver");
//用桥
DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","root");
而就是这一段代码就使用了我们的桥接模式。
首先MySQL的Driver实现了java的Driver然后调用了DriverManager方法。
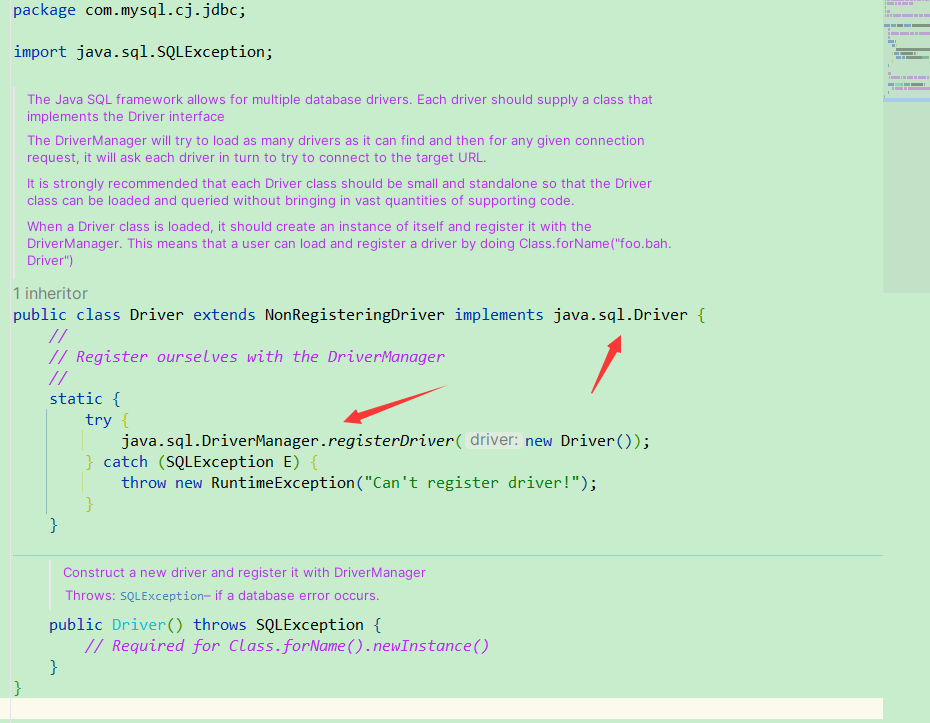
那么实际DriverManager就只是把你传进来的Driver进行封装保存。
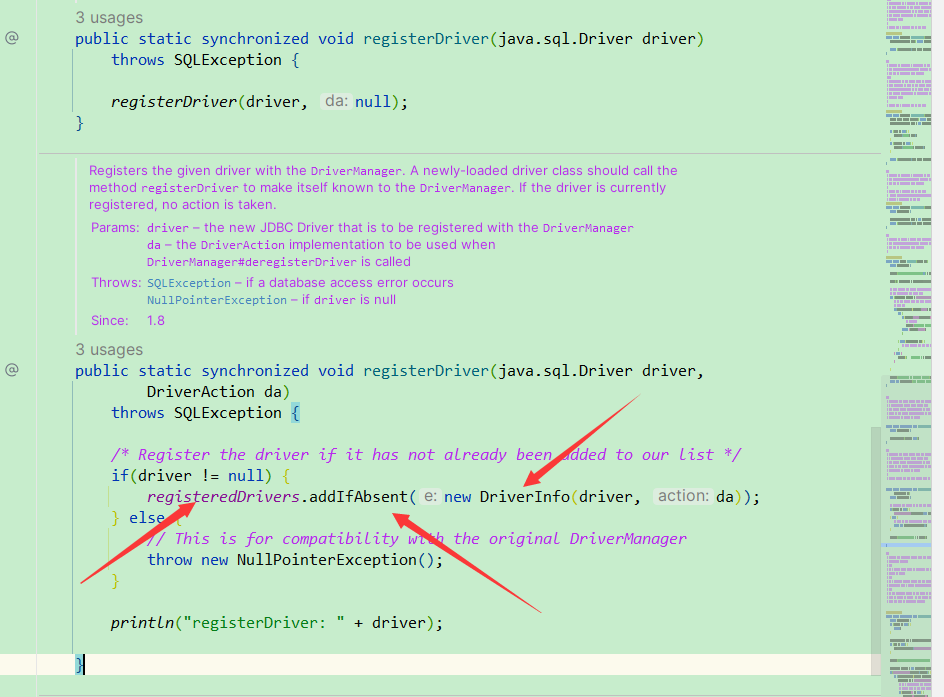
然后实际上我们这里就是调用了MySQL的Driver的connection方法。
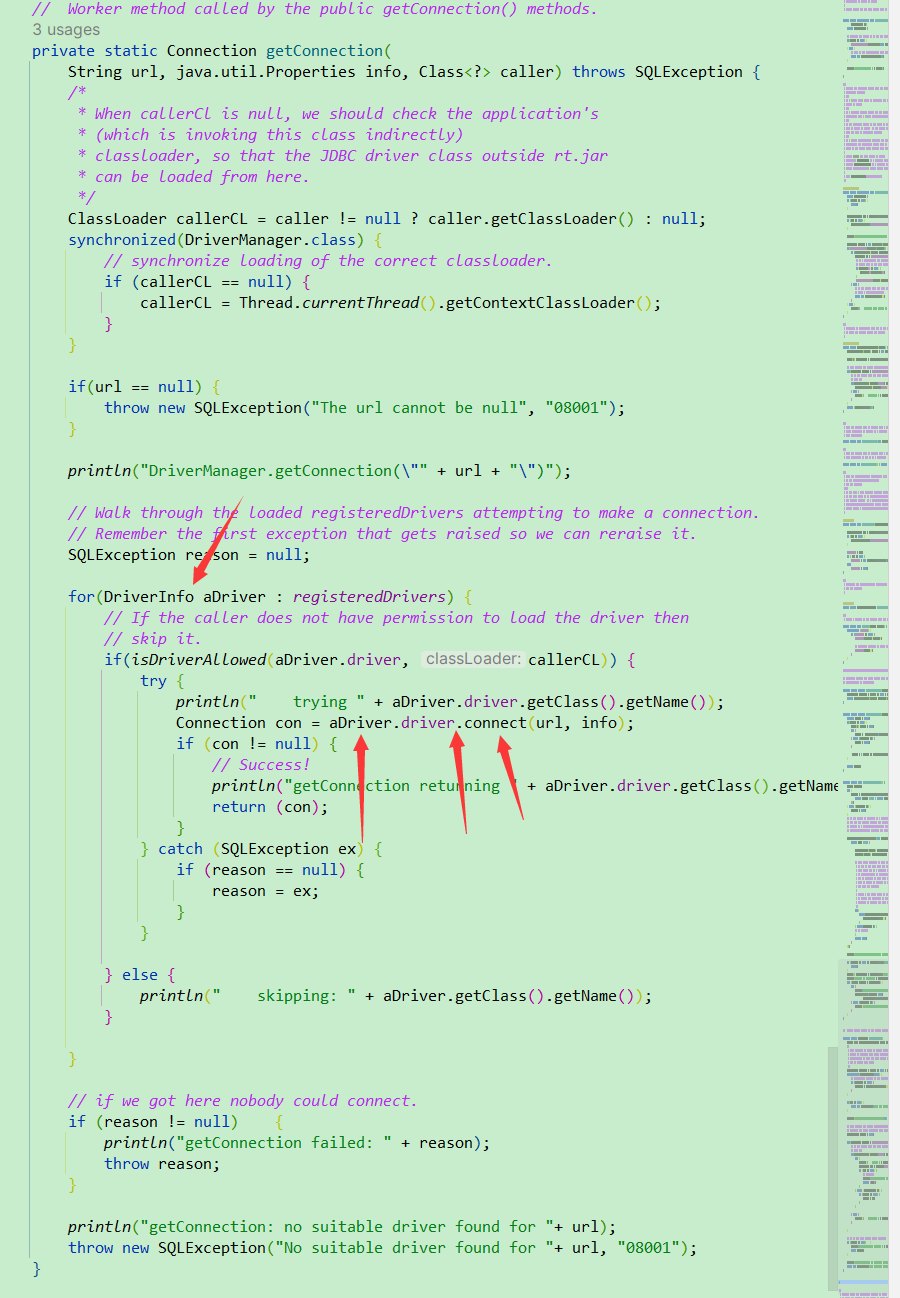
因此,MySQL的Driver就通过这样子的DriverManager与JDBC建立好了链接,从而我们可以方便的使用数据库。
这里我们的抽象维度其实就是我们的DriverManager,而我们的MySQL的Driver就是具体的实现维度,MySQL这边改变了没关系,只要你依旧符合我的DM的规范即可。从而使得他们都可以相互独立的变换。