1.低级语言和高级语言
计算机硬件只能识别由0、1组成的机器指令序列,即机器指令程序,因此机器指令是最基本的计算机语言。由于机器指令是特定的计算机系统所固有的、面向机器的语言,所以用机器语言进行程序设计时效率很低,程序的可读性很差,也难以修改和维护。因此,人们就用容易记忆的符号代替0、1序列来表示机器指令,例如,用ADD 表示加法、用SUB 表示减法等。
用符号表示的指令称为汇编指令,汇编指令的集合被称为汇编语言。汇编语言与机器语言十分接近,其书写格式在很大程度上取决于特定计算机的机器指令,因此它仍然是一种面向机器的
语言,人们称机器语言和汇编语言为低级语言。在此基础上,人们开发了功能更强、抽象级别更高的语言以支持程序设计,于是就产生了面向各类应用的程序设计语言,称为高级语言。常见的有Java、C、C++、PHP、Python、Delphi、PASCAL等。这类语言与人们使用的自然语言比较接近,提高了程序设计的效率。
2.编译程序和解释程序
计算机只能理解由0、1序列构成的机器语言,因此高级程序设计语言需要翻译,担负这一任得的程序称为“语言处理程序”。语言之间的翻译形式有多种,基本方式为汇编、解释和编译。
用某种高级语言或汇编语言编写的程序称为源程序,源程序不能直接在计算机上执行。如果源程序是用汇编语言编写的,则需要一个汇编程序将其翻译成目标程序后才能执行。如果源
程序是用某种高级语言编写的,则需要对应的解释程序或编译程序对其进行翻译,然后在机器上运行。
解释程序也称为解释器,它或者直接解释执行源程序,或者将源程序翻译成某种中间代码后再加以执行:而编译程序(编译器)则是将源程序翻译成目标语言程序,然后在计算机上运行目标程序。这两种语言处理程序的根本区别是:在编译方式下,机器上运行的是与源程序等价的目标程序,源程序和编译程序都不再参与目标程序的执行过程:而在解释方式下,解释程序和源程序(或其某种等价表示)要参与到程序的运行过程中,运行程序的控制权在解释程序。
简单来说,在解释方式下,翻译源程序时不生成独立的目标程序,而编译器则将源程序翻译成独立保存的目标程序。

3.程序设计语言的控制成分
控制成分指明语言允许表述的控制结构,程序员使用控制成分来构造程序中的控制逻辑。理论上已经证明,可计算问题的程序都可以用顺序、选择和循环这3种控制结构来描述。
l)顺序结构
2)选择结构
3)循环结构
4.函数传值或传地址
1)函数定义
函数的定义包括两部分:函数首部和函数体。函数的定义描述了函数做什么和怎么做。函数定义的一般形式为:

(1)值调用(Call by Value)。若实现函数调用时将实参的值传递给相应的形参,则称为是传值调用。在这种方式下形参不能向实参传递信息。
(2)引用调用 (Call by Reference)。引用是 C++中引入的概念,当形式参数为引用类型时,形参名实际上是实参的别名,函数中对形参的访问和修改实际上就是针对相应实参所做的访问和改变。

5.程序翻译阶段


6.符号表

符号表管理
符号表的作用是记录源程序中各个符号的必要信息,以辅助语义的正确性检查和代码生成,在编译过程中需要对符号表进行快速有效地查找、插入、修改和删除等操作。符号表的建立可以始于词法分析阶段,也可以放到语法分析和语义分析阶段,但符号表的使用有时会延续到目标代码的运行阶段。
7.程序编译过程
7.1词法分析
源程序可以简单地被看成是一个多行的字符串。词法分析阶段是编译过程的
第一个阶段,这个阶段的任务是对源程序从前到后(从左到右)逐个字符地扫描,从中识别出一个个“单词”符号。“单词”符号是程序设计语言的基本语法单位,如关键字(或称保留字)、标识符、常数、运算符和分隔符(如标点符号、左右括号)等。词法分析程序输出的“单词”常以二元组的方式输出,即单词种别和单词自身的值。词法分析过程依据的是语言的词法规则,即描述“单词”结构的规则。例如,对于某 PASCAL源程序中的一条声明语句和赋值语句:

7.2语法分析
语法分析的任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,如“表达式”“语句”和“程序”等。语法规则就是各类语法单位的构成规则。通过语法分析确定整个输入串是否构成一个语法上正确的程序。如果源程序中没有语法错误,语法分析后就能正确地构造出其语法树;否则指出语法错误,并给出相应的诊断信息。


7.3语义分析
语义分析阶段分析各语法结构的含义,检查源程序是否包含静态语义错误,并收集类型信息供后面的代码生成阶段使用。只有语法和语义都正确的源程序才能翻译成正确的目标代码。
语义分析的一个主要工作是进行类型分析和检查。程序设计语言中的一个数据类型一般包含两个方面的内容:类型的载体及其上的运算。例如,整除取余运算符只能对整型数据进行运算,若其运算对象中有浮点数就认为是类型不匹配的错误。
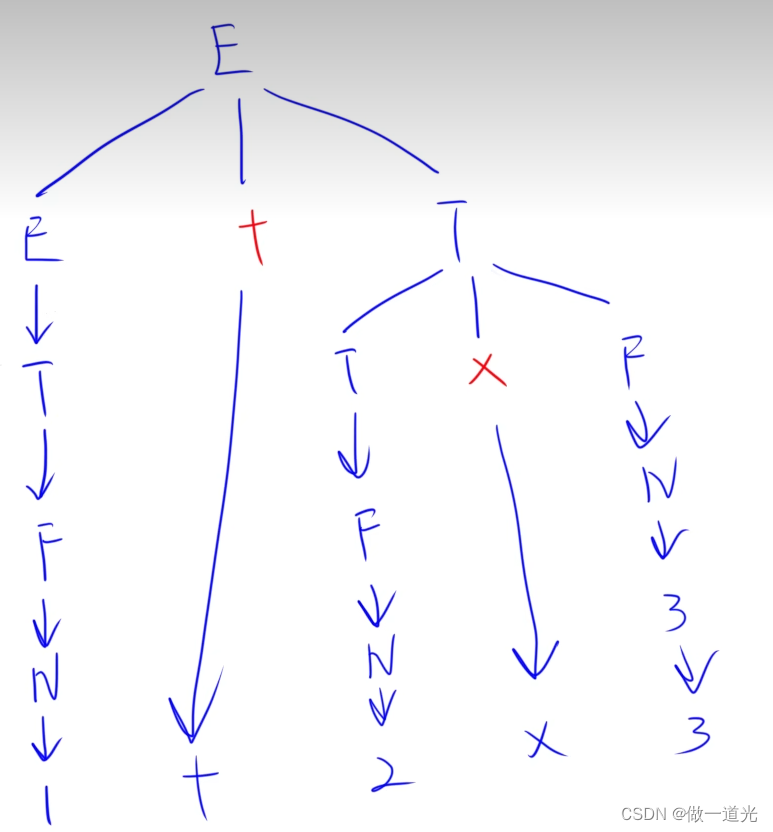
在确认源程序的语法和语义之后,即可对其进行翻译并给出源程序的内部表示。对于声明语句,需要记录所遇到的符号的信息,所以应进行符号表的填查工作。在图2-6所示的符号表中,每一行存放一个符号的信息。第一行存放标识符X的信息,其类型为real,为它分配的逻辑地址是0;第二行存放丫的信息,其类型是real,为它分配的逻辑地址是4。在这种语言中,为一个real型数据分配的存储空间是4个存储单元。对于可执行语句,则检查结构合理的表达式是否有意义。对id1:=id2+id3*60 进行语义分析后的语法树如图2-6所示,其中增加了一个语义处理结点inttoreal,该运算用于将一个整型数转换为浮点数。

7.4目标代码生成
目标代码生成是编译器工作的最后一个阶段。这一阶段的任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码,这个阶段的工作与具体的机器密切相关。例如,使用两个寄存器R1和R2,可对上述的四元式生成下面的目标代码:

这里用#表明60.0为常数。
(3)寄存器的分配。由于访问寄存器的速度远远快于访问内存单元的速度,所以人们总是希望尽可能多地使用寄存器存储数据,而寄存器的个数是有限的,因此,如何分配及使用寄存器是目标代码生成时需要着重考虑的。

7.5动态语义错误
语义分析只能检测出程序的静态语义错误,不能检测出动态的语义错误,要到程序运行时,才能检测出来。
7.6目标代码的生成


8. 正规式

9.有限自动机


10.上下文无关法