文章目录
- 数据类型
- 注意事项
- 表引擎
- 1.TinyLog 引擎
- 2.MergeTree 引擎
- 3.ReplacingMergeTree 引擎
- 4.AggregatingMergeTree 引擎
- 5.SummingMergeTree 引擎
- 6.CollapsingMergeTree 引擎
- 7.Distributed 引擎
- TTL
- 列级 TTL
- 表级TTL
数据类型
| ClickHouse 数据类型 | Java 数据类型 | 数据范围 |
|---|---|---|
| UInt8 | Short | 0 到 255 |
| UInt16 | Integer | 0 到 65,535 |
| UInt32 | Long | 0 到 4,294,967,295 |
| UInt64 | BigInteger | 0 到 18,446,744,073,709,551,615 |
| Int8 | Byte | -128 到 127 |
| Int16 | Short | -32,768 到 32,767 |
| Int32 | Integer | -2,147,483,648 到 2,147,483,647 |
| Int64 | Long | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| Float32 | Float | 约 ±3.4x10^-38 到 ±3.4x10^38 |
| Float64 | Double | 约 ±1.7x10^-308 到 ±1.7x10^308 |
| Decimal(p,s) | BigDecimal | 取决于精度和标度 |
| String | String | 任意长度的字符串 |
| FixedString(n) | String | 固定长度的字符串,长度为 n |
| Date | LocalDate | 0000-01-01 到 9999-12-31 |
| DateTime | LocalDateTime | 0000-01-01 00:00:00 到 9999-12-31 23:59:59 |
| DateTime64 | Instant | 0000-01-01 00:00:00 到 9999-12-31 23:59:59.999999999 |
| Array(T) | Array | 任意长度的 T 类型数组 |
| Nullable(T) | Object (T 或 null) | T 类型或 null |
| Tuple(T1, T2, …) | Object[] | 多个类型的元组 |
| Enum8 | Enum | 8 位枚举值 |
| Enum16 | Enum | 16 位枚举值 |
| UUID | UUID | UUID 格式的字符串 |
| IPv4 | InetAddress | IPv4 地址 |
| IPv6 | InetAddress | IPv6 地址 |
注意事项
1.确定数据类型
我们在建表存储数据时,图省事,可能会全部选择 String 类型,但可能在使用时,需要目标列的数值型或者时间类型等,去操作数据时显然会进行数据转换,降低了执行效率,所以在建表时就要确定好对应字段的数据类型,不要后期操作数据时再进行数据类型转换。
2.不要使用 Nullable 空值类型
在 ClickHouse 中,存储 Nullable 列时,需要创建一个额外的文件来单独保存,且无法进行索引,使用起来效率很低。
因此,在有需要使用空值类型的场景时,可以选择使用一个特殊值来进行替换。
3.分区的合理设置
分区建表时,一般按照年月日进行划分,数据量越大,建议分区的粒度也要变大,尽量不要使用过小的粒度来存储数据。
4.索引的合理设置
在 ClickHouse 建表时,必须指定使用的索引列,也就是 order by,通常进入索引列的字段都是充当后期查询时作为 where 筛选条件的列,查询频率的索引列在前。
5.避免使用轻量删除与修改
虽然 ClickHouse 支持删除、修改操作,但小批量的操作会造成 ClickHouse 产生小分区文件,在执行 Merge 合并任务时,压力很大。例如:从数十万条数据中仅仅删除或修改几条数据。
表引擎
ClickHouse 表引擎是一种用于存储和管理数据的方式,它定义了数据在物理存储和查询处理方面的行为。
表引擎决定了数据的存储格式、索引方式、数据分布方式以及查询优化方式等方面。不同的引擎具有不同的特性和适用场景,可以根据数据的特点和应用需求选择合适的引擎来存储和处理数据。
1.TinyLog 引擎
TinyLog 是 ClickHouse 中的一种存储引擎,它专门用于小规模数据的存储和查询。
它将数据以文本文件的形式存储在磁盘上,每个文件对应一个分区,适用于数据量较小的场景,例如开发、测试或小型项目。
创建表
CREATE TABLE tinylog_example
(id UInt32,name String,age UInt8
)
ENGINE = TinyLog;
创建了一个名为 tinylog_example 的表,包含了三个列:id(ID)、name(姓名)和 age(年龄)。指定了引擎为 TinyLog,表明数据将以 TinyLog 引擎的方式存储。
插入数据
INSERT INTO tinylog_example (id, name, age)
VALUES(1, 'Alice', 30),(2, 'Bob', 25),(3, 'Charlie', 35);
查询数据
SELECT * FROM tinylog_example;
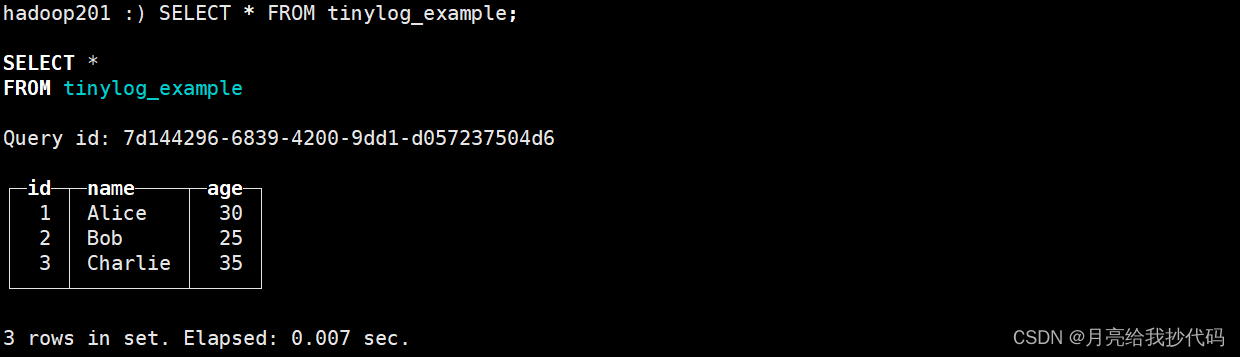
我们也可以进入到本地的磁盘文件中去查看该数据。
进入 ClickHouse 本地数据存储目录(需要切换到 root 用户):
cd /var/lib/clickhouse/data

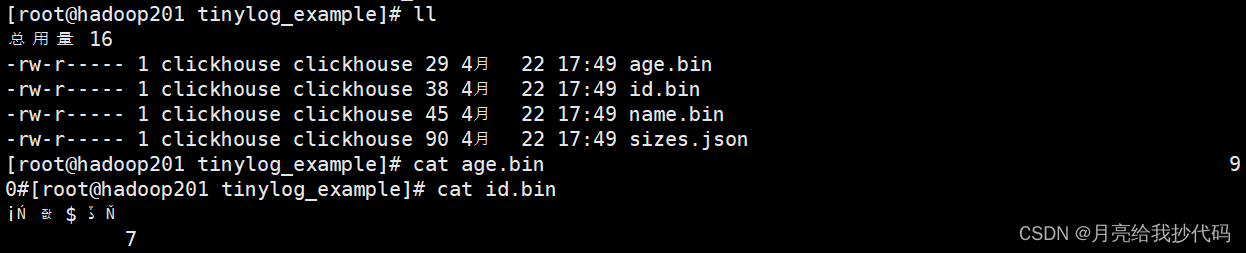
data 目录下的文件夹对应的就是我们创建的库,我上面创建的 tinylog_example 表存储在 test 库下,所以我这里进入到 test 目录中进行查看。
由于 ClickHouse 默认会进行压缩,所以我并不能直接看到:
2.MergeTree 引擎
用于存储有序的时间序列数据,支持灵活的数据分区和排序,适用于日志数据、传感器数据等场景。
假设我们要存储网站的访问日志数据,我们可以使用 MergeTree 引擎来存储这些数据,并且按照日期进行分区。
创建表
CREATE TABLE log_data
(date Date,time DateTime,user_id UInt32,page_visited String,duration Float32
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(date)
ORDER BY (date, time, user_id);
创建一个名为 log_data 的表,用于存储网站访问日志数据。数据按照日期进行分区,并且按照日期、时间和用户 ID 进行排序。
插入数据
INSERT INTO log_data (date, time, user_id, page_visited, duration)
VALUES('2024-04-01', '2024-04-01 10:15:00', 123, '/home', 3.5),('2024-04-01', '2024-04-01 10:20:00', 456, '/products', 5.2),('2024-04-02', '2024-04-02 08:30:00', 789, '/about', 2.1);
查询数据
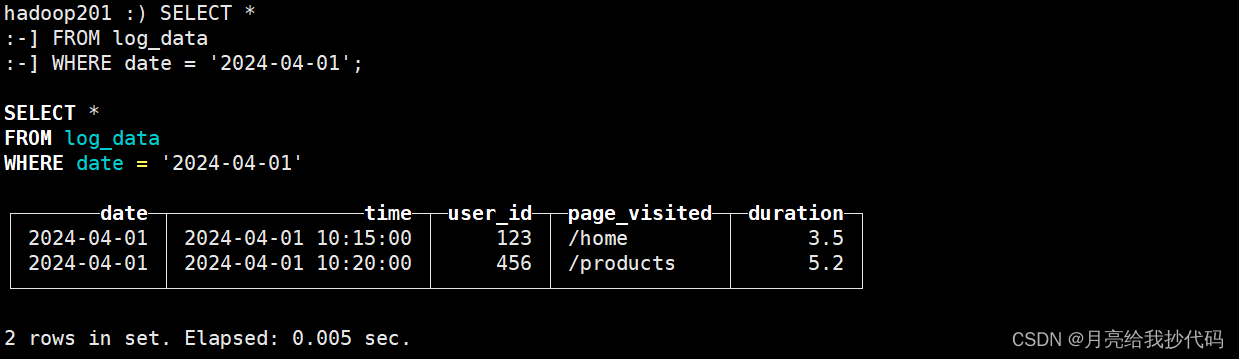
SELECT *
FROM log_data
WHERE date = '2024-04-01';
查询表的分区信息
SELECT *
FROM system.parts
WHERE database = 'test'AND table = 'log_data';
3.ReplacingMergeTree 引擎
ReplacingMergeTree 引擎是 MergeTree 引擎的变种,支持在插入新数据时自动删除旧数据,适用于周期性更新的数据存储场景。
注意! 它在一些老的 ClickHouse 版本中并不会立即去重,而是在经过一定的周期后才会去重。
在新版中则会立即去重,但不同分区中还是可能存在相同的数据。因为它的去重机制并不是全局的,而是在每个分区内部进行操作的。
假设我们需要存储温度传感器数据,并且定期更新数据以保持最新。我们可以使用 ReplacingMergeTree 引擎来实现自动替换过期数据的功能。
创建表
CREATE TABLE temperature_data
(sensor_id UInt32,temperature Float32,timestamp DateTime
)
ENGINE = ReplacingMergeTree(timestamp)
PRIMARY KEY (sensor_id)
ORDER BY (sensor_id);
创建一个名为 temperature_data 的表,用于存储温度传感器数据。数据将按照传感器 ID 进行排序,只保留时间戳最大的值。
ReplacingMergeTree(timestamp) 中的参数
(timestamp)可以不指定。在有重复列的情况下,会根据ORDER BY默认保留重复列中最后插入的那行数据。
插入数据
INSERT INTO temperature_data (sensor_id, temperature, timestamp)
VALUES(1, 23.5, '2024-04-01 12:00:00'),(2, 21.8, '2024-04-01 12:00:00'),(1, 24.3, '2024-04-01 12:15:00'),(2, 22.1, '2024-04-01 12:15:00');
查询数据
SELECT * FROM temperature_data;
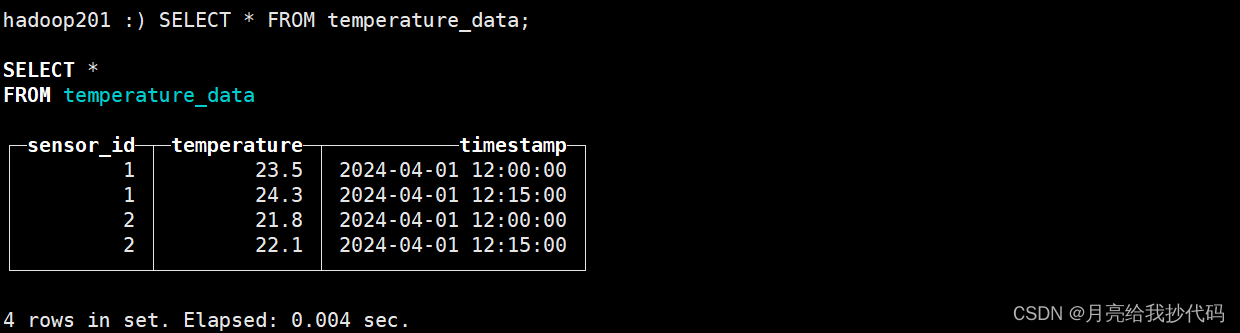
查询出来,可能会出现并没有去重成功的情况,这是因为使用的 ClickHouse 是老版本的,在插入数据时不会立即去重。
此时,我们可以手动执行合并任务:
OPTIMIZE TABLE temperature_data FINAL;
合并任务执行完成后,我们再次查询:
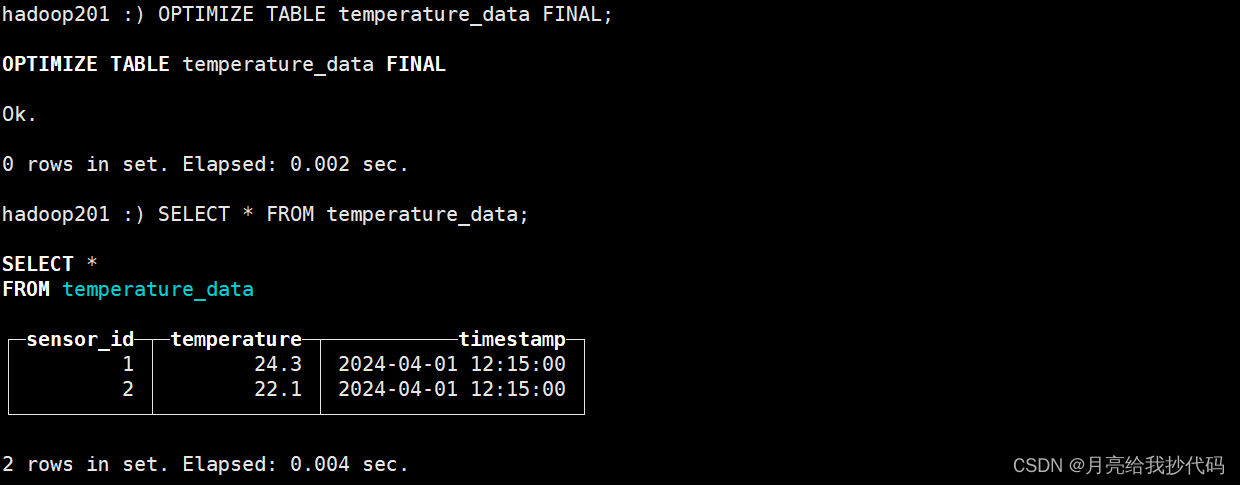
可以看到,已经成功的完成了去重操作,并且在 ID 相同的情况下,保留了时间戳最大的数据。
4.AggregatingMergeTree 引擎
该引擎继承自 MergeTree,改变了数据部分合并的逻辑。
ClickHouse 将具有相同主键(或更准确地说,具有相同排序键)的所有行替换为存储聚合函数状态组合的单行(在一个数据部分内)。
假设我们有一个名为 website_logs 的表,用于存储网站访问日志数据,并且实时计算每小时的访问量。
创建表
CREATE TABLE website_logs(date Date,hour UInt8,visits UInt32
)
ENGINE = AggregatingMergeTree
PARTITION BY toYYYYMM(date)
ORDER BY (date, hour);
插入数据
INSERT INTO website_logs (date, hour, visits)
VALUES('2024-04-01', 0, 100),('2024-04-01', 1, 150),('2024-04-01', 2, 200),('2024-04-01', 3, 180),('2024-04-01', 4, 220),('2024-04-01', 5, 250),('2024-04-01', 6, 300),('2024-04-01', 7, 280),('2024-04-01', 8, 320),('2024-04-01', 9, 350),('2024-04-01', 10, 380),('2024-04-01', 11, 400),('2024-04-01', 12, 420),('2024-04-01', 13, 450),('2024-04-01', 14, 480),('2024-04-01', 15, 500),('2024-04-01', 16, 520),('2024-04-01', 17, 550),('2024-04-01', 18, 580),('2024-04-01', 19, 600),('2024-04-01', 20, 620),('2024-04-01', 21, 640),('2024-04-01', 22, 660),('2024-04-01', 23, 680);
查询数据
SELECT *
FROM website_logs
ORDER BY date, hour;
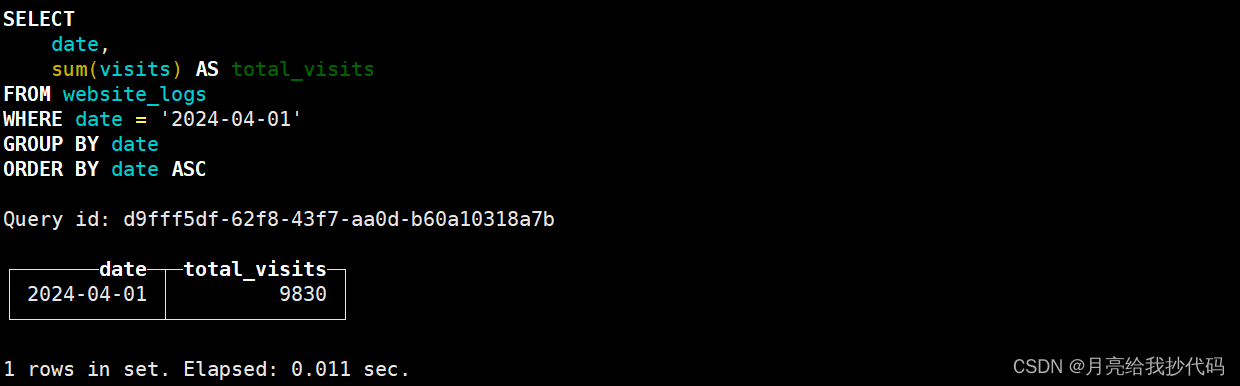
5.SummingMergeTree 引擎
SummingMergeTree 引擎用于对相同主键的行进行聚合,在插入新数据时对相同主键的行进行求和。
假设我们要存储每天的销售数据,并计算每种产品的总销售额。
创建表
CREATE TABLE sales_data
(date Date,product_id UInt32,sales_amount Float32
)
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(date)
ORDER BY (date, product_id);
创建了一个名为 sales_data 的表,用于存储销售数据。表包含了三个列:date(日期)、product_id(产品 ID)和 sales_amount(销售额)。
数据将按照日期和产品 ID 进行分区(这里相当于 date, product_id 是联合主键),并且按照日期和产品 ID 排序。
插入数据
INSERT INTO sales_data (date, product_id, sales_amount)
VALUES('2024-04-01', 1, 100.50),('2024-04-01', 2, 150.75),('2024-04-01', 3, 200.25),('2024-04-01', 1, 120.80),('2024-04-01', 2, 180.60),('2024-04-01', 3, 220.40);
查询数据
SELECT * FROM sales_data;
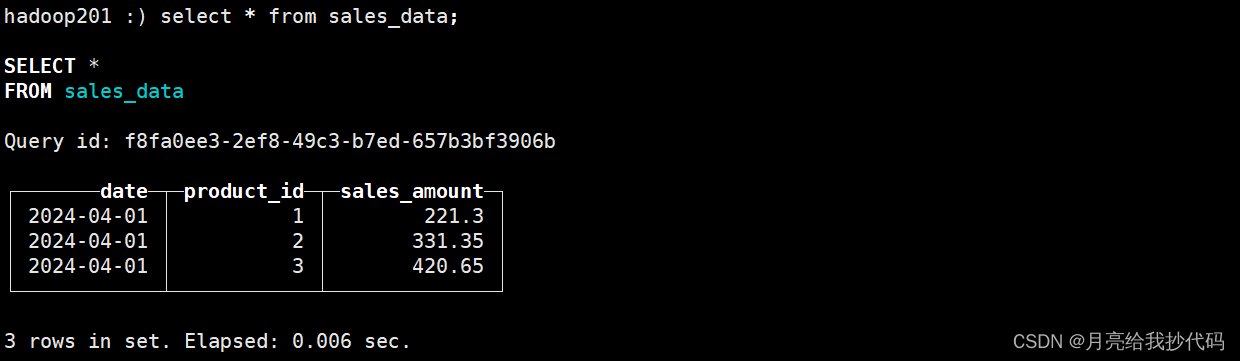
可以看到,即使我们插入了多行数据,但是因为其中包含 date, product_id(联合主键)相同的数据,所以它会自动合并(求和计算)除主键外的所有数值列。
6.CollapsingMergeTree 引擎
用于在插入新数据时折叠(合并)相同主键的行,并且保留最新的行。适用于存储以事件时间为主要维度的数据流,并保留最新的状态。
假设我们要存储用户在网站上的访问记录,并且保留每个用户的最新访问信息。
创建表:
CREATE TABLE user_visits
(user_id UInt32,visit_time DateTime,url String,is_active Int8
)
ENGINE = CollapsingMergeTree(is_active)
PARTITION BY toYYYYMM(visit_time)
ORDER BY (user_id, visit_time);
创建了一个名为 user_visits 的表,用于存储用户访问记录。表包含了四个列:user_id(用户 ID)、visit_time(访问时间)、url(访问的网址)和 is_active(活跃标志)。数据将按照访问时间和用户 ID 进行分区,并且按照用户 ID 和访问时间排序。
在创建表时,我们指定了 CollapsingMergeTree(is_active),表示当插入新数据时,如果有相同主键的行(在这里是相同的 user_id),ClickHouse 将根据 is_active 列的值来选择保留哪一行,只保留 is_active 最大的行。
插入数据
INSERT INTO user_visits (user_id, visit_time, url, is_active)
VALUES(1, '2024-04-01 10:00:00', '/page1', 1),(2, '2024-04-01 10:05:00', '/page2', 1),(1, '2024-04-01 10:10:00', '/page3', -1),(3, '2024-04-01 10:15:00', '/page4', 1),(2, '2024-04-01 10:20:00', '/page5', -1),(1, '2024-04-01 10:25:00', '/page6', 1);
查询数据:
SELECT *
FROM user_visits
ORDER BY user_id, visit_time;
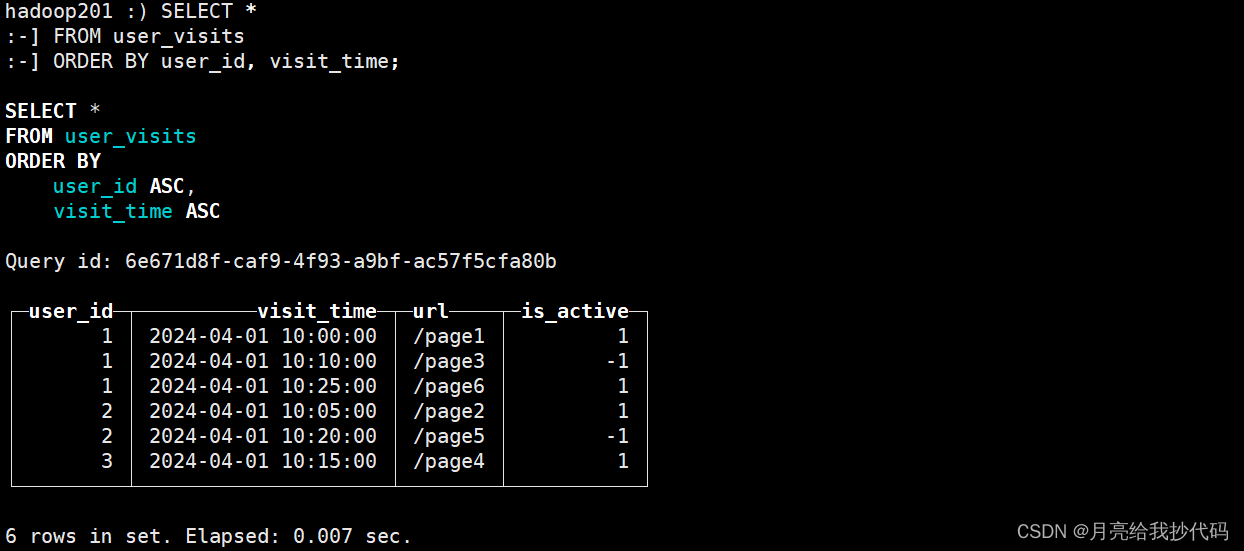
可以看到,它并未进行合并操作,这是因为 ClickHouse 还没有合并数据,它在一个我们无法预料的未知时刻合并数据片段。
此时,我们可以手动执行合并任务,添加关键字 FINAL 强制进行合并:
SELECT *
FROM user_visits FINAL
ORDER BY user_id, visit_time;
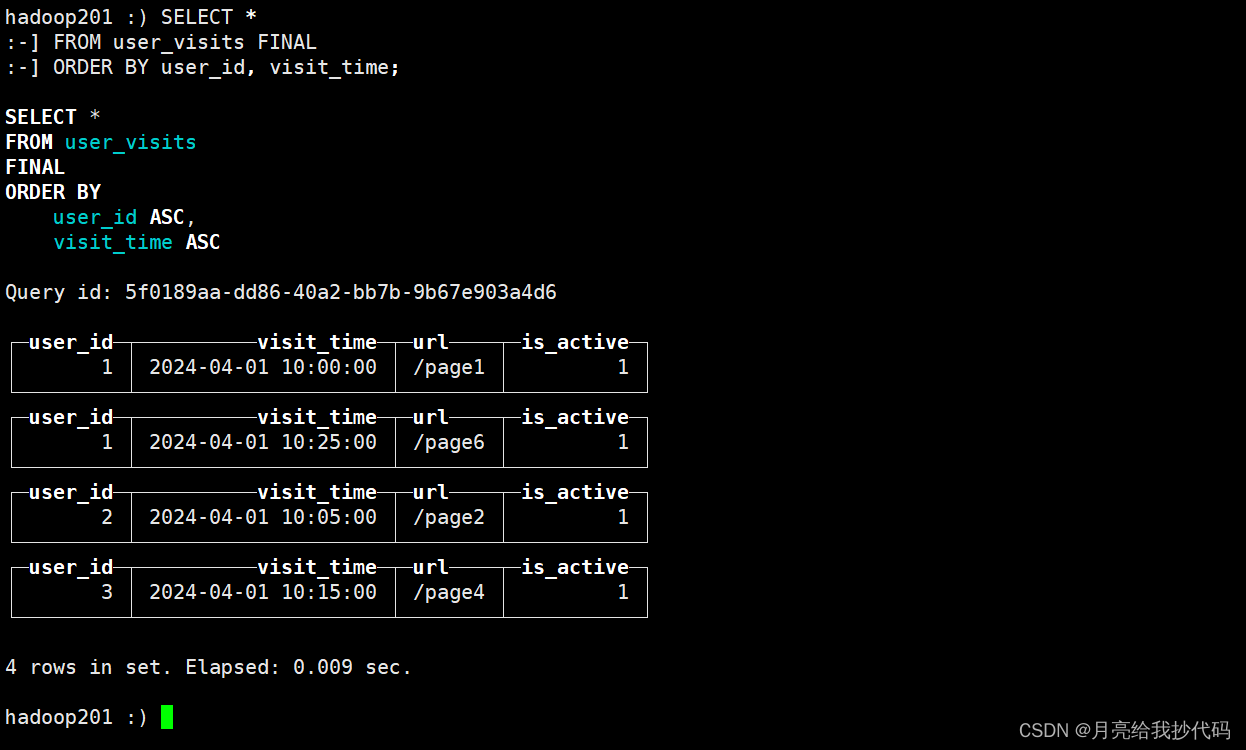
它只会保留当前分区内 is_active 最大的行,最大值一样会保存多行。
7.Distributed 引擎
用于在多个 ClickHouse 节点上分布存储数据,并且实现数据的分片存储和并行查询处理,适用于构建分布式数据仓库和实时分析系统。
假设我们有多个 ClickHouse 节点,我们要在这些节点上分布存储数据,并且进行查询操作。
创建分布式表
CREATE TABLE distributed_log_data
(date Date,time DateTime,user_id UInt32,page_visited String,duration Float32
)
ENGINE = Distributed('cluster_name', 'default', 'log_data', rand());
创建一个名为 distributed_log_data 的分布式表,将数据分布在名为 cluster_name 的 ClickHouse 集群上,并且将数据存储在名为 log_data 的本地表中。
插入数据
INSERT INTO distributed_log_data (date, time, user_id, page_visited, duration)
VALUES('2024-04-01', '2024-04-01 10:15:00', 123, '/home', 3.5),('2024-04-01', '2024-04-01 10:20:00', 456, '/products', 5.2),('2024-04-02', '2024-04-02 08:30:00', 789, '/about', 2.1);
查询数据
SELECT *
FROM distributed_log_data
WHERE date = '2024-04-01';
TTL
TTL(Time to Live)是一种数据管理机制,在 ClickHouse 中,TTL 机制允许你为表中的数据设置生命周期,以控制数据的存储时间。你可以为表中的某个列设置 TTL,指定数据的存储时间,一旦数据的时间戳超过了 TTL 设置的时间,数据将被自动删除。
列级 TTL
注意,列级 TTL 功能只有在 ClickHouse 21.10 版本及以上才能使用,低版本会失效。
创建表并为指定字段设置 TTL
CREATE TABLE ttl_example_col
(d DateTime DEFAULT now(),a Int TTL d + INTERVAL 10 SECOND,b Int TTL d + INTERVAL 10 SECOND,c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
在这里,为 a、b 字段设置了 TTL,指定了该列数据的存储时间为插入时间后的 10 秒,超过就会被自动清除。
如果表已经存在,那么可以通过修改表字段的方式进行添加:
ALTER TABLE ttl_example_col
MODIFY COLUMN a Int32 TTL d + INTERVAL 10 SECOND,
MODIFY COLUMN b String TTL d + INTERVAL 10 SECOND;
插入测试数据
INSERT INTO ttl_example_col (a, b, c) VALUES(10, 20, 'Data1'),(15, 25, 'Data2'),(20, 30, 'Data3');
插入后,立即进行查询:
SELECT * FROM ttl_example_col;
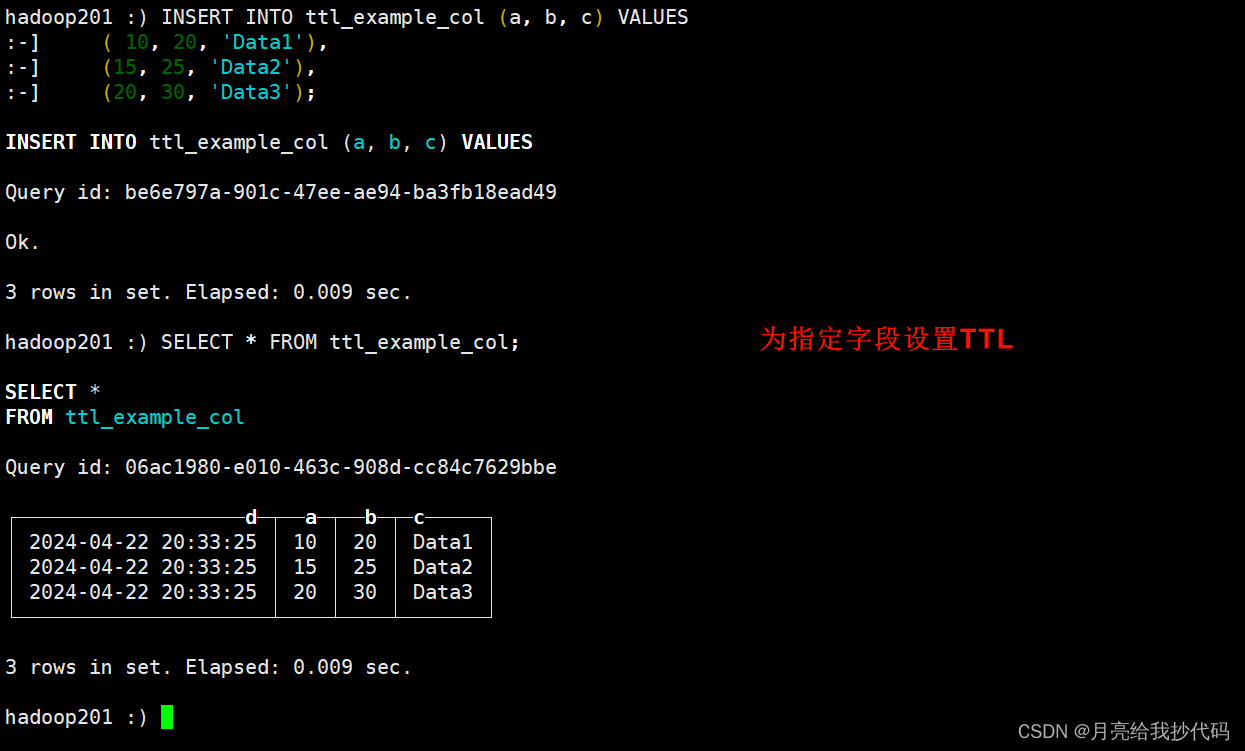
等待一分钟后,再次查询,验证数据是否过期,这里需要我们手动进行合并,因为 ClickHouse 默认合并需要等很久。
OPTIMIZE TABLE ttl_example_col FINAL;
再次查询,此时如果你使用的 ClickHouse 版本是 21.10 以下,那么会不生效,如果是 21.10 版本及以上,则可以生效。
各位可以去 ClickHouse 的在线测试平台选择版本进行测试 —— ClickHouse Playground
这里提供完整的 SQL 测试代码:
CREATE TABLE ttl_example_col
(d DateTime DEFAULT now(),a Int TTL d + INTERVAL 10 SECOND,b Int TTL d + INTERVAL 10 SECOND,c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;INSERT INTO ttl_example_col (a, b, c) VALUES(10, 20, 'Data1'),(15, 25, 'Data2'),(20, 30, 'Data3');SELECT * FROM ttl_example_col;SELECT sleep(3);
SELECT sleep(3);
SELECT sleep(3);
SELECT sleep(3);OPTIMIZE TABLE ttl_example_col FINAL; SELECT * FROM ttl_example_col;
使用 21.10 及以上版本运行结果 —— 成功:
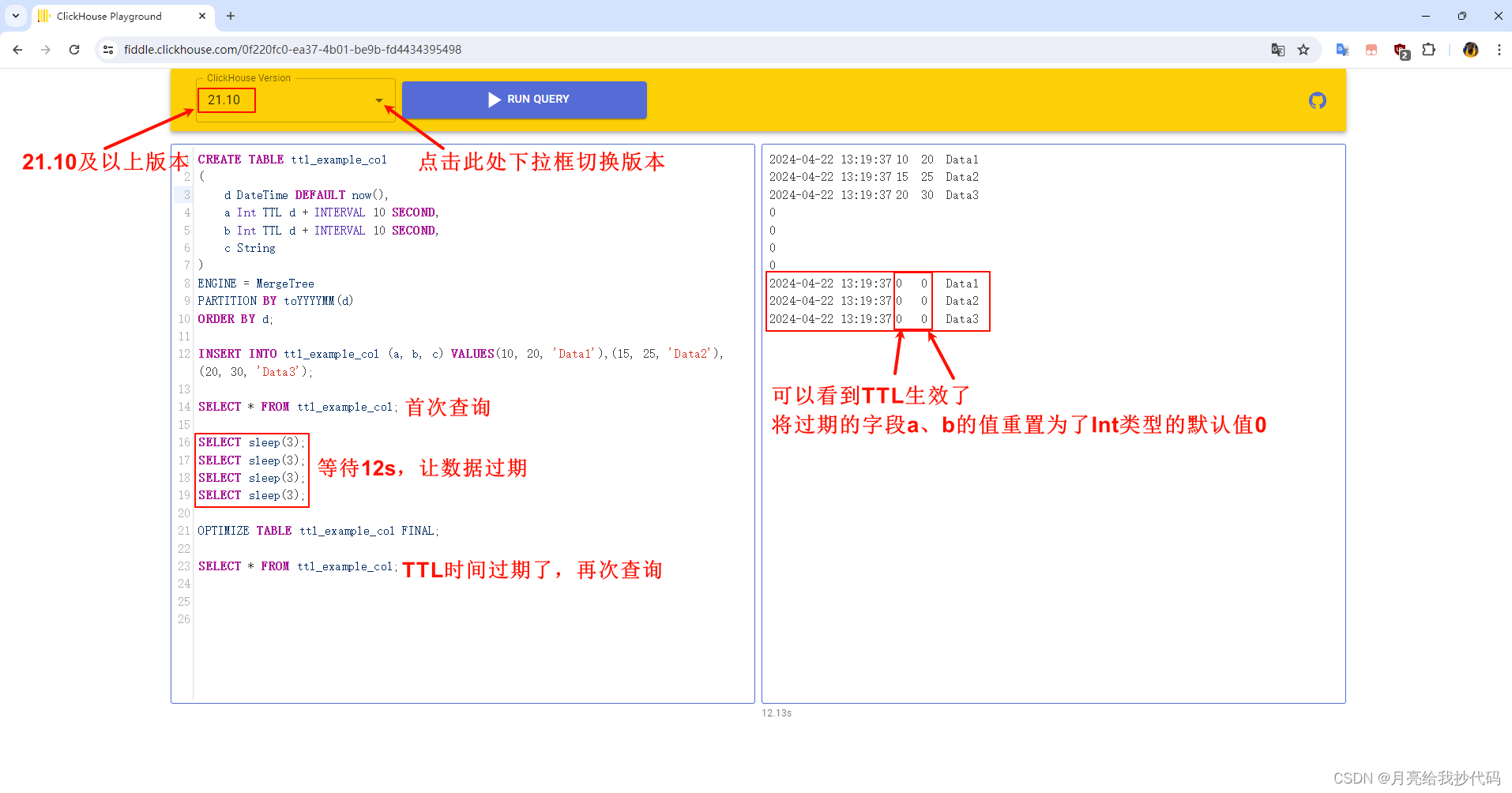
使用 21.10 以下版本运行结果 —— 失败:
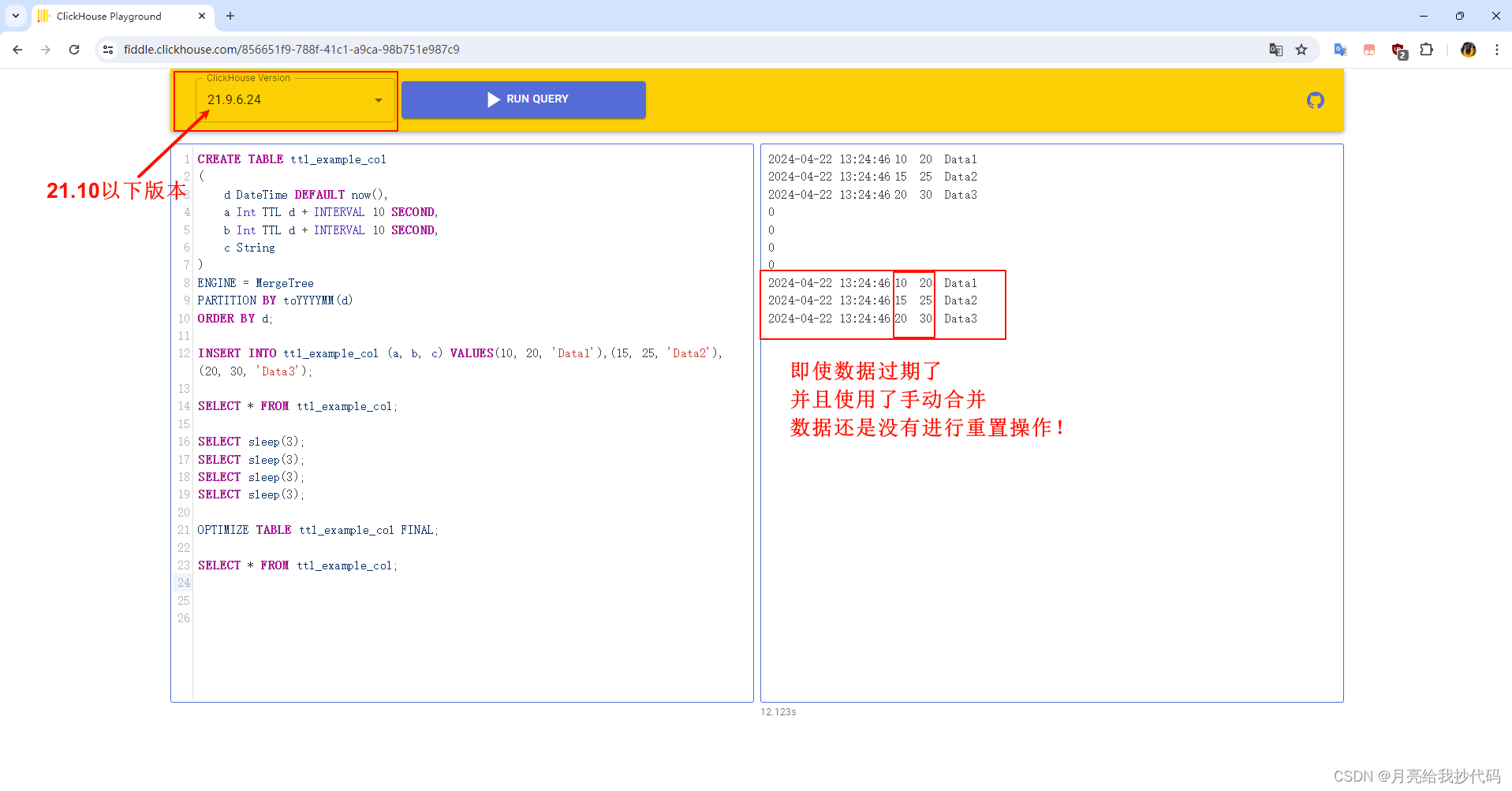
整个网上都没有人探讨这个问题,博主我也是踩了好久坑,一个一个版本测试出来的,一度以为是我本地 ClickHouse 的问题。
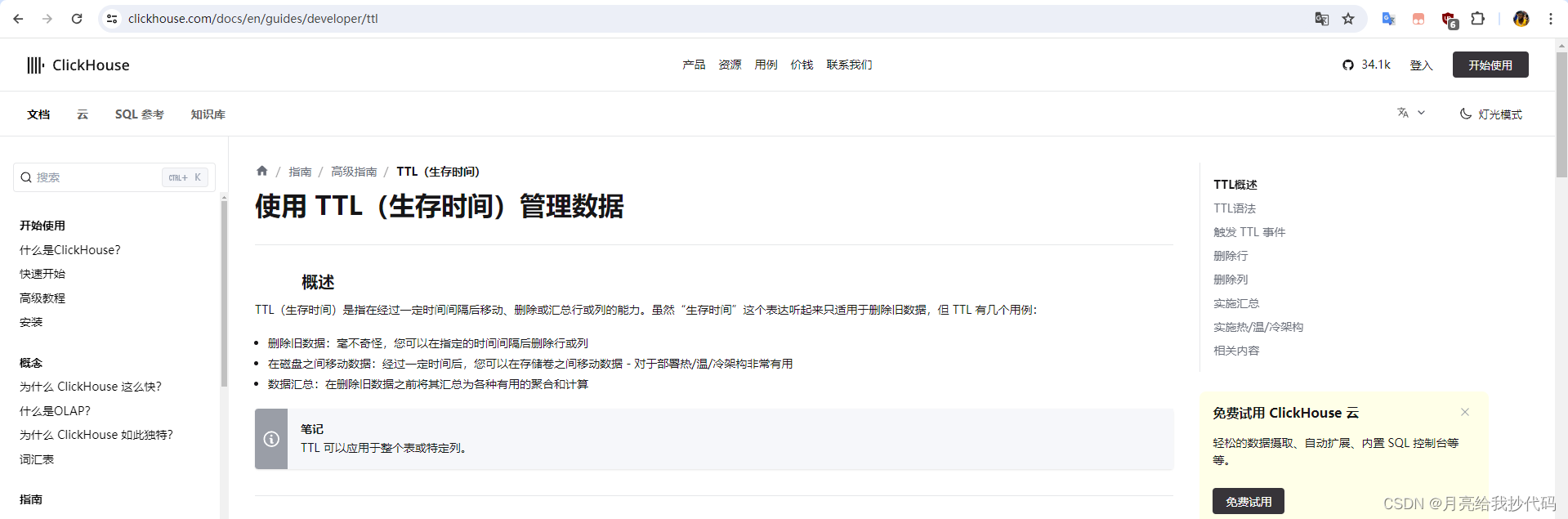
官网中也并没有提到哪些版本可以使用列级 TTL:
表级TTL
整表设置 TTL 时,并没有出现因版本不同导致 TTL 失效的问题。
创建带有 TTL 的表
CREATE TABLE ttl_example
(id UInt32,name String,age UInt8,insertion_time DateTime DEFAULT now()
)
ENGINE = MergeTree
ORDER BY id
TTL insertion_time + INTERVAL 1 MINUTE;
在这个示例中,我们创建了一个名为 ttl_example 的表,包含了 id、name、age 和 insertion_time 四个列。我们通过 TTL 子句为表设置了 TTL,指定了数据的存储时间为插入时间后的 1 分钟,超过就会被自动删除。
如果表已经存在,同样也可以使用修改的方式添加:
ALTER TABLE ttl_example MODIFY TTL insertion_time + INTERVAL 1 MINUTE;
插入测试数据
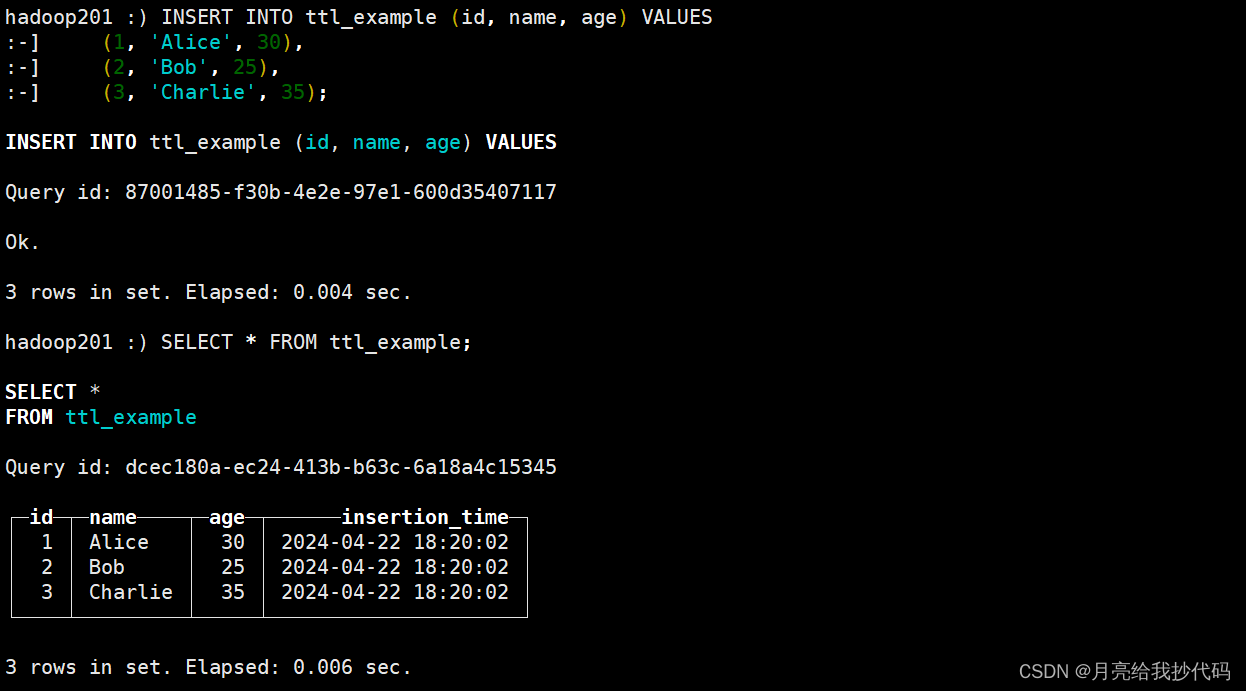
INSERT INTO ttl_example (id, name, age) VALUES(1, 'Alice', 30),(2, 'Bob', 25),(3, 'Charlie', 35);
插入后,同样的,立即进行查询:
SELECT * FROM ttl_example;
测试 TTL 机制
等待 1 分钟后,执行查询操作,可以观察到超过 TTL 时间的数据将会被自动删除:
SELECT * FROM ttl_example;
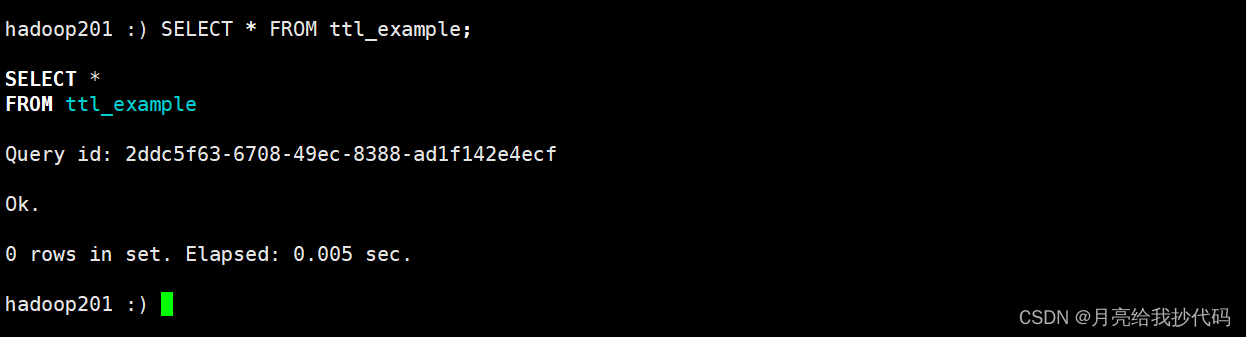
在等待 TTL 时间过去后,我们可以观察到超过 TTL 时间的数据会被自动删除,从而实现了数据的自动清理。