文章目录
- 前言
- 一、mamba结构构建辅助函数解读
- 1、@dataclass方法解读
- 2、Norm归一化
- LayerNorm
- RMSNorm
- RMSNorm源码
- 3、nn.Parameter方法解读
- 二、mamba原理
- 二、mamba模型构建
- 1、主函数入口源码解读
- 2、Mamba类源码解读
- 三、ResidualBlock的mamba结构源码解读
- 四、MambaBlock构成ResidualBlock模块源码解读
- 1、线性结构(获得x与res)
- 2、1维卷积结构(x加工)
- 3、激活结构(x加工)
- 4、ssm结构(x加工)
- 5、激活与连接(x与res加工)
- 6、线性结构(x与res结合后的加工)
- 五、MambaBlock构成ResidualBlock模块源码解读
- 1、ssm参数初始化
- 2、ssm结构
- 六、完整代码Demo
前言
深度神经网络(DNNs)在各种人工智能(AI)任务中展现出卓越的性能,其基本架构在确定模型能力方面发挥着关键作用。传统神经网络通常由多层感知器(MLP)或全连接(FC)层组成。卷积神经网络(CNNs)引入了卷积和池化层,特别适用于处理像图像这样的平移不变数据。循环神经网络(RNNs)利用循环单元处理序列或时间序列数据。为了解决CNN、RNN和GNN模型仅捕获局部关系的问题,2017年引入的Transformer在学习远距离特征表示方面表现出色。Transformer主要依赖于基于注意力的注意力机制,例如自注意力和交叉注意力,来提取内在特征并提高其表示能力。预训练的大规模基于Transformer的模型,如GPT-3,在各种NLP数据集上表现出色,在自然语言理解和生成任务中表现突出。Transformer-based模型的显著性能推动了它们在视觉应用中的广泛采用。Transformer模型的核心是其在捕获长距离依赖关系和最大化利用大型数据集方面的出色能力。特征提取模块是视觉Transformer架构的主要组成部分,它使用一系列自注意力块处理数据,显著提高了分析图像的能力。为此,我给出该结构源码,并解读呈现于读者。
一、mamba结构构建辅助函数解读
1、@dataclass方法解读
@dataclass 是一个Python装饰器,用于简化创建数据类(data class)的过程。数据类是一种用于存储数据的特殊类,它自动为你的类添加一些特殊方法,如 init、repr、eq 等,从而使你可以更轻松地创建和操作数据对象。
使用 @dataclass 装饰器可以自动为类添加一些标准方法,而无需手动编写这些方法。以下是 @dataclass 的一些主要特性:
自动生成 init 方法:@dataclass 装饰器会自动为类生成 init 方法,从而简化实例化对象时的参数传递。
自动生成 repr 方法:@dataclass 装饰器会自动为类生成 repr 方法,以便在打印对象时提供有用的信息。
自动生成 eq 方法:@dataclass 装饰器会自动为类生成 eq 方法,用于比较两个对象是否相等。
自动生成 hash 方法:如果需要将对象用作字典的键或集合的成员,@dataclass 装饰器会自动为类生成 hash 方法。
自动生成 str 方法:@dataclass 装饰器会自动为类生成 str 方法,用于返回对象的字符串表示形式。
以下是一个简单的示例,展示了如何使用 @dataclass 创建一个数据类:
from dataclasses import dataclass# 使用 @dataclass 装饰器创建数据类
@dataclass
class Point:x: inty: int# 创建 Point 对象
p = Point(3, 4)# 打印对象信息
print(p) # 输出: Point(x=3, y=4)在这个示例中,我们使用 @dataclass 装饰器创建了一个名为 Point 的数据类,它具有属性 x 和 y。通过使用装饰器,我们不必手动编写 init、repr 等方法,这些方法会被自动生成。当我们实例化一个 Point 对象并打印它时,会得到一个带有属性值的字符串表示形式。
2、Norm归一化
本次mamba采用RMSNorm,为此我简单介绍Norm相关内容,如下:
LayerNorm
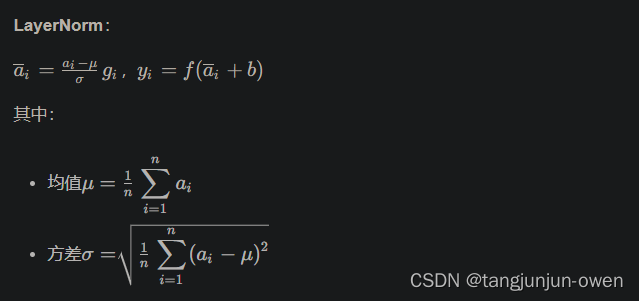
RMSNorm
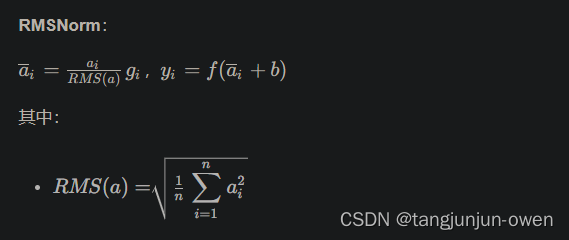
不考虑re-center,效果几乎相似但效率更高
是LayerNorm中均值为0的特殊情况
图来源:这里
RMSNorm源码
源码如下:
class RMSNorm(nn.Module):def __init__(self,d_model: int,eps: float = 1e-5):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(d_model))def forward(self, x):output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) * self.weightreturn output
3、nn.Parameter方法解读
nn.Parameter 是 PyTorch 中的一个类,用于将张量(tensor)包装成模型参数,使其能够被优化器训练。通过将张量包装成 nn.Parameter,PyTorch 将自动跟踪此参数的梯度,并在反向传播过程中更新参数的数值。
详细解释:
nn.Parameter 是 torch.nn.Parameter 类的实例,它继承自 torch.Tensor 类。
当你将一个张量包装成 nn.Parameter 时,这个张量就会被标记为模型参数,可以在模型的参数列表中被访问和优化。
通过将张量包装成 nn.Parameter,你可以方便地定义模型参数,并在训练过程中更新这些参数的数值。
下面是 nn.Parameter 的详细解释和一个简单的示例演示如何使用它:
import torch
import torch.nn as nn# 创建一个普通张量
tensor = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float)# 将张量包装成 nn.Parameter
param = nn.Parameter(tensor)# 打印 nn.Parameter 对象
print(param)# 访问 nn.Parameter 的梯度属性
print("Gradient:", param.grad)# 访问 nn.Parameter 的数据属性
print("Data:", param.data)在这个示例中,我们首先创建了一个普通的张量 tensor,然后将其包装成 nn.Parameter 类型的对象 param。我们展示了如何打印 nn.Parameter 对象、访问其梯度属性和数据属性。请注意,只有 nn.Parameter 类型的对象才会在反向传播过程中跟踪梯度并更新参数值。
注:参数是可以更新的!
二、mamba原理
随着SSMs的发展,一种名为Mamba的新型选择性状态空间模型已经出现。它通过两项关键改进推进了使用状态空间模型(SSMs)对离散数据(如文本)进行建模。首先,它具有一个依赖于输入的机制,动态调整SSM参数,增强信息过滤。其次,Mamba使用一种硬件感知算法,根据序列长度线性处理数据,在现代系统上提高计算速度。受Mamba在语言建模中的成就启发,现在有几个倡议旨在将这一成功案例应用于视觉领域。一些研究探索了它与专家混合(MoE)技术的集成,如Jamba、MoE-Mamba和BlackMamba等文章表明,它们在较少的训练步骤下胜过了最先进的Transformer-MoE架构。如图1(b)所示,自2023年12月发布Mamba以来,专注于Mamba在视觉领域的研究论文数量迅速增加,于2024年3月达到峰值。这一趋势表明,Mamba正在成为视觉领域的一个突出研究领域,可能为Transformer提供一个可行的替代方案。而mamba原理实际如下图显示,至于公式推倒啥的,我这里不在介绍。之所以给出此图,后面mamba结构就是按照此图来构建,以便读者可比较与参考。
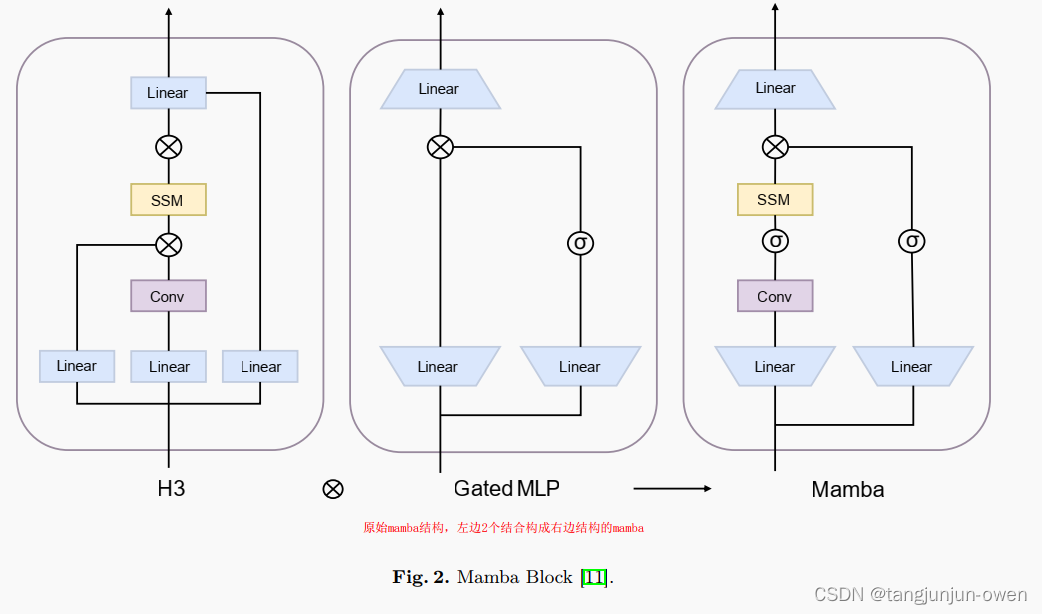
二、mamba模型构建
这里,我们介绍mamba模型结构Demo,给出如何构建数据与调用mamba模型。
1、主函数入口源码解读
以下代码是构建mamba相关参数配置与输入数据,可看出我们给出数据是batch、length,而input_data是字典映射的索引。具体代码如下:
if __name__ == '__main__':# 创建一个简单的Mamba模型实例vocab_size = 32000n_layer = 2d_model = 128model_args = ModelArgs(d_model=d_model, n_layer=n_layer, vocab_size=vocab_size)model_args.__post_init__()mamba_model = Mamba(model_args)# 生成随机整数张量,元素范围在1到999之间, 输入为batch,length分别表示批量,一个句子长度,每个词对应索引input_data = torch.randint(low=1, high=vocab_size, size=(2, 200))output = mamba_model(input_data)print(output.shape)2、Mamba类源码解读
这里,我们构建了一个mamba模型,实际构建mamba结构是ResidualBlock模块。没错,我们构建一个类似残差结构的mamba结构。随后,我们看到forward函数,可看出输入经过embedding后将其使用d_model维度表达,变成B L D结构。然后在经过layer结构,每次输出均为B L D结构数据,这个就是mamba模块加工模型。最后经过一个RMSNorm结构,在经过lm_head结构,即完成词的预测。具体代码如下:
class Mamba(nn.Module):def __init__(self, args: ModelArgs):"""Full Mamba model."""super().__init__()self.args = argsself.embedding = nn.Embedding(args.vocab_size, args.d_model)self.layers = nn.ModuleList([ResidualBlock(args) for _ in range(args.n_layer)])self.norm_f = RMSNorm(args.d_model)self.lm_head = nn.Linear(args.d_model, args.vocab_size, bias=False)self.lm_head.weight = self.embedding.weight # Tie output projection to embedding weights.# See "Weight Tying" paperdef forward(self, input_ids):x = self.embedding(input_ids)for layer in self.layers:x = layer(x)x = self.norm_f(x)logits = self.lm_head(x)return logits三、ResidualBlock的mamba结构源码解读
这个就是每一层结构,我们可以看出输入为(b, l, d),输出也为(b, l, d)结构,只是进行了特征提取,而不改变数据shape。同时,我们也看到这里使用了RMSNorm方法进行归一化的。
class ResidualBlock(nn.Module):def __init__(self, args: ModelArgs):"""Simple block wrapping Mamba block with normalization and residual connection."""super().__init__()self.args = argsself.mixer = MambaBlock(args)self.norm = RMSNorm(args.d_model)def forward(self, x):"""Args:x: shape (b, l, d) (See Glossary at top for definitions of b, l, d_in, n...)Returns:output: shape (b, l, d)"""output = self.mixer(self.norm(x)) + xreturn output在这个forward中,我们可知是一个类似残差的方法结构,x会做norm归一化后,再进行self.mixer结构(即使mamba方法),使用self.mixer(self.norm(x))此代码。接下来,我将介绍self.mixer = MambaBlock(args)结构。
四、MambaBlock构成ResidualBlock模块源码解读
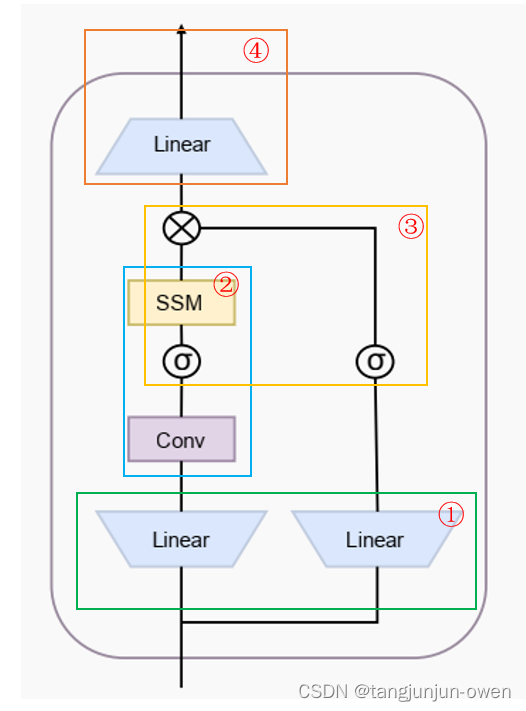
1、线性结构(获得x与res)
首先将输入x为(b, l, d)通过self.in_proj将其转换(b, l, 2 * d_in),也就是下图有圆圈①的结构。当然也可以分别使用对x进行,但这里直接一起使用,在通过x_and_res.split方法划分。其中res就是下图右边,x就是下图左边模块。
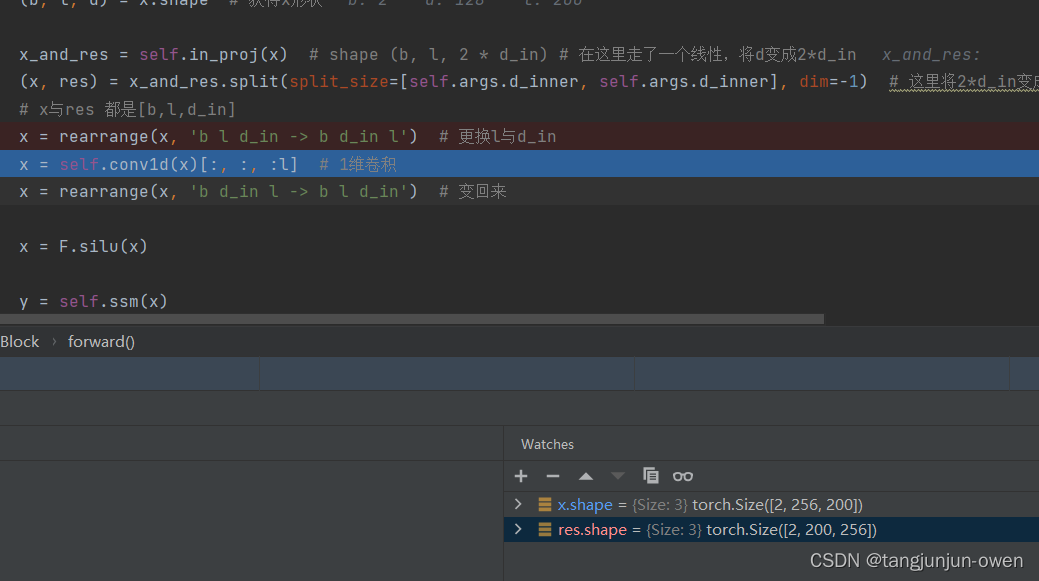
(b, l, d) = x.shape # 获得x形状x_and_res = self.in_proj(x) # shape (b, l, 2 * d_in) # 在这里走了一个线性,将d变成2*d_in(x, res) = x_and_res.split(split_size=[self.args.d_inner, self.args.d_inner], dim=-1) # 这里将2*d_in变成2个d_in,分别为x与res# x与res 都是[b,l,d_in]2、1维卷积结构(x加工)
变换x位置,使用1维卷积加工x输出,再变回原来格式,如下图②结构的一维卷积。
x = rearrange(x, 'b l d_in -> b d_in l') # 更换l与d_in
x = self.conv1d(x)[:, :, :l] # 1维卷积
x = rearrange(x, 'b d_in l -> b l d_in') # 变回来
3、激活结构(x加工)
使用silu对x输出进行激活,如下图②结构的激活。
x = F.silu(x) # 使用silu激活函数
4、ssm结构(x加工)
这一步很重要,我会单独说明。我们需要知道这里x从最开始假设输入为[2,200,128]变成了[2,200,256]。该部分就是下图②结构的ssm。
y = self.ssm(x)
5、激活与连接(x与res加工)
这一步将上面加工x输出y与res进行silu激活后,使用对应乘法方式将其连接起来。如下代码,如下图③结构(排除包含②结构框内容)。
y = y * F.silu(res)
6、线性结构(x与res结合后的加工)
这一步将上面加工输出y,使用线性结构,还有一个目的将d_in变回来为d。如下代码,如下图④结构。
output = self.out_proj(y)
部分代码结构截图,如下:
五、MambaBlock构成ResidualBlock模块源码解读
1、ssm参数初始化
主要记住self.A_log与self.D参数。我感觉这里有点类似DETR设置query方式,也是最后通过模型更新一个适合模型参数。
A = repeat(torch.arange(1, args.d_state + 1), 'n -> d n', d=args.d_inner)
self.A_log = nn.Parameter(torch.log(A))
self.D = nn.Parameter(torch.ones(args.d_inner))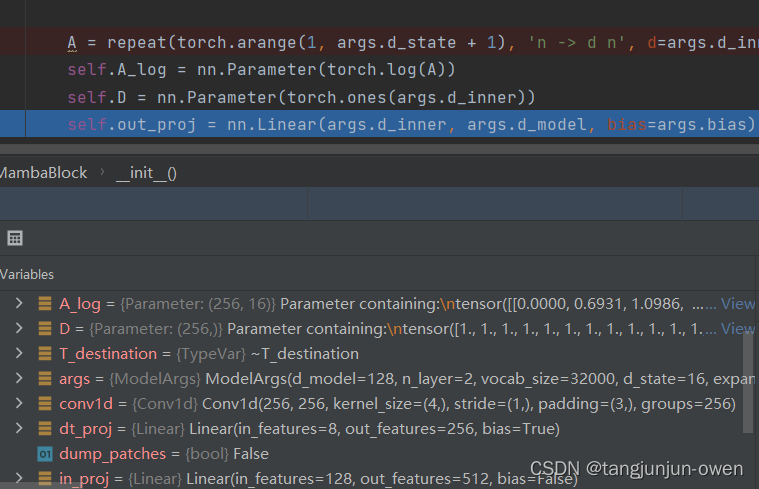
2、ssm结构
这里,直接调用ssm函数。但是我还不太明确公式,我也不在这里做解释了。可以参考一篇文章这里理解。
def ssm(self, x):"""Runs the SSM. See:- Algorithm 2 in Section 3.2 in the Mamba paper [1]- run_SSM(A, B, C, u) in The Annotated S4 [2]Args:x: shape (b, l, d_in) (See Glossary at top for definitions of b, l, d_in, n...)Returns:output: shape (b, l, d_in)Official Implementation:mamba_inner_ref(), https://github.com/state-spaces/mamba/blob/main/mamba_ssm/ops/selective_scan_interface.py#L311"""(d_in, n) = self.A_log.shape# Compute ∆ A B C D, the state space parameters.# A, D are input independent (see Mamba paper [1] Section 3.5.2 "Interpretation of A" for why A isn't selective)# ∆, B, C are input-dependent (this is a key difference between Mamba and the linear time invariant S4,# and is why Mamba is called **selective** state spaces)A = -torch.exp(self.A_log.float()) # shape (d_in, n)D = self.D.float()x_dbl = self.x_proj(x) # (b, l, dt_rank + 2*n)(delta, B, C) = x_dbl.split(split_size=[self.args.dt_rank, n, n],dim=-1) # delta: (b, l, dt_rank). B, C: (b, l, n)delta = F.softplus(self.dt_proj(delta)) # (b, l, d_in)y = self.selective_scan(x, delta, A, B, C, D) # This is similar to run_SSM(A, B, C, u) in The Annotated S4 [2]return ydef selective_scan(self, u, delta, A, B, C, D):"""Does selective scan algorithm. See:- Section 2 State Space Models in the Mamba paper [1]- Algorithm 2 in Section 3.2 in the Mamba paper [1]- run_SSM(A, B, C, u) in The Annotated S4 [2]This is the classic discrete state space formula:x(t + 1) = Ax(t) + Bu(t)y(t) = Cx(t) + Du(t)except B and C (and the step size delta, which is used for discretization) are dependent on the input x(t).Args:u: shape (b, l, d_in) (See Glossary at top for definitions of b, l, d_in, n...)delta: shape (b, l, d_in)A: shape (d_in, n)B: shape (b, l, n)C: shape (b, l, n)D: shape (d_in,)Returns:output: shape (b, l, d_in)Official Implementation:selective_scan_ref(), https://github.com/state-spaces/mamba/blob/main/mamba_ssm/ops/selective_scan_interface.py#L86Note: I refactored some parts out of `selective_scan_ref` out, so the functionality doesn't match exactly."""(b, l, d_in) = u.shapen = A.shape[1]# Discretize continuous parameters (A, B)# - A is discretized using zero-order hold (ZOH) discretization (see Section 2 Equation 4 in the Mamba paper [1])# - B is discretized using a simplified Euler discretization instead of ZOH. From a discussion with authors:# "A is the more important term and the performance doesn't change much with the simplification on B"deltaA = torch.exp(einsum(delta, A, 'b l d_in, d_in n -> b l d_in n'))deltaB_u = einsum(delta, B, u, 'b l d_in, b l n, b l d_in -> b l d_in n')# Perform selective scan (see scan_SSM() in The Annotated S4 [2])# Note that the below is sequential, while the official implementation does a much faster parallel scan that# is additionally hardware-aware (like FlashAttention).x = torch.zeros((b, d_in, n), device=deltaA.device)ys = []for i in range(l):x = deltaA[:, i] * x + deltaB_u[:, i]y = einsum(x, C[:, i, :], 'b d_in n, b n -> b d_in')ys.append(y)y = torch.stack(ys, dim=1) # shape (b, l, d_in)y = y + u * Dreturn y
六、完整代码Demo
最后,我附上复制粘贴即可使用源码,该源码截取github官网,只是修改了数据格式和参数,具体如下:
"""Simple, minimal implementation of Mamba in one file of PyTorch.Suggest reading the following before/while reading the code:[1] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Albert Gu and Tri Dao)https://arxiv.org/abs/2312.00752[2] The Annotated S4 (Sasha Rush and Sidd Karamcheti)https://srush.github.io/annotated-s4Glossary:b: batch size (`B` in Mamba paper [1] Algorithm 2)l: sequence length (`L` in [1] Algorithm 2)d or d_model: hidden dimn or d_state: latent state dim (`N` in [1] Algorithm 2)expand: expansion factor (`E` in [1] Section 3.4)d_in or d_inner: d * expand (`D` in [1] Algorithm 2)A, B, C, D: state space parameters (See any state space representation formula)(B, C are input-dependent (aka selective, a key innovation in Mamba); A, D are not)Δ or delta: input-dependent step sizedt_rank: rank of Δ (See [1] Section 3.6 "Parameterization of ∆")"""
from __future__ import annotations
import mathimport torch
import torch.nn as nn
import torch.nn.functional as F
from dataclasses import dataclass
from einops import rearrange, repeat, einsumfrom typing import Union@dataclass
class ModelArgs:d_model: intn_layer: intvocab_size: intd_state: int = 16expand: int = 2dt_rank: Union[int, str] = 'auto'd_conv: int = 4pad_vocab_size_multiple: int = 8conv_bias: bool = Truebias: bool = Falsedef __post_init__(self):self.d_inner = int(self.expand * self.d_model)if self.dt_rank == 'auto':self.dt_rank = math.ceil(self.d_model / 16)if self.vocab_size % self.pad_vocab_size_multiple != 0:self.vocab_size += (self.pad_vocab_size_multiple- self.vocab_size % self.pad_vocab_size_multiple)class Mamba(nn.Module):def __init__(self, args: ModelArgs):"""Full Mamba model."""super().__init__()self.args = argsself.embedding = nn.Embedding(args.vocab_size, args.d_model)self.layers = nn.ModuleList([ResidualBlock(args) for _ in range(args.n_layer)])self.norm_f = RMSNorm(args.d_model)self.lm_head = nn.Linear(args.d_model, args.vocab_size, bias=False)self.lm_head.weight = self.embedding.weight # Tie output projection to embedding weights.# See "Weight Tying" paperdef forward(self, input_ids):"""Args:input_ids (long tensor): shape (b, l) (See Glossary at top for definitions of b, l, d_in, n...)Returns:logits: shape (b, l, vocab_size)Official Implementation:class MambaLMHeadModel, https://github.com/state-spaces/mamba/blob/main/mamba_ssm/models/mixer_seq_simple.py#L173"""x = self.embedding(input_ids)for layer in self.layers:x = layer(x)x = self.norm_f(x)logits = self.lm_head(x)return logitsclass ResidualBlock(nn.Module):def __init__(self, args: ModelArgs):"""Simple block wrapping Mamba block with normalization and residual connection."""super().__init__()self.args = argsself.mixer = MambaBlock(args)self.norm = RMSNorm(args.d_model)def forward(self, x):"""Args:x: shape (b, l, d) (See Glossary at top for definitions of b, l, d_in, n...)Returns:output: shape (b, l, d)Official Implementation:Block.forward(), https://github.com/state-spaces/mamba/blob/main/mamba_ssm/modules/mamba_simple.py#L297Note: the official repo chains residual blocks that look like[Add -> Norm -> Mamba] -> [Add -> Norm -> Mamba] -> [Add -> Norm -> Mamba] -> ...where the first Add is a no-op. This is purely for performance reasons as thisallows them to fuse the Add->Norm.We instead implement our blocks as the more familiar, simpler, and numerically equivalent[Norm -> Mamba -> Add] -> [Norm -> Mamba -> Add] -> [Norm -> Mamba -> Add] -> ...."""output = self.mixer(self.norm(x)) + xreturn outputclass MambaBlock(nn.Module):def __init__(self, args: ModelArgs):"""A single Mamba block, as described in Figure 3 in Section 3.4 in the Mamba paper [1]."""super().__init__()self.args = argsself.in_proj = nn.Linear(args.d_model, args.d_inner * 2, bias=args.bias)self.conv1d = nn.Conv1d(in_channels=args.d_inner,out_channels=args.d_inner,bias=args.conv_bias,kernel_size=args.d_conv,groups=args.d_inner,padding=args.d_conv - 1,)# x_proj takes in `x` and outputs the input-specific Δ, B, Cself.x_proj = nn.Linear(args.d_inner, args.dt_rank + args.d_state * 2, bias=False)# dt_proj projects Δ from dt_rank to d_inself.dt_proj = nn.Linear(args.dt_rank, args.d_inner, bias=True)A = repeat(torch.arange(1, args.d_state + 1), 'n -> d n', d=args.d_inner)self.A_log = nn.Parameter(torch.log(A))self.D = nn.Parameter(torch.ones(args.d_inner))self.out_proj = nn.Linear(args.d_inner, args.d_model, bias=args.bias)def forward(self, x):"""Mamba block forward. This looks the same as Figure 3 in Section 3.4 in the Mamba paper [1].Args:x: shape (b, l, d) (See Glossary at top for definitions of b, l, d_in, n...)Returns:output: shape (b, l, d)Official Implementation:class Mamba, https://github.com/state-spaces/mamba/blob/main/mamba_ssm/modules/mamba_simple.py#L119mamba_inner_ref(), https://github.com/state-spaces/mamba/blob/main/mamba_ssm/ops/selective_scan_interface.py#L311"""(b, l, d) = x.shape # 获得x形状x_and_res = self.in_proj(x) # shape (b, l, 2 * d_in) # 在这里走了一个线性,将d变成2*d_in(x, res) = x_and_res.split(split_size=[self.args.d_inner, self.args.d_inner], dim=-1) # 这里将2*d_in变成2个d_in,分别为x与res# x与res 都是[b,l,d_in]x = rearrange(x, 'b l d_in -> b d_in l') # 更换l与d_inx = self.conv1d(x)[:, :, :l] # 1维卷积x = rearrange(x, 'b d_in l -> b l d_in') # 变回来x = F.silu(x) # 使用silu激活函数y = self.ssm(x)y = y * F.silu(res)output = self.out_proj(y)return outputdef ssm(self, x):"""Runs the SSM. See:- Algorithm 2 in Section 3.2 in the Mamba paper [1]- run_SSM(A, B, C, u) in The Annotated S4 [2]Args:x: shape (b, l, d_in) (See Glossary at top for definitions of b, l, d_in, n...)Returns:output: shape (b, l, d_in)Official Implementation:mamba_inner_ref(), https://github.com/state-spaces/mamba/blob/main/mamba_ssm/ops/selective_scan_interface.py#L311"""(d_in, n) = self.A_log.shape# Compute ∆ A B C D, the state space parameters.# A, D are input independent (see Mamba paper [1] Section 3.5.2 "Interpretation of A" for why A isn't selective)# ∆, B, C are input-dependent (this is a key difference between Mamba and the linear time invariant S4,# and is why Mamba is called **selective** state spaces)A = -torch.exp(self.A_log.float()) # shape (d_in, n)D = self.D.float()x_dbl = self.x_proj(x) # (b, l, dt_rank + 2*n)(delta, B, C) = x_dbl.split(split_size=[self.args.dt_rank, n, n],dim=-1) # delta: (b, l, dt_rank). B, C: (b, l, n)delta = F.softplus(self.dt_proj(delta)) # (b, l, d_in)y = self.selective_scan(x, delta, A, B, C, D) # This is similar to run_SSM(A, B, C, u) in The Annotated S4 [2]return ydef selective_scan(self, u, delta, A, B, C, D):"""Does selective scan algorithm. See:- Section 2 State Space Models in the Mamba paper [1]- Algorithm 2 in Section 3.2 in the Mamba paper [1]- run_SSM(A, B, C, u) in The Annotated S4 [2]This is the classic discrete state space formula:x(t + 1) = Ax(t) + Bu(t)y(t) = Cx(t) + Du(t)except B and C (and the step size delta, which is used for discretization) are dependent on the input x(t).Args:u: shape (b, l, d_in) (See Glossary at top for definitions of b, l, d_in, n...)delta: shape (b, l, d_in)A: shape (d_in, n)B: shape (b, l, n)C: shape (b, l, n)D: shape (d_in,)Returns:output: shape (b, l, d_in)Official Implementation:selective_scan_ref(), https://github.com/state-spaces/mamba/blob/main/mamba_ssm/ops/selective_scan_interface.py#L86Note: I refactored some parts out of `selective_scan_ref` out, so the functionality doesn't match exactly."""(b, l, d_in) = u.shapen = A.shape[1]# Discretize continuous parameters (A, B)# - A is discretized using zero-order hold (ZOH) discretization (see Section 2 Equation 4 in the Mamba paper [1])# - B is discretized using a simplified Euler discretization instead of ZOH. From a discussion with authors:# "A is the more important term and the performance doesn't change much with the simplification on B"deltaA = torch.exp(einsum(delta, A, 'b l d_in, d_in n -> b l d_in n'))deltaB_u = einsum(delta, B, u, 'b l d_in, b l n, b l d_in -> b l d_in n')# Perform selective scan (see scan_SSM() in The Annotated S4 [2])# Note that the below is sequential, while the official implementation does a much faster parallel scan that# is additionally hardware-aware (like FlashAttention).x = torch.zeros((b, d_in, n), device=deltaA.device)ys = []for i in range(l):x = deltaA[:, i] * x + deltaB_u[:, i]y = einsum(x, C[:, i, :], 'b d_in n, b n -> b d_in')ys.append(y)y = torch.stack(ys, dim=1) # shape (b, l, d_in)y = y + u * Dreturn yclass RMSNorm(nn.Module):def __init__(self,d_model: int,eps: float = 1e-5):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(d_model))def forward(self, x):output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) * self.weightreturn outputif __name__ == '__main__':# 创建一个简单的Mamba模型实例vocab_size = 32000n_layer = 2d_model = 128model_args = ModelArgs(d_model=d_model, n_layer=n_layer, vocab_size=vocab_size)model_args.__post_init__()mamba_model = Mamba(model_args)# 生成随机整数张量,元素范围在1到999之间, 输入为batch,length分别表示批量,一个句子长度,每个词对应索引input_data = torch.randint(low=1, high=vocab_size, size=(2, 200))output = mamba_model(input_data)print(output.shape)