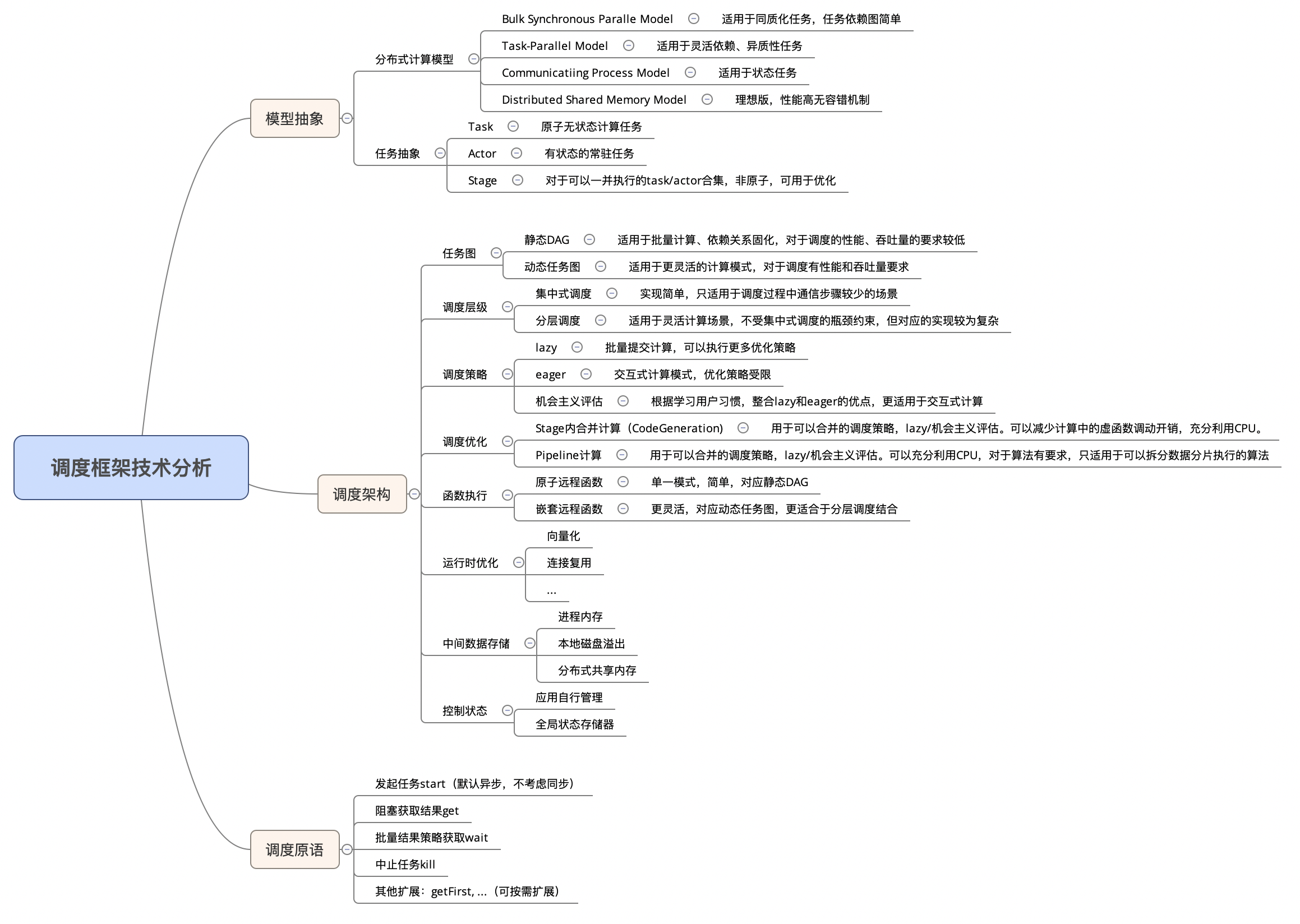
目录
一、分布式计算领域概览
二、Spark计算模型分析
三、Ray计算模型分析
3.1 需求分析
3.2 系统设计
3.3 系统实现
四、总结
一、分布式计算领域概览
当前分布式计算模型主要分为以下4种:
-
Bulk Synchronous Parallel Model(块同步并行模型)
-
BSP模型在大数据处理场景下应用非常广泛,例如MapReduce、Spark等框架都是采用BSP模型。BSP编程模型的实现较为简单,但也具有相当多的限制。
-
BSP模型具有以下特点:
-
BSP模型将计算划分为一个一个的超步(superstep),有效避免死锁。
-
它将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
-
采用障碍同步的方式以硬件实现的全局同步是在可控的粗粒度级,从而提供了执行紧耦合同步式并行算法的有效方式,而程序员并无过分的负担;
-
在分析BSP模型的性能时,假定局部操作可以在一个时间步内完成,而在每一个超级步中,一个处理器至多发送或接收h条消息(称为h-relation)。假定s是传输建立时间,所以传送h条消息的时间为gh+s,如果 ,则障碍同步时间L至少应该大于等于gh。很清楚,硬件可以将L设置尽量小(例如使用流水线或大的通信带宽使g尽量小),而软件可以设置L的上限(因为L越大,并行粒度越大)。在实际使用中,g可以定义为每秒处理器所能完成的局部计算数目与每秒路由器所能传输的数据量之比。如果能够合适的平衡计算和通信,则BSP模型在可编程性方面具有主要的优点,而直接在BSP模型上执行算法(不是自动的编译它们),这个优点将随着g的增加而更加明显;
-
BSP的成本模型:一个超步的计算成本

,其中wi是进程I的局部计算时间,hi是进程I发送或接受的最大通信包数,g是带宽的倒数(时间步/通信包),L是障碍同步时间。在BSP计算中,如果使用了s个超步,那总的运行时间为:
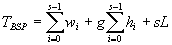
-
-
为PRAM模型所设计的算法,都可以采用在每个BSP处理器上模拟一些PRAM处理器的方法来实现。
-
-
但BSP模型的限制在于,它不支持状态,而且在无法天然拆解为多个超步(可以理解为MapReduce)的应用场景下并行计算就会变得非常困难。
-
-
Task Parallel Model(任务并行模型)
-
Task Parallel Model允许以分布式的方式执行任意无副作用的函数,任务之间可以任意地传输数据。
-
Task Parallel Model比BSP模型更强大,而且与单机顺序程序的表达方式更兼容。它可以通过checkpoint或是lineage来实现容错,但同样也不支持状态。
-
-
Communicating Processes Model(通信进程模型)
-
通信进程模型支持状态,它是task parallel model的通用化,因为每个task 并行程序都可以再一个通信进程上执行,方法是将函数调度到正确的进程上。
-
通信进程有几种实现方式,包括消息传递实现,例如MPI,或是actor system,例如Erlang/ Akka/ Orleans。这里我们可以重点关注actor system,因为它足够强大,同时编程模型更结构化。
-
-
Distributed Shared Memory Model(分布式共享内存模型)
-
分布式共享内存模型是一个理想的版本,它将整个集群暴露为一个单一的大核机器,可以使用多个执行线程进行编程,这些线程通过共享内存的读写进行通信。
-
实际上这种理想状态是无法实现的。通过网络访问远程内存的延迟通常比访问本地内存的延迟大得多。此外,这种架构不具有容错性。
-
二、Spark计算模型分析
Spark其应用程序在集群中以独立的进程组来运行,分为Driver和Executor两个角色。Driver即用户的主程序,Executor会为用户的应用程序处理计算和数据程序,driver程序会在其生命周期中监听并接收来自它的executor连接。
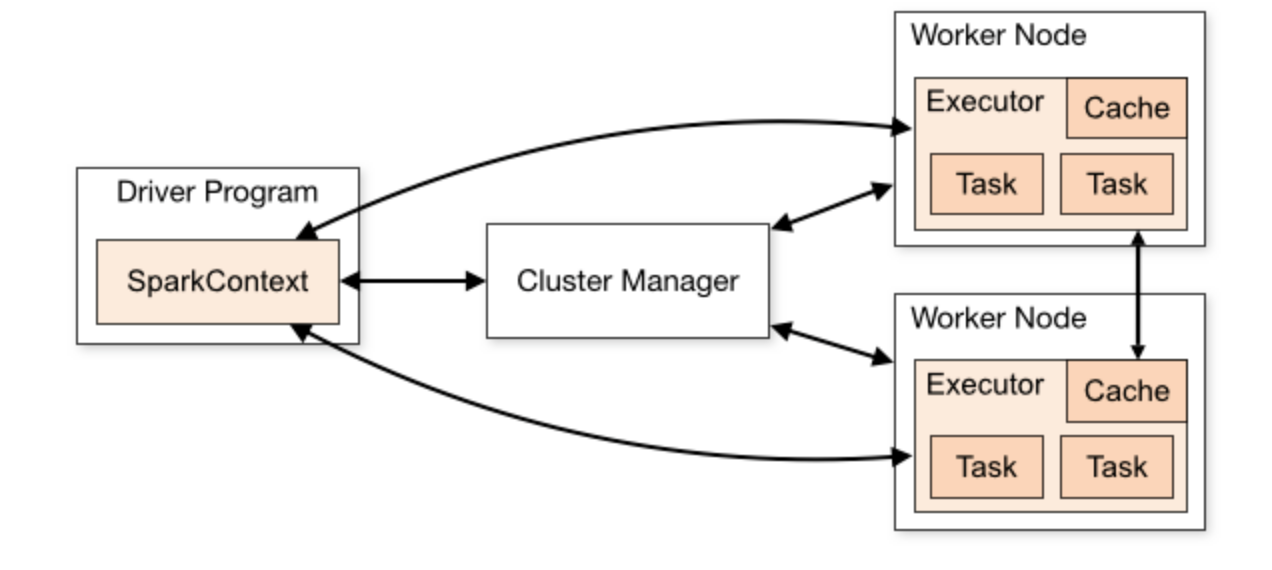
Spark作为典型的BSP模型,它在接收到用户的action算子会执行一个Job的调度,Job的整体调度过程分为以下几个步骤:
-
DAG图的构建:根据用户的算子/SQL输入进行解析,构建一个RDD DAG
-
Stage的划分和提交:DAGScheduler根据shuffle划分Stage,Stage的依赖关系也是一个DAG图
-
Task/TaskSet的创建:在每个Stage中,为每个分区创建一个Task,同一个Stage的Task组成一个TaskSet,交由TaskScheduler
-
Task的提交和执行:TaskScheduler根据调度算法将Task提交到远端执行
这里我们需要注意的是,前面所说的调度过程全部发生在Driver节点,远端的Executor作为执行器,只负责执行独立的Task,而对整个Job是完全无感知的。
当一个远端的Task执行完毕后,DAG调度是被如何继续触发的呢?
-
远端的Executor会将执行成功/失败的信息发送给Driver
-
Driver中的TaskScheduler负责处理Task级别的反馈信息,只有当一个Stage中的所有Task,即一个TaskSet全部成功,才代表着一个Stage成功。若任一Task失败,则会启动容错机制,进行Task重试或是Job失败的触发。
-
当一个Stage成功后,DAGScheduler会以事件的形式接收到信息,进而根据DAG依赖关系检查所有依赖于这一Stage的下游Stage,一个Stage只有在它所依赖的所有Stage都成功后才能启动执行。
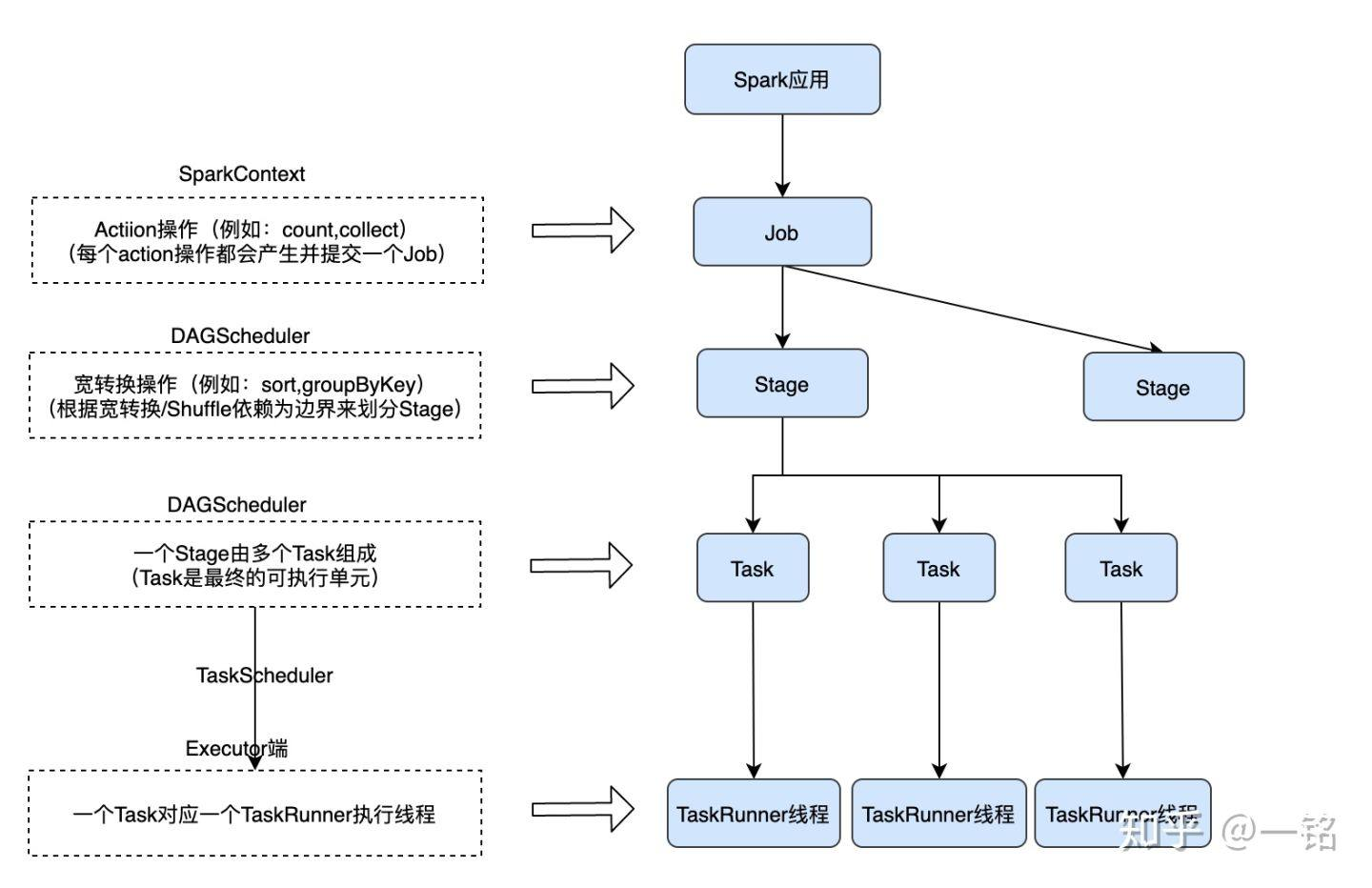
对比前面我们提到的BSP模型,我们可以发现Spark中的Stage即为BSP模型中所提到的"超步"抽象。Spark的调度模式具有以下特点:
-
同质化任务:Spark会假设每个Stage中的多个Task都是执行同样的计算任务,并且花费相同的时间,Task之间无需通信。(如果出现拖尾任务则认为是数据倾斜,需要开发人员解决)
-
批量调度:执行的基本单元是Task,但调度的基本单元是Stage,只有当一个Stage中的全部Task成功后才能触发具有依赖关系的Stage执行,一个Stage被调起时会同时触发所有归属于它的Task开始执行。
-
中心化调度:调度是由driver单节点负责的,一个task执行完毕后的信息只能返回到driver节点的调度器。
-
静态任务图:当一个Job启动时,任务图已经固化,调度器会根据固化的DAG进行调度执行。注意,这里的任务图是从业务意图来看的,虽然Spark已支持自适应优化,但只是根据Stage的统计信息对执行计划进行调优,不改变任务的业务意图。
-
无状态:Task执行任务内容是无状态的,执行结束即退出。
三、Ray计算模型分析
3.1 需求分析
BSP系统在批量数据处理的场景下表现良好,使得我们具备了处理大规模数据的能力。同时许多BSP系统也针对批计算进行了深度的优化,以Spark为例,通过代码生成、优化器、向量化等优化技术使得批计算的性能不断提高。
但在机器学习场景下,计算任务和批计算相比对计算引擎的要求存在比较大的差异。ML应用对于系统的主要要求如下:
-
性能要求:新兴的ML应用有严格的延迟和吞吐量要求。
-
R1:低延迟。新兴的ML应用的实时性、反应性和互动性要求细粒度的任务执行,其端到端的延迟为毫秒级。
-
R2:高吞吐量。训练和部署期间推理所需的微观模拟量,需要支持每秒数百万任务的高吞吐量任务执行。
-
-
执行模型要求:尽管许多现有的并行执行系统在识别和优化常见的计算模式方面取得了很大的进展,但新兴的ML应用需要更大的灵活性。
-
R3:动态任务创建:蒙特卡洛树搜索等RL原语可以在执行过程中根据其他任务的结果或持续时间生成新的任务。
-
R4:异质性任务:深度学习原语和RL模拟产生的任务,其执行时间和资源要求大不相同。为任务和资源的异质性提供明确的系统支持对RL应用来说是至关重要的。
-
R5:任意数据流依赖:同样地,深度学习原语和RL模拟产生了任意的、通常是细粒度的任务依赖(不限于批量同步并行)。
-
-
实现要求
-
R6:透明错误容忍:容错性仍然是许多部署方案的一个关键要求,在支持容错性的同时支持高吞吐量和非确定性的任务,是一个挑战。
-
R7:可调式性和分析性:调试和性能分析是编写任何分布式应用的最耗时的方面。这对ML和RL应用来说尤其如此,因为它们通常是计算密集型和随机的。
-
我们假设有这样一个应用:一个物理机器人视图在一个陌生的现实世界环境中实现一个目标,各种传感器可以融合视频和激光雷达的输入,建立机器人环境的多个候选模型。然后使用由循环神经网络(RNN)策略告知的行动以及蒙特卡洛树搜索和其他在线规划算法实时控制机器人。使用物理模拟器和最新的环境模型,MCTS并行地尝试了数百万个行动序列,自适应地探索最有希望的行动。这样一个实际的应用对于系统的要求有:
-
低延迟(R1):因为机器人需要被实时控制
-
高吞吐量(R2):需要支持MCTS的在线模拟以及流式感官输入
-
异质性任务(R4):一些任务运行物理模型器,一些任务任务处理不同的数据流,一些任务使用基于RNN的策略计算行动
-
任意数据流依赖(R5):除了任务异质性之外,任务之间的依赖关系可能也是复杂的,难以表达为分批BSP阶段
-
动态任务创建(R3):仿真需要自适应地使用最新的环境进行模拟,同时MCTS可能会选择启动更更多的任务来探索特定的子树,这取决于当前的计算情况和计算速度,因此,数据流图必须是动态构建的,以便让算法适应实时约束和机会。
3.2 系统设计
针对这样新兴ML应用的需求,系统设计可以针对性地提供以下功能:
-
架构基准
-
两个关键组件:一个逻辑上的集中控制平面和一个混合调度器,前者提供无状态的分布式组件管理和血缘回放,后者以自下而上的方式分配资源,在节点级别和集群级别调度器之间分配本地工作。
-
-
API和执行模型层面:对应前面所述R3~R5,Ray提出了一个允许任意的函数被指定为可远程执行的任务的API,并在这些远程任务之间进行数据流依赖
-
异步任务创建:任务创建,立刻返回future,作为未来的返回结果,然后任务会被异步执行。
-
远程任务的创建和依赖建立:任意的函数都可以被指定为一个远程任务,通过参数来建立任务之间的依赖关系。对应需求中的R4、R5
-
分层调度:任意的task执行都可以在不阻塞的情况下创建新的task。task的吞吐量不依赖于任何一个worker的带宽限制,同时计算图是动态创建的。对应需求中的R2、R3
-
get原语:get方法可以阻塞地获取一个任务的执行future
-
wait原语:wait方法接收一组future,一个timeout和一些数值。它会出超时时完成的任务,或是达到数量要求的完成任务。
-
wait原语允许开发者指定延迟要求(R1)和超时,考虑到存在异质性的任务(R4),wait原语对于ML应用来说非常重要,避免了拖尾任务对整个应用执行的影响。这个原语增强了我们用执行时间属性动态修改计算图的能力。
-
-
-
系统架构:每个节点上会运行多个工作进程,每个节点有一个本地调度器,整个集群有一个或多个全局调度器,以及一个用于工作进程之间共享数据的内存对象存储。实现R1-R7的两个主要架构特征是一个混合调度器和一个集中地控制平面。
-
集中的控制状态:架构依赖于一个逻辑上集中的控制平面,Ray使用了一个数据库来提供1)系统控制状态的存储,2)发布-订阅功能,使各种系统组件能够相互通信。这样的设计主要是为了通过集中控制状态的容错来减少组件对于容错的考虑,我们可以通过重启组件/ 根据依赖图重新计算来进行容错。同时为了吞吐量考虑,这个数据库可以是分布式的。
-
混合调度:我们对于延迟性(R1)、吞吐量(R2)和动态图创建(R3)的需求自然地促使了我们采用混合调度,其中本地调度器会将task分配给worker或是委托责任给一个或多个全局调度器。这样的混合调度器设计的好处如下,很适合最近大型多核服务器的趋势。
-
避免通信开销来提高低延迟(R1)
-
减少全局调度器的负载来提高吞吐量(R2)
-
-
3.3 系统实现
Ray是一个通用的集群计算框架,开实现模拟、训练以及为RL应用提供服务。这些工作负载的要求从轻量级无状态的计算,如模拟,到长期运行有状态的计算,例如训练。为了满足这些要求,Ray提供了一个统一的接口,可以同时表达task-parallel和actor-based计算。Task能让Ray有效地、动态地平衡模拟的负载,处理大的输入和状态空间(如图像,视频)并容错。相比之下,Actor让Ray能够高效地支持状态计算,例如模型训练和将共享状态暴露给客户,例如参数服务器。Ray在一个具有高度可扩展性和容错性的但一个动态执行引擎上实现了Actor和Task抽象。
Ray的目的不是取代Clipper和TensorFlow Serving[125]这样的服务系统,因为这些系统解决了部署模型中更广泛的挑战,包括模型管理、测试和模型组成。同样,尽管Ray具有灵活性,但它不能替代通用的数据并行框架,如Spark,因为它目前缺乏这些框架所提供的丰富的功能和API(例如,straggler mitigation,查询优化)。
Ray实现了一个动态任务图计算模型,也就是说,它讲一个应用程序建模为一个在置信过程中不断变化的依赖任务图。在这个模型基础上,Ray提供了一个Actor和Task-parallel的变成抽象。Ray的系统实现要点如下:
-
编程模型
-
Task:一个Task代表着一个在无状态worker节点上的远程函数的执行过程,task创建返回future,可以被get方法获取最终结果。远程函数被认为是无状态和无副作用的,它们的输出只由它们的输入决定,这对于容错是一个简化,只要重新执行即可。
-
Actor:一个Actor代表了一个有状态的计算。每个Actor都暴露了可以被远程调用的方法,并顺序执行。一个方法的执行类似于一个task,因为它是远程执行并返回一个future,不同之处在于它在一个有状态的worker节点上执行。Actor的句柄可以远程传递给其他的Actor或是Task。
-
API增强:为了满足异质性和灵活性的需要,Ray以3种方式增强了API
-
ray.wait():wait原语可以等待前k个可用结果,而不是像get一样等待所有结果
-
指定资源:为了满足资源异构任务,支持由开发者指定资源要求,以便Ray调度器能够有效地管理资源
-
嵌套远程函数:为了提高灵活性,远程函数可以调用其他远程函数。(嵌套函数在编写时需要注意先后顺序)
-
-
-
计算模型:Ray采用了一种动态任务图计算模型,远程函数和actor的计算触发由依赖管理。
-
架构:Ray的架构包括 (1)实现API的应用层;(2)提供高可扩展性和容错性的系统层。
-
架构图
-
应用层:应用层由3种不同类型的进程组成
-
Driver:执行用户程序的进程
-
Worker:无状态的进程,执行由driver或者其他worker触发的task(remote functions)。Worker被系统层自动启动和分派task。当一个remote function被声明时,这个function会被自动发布到所有的worker上。Worker节点会顺序地执行task,不会有跨task的本地状态。
-
Actor:一个有状态的进程,只执行它暴露出去的方法。和worker不一样,一个worker是被其他worker或是driver显示初始化的,它也和worker一样顺序执行方法。
-
-
系统层:系统层由3个主要组件组成:Global Control Store(GCS)、一个分布式调度器,和一个分布式的对象存储。所有组件都是可以水平扩展和错误容忍的。
-
Global Control Store(GCS):保存系统中的所有控制状态。它本质上是一个具有pub-sub功能的kv store。GCS极大地简化了Ray的整体设计,它允许系统中的每一个组件都是无状态的。不仅简化了错误容忍机制,也使得分布式对象存储和调度器更简单,因为所有组件都通过GCS共享状态。另一个好处是容易开发调试、分析和可视化工具。
-
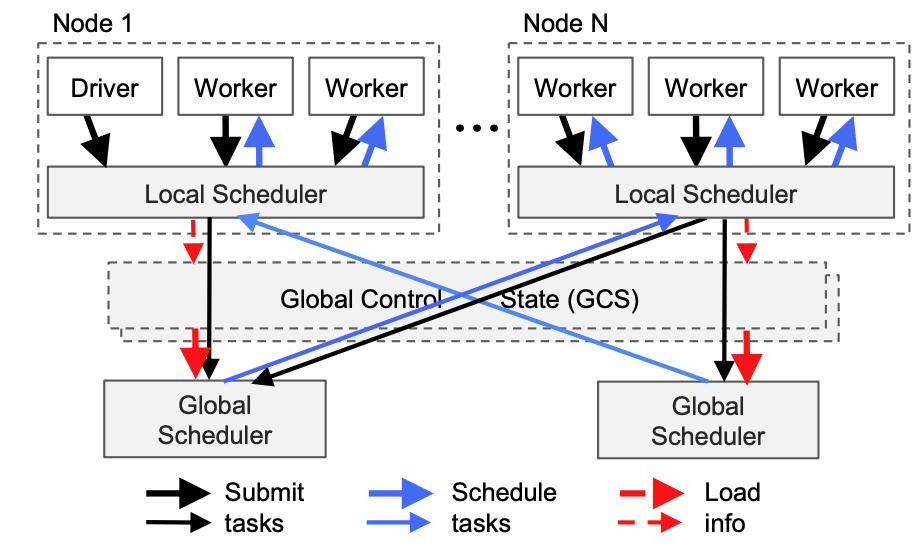
自底向上的分布式调度器:从需求场景看,Ray需要每秒动态调度数百万个任务,这些任务可能执行时只需要几毫秒的时间。大多数的集群计算框架,如Spark,实现了集中式调度器,可以提供本地性调度,但是延迟在几十毫秒,无法满足需求。为了满足需求,Ray设计了一个双层调度器,由一个全局调度器和分布在每一个节点上的本地调度器组成。为了避免对全局调度器造成过载,一个节点创建的任务会首先提交到这个节点上的本地调度器,只有当当前节点过载,或是无法满足任务的要求(例如资源要求),这个任务才会被本地调度器委托给全局调度器。因此我们称之为自底向上的调度器。
-
双层调度架构
-
-
内存分布式对象存储:为了最小化任务延迟,Ray实现了一个内存分布式存储系统来存储每一个task或是无状态计算的输入和输出。它在每个节点上通过共享内存来实现,支持同一节点上的任务间的零拷贝数据共享,使用了Apache Arrow作为数据格式。
-
-

四、总结
前面的章节首先对分布式计算领域进行了概述,同时对Spark和Ray的调度设计进行了简要的介绍。我们可以发现,Spark和Ray之所以会采用不同的调度设计,主要原因还在于它们的目标场景的需求差异。
Spark当前的核心场景还在于批量的数据计算,在这样的需求场景下我们可以假设数据依赖图是较为简单的,不存在单个分区的任务依赖图、对于同一个分布式数据的不同分区,执行的任务都是同质化的,因此它采用了集中式调度、DAG依赖分析、批量调度等设计方案。同样,这也在造成了Spark在一些依赖关系较为复杂、异构任务的应用中表现不太好。
而Ray本身的设计目标就是为了支持新型的ML应用,需要满足ML应用的灵活性和动态性的需求,因此它针对性的选择了task-parallel、混合调度等技术方案。虽然Ray本身作为一个分布式计算框架,也能通过上层核心模块Ray-Dataset支持批量数据计算,但它对比Spark也缺少了在批量数据计算场景下的丰富功能和API,如Stage级别的代码生成、查询优化等等。但Ray本身的目标也并不是替代Spark。
我们对系统设计,特别是调度框架设计的对应技术和适应场景进行了如下的整理,在进行系统设计时需要考虑到需求场景对于系统架构的需求,并对应选择合适的设计与实现。