统计建模涵盖了众多数学模型和分析方法,这些模型和方法被广泛应用于数据分析、预测、推断、分类、聚类等任务中。下面列举了一些常见的统计建模方法及其具体应用方式:
目录
1.线性回归模型:
----python实现线性回归模型
-------使用NumPy手动实现简单线性回归
------使用Scikit-Learn实现简单线性回归
2.逻辑回归模型:
python实现逻辑回归模型
手动实现逻辑回归
使用Scikit-Learn实现逻辑回归
3.决策树与随机森林:
python实现统计建模决策树与随机森林
1. 准备工作
2. 导入所需库
3. 加载数据集
4. 划分训练集和测试集
5. 实现决策树
6. 实现随机森林
4.K-means聚类:
python实现统计建模K-means聚类
1. 导入必要的库
2. 生成模拟数据集
3. 应用K-means聚类
4. 可视化结果
5.主成分分析(PCA)与因子分析:
python实现统计建模主成分分析(PCA)与因子分析
1. 主成分分析(PCA)实现
2. 因子分析(Factor Analysis)实现
6.时间序列分析模型:
python实现统计建模时间序列分析模型
安装statsmodels库
ARIMA模型示例
注意事项
7.泊松回归与负二项回归:
python实现统计建模泊松回归与负二项回归
安装statsmodels库
泊松回归示例
负二项回归示例
注意事项
8.生存分析模型:
python实现统计建模生存分析模型
9.贝叶斯网络:
python实现统计建模贝叶斯网络
安装pgmpy
示例:构建一个简单的贝叶斯网络
实现步骤:
10.灰色预测模型
python实现统计建模灰色预测模型
安装greyatom-python(可选)
手动实现GM(1,1)模型
1.线性回归模型:
应用方式:用于研究一个连续因变量与一个或多个自变量之间的线性关系。通过对数据进行拟合,确定自变量对因变量的影响程度(系数),并可以用来预测给定自变量值时因变量的期望值。例如,在经济学中,用于分析GDP与投资、消费、出口等因素的关系;在市场营销中,预测销售额与广告支出、价格、季节因素等的关系。
----python实现线性回归模型
在Python中实现线性回归模型有多种方式,包括使用基本的数学库如NumPy进行手动实现,或者利用高级的机器学习库如Scikit-Learn、TensorFlow和PyTorch等进行快速构建。下面我将展示使用NumPy手动实现简单线性回归以及使用Scikit-Learn库的示例。
-------使用NumPy手动实现简单线性回归
简单线性回归的目标是找到最佳拟合直线 𝑦=𝑤𝑥+𝑏y=wx+b,其中 𝑤w 是斜率,𝑏b 是截距。我们可以通过最小化均方误差(MSE)来估计这些参数。
import numpy as npdef simple_linear_regression(X, y):# 计算权重w和截距bw = np.dot(X, y) / np.dot(X, X)b = y.mean() - w * X.mean()return w, b# 示例数据
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 3, 5, 7, 11])# 调用函数
w, b = simple_linear_regression(X, y)# 打印结果
print(f"Slope (w): {w}")
print(f"Intercept (b): {b}")
------使用Scikit-Learn实现简单线性回归
Scikit-Learn提供了更简洁且功能强大的接口来实现线性回归,包括模型训练、预测和性能评估等功能。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np# 示例数据
np.random.seed(0)
X = np.random.rand(100, 1) # 假设有100个样本,每个样本1个特征
y = 2 + 3 * X + np.random.randn(100, 1) # 加入噪声# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 查看模型参数
print("模型斜率(w): ", model.coef_)
print("模型截距(b): ", model.intercept_)
以上两种方法分别展示了如何从基础开始手动实现线性回归以及如何使用Scikit-Learn这一高效工具来快速完成任务。根据具体需求和项目复杂度,可以选择适合的实现方式。
2.逻辑回归模型:
应用方式:适用于二分类问题(如“购买/未购买”、“患病/未患病”)或者多分类问题(如“类别A/类别B/类别C”)。通过将线性函数映射到概率分布(如Logit函数或Probit函数),模型可以估计出给定自变量条件下发生某一类别的概率。在医学诊断、信用评分、市场营销响应预测等领域广泛应用。
python实现逻辑回归模型
在Python中实现逻辑回归模型,除了可以使用高级机器学习库如Scikit-Learn之外,也可以手动实现逻辑回归算法。这里我将给出一个简单的手动实现逻辑回归的示例,以及如何使用Scikit-Learn库的版本。
手动实现逻辑回归
手动实现逻辑回归涉及到梯度上升法来优化损失函数(对数似然函数)。以下是一个简化版的逻辑回归实现:
import numpy as npdef sigmoid(z):"""Sigmoid函数"""return 1 / (1 + np.exp(-z))def cost_function(X, y, weights):"""逻辑回归的代价函数(负对数似然函数)"""m = len(y)h = sigmoid(X @ weights)cost = (-y.T @ np.log(h) - (1-y).T @ np.log(1-h)) / mreturn costdef gradient_descent(X, y, weights, learning_rate, num_iterations):"""梯度上升法优化权重"""m = len(y)for _ in range(num_iterations):gradients = (1/m) * (X.T @ (sigmoid(X @ weights) - y))weights -= learning_rate * gradientsreturn weightsdef predict(X, weights):"""预测函数"""return (sigmoid(X @ weights) >= 0.5).astype(int)# 示例数据
np.random.seed(0)
X = np.random.rand(100, 2) # 假设有100个样本,每个样本2个特征
y = (X[:, 0] + X[:, 1] > 1).astype(int) * 2 - 1 # 标签,大于1为1,否则为0
X_b = np.c_[np.ones((len(X), 1)), X] # 添加截距项# 初始化权重
initial_weights = np.zeros(X_b.shape[1])# 设置参数
learning_rate = 0.1
num_iterations = 1000# 训练模型
weights = gradient_descent(X_b, y, initial_weights, learning_rate, num_iterations)# 预测
predictions = predict(X_b, weights)
print("预测结果:", predictions[:10])# 输出最终权重
print("模型权重:", weights)
使用Scikit-Learn实现逻辑回归
使用Scikit-Learn库实现逻辑回归则更加简洁:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np# 示例数据
np.random.seed(0)
X = np.random.rand(100, 2)
y = (X[:, 0] + X[:, 1] > 1).astype(int)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练模型
model = LogisticRegression(max_iter=10000) # max_iter设置足够大以避免迭代次数不足的警告
model.fit(X_train, y_train)# 预测
predictions = model.predict(X_test)# 查看模型分数
print("模型得分:", model.score(X_test, y_test))
print("模型系数:", model.coef_)
print("模型截距:", model.intercept_)
以上代码演示了两种不同的逻辑回归实现方式:一种是手动实现,涉及到了梯度上升法的核心逻辑;另一种是使用Scikit-Learn库,只需几行代码即可完成模型的训练和预测,非常方便。
3.决策树与随机森林:
应用方式:决策树是一种直观展示分类或回归规则的模型,通过一系列内部节点的条件测试和外部节点的结果来做出预测。随机森林则是集成学习方法,由多个决策树构成,通过投票或平均等方式整合单个树的预测结果。它们常用于分类任务(如客户流失预测、疾病诊断)、回归任务(如房价预测)以及特征重要性评估。
python实现统计建模决策树与随机森林
在Python中实现统计建模的决策树与随机森林通常涉及到使用scikit-learn库,这是一个广泛使用的机器学习库,提供了丰富的算法实现,包括决策树和随机森林。下面简要概述如何使用scikit-learn来实现这两个模型。
1. 准备工作
首先,确保安装了scikit-learn库。如果没有安装,可以通过pip安装:
pip install scikit-learn2. 导入所需库
接下来,导入所需的库和模块:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris # 示例数据集
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score3. 加载数据集
这里我们使用load_iris作为示例数据集,你可以替换为你自己的数据集。
data = load_iris()
X = data.data
y = data.target4. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)5. 实现决策树
# 创建决策树模型
dt_model = DecisionTreeClassifier(random_state=42)# 训练模型
dt_model.fit(X_train, y_train)# 预测
dt_predictions = dt_model.predict(X_test)# 计算准确率
dt_accuracy = accuracy_score(y_test, dt_predictions)
print(f"决策树准确率: {dt_accuracy}")6. 实现随机森林
# 创建随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_model.fit(X_train, y_train)# 预测
rf_predictions = rf_model.predict(X_test)# 计算准确率
rf_accuracy = accuracy_score(y_test, rf_predictions)
print(f"随机森林准确率: {rf_accuracy}")
4.K-means聚类:
应用方式:用于无监督学习,将数据集中的观测值自动划分为K个簇,使得同一簇内的观测值相似度高,不同簇间的观测值相似度低。广泛应用于市场细分(识别消费行为模式相似的客户群体)、图像分割、社交网络分析(发现用户兴趣相似的社区)等场景。
python实现统计建模K-means聚类
在Python中实现K-means聚类算法,你可以直接使用scikit-learn库,这是一个非常流行的机器学习库,提供了许多实用的机器学习模型,包括K-means算法。下面是一个简单的示例,演示如何使用scikit-learn来执行K-means聚类:
首先,确保你已经安装了scikit-learn库。如果还没有安装,可以通过pip安装:
pip install scikit-learn然后,你可以按照以下步骤来实现K-means聚类:
1. 导入必要的库
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs # 生成模拟数据集
import matplotlib.pyplot as plt2. 生成模拟数据集
为了演示,我们首先生成一个模拟的数据集,通常在真实场景中,你会有自己的数据集。
# 生成带有3个聚类中心的数据集
X, _ = make_blobs(n_samples=300, centers=3, random_state=0, cluster_std=0.6)3. 应用K-means聚类
# 初始化KMeans对象,指定聚类数量
kmeans = KMeans(n_clusters=3, init='k-means++', random_state=42)# 使用数据训练模型
kmeans.fit(X)# 预测每个样本的聚类标签
labels = kmeans.predict(X)4. 可视化结果
对于二维数据,我们可以用matplotlib来可视化聚类结果。
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='x', label='Cluster Centers')
plt.title('K-means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show() 
这段代码首先生成了一个包含3个聚类中心的二维数据集,然后使用K-means算法对数据进行了聚类,并将聚类结果可视化。kmeans++初始化方法通常能够提供较好的初始聚类中心选择,有助于提高算法的稳定性和速度。
如果你有实际的数据集,可以将make_blobs产生的数据替换为实际数据,记得调整数据加载和预处理步骤以适应你的数据格式。
5.主成分分析(PCA)与因子分析:
应用方式:这两种方法都是降维技术,用于简化高维数据并揭示其内在结构。PCA通过线性变换将原始变量转换为一组不相关的主成分,最大限度保留数据的方差;因子分析则侧重于寻找潜在的“因子”,解释多个观测变量之间的共性。它们可用于数据可视化、特征选择、数据压缩、消费者偏好分析等。
python实现统计建模主成分分析(PCA)与因子分析
在Python中实现主成分分析(PCA)和因子分析,你可以使用scikit-learn库,它提供了简单且高效的方法来执行这些操作。下面是两个简化的示例,分别展示如何使用scikit-learn进行PCA和因子分析。
1. 主成分分析(PCA)实现
首先,确保安装了scikit-learn库。接下来是一个简单的PCA实现步骤:
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import numpy as np
import pandas as pd# 假设df是你的DataFrame,其中包含多列特征数据
# 示例数据创建,实际使用时请替换为你的数据
np.random.seed(0)
df = pd.DataFrame(np.random.rand(100, 5), columns=['Feature1', 'Feature2', 'Feature3', 'Feature4', 'Feature5'])# 数据标准化
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)# 初始化PCA对象
pca = PCA()# 拟合并转换数据
principal_components = pca.fit_transform(df_scaled)# 打印主成分数量和解释的方差比
explained_variance = pca.explained_variance_ratio_
print("Explained Variance Ratio:", explained_variance)# 选择主成分(例如,取前2个主成分)
pca_result = PCA(n_components=2)
principal_components_2d = pca_result.fit_transform(df_scaled)2. 因子分析(Factor Analysis)实现
同样,使用scikit-learn中的FactorAnalysis进行因子分析:
from sklearn.decomposition import FactorAnalysis# 初始化因子分析对象
fa = FactorAnalysis(n_components=2)# 拟合并转换数据
factor_analysis_result = fa.fit_transform(df_scaled)# 打印因子载荷矩阵
loadings = fa.components_
print("Factor Loadings:\n", loadings)在这两个例子中,我们首先对数据进行了标准化处理,这是因为在进行PCA或因子分析之前,通常需要确保所有特征都在同一尺度上,避免因量纲不同导致分析结果失真。PCA是一种无监督学习方法,用于降维并保持数据的最大方差;而因子分析则尝试找出隐藏的、不可观测的变量(即因子),这些因子能够解释观测数据中的变异性。
请注意,上述代码仅为基本示例,实际应用时可能需要根据具体数据和需求调整参数。例如,选择主成分的数量、考虑旋转因子等。

6.时间序列分析模型:
应用方式:针对随时间变化的数据,如股票价格、销售量、气温等,进行趋势分析、周期性检测、异常值识别、预测等。具体模型包括自回归模型(AR)、滑动平均模型(MA)、自回归滑动平均模型(ARIMA)、季节性分解整合移动平均模型(SARIMA)等。在金融、经济预测、库存管理、能源需求分析等领域广泛应用。
python实现统计建模时间序列分析模型
在Python中实现时间序列分析模型,一个常用的库是statsmodels,它提供了多种时间序列分析和预测的方法,包括ARIMA模型、季节性分解(Seasonal Decomposition of Time Series, STL)、自回归(AR)、移动平均(MA)等。以下是一个使用statsmodels实现ARIMA模型的示例:
安装statsmodels库
首先,确保已经安装了statsmodels库。如果未安装,可以通过pip命令安装:
pip install statsmodelsARIMA模型示例
ARIMA模型由三部分组成:自回归项(AR)、差分(I)和移动平均项(MA)。下面是一个使用ARIMA模型对时间序列数据进行分析和预测的基本步骤:
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt# 假设有一个名为"data.csv"的时间序列数据文件,其中包含两列:'date'和'value'
# 加载数据
data = pd.read_csv('data.csv', parse_dates=['date'], index_col='date')# 检查数据是否为时间序列
print(data.head())# 拟合ARIMA模型
# 注意:p, d, q分别代表AR、差分和MA的阶数,需要根据数据特性确定
model = ARIMA(data['value'], order=(1, 1, 1)) # 示例中使用(1,1,1),实际应用时需根据诊断选择# 模型训练
model_fit = model.fit()# 输出模型摘要,查看模型参数和统计检验结果
print(model_fit.summary())# 预测未来几个时间点的数据
forecast_steps = 5
forecast = model_fit.forecast(steps=forecast_steps)# 绘制原始数据和预测结果
plt.figure(figsize=(12, 6))
plt.plot(data, label='Original')
plt.plot(pd.date_range(data.index[-1]+pd.DateOffset(1), periods=forecast_steps, closed='right'), forecast, marker='o', linestyle='-', color='red', label='Forecast')
plt.legend()
plt.title('ARIMA Model Forecast')
plt.show()注意事项
- 在选择ARIMA模型的阶数(p, d, q)时,通常需要通过分析时间序列的自相关函数(ACF)和偏自相关函数(PACF)来确定,或者使用自动ARIMA(auto_arima)方法来自动确定最优参数。
- 上面的代码示例是基于ARIMA模型的一个基础应用,实际应用中可能还需要进行数据的平稳性检验(如ADF检验)、季节性检测、残差诊断等预处理步骤。
auto_arima功能不在statsmodels库内,但可通过安装pmdarima库来使用。
确保在应用模型前,对数据进行适当的预处理和检验,以确保模型的有效性和准确性。
7.泊松回归与负二项回归:
应用方式:针对计数数据(如事件发生次数、网页点击量、疾病病例数),这类模型能处理非负整数响应变量。泊松回归假设计数服从泊松分布,适用于事件发生率相对稳定的情况;负二项回归则允许计数数据存在过分散现象(方差大于均值)。在公共卫生、风险管理、互联网流量分析等领域有应用。
python实现统计建模泊松回归与负二项回归
在Python中实现泊松回归和负二项回归,可以使用statsmodels库,因为它提供了广义线性模型(GLM)的实现,这包括泊松回归和负二项回归。下面是两个模型的基本实现示例:
安装statsmodels库
如果你还没有安装statsmodels库,可以通过pip安装:
pip install statsmodels泊松回归示例
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import glm# 假设df是包含因变量(计数数据)和自变量的数据框
# df['count'] 是因变量,df[['var1', 'var2']] 是自变量列表
# 示例数据创建,实际情况中应该从csv文件或其他来源加载数据
np.random.seed(0)
df = pd.DataFrame({'count': np.random.poisson(lam=5, size=100),'var1': np.random.normal(size=100),'var2': np.random.randint(0, 2, size=100)
})# 泊松回归模型
poisson_model = glm(formula="count ~ var1 + var2", data=df, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary()) # 注意这里调用了summary()方法 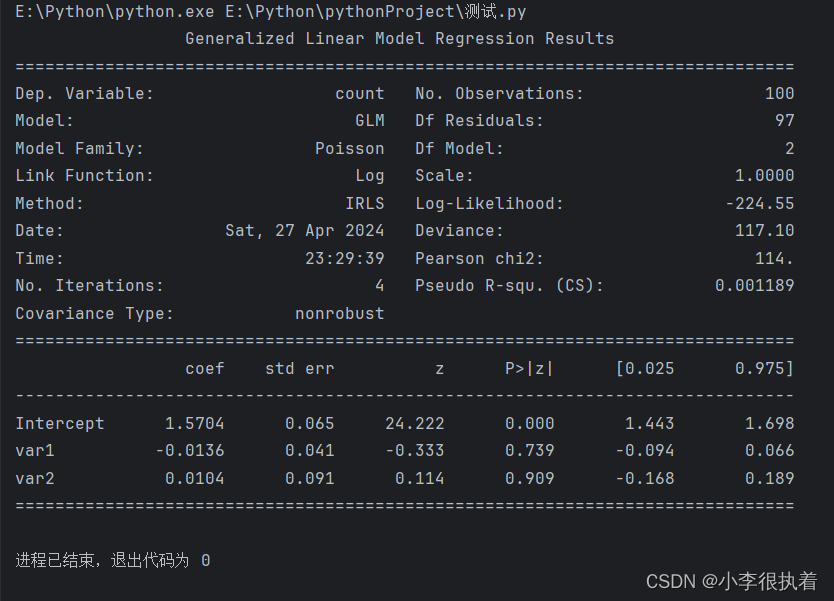
负二项回归示例
对于负二项回归,我们需要指定一个额外的参数dispersion来处理过度离散的情况。statsmodels允许我们通过family参数中的NegativeBinomial类来实现,同时可以设置其link函数(默认为log链接)。
# 负二项回归模型,这里使用默认的dispersion估计
negbin_model = glm(formula="count ~ var1 + var2", data=df, family=sm.families.NegativeBinomial(alpha=sm.families.links.nbinom_gen.default_link()))
negbin_results = negbin_model.fit()
print(negbin_results.summary())注意事项
- 在实际应用中,你需要根据数据的特性选择合适的模型。如果数据的方差远大于均值(过度离散),负二项回归可能是更好的选择。
alpha参数在NegativeBinomial家族中用于控制过度离散的程度,当设置为默认值(通常是通过最大似然估计得到)时,模型会自动估计过度离散的参数。- 分析前确保数据已经被正确清洗和预处理,例如处理缺失值、异常值等。
- 在比较泊松回归和负二项回归的模型效果时,可以考虑使用AIC、BIC等信息准则或者残差分析来评估模型的适用性。
8.生存分析模型:
应用方式:研究个体或系统在特定条件下的生存(持续)时间,如病人的生存期、设备的使用寿命、产品的退货时间等。常用模型包括 Kaplan-Meier 生存曲线、Cox比例风险模型等,用于估计生存概率、比较不同组别生存率差异、识别影响生存时间的关键因素等。
python实现统计建模生存分析模型
在Python中,使用lifelines库来实现生存分析是一种常见且方便的方法。lifelines库提供了丰富的功能来拟合生存模型,如Kaplan-Meier曲线、cox比例风险模型等。下面是一个简单的示例,展示如何使用lifelines库构建Cox比例风险模型。
首先,确保安装了lifelines库。如果未安装,可以通过pip安装:
pip install lifelines接下来,我们将通过一个假设的数据集来演示如何构建一个Cox模型。在这个例子中,我们假设有两个协变量age和treatment影响生存时间。
import numpy as np
import pandas as pd
from lifelines import CoxPHFitter# 假设数据集创建,实际情况中应从实际数据源读取
np.random.seed(42)
n_samples = 100
df = pd.DataFrame({'id': range(n_samples),'age': np.random.normal(60, 10, n_samples), # 年龄,连续变量'treatment': np.random.choice(['A', 'B'], n_samples, p=[0.3, 0.7]), # 治疗类型,类别变量'time': np.random.exponential(scale=10, size=n_samples), # 生存时间'event': np.random.binomial(1, 0.8, n_samples) # 是否发生事件(1为事件发生,0为删失)
})# 使用lifelines的CoxPHFitter进行生存分析
cph = CoxPHFitter()
cph.fit(df, duration_col='time', event_col='event', show_progress=False)# 打印模型摘要
print(cph.summary)# 预测风险得分
risk_scores = cph.predict_survival_function(df)这段代码首先创建了一个包含模拟生存数据的数据框,其中time表示生存时间,event是一个二元变量,表示研究期间是否观察到终点事件(例如,生存或死亡)。然后,我们使用CoxPHFitter类拟合Cox比例风险模型,并打印出模型的摘要信息,其中包括每个协变量的系数、p值、风险比等统计量。最后,我们计算了基于该模型预测的生存函数。
请注意,这只是一个简化的示例,实际应用时需要依据真实数据调整模型设定和处理缺失值、异常值等问题。此外,生存分析通常要求对生存数据的特性有深入理解,比如 censoring(删失)的处理。
9.贝叶斯网络:
应用方式:基于贝叶斯定理和图模型表示变量间的条件依赖关系,常用于复杂系统的因果推理、不确定性分析、诊断决策支持等。例如,在医学诊断中构建症状与疾病之间的概率关系网络,根据患者症状推断可能的疾病状态。
python实现统计建模贝叶斯网络
安装pgmpy
首先,确保安装了pgmpy库。可以通过pip安装:
pip install pgmpy示例:构建一个简单的贝叶斯网络
假设我们要构建一个简单的贝叶斯网络来模拟天气、草地湿润和洒水器工作之间的关系。网络结构如下:
- 天气(Weather)可以是晴天(Sunny)或雨天(Rainy)。
- 草地湿润(GrassWet)可以是湿的或干的。
- 洒水器工作(Sprinkler)可以是开启或关闭。
规则如下:
- 如果下雨(Rainy),草地必定湿(不管洒水器是否开启)。
- 如果洒水器开启并且没有下雨,草地也是湿的。
- 如果没有下雨且洒水器没开,草地是干的。
实现步骤:
-
定义网络结构:创建节点并定义它们之间的条件关系。
-
指定CPDs(条件概率分布):为每个节点定义在给定其父节点状态下的概率。
-
构建并查询网络:使用网络进行概率推断。
下面是相应的Python代码示例:
from pgmpy.models import BayesianModel
from pgmpy.factors.discrete import TabularCPD# 定义网络结构
model = BayesianModel([('Weather', 'GrassWet'), ('Sprinkler', 'GrassWet')])# 指定条件概率分布 (CPDs)
cpd_weather = TabularCPD(variable='Weather', variable_card=2, values=[[0.5], [0.5]], state_names={'Weather': ['Sunny', 'Rainy']})
cpd_sprinkler = TabularCPD(variable='Sprinkler', variable_card=2, values=[[0.5, 0.9], [0.5, 0.1]], evidence=['Weather'], evidence_card=[2], state_names={'Sprinkler': ['Off', 'On'], 'Weather': ['Sunny', 'Rainy']})
cpd_grass_wet = TabularCPD(variable='GrassWet', variable_card=2,values=[[0.0, 0.0, 0.9, 0.9], [1.0, 0.1, 0.1, 0.1]], evidence=['Weather', 'Sprinkler'], evidence_card=[2, 2],state_names={'GrassWet': ['Dry', 'Wet'], 'Weather': ['Sunny', 'Rainy'], 'Sprinkler': ['Off', 'On']})# 添加CPDs到模型
model.add_cpds(cpd_weather, cpd_sprinkler, cpd_grass_wet)# 检查模型是否完全指定
assert model.check_model()# 查询概率
# 例如,查询在已知天气为晴天的情况下,草地湿润的概率
query = model.query(['GrassWet'])
print(query.values[{'Weather': 'Sunny'}])这段代码首先定义了一个贝叶斯网络模型,并为每个节点分配了条件概率分布。然后,通过查询模型,我们可以计算出在特定条件下某个变量的概率,比如在已知天气为晴天时,草地湿润的概率。请注意,实际应用中,这些概率值应基于真实数据或领域知识来设定。
10.灰色预测模型
灰色预测模型是统计建模中的一种方法,主要用于处理含有不确定性信息的系统预测问题。它特别适用于数据量有限、信息不完全或者系统内部机理不甚明确的情况。灰色预测理论由邓聚龙教授于1982年首次提出,基于灰色系统理论,认为尽管系统中的现象可能表现为随机和杂乱无章,但本质上是有序和有界的,可以通过灰色预测模型揭示隐藏的规律,从而对未来状态进行预测。
python实现统计建模灰色预测模型
灰色预测模型,特别是灰色系统理论中的GM(1,1)模型,常用于具有较少数据且带有一定不确定性的短期预测问题。在Python中实现灰色预测模型,可以使用greyatom-python库,这是一个专为灰色预测设计的库。然而,该库不如statsmodels或sklearn那样广泛使用,因此在某些情况下,你可能需要自己实现算法逻辑。以下是使用Python手动实现GM(1,1)模型的一个基本示例:
安装greyatom-python(可选)
尽管不是必需的,但如果你希望使用专门的库来简化过程,可以尝试安装greyatom-python:
pip install greyatom-python手动实现GM(1,1)模型
如果不想使用外部库,可以手动实现GM(1,1)模型的步骤。以下是一个简化的实现:
import numpy as np
from scipy.optimize import minimizedef generate_sequence(data, alpha):"""生成GM(1,1)模型的一阶累加生成序列"""sequence = np.cumsum(data)return sequencedef gm11_model(x, data):"""定义GM(1,1)模型的目标函数,用于最小化残差平方和"""u = generate_sequence(data, x[0]) # 根据参数alpha生成一阶累加序列zu = np.diff(u) # 计算一阶差分zu = np.insert(zu, 0, 0) # 插入初始值0,保持长度一致a = x[0] # 参数ab = x[1] # 参数be = np.power((u[:-1] - (b + a * zu[:-1])), 2).sum() # 残差平方和return edef predict_next(data, alpha, beta):"""根据模型参数预测下一个值"""last_u = np.cumsum(data)[-1] # 最后一个累加值next_zu = beta + alpha * (last_u - data[-1]) # 计算下一个一阶差分next_data = data[-1] + next_zu # 预测下一个值return next_data# 示例数据
data = np.array([10, 20, 30, 40, 50])# 初始参数猜测
x0 = np.array([0.5, 10]) # alpha, beta# 最小化目标函数找到最佳参数
res = minimize(gm11_model, x0, args=(data,), method='Nelder-Mead')alpha_opt, beta_opt = res.x # 最优参数# 预测下一个值
next_prediction = predict_next(data, alpha_opt, beta_opt)
print(f"Next predicted value: {next_prediction}")这段代码首先定义了生成一阶累加序列和GM(1,1)模型目标函数的函数,然后使用优化算法(如Nelder-Mead)寻找使残差平方和最小化的模型参数。最后,根据得到的参数预测序列的下一个值。
请注意,手动实现可能在数值稳定性、效率或功能完整性方面不如成熟库。对于更复杂的需求,建议查找并使用经过良好测试的第三方库。
以上仅列举了部分统计建模方法及其应用方式,实际应用中还会涉及更多其他模型和技术,如支持向量机(SVM)、神经网络、深度学习模型、混合模型、马尔科夫链蒙特卡洛方法(MCMC)等,具体选择取决于数据特性、研究目的、领域知识以及计算资源等因素。