YOLOX: Exceeding YOLO Series in 2021
Abstract
- 在本报告中,我们介绍了YOLO系列的一些经验改进,形成了一种新的高性能探测器—YOLOX。我们将YOLO检测器切换到无锚方式,并进行其他先进的检测技术,即去耦头和领先的标签分配策略SimOTA,以在大规模的模型范围内实现最先进的结果:对于只有0.91M参数和1.08G FLOP的YOLONano,我们在COCO上获得25.3%的AP,超过NanoDet 1.8%的AP;对于工业上使用最广泛的探测器之一YOLOv3,我们在COCO上将其提高到47.3%的AP,比当前的最佳实践高3.0%的AP;对于与YOLOv4-CSP、YOLOv5-L参数量大致相同的YOLOX-L,我们在特斯拉V100上以68.9 FPS的速度在COCO上实现了50.0%的AP,超过YOLOv5-5L 1.8%的AP。此外,我们使用一款YOLOX-L赢得了流媒体感知挑战赛(CVPR 2021自动驾驶研讨会)的第一名。我们希望这份报告能为开发人员和研究人员在实际场景中提供有用的经验,我们还提供了支持ONNX、TensorRT、NCNN和Openvino的部署版本。源代码位于https://github.com/Megvii-BaseDetection/YOLOX。
- 论文地址:[2107.08430] YOLOX: Exceeding YOLO Series in 2021 (arxiv.org)
- YOLOX 的设计,在大方向上主要遵循以下几个原则: 所有组件全平台可部署;避免过拟合 COCO,在保持超参规整的前提下,适度调参;不做或少做稳定涨 点但缺乏新意的工作(更大模型,更多的数据)。
- Anchor Free 的好处是全方位的。1). Anchor Based 检测器为了追求最优性能通常会需要对anchor box 进行聚类分析,这无形间增加了算法工程师的时间成本; 2). Anchor 增加了检测头的复杂度以及生成结果的数量,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。 3). Anchor Free 的解码代码逻辑更简单,可读性更高。
- 至于为什么 Anchor Free 现在可以上 YOLO ,并且性能不降反升,这与样本匹配有密不可分的联系。与 Anchor Free 比起来,样本匹配在业界似乎没有什么关注度。但是一个好的样本匹配算法可以天然缓解拥挤场景的检测问题( LLA、OTA 里使用动态样本匹配可以在 CrowdHuman 上提升 FCOS 将近 10 个点),缓解极端长宽比的物体的检测效果差的问题,以及极端大小目标正样本不均衡的问题。甚至可能可以缓解旋转物体检测效果不好的问题,这些问题本质上都是样本匹配的问题。样本匹配有 4 个因素十分重要:(45 封私信 / 80 条消息) 如何评价旷视开源的YOLOX,效果超过YOLOv5? - 知乎 (zhihu.com)
- loss/quality/prediction aware :基于网络自身的预测来计算 anchor box 或者 anchor point 与 gt 的匹配关系,充分考虑到了不同结构/复杂度的模型可能会有不同行为,是一种真正的 dynamic 样本匹配。而 loss aware 后续也被发现对于 DeTR 和 DeFCN 这类端到端检测器至关重要。与之相对的,基于 IoU 阈值 /in Grid(YOLOv1)/in Box or Center(FCOS) 都属于依赖人为定义的几何先验做样本匹配,目前来看都属于次优方案。
- center prior : 考虑到感受野的问题,以及大部分场景下,目标的质心都与目标的几何中心有一定的联系,将正样本限定在目标中心的一定区域内做 loss/quality aware 样本匹配能很好地解决收敛不稳定的问题。
- 不同目标设定不同的正样本数量( dynamic k ):我们不可能为同一场景下的西瓜和蚂蚁分配同样的正样本数,如果真是那样,那要么蚂蚁有很多低质量的正样本,要么西瓜仅仅只有一两个正样本。Dynamic k 的关键在于如何确定k,有些方法通过其他方式间接实现了动态 k ,比如 ATSS、PAA ,甚至 RetinaNet ,同时,k的估计依然可以是 prediction aware的,我们具体的做法是首先计算每个目标最接近的10个预测,然后把这个 10 个预测与 gt 的 iou 加起来求得最终的k,很简单有效,对 10 这个数字也不是很敏感,在 5~15 调整几乎没有影响。
- 全局信息:有些 anchor box/point 处于正样本之间的交界处、或者正负样本之间的交界处,这类 anchor box/point 的正负划分,甚至若为正,该是谁的正样本,都应充分考虑全局信息。
Introduction
- 随着目标检测的发展,YOLO系列始终追求实时应用的最佳速度和精度权衡。他们提取了当时可用的最先进的检测技术(例如,YOLOv2的锚点,YOLOv3的残差结构),并优化了最佳实践的实现。目前,YOLOv5具有最佳的权衡性能,在13.7ms的COCO上有48.2%的AP。我们选择分辨率为640×640的YOLOv5-L模型,并在V100上以FP16精度和batchsize=1对模型进行测试,以调整YOLOv4和YOLOv4 CSP的设置,以便进行公平的比较。
- 然而,在过去两年中,物体检测学术界的主要进展集中在无锚检测器、高级标签分配策略和端到端(无NMS)检测器。这些还没有集成到YOLO系列中,因为YOLOv4和YOLOv5仍然是基于锚的检测器,具有手工制定的训练分配规则。
- 这就是我们来到这里的原因,通过经验丰富的优化将这些最新进展交付给YOLO系列。考虑到YOLOv4和YOLOv5对于基于锚点的管道可能有点优化过度,我们选择YOLOv3作为我们的起点(我们将YOLOv3 SPP设置为默认YOLOv3)。事实上,由于计算资源有限,在各种实际应用中软件支持不足,YOLOv3仍然是行业中使用最广泛的检测器之一。
- 如下图所示,通过对上述技术的经验更新,我们在COCO上以640×640的分辨率将YOLOv3的AP(YOLOX-DarkNet53)提高到47.3%,大大超过了YOLOv3目前的最佳实践(44.3%AP,ultralytics版本)。此外,当切换到采用高级CSPNet主干和额外的PAN头的高级YOLOv5架构时,YOLOX-L在640×640分辨率的COCO上实现了50.0%的AP,比对应的YOLOv5-L高1.8%的AP。我们还在小尺寸的模型上测试我们的设计策略。YOLOX Tiny和YOLOX Nano(仅0.91M参数和1.08G FLOP)分别比相应的YOLOv4 Tiny和NanoDet3高出10%的AP和1.8%的AP。
-

-
YOLOX和其他最先进的物体探测器的精确模型的速度-精度权衡(顶部)和移动设备上lite模型的尺寸-精度曲线(底部)。
-
- Yolox 将 Anchor free 的方式引入到Yolo系列中,使用anchor free方法有如下好处:降低了计算量,不涉及IoU计算,另外产生的预测框数量也更少:假设 feature map的尺度为 80 × 80 80\times8080×80,anchor based 方法在Feature Map上,每个单元格一般设置三个不同尺寸大小的锚框,因此产生 3 × 80 × 80 = 19200 个预测框。而使用anchor free的方法,则仅产生 80 × 80 = 6400 个预测框,降低了计算量。缓解了正负样本不平衡问题:anchor free方法的预测框只有anchor based方法的1/3,而预测框中大部分是负样本,因此anchor free方法可以减少负样本数,进一步缓解了正负样本不平衡问题。 避免了anchor的调参:anchor based方法的anchor box的尺度是一个超参数,不同的超参设置会影响模型性能,anchor free方法避免了这一点。
- YOLOX 是旷视开源的高性能检测器。旷视的研究者将解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展与 YOLO 进行了巧妙的集成组合,提出了 YOLOX,不仅实现了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。Yolox使用FCOS中的center sampling方法,将目标中心3x3的区域内的像素点都作为 target,这在Yolox论文中称为 multi positives。
YOLOX
YOLOX-DarkNet53
-
我们选择YOLOv3,Darknet53作为我们的基线。在接下来的部分中,我们将逐步介绍YOLOX中的整个系统设计。
-
Implementation details :我们的训练设置从基线到最终模型基本一致。我们在COCO train2017上总共训练了300个epoch的模型,其中5个epoch进行了预热。我们使用随机梯度下降(SGD)进行训练。我们使用 lr×BatchSize/64(线性缩放)的学习率,初始 lr=0.01 和余弦lr调度。重量衰减为0.0005,SGD动量为0.9。默认情况下,对于典型的 8-GPU 设备,批处理大小为128。其他批量大小包括单个GPU训练也可以很好地工作。输入大小从448到832以32步幅均匀绘制。本报告中的FPS和延迟都是在单个特斯拉V100上以FP16精度和批次=1进行测量的。
-
YOLOv3基线,我们的基线采用了DarkNet53主干和SPP层的架构,在一些论文中称为YOLOv3 SPP。与最初的实现相比,我们略微改变了一些训练策略,增加了EMA权重更新、余弦lr调度、IoU损失和IoU感知分支。我们将BCE损失用于训练cls和obj分支,将IoU损失用于训练reg分支。这些通用训练技巧与YOLOX的关键改进正交,因此我们将其放在基线上。此外,我们只进行RandomHorizontalFlip、ColorJitter和多尺度的数据增强,并放弃了RandomResizedCrop策略,因为我们发现RandomResiizedCrop与计划的马赛克增强有点重叠。有了这些增强,我们的基线在COCO val上实现了38.5%的AP,如下表所示。
-

-
YOLOX-Darknet53在COCO上的AP(%)路线图。所有型号都在特斯拉V100上以640×640分辨率、FP16精度和批次=1进行了测试。此表中的延迟和FPS是在不进行后处理的情况下测量的。
-
-
解耦头:在对象检测中,分类和回归任务之间的冲突是一个众所周知的问题。因此,用于分类和定位的解耦头被广泛用于大多数一级和两级检测器。然而,随着YOLO系列的主干和特征金字塔(例如,FPN、PAN)的不断发展,它们的检测头保持耦合,如下图所示。
-

-
YOLOv3 头和所提出的去耦磁头之间的差异说明。对于每一级FPN特征,我们首先采用1×1的conv层将特征通道减少到256,然后添加两个平行分支,每个分支具有两个3×3的conv图层,分别用于分类和回归任务。在回归分支上添加IoU分支。
-
-
我们的两个分析实验表明,耦合的检测头可能会损害性能。1.如下图所示,用解耦的YOLO头代替YOLO头大大提高了收敛速度。2.去耦头对于YOLO的端到端版本至关重要(将在下面进行描述)。
-

-
YOLOv3头和解耦头探测器的训练曲线。我们每10个epoch对COCO上的AP进行一次评估。很明显,解耦头的收敛速度比YOLOv3头快得多,最终达到了更好的效果。
-
-
从下表可以看出,耦合头的端到端特性降低了4.2%AP,而解耦头的端至端特性降低到0.8%。因此,我们将YOLO检测头替换为如上文图所示的轻解耦头。具体来说,它包含一个1×1的对流层以减小通道尺寸,然后是两个平行的分支,分别具有两个3×3的对流层。我们在上文表中报告了V100上批次=1的推理时间,并且lite解耦头带来了额外的1.1ms(11.6ms vs.s.10.5ms)。
-

-
端到端YOLO的解耦头对COCO的影响(以AP(%)表示)。
-
-
强大的数据增强我们将Mosaic和MixUp添加到增强策略中,以提高YOLOX的性能。Mosaic是ultralytics-YOLOv3提出的一种有效的扩增策略。然后它被广泛用于YOLOv4、YOLOv5和其他检测器。MixUp最初是为图像分类任务设计的,但后来在BoF中进行了修改,用于对象检测训练。我们在模型中采用了MixUp和Mosaic实现,并在过去的15个epoch中关闭了它,实现了42.0%的AP。在使用强大的数据增强后,我们发现ImageNet预训练不再有益,因此我们从头开始训练以下所有模型。
-
Anchor-free , YOLOv4和YOLOv5都遵循YOLOv3的原始基于锚的管道。然而,锚机制具有许多已知的问题。首先,为了实现最佳检测性能,需要在训练前进行聚类分析以确定一组最佳锚。这些集群锚点是特定于领域的,并且不太通用。其次,锚机制增加了检测头的复杂性,以及每个图像的预测数量。在一些边缘人工智能系统上,在设备之间移动如此大量的预测(例如,从NPU到CPU)可能会成为整体延迟的潜在瓶颈。
-
无锚探测器[Fcos,Objects as points,Cornernet]在过去两年中发展迅速。这些工作表明,无锚检测器的性能可以与基于锚的检测器不相上下。无锚机制显著减少了需要启发式调整的设计参数的数量和所涉及的许多技巧(例如,锚聚类,网格敏感),以获得良好的性能,使检测器,特别是其训练和解码阶段,变得相当简单。
-
将YOLO切换为无锚方式非常简单。我们将每个位置的预测从3减少到1,并使它们直接预测四个值,即网格左上角的两个偏移,以及预测框的高度和宽度。我们将每个对象的中心位置指定为正样本,并预先定义比例范围,如[Fcos]所述,以指定每个对象的FPN级别。这种修改减少了探测器的参数和GFLOP,使其更快,但获得了更好的性能——42.9%的AP。
-
Multi positives : 为了与YOLOv3的分配规则一致,上述无锚版本仅为每个对象选择一个阳性样本(中心位置),同时忽略其他高质量预测。然而,优化这些高质量的预测也可以带来有益的梯度,这可以缓解训练期间正/负采样的极端不平衡。我们简单地将中心3×3区域分配为阳性,在FCOS中也称为“中心采样”。检测器的性能提高到45.0%AP,已经超过了目前的最佳实践ultralytics-YOLOv3(44.3%AP)。
-
SimOTA,高级标签分配是近年来目标检测的又一重要进展。基于我们自己的研究OTA,我们得出了高级标签分配的四个关键见解:1)loss/quality aware; 2)center prior ;3)每个GT的正锚的动态数目(缩写为动态top-k);4)global view. OTA满足上述四条规则,因此我们选择它作为候选标签分配策略。
-
具体而言,OTA从全局角度分析标签分配,并将分配过程公式化为最优传输(OT)问题,从而在当前分配策略中产生SOTA性能。然而,在实践中,我们发现通过Sinkhorn-Knopp算法解决OT问题会带来25%的额外训练时间,这对于训练300个epoch来说是相当昂贵的。因此,我们将其简化为动态top-k策略,称为SimOTA,以获得近似解。
-
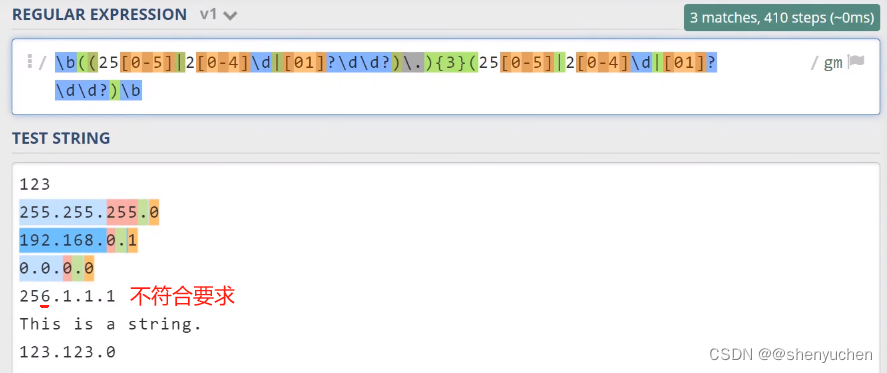
我们在这里简单介绍一下SimOTA。SimOTA首先计算成对匹配度,由每个预测 gt 对的成本或质量表示。例如,在SimOTA中,gt-gi和预测pj之间的成本计算为:
-
c i j = L i j c l s + λ L i j r e g c_{ij}=L^{cls}_{ij}+\lambda L^{reg}_{ij} cij=Lijcls+λLijreg
-
其中λ为平衡系数。 L i j c l s L^{cls}_{ij} Lijcls和 L i j r e g L^{reg}_{ij} Lijreg 是gt gi和预测pj之间的分类损失和回归损失。然后,对于gt-gi,我们选择固定中心区域内成本最小的前k个预测作为其正样本。最后,这些正预测的相应网格被指定为正网格,而其余网格是负网格。注意到,k值因不同的 GT 而变化。有关更多详细信息,请参阅OTA中的动态k估计策略。
-
-
SimOTA不仅减少了训练时间,而且避免了SinkhornKnopp算法中额外的求解器超参数。SimOTA将检测器从45.0%AP提高到47.3%AP,比SOTA ultralytics-YOLOv3高3.0%AP,显示了高级分配策略的威力。
-
端到端YOLO我们按照[Object detection made simpler by eliminating heuristic nms]添加两个额外的conv层、一对一标签分配和停止梯度。这些使检测器能够以端到端的方式执行,但略微降低了性能和推理速度。因此,我们将其作为一个可选模块,不涉及我们的最终模型。
-
进行Loss 计算前,需要将不同特征层的输出预测框映射回原图。因为head关于bbox的输出位置是相对grid的距离,所以映射回原图需要加上grid坐标。宽高尺寸为正数,所以对output的宽高先做指数运算,再乘上stride,得到原图尺度下的宽高。最后将3个特征图上的预测框结果合并,得到所有的预测框结果,输出shape为(1,8400,85)。
-

-
得到预测结果之后,如果是推断,只要输出
output det即可。如果是训练,需要通过函数get_assignments先得到 8400个预测框的target,即标签分配,随后再进行loss计算。
-
-
经过 3个head的输出,一共有8400个预测框,这8400个预测框的标签是什么?这8400个预测框绝大部分是负样本,只有少数是正样本,直接对8400个预测框做精确的标签分配,计算量较大。yolox分配标签过程分为2步:(1) 粗筛选;(2)simOTA 精确分配标签目标检测: 一文读懂 OTA 标签分配_ota标签分配-CSDN博客
-
粗筛选:筛选出潜在包含正样本的预测框,如果
anchor bbox中心落在groundtruth bbox或fixed bbox,则被选中为候选正样本。-
判断 anchor bbox 中心是否在 groundtruth bbox
-
计算groundtruth的左上角、右下角坐标,groundtruth的 gt_bboxes_per_image为:[x_center,y_center,w,h]。
-
判断anchor bbox 中心是否落在groudtruth边框范围内,
-
b_l = x_centers_per_image - gt_bboxes_per_image_l # shape:(3,8400) b_r = gt_bboxes_per_image_r - x_centers_per_image # shape:(3,8400) b_t = y_centers_per_image - gt_bboxes_per_image_t # shape:(3,8400) b_b = gt_bboxes_per_image_b - y_centers_per_image # shape:(3,8400) bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2) # shape:(3,8400,4) is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0 # shape:(3,8400) is_in_boxes_all = is_in_boxes.sum(dim=0) > 0 # shape:(8400,) -
前4行代码计算锚框中心点(x_center,y_center),和标注框左上角(gt_l,gt_t),右下角(gt_r,gt_b)两个角点的相应距离。第5行将四个值叠加之后,通过第六行,判断是否都大于0? 就可以将落在groundtruth矩形范围内的所有anchors,都提取出来了。因为ancor box的中心点,只有落在矩形范围内,这时的b_l,b_r,b_t,b_b都大于0。
-
判断anchor bbox 中心是否在 fixed bbox:以groundtruth的中心点为中心,在特征层尺度上做 5 × 5 的正方形。如果图片的尺寸为 640 × 640 ,且当前特征图的尺度为 80 × 80 ,则此时stride为 8, 将 5 × 5 的正方形映射回原图,fixed bbox 尺寸为 400 × 400 。所以如果 ancor box的中心点落在 fixed bbox范围内,也将被选中。未选中的预测框为负样本,直接打上负样本标签。
-
-
simOTA:经过粗筛选,假设筛选出1000个预测框为潜在正样本,这1000个预测框并不是都作为正样本分配标签,而是需要进一步做标签分配,yolox使用simOTA方法。
-
目标检测的一个底层问题是标签分配问题,比如网络预测10000个检测框,为了训练网络,首先需要知道这10000个检测框的标签是什么?这个问题看似简单,然而实做起来并不容易,比如如何处理模糊标签?正样本数多少为合适?不同的标签分配策略会对模型性能带来很大影响。
-
目标
CNN-based的目标检测器是预测pre-defined anchors的类别 (cls) 以及偏移量 (reg) 。为了训练目标检测器,需要为每个anchor分配cls和reg目标,这个过程称为标签分配或者正采样。一些经典的标签分配方法:RetinaNet、Faster-RCNN: 使用pre-defined anchors与groudtruth 的IoU阈值来区分正负样本;YOLOV5: 为了增加正样本数量,使用pre-defined anchors与groudtruth的 宽高比进行正采样;FCOS:处于groundtruth的中心区域的anchors作为正样本。- 使用人工规则的分配方法,无法考虑尺寸、形状或边界遮挡的差异性。虽然有一些改进工作,如
ATSS动态分配方法,可以为每个目标动态的选择正样本。但是上述方法都一个缺陷:没有全局性的考虑,比如当处理模糊标签时 (一个anchor可能对应多个目标),对其分配任何一个标签都可能对网络学习产生负面影响。OTA就是解决上述问题,以获得全局最优的分配策略。
-
为了得到全局最优的分配策略,
OTA方法提出将标签分配问题当作Optimal Transport(OT) 问题。将每个 gt 当作可以提供一定数量labels的supplier,而每个anchor可以看作是需要唯一label的demander,如果某个anchor从gt那儿获得足够的label,那么这个anchor就是此gt的一个正样本。因为有很多anchor是负样本,所以还需引入另一个backgroundsupplier,专门为anchor提供negative标签,问题目标是supplier如何分配label给demander,可以让cost最低。其中cost的定义为:- 对于每个
anchor-gt pair,cost为pair-wise cls loss和pair-wise reg loss的加权和。 - 对于每个
anchor-background pair,cost为pair-wise cls loss这一项。 
- 对于每个
-
为了便于理解,我们假定图片上有3个目标框,即3个groundtruth,再假定项目有2个检测类别,网络输出1000个预测框,其中只有少部分是正样本,绝大多数是负样本。bboxes_preds_per_image 是候选检测框的信息,维度是 [1000,4]。obj_preds 是目标分数,维度是 [1000,1]。cls_preds 是类别分数,维度是 [1000,2]。
-
OTA方法分配标签是基于cost的,因为有3个目标框和1000个预测框,所以需要生成 3 × 1000 的 cost matrix,对于目标检测任务,cost 组成为位置损失和类别损失,计算方法如下:
-
位置损失:计算3个目标框,和1000个候选框,得到每个框相互之间的 iou pair_wise_ious。再通过
-torch.log计算得到位置损失,即pair_wise_iou_loss,向量维度为 [3,1000]。 -
类别损失:通过第一行代码,将类别的条件概率和目标的先验概率做乘积,得到目标的类别分数。再通过第二行代码,
F.binary_cross_entroy的处理,得到3个目标框和1000个候选框的综合loss值,得到类别损失,即pair_wise_cls_loss,向量维度为 [3,1000]。 -
cls_preds=(cls_preds_.float().unsqueeze(0).repeat(num_gt,1,1).sigmoid_()*obj_preds_.unsqueeze(0).repeat(num_gt,1,1).sigmoid_()) pair_wise_cls_losss=F.binary_cross_entropy(cls_pres_.sqrt_(),gt_cls_per_image,reduction='none').sum(-1) -
有了reg_loss和 cls_loss,将两个损失函数加权相加,就可以得到cost成本函数了。
-
每个 gt 提供多少正样本,可以理解为“这个 gt 需要多少个正样本才能让网络更好的训练收敛”。每个gt 的大小、尺度和遮挡条件不同,所以其提供的positive label数量也应该是不同的,如何确定每个gt的正样本数 k 值呢,论文提供了一个简单的方案,该方法称之为:Dynamic k Estimation,具体做法如下:从前面的pair_wise_ious中,给每个目标框,挑选10个iou最大的候选框。因为前面假定有3个目标,因此这里topk_ious的维度为[3,10]。针对每个目标框,计算所有anchor的 iou 值之和,再经过torch.clamp函数,得到最终右面的dynamic_ks值,给目标框1和3各分配3个候选框,给目标框2分配4个候选框。
-

-
针对每个目标框挑选相应的 cost值最低的一些候选框。比如右面的
matching_matrix中,cost值最低的一些位置,数值为1,其余位置都为0。因为目标框1和3,dynamic_ks值都为3,因此matching_matrix的第一行和第三行,有3个1。而目标框2,dynamic_ks值为4,因此matching_matrix的第二行,有4个1。 -

-
过滤共用的候选框,
matching_matrix种第5列有两个1,这说明第5列所对应的候选框,被目标检测框1和2都进行关联。因此对这两个位置,还要使用cost值进行对比,选择较小的值,再进一步筛选。假设第5列两个位置的值分别为0.4和0.3。最终我们可以得到3个目标框,最合适的一些候选框,即matching_matrix中,所有1所对应的位置。 -

-
anchor_matching_gt = matching_matrix.sum(0) if (anchor_matching_gt > 1).sum() > 0:_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)matching_matrix[:, anchor_matching_gt > 1] *= 0matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1
-
-
-
Other Backbones
-
除了DarkNet53,我们还在不同尺寸的其他主干上测试YOLOX,其中YOLOX相对于所有相应的主干实现了一致的改进。
-
YOLOv5中的改良CSPNet为了进行公平的比较,我们采用了确切的YOLOv5的主干,包括改良的CSPNet、SiLU激活和PAN头。我们还遵循其缩放规则来生产YOLOXS、YOLOX-M、YOLOX-L和YOLOX-X型号。与下表中的YOLOv5相比,我们的模型持续改进了约3.0%至约1.0%的AP,仅增加了边际时间(来自解耦头)。
-

-
YOLOX和YOLOv5在COCO上的AP(%)比较。所有型号都在特斯拉V100上以640×640分辨率、FP16精度和批次=1进行了测试。
-
-
Tiny和Nano探测器,我们进一步将我们的模型缩小为YOLOX-Tiny,以与YOLOv4-Tiny进行比较。对于移动设备,我们采用深度卷积来构建YOLOX-Nano模型,该模型只有0.91M的参数和1.08G的FLOP。如下表所示,YOLOX在比同类产品更小的型号尺寸下表现良好。
-

-
YOLOX-Tiny和YOLOX Nano与对应产品在COCO值上的AP(%)的比较。所有模型都在416×416分辨率下进行了测试。
-
-
模型大小和数据扩充在我们的实验中,所有模型都保持了几乎相同的学习计划和优化参数,如2.1所示。然而,我们发现,合适的增强策略因不同尺寸的模型而异。如下表所示,虽然对YOLOX-L应用MixUp可以将AP提高0.9%,但最好削弱对YOLOX Nano等小型模型的增强。具体而言,当训练小型模型,即YOLOX-S、YOLOX-Tiny和YOLOX-Nano时,我们去除了混合增强并削弱了马赛克(将比例范围从[0.1,2.0]减小到[0.5,1.5])。这样的改性将YOLOX Nano的AP从24.0%提高到25.3%。
-

-
不同模型大小下数据扩充的影响。“比例抖动”表示马赛克图像的比例抖动范围。当采用Copypaste时,将使用来自COCO trainval的实例掩码注释。
-
-
对于大型模型,我们还发现更强的增强更有帮助。事实上,我们的MixUp实现比 [Bag of freebies for training object detection neural networks] 中的原始版本更重。受Copypaste的启发,我们在将两张图像混合之前,通过随机采样的比例因子对其进行抖动处理。为了理解Mixup具有缩放抖动的功能,我们将其与YOLOX-L上的Copypaste进行了比较。注意到Copypaste需要额外的实例掩码注释,而Mixup则不需要。但如上表所示,这两种方法实现了有竞争力的性能,表明当没有实例掩码注释可用时,具有缩放抖动的MixUp是Copypaste的合格替代品。
Comparison with the SOTA
-
传统上显示SOTA比较表,如下表所示。然而,请记住,由于速度随软件和硬件的变化而变化,因此该表中模型的推理速度通常是不受控制的。因此,我们对所有YOLO系列使用相同的硬件和代码库。绘制了稍微受控的速度/精度曲线。
-

-
COCO 2017测试中不同物体探测器的速度和精度的比较。我们选择了在300个epoch上训练的所有模型进行公平比较。
-
-
我们注意到,有一些高性能YOLO系列具有更大的型号尺寸,如Scale-YOLOv4和YOLOv5-P6。基于 Transformer 的检测器将SOTA的精度提高到~60 AP。由于时间和资源的限制,我们没有在本报告中探讨这些重要特征。然而,它们已经在我们的范围内。
1st Place on Streaming Perception Challenge (WAD at CVPR 2021)
- WAD 2021上的流感知挑战是通过最近提出的一个指标对准确性和延迟进行联合评估:流准确性。该度量背后的关键见解是在每个时刻联合评估整个感知堆栈的输出,迫使堆栈考虑在进行计算时应忽略的流数据量。我们发现,在30FPS数据流上,度量的最佳折衷点是推理时间≤33ms的强大模型。因此,我们采用了带有TensorRT的YOLOX-L模型来生产我们的最终模型,以迎接赢得第一名的挑战。有关更多详细信息,请参阅挑战网站 Overview - EvalAI。
Conclusion
- 在本报告中,我们介绍了YOLO系列的一些经验丰富的更新,它形成了一种称为YOLOX的高性能无锚检测器。YOLOX配备了一些最新的先进检测技术,即解耦头、无锚和先进的标签分配策略,在所有型号的情况下,YOLOX在速度和精度之间实现了比其他同类产品更好的平衡。值得注意的是,我们在COCO上将YOLOv3的架构提升到了47.3%的AP,超过了当前的最佳实践3.0%的AP。YOLOv3由于其广泛的兼容性,仍然是行业中使用最广泛的检测器之一。我们希望这份报告能帮助开发人员和研究人员在实际场景中获得更好的体验。