提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、爬取的源网站
- 二、实现代码
- 总结
一、爬取的源网站
http://www.lzizy9.com/
在这里以电影片栏下的动作片为例来爬取。
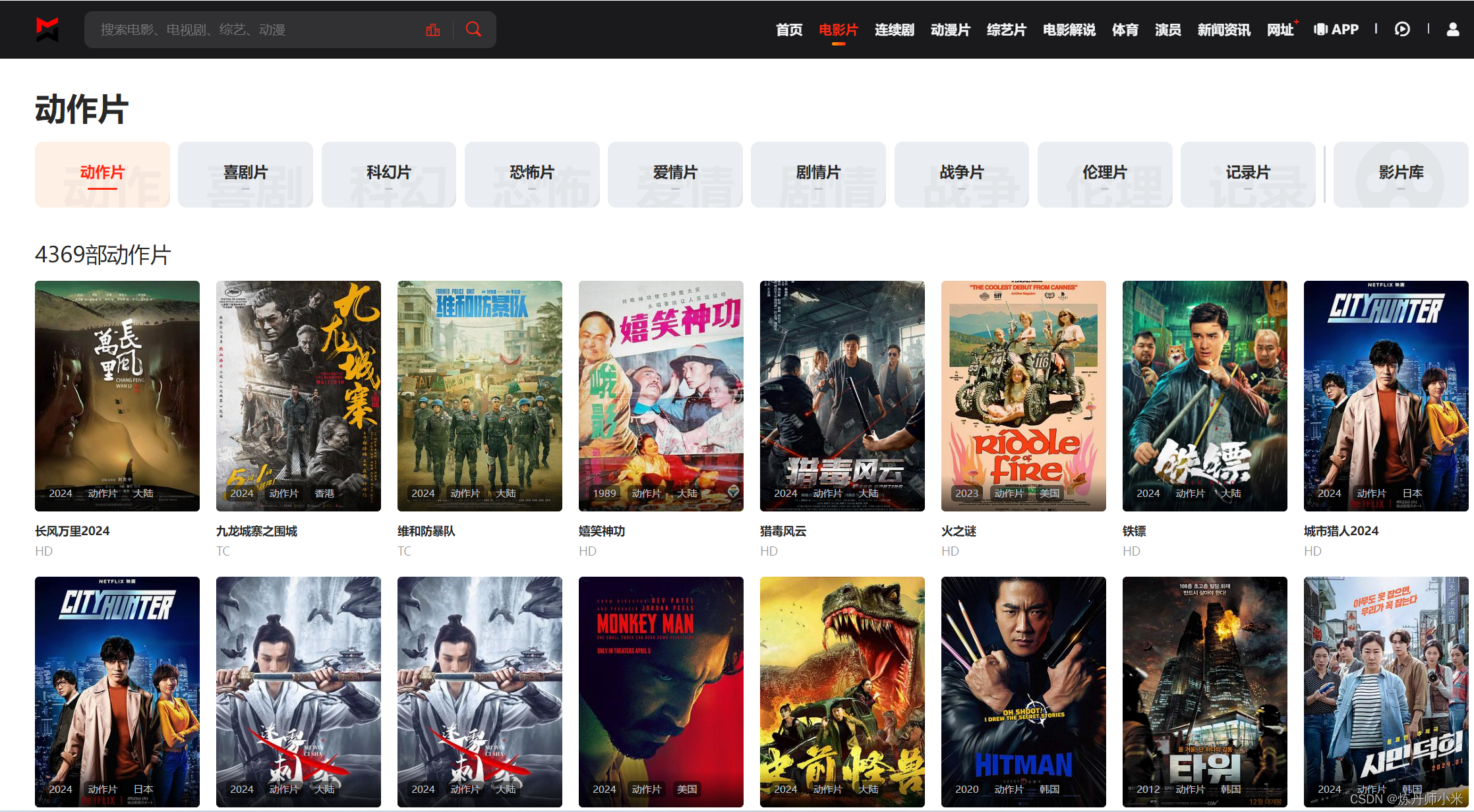
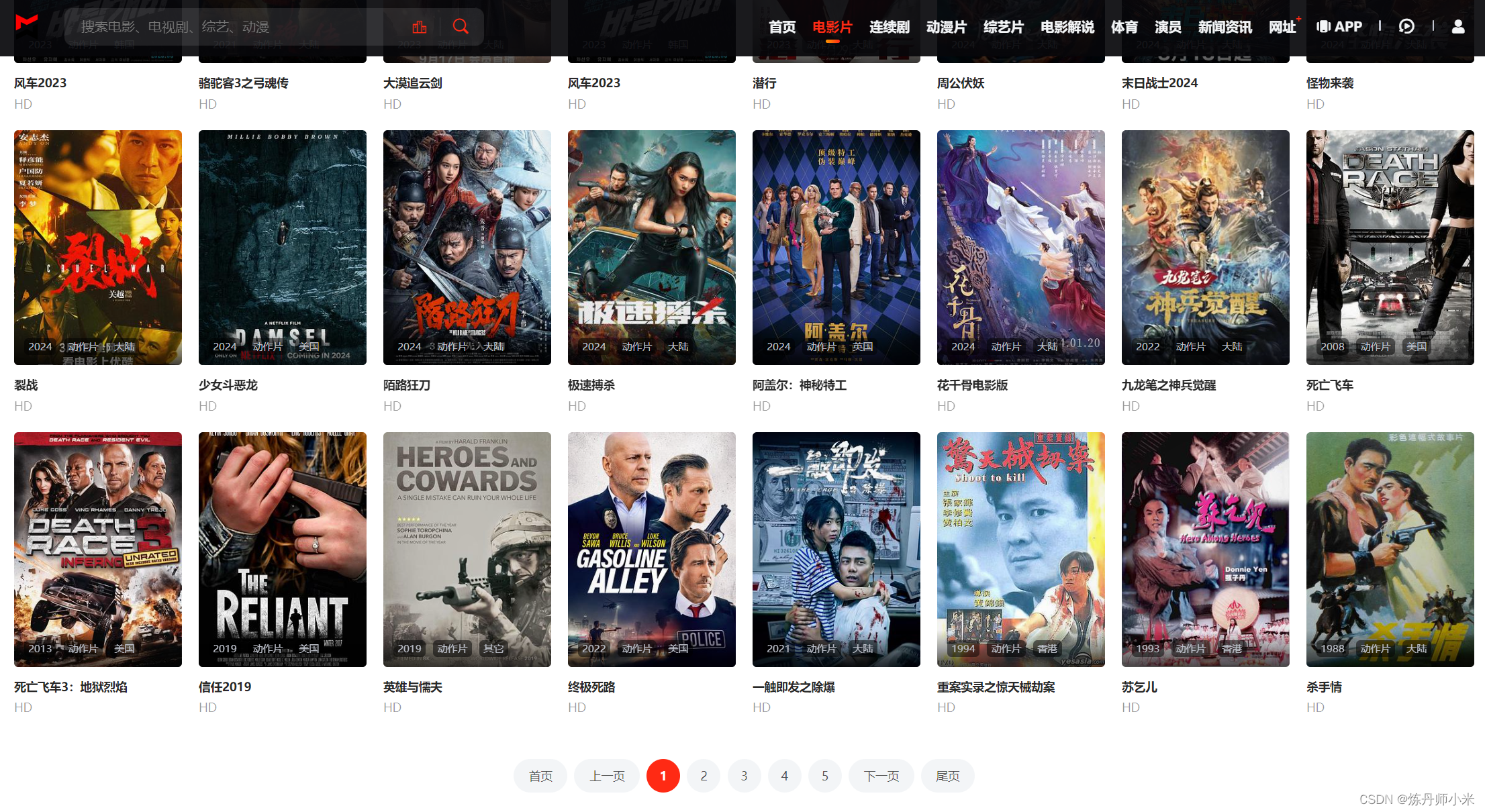
可以看到视频有多页,因此需要多页爬取。
二、实现代码
import requests
from bs4 import BeautifulSoup
import osif __name__=='__main__':# headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。# 对反爬虫网页,设置headers的信息可以让我们的爬取操作模拟成浏览器取访问网站。# 当访问太频繁的时候,容易被服务器禁止访问,这时可以设置多个代理头,通过随机选择某一个代理头来爬取数据,这样可以避免使用同一个头频繁访问的封禁问题。headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}headers2 = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',}# 通过requests.get方法可以发送GET请求html_doc = requests.get(f"http://www.lzizy9.com/index.php/vod/type/id/6/page/1.html", headers=headers)# BeautifulSoup将复杂的HTML文件转化为一个Python对象,使得用户可以更方便地解析、搜索和修改HTML内容。# html_doc.text获取网页的HTML内容soup = BeautifulSoup(html_doc.text, 'html.parser')# 使用findALL提取网页中的信息,其返回的是一个可迭代的对象,具体的用法自行搜索# 我们要爬取所有的视频,需要识别视频一共有多少页,其返回结果为['/index.php/vod/type/id/6/page/61.html'],根据参数我们得知一共有61页视频href_values = [link['href'] for link in soup.findAll('a', title='尾页')]# 获取页数,并将字符串string转化为int整数end_page = int(href_values[0][30:32])# 遍历每一页来获取视频的url链接for page in range(1, end_page+1):# 此处获取网页信息与上面类似html_page = requests.get(f"http://www.lzizy9.com/index.php/vod/type/id/6/page/{page}.html", headers=headers)page_values = BeautifulSoup(html_page.text, "html.parser")# 找视频播放的链接,其在标签为a,class为"module-item-title"的下面href_players = [link['href'] for link in page_values.findAll('a', attrs={"class": "module-item-title"})]for href in href_players:# 寻找播放界面的规律,发现其除了id号不同以外,其他的都一样,从上面获取的视频播放链接中提取id号id = href[25:30]url = f"http://www.lzizy9.com/index.php/vod/play/id/{id}/sid/1/nid/1.html"html_player = requests.get(url, headers=headers)player_values = BeautifulSoup(html_player.text, "html.parser")href_video = player_values.findAll('iframe') # 注意这里是没有获取到信息的,因为HTML源码中的iframe标签是js加载的,因此通过requests无法获取,这里大家可以想别的办法获取视频的真实链接print(href_video)
注意这个代码在最后一次捕获标签iframe时,并没有捕捉到,这是因为爬取的标签不在源HTML源代码中,而是通过js加载进来的,我目前也是第一次碰到这种情况,不过大部分视频网站都是可以正常爬取的,在这里只是一个爬取模板,这个爬取可以用到很多网站。
总结
最后获取的是视频的下载地址url,如果要爬取视频还需要写一个视频下载脚本,可以看后面的教程。


![P9527 [JOISC2022] 洒水器 题解](https://cdn.luogu.com.cn/upload/image_hosting/72n1dcm7.png)