第1关:SparkSQL初识
任务描述
本关任务:编写一个sparksql基础程序。
相关知识
为了完成本关任务,你需要掌握:1. 什么是SparkSQL 2. 什么是SparkSession。
什么是SparkSQL
Spark SQL是用来操作结构化和半结构化数据的接口。
当每条存储记录共用已知的字段集合,数据符合此条件时,Spark SQL就会使得针对这些数据的读取和查询变得更加简单高效。具体来说,Spark SQL提供了以下三大功能:
(1) Spark SQL可以从各种结构化数据源(例如JSON、Parquet等)中读取数据。
(2) Spark SQL不仅支持在Spark程序内使用SQL语句进行数据查询,也支持从类似商业智能软件Tableau这样的外部工具中通过标准数据库连接器(JDBC/ODBC)连接sparkSQL进行查询。
(3) 当在Spark程序内使用Spark SQL时,Spark SQL支持SQL与常规的Python/Java/Scala代码高度整合,包括连接RDD与SQL表、公开的自定义SQL函数接口等。
什么是SparkSession
Spark中所有功能的入口点都是SparkSession类。要创建基本的SparkSession,只需使用SparkSession.builder()。
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession .builder().appName("Java Spark SQL基本示例").master("local").config("spark.some.config.option" , "some-value").getOrCreate();//打印spark版本号System.out.println(spark.version());
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,具体任务如下:
打印spark的版本号。
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
package com.educoder.bigData.sparksql;import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;public class Test1 {public static void main(String[] args) throws AnalysisException {/********* Begin *********/SparkSession spark = SparkSession .builder() .appName("Java Spark SQL基本示例") .master("local") .config("spark.some.config.option" , "some-value") .getOrCreate(); //打印spark版本号 System.out.println(spark.version()); /********* End *********/}}第2关:Dataset创建及使用
任务描述
本关任务:创建Dataset并使用
相关知识
为了完成本关任务,你需要掌握:
什么是Dataset;
Dataset如何创建 ;
Dataset如何操作数据。
什么是Dataset
在Spark2.0版本以后,DataFrame API将会和Dataset API合并,统一数据处理API。故实训中的Dateset和DataFrame可看成一个概念。
Dataset和RDD一样,也是Spark的一种弹性分布式数据集,它是一个由列组成的数据集,概念上等同于关系型数据库中的一张表,但在底层具有更丰富的优化。Dataset可以从多种来源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。有人肯定会问,已经有了弹性分布式数据集RDD,为什么还要引入Dataset呢?因为在Spark中,我们可以像在关系型数据库中使用SQL操作数据库表一样,使用Spark SQL操作Dataset。这让熟悉关系型数据库SQL人员也能轻松掌握。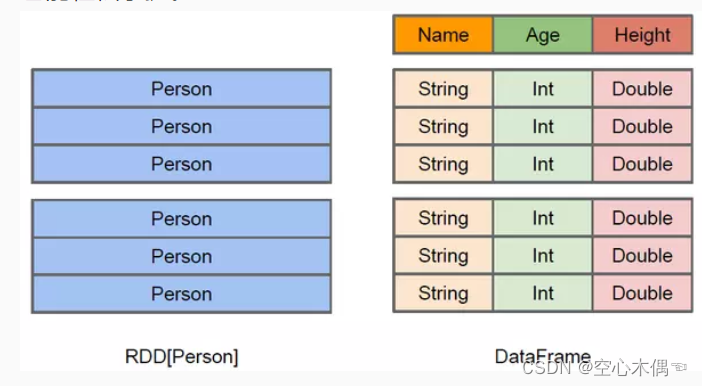
上图直观地体现了 Dataset 和 RDD 的区别。左侧的 RDD[Person] 虽然以 Person 为类型参数,但 Spark 框架本身不了解 Person 类的内部结构。而右侧的 Dataset 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。Dataset 除了提供了比 RDD 更丰富的算子以外,更重要的特点能提升执行效率、减少数据读取以及执行计划的优化等。
Dataset 上可用的操作分为转换和操作。转换是产生新 Dataset 的转换,动作是触发计算和返回结果的转换。示例转换包括map,filter,select和aggregate(groupBy)。示例操作将数据计数,显示或写入文件系统。
Dataset 是“懒惰的”,即只有在调用动作时才会触发计算。在内部,Dataset 表示描述生成数据所需计算的逻辑计划。调用操作时,Spark 的查询优化器会优化逻辑计划,并以并行和分布式方式生成有效执行的物理计划。要探索逻辑计划以及优化的物理计划,请使用explain函数。
要有效地支持特定于域的对象,需要使用编码器。编码器将域特定类型T映射到 Spark 的内部类型系统。例如,给定一个具有两个字段的 Person,name(string)和age(int),编码器用于告诉 Spark 在运行时生成代码以将 Person 对象序列化为二进制结构。该二进制结构通常具有低得多的存储器占用面积以及针对数据处理(例如,柱状格式)的效率进行优化。要了解数据的内部二进制表示,请使用模式函数。
Dataset如何创建
通常有两种方法来创建Dataset。最常见的方法是使用SparkSession上提供的读取功能将Spark指向存储系统上的某些文件。
//创建泛型的Dataset
Dataset<Row> df = spark.read().json("people.json");
//创建Person类型的DatasetDataset<Person> people = spark.read().json("people.json").as(Encoders.bean(Person.class));
//以表格形式显示前20行Dataset
df.show();
people.show();
也可以通过现有数据集上的转换来创建Dataset。 例如,以下内容通过对现有数据集应用过滤器来创建新Dataset:
Dataset<String> names = people.map((Person p) -> p.name, Encoders.STRING));
Dataset如何操作数据
Dataset操作数据有两种方式:API方式处理数据和以编程方式处理数据。
API方式处理数据
Dataset操作也可以通过以下定义的各种特定于域的语言(DSL)函数进行无类型操作:Dataset(类),列和函数。 这些操作与R或Python中的数据框抽象中可用的操作非常相似。
要从数据集中选择列,请在在Java中使用col 。
Column ageCol = people.col("age");
请注意,Column类型也可以通过其各种功能进行操作。
import static org.apache.spark.sql.functions.col;
以树格式
df.printSchema();
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// 仅选择“名称”列
df.select("name").show();
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// 选择所有人,但将年龄增加1
df.select(col("name"), col("age").plus(1)).show();
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// 选择年龄超过21
df.filter(col("age").gt(21)).show();
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// 计数按年龄的人
df.groupBy("age").count().show();
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
以编程方式处理数据
SparkSession支持让应用程序以编程方式运行SQL查询并返回结果。
//读取json,并将Dataset,并注册为SQL临时视图
sparkSession.read().json("people.json").createOrReplaceTempView("people");
//以表格形式显示前20行Dataset
sparkSession.sql("select * from people").show();
// + ---- + ------- +
// | 年龄| 名称|
// + ---- + ------- +
// | null | Michael |
// | 30 | 安迪|
// | 19 | 贾斯汀|
// + ---- + ------- +
编程要求
根据提示,在右侧编辑器补充代码,读取people.json文件,过滤age为23的数据,并以表格形式显示前20行Dataset。
people.json文件内容如下:
{"age":21,"name":"张三", "salary":"3000"}
{"age":22,"name":"李四", "salary":"4500"}
{"age":23,"name":"王五", "salary":"7500"}
package com.educoder.bigData.sparksql;import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.SparkSession;public class Test2 {public static void main(String[] args) throws AnalysisException {SparkSession spark = SparkSession .builder().appName("test1").master("local").config("spark.some.config.option" , "some-value").getOrCreate();/********* Begin *********/spark.read().json("people.json").createOrReplaceTempView("people"); spark.sql("select * from people where age != '23'").show();/********* End *********/}}
第3关:Dataset自定义函数
任务描述
本关任务:编写Dataset自定义函数。
相关知识
为了完成本关任务,你需要掌握:
UserDefinedAggregateFunction介绍;
如何使用。
UserDefinedAggregateFunction
UserDefinedAggregateFunction是实现用户定义的聚合函数基础类,用户实现自定义无类型聚合函数必须扩展UserDefinedAggregateFunction 抽象类,相关方法如下:
方法及方法返回 描述
StructType bufferSchema() StructType表示聚合缓冲区中值的数据类型。
DataType dataType() UserDefinedAggregateFunction的返回值的数据类型
boolean deterministic() 如果此函数是确定性的,则返回true
Object evaluate(Row buffer) 根据给定的聚合缓冲区计算此UserDefinedAggregateFunction的最终结果
void initialize(MutableAggregationBuffer buffer) 初始化给定的聚合缓冲区
StructType inputSchema() StructType表示此聚合函数的输入参数的数据类型。
void merge(MutableAggregationBuffer buffer1, Row buffer2) 合并两个聚合缓冲区并将更新的缓冲区值存储回buffer1
void update(MutableAggregationBuffer buffer, Row input) 使用来自输入的新输入数据更新给定的聚合缓冲区
如何使用
我们以计算员工薪水平均值的例子来说:
首先在用户自定义函数的构造函数中,定义聚合函数的输入参数的数据类型和聚合缓冲区中值的数据类型。
//定义员工薪水的输入参数类型为LongType
List<StructField> inputFields = new ArrayList<StructField>();
inputFields.add(DataTypes.createStructField("inputColumn", DataTypes.LongType, true));
inputSchema = DataTypes.createStructType(inputFields);
//定义员工薪水总数、员工个数的参数类型
List<StructField> bufferFields = new ArrayList<StructField>();
bufferFields.add(DataTypes.createStructField("sum", DataTypes.LongType, true));
bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType, true));
bufferSchema = DataTypes.createStructType(bufferFields);
对聚合缓冲区中值设置初始值。
@Overridepublic void initialize(MutableAggregationBuffer buffer) {// TODO Auto-generated method stubbuffer.update(0, 0L);buffer.update(1, 0L);}
把自定义函数的输入薪水数据转化为定义的聚合缓冲区的值(薪水总数、员工个数),并更新。
@Override
public void update(MutableAggregationBuffer buffer, Row input) {if (!input.isNullAt(0)) {long updatedSum = buffer.getLong(0) + input.getLong(0);long updatedCount = buffer.getLong(1) + 1;buffer.update(0, updatedSum);buffer.update(1, updatedCount);}
}
把多个聚合缓冲区的值进行合并。
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {// TODO Auto-generated method stublong mergedSum = buffer1.getLong(0) + buffer2.getLong(0);long mergedCount = buffer1.getLong(1) + buffer2.getLong(1);buffer1.update(0, mergedSum);buffer1.update(1, mergedCount);
}
最后通过聚合缓冲区的值计算输出结果。
@Override
public Object evaluate(Row buffer) {// TODO Auto-generated method stubreturn ((double) buffer.getLong(0)) / buffer.getLong(1);
}
就此自定义函数就开发完了,通过SparkSession的udf()方法会返回注册用户定义函数的方法集合UDFRegistration
通过UDFRegistration调用register方法进行自定义函数注册,使用如下:
// 注册自定义函数myAverage
spark.udf().register("myAverage", new MyAverage());
//读取json文件
spark.read().json("people.json").createOrReplaceTempView("people");
//使用自定义函数计算薪水平均值
spark.sql("SELECT myAverage(salary) as average_salary FROM people").show();
// +--------------+
// |average_salary|
// +--------------+
// | 5000|
// +--------------+
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,编写自定义函数类MyAverage,用来计算用户薪水平均值,平台已提供了最后的实现:
spark.udf().register("myAverage", new MyAverage());
spark.read().json("people.json").createOrReplaceTempView("people");
spark.sql("SELECT myAverage(salary) as average_salary FROM people").show();
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
package com.educoder.bigData.sparksql;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class MyAverage extends UserDefinedAggregateFunction {
private static final long serialVersionUID = 1L;
private StructType inputSchema;
private StructType bufferSchema;
public MyAverage() {
List<StructField> inputFields = new ArrayList<StructField>();
inputFields.add(DataTypes.createStructField("inputColumn", DataTypes.LongType, true));
inputSchema = DataTypes.createStructType(inputFields);
List<StructField> bufferFields = new ArrayList<StructField>();
bufferFields.add(DataTypes.createStructField("sum", DataTypes.LongType, true));
bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType, true));
bufferSchema = DataTypes.createStructType(bufferFields);
}
@Override
public StructType bufferSchema() {
// TODO Auto-generated method stub
return bufferSchema;
}
@Override
public DataType dataType() {
// TODO Auto-generated method stub
return DataTypes.DoubleType;
}
@Override
public boolean deterministic() {
// TODO Auto-generated method stub
return true;
}
@Override
public Object evaluate(Row buffer) {
// TODO Auto-generated method stub
return ((double) buffer.getLong(0)) / buffer.getLong(1);
}
@Override
public void initialize(MutableAggregationBuffer buffer) {
// TODO Auto-generated method stub
buffer.update(0, 0L);
buffer.update(1, 0L);
}
@Override
public StructType inputSchema() {
// TODO Auto-generated method stub
return inputSchema;
}
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
// TODO Auto-generated method stub
long mergedSum = buffer1.getLong(0) + buffer2.getLong(0);
long mergedCount = buffer1.getLong(1) + buffer2.getLong(1);
buffer1.update(0, mergedSum);
buffer1.update(1, mergedCount);
}
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
if (!input.isNullAt(0)) {
long updatedSum = buffer.getLong(0) + input.getLong(0);
long updatedCount = buffer.getLong(1) + 1;
buffer.update(0, updatedSum);
buffer.update(1, updatedCount);
}
}
}