集成学习:强化机器学习模型预测性能的利器
- 一、集成学习的核心思想
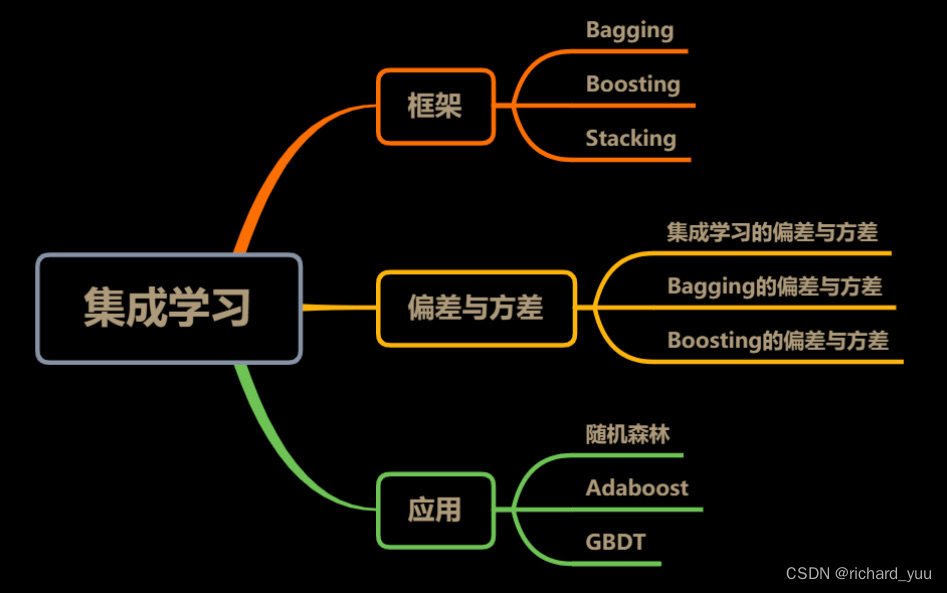
- 二、常用集成学习方法
- Bagging方法
- Boosting方法
- Stacking方法
- 三、集成学习代表模型与实现
- 四、总结与展望
在大数据时代的浪潮下,机器学习模型的应用越来越广泛,而集成学习作为一类重要的模型融合技术,正逐渐成为数据挖掘领域的神器。集成学习通过结合多个学习器的预测结果,不仅提高了整体的预测精度和稳定性,还降低了单一学习器可能存在的过拟合和欠拟合风险。本文将深入探讨集成学习的核心思想,介绍几种常用的集成学习方法,并通过实例和代码展示其在Python中的实现。
一、集成学习的核心思想
集成学习的核心思想在于“集思广益”,通过组合多个基学习器的预测结果,以期望获得比单一学习器更好的性能。这种思想基于一个假设:即使每个基学习器的性能都不是特别出色,但它们的预测结果之间存在一定的差异性和互补性。通过将这些差异性和互补性进行合理的组合,可以有效地提升整体模型的预测精度和泛化能力。
二、常用集成学习方法
Bagging方法
Bagging是一种基于自助采样法的集成学习方法,它通过从原始数据集中随机抽取多个子集,并在每个子集上训练一个基学习器,然后将这些基学习器的预测结果进行平均或投票,得到最终的预测结果。Bagging方法可以有效地减少模型的方差,提高模型的稳定性。
Boosting方法
Boosting是一种通过串行训练多个基学习器,并根据每个基学习器的性能调整其在最终预测中的权重,以实现性能提升的集成学习方法。Boosting方法的典型代表有Adaboost和Gradient Boosting Decision Tree(GBDT)。与Bagging不同,Boosting更加注重基学习器之间的顺序性和依赖性。
Stacking方法
Stacking是一种更为高级的集成学习方法,它将多个基学习器的预测结果作为新的特征,然后训练一个元学习器对这些特征进行再次学习,以得到最终的预测结果。Stacking方法可以利用基学习器之间的互补性,进一步提升模型的泛化能力。
三、集成学习代表模型与实现
随机森林
随机森林是集成学习中非常具有代表性的一个模型,它结合了Bagging和决策树的思想。在随机森林中,每个基学习器都是一棵决策树,通过自助采样法构建多个训练子集,并在每个子集上训练一棵决策树。最终,将多棵决策树的预测结果进行平均或投票,得到随机森林的预测结果。
以下是使用Python中的Scikit-learn库实现随机森林算法的代码示例:
pythonfrom sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器
rf = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf.predict(X_test)# 输出模型准确率
print("Model accuracy:", rf.score(X_test, y_test))
在上述代码中,我们首先加载了鸢尾花数据集,并将其划分为训练集和测试集。然后,我们创建了一个随机森林分类器,并设置了基学习器的数量为100。接着,我们使用训练集对模型进行训练,并在测试集上进行预测。最后,我们输出了模型的准确率。
四、总结与展望
集成学习作为一种多模型融合的思想,在机器学习领域具有广泛的应用前景。通过结合多个基学习器的预测结果,集成学习可以有效地提高模型的预测精度和稳定性,降低过拟合和欠拟合的风险。未来,随着数据量的不断增长和模型复杂度的提升,集成学习将继续发挥其独特优势,成为机器学习领域的重要发展方向之一。