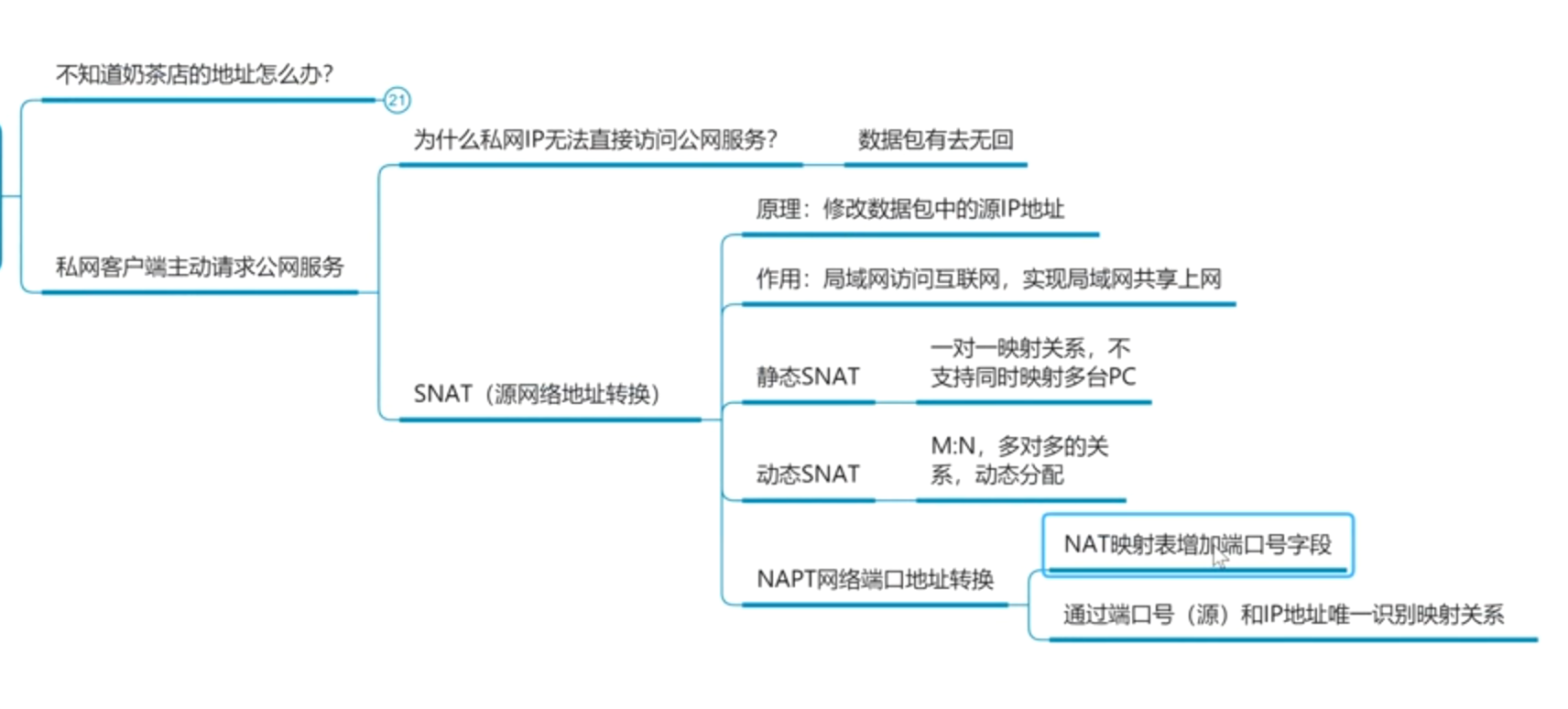
1、数据同步
数据同步我们之前在数仓当中使用了多种工具,比如使用 Flume 将日志文件从服务器采集到 Kafka,再通过 Flume 将 Kafka 中的数据采集到 HDFS。使用 MaxWell 实时监听 MySQL 的 binlog 日志,并将采集到的变更日志(json 格式)保存到 Kafka,同样再由一个 Flume 同步到 HDFS。使用 DataX 每天 0 点将需要全量同步的数据全量采集到 HDFS。
数据同步主要的作用就是实现不同数据源的数据流转,对于大数据系统来说,包含把数据从业务系统同步进入数据仓库和把数据从数据仓库当中同步进入数据服务和数据应用两个方面。
1.1、三种同步方式
1.1.1、直连同步
直连同步是指通过定义好的规范接口 API 和基于动态链接库的方式直接连接业务数据库,比如 ODBC/JDBC 等规定了统一规范的标准接口,不同数据库厂商基于这套接口实现了自己的驱动,支持完全相同的函数调用和 SQL 实现。
直连同步就是通过 JDBC/ODBC 连接数据库来往数仓进行写入,但是这种方式对数据库系统的性能影响比较大,尤其是执行大批量的数据同步可能会严重拖垮业务系统的性能。如果业务系统采用主备策略,则可以从备库抽取数据,避免对业务系统产生性能影响。但是终究这不是一种好办法。
1.1.2、数据文件同步
通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件(比如把数据库的二进制文件转为文本文件),由专门的文件服务器传输到目标系统,对于常见的关系型数据库,这种方式比较简单实用。
另外,对于互联网日志数据,通常是以文本文件形式保存的,所以也适合这种方式。
1.1.3、数据库日志解析同步
现在大多数主流的数据库都已经实现了使用日志文件进行系统恢复,比如 MySQL 的 binlog,通过数据库日志可以实现增量同步的需求,不仅延迟可以控制在毫秒级别,而且对数据库性能影响也比较小,目前这种方式也是广泛应用于从业务系统到数仓的增量同步应用中的。
通过数据库日志解析同步的效率虽然高,但是依然存在一些问题:
- 数据延迟。当业务系统做批量补录时可能会使数据更新量超出系统处理的峰值,导致数据延迟。
- 投入较大。需要在业务数据库和数仓之间部署一个专门用来实时同步的系统(比如 MaxWell,Cannal,这倒是也不算太大问题)。
- 数据漂移和遗漏。数据漂移一般是对于增量表而言的。具体解决方案下面会专门介绍。
1.2、阿里数据仓库的同步方式
关于阿里云数据仓库的同步方式这里简单介绍,对于批量数据同步,阿里云使用的就是人家自研的 DataX;而关于实时数据同步,我们之前使用的是 MaxWell,而阿里云使用的是自家的 TT(TimeTunnel),具有高性能、实时性、高可用、可扩展等特点,被阿里巴巴广泛应用于日志收集、数据监控、广告反馈、量子统计、数据库同步等领域。TT 是一种基于生产者、消费者和 Topic 的消息中间件(基于 HBase),不管是日志服务器中的日志还是业务系统中的数据都可以通过 TT 来进行同步到 MaxCompute。
1.3、数据同步中的问题与决绝方案
这里主要介绍数据漂移
1.3.1、数据漂移问题
数据漂移一般是对增量表而言的,它指的是数据在同步到数仓(ODS 层)过程中,由于网络延迟或者系统压力的原因,导致上一个分区的数据进入了下一个分区(今天的数据到了明天)。
由于 ODS 层有着面向历史的细节数据查询需求,这就要求数据采集到 ODS 层后必须按照时间进行分区存储(离线数仓基本都是按天进行分区)
说明:
尽管离线数仓一般是以天为单位来进行数据分析,但并不是说我们就等到每天 0 点才开始同步前一整天的数据。
事实上,数据同步策略分为全量/增量同步,对于订单表这种本身就非常大,而且变化也特别大的表一般都是采用实时同步策略(增量)。阿里巴巴采用 TT(TimeTunnel)来实现对业务数据库的实时数据同步(原理就是监听 binlog),但是一般并不是一条数据同步一次,而是累积一定时间间隔进行同步(比如每 15 分钟)
这里使用订单表来说明数据漂移是怎么发生的,对于我们的业务数据表,它并不会像我们在数仓建表那样为每个业务过程建立一张表,而是通过 update 操作来实现业务过程的变化,比如当 order_status 为已下单时,proc_time 就代表下单时间;当 order_status 为待支付时,modified_time 就代表状态变化为待支付的时间。
| id | order_id | proc_time | order_status | modified_time |
|---|---|---|---|---|
| 1 | 1001 | 下单时间 | 已下单/支付中/支付成功 | 状态修改时间 |
通常,用于分区的时间戳字段分为四种:
- 业务表中用于标识数据记录更新的时间戳字段(modified_time,比如订单表中当订单状态变化为待支付、支付成功的识货,modified_time 就会发生变化)
- 数据库日志(binlog)当中用于标识数据记录更新的时间戳字段(log_time)
- 业务表中用于记录业务过程发生时间的时间戳字段(proc_time,比如下单时间、支付时间)
- 数据被抽取到的时间戳字段(extract_time, Flume 中的数据在写入到 Kafka 之后,如果没有 Event Header ,那么数据的时间默认就是写入到 Kafka 的时间)
理论上,这几个时间应该是一致的,但是在现实中,四个时间戳的大小关系为:proc_time<log_time<modified_time<extract_time,造成这些差异的原因有:
- 数据抽取是需要时间的而且得在数据产生之后,所以 extract_time 往往比另外三个时间都晚。
- 关系型数据库采用预写日志方式来更新数据,所以更新时间modified_time会晚于log_time
- 业务不能保证 modified_time 一定被更新。
- 由于网络或系统压力问题,会导致数据延迟写入/数据延迟更新。log_time或者modified_time会晚于proc_time
通常的做法是选择其中一个字段来进行分区,这就导致了数据漂移。下面是数据漂移常见的几种场景:
- 根据 extract_time 进行分区。这种情况下最容易出现数据漂移。(比如 Flume 经过一定延迟把数据写入到 Kafka 之后,如果没有 Event Header,那么当 Kafka 的数据被转为 Flume 格式时,Header 中默认的 timestamp 就是写入到 Kafka 的时间 )
- 根据 modified_time 进行分区。但是业务不能保证 modified_time 一定被更新。
- 根据 log_time 进行分区。由于网络或者系统压力,可能会出现延迟。
- 根据 proc_time 进行分区。如果根据 proc_time 进行分区,我们得到的数据就遗漏了业务过程的变化(比如对于待支付、支付成功这些业务过程都是需要通过 modified_time 和 order_status 来确定的)。
数据漂移问题的解决方案(面试题)
1、多获取后一天的数据
在每个 ODS 表时间分区中多冗余一部分数据,保证数据只多不少,毕竟即使网络延迟再高,很小概率会超过 15 分钟,所以我们可以向后冗余 15 分钟的数据。但是这种方式会有一些误差,比如我 1 号 0 点之前下单,2 号 1 点取消订单,那么对于 1 号,我的数据状态应该是已下单状态,但是由于我把 2 号的部分数据页拉到我的分区了,所以就可能导致记录的状态为订单已关闭。所以对于记录状态更新频繁的场景,我们可以创建拉链表,用时间(起始时间和结束时间)来约束获取记录的状态。
2、多个时间戳字段限制
① 根据 modified_time 获取后一天 15 分钟的数据,并限制多个和业务过程的时间戳(下单、支付、成功)都是当天,然后根据这些数据按照 modified_time 升序排序,获取每个数据(每个订单,可以用 order_id 唯一区分)首次数据变更的那条记录。
② 根据 log_time 分别冗余前一天最后15分钟的数据和后一天凌晨开始15分钟的数据,并用 modified_time 过滤非当天数据,并针对每个订单按照 log_time 进行降序排序,取每个订单当天最后一次数据变更的那条记录。
③ 将两部分数据根据 order_id 做full join 全外连接,将漂移数据回补到当天数据中。
总之,数据漂移是不可能杜绝的,毕竟大数据场景下网络延迟和系统压力不可避免,所以只能通过一些规则限制获得相对准确的数据。