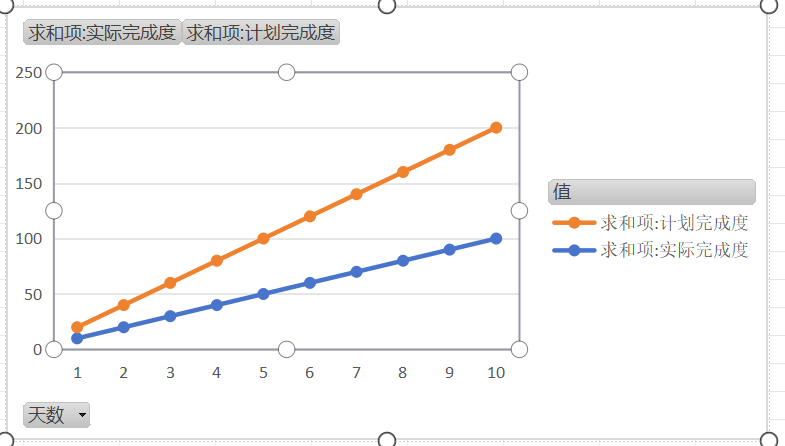
接着上期,CBOW模型无法解决文章内容过长的单词预测的,那该如何解决呢?
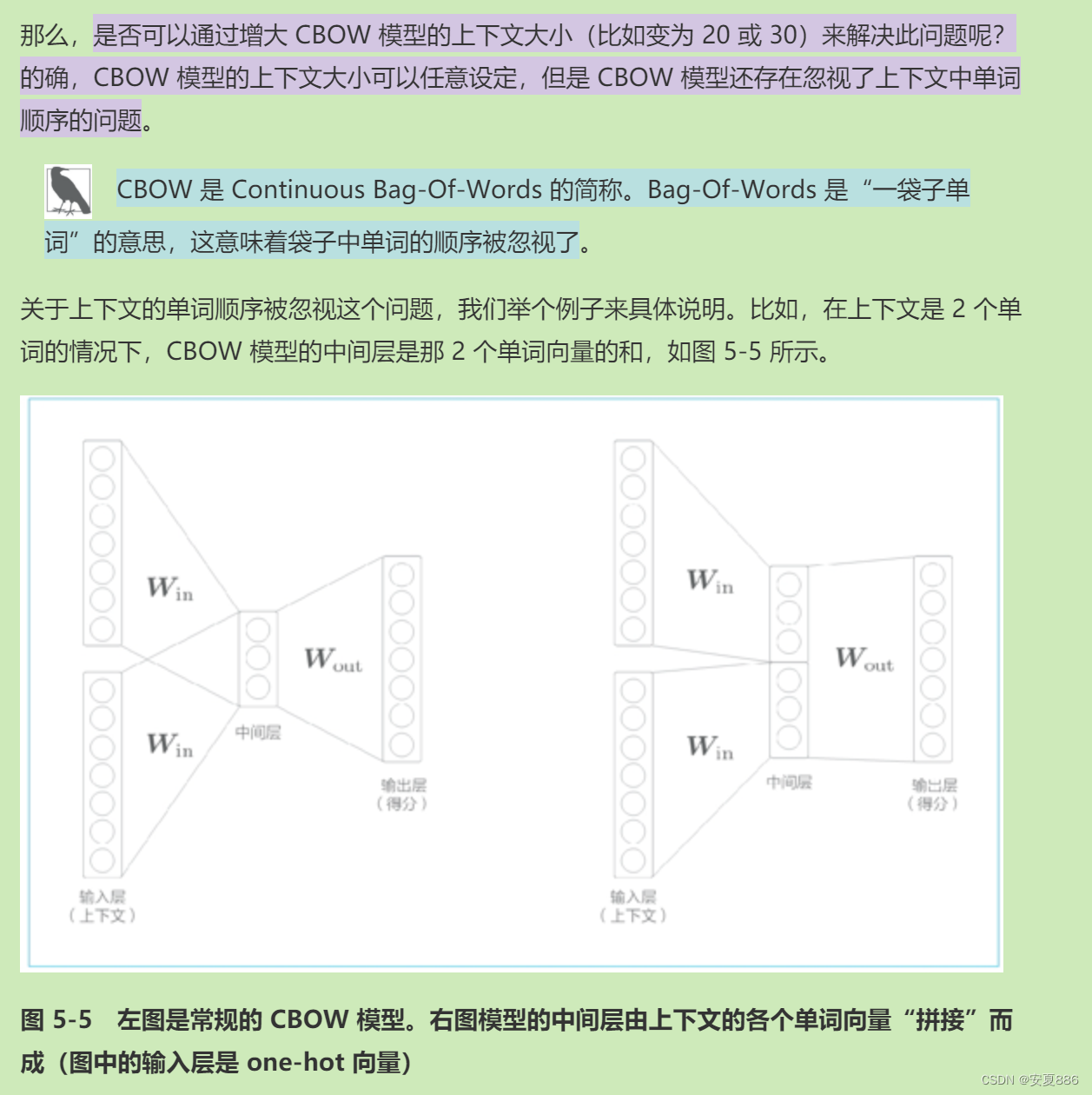
除此之外,根据图中5-5的左图所示,在CBOW模型的中间层求单词向量的和,这时就会出现另一个问题的,那就是上下文的单词的顺序将会被打乱的;举个例子:(you, say)和(say, you)会被视为相同内容处理的,这又该如何解决呢?

方案一:拼接法,就如5-5图右侧的那样,在中间层“拼接”上下文的单词向量的。
但是,这时候新的问题又出现了的,采用拼接法固然可以解决上一个问题的,但是,这时候就会发生一系列连锁反应的,出现新的问题的:权重参数等比例增加,处理的数据量爆炸式增加!
这时候有该如何解决呢?嘿嘿!
主角终于还是在最后登场的啦,有请RNN大哥善良登场的
RNN有一个特性:
 是不是感觉用RNN解决这个问题,专业且对口,哈哈。
是不是感觉用RNN解决这个问题,专业且对口,哈哈。
总结:专业的领域就应该派出合适的人解决它的,不禁让老夫想到“万物相生相克!”大道就在脚下,冲啊!热血少年
小故事驿站:

5.2 RNN
RNN(Recurrent Neural Network)中的 Recurrent 源自拉丁语,意思是“反复发生。

RNN核心:RNN 的特征就在于拥有这样一个环路(或回路)。这个环路可以使数据不断循环。通过数据的循环,RNN 一边记住过去的数据,一边更新到最新的数据。

5.2.2 展开循环

从图中可以看出:RNN类似于曾经的前馈神经网络结构是相同的
二者区别:前馈神经网络的数据是一个方向传播的,而RNN是向两个方向传播的嘛,为啥?分叉呗,他的输出数据被复制了一份返回输入了的。
还有多个RNN都是同一个层,怎么理解呢?就是他是个循环的,所以就相当于在同一个层的,这一点也是与之前的神经网络不一样的。

为什么说RNN具有状态呢?因为:RNN不是输出时复制了一份吗?我个人的理解就是他在每一个计算的结束留下了一个表明时间的影子的,以此来处理时序问题。
5.2.3 Backpropagation Through Time
这个东西是干什么的?
用来计算“按时间顺序展开的神经网络的误差反向传播法”,所以引入Backpropagation Through Time的,(中文:基于时间的反向传播法),方便起见,就把他简称为BPTT吧。
用来常规的误差反向传播法,看似就可以让RNN学习了的,但是,又有新问题了的,随着RNN学习长时序的问题时,随着数据的不断增多,BPTT消耗的计算机资源也会不断增加的,当增加到一定程度时,反向传播的梯度也会变得极其不稳定的,就等同盖的高楼是豆腐渣工程,很可能一夜回到解放前,崩溃掉。
然后呢,引入了新的伙伴:Truncated BPTT
他是干啥子的?帮忙解决上述问题的;
他的核心:就是将一条长长的网络连接分成小段的,分开处理,间接减小他的处理太长时序数据的工作量,避免累垮掉Backpropagation Trough Time的(也就是处理时序问题的反向传播法的)。
登场:
5.2.4 Truncated BPTT

抽象剪刀图片:

这时我们剪断了反向传播的连接的,以使它可以以10个RNN层为单位进行反向传播的。但是要注意的是:他斩断的只是反向传播的,不影响正向传播的正常进行的。
然后呢,困难又来了的,正向传播前后数据之间不是都有关系的嘛,这就可以间接的想到我们最初的问题中的数据的顺序问题的,这意味着数据必须是按照顺序输入的
困难已至,我们该怎么办的?躲不掉,那就干掉他!
干掉他的方法如下:


总结:核心就是保留上一个斩断部分的隐藏层h的(说人话就是曾经被我们复制的两份输出的嘞)
原理类似于数据结构的链表的指针域的,(指针域中会存储着上一个数据的位置的,可以认为是间接排序)。
好处:不会乱序的,解决掉了斩断乱序的困难的。
接着嘞,困难又来了,mini-batch学习,需要考虑批数据的,这咋办,接着干掉他。
这时,又请来了“偏移”来干掉他。

抽象理解:就是假如数据有一千份,可以把他从中间斩断,变成两批数据去完成mini-batch的

原理解释:

核心:斩断后的两组数据同样按照一组数据处理的操作进行的,只不过将一组变为了两组的额,类似之前让你计算一个1+1,现在拓展一下,计算两个1+1的。
5.3 RNN的实现

CORE(核心):引入两个大箱子:hs,xs;hs装RNN每次输出的数据h,xs装RNN每次输入的数据x的。

5.3.1 RNN的实现
class RNN:def __init__(self, Wx, Wh, b):self.params = [Wx, Wh, b]self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]self.cache = Nonedef forward(self, x, h_prev):Wx, Wh, b = self.paramst = np.dot(h_prev, Wh) + np.dot(x, Wx) + bh_next = np.tanh(t)self.cache = (x, h_prev, h_next)return h_next
# params:用来保存列表类型的成员变量的。
# grads:保存各个参数对应的形状初始化梯度的
# cache:保存反向传播时用到的中间层数据
RNN的backward:
def backward(self, dh_next):Wx, Wh, b = self.paramsx, h_prev, h_next = self.cachedt = dh_next * (1 - h_next ** 2)db = np.sum(dt, axis=0)dWh = np.dot(h_prev.T, dt)dh_prev = np.dot(dt, Wh.T)dWx = np.dot(x.T, dt)dx = np.dot(dt, Wx.T)self.grads[0][...] = dWxself.grads[1][...] = dWhself.grads[2][...] = dbreturn dx, dh_prevTime RNN:
def backward(self, dh_next):Wx, Wh, b = self.paramsx, h_prev, h_next = self.cachedt = dh_next * (1 - h_next ** 2)db = np.sum(dt, axis=0)dWh = np.dot(h_prev.T, dt)dh_prev = np.dot(dt, Wh.T)dWx = np.dot(x.T, dt)dx = np.dot(dt, Wx.T)self.grads[0][...] = dWxself.grads[1][...] = dWhself.grads[2][...] = dbreturn dx, dh_prev

RNN forward:
def forward(self, xs):Wx, Wh, b = self.paramsN, T, D = xs.shapeD, H = Wx.shapeself.layers = []hs = np.empty((N, T, H), dtype='f')if not self.stateful or self.h is None:self.h = np.zeros((N, H), dtype='f')for t in range(T):layer = RNN(*self.params)self.h = layer.forward(xs[:, t, :], self.h)hs[:, t, :] = self.hself.layers.append(layer)return hs第t个RNN的反向传播的实现:
def backward(self, dhs):Wx, Wh, b = self.paramsN, T, H = dhs.shapeD, H = Wx.shape dxs = np.empty((N, T, D), dtype='f')dh = 0grads = [0, 0, 0]for t in reversed(range(T)):layer = self.layers[t]dx, dh = layer.backward(dhs[:, t, :] + dh) # 求和后的梯度dxs[:, t, :] = dxfor i, grad in enumerate(layer.grads):grads[i] += gradfor i, grad in enumerate(grads):self.grads[i][...] = gradself.dh = dhreturn dxs
5.4 处理时序数据的层的实现


5.5.2 语言模型的评价



![[SNOI2019] 数论](https://img2024.cnblogs.com/blog/2490134/202405/2490134-20240507000711825-1944717934.png)