MySQL允许在 UPDATE 语句中,使用 LIMIT 子句来限制更新的记录数。如:UPDATE my_user SET pwd ='new_password'WHERE name LIKE'张%'LIMIT1;这条语句,将只更新 name 列以"张"开头的第一条记录的pwd列的值。
注意
1、WHERE 子句是 UPDATE 语句中非常重要的部分,因为它决定了哪些记录会被更新,如果,没有正确地指定 WHERE 子句,或者,完全省略了它,那么,所有的记录都会被更新,这是一个严重的bug。2、始终确保 SET 子句中的列名和值,与数据库中的实际情况相匹配。
删除
语法
语法:DELETEFROM 表名 WHERE 条件;解释:DELETEFROM:表示要从哪个表中删除记录WHERE:这是一个可选的子句,用于指定哪些记录应该被删除,如果省略 WHERE 子句,将删除表中的所有记录举例:删除"my_user"表中,名为"张三"的用户记录,DELETEFROM my_user WHERE name ='张三';
1、内连接,会返回,两个表中满足连接条件的行。2、内连接,通过'在ON子句中指定连接条件',来将两个表中的行连接起来,只有当连接条件满足时,内连接才会返回匹配的行,如果某个表中的行,在另一个表中没有匹配的行,则这些行不会出现在内连接的结果中。语法:SELECT*FROM TableAINNERJOIN TableBON TableA.column_name = TableB.column_name;-- column_name:列名举例:Students表:| student_id | student_name | course_id ||------------|--------------|-----------||1| Alice |101||2| Bob |102||3| Charlie |103|Courses表:| course_id | course_name ||-----------|-------------||101| Math ||102| Science ||104| History |通过内连接,查询学生的姓名和所选课程的名称:select Students.student_name, Courses.course_namefrom Studentsinnerjoin Courseson Students.course_id = Courses.course_id执行结果为:| student_name | course_name ||--------------|-------------|| Alice | Math || Bob | Science |
join-左连接
1、左连接(LeftJoin),它会返回,左表中的所有行,以及右表中满足连接条件的行,如果右表中没有匹配的行,那么结果集中将会包含 NULL 值。2、左连接,常用于,需要保留左表中所有行的情况,即使,右表中没有匹配的行也要显示左表中的数据语法:SELECT*FROM TableALEFTJOIN TableBON TableA.column_name = TableB.column_name;'LEFT JOIN'表示进行左连接操作,'ON TableA.column_name = TableB.column_name'表示连接条件,左连接,将返回左表TableA中的所有行,以及右表TableB中满足连接条件的行,如果,右表中没有匹配的行,对应的列将会显示 NULL 值。举例:Employees表:| employee_id | employee_name | department_id ||-------------|---------------|--------------||1| Alice |101||2| Bob |102||3| Charlie |103||4| David |102|Departments表:| department_id | department_name ||---------------|-----------------||101| HR ||102| Marketing ||104| Finance |通过,左连接,查询员工的姓名和所属部门的名称:select Employees.employee_name, Departments.department_namefrom Employeesleftjoin Departmentson Employees.department_id = Departments.department_id执行结果为:| employee_name | department_name ||---------------|-----------------|| Alice | HR || Bob | Marketing || Charlie |NULL|| David | Marketing |解释:Alice属于HR部门,Bob和David都属于Marketing部门,而,Charlie的部门在Departments表中找不到对应的记录,因此在左连接的结果中显示为NULL,左连接操作保留了Employees表中的所有员工信息,并将其与Departments表中匹配的部门信息进行连接。
join-右连接
1、右连接(RightJoin),它会返回右表中的所有行,以及左表中满足连接条件的行,如果,左表中没有匹配的行,那么结果集中将会包含 NULL 值。2、右连接与左连接相反,右连接,用于需要保留右表中所有数据的情况,即使,左表中没有匹配的数据也要显示右表中的数据语法:SELECT*FROM TableARIGHTJOIN TableBON TableA.column_name = TableB.column_name;'RIGHT JOIN'表示进行右连接操作,'ON TableA.column_name = TableB.column_name'表示连接条件。举例:Students表:| student_id | student_name | course_id ||------------|--------------|-----------||1| Alice |101||2| Bob |102||3| Charlie |103||4| David |NULL|Courses表:| course_id | course_name ||-----------|-------------||101| Math ||102| English ||104| History |通过,右连接,查询学生的姓名和所选课程的名称:select Students.student_name, Courses.course_namefrom Studentsrightjoin Courseson Students.course_id = Courses.course_id执行结果为:| student_name | course_name ||--------------|-------------|| Alice | Math || Bob | English || Charlie |NULL||NULL| History |解释:Alice选择了Math课程,Bob选择了English课程,Charlie的课程在Courses表中找不到对应的记录,而,David在Students表中的course_id为NULL,因此,在右连接的结果中显示为NULL,右连接操作保留了Courses表中的所有课程信息,并将其与Students表中匹配的学生信息进行连接
join-全连接
1、全连接(FullJoin),它会返回,左表和右表中的所有行,同时,将满足连接条件的行,进行连接,如果,某个表中没有匹配的行,对应的列将会显示 NULL 值。2、全连接,会返回左表和右表中的所有数据,无论是否有匹配的行,如果,左表或右表中的某些行,在另一张表中没有匹配的行,那么对应的列将会显示 NULL 值。语法:SELECT*FROM TableAFULLJOIN TableBON TableA.column_name = TableB.column_name;'FULL JOIN'表示进行全连接操作,'ON TableA.column_name = TableB.column_name'表示连接条件,全连接,将返回左表TableA和右表TableB中的所有行,并将满足连接条件的行进行连接,如果,某个表中没有匹配的行,对应的列将会显示 NULL 值。举例:Employees表:| employee_id | employee_name | department_id ||-------------|---------------|---------------||1| Alice |101||2| Bob |102||3| Charlie |103||4| David |NULL|Departments表:| department_id | department_name ||---------------|-----------------||101| HR ||102| Finance ||104| Marketing |通过全连接,查询员工的姓名和所属部门的名称,即使有些员工的部门在Departments表中找不到对应的记录,或者有些部门没有员工。select Employees.employee_name, Departments.department_namefrom Employeesfulljoin Departmentson Employees.department_id = Departments.department_id执行结果:| employee_name | department_name ||---------------|-----------------|| Alice | HR || Bob | Finance || Charlie |NULL|| David |NULL||NULL| Marketing |解释:Alice属于HR部门,Bob属于Finance部门,Charlie和David的部门,在Departments表中找不到对应的记录,而,Marketing部门没有员工,全连接操作,保留了Employees表 和 Departments表中的所有数据,并将其进行连接。
子查询
1、子查询是指,在'SQL查询语句中嵌套另一个查询',内部查询的结果,作为外部查询的条件之一,子查询可以用于过滤数据、进行计算、比较值等各种操作。举例:Employees表:| employee_id | employee_name | department_id | salary ||-------------|---------------|---------------|--------||1| Alice |101|60000||2| Bob |102|70000||3| Charlie |101|55000||4| David |103|75000|Departments表:| department_id | department_name ||---------------|-----------------||101| Sales ||102| Marketing ||103| Finance |查询每个部门的平均工资,并找出,工资高于部门平均工资的员工select Employees.salary, Employees.employee_name, Departments.department_namefrom Employees ejoin Departments don e.department_id = d.department_idwhere e.salary >(selectAVG(salary)from Employees e2where e2.department_id = e.department_id)| salary | employee_name | department_name ||--------|---------------|------------- --||60000| Alice | Sales ||70000| Bob | Marketing |
例子
学生表Students:| student_id | student_name | age ||------------|--------------|-----------||1| Alice |20||2| Bob |21||3| Charlie |19|成绩表Scores:| student_id | subject | score ||------------|--------------|-----------||1| Math |85||1| Science |90||2| Math |75||2| Science |80||3| Math |95||3| Science |88|找出每个学生的平均分,并列出高于平均分的学生及其成绩:select Students.student_id, Students.student_name, Scores.subject, Scores.scorefrom Students stujoin Scores son stu.student_id = s.student_idwhere Scores.score >(selectAVG(score)from Scoreswhere student_id = s.student_id)
在数字化时代,条形码的应用越来越广泛。iBarcoder for Mac作为一款专业的条形码生成软件,为用户提供了一站式的解决方案。无论是零售、出版还是物流等行业,iBarcoder都能轻松应对,助力用户实现高效管理。 iBarcoder for Mac v3.14…
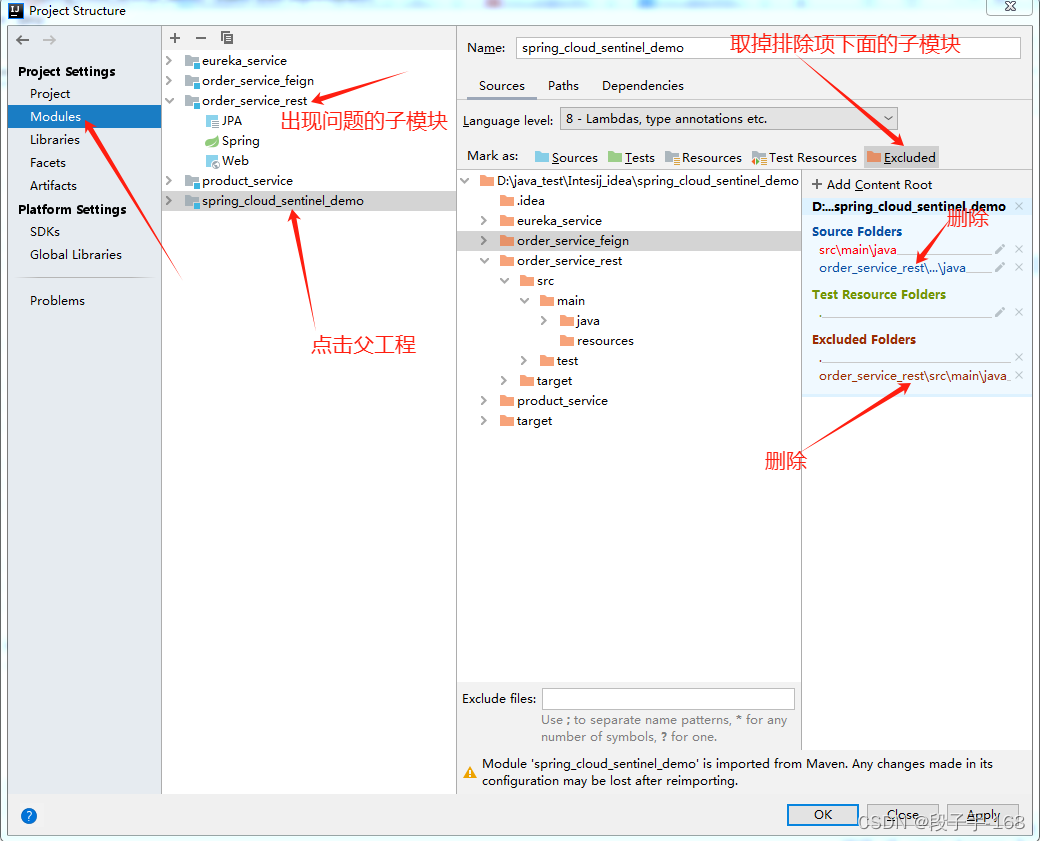
IDEA 多模块项目报错 Cannot Save Settings 问题
Cannot Save Settings:
Module "spring_cloud_sentinel_demo"
must not contain source root "D:\java_test\Intesij_idea\spring_cloud_sentinel_demo\order_service_rest\src\main\resources"…