文章目录
- 前言
- 数据仓库
- 数仓基础
- 好处和优势
- 限制和挑战
- 数据湖
- 数据湖基础
- 好处和优势
- 限制和挑战
- 现代数据平台
- 云数据湖与云数仓组合架构
- 现代数据平台的期望
- Lakehouse 架构的出现
- 未来数据平台的默认选择?
- 总结
前言
本文概述了传统数据架构:数据仓库和数据湖,以及现代数据平台的期望,和新兴数据架构 Lakehouse 的详细介绍说明,架构没有好坏只有合适与否,但是个人认为湖仓一体架构 Lakehouse 将在未来数据平台的架构设计中占有强大的竞争力。
数据仓库
数仓基础
文件格式和数据库是保存数据最广泛的形式,在公司内,各个部门的应用程序都带有后端事务数据库,这些孤立的数据库限制了跨部门分析。这就是公司开始构建数据仓库(一种基于数据库技术的架构)的原因,以达到数据集中存储分析的目的。
使用传统数据仓库搭建数据平台,需要三步:
- 从不同的源系统中抽取数据
- 通过数据建模来验证、清理和转换数据
- 加载到数据仓库中
这就是 ETL 过程,有助于在数据仓库的目标表中抽取、转换和加载数据。
Bill Inmon,通常被称为数据仓库之父,他将数据仓库定义为面向主题的、集成的、随时间变化的、非易失性的数据集合,可以帮助做出管理决策。现在让我们看看使用数据仓库架构构建的数据平台的基本特征。
结构化数据
数据仓库保存并处理结构化数据,从多个源系统中抽取结构化数据并将其加载到仓库中以进行决策和生成报表。
面向主题、数据集成且清理过的数据
数据仓库集成了来自各种源系统的数据,从源系统抽取的数据在加载到特定主题(例如产品或客户)表之前会经过多次验证。数据根据源系统提供的数据规范进行验证,任何异常数据都会被拒绝并发送回源系统进行更正。
随时间变化、非易失的历史数据
数据仓库是专门为存储大量数据而构建的,当数据随时间变化时,数据仓库会保留所有这些变化及其时间戳。它保留数据的先前版本,而不删除旧值。
当公司实施数据仓库时,这些特征可以帮助公司获得多种好处。
好处和优势
业务决策
数据仓库的主要用例是帮助公司通过利用各个业务/部门的数据来实现报表生成和业务决策的系统。数据仓库有助于实施决策支持系统,它使公司能够跨业务维度全面查看数据,以采取数据驱动的分析和策略。
优秀的 BI 能力
数据仓库为 BI 工作内容(例如创建报表、仪表盘、分析结果或临时数据分析)提供优秀的性能。为了增强性能,它支持表分区、索引、物化视图、临时表等,出色的性能使得数据仓库在现代数据平台上实现 BI 用例时很受欢迎。
支持 ACID、更新和删除
数据仓库支持更新或删除仓库内存储的记录,它还保证对其事务提供强大的 ACID 支持,可以像使用 MySQL 一样简单的进行 SQL 操作。
Lakehouse(湖仓一体)架构也支持ACID 特性,但是数据湖不支持。
建模和组织数据
数据仓库架构支持数据建模,便于以更好的方式组织数据。我们可以使用维度建模等技术将数据组织到数据集市中,以创建事实和维度。此类建模方法有助于降低存储成本并提高查询性能。
什么是数据集市?
数据集市是企业数据的子集,可以为组织内的特定部门创建数据集市。该部门的用户只能访问其数据集市中存在的数据,例如,营销部门将可以访问其数据集市来分析营销数据,这些用户无法访问其他组织数据以进行跨部门分析。
更好的访问控制
与数据库一样,数据仓库也将数据以行和列的形式存储在表中。可以在表或列级别实施细粒度的访问控制,以限制其用户的访问权限。还可以创建视图以根据特定过滤条件限制用户访问数据。
统一数据查询源
最后,数据仓库可帮助公司为数据创建统一查询源,消费者可以在中央仓库中查询所需的表,而无需在任何其他源系统所在的数据库中搜索数据。
限制和挑战
虽然数据仓库比特定于部门的孤立数据库具有显着的优势,但它们也有一些基本的局限性。随着大数据、社交媒体、物联网设备以及流式处理需求的兴起,这些局限性会进一步拉大。
存储和计算紧密耦合
传统的数据仓库架构,存储和计算捆绑在一起,紧密耦合,无法单独扩展存储或计算。
被供应商捆绑
数据仓库使用专有的格式来存储数据,存储在仓库中的数据只能使用本机对应的计算引擎来处理,如果使用的是供应商的云服务,我们就得同时购买供应商的存储服务和计算服务,而无法单独购买存储服务,使用外部计算引擎来处理出具。
不支持非结构化数据和 AI/ML 工作负载
传统的数据仓库只支持结构化数据,没有直接的方法来存储非结构化数据,例如社交媒体评论、音频、视频或图像文件中的文本。 AI/ML 机器学习则主要需要非结构化数据来进行训练。
不支持流式处理
数据仓库每天定时ETL 加载数据,它们不支持高吞吐量和低延迟的近/实时的流式数据处理。
成本较高
最后,与传统仓库相关的最关键因素之一是运行和维护成本高。没有好的办法说什么时候可以停止 ETL,来释放未使用的磁盘,然后更换成价格便宜的存储,或者制定数据的生命周期。同时,高性能的硬件要求也显着增加了成本。
数据湖
数据湖基础
社区逐渐意识到非结构化数据的价值以及传统数据仓库处理这些数据的局限性,社交媒体、机器日志、物联网设备和网站点击流等数据源快速生成大量非结构化数据。
随着 Hadoop 技术的兴起,社区看到了构建可以克服数据仓库这些限制的数据平台的机会。 Hadoop 引入了一种称为 Hadoop 分布式文件系统 (HDFS) 的技术,可以存储结构化、半结构化或非结构化数据。从那时起,数仓开始构建基于 HDFS 技术的数据湖。
数据湖是可以持久保存结构化、半结构化和非结构化数据的中央数据存储。它存储来自 CSV、JSON、XML、数据库、图像、音频、视频等的数据。就像数据仓库使用数据库技术一样,本地数据湖使用 HDFS 来存储大量数据。
下图是基于数据湖架构的数据平台,显示了数据湖如何帮助实现中央存储以保存来自多个源系统的原始数据,这些数据进一步用于数据分析(生成报表)和 ML/DS 机器学习场景。
标准的数据湖具有以下特征。
支持所有数据格式
在数据湖中,可以存储非结构化数据,例如文本、图像、音频和视频文件。与数据仓库相比,对非结构化数据的支持是最重要的功能,导致数据湖的大力发展。
读时 schema 限制
源数据在写入数据湖时,没有 schema 限制,可以按数据原样格式存储,这样可以保证源数据的完整不会丢失数据。只需要在读取数据时定义 schema 即可获取想要的数据,被称为“读时schema”。
存储不可变
HDFS 是一种不可变的存储,我们无法更改存储在使用 HDFS 构建的数据湖中的数据,只能在数据湖中追加存储新对象。使用云技术构建的现代数据湖表现出与 HDFS 类似的特征,并将数据存储为不可变对象。
好处和优势
支持 AI/ML 和 DS 场景
由于其能够保存非结构化数据,数据湖是执行 ML 和 DS 工作负载的理想平台。 ML 工作内容可以直接访问来自各种系统的原始数据,这些数据以开放文件格式(例如数据湖中的 Parquet、CSV 和 JSON)存储。
通过 Hadoop 生成报表
HDFS 是数据湖的一种格式,可以原生和 Hadoop 结合,然后通过 Hadoop 的计算引擎,通过 SQL 查询生成报表。
支持实时工作方式
数据湖可以支持实时工作方式和批量工作方式,实时数据从源系统中获取,并在数据湖中提供以供进一步分析。虽然数据湖不是最适合实时计算的存储方式,但是它可以近实时,减少延迟。
成本更便宜
由于数据湖使用便宜的硬件和 Hadoop 框架内的 HDFS 等开源技术,因此运行这些系统的成本远低于使用高性能的硬件和专有软件的传统数据仓库。
限制和挑战
使用数据湖架构构建的数据平台虽然可以支持 BI 报表查询,然而,它们的性能无法与数据仓库系统相提并论。
不支持 ACID、更新和删除
由于 HDFS 是不可变存储,因此在 Hive 中运行工作任务的用户无法进行直接更新。任何更新或删除都必须以编程方式完成。缺少事务支持是数据湖需要 Apache Iceberg、Apache Hudi 和 Delta Lake 等新技术的另一个重要原因,这些技术使开发人员能够在数据湖上轻松执行更新/删除。
数据质量下降
数据湖以原始形式存储数据,它不像数据仓库那样有严格的质量控制。存储数据时,数据不经过schema 、技术或业务验证。这些缺失的验证通常会导致数据不准确和不完整。
有限的访问控制
湖中数据访问权限的控制范围有限,与数据仓库不同,数据湖中的数据没有细粒度的控制,访问权限只能在对象或文件级别设置和管理。
存在成为数据沼泽的风险
数据湖很快就会变成数据沼泽,数据会被转储并保留多年,但不会得到利用。质量下降、访问控制有限以及元数据的缺乏——所有这些因素都会降低数据的可发现性,并使用户利用数据产生价值更加困难。
现代数据平台
传统的数据仓库和数据湖都有自己的优势和局限性,总的来说传统数据的优势就是数据湖所缺少的,而数据湖的优势也是传统数仓所缺少的。
幸运的是,随着大数据技术的快速发展,目前已经出现了最新的湖仓一体架构(Lakehouse), 完美结合了数据仓库和数据湖的优势。
云数据湖与云数仓组合架构

上图是使用云数据湖(例如S3, OSS)和云数据仓库(例如Amazon Redshift 和 Google BigQuery) 构建的湖仓一体架构的数据平台。
上云有许多好处:
- 存储便宜,快速扩容
- 支持结构化和非结构化的数据存储,将原始数据保存在湖中,将转换清理过的数据保存在数仓中
- 平台可以支持多种工作方式,比如报表生成,机器学习模型训练,实时流计算等。
- 可以构建一个对公司所有角色都有用的数据平台,包括数据分析师,工程师,算法工程师等。
上边这种拼接式的湖仓一体方案也存在着很多局限性:
-
数据重复
组合架构在两个存储层中保存大量数据,虽然数据湖存储从源系统抽取的所有数据,但大量数据集被复制到数据仓库以进行 BI 分析。随着数据的增长,仓库中重复的数据量不断增加。由于有两个存储层,因此需要不断地将数据从数据湖复制到数据仓库。这种连续的数据复制增加了在两层之间同步数据所需的工作量。同样,对于某些需要处理或聚合数据的 ML 场景,通常需要将数据从数据仓库复制回数据湖。
-
数据类型不匹配
数据湖和数据仓库的数据类型不同,在这些系统之间同步元数据并不容易。数据湖技术使用的数据类型可能与数据仓库中可用的数据类型有很大不同。在两个存储层之间移动数据时,需要付出额外的工作来转换数据类型。
-
访问控制
管理两个系统之间的访问控制策略具有挑战性,因为仓库可以在列和行级别进行细粒度的控制。数据湖管理文件或对象级别的访问。在两个系统之间拥有类似的访问控制通常需要定制实施。
-
用户体验
用户在查询之前需要知道数据驻留在哪里,因为没有统一的层来访问两层数据。此外,将湖中的原始数据和仓库中的聚合数据连接起来进行交互式分析并不容易。
现代数据平台的期望
组合方法的缺点导致了 Lakehouse 架构的发展,它将数据仓库和数据湖融合在一起,形成一个统一的现代平台,下图是现代数据平台所期望的功能: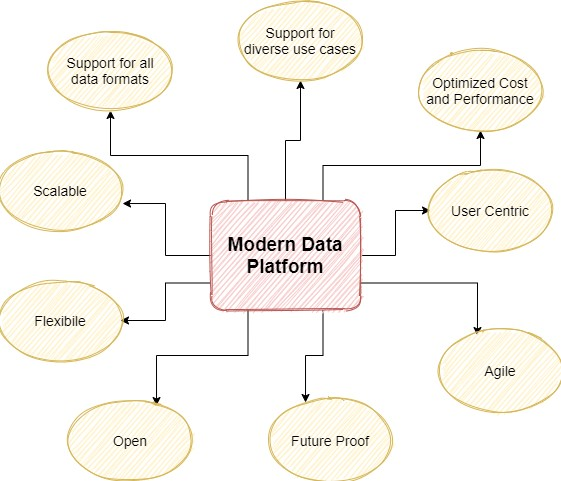
支持所有数据格式和不同的使用场景
可穿戴设备、智能手机和支持物联网的机器等多种新时代系统,会生成非结构化数据,包括图像、音频、视频和日志,现代数据平台不仅要支持内部系统的结构化数据同时也要支持外部系统的非结构化数据存储,以利用它来实现不同的工作场景。其中包括报表生成、数据分析、流处理、自助查询分析、机器学习和人工智能等场景。
可扩展、灵活、开放
随着技术的快速发展,现代数据平台应该结合云技术,使其具有可扩展性和灵活性,并且应该能够快速调整以适应不断增长的数据和业务需求。现代平台应该使用开源技术与其他系统轻松交互,并可以自由地与不同供应商或云服务提供商的产品集成。
成本优化与性能平衡
现代数据平台在优化成本的同时,应该考虑性能的损失,在成本优化和性能直接取得平衡。
以用户为中心
随着数据架构的发展,数据平台使用的架构结合了许多方法来支持各种分析场景,导致系统设计越来越复杂。现代数据平台应该以用户为中心,具有简单和开放的架构,便于使用平台的各个角色都能轻松的工作。
敏捷且面向未来
敏捷性是现代数据平台最受追捧的期望之一,无论是加快上市时间的业务需求还是更快的流分析的技术要求 - 敏捷性推动着设计和架构决策。现代数据平台应该是敏捷的,并使公司能够缩短其产品的“上市时间”。同时,它们还应该灵活地适应未来的使用场景、用户需求和技术进步。
Lakehouse 架构的出现
随着 open file format 和 open table format 技术的发展,新一代大数据湖仓一体架构(Lakehouse)闪亮登场,它完美融合了数据湖与数据仓库,架构简单分为存储层和计算层:
关于 Lakehouse 的详细说明可以看我这篇文章:
新型大数据架构之湖仓一体(Lakehouse)架构特性说明——Lakehouse 架构(一)
未来数据平台的默认选择?
有四种类型的公司可能会考虑采用新的数据平台或更改现有的数据平台:
- 没有企业级数据平台并希望实施中央数据存储库的公司。
- 在本地基础设施上拥有数据平台的公司希望迁移到云。
- 使用独立云数据仓库或独立云数据湖并希望实施组合方法来支持不同使用场景的公司。
- 现在正在寻找一种简单、统一的组合方法来构建数据平台的公司,没有历史包袱。
总结
本文概述了传统数据架构:数据仓库和数据湖,以及现代数据平台的期望,和超新星数据架构 Lakehouse 的简单优点介绍,上云是大势所趋,笔者认为在未来大数据架构会越来越简单,可以让各行各业都能感受到数据带来的价值,以及大数据带来的魅力。