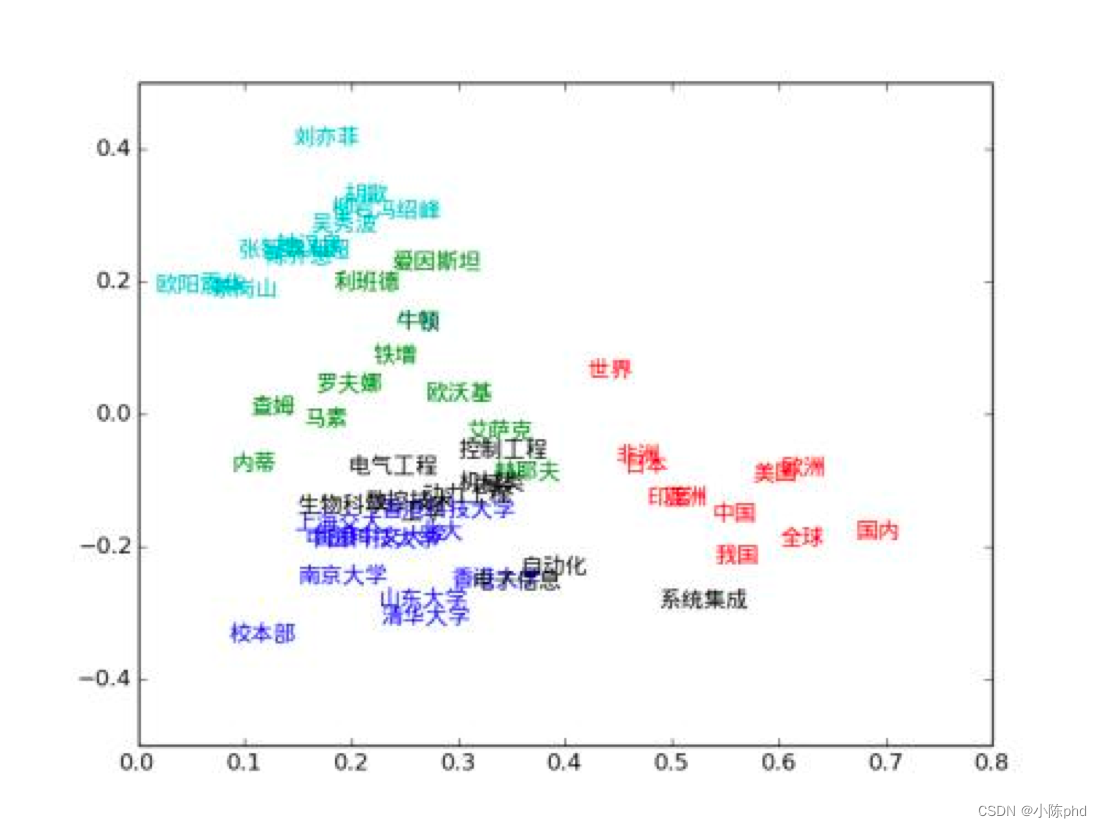
词向量介绍
- 词向量(Word embedding),即把词语表示成实数向量。“好”的词向量能体现词语直接的相近关系。词向量已经被证明可以提高NLP任务的性能,例如语法分析和情感分析。
- 词向量与词嵌入技术的提出是为了解决onehot的缺陷。它把每个词表示成连续稠密的向量,能较好地表达不同词之间的关联关系。
- 如果两个词是关联的,那么这两个词分别对应的词向量的余弦相似度越接近于1。如果两个词关联关系比较小,那么这两个词分别对应的词向量的余弦相似度越接近于0.
1.1 加载TokenEmbedding
TokenEmbedding()参数
embedding_name
将模型名称以参数形式传入TokenEmbedding,加载对应的模型。默认为w2v.baidu_encyclopedia.target.word-word.dim300的词向量。unknown_token
未知token的表示,默认为[UNK]。unknown_token_vector
未知token的向量表示,默认生成和embedding维数一致,数值均值为0的正态分布向量。extended_vocab_path
扩展词汇列表文件路径,词表格式为一行一个词。如引入扩展词汇列表,trainable=True。trainable
Embedding层是否可被训练。True表示Embedding可以更新参数,False为不可更新。默认为True。dim300代表该词向量维度大小为300.
这里参考的预训练embedding 包括以下:
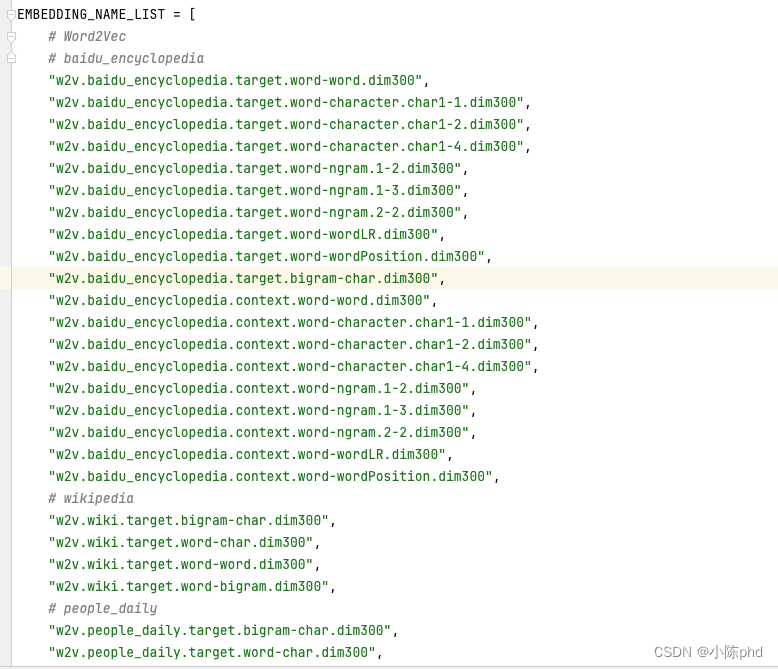
EMBEDDING_NAME_LIST = [# Word2Vec# baidu_encyclopedia"w2v.baidu_encyclopedia.target.word-word.dim300","w2v.baidu_encyclopedia.target.word-character.char1-1.dim300","w2v.baidu_encyclopedia.target.word-character.char1-2.dim300","w2v.baidu_encyclopedia.target.word-character.char1-4.dim300","w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300","w2v.baidu_encyclopedia.target.word-ngram.1-3.dim300","w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300","w2v.baidu_encyclopedia.target.word-wordLR.dim300","w2v.baidu_encyclopedia.target.word-wordPosition.dim300","w2v.baidu_encyclopedia.target.bigram-char.dim300","w2v.baidu_encyclopedia.context.word-word.dim300","w2v.baidu_encyclopedia.context.word-character.char1-1.dim300","w2v.baidu_encyclopedia.context.word-character.char1-2.dim300","w2v.baidu_encyclopedia.context.word-character.char1-4.dim300","w2v.baidu_encyclopedia.context.word-ngram.1-2.dim300","w2v.baidu_encyclopedia.context.word-ngram.1-3.dim300","w2v.baidu_encyclopedia.context.word-ngram.2-2.dim300","w2v.baidu_encyclopedia.context.word-wordLR.dim300","w2v.baidu_encyclopedia.context.word-wordPosition.dim300",# wikipedia"w2v.wiki.target.bigram-char.dim300","w2v.wiki.target.word-char.dim300","w2v.wiki.target.word-word.dim300","w2v.wiki.target.word-bigram.dim300",# people_daily"w2v.people_daily.target.bigram-char.dim300","w2v.people_daily.target.word-char.dim300","w2v.people_daily.target.word-word.dim300","w2v.people_daily.target.word-bigram.dim300",# weibo"w2v.weibo.target.bigram-char.dim300","w2v.weibo.target.word-char.dim300","w2v.weibo.target.word-word.dim300","w2v.weibo.target.word-bigram.dim300",# sogou"w2v.sogou.target.bigram-char.dim300","w2v.sogou.target.word-char.dim300","w2v.sogou.target.word-word.dim300","w2v.sogou.target.word-bigram.dim300",# zhihu"w2v.zhihu.target.bigram-char.dim300","w2v.zhihu.target.word-char.dim300","w2v.zhihu.target.word-word.dim300","w2v.zhihu.target.word-bigram.dim300",# finacial"w2v.financial.target.bigram-char.dim300","w2v.financial.target.word-char.dim300","w2v.financial.target.word-word.dim300","w2v.financial.target.word-bigram.dim300",# literature"w2v.literature.target.bigram-char.dim300","w2v.literature.target.word-char.dim300","w2v.literature.target.word-word.dim300","w2v.literature.target.word-bigram.dim300",# siku"w2v.sikuquanshu.target.word-word.dim300","w2v.sikuquanshu.target.word-bigram.dim300",# Mix-large"w2v.mixed-large.target.word-char.dim300","w2v.mixed-large.target.word-word.dim300",# GOOGLE NEWS"w2v.google_news.target.word-word.dim300.en",# GloVe"glove.wiki2014-gigaword.target.word-word.dim50.en","glove.wiki2014-gigaword.target.word-word.dim100.en","glove.wiki2014-gigaword.target.word-word.dim200.en","glove.wiki2014-gigaword.target.word-word.dim300.en","glove.twitter.target.word-word.dim25.en","glove.twitter.target.word-word.dim50.en","glove.twitter.target.word-word.dim100.en","glove.twitter.target.word-word.dim200.en",# FastText"fasttext.wiki-news.target.word-word.dim300.en","fasttext.crawl.target.word-word.dim300.en",
]
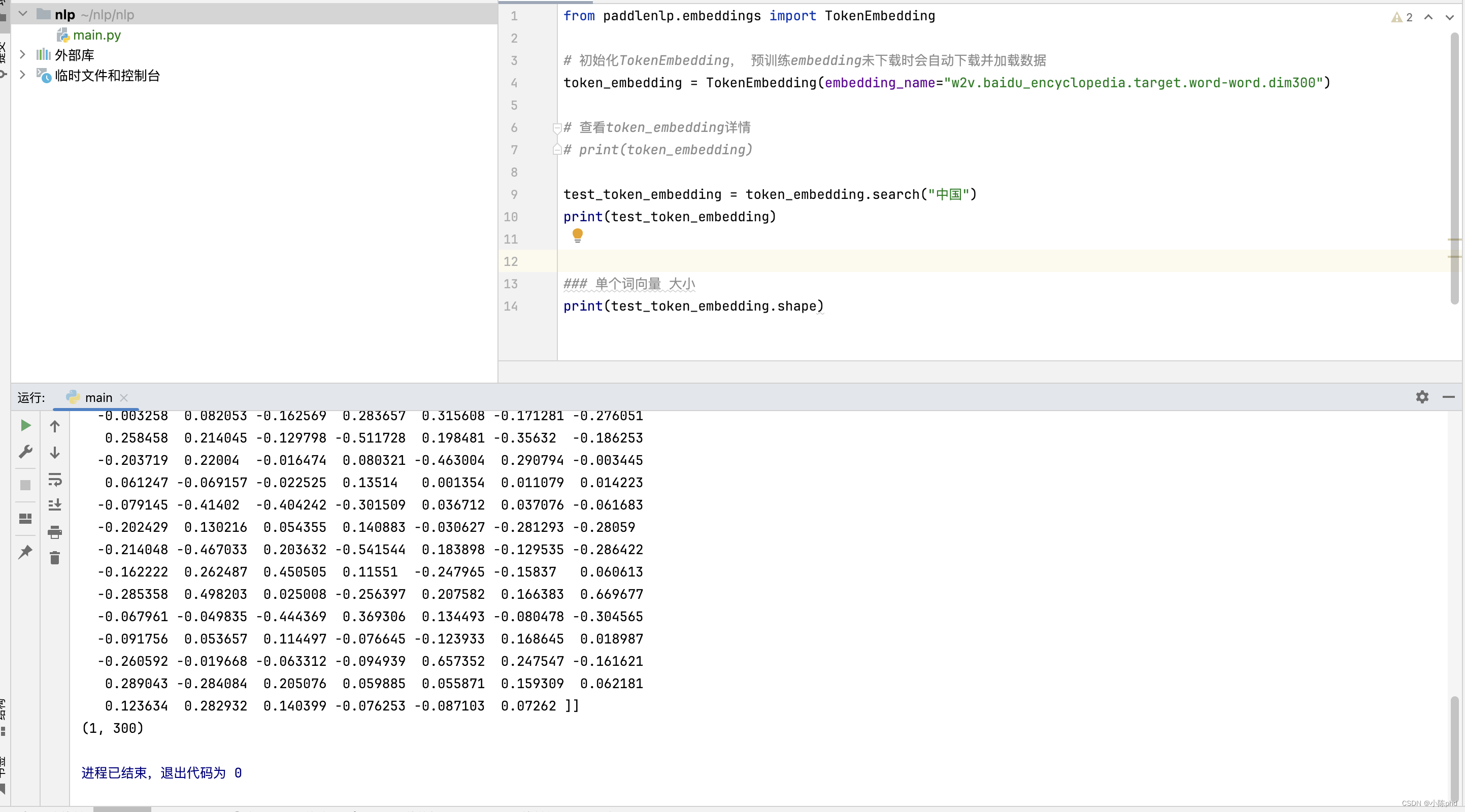
from paddlenlp.embeddings import TokenEmbedding# 初始化TokenEmbedding, 预训练embedding未下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")# 查看token_embedding详情
print(token_embedding)

1.2 认识一下Embedding
TokenEmbedding.search()
1.3 单词相似度对比
TokenEmbedding.cosine_sim()
计算词向量间余弦相似度,语义相近的词语余弦相似度更高,说明预训练好的词向量空间有很好的语义表示能力。
score1 = token_embedding.cosine_sim("女孩", "女人")
score2 = token_embedding.cosine_sim("女孩", "书籍")
print('score1:', score1)
print('score2:', score2)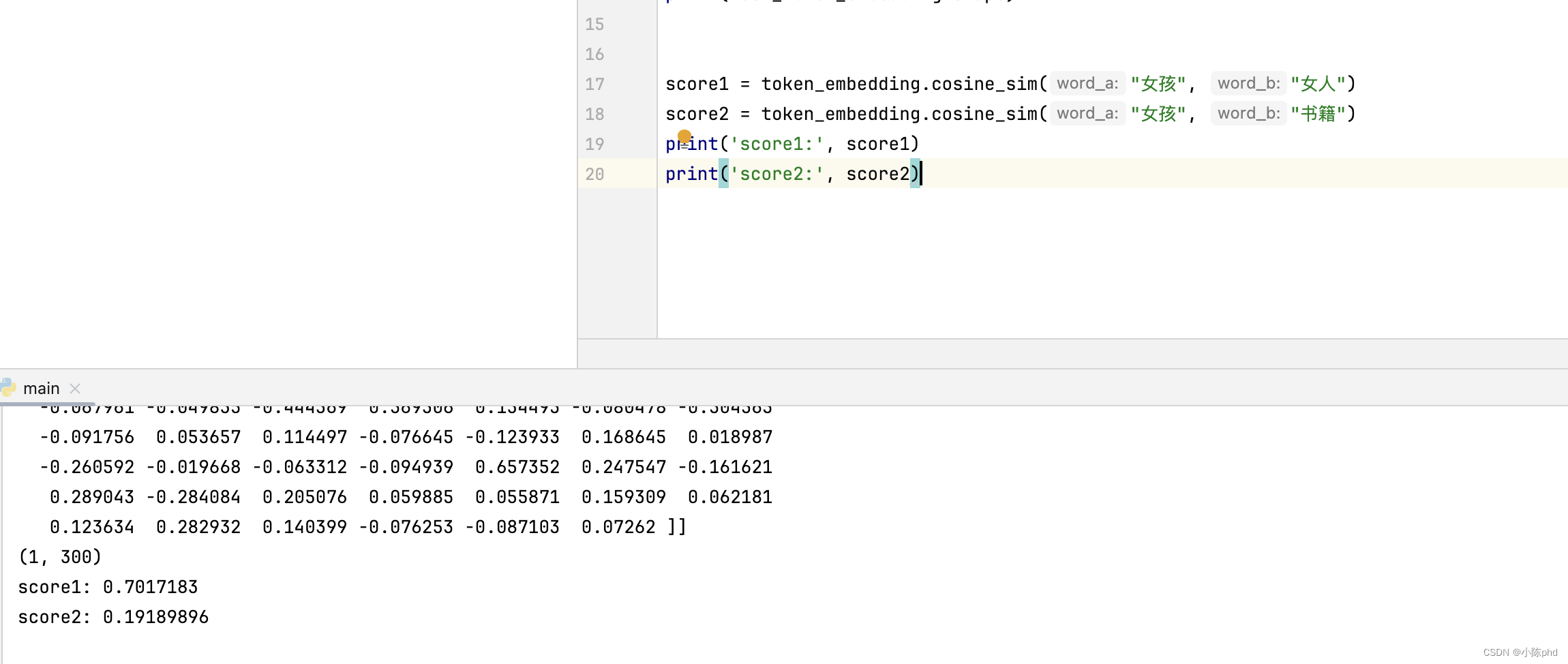
2. 基于TokenEmbedding衡量句子语义相似度
在许多实际应用场景(如文档检索系统)中, 需要衡量两个句子的语义相似程度。此时我们可以使用词袋模型(Bag of Words,简称BoW)计算句子的语义向量。
首先,将两个句子分别进行切词,并在TokenEmbedding中查找相应的单词词向量(word embdding)。
然后,根据词袋模型,将句子的word embedding叠加作为句子向量(sentence embedding)。
最后,计算两个句子向量的余弦相似度。
2.1 基于TokenEmbedding的词袋模型
使用BoWEncoder搭建一个BoW模型用于计算句子语义。
paddlenlp.TokenEmbedding组建word-embedding层paddlenlp.seq2vec.BoWEncoder组建句子建模层- 通过词袋编码和余弦相似度计算来评估两个文本之间的相似度
class BoWModel(nn.Layer):def __init__(self, embedder):super().__init__()self.embedder = embedderemb_dim = self.embedder.embedding_dim# 编码self.encoder = paddlenlp.seq2vec.BoWEncoder(emb_dim)# 计算相似度self.cos_sim_func = nn.CosineSimilarity(axis=-1)def get_cos_sim(self, text_a, text_b):text_a_embedding = self.forward(text_a)text_b_embedding = self.forward(text_b)cos_sim = self.cos_sim_func(text_a_embedding, text_b_embedding)return cos_simdef forward(self, text):# Shape: (batch_size, num_tokens, embedding_dim)embedded_text = self.embedder(text)# Shape: (batch_size, embedding_dim)summed = self.encoder(embedded_text)return summed2.2 使用 JiebaTokenizer 进行高效的中文文本分词
在处理中文自然语言处理任务时,文本分词是一个非常关键的步骤。本文将详细介绍如何使用 JiebaTokenizer,一个基于 jieba 分词库的自定义分词器类,进行中文文本的分词及其转换为词汇索引。
class JiebaTokenizer():"""Constructs a tokenizer based on `jieba <https://github.com/fxsjy/jieba>`__.It supports :meth:`cut` method to split the text to tokens, and :meth:`encode`method to covert text to token ids.Args:vocab(paddlenlp.data.Vocab): An instance of :class:`paddlenlp.data.Vocab`."""def __init__(self, vocab):super(JiebaTokenizer, self).__init__(vocab)self.tokenizer = jieba.Tokenizer()# initialize tokenizerself.tokenizer.FREQ = {key: 1 for key in self.vocab.token_to_idx.keys()}self.tokenizer.total = len(self.tokenizer.FREQ)self.tokenizer.initialized = Truedef get_tokenizer(self):return self.tokenizerdef cut(self, sentence, cut_all=False, use_hmm=True):"""The method used to cut the text to tokens.Args:sentence(str): The text that needs to be cuted.cut_all(bool, optional): Whether to use the full mode. If True,using full mode that gets all the possible words from thesentence, which is fast but not accurate. If False, usingaccurate mode that attempts to cut the sentence into the mostaccurate segmentations, which is suitable for text analysis.Default: False.use_hmm(bool, optional): Whether to use the HMM model. Default: True.Returns:list[str]: A list of tokens.Example:.. code-block:: pythonfrom paddlenlp.data import Vocab, JiebaTokenizer# The vocab file. The sample file can be downloaded firstly.# wget https://bj.bcebos.com/paddlenlp/data/senta_word_dict.txtvocab_file_path = './senta_word_dict.txt'# Initialize the Vocabvocab = Vocab.load_vocabulary(vocab_file_path,unk_token='[UNK]',pad_token='[PAD]')tokenizer = JiebaTokenizer(vocab)tokens = tokenizer.cut('我爱你中国')print(tokens)# ['我爱你', '中国']"""return self.tokenizer.lcut(sentence, cut_all, use_hmm)def encode(self, sentence, cut_all=False, use_hmm=True):"""The method used to convert the text to ids. It will firstly call:meth:`cut` method to cut the text to tokens. Then, convert tokens toids using `vocab`.Args:sentence(str): The text that needs to be cuted.cut_all(bool, optional): Whether to use the full mode. If True,using full mode that gets all the possible words from thesentence, which is fast but not accurate. If False, usingaccurate mode that attempts to cut the sentence into the mostaccurate segmentations, which is suitable for text analysis.Default: False.use_hmm(bool, optional): Whether to use the HMM model. Default: True.Returns:list[int]: A list of ids.Example:.. code-block:: pythonfrom paddlenlp.data import Vocab, JiebaTokenizer# The vocab file. The sample file can be downloaded firstly.# wget https://bj.bcebos.com/paddlenlp/data/senta_word_dict.txtvocab_file_path = './senta_word_dict.txt'# Initialize the Vocabvocab = Vocab.load_vocabulary(vocab_file_path,unk_token='[UNK]',pad_token='[PAD]')tokenizer = JiebaTokenizer(vocab)ids = tokenizer.encode('我爱你中国')print(ids)# [1170578, 575565]"""words = self.cut(sentence, cut_all, use_hmm)return [get_idx_from_word(word, self.vocab.token_to_idx, self.vocab.unk_token) for word in words]2.2.1 JiebaTokenizer 类的设计与实现
初始化 jieba.Tokenizer 实例,并设置词频和总词数以匹配提供的词汇表 vocab。
class JiebaTokenizer():def __init__(self, vocab):super(JiebaTokenizer, self).__init__(vocab)self.tokenizer = jieba.Tokenizer()# initialize tokenizerself.tokenizer.FREQ = {key: 1 for key in self.vocab.token_to_idx.keys()}self.tokenizer.total = len(self.tokenizer.FREQ)self.tokenizer.initialized = True
2.2.2 分词方法 cut
cut 方法用于将输入的中文句子分割成词汇单元列表。它允许用户选择全模式或精确模式分词,以及是否使用 HMM 模型。这里,lcut 方法来自 jieba 库,根据 cut_all 和 use_hmm 参数返回最适合的分词结果。
def cut(self, sentence, cut_all=False, use_hmm=True):return self.tokenizer.lcut(sentence, cut_all, use_hmm)
2.2.3 编码方法 encode
在 encode 方法中,我们首先使用 cut 方法对句子进行分词,然后将分词结果转换为词汇索引。
def encode(self, sentence, cut_all=False, use_hmm=True):words = self.cut(sentence, cut_all, use_hmm)return [self.vocab.token_to_idx.get(word, self.vocab.unk_token) for word in words]
展示如何将分词结果映射到它们对应的索引值。若词汇不存在于词汇表中,则使用未知词标记 unk_token。JiebaTokenizer 提供了一个强大且灵活的方式来处理中文文本,非常适合用于自然语言处理中的文本预处理。通过这个类,开发者可以轻松地集成 jieba 的分词功能到自己的 NLP 项目中,提高文本处理的效率和精度。
计算得到句子之间的相似度
text_pairs = {}with open("data/text_pair.txt", "r", encoding="utf8") as f:for line in f:text_a, text_b = line.strip().split("\t")if text_a not in text_pairs:text_pairs[text_a] = []text_pairs[text_a].append(text_b)for text_a, text_b_list in text_pairs.items():text_a_ids = paddle.to_tensor([tokenizer.text_to_ids(text_a)])for text_b in text_b_list:text_b_ids = paddle.to_tensor([tokenizer.text_to_ids(text_b)])print("text_a: {}".format(text_a))print("text_b: {}".format(text_b))print("cosine_sim: {}".format(model.get_cos_sim(text_a_ids, text_b_ids).numpy()[0]))# print()
参考百度飞桨链接:PaddleNLP词向量应用展示