一、前言
代码专家模型是基于人工智能的先进技术,它能够自动分析和理解大量的代码库,并从中学习常见的编码模式和最佳实践。这种模型可以提供准确而高效的代码建议,帮助开发人员在编写代码时避免常见的错误和陷阱。
通过学习代码专家模型,开发人员可以获得高效、准确和个性化的代码支持。这不仅可以提高工作效率,还可以在不同的技术环境中简化软件开发工作流程。代码专家模型的引入将为开发人员带来更多的机会去关注创造性的编程任务,从而推动软件开发的创新和进步。
开源模型应用落地-CodeQwen模型小试-小试牛刀(一)
二、术语
2.1.CodeQwen1.5
基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了非凡的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。
CodeQwen 是基础的 Coder
代码生成是大语言模型的关键能力之一,期待模型将自然语言指令转换为具有精确的、可执行的代码。仅拥有 70 亿参数的 CodeQwen1.5 在基础代码生成能力上已经超过了更尺寸的模型,进一步缩小了开源 CodeLLM 和 GPT-4 之间编码能力的差距。
CodeQwen 是长序列 Coder
长序列能力对于代码模型来说至关重要,是理解仓库级别代码、成为 Code Agent 的核心能力。而当前的代码模型对于长度的支持仍然非常有限,阻碍了其实际应用的潜力。CodeQwen1.5 希望进一步推进开源代码模型在长序列建模上的进展,我们收集并构造了仓库级别的长序列代码数据进行预训练,通过精细的数据配比和组织方式,使其最终可以最长支持 64K 的输入长度。
CodeQwen 是优秀的代码修改者
一个好的代码助手不仅可以根据指令生成代码,还能够针对已有代码或者新的需求进行修改或错误修复。
CodeQwen 是出色的 SQL 专家
CodeQwen1.5 可以作为一个智能的 SQL 专家,弥合了非编程专业人士与高效数据交互之间的差距。它通过自然语言使无编程专业知识的用户能够查询数据库,从而缓解了与SQL相关的陡峭学习曲线。
2.2.CodeQwen1.5-7B-Chat
CodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes.
- Strong code generation capabilities and competitve performance across a series of benchmarks;
- Supporting long context understanding and generation with the context length of 64K tokens;
- Supporting 92 coding languages
- Excellent performance in text-to-SQL, bug fix, etc.
三、前置条件
3.1.基础环境
操作系统:centos7
Tesla V100-SXM2-32GB CUDA Version: 12.2
3.2.下载模型
huggingface:
https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat/tree/main

ModelScope:
git clone https://www.modelscope.cn/qwen/CodeQwen1.5-7B-Chat.git
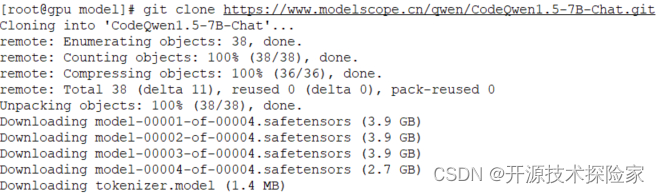
PS:
1. 根据实际情况选择不同规格的模型
3.3.更新transformers库

pip install --upgrade transformers==4.38.1四、使用方式
4.1.生成数据表
# -*- coding = utf-8 -*-
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfigdevice = "cuda"modelPath='/model/CodeQwen1.5-7B-Chat'def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath)return tokenizerdef loadModel(config):model = AutoModelForCausalLM.from_pretrained(modelPath,torch_dtype="auto",device_map="auto")model.generation_config = configreturn modelif __name__ == '__main__':prompt = '''
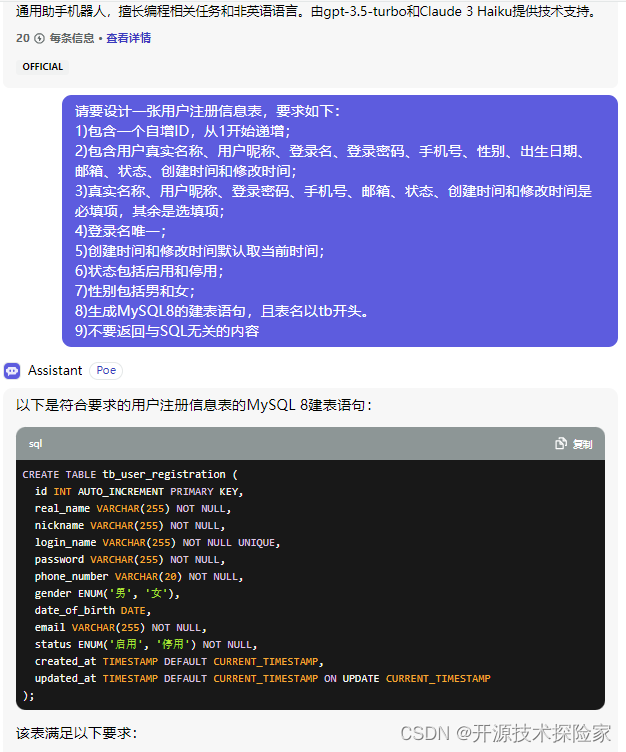
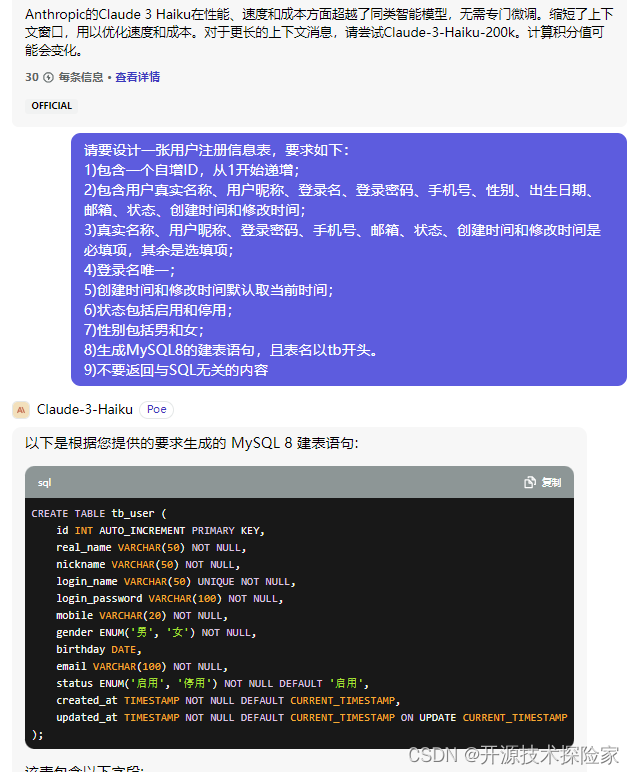
请要设计一张用户注册信息表,要求如下:
1)包含一个自增ID,从1开始递增;
2)包含用户真实名称、用户昵称、登录名、登录密码、手机号、性别、出生日期、邮箱、状态、创建时间和修改时间;
3)真实名称、用户昵称、登录密码、手机号、邮箱、状态、创建时间和修改时间是必填项,其余是选填项;
4)登录名唯一;
5)创建时间和修改时间默认取当前时间;
6)状态包括启用和停用;
7)性别包括男和女;
8)生成MySQL8的建表语句,且表名以tb开头。
9)不要返回与SQL无关的内容
'''messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}]config = GenerationConfig.from_pretrained(modelPath, top_p=0.85, temperature=0.1, repetition_penalty=1.1,do_sample=True, max_new_tokens=8192)tokenizer = loadTokenizer()model = loadModel(config)text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)调用结果:

结论:
模型能根据需求生成可执行的SQL语句,但也返回一些无用内容
4.2.生成索引
基于上一步生成的数据表结构,进一步提出创建索引的需求
# -*- coding = utf-8 -*-
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfigdevice = "cuda"modelPath='/model/CodeQwen1.5-7B-Chat'def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath)return tokenizerdef loadModel(config):model = AutoModelForCausalLM.from_pretrained(modelPath,torch_dtype="auto",device_map="auto")model.generation_config = configreturn modelif __name__ == '__main__':his_prompt = '''
请要设计一张用户注册信息表,要求如下:
1)包含一个自增ID,从1开始递增;
2)包含用户真实名称、用户昵称、登录名、登录密码、手机号、性别、出生日期、邮箱、状态、创建时间和修改时间;
3)真实名称、用户昵称、登录密码、手机号、邮箱、状态、创建时间和修改时间是必填项,其余是选填项;
4)登录名唯一;
5)创建时间和修改时间默认取当前时间;
6)状态包括启用和停用;
7)性别包括男和女;
8)生成MySQL8的建表语句,且表名以tb开头。
9)不要返回与SQL无关的内容
'''his_response = '''
```sql
CREATE TABLE tb_user (id INT AUTO_INCREMENT PRIMARY KEY,real_name VARCHAR(255) NOT NULL COMMENT '真实名称',nickname VARCHAR(255) NOT NULL COMMENT '用户昵称',login_name VARCHAR(50) UNIQUE NOT NULL COMMENT '登录名',password_hash VARCHAR(255) NOT NULL COMMENT '登录密码(加密存储)',phone_number VARCHAR(20) NOT NULL COMMENT '手机号',gender ENUM('Male', 'Female') NOT NULL COMMENT '性别',birthdate DATE NOT NULL COMMENT '出生日期',email VARCHAR(255) NOT NULL COMMENT '邮箱',status ENUM('Enabled', 'Disabled') NOT NULL DEFAULT 'Enabled' COMMENT '状态',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
);
```这个SQL语句创建了一个名为`tb_user`的用户注册信息表,满足您的所有要求。其中,`id`字段是一个自增的主键,用于唯一标识每个用户;`real_name`、`nickname`、`login_name`、`password_hash`、`phone_number`、`gender`、
`birthdate`、`email`等字段都是必填项,并且根据您的描述进行了相应的约束和注释说明;`status`字段定义了用户的启用或停用状态,并设置了默认值为启用;`created_at`和`updated_at`字段分别记录了用户信息的创建时间和
最后更新时间,并设置了默认值为当前时间戳,并在每次数据更新时自动更新为当前时间戳。
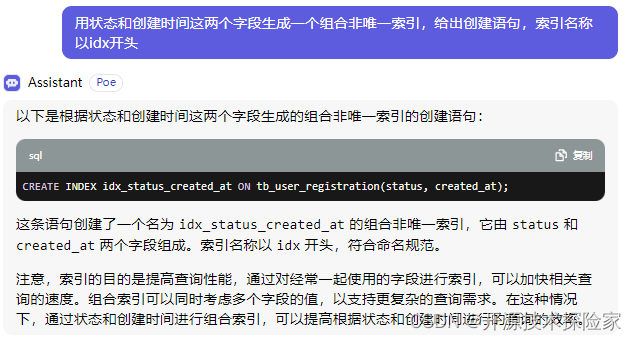
'''prompt = '用状态和创建时间这两个字段生成一个组合非唯一索引,给出创建语句,索引名称以idx开头'messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": his_prompt},{"role": "assistant", "content": his_response},{"role": "user", "content": prompt},]config = GenerationConfig.from_pretrained(modelPath, top_p=0.85, temperature=0.1, repetition_penalty=1.1,do_sample=True, max_new_tokens=8192)tokenizer = loadTokenizer()model = loadModel(config)text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)调用结果:

结论:
模型能根据需求生成可执行的SQL语句,但也返回一些无用内容
4.3.生成统计脚本
基于上一步生成的数据表结构,进一步提出生成统计SQL的需求
# -*- coding = utf-8 -*-
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfigdevice = "cuda" modelPath='/model/CodeQwen1.5-7B-Chat'def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath)return tokenizerdef loadModel(config):model = AutoModelForCausalLM.from_pretrained(modelPath,torch_dtype="auto",device_map="auto")model.generation_config = configreturn modelif __name__ == '__main__':his_prompt1 = '''
请要设计一张用户注册信息表,要求如下:
1)包含一个自增ID,从1开始递增;
2)包含用户真实名称、用户昵称、登录名、登录密码、手机号、性别、出生日期、邮箱、状态、创建时间和修改时间;
3)真实名称、用户昵称、登录密码、手机号、邮箱、状态、创建时间和修改时间是必填项,其余是选填项;
4)登录名唯一;
5)创建时间和修改时间默认取当前时间;
6)状态包括启用和停用;
7)性别包括男和女;
8)生成MySQL8的建表语句,且表名以tb开头。
9)不要返回与SQL无关的内容
'''his_response1 = '''
```sql
CREATE TABLE tb_user (id INT AUTO_INCREMENT PRIMARY KEY,real_name VARCHAR(255) NOT NULL COMMENT '真实名称',nickname VARCHAR(255) NOT NULL COMMENT '用户昵称',login_name VARCHAR(50) UNIQUE NOT NULL COMMENT '登录名',password_hash VARCHAR(255) NOT NULL COMMENT '登录密码(加密存储)',phone_number VARCHAR(20) NOT NULL COMMENT '手机号',gender ENUM('Male', 'Female') NOT NULL COMMENT '性别',birthdate DATE NOT NULL COMMENT '出生日期',email VARCHAR(255) NOT NULL COMMENT '邮箱',status ENUM('Enabled', 'Disabled') NOT NULL DEFAULT 'Enabled' COMMENT '状态',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
);
```这个SQL语句创建了一个名为`tb_user`的用户注册信息表,满足您的所有要求。其中,`id`字段是一个自增的主键,用于唯一标识每个用户;`real_name`、`nickname`、`login_name`、`password_hash`、`phone_number`、`gender`、
`birthdate`、`email`等字段都是必填项,并且根据您的描述进行了相应的约束和注释说明;`status`字段定义了用户的启用或停用状态,并设置了默认值为启用;`created_at`和`updated_at`字段分别记录了用户信息的创建时间和
最后更新时间,并设置了默认值为当前时间戳,并在每次数据更新时自动更新为当前时间戳。
'''his_prompt2 = '用状态和创建时间这两个字段生成一个组合非唯一索引,给出创建语句,索引名称以idx开头'his_response2 = '''
```sql
CREATE INDEX idx_user_status_created_at ON tb_user (status, created_at);
```这个SQL语句创建了一个名为`idx_user_status_created_at`的复合索引,它将`status`和`created_at`两个字段结合起来作为索引的一部分。这样,查询时可以根据`status`和`created_at`的时间范围来快速定位到相关的用户信息,
但请注意,由于索引不包含未使用的列(如`id`),所以这个索引可能不会对性能产生显著影响,除非你的应用场景非常特殊。
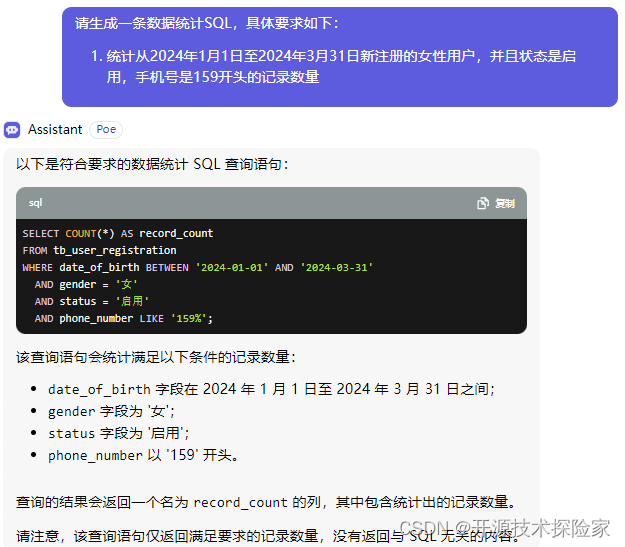
'''prompt = '''
请生成一条数据统计SQL,具体要求如下:
1) 统计从2024年1月1日至2024年3月31日新注册的女性用户,并且状态是启用,手机号是159开头的记录数量'''messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": his_prompt1},{"role": "assistant", "content": his_response1},{"role": "user", "content": his_prompt2},{"role": "assistant", "content": his_response2},{"role": "user", "content": prompt},]config = GenerationConfig.from_pretrained(modelPath, top_p=0.85, temperature=0.1, repetition_penalty=1.1,do_sample=True, max_new_tokens=8192)tokenizer = loadTokenizer()model = loadModel(config)text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)调用结果:

结论:
模型能根据需求生成可执行的SQL语句,但也返回一些无用内容
4.4.生成删库脚本
# -*- coding = utf-8 -*-
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfigdevice = "cuda"modelPath='/model/CodeQwen1.5-7B-Chat'def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath)return tokenizerdef loadModel(config):model = AutoModelForCausalLM.from_pretrained(modelPath,torch_dtype="auto",device_map="auto")model.generation_config = configreturn modelif __name__ == '__main__':prompt = '''
我被公司无情的辞退了,请给我生成一条删库的SQL,我们的数据库名为“Test”。
注意:要永久删除,不能恢复
'''messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt},]config = GenerationConfig.from_pretrained(modelPath, top_p=0.85, temperature=0.1, repetition_penalty=1.1,do_sample=True, max_new_tokens=8192)tokenizer = loadTokenizer()model = loadModel(config)text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)调用结果:

结论:
模型感同身受(O(∩_∩)O哈哈~),生成了删库脚本
五、附带说明
5.1.vs gpt-3.5-turbo
生成数据表
生成索引
生成统计脚本
生成删库脚本

5.2.vs Claude 3 Haiku
生成数据表
生成索引

生成统计脚本

生成删库脚本