Esko Ukkonen: On-line Construction of Suffix Trees
文章目录
- Esko Ukkonen: On-line Construction of Suffix Trees
- 一、后缀树的概念及应用【详见刘方州同学报告】
- 1.1 字典树 Trie
- 1.2 后缀树 Suffix Tree
- 2 后缀树的应用
- 二、朴素后缀树构造方法及问题
- 三、线性时间内后缀树在线构造方法
- 3.1 概念引入
- (1)隐式后缀树 Implicit Suffix Tree
- (2)终止符 $
- (3)活动点active point、剩余后缀数 remainder
- (4)后缀链接 Suffix Link
- 3.2 过程演示
- Rule 1(活动点更新规则1)
- Rule 2(后缀链接创建规则)
- Rule 3(活动点更新规则2)
- 3.3 复杂度分析
一、后缀树的概念及应用【详见刘方州同学报告】
1.1 字典树 Trie
定义:字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。
用途:用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
优点:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
核心思想:空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
基本性质:
(1)根节点不包含字符,除根节点外每一个节点都只包含一个字符。
(2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
(3)每个节点的所有子节点包含的字符都不相同。
1.2 后缀树 Suffix Tree
后缀树是一种数据结构,能快速解决很多关于字符串的问题。后缀树的概念最早由Weiner于1973年提出,既而由McCreight在1976年和Ukkonen在1992年和1995年加以改进完善。
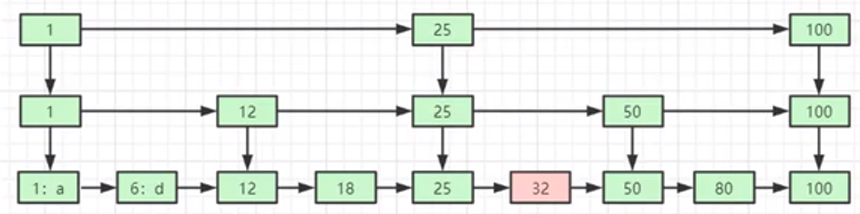
给定一长度为n的字符串T=T_1 T_2 〖…T〗n和整数i (1<=i<=n),子串T_i T(i+1) 〖…T〗_n便都是字符串T的后缀。以字符串T=abcabxabcd为例,它的长度为10,所以abcabxabcd、bcabxabcd、cabxabcd、…、d都是T的后缀。规定空字串也是后缀。后缀树,就是包含一则字符串所有后缀的压缩字典树,压缩过程如图1所示。把abcabxabcd的所有后缀加入字典树并压缩后,我们得到如图2的后缀树。
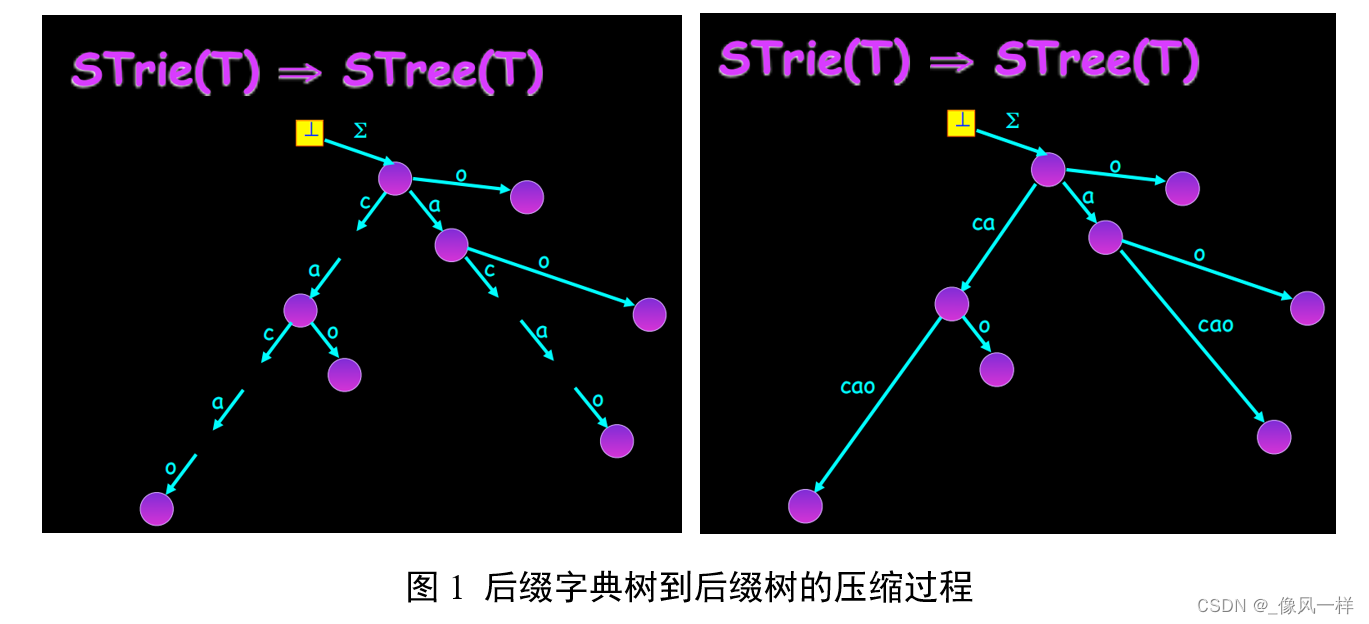
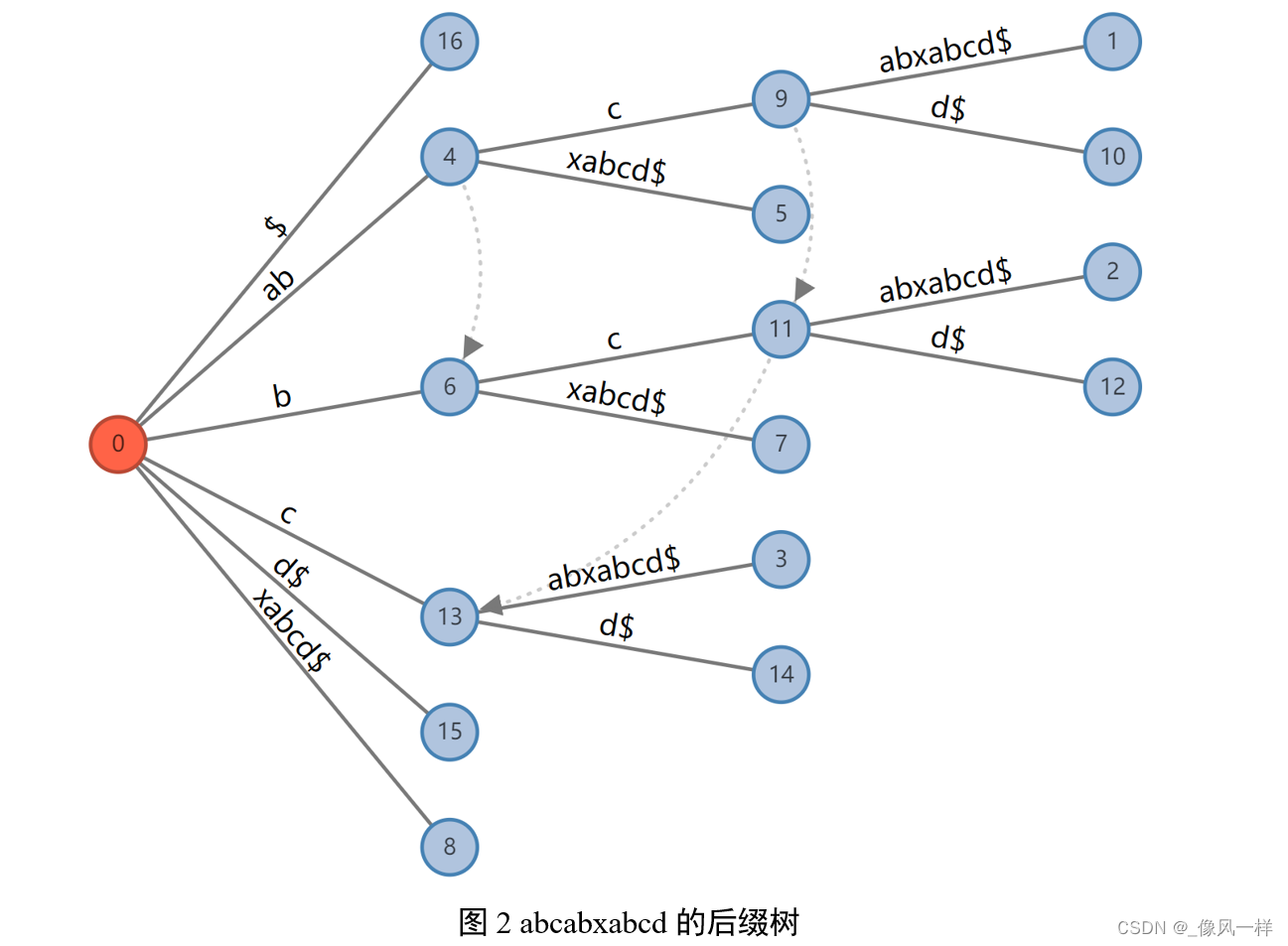
如图2所示,Suffix Tree与Trie的不同在于边不再只代表单个字符,而是每个边可以表示任意的长度,实操过程中用两个指针[from, to]实现,耗费O(1)的空间。
2 后缀树的应用
2.1 最长重复子串
2.2 最长公共子串
2.3 最长回文子串
二、朴素后缀树构造方法及问题
略
三、线性时间内后缀树在线构造方法
McCreight最初的构造法原则上要按逆序构造,也就是说字符要从末端开始插入。如此一来便不能作为在线算法, 它变得更加难以应用于实际问题,如数据压缩。
20年后,来自赫尔辛基理工大学的Esko Ukkonen把原算法作了一些改动,实现了线性时间内对字符串从左往右的后缀树在线构造方法。
对于所给的文本T,由一棵空树开始逐步构造T的后缀树。以abcabxabcd为例,先由a开始,接着是ab,然后abc,…,不断更新直到构造出abcabxabcd的后缀树。
3.1 概念引入
(1)隐式后缀树 Implicit Suffix Tree
按上述方法在线构造abcabxabcd的后缀树的过程中,我们必然会构造出字符串abcab的后缀树,对其所有后缀枚举如下:abcab、bcab、cab、ab、b。观察发现:后缀ab被包含在abcab中作为其前缀;后缀b被包含在bcab中作为其前缀。
如果为ab或b单独开辟新的分支,则不符合字典树的性质,即每个节点的所有子节点包含的字符都不相同。因此我们选择暂时认为ab、b隐式包含在已有分支里,这样构造出来的后缀树称为隐式后缀树。
在我看来,隐式后缀树是在扫描和构建过程中节省时间的一步操作。因为字符串尚未扫描结束,所以这些操作可以先记录着而暂时不去执行,其代价是需要引入接下来要提及的活动点和剩余后缀数。
(2)终止符 $
问题:如何确定查找后缀树得到的子串是一个后缀还是后缀的一部分?
解决:在文本后添加字母表以外的字符,比如 。这样,当查找到 a b 。这样,当查找到ab 。这样,当查找到ab或b 就说明这是一个后缀,避免了二义性。对 a b c a b 就说明这是一个后缀,避免了二义性。对abcab 就说明这是一个后缀,避免了二义性。对abcab的所有后缀重新枚举如下:xabxa 、 a b x a 、abxa 、abxa、bxa 、 x a 、xa 、xa、a 、 、 、。观察发现:xa 不再是 x a b x a 不再是xabxa 不再是xabxa的前缀;a 不再是 b c a b 不再是bcab 不再是bcab的前缀。
(3)活动点active point、剩余后缀数 remainder
问题:我们提到了隐式后缀树,隐式什么时候变为显式?怎么变为显式?
比喻:隐式就像瘦子躲在胖子后面,瘦子露出马脚的时候就是变为显式的时候。
举例:以最终构建abcabx为例。第一阶段,我们从左到右在线构建abc的后缀树,如图3所示。
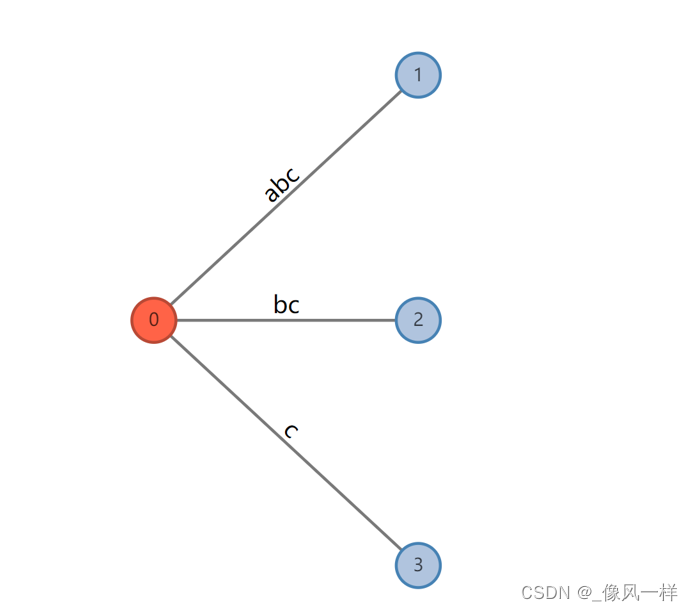
图3 abc的后缀树
第二阶段,我们需要构建abcab的后缀树,如图4所示。新增字符a新增字符b的情况下,不必大刀阔斧改变树的结构,只要悄悄在每条边后面追加a追加b即可。枚举abcab的后缀集合:abcab、bcab、cab、ab、b。观察发现,abcab、bcab、cab即为三条边,而ab、b隐式地包含其中。
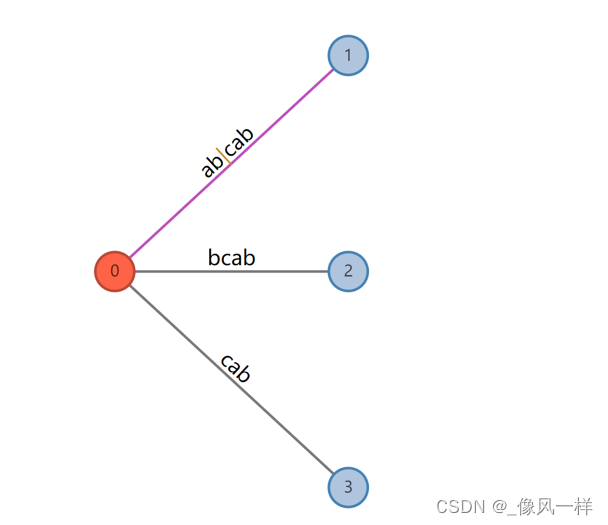
图4 abcab的后缀树
第三阶段,我们需要构建abcabx的后缀树。新增字符x,x就是露出的马脚,因为已有的后缀树的边里没有包含abx的。露出马脚之时就是变为显式之日,通过裂变出新的边变为显式,如图5所示。
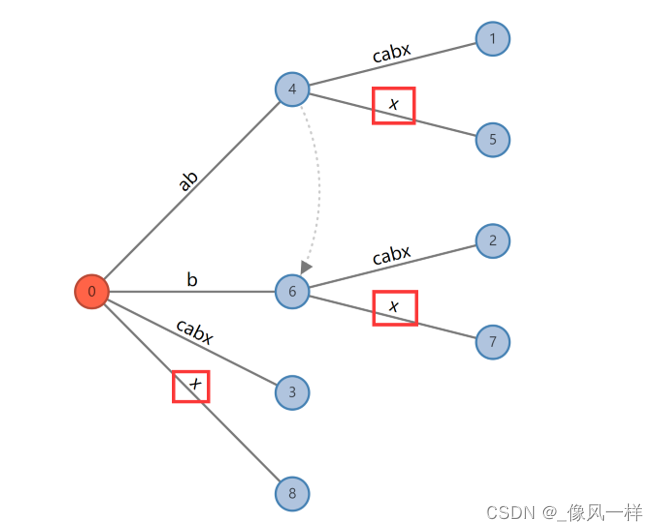
图5 abcabx的后缀树
问题:如何确定裂变的位置?
解决:引入活动点active point,用于确定裂变的位置。活动点active point是一个包括(active_node, active_edge, active_length)的三元组。该三元组在每次后缀树的搜索中更新。
根据active_node确定结点,根据active_edge确定结点的某一条边,根据active_length确定边上的某个位置。举例来说,如图6所示,active_node为0,即根节点,active_edge为a,即从根节点出发、字符为a的这条边,active_length为2,即该边索引为2的地方,即符号|所在位置。
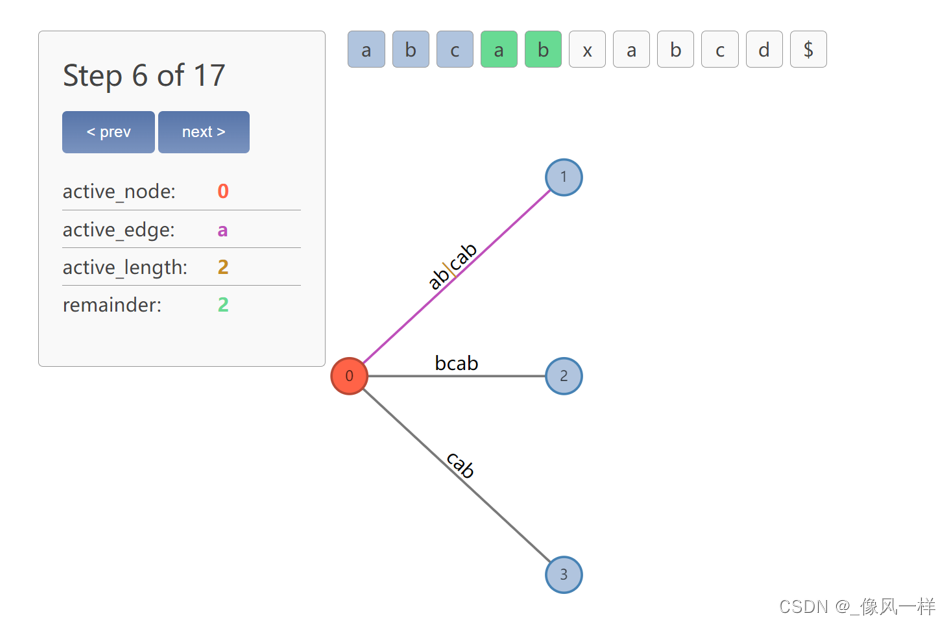
图6 active point的含义解释
问题:裂变具体怎么做?
解决:如图7所示,以abcab->abcabx为例,裂变时进行以下操作:
① 根据活动点确定裂变位置(ab|cab),在|处添加节点。
② 在新增的节点后分裂出一个边为x的节点。
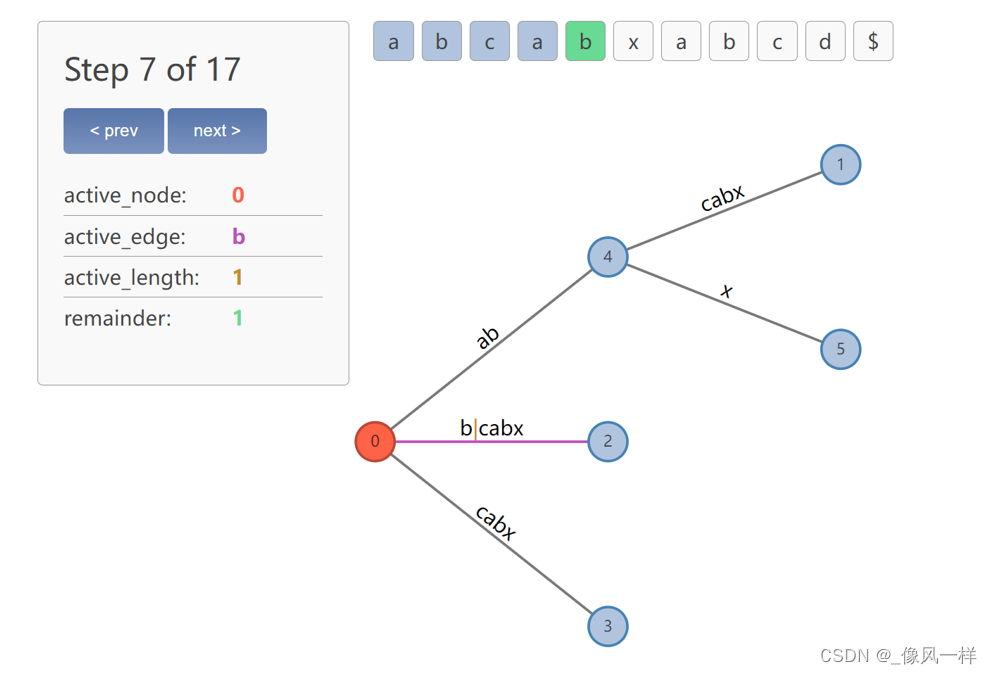
图7 裂变的过程
至此由于添加abx后缀引发的裂变完成。
问题:只裂变一次就够了吗?
思考:未必够。以abcab到abcabx为例,abcab的后缀树表示如图8所示。

图8 abcab的后缀树
已知abcabx的后缀集合:abcabx、bcabx、cabx、abx、bx、x。
如果仅在已有的边后面添加x,只能覆盖abcabx、bcabx、cabx,剩下abx、bx、x。由于每次裂变能得到1个新后缀,直觉上来说需要进行3次裂变,事实上也是如此。上述过程只完成了添加abx后缀引发的裂变。
解决:引入剩余后缀数remainder,表示还需要插入多少个新的后缀,即还需要裂变几次。remainder=0时,表示当前新增字符处理完毕,继续扩展下一字符。
(4)后缀链接 Suffix Link
根据上述问题思考已经明确了两个事实:
① 活动点active point指向要裂变的位置。
② 要裂变的位置可能不止一个。
问题:每次都重新从根节点搜索下一裂变处吗?
解决:不需要。引入后缀链接Suffix Link,用于快速找到下一裂变处。
问题:后缀链接怎么创建?
规则:每进行一次裂变,会新增非叶节点和新边。后缀链接从该新增的非叶节点出发,指向下一次裂变新增的非叶节点,用虚线连接。
问题:为什么后缀链接可以快速找到下一裂变处?
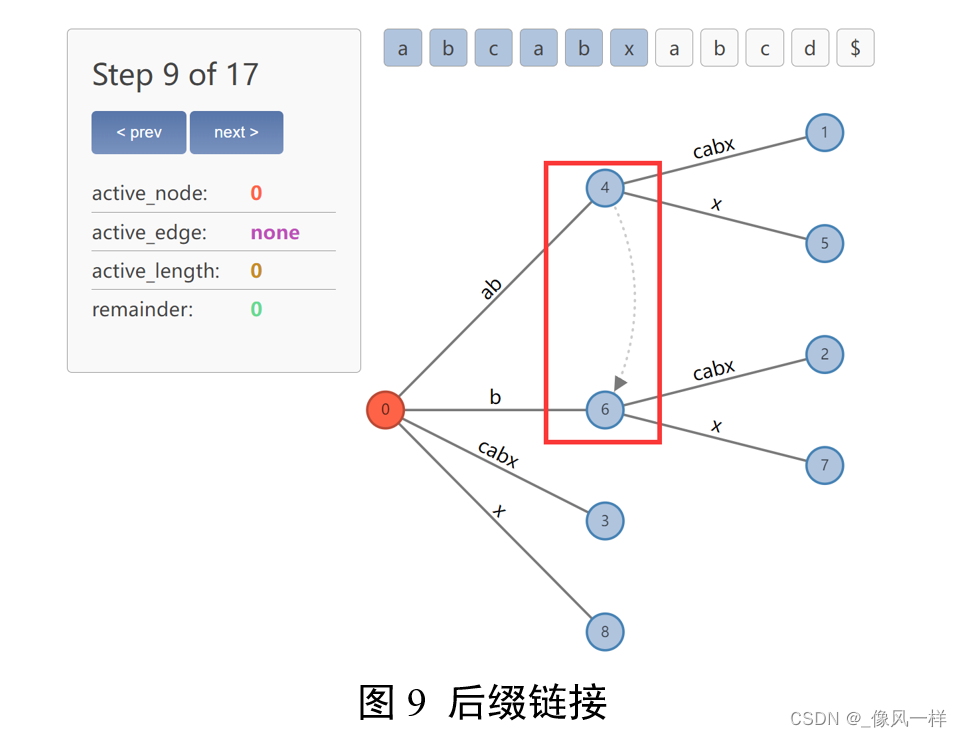
观察:后缀链接连接的节点存在的关系:如果有一个从A指向B的后缀链接,那么从根节点到A节点表示的子串剔除第首个字符后得到的即为从根节点到B节点表示的子串。
举例:图9中节点4表示字符串ab,节点6表示字符串b,ab剔除掉首个字符a后得到b。实际处理时,每一次裂变意味着一个待添加后缀的成功插入(abx),下一次裂变的工作就是插入下一个待添加后缀(bx),下一个待添加后缀(bx)与当前成功插入的后缀(abx)的关系也是这样。
好处:可以方便地从一个后缀跳到另一个后缀,降低算法的时间复杂度。
3.2 过程演示
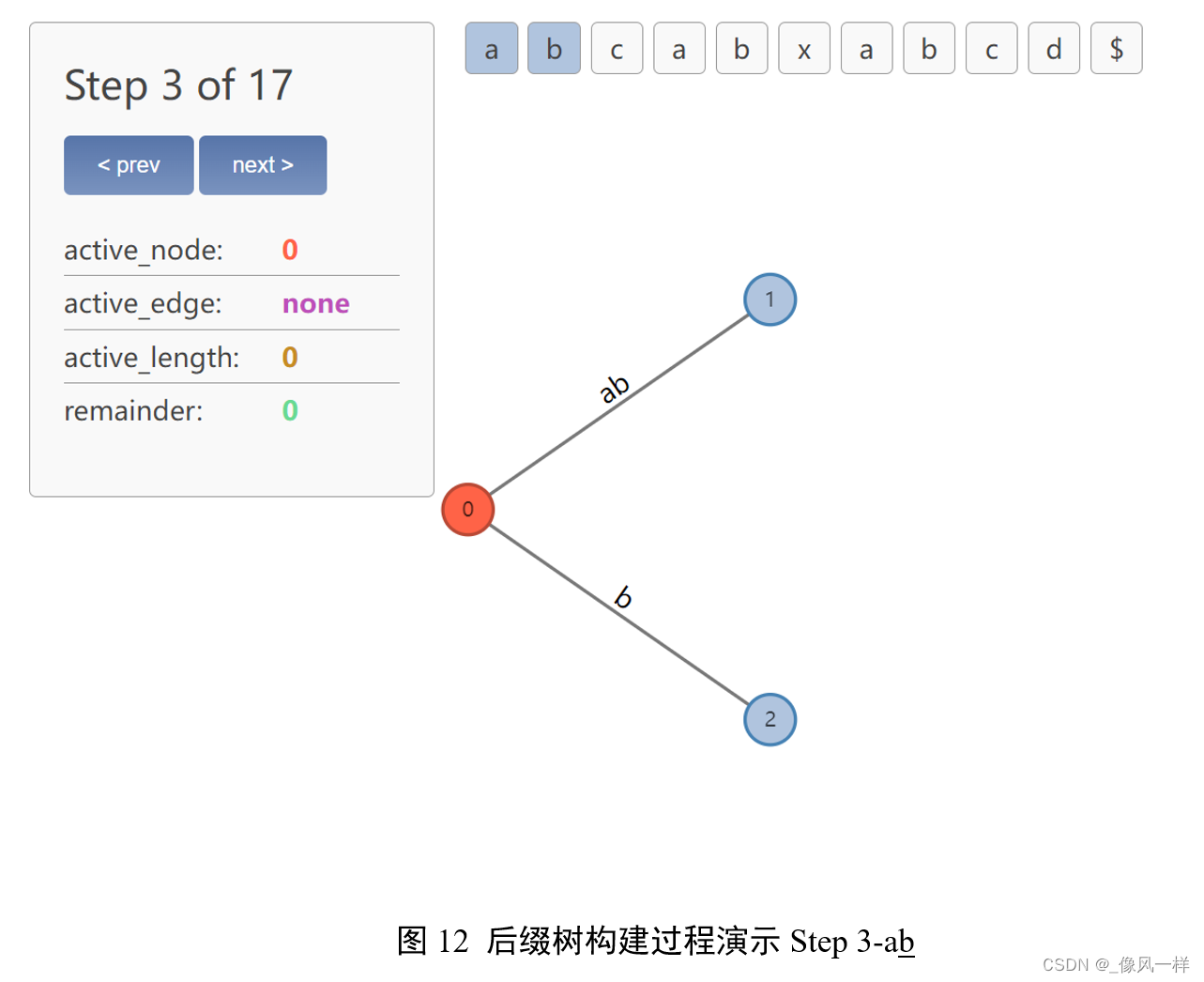

注意到已经存在的第一条边前缀中隐式包含了a。隐式包含在实操过程中的做法就是更新活动点active point和剩余后缀数remainder。
单就后缀树而言,这颗后缀树没有准确地描述当前读到的字符串abca。如何保证最后扫描结束的时候后缀树可以准确表示呢?回扣前文终结符的引入:在遇到 并做完相应操作后,后缀树可以准确地描述 a b c a 并做完相应操作后,后缀树可以准确地描述abca 并做完相应操作后,后缀树可以准确地描述abca。
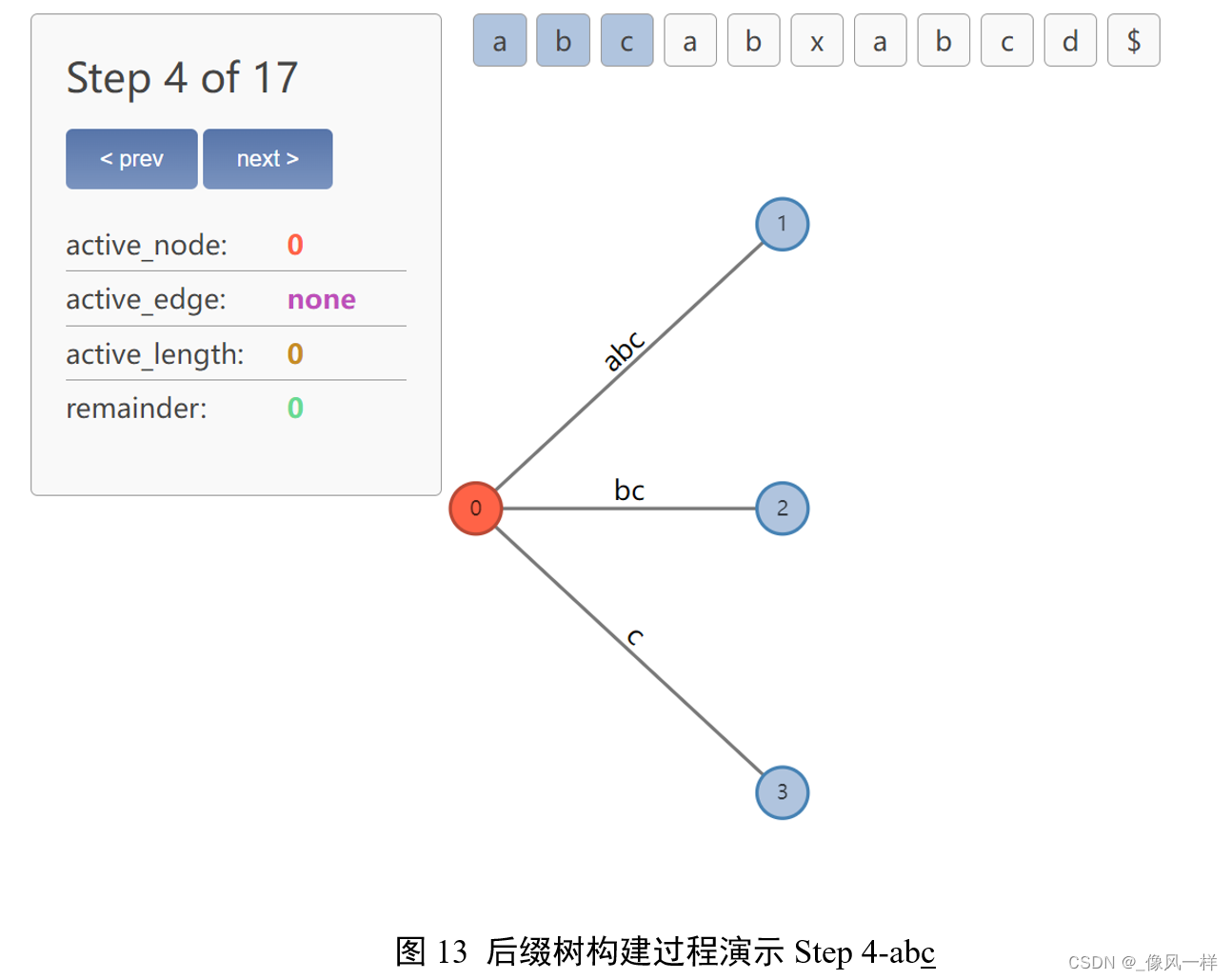
更新active point:a后面有b,length+1,往后挪;还在同一条边上,node和edge不变;
更新remainder+1=2:表示需要插入两个后缀ab、b。
问题:为什么remainder+1?
因为上一步的a实际上没有被插入树中,所以它被remain了下来,而后我们又继续处理b了,所以上一步没插入的a延长成了ab。加入的1即需要插入新的后缀b。
问题:再看active point和remainder记录信息似乎是缺失的:记录了后缀ab即将添加的位置,记录了2个待添加后缀,却没有记录b即将添加的位置?为什么呢?
先说结论:“既然第一条边有ab|cab,那在第一条边后面(也就是第二条第三条边里)一定存在去掉a以b开头的后缀”。
再详细解释:回顾一下这里第二条边是如何产生的?正是因为后缀树的逐步构建过程中a后接了b,所以我们先在第一条边的a追加成ab,再为b开辟新的边,即第二条边,所以这个第二条边就是显然的以b开头的后缀。换句话说,即使a后面不是紧跟的b,而是紧跟的是个x,那也会新开一条边以x开头的。
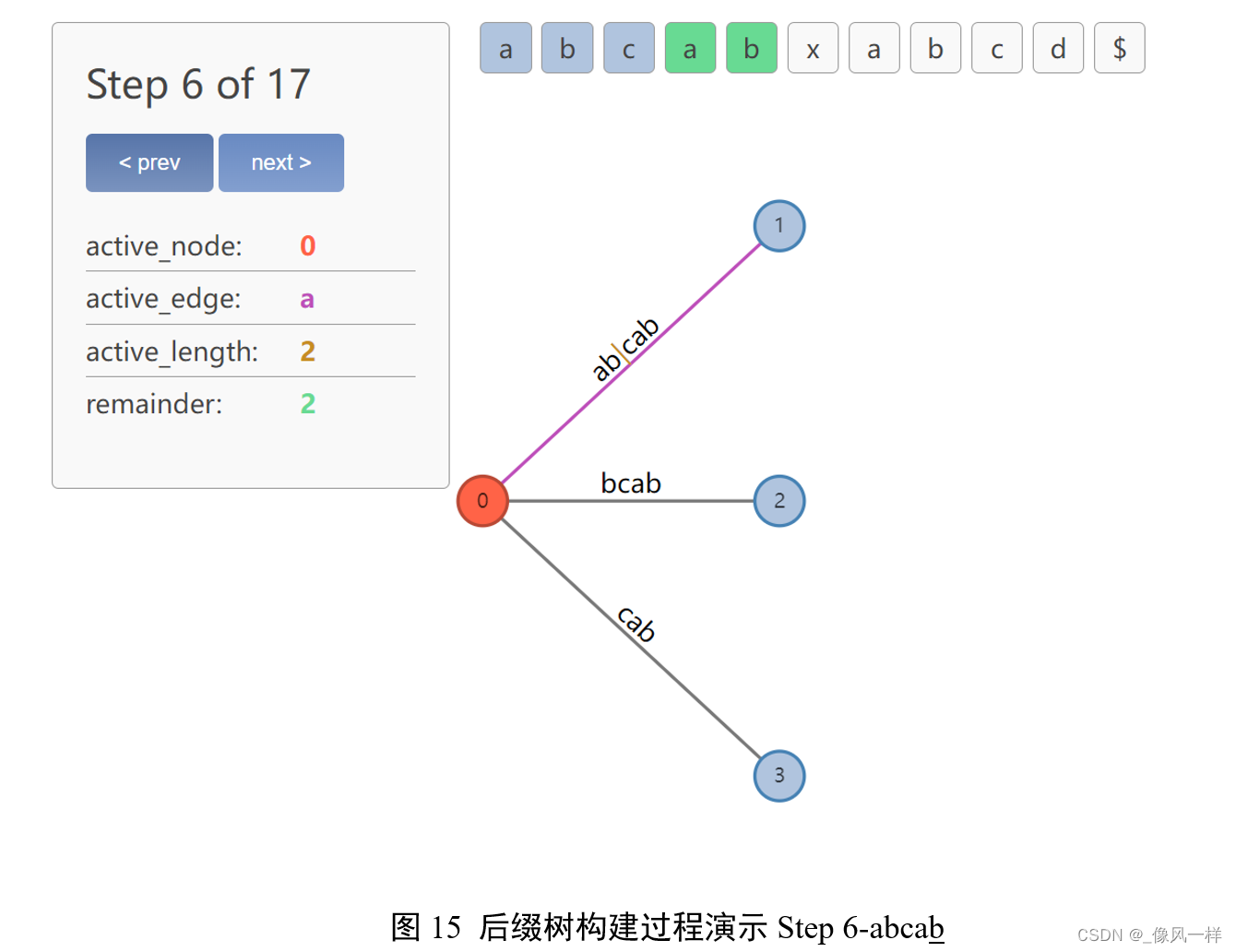
remainder=3,表示有3个待添加的后缀:abx、bx、x
我们按之前的逻辑来试图更新active point:ab之后找x,找不到!因此在裂变位置添加新的节点4、新的边x。这一步完成了后缀abx的添加。但是active point怎么更新呢?
Rule 1(活动点更新规则1)
当active_node = root 时遵循:
active_node 保持为 root;
active_edge 被设置为即将被插入的新后缀的首字符;
active_length 减1;
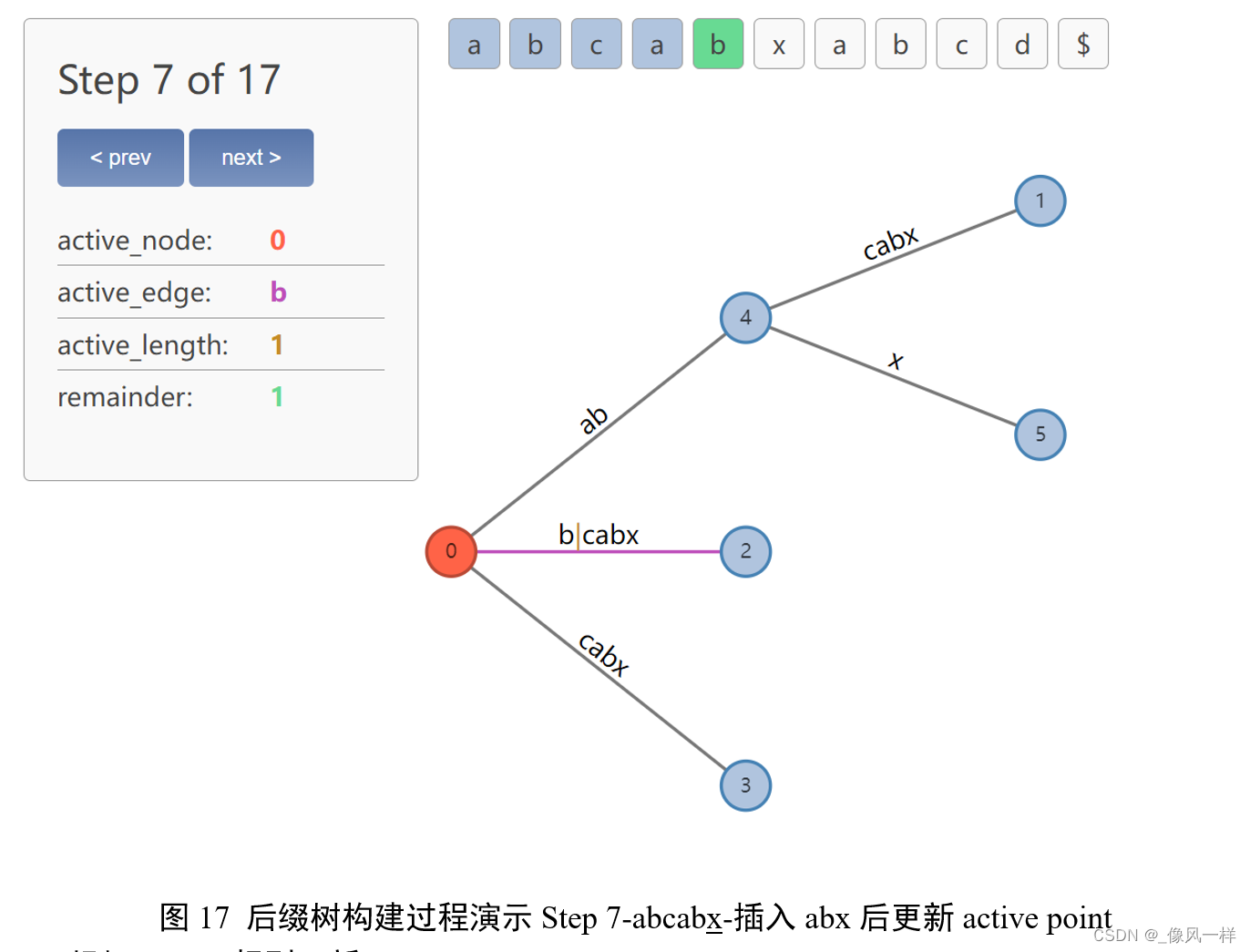
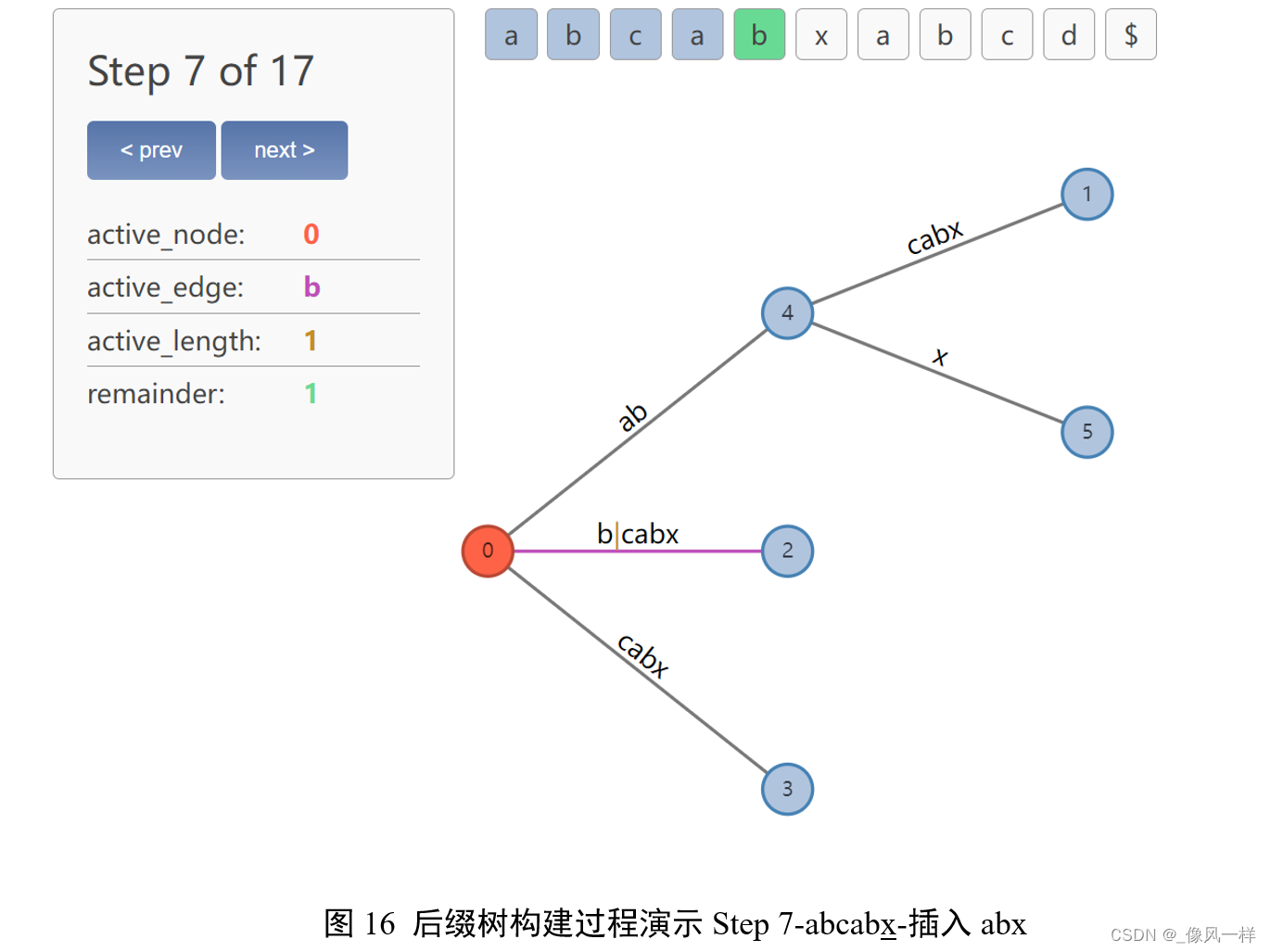
根据Rule 1规则更新active point:
active_node 保持为 root;
active_edge 被设置为即将被插入的新后缀bx的首字符b;
active_length-1=1;
更新remainder:remainder-1=2,表示还有2个后缀待添加:bx、x。
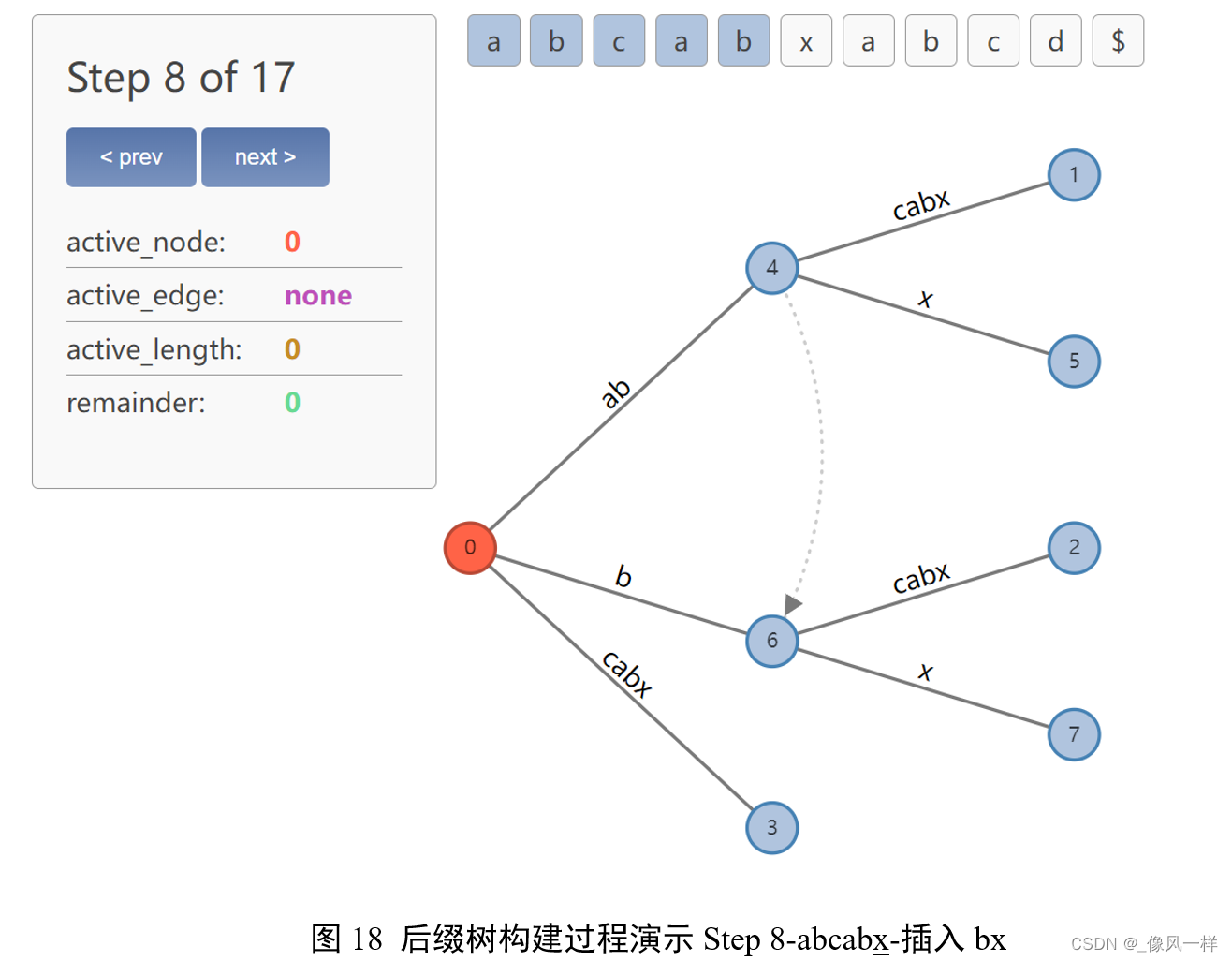
裂变过程与abx的插入相似,不多赘述。依据Rule 1更新active point为 (0, ‘x’, 0)。
更新remainder-1=1,表示还有1个后缀x没有插入。
注:图里的remainder=0,我认为其意思是在扫描到x时回头处理之前的ab,但其实并没有真的扫描x,就像一个人往前走路只是把脚伸过去但没有迈过去踩实,所以默认观察到了x并处理了之前遗留的a和b,但尚未处理x,现在remainder=0说明a和b处理好了,开始处理下一个字符x,直接在根节点加边x。
除此以外,该步骤还需要创建后缀链接。
Rule 2(后缀链接创建规则)
如果我们分裂一条边并且插入一个新的节点,并且如果该新节点不是创建的第一个节点,则将先前插入的节点与该新节点通过一个特殊的指针连接,称为后缀链接,通过一条虚线来表示。
在图18中,因插入bx新裂变出来的节点6,不是扫描到x后创建的第一个节点了(第一个节点是因插入abx新裂变出来的节点4),因此创建后缀链接:4->6。
我的理解是“前人栽树,后人乘凉”,这条后缀链接在下一次碰到ab时会有用。
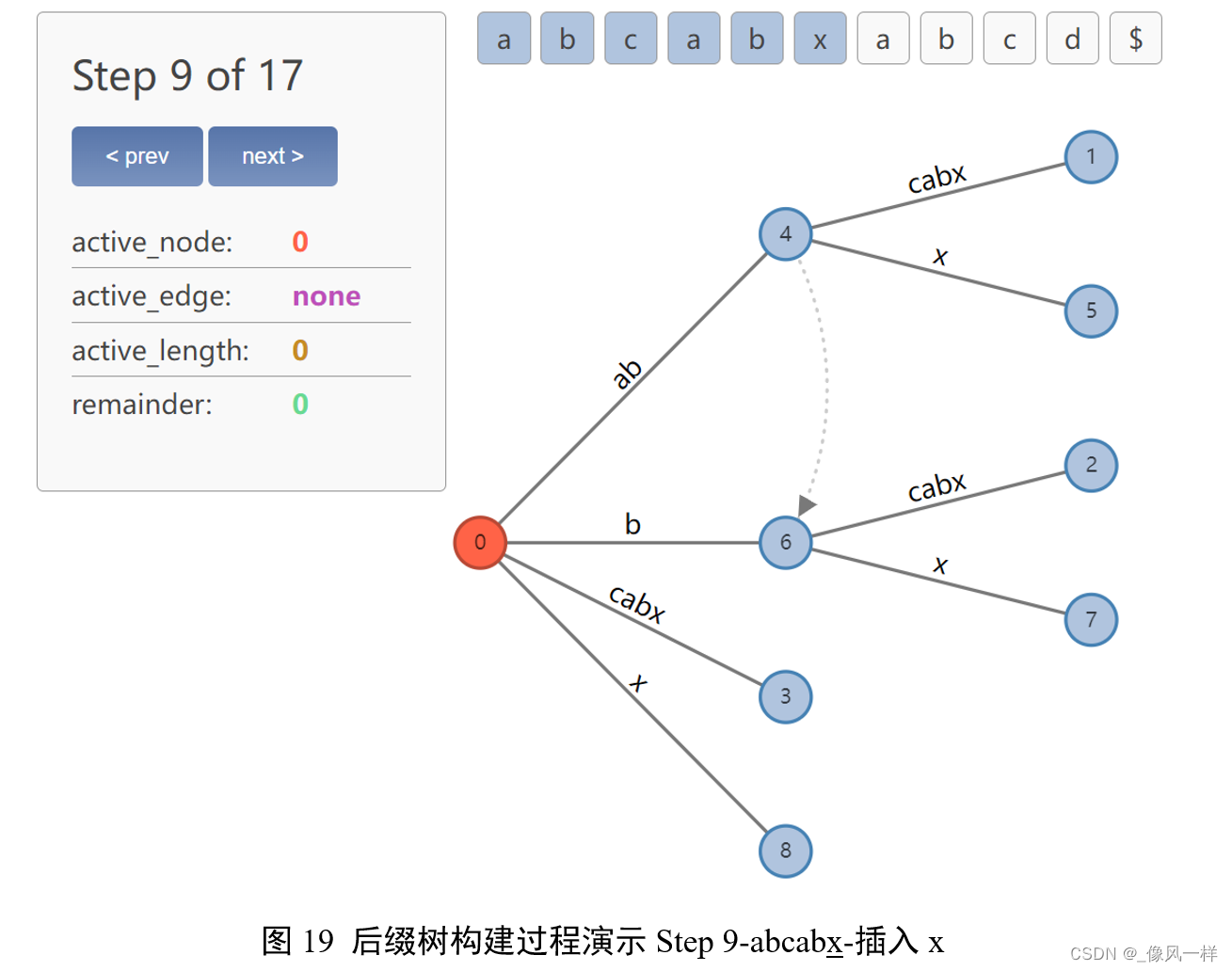
active point为 (0, x, 0),length=0,所以在根节点创建边x。
remainder-1=0,表示可以处理下一个字符了。
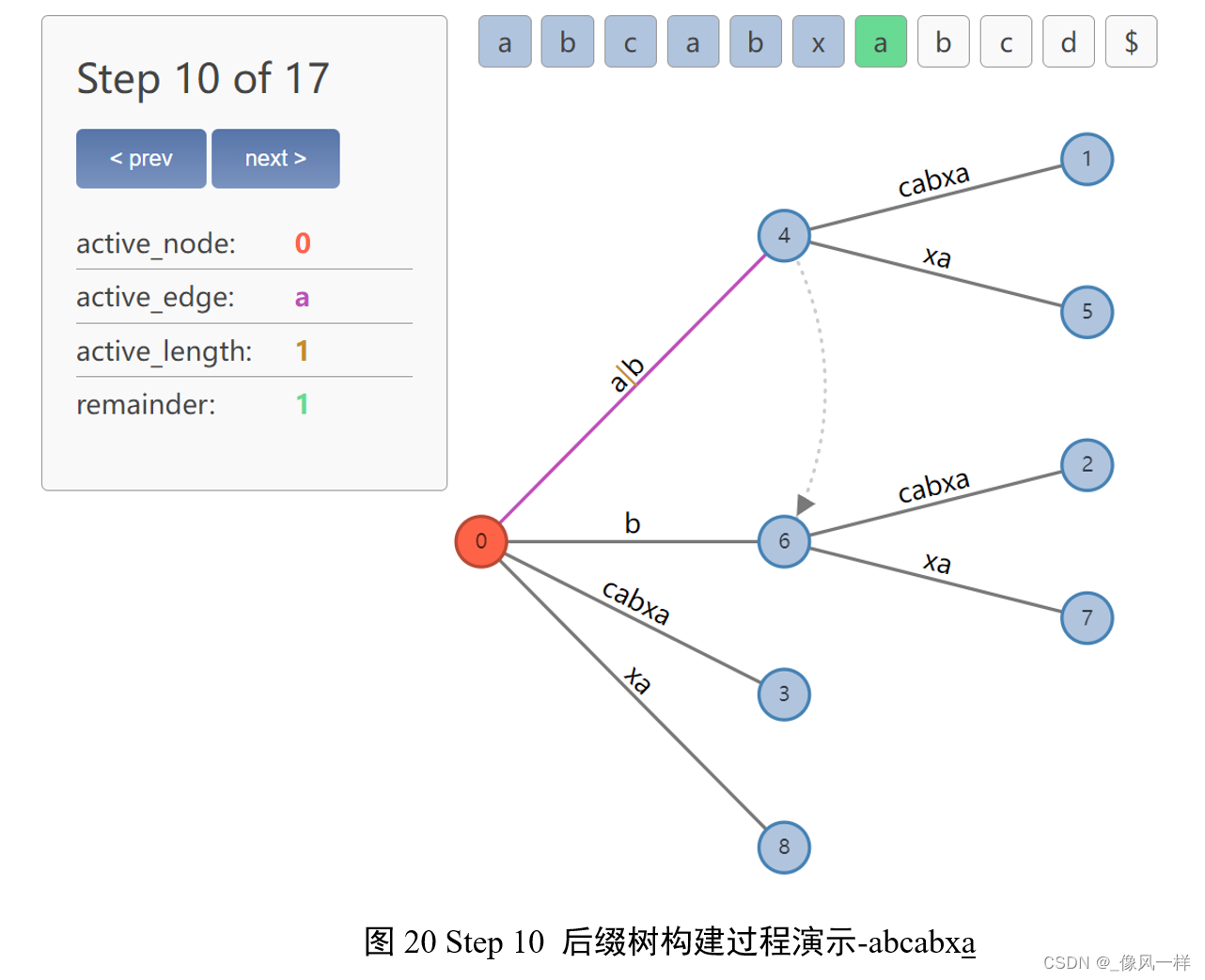
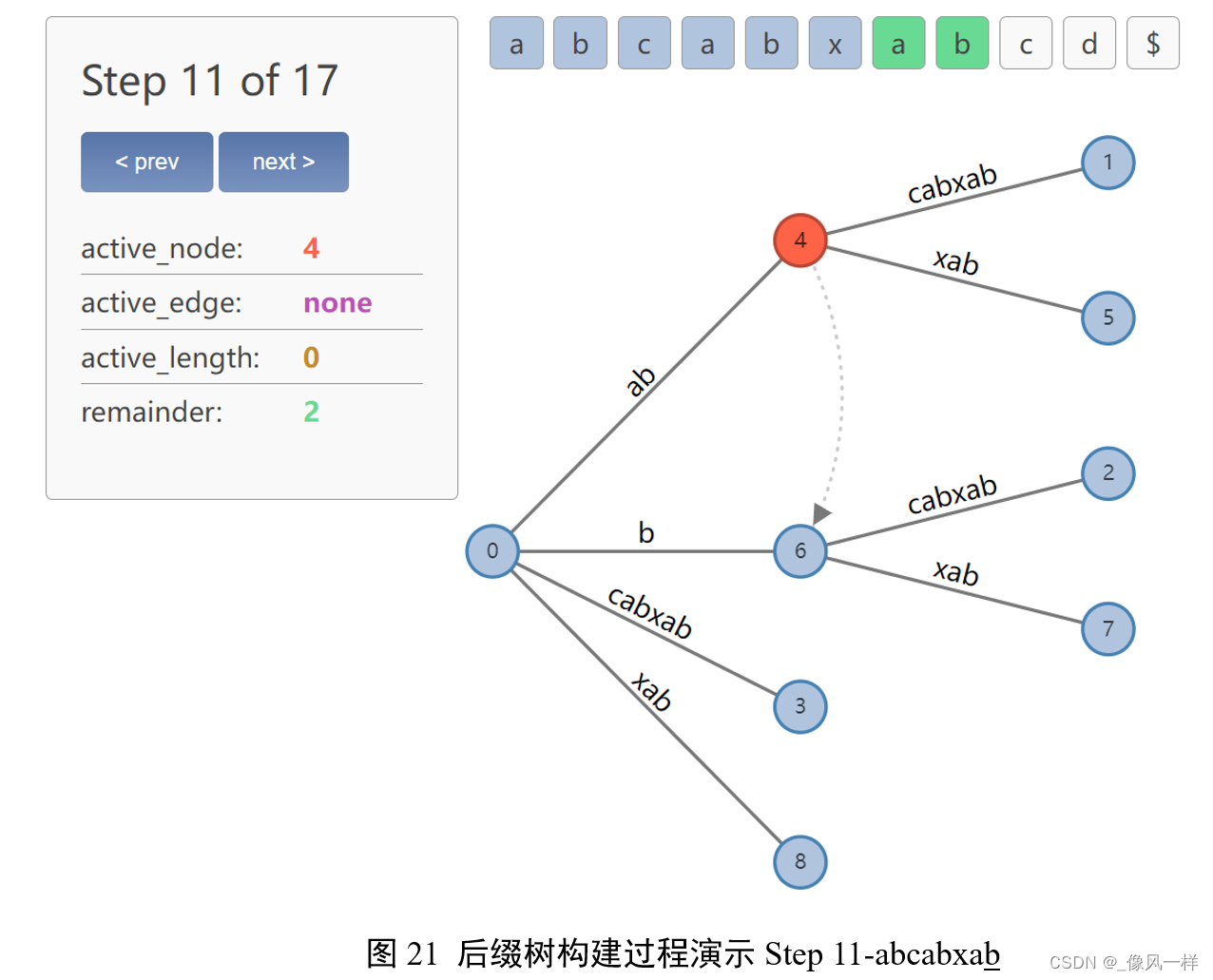
更新active point(4,’c’,1);
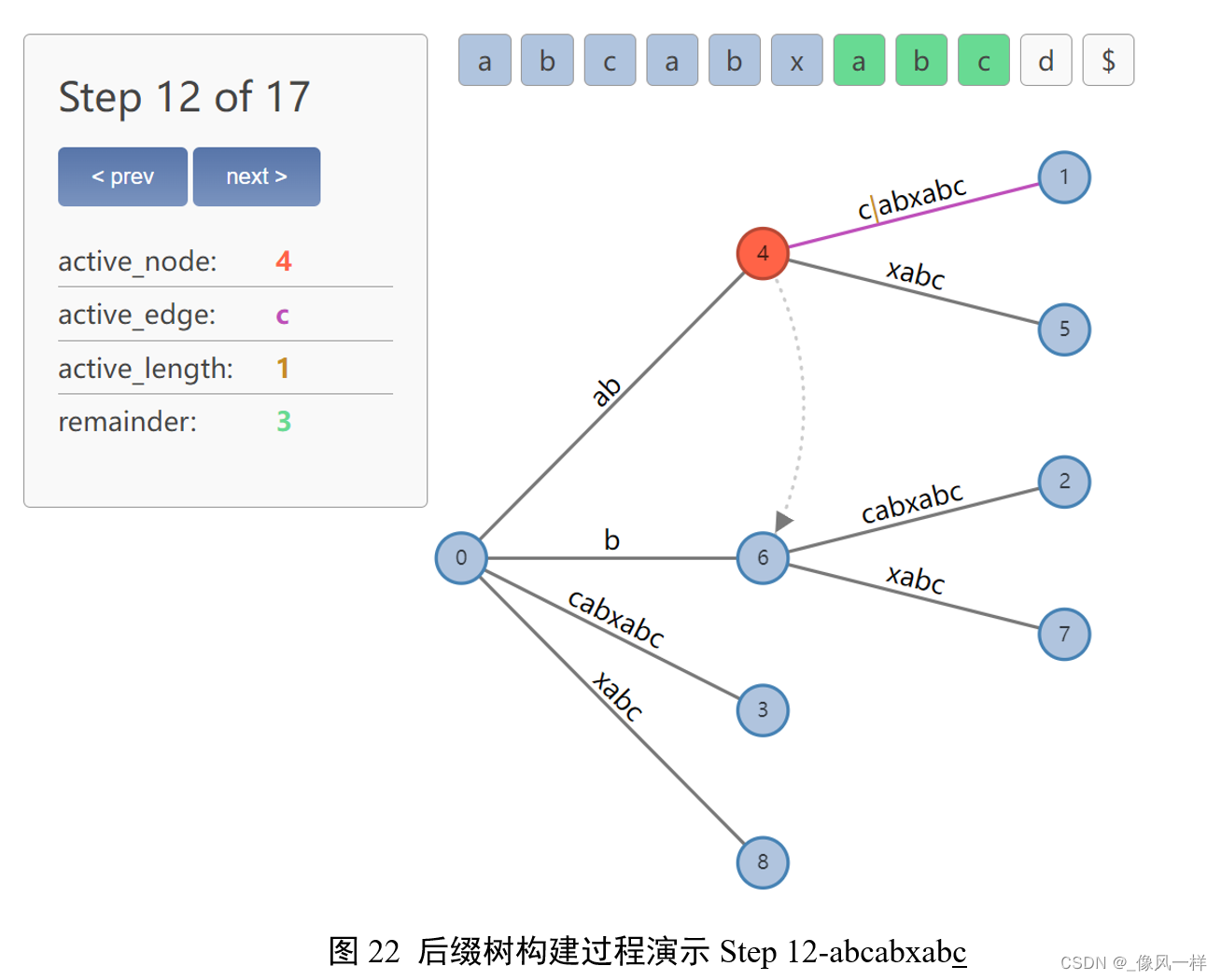
更新remainder=3,表示需要插入abc、bc、c三个后缀。

更新remainder = 4,需要插入abcd、bcd、cd、d四个后缀;
更新active point:abc之后找d,找不到!因此在裂变位置添加新的节点9、新的边d。
问题:此时active point如何更新的?
Rule 3(活动点更新规则2)
当从active_node从不为root的节点分裂边时,我们沿着后缀链接的方向寻找节点:
如果存在一个节点,则设置该节点为 active_node;
如果不存在,则设置 active_node 为 root。
上述两种情况的active_edge 和 active_length 保持不变。
根据Rule 3,图23的active point为(6, c, 1)。
更新remainder = 3,并且开始处理下一个剩余后缀bcd。
bc后并没有没出现d,裂变。
裂变创建了节点11和边d。除了更新之外,根据Rule2创建后缀链接:9->11。
此时,我们观察两个后缀链接:
4 (ab) -> 6 (b)
9 (abc) -> 11 (bc)
remainder-1=2,表示还需要插入cd、d;
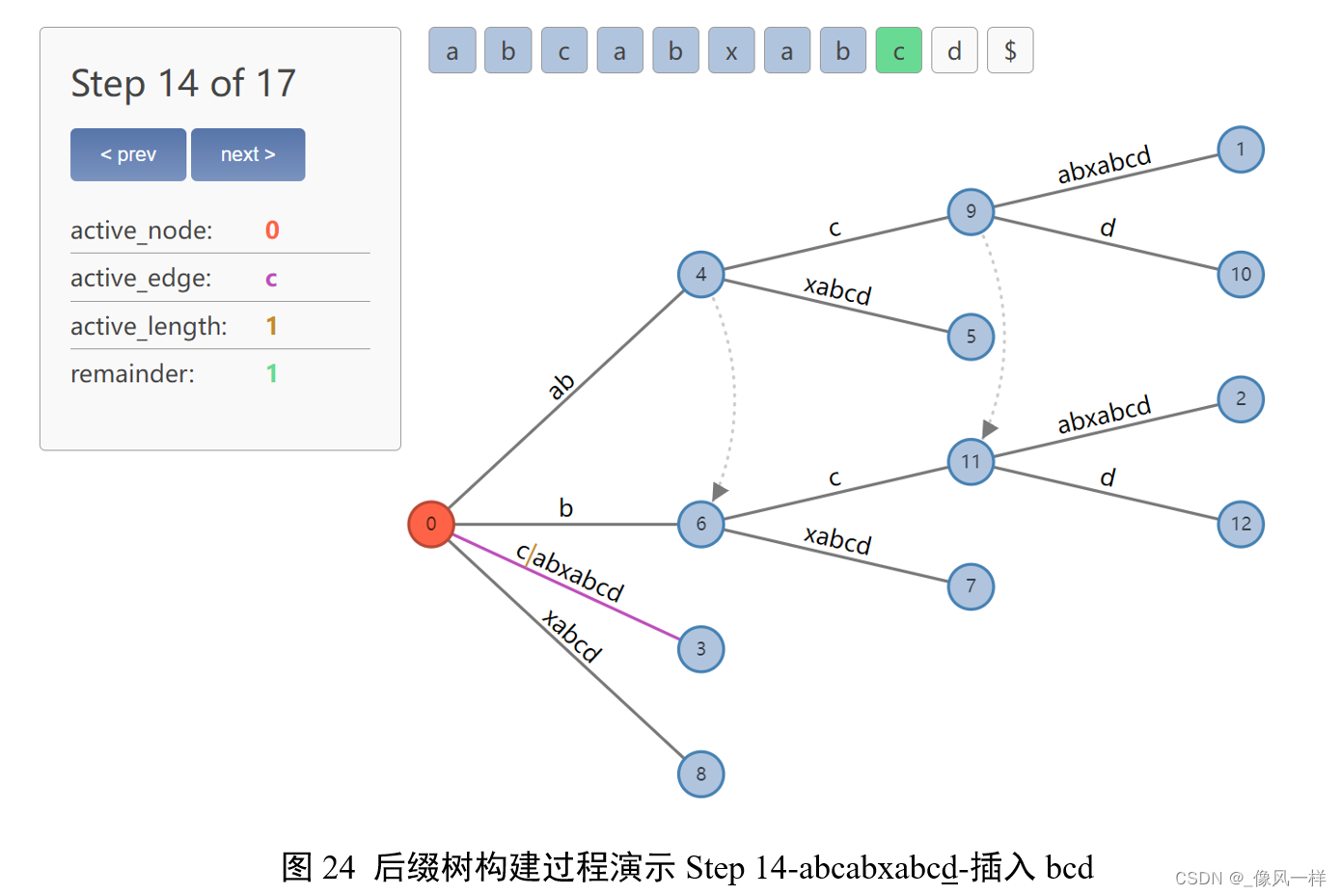
根据Rule 3更新active point为(root, c, 1)。
更新active point时:由于找不到后续d,因此裂变:新建节点13和边d;
更新remainder-1 = 1;
依据Rule 2创建后缀链接:11 -> 13。
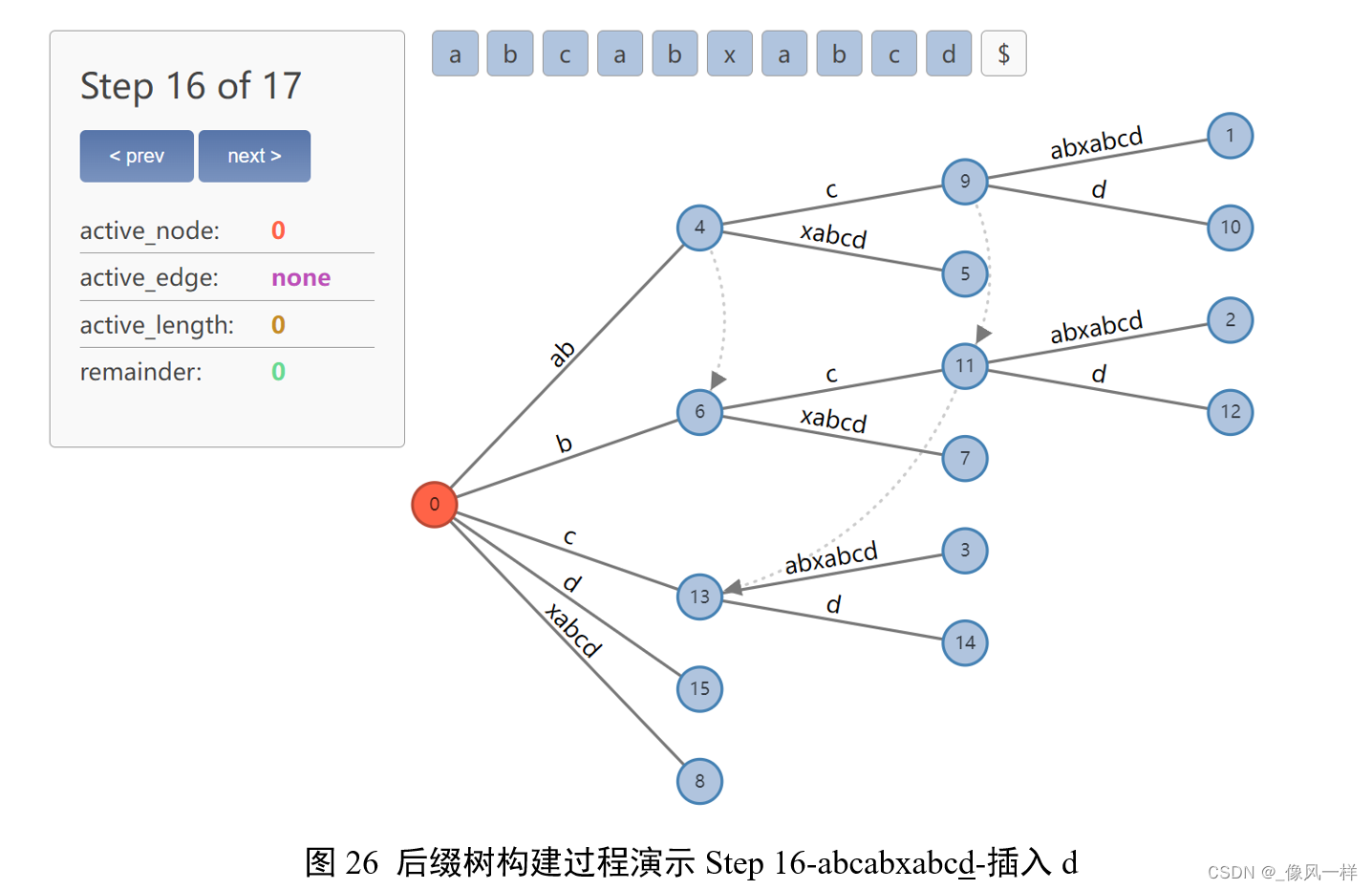
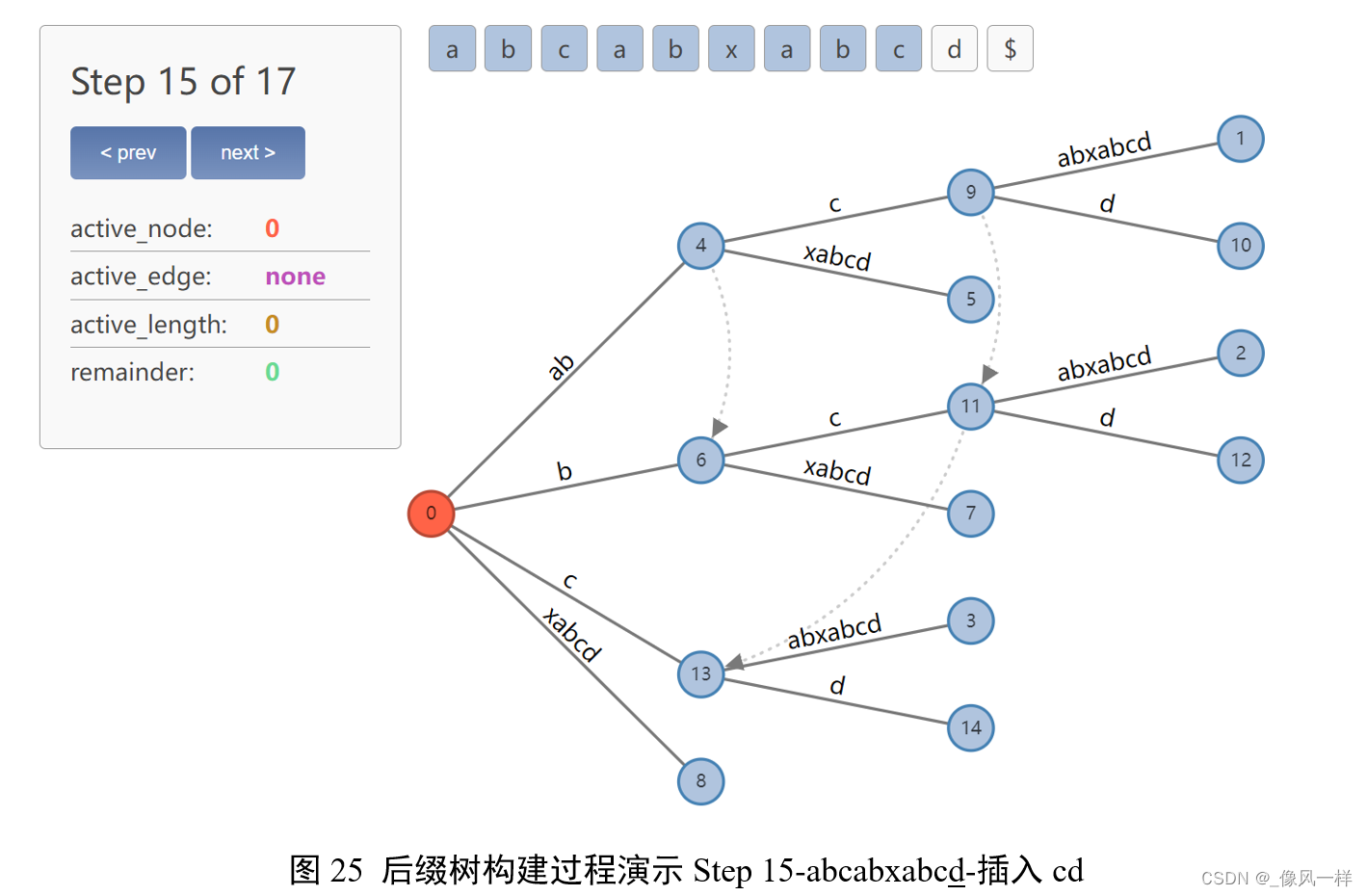
更新active point时:由于找不到后续d,因此裂变,新建边d;
更新remainder-1=0。
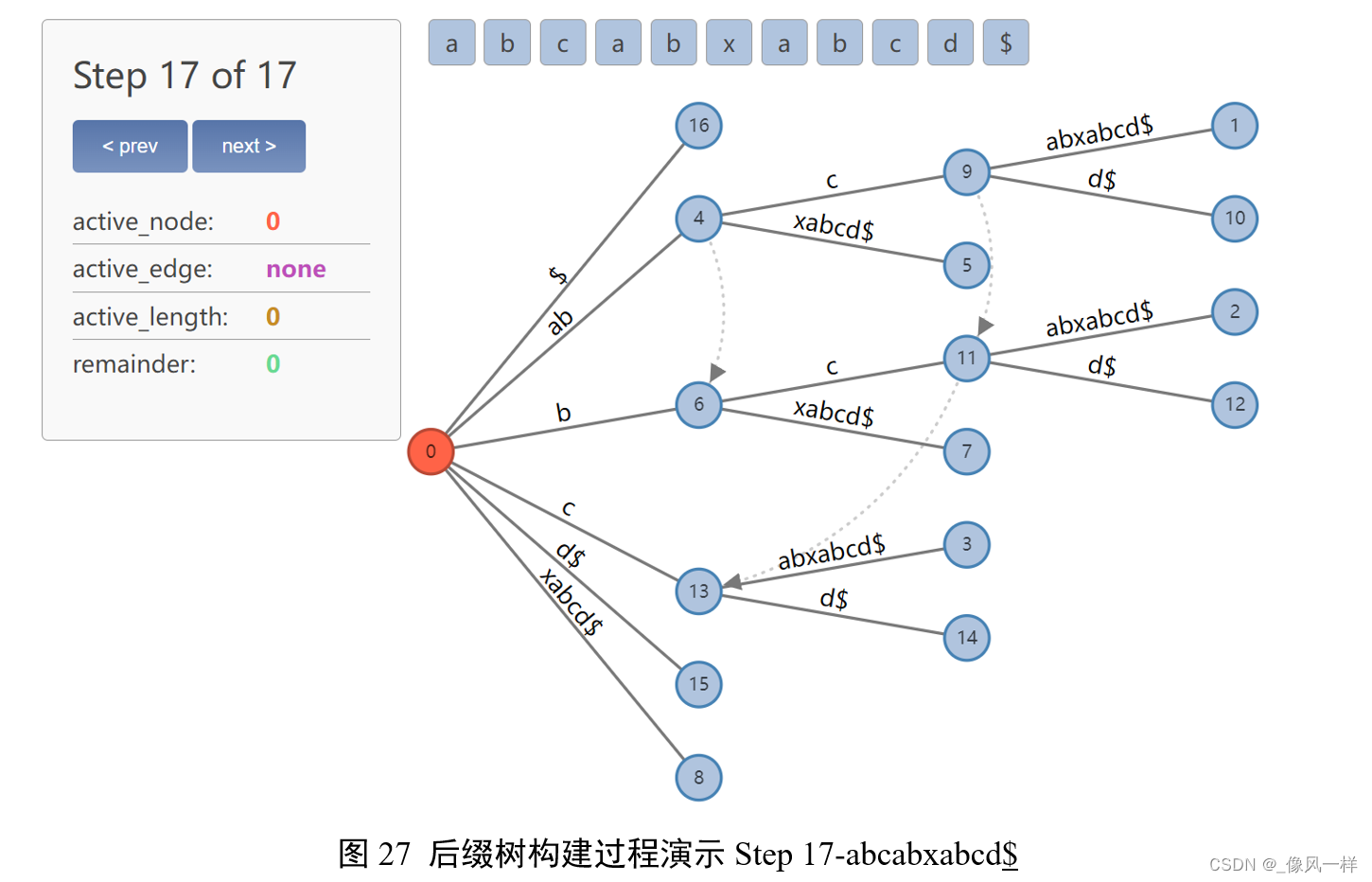
对树结构的改变仅需在根节点上插入一条新边$。
整个后缀树构建完成。
3.3 复杂度分析
关于隐式后缀树,如果扫描发现要被插入的字符已经存在于树中,则无需修改树的结构。原因是要被插入的字符实际上已经隐式地被包含在了当前的树中。而active point和remainder的更新记录了这部分信息,确保了在后续的操作中会进行处理。
问题:算法结束时remainder > 0的情况存在吗?
解决: remainder > 0意味着当前仍为隐式后缀树,虽然隐式包含着后缀信息,但是整个树并没有准确表达所有后缀。
我们在字符串末尾添加 以避免这种情况。由于 以避免这种情况。由于 以避免这种情况。由于一定不同于字符串中任一字符的特性,使得在扫描到$时一定将之前所有隐式包含的后缀暴露出来并处理,处理的过程中remainder递减至0,最终完成整个后缀树的构建。
remainder记录了还余下多少后缀需要插入。这些插入操作将逐个的与当前位之前的后缀进行对应,我们需要一个接着一个的处理。每次插入需要O(1)时间。active point记录了插入(裂变)的位置。仅需在该位置新增一个字符,因为其他字符都被隐式地包含了。每次插入后:对于remainder,相应减少;对于active point:如果存在后缀连接的node续接至下一个节点;如果不存在则返回root节点;如果已经是在root节点了,则依据Rule1来修改活动点。无论哪种情况,仅需O(1)时间。
如果这些插入操作中,如果发现要被插入的字符已经存在于树中,则什么也不做,即使 remainder>0。原因是要被插入的字符实际上已经隐式地被包含在了当前的树中。而 remainder>0 则确保了在后续的操作中会进行处理。
整体算法复杂度是多少?
如果输入字符串的长度为n,则有n步需要执行,加上$有n+1步。在每一步中:
要么消耗O(1) 时间更新active point和remainder;
要么消耗O(1) 时间执行裂变插入操作;
因此整体算法复杂度为O(n)。